



More on Productivity

Pen Magnet
3 years ago
Why Google Staff Doesn't Work

Sundar Pichai unveiled Simplicity Sprint at Google's latest all-hands conference.
To boost employee efficiency.
Not surprising. Few envisioned Google declaring a productivity drive.
Sunder Pichai's speech:
“There are real concerns that our productivity as a whole is not where it needs to be for the head count we have. Help me create a culture that is more mission-focused, more focused on our products, more customer focused. We should think about how we can minimize distractions and really raise the bar on both product excellence and productivity.”
The primary driver driving Google's efficiency push is:
Google's efficiency push follows 13% quarterly revenue increase. Last year in the same quarter, it was 62%.
Market newcomers may argue that the previous year's figure was fuelled by post-Covid reopening and growing consumer spending. Investors aren't convinced. A promising company like Google can't afford to drop so quickly.
Google’s quarterly revenue growth stood at 13%, against 62% in last year same quarter.
Google isn't alone. In my recent essay regarding 2025 programmers, I warned about the economic downturn's effects on FAAMG's workforce. Facebook had suspended hiring, and Microsoft had promised hefty bonuses for loyal staff.
In the same article, I predicted Google's troubles. Online advertising, especially the way Google and Facebook sell it using user data, is over.
FAAMG and 2nd rung IT companies could be the first to fall without Post-COVID revival and uncertain global geopolitics.
Google has hardly ever discussed effectiveness:
Apparently openly.
Amazon treats its employees like robots, even in software positions. It has significant turnover and a terrible reputation as a result. Because of this, it rarely loses money due to staff productivity.
Amazon trumps Google. In reality, it treats its employees poorly.
Google was the founding father of the modern-day open culture.
Larry and Sergey Google founded the IT industry's Open Culture. Silicon Valley called Google's internal democracy and transparency near anarchy. Management rarely slammed decisions on employees. Surveys and internal polls ensured everyone knew the company's direction and had a vote.
20% project allotment (weekly free time to build own project) was Google's open-secret innovation component.
After Larry and Sergey's exit in 2019, this is Google's first profitability hurdle. Only Google insiders can answer these questions.
Would Google's investors compel the company's management to adopt an Amazon-style culture where the developers are treated like circus performers?
If so, would Google follow suit?
If so, how does Google go about doing it?
Before discussing Google's likely plan, let's examine programming productivity.
What determines a programmer's productivity is simple:
How would we answer Google's questions?
As a programmer, I'm more concerned about Simplicity Sprint's aftermath than its economic catalysts.
Large organizations don't care much about quarterly and annual productivity metrics. They have 10-year product-launch plans. If something seems horrible today, it's likely due to someone's lousy judgment 5 years ago who is no longer in the blame game.
Deconstruct our main question.
How exactly do you change the culture of the firm so that productivity increases?
How can you accomplish that without affecting your capacity to profit? There are countless ways to increase output without decreasing profit.
How can you accomplish this with little to no effect on employee motivation? (While not all employers care about it, in this case we are discussing the father of the open company culture.)
How do you do it for a 10-developer IT firm that is losing money versus a 1,70,000-developer organization with a trillion-dollar valuation?
When implementing a large-scale organizational change, success must be carefully measured.
The fastest way to do something is to do it right, no matter how long it takes.
You require clearly-defined group/team/role segregation and solid pass/fail matrices to:
You can give performers rewards.
Ones that are average can be inspired to improve
Underachievers may receive assistance or, in the worst-case scenario, rehabilitation
As a 20-year programmer, I associate productivity with greatness.
Doing something well, no matter how long it takes, is the fastest way to do it.
Let's discuss a programmer's productivity.
Why productivity is a strange term in programming:
Productivity is work per unit of time.
Money=time This is an economic proverb. More hours worked, more pay. Longer projects cost more.
As a buyer, you desire a quick supply. As a business owner, you want employees who perform at full capacity, creating more products to transport and boosting your profits.
All economic matrices encourage production because of our obsession with it. Productivity is the only organic way a nation may increase its GDP.
Time is money — is not just a proverb, but an economical fact.
Applying the same productivity theory to programming gets problematic. An automating computer. Its capacity depends on the software its master writes.
Today, a sophisticated program can process a billion records in a few hours. Creating one takes a competent coder and the necessary infrastructure. Learning, designing, coding, testing, and iterations take time.
Programming productivity isn't linear, unlike manufacturing and maintenance.
Average programmers produce code every day yet miss deadlines. Expert programmers go days without coding. End of sprint, they often surprise themselves by delivering fully working solutions.
Reversing the programming duties has no effect. Experts aren't needed for productivity.
These patterns remind me of an XKCD comic.
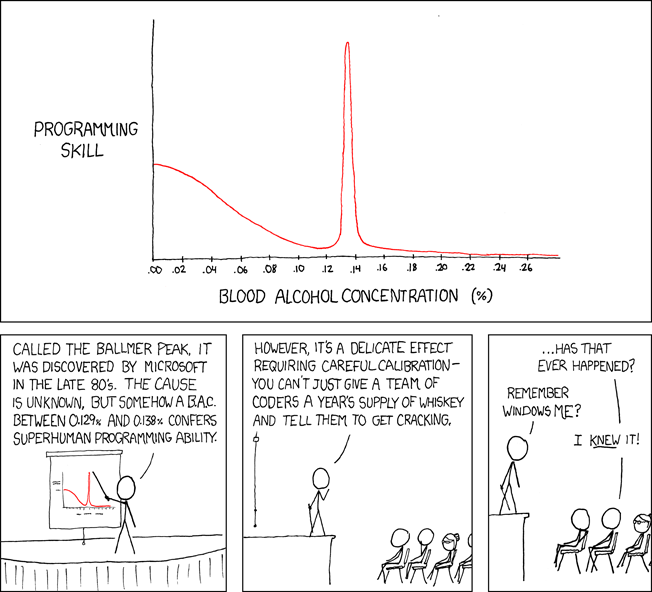
Programming productivity depends on two factors:
The capacity of the programmer and his or her command of the principles of computer science
His or her productive bursts, how often they occur, and how long they last as they engineer the answer
At some point, productivity measurement becomes Schrödinger’s cat.
Product companies measure productivity using use cases, classes, functions, or LOCs (lines of code). In days of data-rich source control systems, programmers' merge requests and/or commits are the most preferred yardstick. Companies assess productivity by tickets closed.
Every organization eventually has trouble measuring productivity. Finer measurements create more chaos. Every measure compares apples to oranges (or worse, apples with aircraft.) On top of the measuring overhead, the endeavor causes tremendous and unnecessary stress on teams, lowering their productivity and defeating its purpose.
Macro productivity measurements make sense. Amazon's factory-era management has done it, but at great cost.
Google can pull it off if it wants to.
What Google meant in reality when it said that employee productivity has decreased:
When Google considers its employees unproductive, it doesn't mean they don't complete enough work in the allotted period.
They can't multiply their work's influence over time.
Programmers who produce excellent modules or products are unsure on how to use them.
The best data scientists are unable to add the proper parameters in their models.
Despite having a great product backlog, managers struggle to recruit resources with the necessary skills.
Product designers who frequently develop and A/B test newer designs are unaware of why measures are inaccurate or whether they have already reached the saturation point.
Most ignorant: All of the aforementioned positions are aware of what to do with their deliverables, but neither their supervisors nor Google itself have given them sufficient authority.
So, Google employees aren't productive.
How to fix it?
Business analysis: White suits introducing novel items can interact with customers from all regions. Track analytics events proactively, especially the infrequent ones.
SOLID, DRY, TEST, and AUTOMATION: Do less + reuse. Use boilerplate code creation. If something already exists, don't implement it yourself.
Build features-building capabilities: N features are created by average programmers in N hours. An endless number of features can be built by average programmers thanks to the fact that expert programmers can produce 1 capability in N hours.
Work on projects that will have a positive impact: Use the same algorithm to search for images on YouTube rather than the Mars surface.
Avoid tasks that can only be measured in terms of time linearity at all costs (if a task can be completed in N minutes, then M copies of the same task would cost M*N minutes).
In conclusion:
Software development isn't linear. Why should the makers be measured?
Notation for The Big O
I'm discussing a new way to quantify programmer productivity. (It applies to other professions, but that's another subject)
The Big O notation expresses the paradigm (the algorithmic performance concept programmers rot to ace their Google interview)
Google (or any large corporation) can do this.
Sort organizational roles into categories and specify their impact vs. time objectives. A CXO role's time vs. effect function, for instance, has a complexity of O(log N), meaning that if a CEO raises his or her work time by 8x, the result only increases by 3x.
Plot the influence of each employee over time using the X and Y axes, respectively.
Add a multiplier for Y-axis values to the productivity equation to make business objectives matter. (Example values: Support = 5, Utility = 7, and Innovation = 10).
Compare employee scores in comparable categories (developers vs. devs, CXOs vs. CXOs, etc.) and reward or help employees based on whether they are ahead of or behind the pack.
After measuring every employee's inventiveness, it's straightforward to help underachievers and praise achievers.
Example of a Big(O) Category:
If I ran Google (God forbid, its worst days are far off), here's how I'd classify it. You can categorize Google employees whichever you choose.
The Google interview truth:
O(1) < O(log n) < O(n) < O(n log n) < O(n^x) where all logarithmic bases are < n.
O(1): Customer service workers' hours have no impact on firm profitability or customer pleasure.
CXOs Most of their time is spent on travel, strategic meetings, parties, and/or meetings with minimal floor-level influence. They're good at launching new products but bad at pivoting without disaster. Their directions are being followed.
Devops, UX designers, testers Agile projects revolve around deployment. DevOps controls the levers. Their automation secures results in subsequent cycles.
UX/UI Designers must still prototype UI elements despite improved design tools.
All test cases are proportional to use cases/functional units, hence testers' work is O(N).
Architects Their effort improves code quality. Their right/wrong interference affects product quality and rollout decisions even after the design is set.
Core Developers Only core developers can write code and own requirements. When people understand and own their labor, the output improves dramatically. A single character error can spread undetected throughout the SDLC and cost millions.
Core devs introduce/eliminate 1000x bugs, refactoring attempts, and regression. Following our earlier hypothesis.
The fastest way to do something is to do it right, no matter how long it takes.
Conclusion:
Google is at the liberal extreme of the employee-handling spectrum
Microsoft faced an existential crisis after 2000. It didn't choose Amazon's data-driven people management to revitalize itself.
Instead, it entrusted developers. It welcomed emerging technologies and opened up to open source, something it previously opposed.
Google is too lax in its employee-handling practices. With that foundation, it can only follow Amazon, no matter how carefully.
Any attempt to redefine people's measurements will affect the organization emotionally.
The more Google compares apples to apples, the higher its chances for future rebirth.

The woman
3 years ago
I received a $2k bribe to replace another developer in an interview
I can't believe they’d even think it works!

Developers are usually interviewed before being hired, right? Every organization wants candidates who meet their needs. But they also want to avoid fraud.
There are cheaters in every field. Only two come to mind for the hiring process:
Lying on a resume.
Cheating on an online test.
Recently, I observed another one. One of my coworkers invited me to replace another developer during an online interview! I was astonished, but it’s not new.
The specifics
My ex-colleague recently texted me. No one from your former office will ever approach you after a year unless they need something.
Which was the case. My coworker said his wife needed help as a programmer. I was glad someone asked for my help, but I'm still a junior programmer.
Then he informed me his wife was selected for a fantastic job interview. He said he could help her with the online test, but he needed someone to help with the online interview.
Okay, I guess. Preparing for an online interview is beneficial. But then he said she didn't need to be ready. She needed someone to take her place.
I told him it wouldn't work. Every remote online interview I've ever seen required an open camera.
What followed surprised me. She'd ask to turn off the camera, he said.
I asked why.
He told me if an applicant is unwell, the interviewer may consider an off-camera interview. His wife will say she's sick and prefers no camera.
The plan left me speechless. I declined politely. He insisted and promised $2k if she got the job.
I felt insulted and told him if he persisted, I'd inform his office. I was furious. Later, I apologized and told him to stop.
I'm not sure what they did after that
I'm not sure if they found someone or listened to me. They probably didn't. How would she do the job if she even got it?
It's an internship, he said. With great pay, though. What should an intern do?
I suggested she do the interview alone. Even if she failed, she'd gain confidence and valuable experience.
Conclusion
Many interviewees cheat. My profession is vital to me, thus I'd rather improve my abilities and apply honestly. It's part of my identity.
Am I truthful? Most professionals are not. They fabricate their CVs. Often.
When you support interview cheating, you encourage more cheating! When someone cheats, another qualified candidate may not obtain the job.
One day, that could be you or me.

Recep İnanç
3 years ago
Effective Technical Book Reading Techniques

Technical books aren't like novels. We need a new approach to technical texts. I've spent years looking for a decent reading method. I tried numerous ways before finding one that worked. This post explains how I read technical books efficiently.
What Do I Mean When I Say Effective?
Effectiveness depends on the book. Effective implies I know where to find answers after reading a reference book. Effective implies I learned the book's knowledge after reading it.
I use reference books as tools in my toolkit. I won't carry all my tools; I'll merely need them. Non-reference books teach me techniques. I never have to make an effort to use them since I always have them.
Reference books I like:
Design Patterns: Elements of Reusable Object-Oriented Software
Refactoring: Improving the Design of Existing Code
You can also check My Top Takeaways from Refactoring here.
Non-reference books I like:
The Approach
Technical books might be overwhelming to read in one sitting. Especially when you have no idea what is coming next as you read. When you don't know how deep the rabbit hole goes, you feel lost as you read. This is my years-long method for overcoming this difficulty.
Whether you follow the step-by-step guide or not, remember these:
Understand the terminology. Make sure you get the meaning of any terms you come across more than once. The likelihood that a term will be significant increases as you encounter it more frequently.
Know when to stop. I've always believed that in order to truly comprehend something, I must delve as deeply as possible into it. That, however, is not usually very effective. There are moments when you have to draw the line and start putting theory into practice (if applicable).
Look over your notes. When reading technical books or documents, taking notes is a crucial habit to develop. Additionally, you must regularly examine your notes if you want to get the most out of them. This will assist you in internalizing the lessons you acquired from the book. And you'll see that the urge to review reduces with time.
Let's talk about how I read a technical book step by step.
0. Read the Foreword/Preface
These sections are crucial in technical books. They answer Who should read it, What each chapter discusses, and sometimes How to Read? This is helpful before reading the book. Who could know the ideal way to read the book better than the author, right?
1. Scanning
I scan the chapter. Fast scanning is needed.
I review the headings.
I scan the pictures quickly.
I assess the chapter's length to determine whether I might divide it into more manageable sections.
2. Skimming
Skimming is faster than reading but slower than scanning.
I focus more on the captions and subtitles for the photographs.
I read each paragraph's opening and closing sentences.
I examined the code samples.
I attempt to grasp each section's basic points without getting bogged down in the specifics.
Throughout the entire reading period, I make an effort to make mental notes of what may require additional attention and what may not. Because I don't want to spend time taking physical notes, kindly notice that I am using the term "mental" here. It is much simpler to recall. You may think that this is more significant than typing or writing “Pay attention to X.”
I move on quickly. This is something I considered crucial because, when trying to skim, it is simple to start reading the entire thing.
3. Complete reading
Previous steps pay off.
I finished reading the chapter.
I concentrate on the passages that I mentally underlined when skimming.
I put the book away and make my own notes. It is typically more difficult than it seems for me. But it's important to speak in your own words. You must choose the right words to adequately summarize what you have read. How do those words make you feel? Additionally, you must be able to summarize your notes while you are taking them. Sometimes as I'm writing my notes, I realize I have no words to convey what I'm thinking or, even worse, I start to doubt what I'm writing down. This is a good indication that I haven't internalized that idea thoroughly enough.
I jot my inquiries down. Normally, I read on while compiling my questions in the hopes that I will learn the answers as I read. I'll explore those issues more if I wasn't able to find the answers to my inquiries while reading the book.
Bonus!
Best part: If you take lovely notes like I do, you can publish them as a blog post with a few tweaks.
Conclusion
This is my learning journey. I wanted to show you. This post may help someone with a similar learning style. You can alter the principles above for any technical material.
You might also like

Rita McGrath
3 years ago
Flywheels and Funnels
Traditional sales organizations used the concept of a sales “funnel” to describe the process through which potential customers move, ending up with sales at the end. Winners today have abandoned that way of thinking in favor of building flywheels — business models in which every element reinforces every other.
Ah, the marketing funnel…
Prospective clients go through a predictable set of experiences, students learn in business school marketing classes. It looks like this:

Understanding the funnel helps evaluate sales success indicators. Gail Goodwin, former CEO of small business direct mail provider Constant Contact, said managing the pipeline was key to escaping the sluggish SaaS ramp of death.
Like the funnel concept. To predict how well your business will do, measure how many potential clients are aware of it (awareness) and how many take the next step. If 1,000 people heard about your offering and 10% showed interest, you'd have 100 at that point. If 50% of these people made buyer-like noises, you'd know how many were, etc. It helped model buying trends.
TV, magazine, and radio advertising are pricey for B2C enterprises. Traditional B2B marketing involved armies of sales reps, which was expensive and a barrier to entry.
Cracks in the funnel model
Digital has exposed the funnel's limitations. Hubspot was born at a time when buyers and sellers had huge knowledge asymmetries, according to co-founder Brian Halligan. Those selling a product could use the buyer's lack of information to become a trusted partner.
As the world went digital, getting information and comparing offerings became faster, easier, and cheaper. Buyers didn't need a seller to move through a funnel. Interactions replaced transactions, and the relationship didn't end with a sale.
Instead, buyers and sellers interacted in a constant flow. In many modern models, the sale is midway through the process (particularly true with subscription and software-as-a-service models). Example:
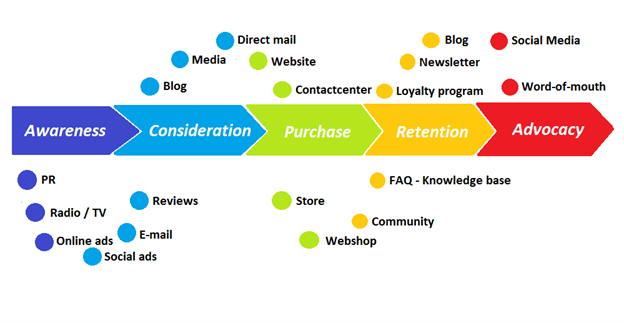
You're creating a winding journey with many touch points, not a funnel (and lots of opportunities for customers to get lost).
From winding journey to flywheel
Beyond this revised view of an interactive customer journey, a company can create what Jim Collins famously called a flywheel. Imagine rolling a heavy disc on its axis. The first few times you roll it, you put in a lot of effort for a small response. The same effort yields faster turns as it gains speed. Over time, the flywheel gains momentum and turns without your help.
Modern digital organizations have created flywheel business models, in which any additional force multiplies throughout the business. The flywheel becomes a force multiplier, according to Collins.
Amazon is a famous flywheel example. Collins explained the concept to Amazon CEO Jeff Bezos at a corporate retreat in 2001. In The Everything Store, Brad Stone describes in his book The Everything Store how he immediately understood Amazon's levers.
The result (drawn on a napkin):
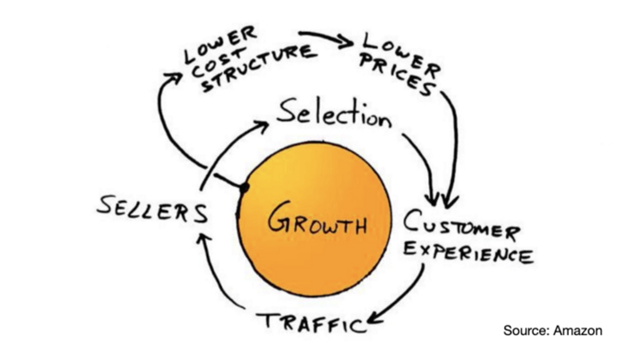
Low prices and a large selection of products attracted customers, while a focus on customer service kept them coming back, increasing traffic. Third-party sellers then increased selection. Low-cost structure supports low-price commitment. It's brilliant! Every wheel turn creates acceleration.
Where from here?
Flywheel over sales funnel! Consider these business terms.

Thomas Huault
3 years ago
A Mean Reversion Trading Indicator Inspired by Classical Mechanics Is The Kinetic Detrender
DATA MINING WITH SUPERALGORES
Old pots produce the best soup.

Science has always inspired indicator design. From physics to signal processing, many indicators use concepts from mechanical engineering, electronics, and probability. In Superalgos' Data Mining section, we've explored using thermodynamics and information theory to construct indicators and using statistical and probabilistic techniques like reduced normal law to take advantage of low probability events.
An asset's price is like a mechanical object revolving around its moving average. Using this approach, we could design an indicator using the oscillator's Total Energy. An oscillator's energy is finite and constant. Since we don't expect the price to follow the harmonic oscillator, this energy should deviate from the perfect situation, and the maximum of divergence may provide us valuable information on the price's moving average.
Definition of the Harmonic Oscillator in Few Words
Sinusoidal function describes a harmonic oscillator. The time-constant energy equation for a harmonic oscillator is:
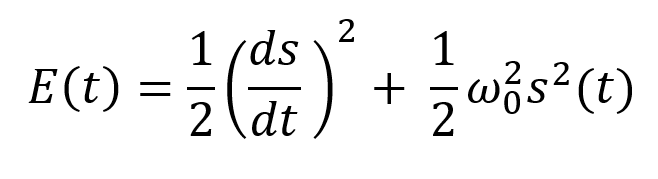
With
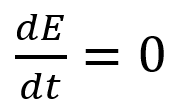
Time saves energy.
In a mechanical harmonic oscillator, total energy equals kinetic energy plus potential energy. The formula for energy is the same for every kind of harmonic oscillator; only the terms of total energy must be adapted to fit the relevant units. Each oscillator has a velocity component (kinetic energy) and a position to equilibrium component (potential energy).
The Price Oscillator and the Energy Formula
Considering the harmonic oscillator definition, we must specify kinetic and potential components for our price oscillator. We define oscillator velocity as the rate of change and equilibrium position as the price's distance from its moving average.
Price kinetic energy:
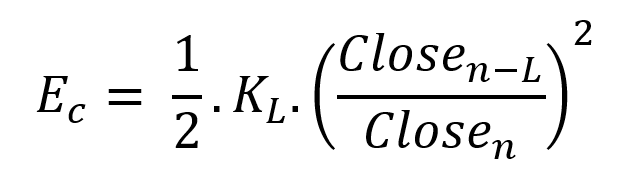
It's like:
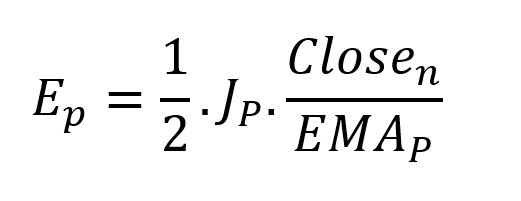
With
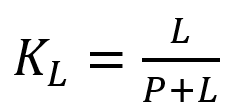
and
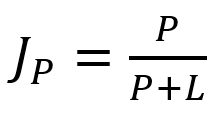
L is the number of periods for the rate of change calculation and P for the close price EMA calculation.
Total price oscillator energy =
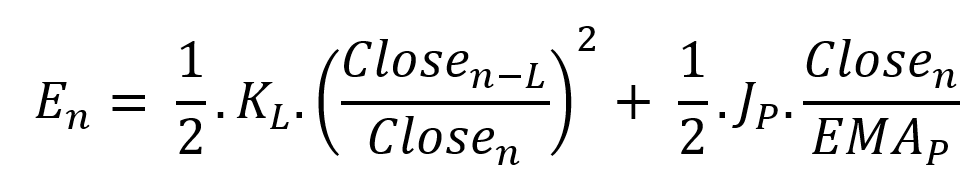
Given that an asset's price can theoretically vary at a limitless speed and be endlessly far from its moving average, we don't expect this formula's outcome to be constrained. We'll normalize it using Z-Score for convenience of usage and readability, which also allows probabilistic interpretation.
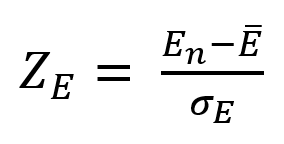
Over 20 periods, we'll calculate E's moving average and standard deviation.
We calculated Z on BTC/USDT with L = 10 and P = 21 using Knime Analytics.
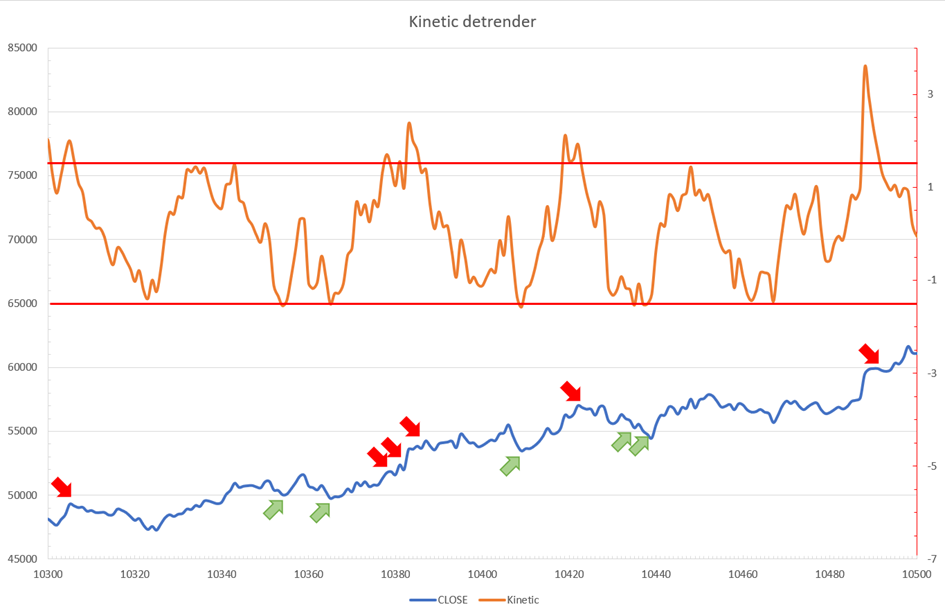
The graph is detrended. We added two horizontal lines at +/- 1.6 to construct a 94.5% probability zone based on reduced normal law tables. Price cycles to its moving average oscillate clearly. Red and green arrows illustrate where the oscillator crosses the top and lower limits, corresponding to the maximum/minimum price oscillation. Since the results seem noisy, we may apply a non-lagging low-pass or multipole filter like Butterworth or Laguerre filters and employ dynamic bands at a multiple of Z's standard deviation instead of fixed levels.
Kinetic Detrender Implementation in Superalgos
The Superalgos Kinetic detrender features fixed upper and lower levels and dynamic volatility bands.
The code is pretty basic and does not require a huge amount of code lines.
It starts with the standard definitions of the candle pointer and the constant declaration :
let candle = record.current
let len = 10
let P = 21
let T = 20
let up = 1.6
let low = 1.6Upper and lower dynamic volatility band constants are up and low.
We proceed to the initialization of the previous value for EMA :
if (variable.prevEMA === undefined) {
variable.prevEMA = candle.close
}And the calculation of EMA with a function (it is worth noticing the function is declared at the end of the code snippet in Superalgos) :
variable.ema = calculateEMA(P, candle.close, variable.prevEMA)
//EMA calculation
function calculateEMA(periods, price, previousEMA) {
let k = 2 / (periods + 1)
return price * k + previousEMA * (1 - k)
}The rate of change is calculated by first storing the right amount of close price values and proceeding to the calculation by dividing the current close price by the first member of the close price array:
variable.allClose.push(candle.close)
if (variable.allClose.length > len) {
variable.allClose.splice(0, 1)
}
if (variable.allClose.length === len) {
variable.roc = candle.close / variable.allClose[0]
} else {
variable.roc = 1
}Finally, we get energy with a single line:
variable.E = 1 / 2 * len * variable.roc + 1 / 2 * P * candle.close / variable.emaThe Z calculation reuses code from Z-Normalization-based indicators:
variable.allE.push(variable.E)
if (variable.allE.length > T) {
variable.allE.splice(0, 1)
}
variable.sum = 0
variable.SQ = 0
if (variable.allE.length === T) {
for (var i = 0; i < T; i++) {
variable.sum += variable.allE[i]
}
variable.MA = variable.sum / T
for (var i = 0; i < T; i++) {
variable.SQ += Math.pow(variable.allE[i] - variable.MA, 2)
}
variable.sigma = Math.sqrt(variable.SQ / T)
variable.Z = (variable.E - variable.MA) / variable.sigma
} else {
variable.Z = 0
}
variable.allZ.push(variable.Z)
if (variable.allZ.length > T) {
variable.allZ.splice(0, 1)
}
variable.sum = 0
variable.SQ = 0
if (variable.allZ.length === T) {
for (var i = 0; i < T; i++) {
variable.sum += variable.allZ[i]
}
variable.MAZ = variable.sum / T
for (var i = 0; i < T; i++) {
variable.SQ += Math.pow(variable.allZ[i] - variable.MAZ, 2)
}
variable.sigZ = Math.sqrt(variable.SQ / T)
} else {
variable.MAZ = variable.Z
variable.sigZ = variable.MAZ * 0.02
}
variable.upper = variable.MAZ + up * variable.sigZ
variable.lower = variable.MAZ - low * variable.sigZWe also update the EMA value.
variable.prevEMA = variable.EMA
Conclusion
We showed how to build a detrended oscillator using simple harmonic oscillator theory. Kinetic detrender's main line oscillates between 2 fixed levels framing 95% of the values and 2 dynamic levels, leading to auto-adaptive mean reversion zones.
Superalgos' Normalized Momentum data mine has the Kinetic detrender indication.
All the material here can be reused and integrated freely by linking to this article and Superalgos.
This post is informative and not financial advice. Seek expert counsel before trading. Risk using this material.

Theresa W. Carey
4 years ago
How Payment for Order Flow (PFOF) Works
What is PFOF?
PFOF is a brokerage firm's compensation for directing orders to different parties for trade execution. The brokerage firm receives fractions of a penny per share for directing the order to a market maker.
Each optionable stock could have thousands of contracts, so market makers dominate options trades. Order flow payments average less than $0.50 per option contract.
Order Flow Payments (PFOF) Explained
The proliferation of exchanges and electronic communication networks has complicated equity and options trading (ECNs) Ironically, Bernard Madoff, the Ponzi schemer, pioneered pay-for-order-flow.
In a December 2000 study on PFOF, the SEC said, "Payment for order flow is a method of transferring trading profits from market making to brokers who route customer orders to specialists for execution."
Given the complexity of trading thousands of stocks on multiple exchanges, market making has grown. Market makers are large firms that specialize in a set of stocks and options, maintaining an inventory of shares and contracts for buyers and sellers. Market makers are paid the bid-ask spread. Spreads have narrowed since 2001, when exchanges switched to decimals. A market maker's ability to play both sides of trades is key to profitability.
Benefits, requirements
A broker receives fees from a third party for order flow, sometimes without a client's knowledge. This invites conflicts of interest and criticism. Regulation NMS from 2005 requires brokers to disclose their policies and financial relationships with market makers.
Your broker must tell you if it's paid to send your orders to specific parties. This must be done at account opening and annually. The firm must disclose whether it participates in payment-for-order-flow and, upon request, every paid order. Brokerage clients can request payment data on specific transactions, but the response takes weeks.
Order flow payments save money. Smaller brokerage firms can benefit from routing orders through market makers and getting paid. This allows brokerage firms to send their orders to another firm to be executed with other orders, reducing costs. The market maker or exchange benefits from additional share volume, so it pays brokerage firms to direct traffic.
Retail investors, who lack bargaining power, may benefit from order-filling competition. Arrangements to steer the business in one direction invite wrongdoing, which can erode investor confidence in financial markets and their players.
Pay-for-order-flow criticism
It has always been controversial. Several firms offering zero-commission trades in the late 1990s routed orders to untrustworthy market makers. During the end of fractional pricing, the smallest stock spread was $0.125. Options spreads widened. Traders found that some of their "free" trades cost them a lot because they weren't getting the best price.
The SEC then studied the issue, focusing on options trades, and nearly decided to ban PFOF. The proliferation of options exchanges narrowed spreads because there was more competition for executing orders. Options market makers said their services provided liquidity. In its conclusion, the report said, "While increased multiple-listing produced immediate economic benefits to investors in the form of narrower quotes and effective spreads, these improvements have been muted with the spread of payment for order flow and internalization."
The SEC allowed payment for order flow to continue to prevent exchanges from gaining monopoly power. What would happen to trades if the practice was outlawed was also unclear. SEC requires brokers to disclose financial arrangements with market makers. Since then, the SEC has watched closely.
2020 Order Flow Payment
Rule 605 and Rule 606 show execution quality and order flow payment statistics on a broker's website. Despite being required by the SEC, these reports can be hard to find. The SEC mandated these reports in 2005, but the format and reporting requirements have changed over the years, most recently in 2018.
Brokers and market makers formed a working group with the Financial Information Forum (FIF) to standardize order execution quality reporting. Only one retail brokerage (Fidelity) and one market maker remain (Two Sigma Securities). FIF notes that the 605/606 reports "do not provide the level of information that allows a retail investor to gauge how well a broker-dealer fills a retail order compared to the NBBO (national best bid or offer’) at the time the order was received by the executing broker-dealer."
In the first quarter of 2020, Rule 606 reporting changed to require brokers to report net payments from market makers for S&P 500 and non-S&P 500 equity trades and options trades. Brokers must disclose payment rates per 100 shares by order type (market orders, marketable limit orders, non-marketable limit orders, and other orders).
Richard Repetto, Managing Director of New York-based Piper Sandler & Co., publishes a report on Rule 606 broker reports. Repetto focused on Charles Schwab, TD Ameritrade, E-TRADE, and Robinhood in Q2 2020. Repetto reported that payment for order flow was higher in the second quarter than the first due to increased trading activity, and that options paid more than equities.
Repetto says PFOF contributions rose overall. Schwab has the lowest options rates, while TD Ameritrade and Robinhood have the highest. Robinhood had the highest equity rating. Repetto assumes Robinhood's ability to charge higher PFOF reflects their order flow profitability and that they receive a fixed rate per spread (vs. a fixed rate per share by the other brokers).
Robinhood's PFOF in equities and options grew the most quarter-over-quarter of the four brokers Piper Sandler analyzed, as did their implied volumes. All four brokers saw higher PFOF rates.
TD Ameritrade took the biggest income hit when cutting trading commissions in fall 2019, and this report shows they're trying to make up the shortfall by routing orders for additional PFOF. Robinhood refuses to disclose trading statistics using the same metrics as the rest of the industry, offering only a vague explanation on their website.
Summary
Payment for order flow has become a major source of revenue as brokers offer no-commission equity (stock and ETF) orders. For retail investors, payment for order flow poses a problem because the brokerage may route orders to a market maker for its own benefit, not the investor's.
Infrequent or small-volume traders may not notice their broker's PFOF practices. Frequent traders and those who trade larger quantities should learn about their broker's order routing system to ensure they're not losing out on price improvement due to a broker prioritizing payment for order flow.
This post is a summary. Read full article here