



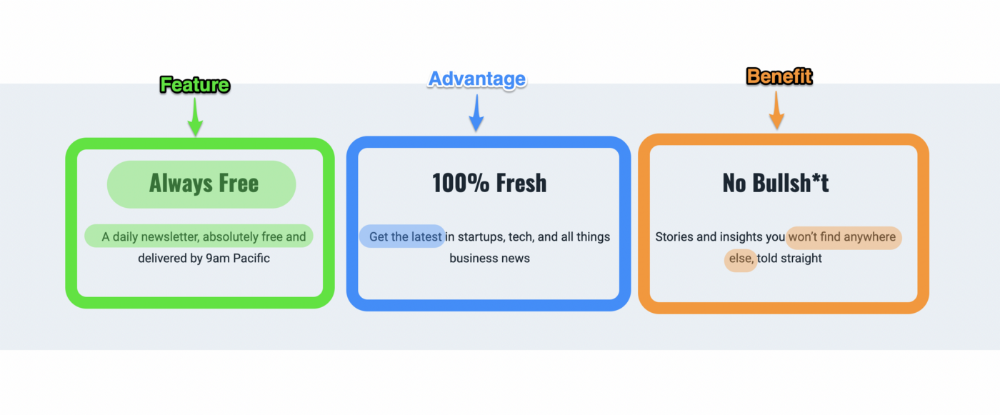


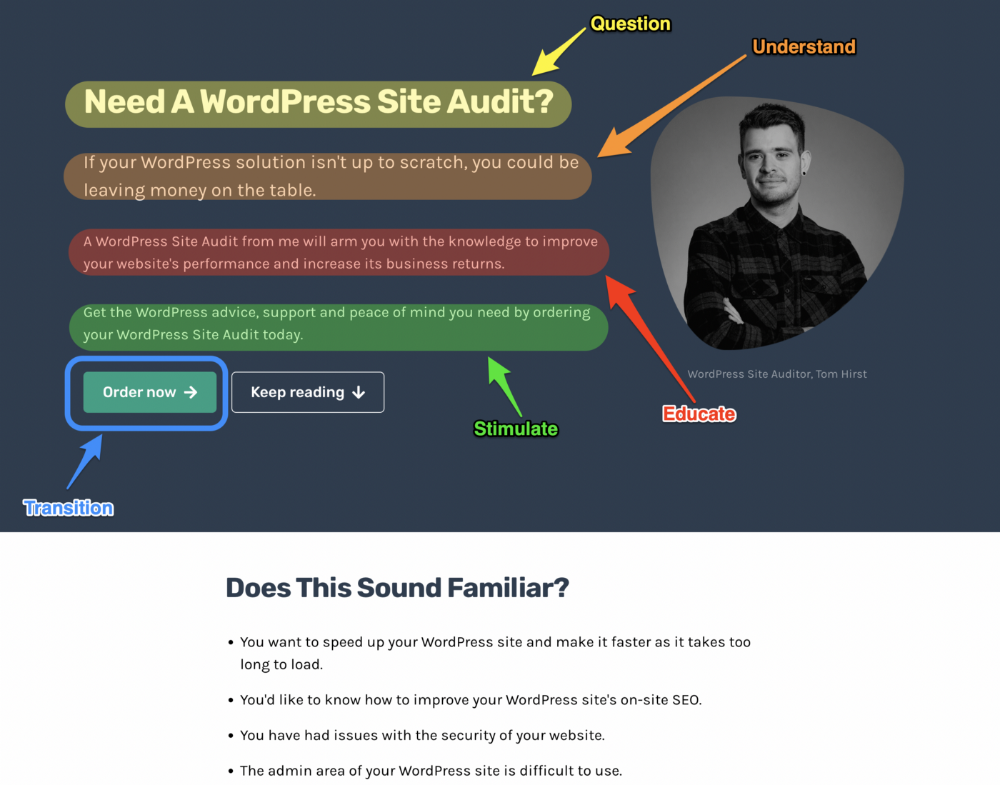

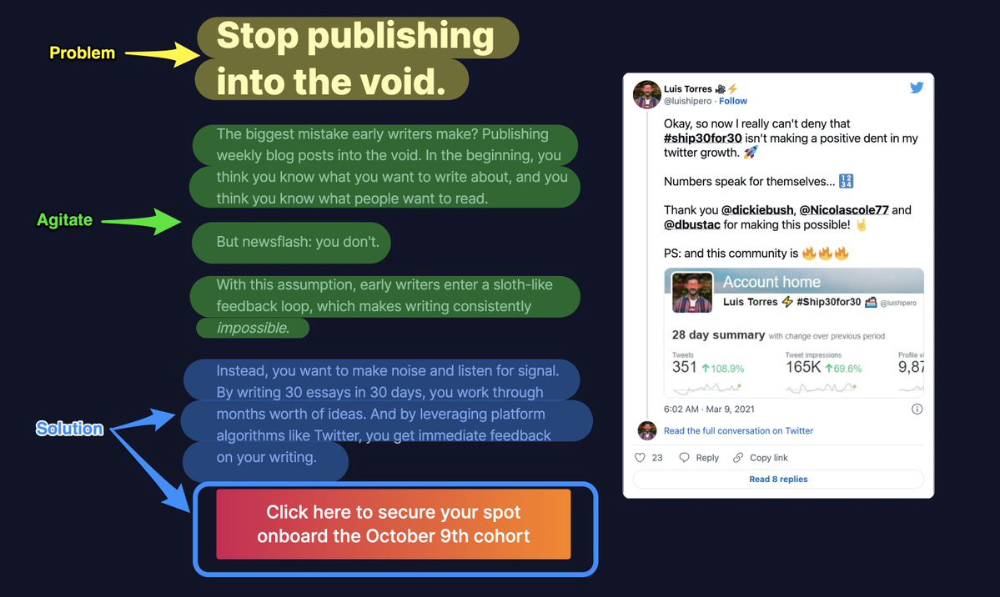
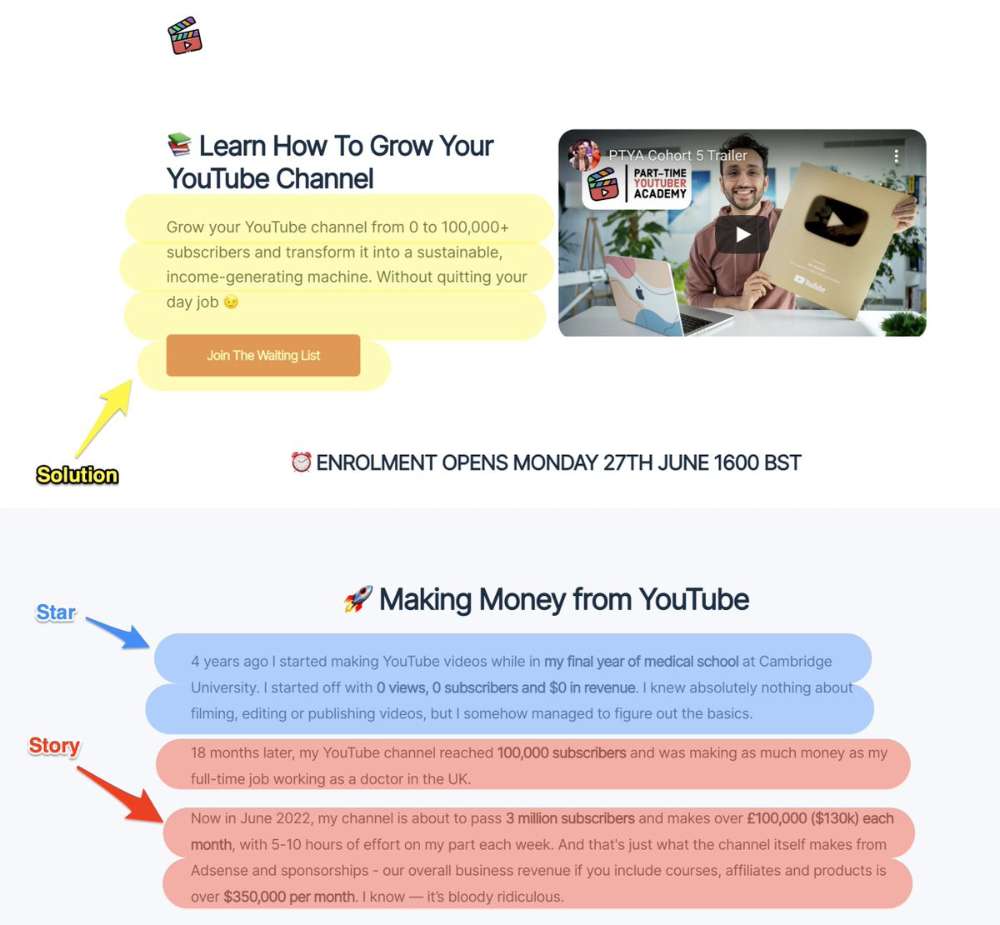
More on Marketing

Karo Wanner
3 years ago
This is how I started my Twitter account.
My 12-day results look good.

Twitter seemed for old people and politicians.
I thought the platform would die soon like Facebook.
The platform's growth stalled around 300m users between 2015 and 2019.
In 2020, Twitter grew and now has almost 400m users.
Niharikaa Kaur Sodhi built a business on Twitter while I was away, despite its low popularity.
When I read about the success of Twitter users in the past 2 years, I created an account and a 3-month strategy.
I'll see if it's worth starting Twitter in 2022.
Late or perfect? I'll update you. Track my Twitter growth. You can find me here.
My Twitter Strategy
My Twitter goal is to build a community and recruit members for Mindful Monday.
I believe mindfulness is the only way to solve problems like poverty, inequality, and the climate crisis.
The power of mindfulness is my mission.
Mindful Monday is your weekly reminder to live in the present moment. I send mindfulness tips every Monday.
My Twitter profile promotes Mindful Monday and encourages people to join.
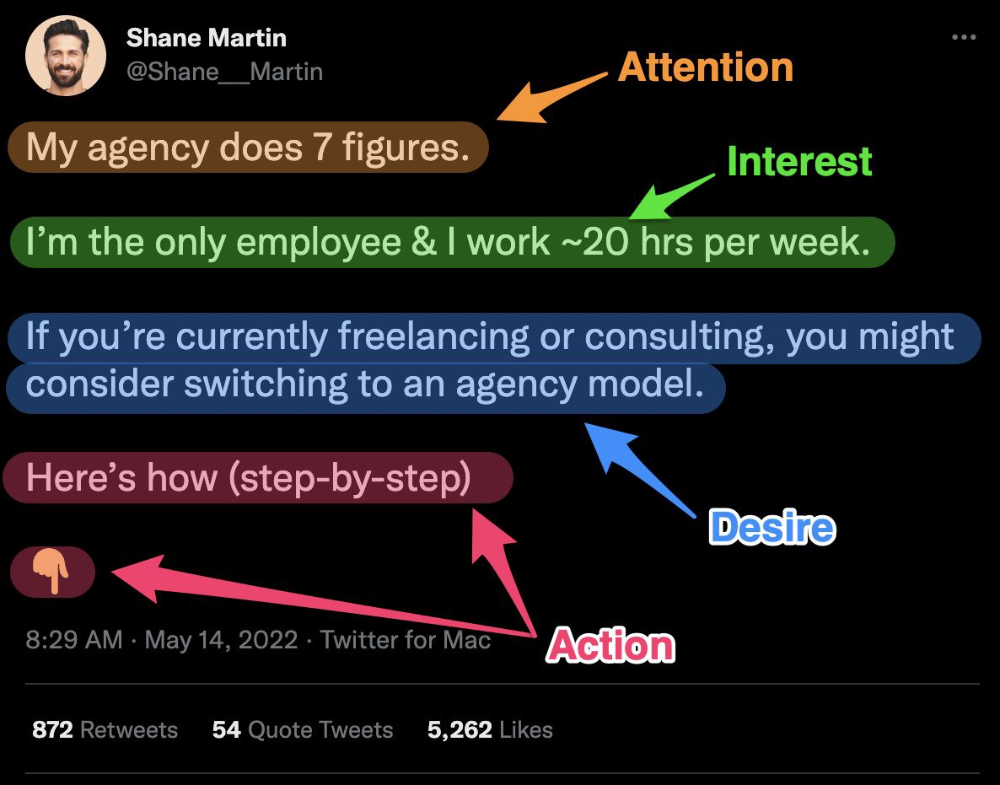
What I paid attention to:
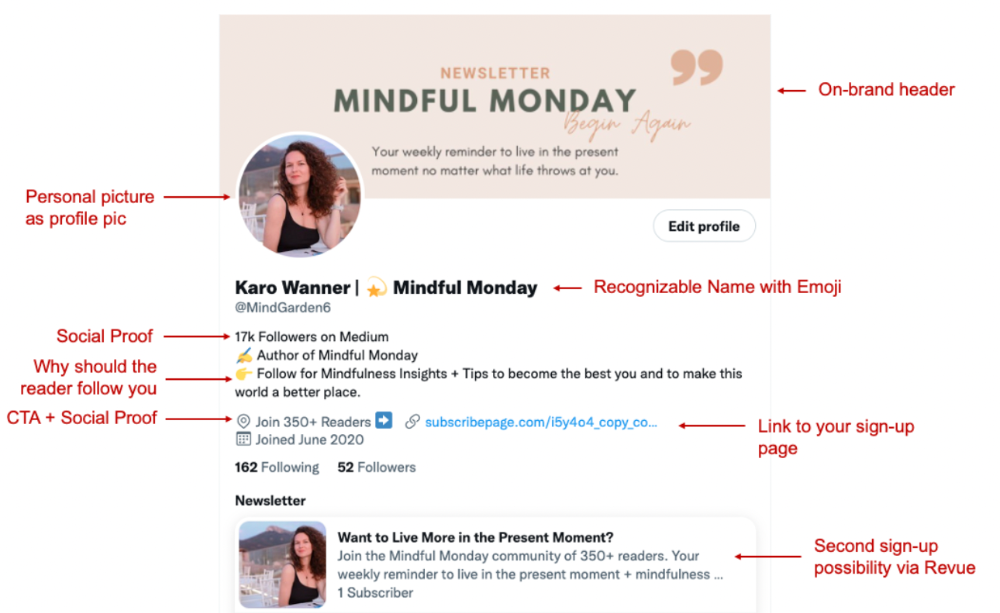
I designed a brand-appropriate header to promote Mindful Monday.
Choose a profile picture. People want to know who you are.
I added my name as I do on Medium, Instagram, and emails. To stand out and be easily recognized, add an emoji if appropriate. Add what you want to be known for, such as Health Coach, Writer, or Newsletter.
People follow successful, trustworthy people. Describe any results you have. This could be views, followers, subscribers, or major news outlets. Create!
Tell readers what they'll get by following you. Can you help?
Add CTA to your profile. Your Twitter account's purpose. Give instructions. I placed my sign-up link next to the CTA to promote Mindful Monday. Josh Spector recommended this. (Thanks! Bonus tip: If you don't want the category to show in your profile, e.g. Entrepreneur, go to edit profile, edit professional profile, and choose 'Other'
Here's my Twitter:
I'm no expert, but I tried. Please share any additional Twitter tips and suggestions in the comments.
To hide your Revue newsletter subscriber count:
Join Revue. Select 'Hide Subscriber Count' in Account settings > Settings > Subscriber Count. Voila!
How frequently should you tweet?
1 to 20 Tweets per day, but consistency is key.
Stick to a daily tweet limit. Start with less and be consistent than the opposite.
I tweet 3 times per day. That's my comfort zone. Larger accounts tweet 5–7 times daily.
Do what works for you and that is the right amount.
Twitter is a long-term game, so plan your tweets for a year.
How to Batch Your Tweets?
Sunday batchs.
Sunday evenings take me 1.5 hours to create all my tweets for the week.
Use a word document and write down your posts. Podcasts, books, my own articles inspire me.
When I have a good idea or see a catchy Tweet, I take a screenshot.
To not copy but adapt.
Two pillars support my content:
(90% ~ 29 tweets per week) Inspirational quotes, mindfulness tips, zen stories, mistakes, myths, book recommendations, etc.
(10% 2 tweets per week) I share how I grow Mindful Monday with readers. This pillar promotes MM and behind-the-scenes content.
Second, I schedule all my Tweets using TweetDeck. I tweet at 7 a.m., 5 p.m., and 6 p.m.
Include Twitter Threads in your content strategy
Tweets are blog posts. In your first tweet, you include a headline, then tweet your content.
That’s how you create a series of connected Tweets.
What’s the point? You have more room to convince your reader you're an expert.
Add a call-to-action to your thread.
Follow for more like this
Newsletter signup (share your link)
Ask for retweet
One thread per week is my goal.
I'll schedule threads with Typefully. In the free version, you can schedule one Tweet, but that's fine.
Pin a thread to the top of your profile if it leads to your newsletter. So new readers see your highest-converting content first.
Tweet Medium posts
I also tweet Medium articles.
I schedule 1 weekly repost for 5 weeks after each publication. I share the same article daily for 5 weeks.
Every time I tweet, I include a different article quote, so even if the link is the same, the quote adds value.
Engage Other Experts
When you first create your account, few people will see it. Normal.
If you comment on other industry accounts, you can reach their large audience.
First, you need 50 to 100 followers. Here's my beginner tip.
15 minutes a day or when I have downtime, I comment on bigger accounts in my niche.
My 12-Day Results
Now let's look at the first data.
I had 32 followers on March 29. 12 followers in 11 days. I have 52 now.
Not huge, but growing rapidly.
Let's examine impressions/views.
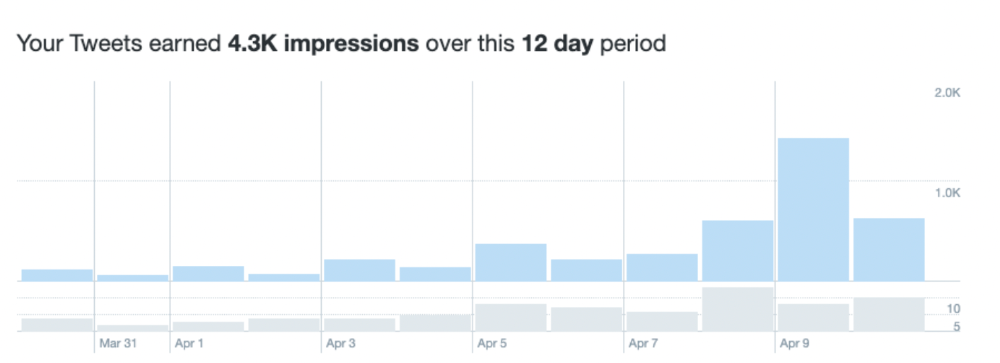
As a newbie, I gained 4,300 impressions/views in 12 days. On Medium, I got fewer views.
The 1,6k impressions per day spike comes from a larger account I mentioned the day before. First, I was shocked to see the spike and unsure of its origin.
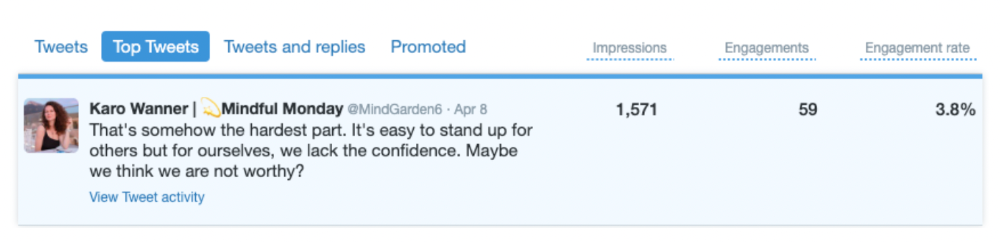
These results are promising given the effort required to be consistent on Twitter.
Let's see how my journey progresses. I'll keep you posted.
Tweeters, Does this content strategy make sense? What's wrong? Comment below.
Let's support each other on Twitter. Here's me.
Which Twitter strategy works for you in 2022?
This post is a summary. Read the full article here

Rachel Greenberg
3 years ago
6 Causes Your Sales Pitch Is Unintentionally Repulsing Customers
Skip this if you don't want to discover why your lively, no-brainer pitch isn't making $10k a month.

You don't want to be repulsive as an entrepreneur or anyone else. Making friends, influencing people, and converting strangers into customers will be difficult if your words evoke disgust, distrust, or disrespect. You may be one of many entrepreneurs who do this obliviously and involuntarily.
I've had to master selling my skills to recruiters (to land 6-figure jobs on Wall Street), selling companies to buyers in M&A transactions, and selling my own companies' products to strangers-turned-customers. I probably committed every cardinal sin of sales repulsion before realizing it was me or my poor salesmanship strategy.
If you're launching a new business, frustrated by low conversion rates, or just curious if you're repelling customers, read on to identify (and avoid) the 6 fatal errors that can kill any sales pitch.
1. The first indication
So many people fumble before they even speak because they assume their role is to convince the buyer. In other words, they expect to pressure, arm-twist, and combat objections until they convert the buyer. Actuality, the approach stinks of disgust, and emotionally-aware buyers would feel "gross" immediately.
Instead of trying to persuade a customer to buy, ask questions that will lead them to do so on their own. When a customer discovers your product or service on their own, they need less outside persuasion. Why not position your offer in a way that leads customers to sell themselves on it?
2. A flawless performance
Are you memorizing a sales script, tweaking video testimonials, and expunging historical blemishes before hitting "publish" on your new campaign? If so, you may be hurting your conversion rate.
Perfection may be a step too far and cause prospects to mistrust your sincerity. Become a great conversationalist to boost your sales. Seriously. Being charismatic is hard without being genuine and showing a little vulnerability.
People like vulnerability, even if it dents your perfect facade. Show the customer's stuttering testimonial. Open up about your or your company's past mistakes (and how you've since improved). Make your sales pitch a two-way conversation. Let the customer talk about themselves to build rapport. Real people sell, not canned scripts and movie-trailer testimonials.
If marketing or sales calls feel like a performance, you may be doing something wrong or leaving money on the table.
3. Your greatest phobia
Three minutes into prospect talks, I'd start sweating. I was talking 100 miles per hour, covering as many bases as possible to avoid the ones I feared. I knew my then-offering was inadequate and my firm had fears I hadn't addressed. So I word-vomited facts, features, and everything else to avoid the customer's concerns.
Do my prospects know I'm insecure? Maybe not, but it added an unnecessary and unhelpful layer of paranoia that kept me stressed, rushed, and on edge instead of connecting with the prospect. Skirting around a company, product, or service's flaws or objections is a poor, temporary, lazy (and cowardly) decision.
How can you project confidence and trust if you're afraid? Before you make another sales call, face your shortcomings, weak points, and objections. Your company won't be everyone's cup of tea, but you should have answers to every question or objection. You should be your business's top spokesperson and defender.
4. The unintentional apologies
Have you ever begged for a sale? I'm going to say no, however you may be unknowingly emitting sorry, inferior, insecure energy.
Young founders, first-time entrepreneurs, and those with severe imposter syndrome may elevate their target customer. This is common when trying to get first customers for obvious reasons.
Since you're truly new at this, you naturally lack experience.
You don't have the self-confidence boost of thousands or hundreds of closed deals or satisfied client results to remind you that your good or service is worthwhile.
Getting those initial few clients seems like the most difficult task, as if doing so will decide the fate of your company as a whole (it probably won't, and you shouldn't actually place that much emphasis on any one transaction).
Customers can smell fear, insecurity, and anxiety just like they can smell B.S. If you believe your product or service improves clients' lives, selling it should feel like a benevolent act of service, not a sleazy money-grab. If you're a sincere entrepreneur, prospects will believe your proposition; if you're apprehensive, they'll notice.
Approach every sale as if you're fine with or without it. This has improved my salesmanship, marketing skills, and mental health. When you put pressure on yourself to close a sale or convince a difficult prospect "or else" (your company will fail, your rent will be late, your electricity will be cut), you emit desperation and lower the quality of your pitch. There's no point.
5. The endless promises
We've all read a million times how to answer or disprove prospects' arguments and add extra incentives to speed or secure the close. Some objections shouldn't be refuted. What if I told you not to offer certain incentives, bonuses, and promises? What if I told you to walk away from some prospects, even if it means losing your sales goal?
If you market to enough people, make enough sales calls, or grow enough companies, you'll encounter prospects who can't be satisfied. These prospects have endless questions, concerns, and requests for more, more, more that you'll never satisfy. These people are a distraction, a resource drain, and a test of your ability to cut losses before they erode your sanity and profit margin.
To appease or convert these insatiably needy, greedy Nellies into customers, you may agree with or acquiesce to every request and demand — even if you can't follow through. Once you overpromise and answer every hole they poke, their trust in you may wane quickly.
Telling a prospect what you can't do takes courage and integrity. If you're honest, upfront, and willing to admit when a product or service isn't right for the customer, you'll gain respect and positive customer experiences. Sometimes honesty is the most refreshing pitch and the deal-closer.
6. No matter what
Have you ever said, "I'll do anything to close this sale"? If so, you've probably already been disqualified. If a prospective customer haggles over a price, requests a discount, or continues to wear you down after you've made three concessions too many, you have a metal hook in your mouth, not them, and it may not end well. Why?
If you're so willing to cut a deal that you cut prices, comp services, extend payment plans, waive fees, etc., you betray your own confidence that your product or service was worth the stated price. They wonder if anyone is paying those prices, if you've ever had a customer (who wasn't a blood relative), and if you're legitimate or worth your rates.
Once a prospect senses that you'll do whatever it takes to get them to buy, their suspicions rise and they wonder why.
Why are you cutting pricing if something is wrong with you or your service?
Why are you so desperate for their sale?
Why aren't more customers waiting in line to pay your pricing, and if they aren't, what on earth are they doing there?
That's what a prospect thinks when you reveal your lack of conviction, desperation, and willingness to give up control. Some prospects will exploit it to drain you dry, while others will be too frightened to buy from you even if you paid them.
Walking down a two-way street. Be casual.
If we track each act of repulsion to an uneasiness, fear, misperception, or impulse, it's evident that these sales and marketing disasters were forced communications. Stiff, imbalanced, divisive, combative, bravado-filled, and desperate. They were unnatural and accepted a power struggle between two sparring, suspicious, unequal warriors, rather than a harmonious oneness of two natural, but opposite parties shaking hands.
Sales should be natural, harmonious. Sales should feel good for both parties, not like one party is having their arm twisted.
You may be doing sales wrong if it feels repulsive, icky, or degrading. If you're thinking cringe-worthy thoughts about yourself, your product, service, or sales pitch, imagine what you're projecting to prospects. Don't make it unpleasant, repulsive, or cringeworthy.

Victoria Kurichenko
3 years ago
What Happened After I Posted an AI-Generated Post on My Website
This could cost you.

Content creators may have heard about Google's "Helpful content upgrade."
This change is another Google effort to remove low-quality, repetitive, and AI-generated content.
Why should content creators care?
Because too much content manipulates search results.
My experience includes the following.
Website admins seek high-quality guest posts from me. They send me AI-generated text after I say "yes." My readers are irrelevant. Backlinks are needed.
Companies copy high-ranking content to boost their Google rankings. Unfortunately, it's common.
What does this content offer?
Nothing.
Despite Google's updates and efforts to clean search results, webmasters create manipulative content.
As a marketer, I knew about AI-powered content generation tools. However, I've never tried them.
I use old-fashioned content creation methods to grow my website from 0 to 3,000 monthly views in one year.
Last year, I launched a niche website.
I do keyword research, analyze search intent and competitors' content, write an article, proofread it, and then optimize it.
This strategy is time-consuming.
But it yields results!
Here's proof from Google Analytics:
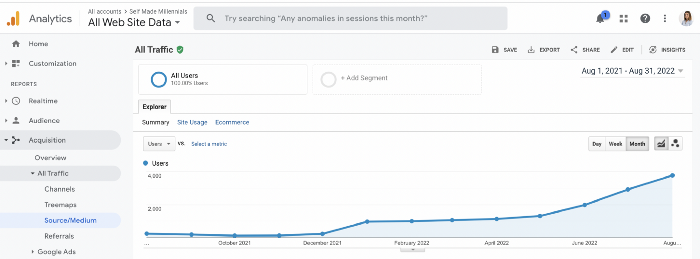
Proven strategies yield promising results.
To validate my assumptions and find new strategies, I run many experiments.
I tested an AI-powered content generator.
I used a tool to write this Google-optimized article about SEO for startups.
I wanted to analyze AI-generated content's Google performance.
Here are the outcomes of my test.
First, quality.
I dislike "meh" content. I expect articles to answer my questions. If not, I've wasted my time.
My essays usually include research, personal anecdotes, and what I accomplished and achieved.
AI-generated articles aren't as good because they lack individuality.
Read my AI-generated article about startup SEO to see what I mean.

It's dry and shallow, IMO.
It seems robotic.
I'd use quotes and personal experience to show how SEO for startups is different.
My article paraphrases top-ranked articles on a certain topic.
It's readable but useless. Similar articles abound online. Why read it?
AI-generated content is low-quality.
Let me show you how this content ranks on Google.
The Google Search Console report shows impressions, clicks, and average position.
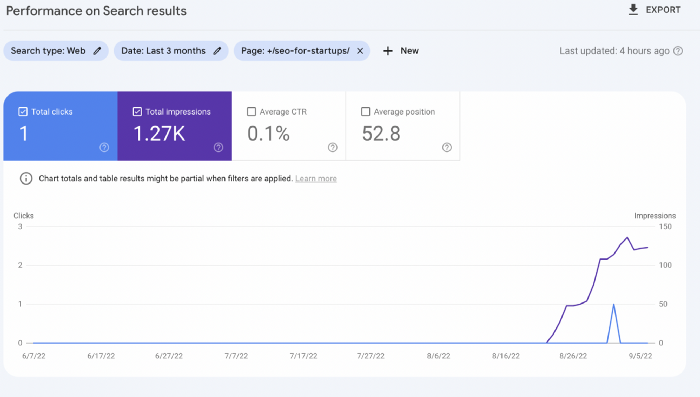
Low numbers.
No one opens the 5th Google search result page to read the article. Too far!
You may say the new article will improve.
Marketing-wise, I doubt it.
This article is shorter and less comprehensive than top-ranking pages. It's unlikely to win because of this.
AI-generated content's terrible reality.
I'll compare how this content I wrote for readers and SEO performs.
Both the AI and my article are fresh, but trends are emerging.
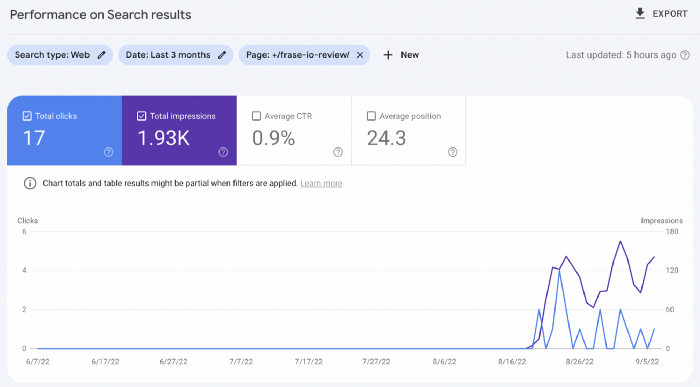
My article's CTR and average position are higher.
I spent a week researching and producing that piece, unlike AI-generated content. My expert perspective and unique consequences make it interesting to read.
Human-made.
In summary
No content generator can duplicate a human's tone, writing style, or creativity. Artificial content is always inferior.
Not "bad," but inferior.
Demand for content production tools will rise despite Google's efforts to eradicate thin content.
Most won't spend hours producing link-building articles. Costly.
As guest and sponsored posts, artificial content will thrive.
Before accepting a new arrangement, content creators and website owners should consider this.
You might also like

Sammy Abdullah
3 years ago
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
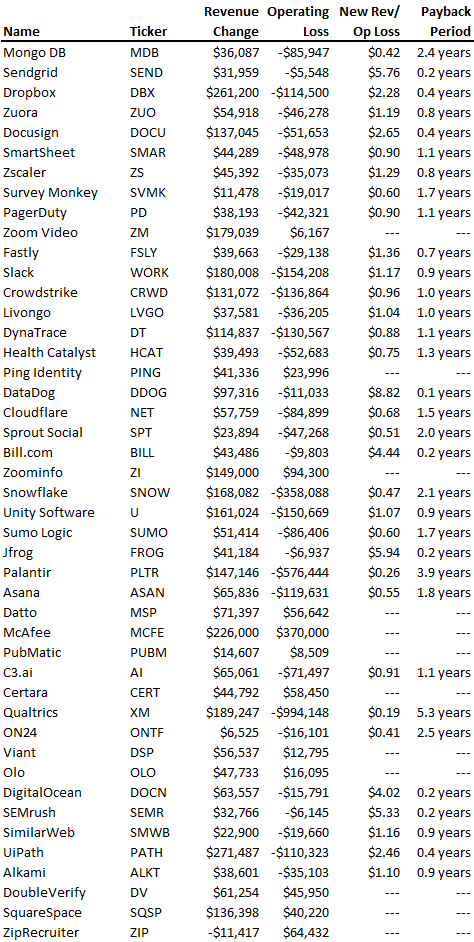
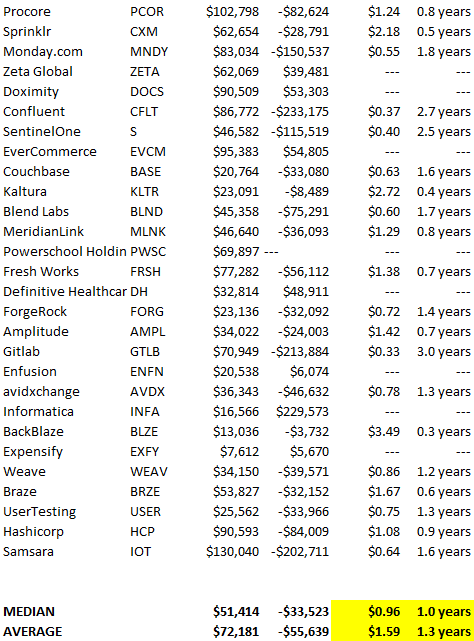
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.

forkast
3 years ago
Three Arrows Capital collapse sends crypto tremors

Three Arrows Capital's Google search volume rose over 5,000%.
Three Arrows Capital, a Singapore-based cryptocurrency hedge fund, filed for Chapter 15 bankruptcy last Friday to protect its U.S. assets from creditors.
Three Arrows filed for bankruptcy on July 1 in New York.
Three Arrows was ordered liquidated by a British Virgin Islands court last week after defaulting on a $670 million loan from Voyager Digital. Three days later, the Singaporean government reprimanded Three Arrows for spreading misleading information and exceeding asset limits.
Three Arrows' troubles began with Terra's collapse in May, after it bought US$200 million worth of Terra's LUNA tokens in February, co-founder Kyle Davies told the Wall Street Journal. Three Arrows has failed to meet multiple margin calls since then, including from BlockFi and Genesis.
Three Arrows Capital, founded by Kyle Davies and Su Zhu in 2012, manages $10 billion in crypto assets.
Bitcoin's price fell from US$20,600 to below US$19,200 after Three Arrows' bankruptcy petition. According to CoinMarketCap, BTC is now above US$20,000.
What does it mean?
Every action causes an equal and opposite reaction, per Newton's third law. Newtonian physics won't comfort Three Arrows investors, but future investors will thank them for their overconfidence.
Regulators are taking notice of crypto's meteoric rise and subsequent fall. Historically, authorities labeled the industry "high risk" to warn traditional investors against entering it. That attitude is changing. Regulators are moving quickly to regulate crypto to protect investors and prevent broader asset market busts.
The EU has reached a landmark deal that will regulate crypto asset sales and crypto markets across the 27-member bloc. The U.S. is close behind with a similar ruling, and smaller markets are also looking to improve safeguards.
For many, regulation is the only way to ensure the crypto industry survives the current winter.

Caleb Naysmith
3 years ago Draft
A Myth: Decentralization
It’s simply not conceivable, or at least not credible.

One of the most touted selling points of Crypto has always been this grandiose idea of decentralization. Bitcoin first arose in 2009 after the housing crisis and subsequent crash that came with it. It aimed to solve this supposed issue of centralization. Nobody “owns” Bitcoin in theory, so the idea then goes that it won’t be subject to the same downfalls that led to the 2008 crash or similarly speculative events that led to the 2008 disaster. The issue is the banks, not the human nature associated with the greedy individuals running them.
Subsequent blockchains have attempted to fix many of the issues of Bitcoin by increasing capacity, decreasing the costs and processing times associated with Bitcoin, and expanding what can be done with their blockchains. Since nobody owns Bitcoin, it hasn’t really been able to be expanded on. You have people like Vitalk Buterin, however, that actively work on Ethereum though.
The leap from Bitcoin to Ethereum was a massive leap toward centralization, and the trend has only gotten worse. In fact, crypto has since become almost exclusively centralized in recent years.
Decentralization is only good in theory
It’s a good idea. In fact, it’s a wonderful idea. However, like other utopian societies, individuals misjudge human nature and greed. In a perfect world, decentralization would certainly be a wonderful idea because sure, people may function as their own banks, move payments immediately, remain anonymous, and so on. However, underneath this are a couple issues:
You can already send money instantaneously today.
They are not decentralized.
Decentralization is a bad idea.
Being your own bank is a stupid move.
Let’s break these down. Some are quite simple, but lets have a look.
Sending money right away
One thing with crypto is the idea that you can send payments instantly. This has pretty much been entirely solved in current times. You can transmit significant sums of money instantly for a nominal cost and it’s instantaneously cleared. Venmo was launched in 2009 and has since increased to prominence, and currently is on most people's phones. I can directly send ANY amount of money quickly from my bank to another person's Venmo account.
Comparing that with ETH and Bitcoin, Venmo wins all around. I can send money to someone for free instantly in dollars and the only fee paid is optional depending on when you want it.
Both Bitcoin and Ethereum are subject to demand. If the blockchains have a lot of people trying to process transactions fee’s go up, and the time that it takes to receive your crypto takes longer. When Ethereum gets bad, people have reported spending several thousand of dollars on just 1 transaction.
These transactions take place via “miners” bundling and confirming transactions, then recording them on the blockchain to confirm that the transaction did indeed happen. They charge fees to do this and are also paid in Bitcoin/ETH. When a transaction is confirmed, it's then sent to the other users wallet. This within itself is subject to lots of controversy because each transaction needs to be confirmed 6 times, this takes massive amounts of power, and most of the power is wasted because this is an adversarial system in which the person that mines the transaction gets paid, and everyone else is out of luck. Also, these could theoretically be subject to a “51% attack” in which anyone with over 51% of the mining hash rate could effectively control all of the transactions, and reverse transactions while keeping the BTC resulting in “double spending”.
There are tons of other issues with this, but essentially it means: They rely on these third parties to confirm the transactions. Without people confirming these transactions, Bitcoin stalls completely, and if anyone becomes too dominant they can effectively control bitcoin.
Not to mention, these transactions are in Bitcoin and ETH, not dollars. So, you need to convert them to dollars still, and that's several more transactions, and likely to take several days anyway as the centralized exchange needs to send you the money by traditional methods.
They are not distributed
That takes me to the following point. This isn’t decentralized, at all. Bitcoin is the closest it gets because Satoshi basically closed it to new upgrades, although its still subject to:
Whales
Miners
It’s vital to realize that these are often the same folks. While whales aren’t centralized entities typically, they can considerably effect the price and outcome of Bitcoin. If the largest wallets holding as much as 1 million BTC were to sell, it’d effectively collapse the price perhaps beyond repair. However, Bitcoin can and is pretty much controlled by the miners. Further, Bitcoin is more like an oligarchy than decentralized. It’s been effectively used to make the rich richer, and both the mining and price is impacted by the rich. The overwhelming minority of those actually using it are retail investors. The retail investors are basically never the ones generating money from it either.
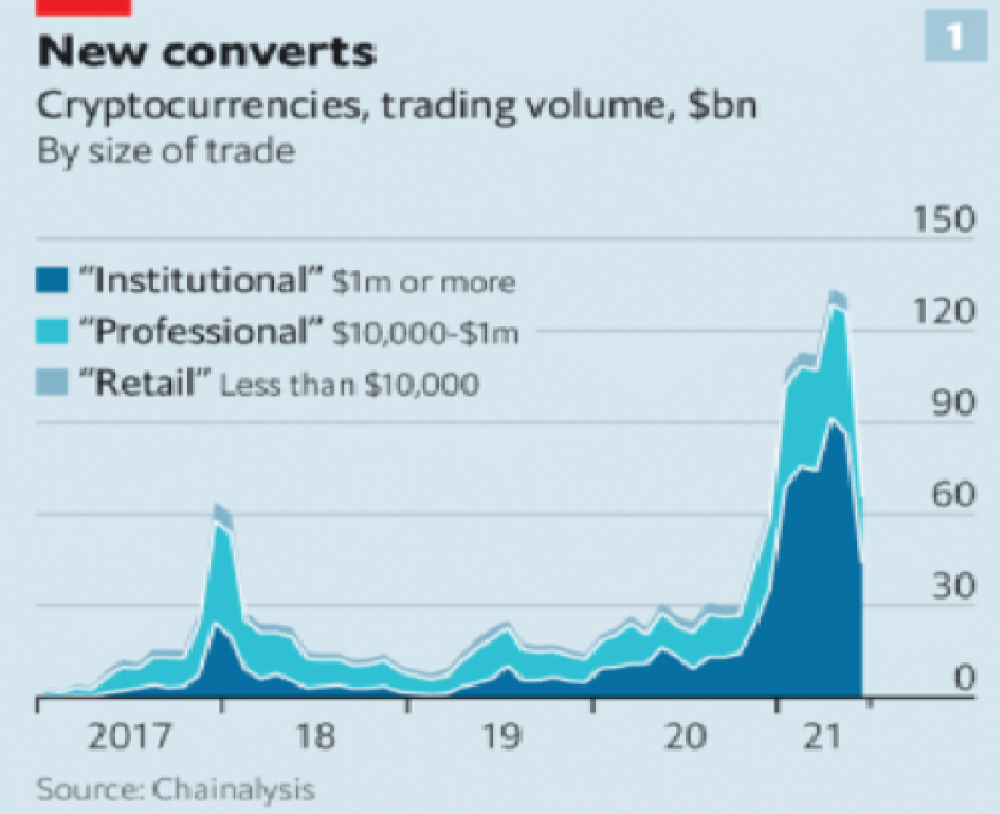
As far as ETH and other cryptos go, there is realistically 0 case for them being decentralized. Vitalik could not only kill it but even walking away from it would likely lead to a significant decline. It has tons of issues right now that Vitalik has promised to fix with the eventual Ethereum 2.0., and stepping away from it wouldn’t help.
Most tokens as well are generally tied to some promise of future developments and creators. The same is true for most NFT projects. The reason 99% of crypto and NFT projects fail is because they failed to deliver on various promises or bad dev teams, or poor innovation, or the founders just straight up stole from everyone. I could go more in-depth than this but go find any project and if there is a dev team, company, or person tied to it then it's likely, not decentralized. The success of that project is directly tied to the dev team, and if they wanted to, most hold large wallets and could sell it all off effectively killing the project. Not to mention, any crypto project that doesn’t have a locked contract can 100% be completely rugged and they can run off with all of the money.
Decentralization is undesirable
Even if they were decentralized then it would not be a good thing. The graphic above indicates this is effectively a rich person’s unregulated playground… so it’s exactly like… the very issue it tried to solve?
Not to mention, it’s supposedly meant to prevent things like 2008, but is regularly subjected to 50–90% drawdowns in value? Back when Bitcoin was only known in niche parts of the dark web and illegal markets, it would regularly drop as much as 90% and has a long history of massive drawdowns.
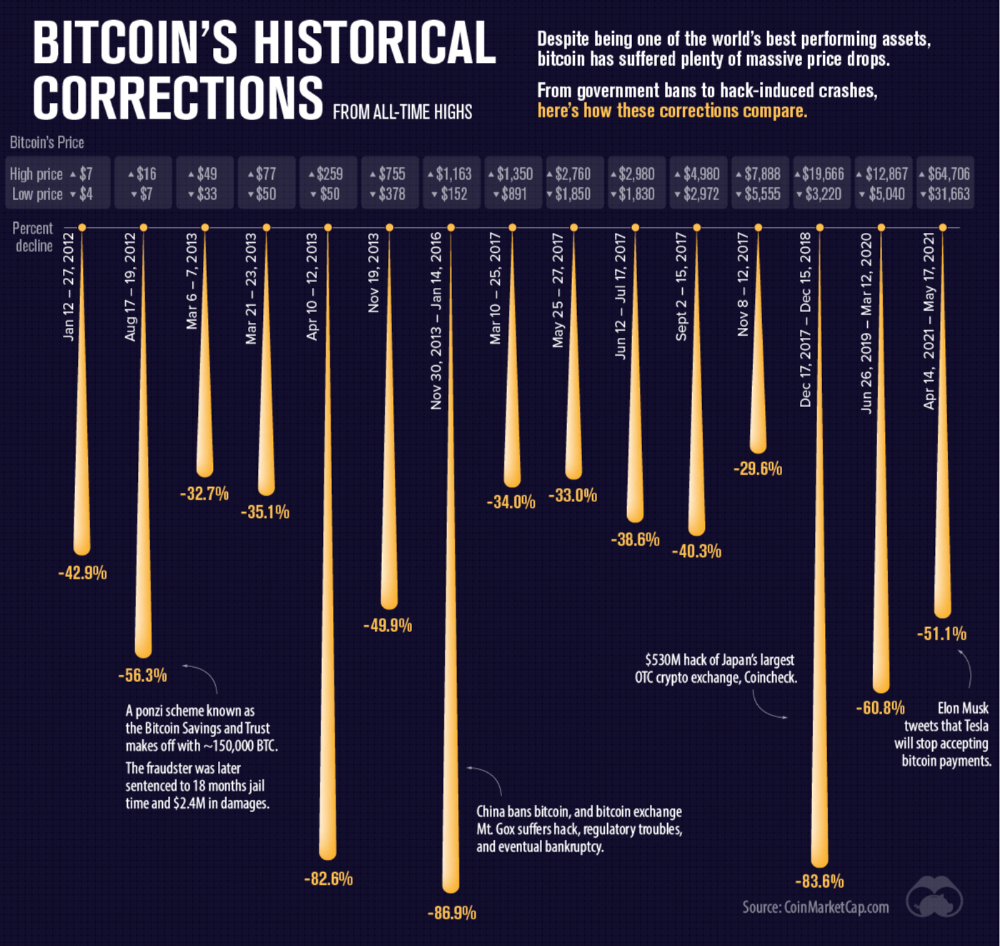
The majority of crypto is blatant scams, and ALL of crypto is a “zero” or “negative” sum game in that it relies on the next person buying for people to make money. This is not a good thing. This has yet to solve any issues around what caused the 2008 crisis. Rather, it seemingly amplified all of the bad parts of it actually. Crypto is the ultimate speculative asset and realistically has no valuation metric. People invest in Apple because it has revenue and cash on hand. People invest in crypto purely for speculation. The lack of regulation or accountability means this is amplified to the most extreme degree where anything goes: Fraud, deception, pump and dumps, scams, etc. This results in a pure speculative madhouse where, unsurprisingly, only the rich win. Not only that but the deck is massively stacked in against the everyday investor because you can’t do a pump and dump without money.
At the heart of all of this is still the same issues: greed and human nature. However, in setting out to solve the issues that allowed 2008 to happen, they made something that literally took all of the bad parts of 2008 and then amplified it. 2008, similarly, was due to greed and human nature but was allowed to happen due to lack of oversite, rich people's excessive leverage over the poor, and excessive speculation. Crypto trades SOLELY on human emotion, has 0 oversite, is pure speculation, and the power dynamic is just as bad or worse.
Why should each individual be their own bank?
This is the last one, and it's short and basic. Why do we want people functioning as their own bank? Everything we do relies on another person. Without the internet, and internet providers there is no crypto. We don’t have people functioning as their own home and car manufacturers or internet service providers. Sure, you might specialize in some of these things, but masquerading as your own bank is a horrible idea.
I am not in the banking industry so I don’t know all the issues with banking. Most people aren’t in banking or crypto, so they don’t know the ENDLESS scams associated with it, and they are bound to lose their money eventually.
If you appreciate this article and want to read more from me and authors like me, without any limits, consider buying me a coffee: buymeacoffee.com/calebnaysmith