

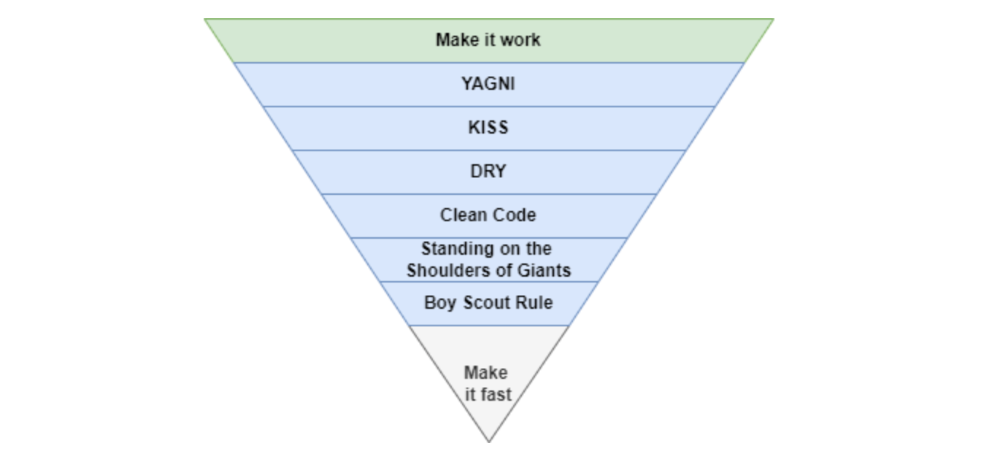
More on Technology
Colin Faife
3 years ago
The brand-new USB Rubber Ducky is much riskier than before.
The brand-new USB Rubber Ducky is much riskier than before.

With its own programming language, the well-liked hacking tool may now pwn you.
With a vengeance, the USB Rubber Ducky is back.
This year's Def Con hacking conference saw the release of a new version of the well-liked hacking tool, and its author, Darren Kitchen, was on hand to explain it. We put a few of the new features to the test and discovered that the most recent version is riskier than ever.
WHAT IS IT?
The USB Rubber Ducky seems to the untrained eye to be an ordinary USB flash drive. However, when you connect it to a computer, the computer recognizes it as a USB keyboard and will accept keystroke commands from the device exactly like a person would type them in.
Kitchen explained to me, "It takes use of the trust model built in, where computers have been taught to trust a human, in that anything it types is trusted to the same degree as the user is trusted. And a computer is aware that clicks and keystrokes are how people generally connect with it.

Over ten years ago, the first Rubber Ducky was published, quickly becoming a hacker favorite (it was even featured in a Mr. Robot scene). Since then, there have been a number of small upgrades, but the most recent Rubber Ducky takes a giant step ahead with a number of new features that significantly increase its flexibility and capability.
WHERE IS ITS USE?
The options are nearly unlimited with the proper strategy.
The Rubber Ducky has already been used to launch attacks including making a phony Windows pop-up window to collect a user's login information or tricking Chrome into sending all saved passwords to an attacker's web server. However, these attacks lacked the adaptability to operate across platforms and had to be specifically designed for particular operating systems and software versions.

The nuances of DuckyScript 3.0 are described in a new manual.
The most recent Rubber Ducky seeks to get around these restrictions. The DuckyScript programming language, which is used to construct the commands that the Rubber Ducky will enter into a target machine, receives a significant improvement with it. DuckyScript 3.0 is a feature-rich language that allows users to write functions, store variables, and apply logic flow controls, in contrast to earlier versions that were primarily limited to scripting keystroke sequences (i.e., if this... then that).
This implies that, for instance, the new Ducky can check to see if it is hooked into a Windows or Mac computer and then conditionally run code specific to each one, or it can disable itself if it has been attached to the incorrect target. In order to provide a more human effect, it can also generate pseudorandom numbers and utilize them to add a configurable delay between keystrokes.
The ability to steal data from a target computer by encoding it in binary code and transferring it through the signals intended to instruct a keyboard when the CapsLock or NumLock LEDs should light up is perhaps its most astounding feature. By using this technique, a hacker may plug it in for a brief period of time, excuse themselves by saying, "Sorry, I think that USB drive is faulty," and then take it away with all the credentials stored on it.
HOW SERIOUS IS THE RISK?
In other words, it may be a significant one, but because physical device access is required, the majority of people aren't at risk of being a target.
The 500 or so new Rubber Duckies that Hak5 brought to Def Con, according to Kitchen, were his company's most popular item at the convention, and they were all gone on the first day. It's safe to suppose that hundreds of hackers already possess one, and demand is likely to persist for some time.
Additionally, it has an online development toolkit that can be used to create attack payloads, compile them, and then load them onto the target device. A "payload hub" part of the website makes it simple for hackers to share what they've generated, and the Hak5 Discord is also busy with conversation and helpful advice. This makes it simple for users of the product to connect with a larger community.
It's too expensive for most individuals to distribute in volume, so unless your favorite cafe is renowned for being a hangout among vulnerable targets, it's doubtful that someone will leave a few of them there. To that end, if you intend to plug in a USB device that you discovered outside in a public area, pause to consider your decision.
WOULD IT WORK FOR ME?
Although the device is quite straightforward to use, there are a few things that could cause you trouble if you have no prior expertise writing or debugging code. For a while, during testing on a Mac, I was unable to get the Ducky to press the F4 key to activate the launchpad, but after forcing it to identify itself using an alternative Apple keyboard device ID, the problem was resolved.
From there, I was able to create a script that, when the Ducky was plugged in, would instantly run Chrome, open a new browser tab, and then immediately close it once more without requiring any action from the laptop user. Not bad for only a few hours of testing, and something that could be readily changed to perform duties other than reading technology news.

Gareth Willey
3 years ago
I've had these five apps on my phone for a long time.
TOP APPS
Who survives spring cleaning?

Relax. Notion is off-limits. This topic is popular.
(I wrote about it 2 years ago, before everyone else did.) So).
These apps are probably new to you. I hope you find a new phone app after reading this.
Outdooractive
ViewRanger is Google Maps for outdoor enthusiasts.
This app has been so important to me as a freedom-loving long-distance walker and hiker.
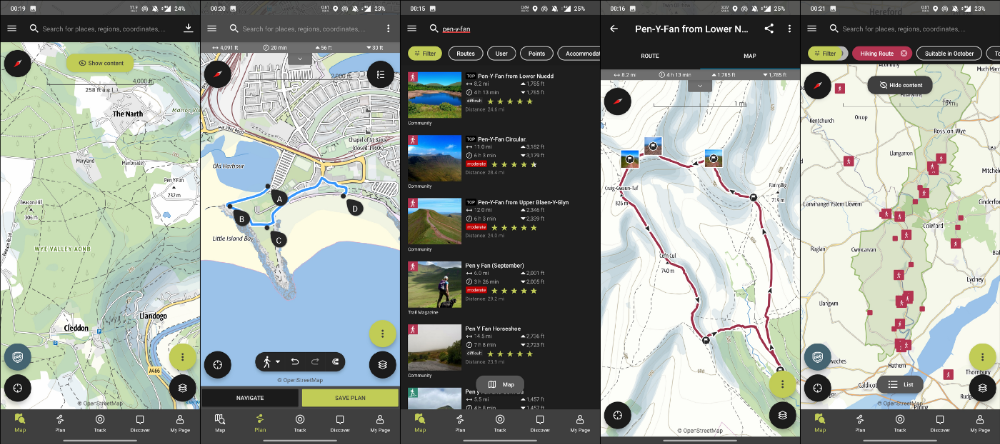
This app shows nearby trails and right-of-ways on top of an Open Street Map.
Helpful detail and data. Any route's distance,
You can download and follow tons of routes planned by app users.
This has helped me find new routes and places a fellow explorer has tried.
Free with non-intrusive ads. Years passed before I subscribed. Pro costs £2.23/month.

This app is for outdoor lovers.
Google Files
New phones come with bloatware. These rushed apps are frustrating.
We must replace these apps. 2017 was Google's year.
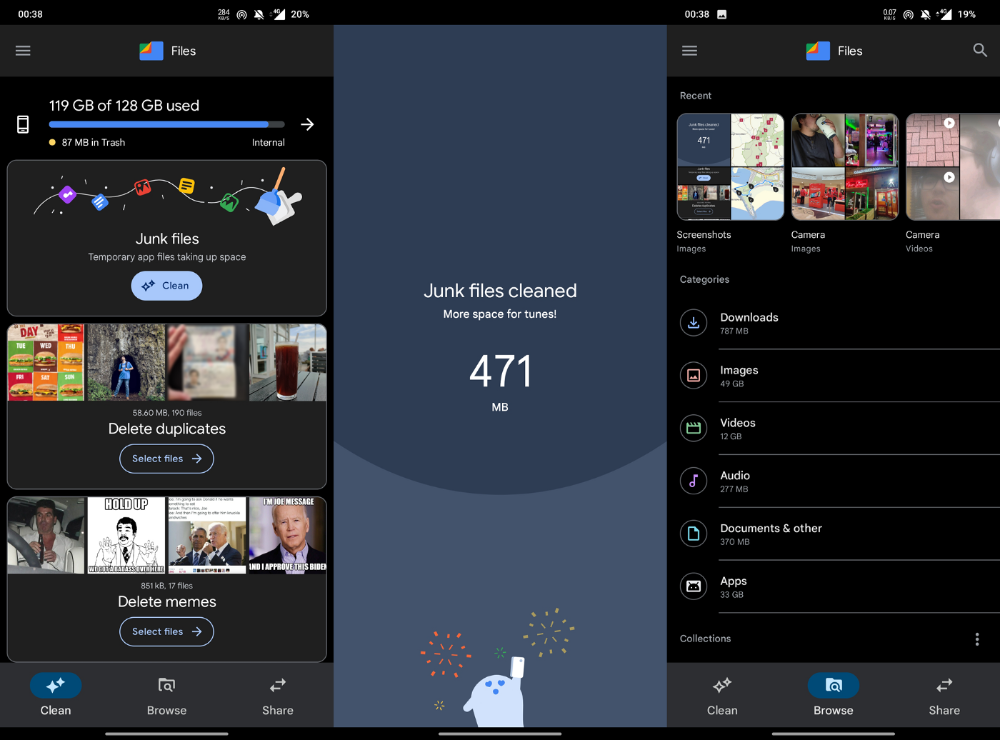
Files is a file manager. It's quick, innovative, and clean. They've given people what they want.
It's easy to organize files, clear space, and clear cache.
I recommend Gallery by Google as a gallery app alternative. It's quick and easy.
Trainline
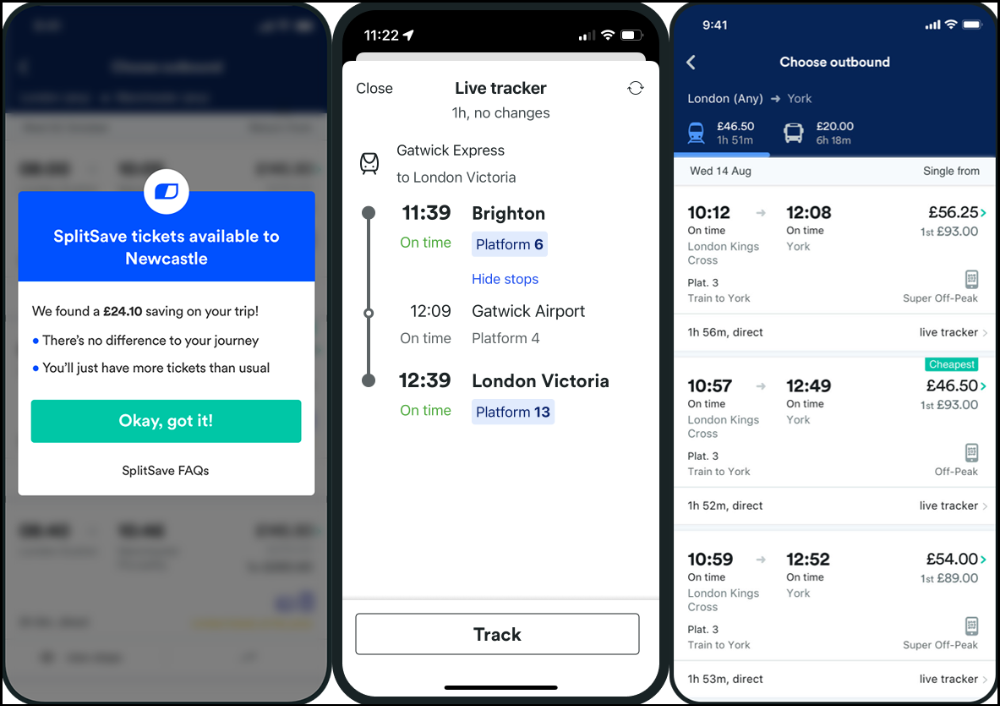
App for trains, buses, and coaches.
I've used this app for years. It did the basics well when I first used it.
Since then, it's improved. It's constantly adding features to make traveling easier and less stressful.
Split-ticketing helps me save hundreds a year on train fares. This app is only available in the UK and Europe.
This service doesn't link to a third-party site. Their app handles everything.
Not all train and coach companies use this app. All the big names are there, though.
Here's more on the app.
Battlefield: Mobile
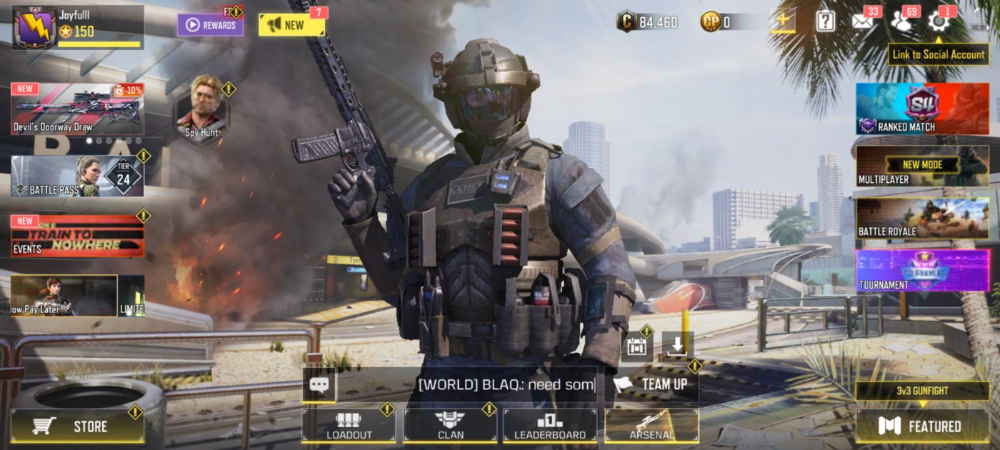
Play Store has 478,000 games. Few can turn my phone into a console.
Call of Duty Mobile and Asphalt 8/9 are examples.
Asphalt's loot boxes and ads make it unplayable. Call of Duty opens with a few ads. Close them to play without hassle.
This game uses all your phone's features to provide a high-quality, seamless experience. If my internet connection is good, I never experience lag or glitches.
The gameplay is energizing and intense, just like on consoles. Sometimes I'm too involved. I've thrown my phone in anger. I'm totally absorbed.
Customizability is my favorite. Since phones have limited screen space, we should only have the buttons we need, placed conveniently.
Size, opacity, and position are modifiable. Adjust audio, graphics, and textures. It's customizable.
This game has been on my phone for three years. It began well and has gotten better. When I think the creators can't do more, they do.
If you play, read my tips for winning a Battle Royale.
Lightroom
As a photographer, I believe your best camera is on you. The phone.
2017 was a big year for this app. I've tried many photo-editing apps since then. This always wins.
The app is dull. I've never seen better photo editing on a phone.
Adjusting settings and sliders doesn't damage or compress photos. It's detailed.
This is important for phone photos, which are lower quality than professional ones.
Some tools are behind a £4.49/month paywall. Adobe must charge a subscription fee instead of selling licenses. (I'm still bitter about Creative Cloud's price)
Snapseed is my pick. Lightroom is where I do basic editing before moving to Snapseed. Snapseed review:

These apps are great. They cover basic and complex editing needs while traveling.
Final Reflections
I hope you downloaded one of these. Share your favorite apps. These apps are scarce.

Jussi Luukkonen, MBA
3 years ago
Is Apple Secretly Building A Disruptive Tsunami?
A TECHNICAL THOUGHT
The IT giant is seeding the digital Great Renaissance.

Recently, technology has been dull.
We're still fascinated by processing speeds. Wearables are no longer an engineer's dream.
Apple has been quiet and avoided huge announcements. Slowness speaks something. Everything in the spaceship HQ seems to be turning slowly, unlike competitors around buzzwords.
Is this a sign of the impending storm?
Metas stock has fallen while Google milks dumb people. Microsoft steals money from corporations and annexes platforms like Linkedin.
Just surface bubbles?
Is Apple, one of the technology continents, pushing against all others to create a paradigm shift?
The fundamental human right to privacy
Apple's unusual remarks emphasize privacy. They incorporate it into their business models and judgments.
Apple believes privacy is a human right. There are no compromises.
This makes it hard for other participants to gain Apple's ecosystem's efficiencies.
Other players without hardware platforms lose.
Apple delivers new kidneys without rejection, unlike other software vendors. Nothing compromises your privacy.
Corporate citizenship will become more popular.
Apples have full coffers. They've started using that flow to better communities, which is great.
Apple's $2.5B home investment is one example. Google and Facebook are building or proposing to build workforce housing.
Apple's funding helps marginalized populations in more than 25 California counties, not just Apple employees.
Is this a trend, and does Apple keep giving back? Hope so.
I'm not cynical enough to suspect these investments have malicious motives.
The last frontier is the environment.
Climate change is a battle-to-win.
Long-term winners will be companies that protect the environment, turning climate change dystopia into sustainable growth.
Apple has been quietly changing its supply chain to be carbon-neutral by 2030.
“Apple is dedicated to protecting the planet we all share with solutions that are supporting the communities where we work.” Lisa Jackson, Apple’s vice president of environment.
Apple's $4.7 billion Green Bond investment will produce 1.2 gigawatts of green energy for the corporation and US communities. Apple invests $2.2 billion in Europe's green energy. In the Philippines, Thailand, Nigeria, Vietnam, Colombia, Israel, and South Africa, solar installations are helping communities obtain sustainable energy.
Apple is already carbon neutral today for its global corporate operations, and this new commitment means that by 2030, every Apple device sold will have net zero climate impact. -Apple.
Apple invests in green energy and forests to reduce its paper footprint in China and the US. Apple and the Conservation Fund are safeguarding 36,000 acres of US working forest, according to GreenBiz.
Apple's packaging paper is recycled or from sustainably managed forests.
What matters is the scale.
$1 billion is a rounding error for Apple.
These small investments originate from a tree with deep, spreading roots.
Apple's genes are anchored in building the finest products possible to improve consumers' lives.
I felt it when I switched to my iPhone while waiting for a train and had to pack my Macbook. iOS 16 dictation makes writing more enjoyable. Small change boosts productivity. Smooth transition from laptop to small screen and dictation.
Apples' tiny, well-planned steps have great growth potential for all consumers in everything they do.
There is clearly disruption, but it doesn't have to be violent
Digital channels, methods, and technologies have globalized human consciousness. One person's responsibility affects many.
Apple gives us tools to be privately connected. These technologies foster creativity, innovation, fulfillment, and safety.
Apple has invented a mountain of technologies, services, and channels to assist us adapt to the good future or combat evil forces who cynically aim to control us and ruin the environment and communities. Apple has quietly disrupted sectors for decades.
Google, Microsoft, and Meta, among others, should ride this wave. It's a tsunami, but it doesn't have to be devastating if we care, share, and cooperate with political decision-makers and community leaders worldwide.
A fresh Renaissance
Renaissance geniuses Michelangelo and Da Vinci. Different but seeing something no one else could yet see. Both were talented in many areas and could discover art in science and science in art.
These geniuses exemplified a period that changed humanity for the better. They created, used, and applied new, valuable things. It lives on.
Apple is a digital genius orchard. Wozniak and Jobs offered us fertile ground for the digital renaissance. We'll build on their legacy.
We may put our seeds there and see them bloom despite corporate greed and political ignorance.
I think the coming tsunami will illuminate our planet like the Renaissance.
You might also like

DC Palter
2 years ago
Why Are There So Few Startups in Japan?
Japan's startup challenge: 7 reasons

Every day, another Silicon Valley business is bought for a billion dollars, making its founders rich while growing the economy and improving consumers' lives.
Google, Amazon, Twitter, and Medium dominate our daily lives. Tesla automobiles and Moderna Covid vaccinations.
The startup movement started in Silicon Valley, California, but the rest of the world is catching up. Global startup buzz is rising. Except Japan.
644 of CB Insights' 1170 unicorns—successful firms valued at over $1 billion—are US-based. China follows with 302 and India third with 108.
Japan? 6!
1% of US startups succeed. The third-largest economy is tied with small Switzerland for startup success.
Mexico (8), Indonesia (12), and Brazil (12) have more successful startups than Japan (16). South Korea has 16. Yikes! Problem?
Why Don't Startups Exist in Japan More?
Not about money. Japanese firms invest in startups. To invest in startups, big Japanese firms create Silicon Valley offices instead of Tokyo.
Startups aren't the issue either. Local governments are competing to be Japan's Shirikon Tani, providing entrepreneurs financing, office space, and founder visas.
Startup accelerators like Plug and Play in Tokyo, Osaka, and Kyoto, the Startup Hub in Kobe, and Google for Startups are many.
Most of the companies I've encountered in Japan are either local offices of foreign firms aiming to expand into the Japanese market or small businesses offering local services rather than disrupting a staid industry with new ideas.
There must be a reason Japan can develop world-beating giant corporations like Toyota, Nintendo, Shiseido, and Suntory but not inventive startups.
Culture, obviously. Japanese culture excels in teamwork, craftsmanship, and quality, but it hates moving fast, making mistakes, and breaking things.
If you have a brilliant idea in Silicon Valley, quit your job, get money from friends and family, and build a prototype. To fund the business, you approach angel investors and VCs.
Most non-startup folks don't aware that venture capitalists don't want good, profitable enterprises. That's wonderful if you're developing a solid small business to consult, open shops, or make a specialty product. However, you must pay for it or borrow money. Venture capitalists want moon rockets. Silicon Valley is big or bust. Almost 90% will explode and crash. The few successes are remarkable enough to make up for the failures.
Silicon Valley's high-risk, high-reward attitude contrasts with Japan's incrementalism. Japan makes the best automobiles and cleanrooms, but it fails to produce new items that grow the economy.
Changeable? Absolutely. But, what makes huge manufacturing enterprises successful and what makes Japan a safe and comfortable place to live are inextricably connected with the lack of startups.
Barriers to Startup Development in Japan
These are the 7 biggest obstacles to Japanese startup success.
Unresponsive Employment Market
While the lifelong employment system in Japan is evolving, the average employee stays at their firm for 12 years (15 years for men at large organizations) compared to 4.3 years in the US. Seniority, not experience or aptitude, determines career routes, making it tough to quit a job to join a startup and then return to corporate work if it fails.
Conservative Buyers
Even if your product is buggy and undocumented, US customers will migrate to a cheaper, superior one. Japanese corporations demand perfection from their trusted suppliers and keep with them forever. Startups need income fast, yet product evaluation takes forever.
Failure intolerance
Japanese business failures harm lives. Failed forever. It hinders risk-taking. Silicon Valley embraces failure. Build another startup if your first fails. Build a third if that fails. Every setback is viewed as a learning opportunity for success.
4. No Corporate Purchases
Silicon Valley industrial giants will buy fast-growing startups for a lot of money. Many huge firms have stopped developing new goods and instead buy startups after the product is validated.
Japanese companies prefer in-house product development over startup acquisitions. No acquisitions mean no startup investment and no investor reward.
Startup investments can also be monetized through stock market listings. Public stock listings in Japan are risky because the Nikkei was stagnant for 35 years while the S&P rose 14x.
5. Social Unity Above Wealth
In Silicon Valley, everyone wants to be rich. That creates a competitive environment where everyone wants to succeed, but it also promotes fraud and societal problems.
Japan values communal harmony above individual success. Wealthy folks and overachievers are avoided. In Japan, renegades are nearly impossible.
6. Rote Learning Education System
Japanese high school graduates outperform most Americans. Nonetheless, Japanese education is known for its rote memorization. The American system, which fails too many kids, emphasizes creativity to create new products.
Immigration.
Immigrants start 55% of successful Silicon Valley firms. Some come for university, some to escape poverty and war, and some are recruited by Silicon Valley startups and stay to start their own.
Japan is difficult for immigrants to start a business due to language barriers, visa restrictions, and social isolation.
How Japan Can Promote Innovation
Patchwork solutions to deep-rooted cultural issues will not work. If customers don't buy things, immigration visas won't aid startups. Startups must have a chance of being acquired for a huge sum to attract investors. If risky startups fail, employees won't join.
Will Japan never have a startup culture?
Once a consensus is reached, Japan changes rapidly. A dwindling population and standard of living may lead to such consensus.
Toyota and Sony were firms with renowned founders who used technology to transform the world. Repeatable.
Silicon Valley is flawed too. Many people struggle due to wealth disparities, job churn and layoffs, and the tremendous ups and downs of the economy caused by stock market fluctuations.
The founders of the 10% successful startups are heroes. The 90% that fail and return to good-paying jobs with benefits are never mentioned.
Silicon Valley startup culture and Japanese corporate culture are opposites. Each have pros and cons. Big Japanese corporations make the most reliable, dependable, high-quality products yet move too slowly. That's good for creating cars, not social networking apps.
Can innovation and success be encouraged without eroding social cohesion? That can motivate software firms to move fast and break things while recognizing the beauty and precision of expert craftsmen? A hybrid culture where Japan can make the world's best and most original items. Hopefully.

Sammy Abdullah
3 years ago
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
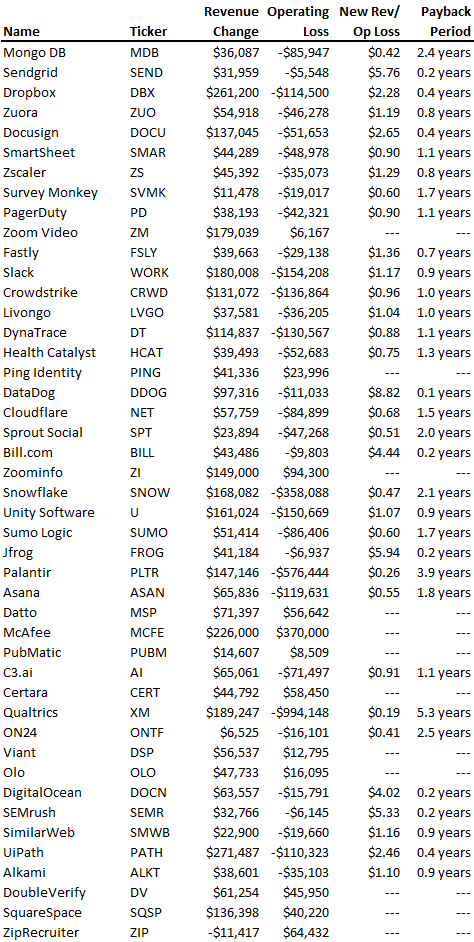
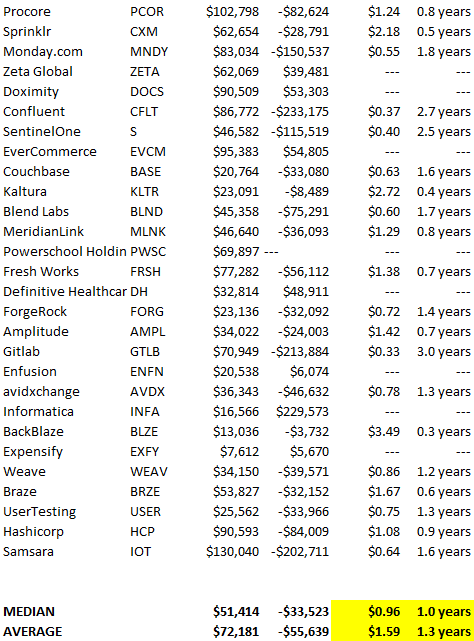
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.

Vitalik
4 years ago
An approximate introduction to how zk-SNARKs are possible (part 2)
If tasked with the problem of coming up with a zk-SNARK protocol, many people would make their way to this point and then get stuck and give up. How can a verifier possibly check every single piece of the computation, without looking at each piece of the computation individually? But it turns out that there is a clever solution.
Polynomials
Polynomials are a special class of algebraic expressions of the form:
- x+5
- x^4
- x^3+3x^2+3x+1
- 628x^{271}+318x^{270}+530x^{269}+…+69x+381
i.e. they are a sum of any (finite!) number of terms of the form cx^k
There are many things that are fascinating about polynomials. But here we are going to zoom in on a particular one: polynomials are a single mathematical object that can contain an unbounded amount of information (think of them as a list of integers and this is obvious). The fourth example above contained 816 digits of tau, and one can easily imagine a polynomial that contains far more.
Furthermore, a single equation between polynomials can represent an unbounded number of equations between numbers. For example, consider the equation A(x)+ B(x) = C(x). If this equation is true, then it's also true that:
- A(0)+B(0)=C(0)
- A(1)+B(1)=C(1)
- A(2)+B(2)=C(2)
- A(3)+B(3)=C(3)
And so on for every possible coordinate. You can even construct polynomials to deliberately represent sets of numbers so you can check many equations all at once. For example, suppose that you wanted to check:
- 12+1=13
- 10+8=18
- 15+8=23
- 15+13=28
You can use a procedure called Lagrange interpolation to construct polynomials A(x) that give (12,10,15,15) as outputs at some specific set of coordinates (eg. (0,1,2,3)), B(x) the outputs (1,8,8,13) on thos same coordinates, and so forth. In fact, here are the polynomials:
- A(x)=-2x^3+\frac{19}{2}x^2-\frac{19}{2}x+12
- B(x)=2x^3-\frac{19}{2}x^2+\frac{29}{2}x+1
- C(x)=5x+13
Checking the equation A(x)+B(x)=C(x) with these polynomials checks all four above equations at the same time.
Comparing a polynomial to itself
You can even check relationships between a large number of adjacent evaluations of the same polynomial using a simple polynomial equation. This is slightly more advanced. Suppose that you want to check that, for a given polynomial F, F(x+2)=F(x)+F(x+1) with the integer range {0,1…89} (so if you also check F(0)=F(1)=1, then F(100) would be the 100th Fibonacci number)
As polynomials, F(x+2)-F(x+1)-F(x) would not be exactly zero, as it could give arbitrary answers outside the range x={0,1…98}. But we can do something clever. In general, there is a rule that if a polynomial P is zero across some set S=\{x_1,x_2…x_n\} then it can be expressed as P(x)=Z(x)*H(x), where Z(x)=(x-x_1)*(x-x_2)*…*(x-x_n) and H(x) is also a polynomial. In other words, any polynomial that equals zero across some set is a (polynomial) multiple of the simplest (lowest-degree) polynomial that equals zero across that same set.
Why is this the case? It is a nice corollary of polynomial long division: the factor theorem. We know that, when dividing P(x) by Z(x), we will get a quotient Q(x) and a remainder R(x) is strictly less than that of Z(x). Since we know that P is zero on all of S, it means that R has to be zero on all of S as well. So we can simply compute R(x) via polynomial interpolation, since it's a polynomial of degree at most n-1 and we know n values (the zeros at S). Interpolating a polynomial with all zeroes gives the zero polynomial, thus R(x)=0 and H(x)=Q(x).
Going back to our example, if we have a polynomial F that encodes Fibonacci numbers (so F(x+2)=F(x)+F(x+1) across x=\{0,1…98\}), then I can convince you that F actually satisfies this condition by proving that the polynomial P(x)=F(x+2)-F(x+1)-F(x) is zero over that range, by giving you the quotient:
H(x)=\frac{F(x+2)-F(x+1)-F(x)}{Z(x)}
Where Z(x) = (x-0)*(x-1)*…*(x-98).
You can calculate Z(x) yourself (ideally you would have it precomputed), check the equation, and if the check passes then F(x) satisfies the condition!
Now, step back and notice what we did here. We converted a 100-step-long computation into a single equation with polynomials. Of course, proving the N'th Fibonacci number is not an especially useful task, especially since Fibonacci numbers have a closed form. But you can use exactly the same basic technique, just with some extra polynomials and some more complicated equations, to encode arbitrary computations with an arbitrarily large number of steps.
see part 3