



More on Technology

Duane Michael
3 years ago
Don't Fall Behind: 7 Subjects You Must Understand to Keep Up with Technology
As technology develops, you should stay up to date

You don't want to fall behind, do you? This post covers 7 tech-related things you should know.
You'll learn how to operate your computer (and other electronic devices) like an expert and how to leverage the Internet and social media to create your brand and business. Read on to stay relevant in today's tech-driven environment.
You must learn how to code.
Future-language is coding. It's how we and computers talk. Learn coding to keep ahead.
Try Codecademy or Code School. There are also numerous free courses like Coursera or Udacity, but they take a long time and aren't necessarily self-paced, so it can be challenging to find the time.
Artificial intelligence (AI) will transform all jobs.
Our skillsets must adapt with technology. AI is a must-know topic. AI will revolutionize every employment due to advances in machine learning.
Here are seven AI subjects you must know.
What is artificial intelligence?
How does artificial intelligence work?
What are some examples of AI applications?
How can I use artificial intelligence in my day-to-day life?
What jobs have a high chance of being replaced by artificial intelligence and how can I prepare for this?
Can machines replace humans? What would happen if they did?
How can we manage the social impact of artificial intelligence and automation on human society and individual people?
Blockchain Is Changing the Future
Few of us know how Bitcoin and blockchain technology function or what impact they will have on our lives. Blockchain offers safe, transparent, tamper-proof transactions.
It may alter everything from business to voting. Seven must-know blockchain topics:
Describe blockchain.
How does the blockchain function?
What advantages does blockchain offer?
What possible uses for blockchain are there?
What are the dangers of blockchain technology?
What are my options for using blockchain technology?
What does blockchain technology's future hold?
Cryptocurrencies are here to stay
Cryptocurrencies employ cryptography to safeguard transactions and manage unit creation. Decentralized cryptocurrencies aren't controlled by governments or financial institutions.

Bitcoin, the first cryptocurrency, was launched in 2009. Cryptocurrencies can be bought and sold on decentralized exchanges.
Bitcoin is here to stay.
Bitcoin isn't a fad, despite what some say. Since 2009, Bitcoin's popularity has grown. Bitcoin is worth learning about now. Since 2009, Bitcoin has developed steadily.
With other cryptocurrencies emerging, many people are wondering if Bitcoin still has a bright future. Curiosity is natural. Millions of individuals hope their Bitcoin investments will pay off since they're popular now.
Thankfully, they will. Bitcoin is still running strong a decade after its birth. Here's why.
The Internet of Things (IoT) is no longer just a trendy term.
IoT consists of internet-connected physical items. These items can share data. IoT is young but developing fast.
20 billion IoT-connected devices are expected by 2023. So much data! All IT teams must keep up with quickly expanding technologies. Four must-know IoT topics:
Recognize the fundamentals: Priorities first! Before diving into more technical lingo, you should have a fundamental understanding of what an IoT system is. Before exploring how something works, it's crucial to understand what you're working with.
Recognize Security: Security does not stand still, even as technology advances at a dizzying pace. As IT professionals, it is our duty to be aware of the ways in which our systems are susceptible to intrusion and to ensure that the necessary precautions are taken to protect them.
Be able to discuss cloud computing: The cloud has seen various modifications over the past several years once again. The use of cloud computing is also continually changing. Knowing what kind of cloud computing your firm or clients utilize will enable you to make the appropriate recommendations.
Bring Your Own Device (BYOD)/Mobile Device Management (MDM) is a topic worth discussing (MDM). The ability of BYOD and MDM rules to lower expenses while boosting productivity among employees who use these services responsibly is a major factor in their continued growth in popularity.
IoT Security is key
As more gadgets connect, they must be secure. IoT security includes securing devices and encrypting data. Seven IoT security must-knows:
fundamental security ideas
Authorization and identification
Cryptography
electronic certificates
electronic signatures
Private key encryption
Public key encryption
Final Thoughts
With so much going on in the globe, it can be hard to stay up with technology. We've produced a list of seven tech must-knows.

Liz Martin
3 years ago
A Search Engine From Apple?

Apple's search engine has long been rumored. Recent Google developments may confirm the rumor. Is Apple about to become Google's biggest rival?
Here's a video:
People noted Apple's changes in 2020. AppleBot, a web crawler that downloads and caches Internet content, was more active than in the last five years.
Apple hired search engine developers, including ex-Googlers, such as John Giannandrea, Google's former search chief.
Apple also changed the way iPhones search. With iOS 14, Apple's search results arrived before Google's.
These facts fueled rumors that Apple was developing a search engine.
Apple and Google Have a Contract
Many skeptics said Apple couldn't compete with Google. This didn't affect the company's competitiveness.
Apple is the only business with the resources and scale to be a Google rival, with 1.8 billion active devices and a $2 trillion market cap.
Still, people doubted that due to a license deal. Google pays Apple $8 to $12 billion annually to be the default iPhone and iPad search engine.
Apple can't build an independent search product under this arrangement.
Why would Apple enter search if it's being paid to stay out?
Ironically, this partnership has many people believing Apple is getting into search.
A New Default Search Engine May Be Needed
Google was sued for antitrust in 2020. It is accused of anticompetitive and exclusionary behavior. Justice wants to end Google's monopoly.
Authorities could restrict Apple and Google's licensing deal due to its likely effect on market competitiveness. Hence Apple needs a new default search engine.
Apple Already Has a Search Engine
The company already has a search engine, Spotlight.

Since 2004, Spotlight has aired. It was developed to help users find photos, documents, apps, music, and system preferences.
Apple's search engine could do more than organize files, texts, and apps.
Spotlight Search was updated in 2014 with iOS 8. Web, App Store, and iTunes searches became available. You could find nearby places, movie showtimes, and news.
This search engine has subsequently been updated and improved. Spotlight added rich search results last year.
If you search for a TV show, movie, or song, photos and carousels will appear at the top of the page.
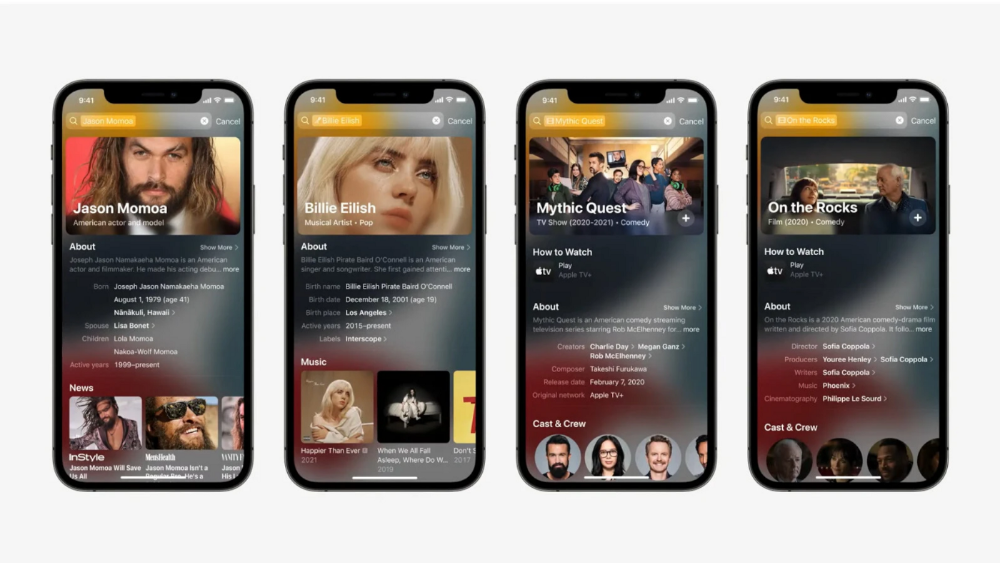
This resembles Google's rich search results.
When Will the Apple Search Engine Be Available?
When will Apple's search launch? Robert Scoble says it's near.
Scoble tweeted a number of hints before this year's Worldwide Developer Conference.
Scoble bases his prediction on insider information and deductive reasoning. January 2023 is expected.
Will you use Apple's search engine?

Paul DelSignore
2 years ago
The stunning new free AI image tool is called Leonardo AI.
Leonardo—The New Midjourney?
Users are comparing the new cowboy to Midjourney.
Leonardo.AI creates great photographs and has several unique capabilities I haven't seen in other AI image systems.
Midjourney's quality photographs are evident in the community feed.

Create Pictures Using Models
You can make graphics using platform models when you first enter the app (website):
Luma, Leonardo creative, Deliberate 1.1.
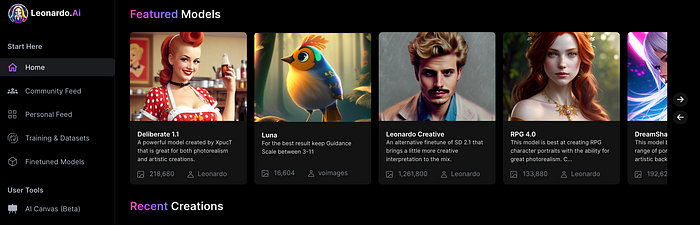
Clicking a model displays its description and samples:
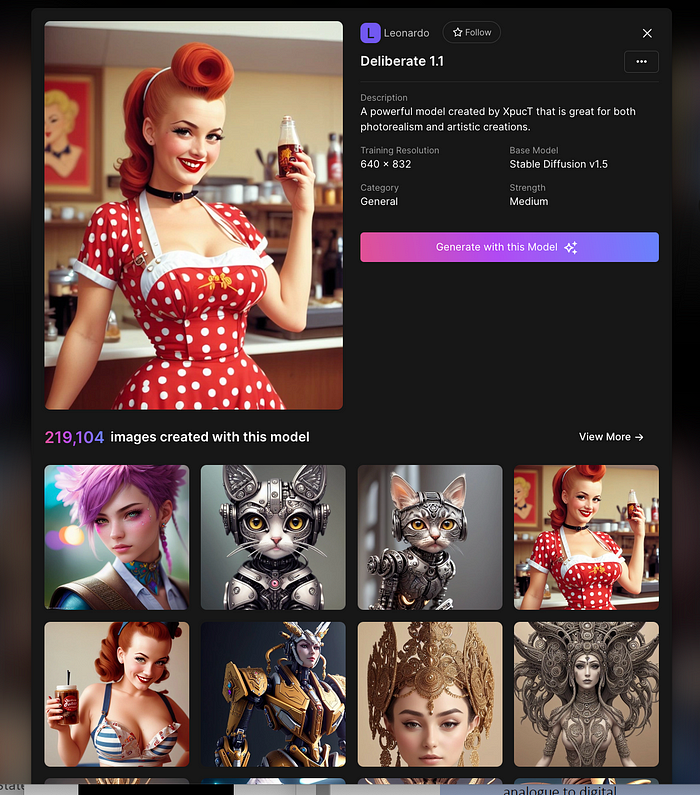
Click Generate With This Model.
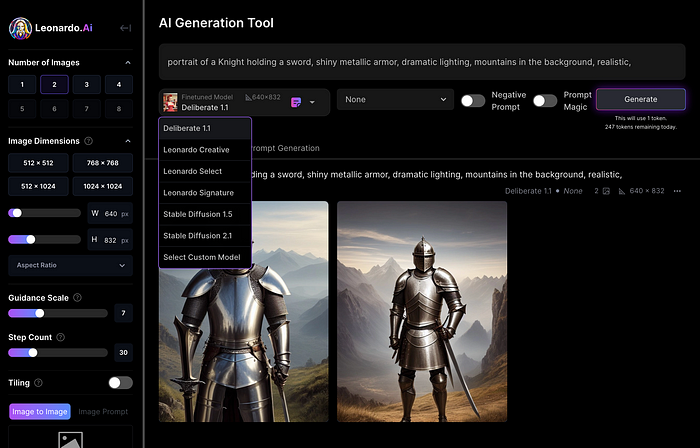
Then you can add your prompt, alter models, photos, sizes, and guide scale in a sleek UI.
Changing Pictures
Leonardo's Canvas editor lets you change created images by hovering over them:

The editor opens with masking, erasing, and picture download.

Develop Your Own Models
I've never seen anything like Leonardo's model training feature.
Upload a handful of similar photographs and save them as a model for future images. Share your model with the community.
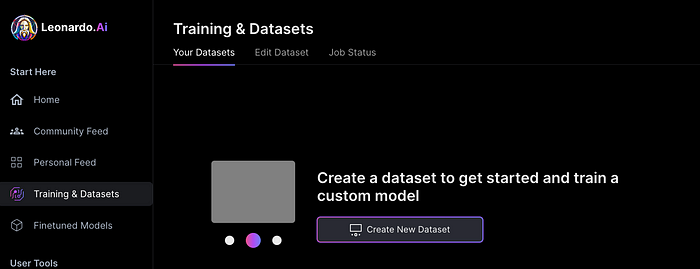
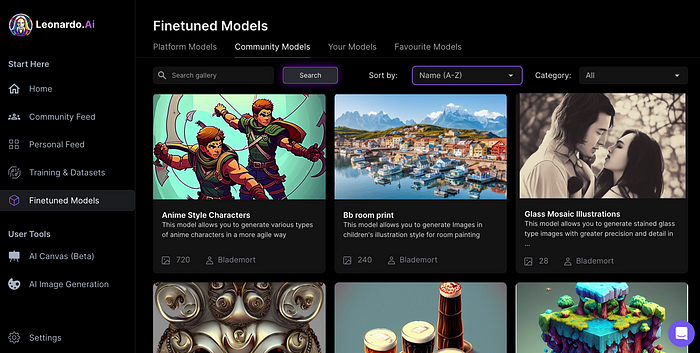
You can make photos using your own model and a community-shared set of fine-tuned models:
Obtain Leonardo access
Leonardo is currently free.
Visit Leonardo.ai and click "Get Early Access" to receive access.
Add your email to receive a link to join the discord channel. Simply describe yourself and fill out a form to join the discord channel.
Please go to 👑│introductions to make an introduction and ✨│priority-early-access will be unlocked, you must fill out a form and in 24 hours or a little more (due to demand), the invitation will be sent to you by email.
I got access in two hours, so hopefully you can too.
Last Words
I know there are many AI generative platforms, some free and some expensive, but Midjourney produces the most artistically stunning images and art.
Leonardo is the closest I've seen to Midjourney, but Midjourney is still the leader.
It's free now.
Leonardo's fine-tuned model selections, model creation, image manipulation, and output speed and quality make it a great AI image toolbox addition.
You might also like

Hector de Isidro
3 years ago
Why can't you speak English fluently even though you understand it?
Many of us have struggled for years to master a second language (in my case, English). Because (at least in my situation) we've always used an input-based system or method.
I'll explain in detail, but briefly: We can understand some conversations or sentences (since we've trained), but we can't give sophisticated answers or speak fluently (because we have NOT trained at all).
What exactly is input-based learning?
Reading, listening, writing, and speaking are key language abilities (if you look closely at that list, it seems that people tend to order them in this way: inadvertently giving more priority to the first ones than to the last ones).
These talents fall under two learning styles:
Reading and listening are input-based activities (sometimes referred to as receptive skills or passive learning).
Writing and speaking are output-based tasks (also known as the productive skills and/or active learning).
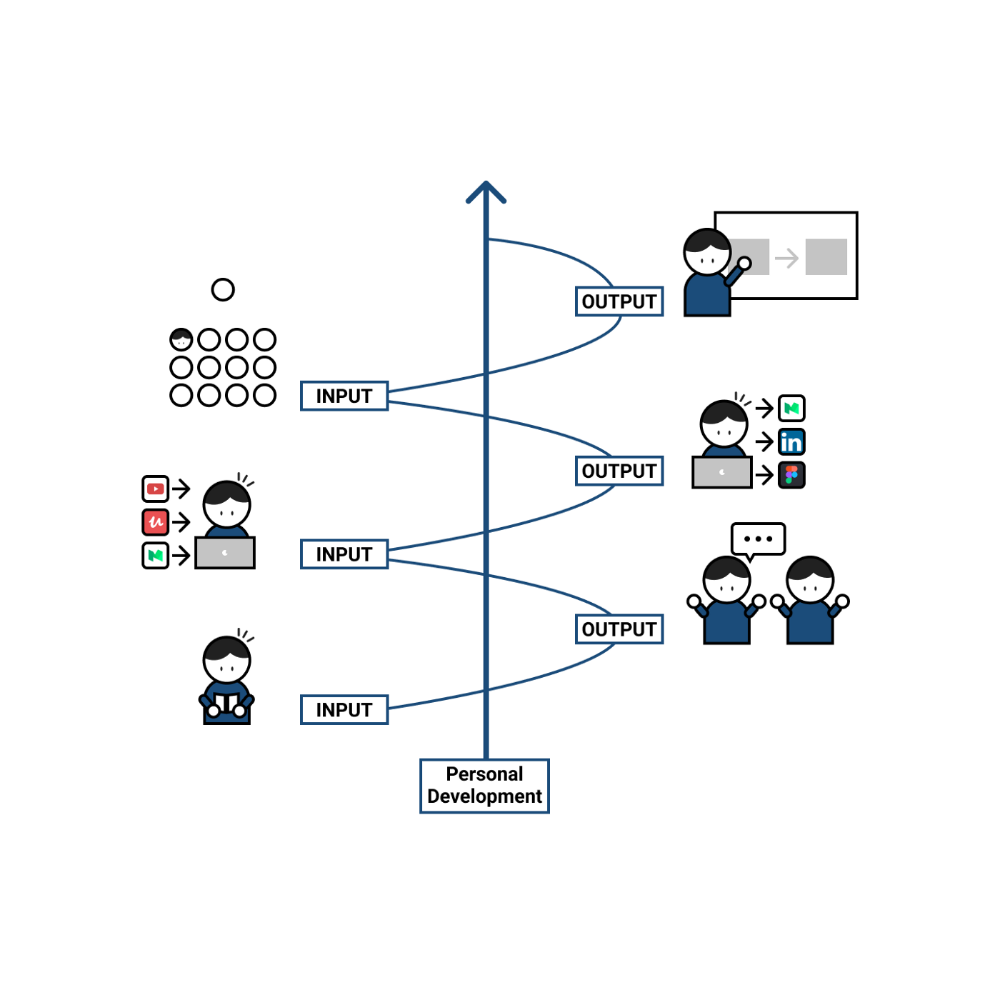
What's the best learning style? To learn a language, we must master four interconnected skills. The difficulty is how much time and effort we give each.
According to Shion Kabasawa's books The Power of Input: How to Maximize Learning and The Power of Output: How to Change Learning to Outcome (available only in Japanese), we spend 7:3 more time on Input Based skills than Output Based skills when we should be doing the opposite, leaning more towards Output (Input: Output->3:7).
I can't tell you how he got those numbers, but I think he's not far off because, for example, think of how many people say they're learning a second language and are satisfied bragging about it by only watching TV, series, or movies in VO (and/or reading a book or whatever) their Input is: 7:0 output!
You can't be good at a sport by watching TikTok videos about it; you must play.
“being pushed to produce language puts learners in a better position to notice the ‘gaps’ in their language knowledge”, encouraging them to ‘upgrade’ their existing interlanguage system. And, as they are pushed to produce language in real time and thereby forced to automate low-level operations by incorporating them into higher-level routines, it may also contribute to the development of fluency. — Scott Thornbury (P is for Push)
How may I practice output-based learning more?
I know that listening or reading is easy and convenient because we can do it on our own in a wide range of situations, even during another activity (although, as you know, it's not ideal), writing can be tedious/boring (it's funny that we almost always excuse ourselves in the lack of ideas), and speaking requires an interlocutor. But we must leave our comfort zone and modify our thinking to go from 3:7 to 7:3. (or at least balance it better to something closer). Gradually.
“You don’t have to do a lot every day, but you have to do something. Something. Every day.” — Callie Oettinger (Do this every day)
We can practice speaking like boxers shadow box.
Speaking out loud strengthens the mind-mouth link (otherwise, you will still speak fluently in your mind but you will choke when speaking out loud). This doesn't mean we should talk to ourselves on the way to work, while strolling, or on public transportation. We should try to do it without disturbing others, such as explaining what we've heard, read, or seen (the list is endless: you can TALK about what happened yesterday, your bedtime book, stories you heard at the office, that new kitten video you saw on Instagram, an experience you had, some new fact, that new boring episode you watched on Netflix, what you ate, what you're going to do next, your upcoming vacation, what’s trending, the news of the day)
Who will correct my grammar, vocabulary, or pronunciation with an imagined friend? We can't have everything, but tools and services can help [1].
Lack of bravery
Fear of speaking a language different than one's mother tongue in front of native speakers is global. It's easier said than done, because strangers, not your friends, will always make fun of your accent or faults. Accept it and try again. Karma will prevail.
Perfectionism is a trap. Stop self-sabotaging. Communication is key (and for that you have to practice the Output too ).
“Don’t forget to have fun and enjoy the process.” — Ruri Ohama
[1] Grammarly, Deepl, Google Translate, etc.

Aaron Dinin, PhD
2 years ago
The Advantages and Disadvantages of Having Investors Sign Your NDA
Startup entrepreneurs assume what risks when pitching?

Last week I signed four NDAs.
Four!
NDA stands for non-disclosure agreement. A legal document given to someone receiving confidential information. By signing, the person pledges not to share the information for a certain time. If they do, they may be in breach of contract and face legal action.
Companies use NDAs to protect trade secrets and confidential internal information from employees and contractors. Appropriate. If you manage a huge, successful firm, you don't want your employees selling their information to your competitors. To be true, business NDAs don't always prevent corporate espionage, but they usually make employees and contractors think twice before sharing.
I understand employee and contractor NDAs, but I wasn't asked to sign one. I counsel entrepreneurs, thus the NDAs I signed last week were from startups that wanted my feedback on their concepts.
I’m not a startup investor. I give startup guidance online. Despite that, four entrepreneurs thought their company ideas were so important they wanted me to sign a generically written legal form they probably acquired from a shady, spam-filled legal templates website before we could chat.
False. One company tried to get me to sign their NDA a few days after our conversation. I gently rejected, but their tenacity encouraged me. I considered sending retroactive NDAs to everyone I've ever talked to about one of my startups in case they establish a successful company based on something I said.
Two of the other three NDAs were from nearly identical companies. Good thing I didn't sign an NDA for the first one, else they may have sued me for talking to the second one as though I control the firms people pitch me.
I wasn't talking to the fourth NDA company. Instead, I received an unsolicited email from someone who wanted comments on their fundraising pitch deck but required me to sign an NDA before sending it.
That's right, before I could read a random Internet stranger's unsolicited pitch deck, I had to sign his NDA, potentially limiting my ability to discuss what was in it.
You should understand. Advisors, mentors, investors, etc. talk to hundreds of businesses each year. They cannot manage all the companies they deal with, thus they cannot risk legal trouble by talking to someone. Well, if I signed NDAs for all the startups I spoke with, half of the 300+ articles I've written on Medium over the past several years could get me sued into the next century because I've undoubtedly addressed topics in my articles that I discussed with them.
The four NDAs I received last week are part of a recent trend of entrepreneurs sending out NDAs before meetings, despite the practical and legal issues. They act like asking someone to sign away their right to talk about all they see and hear in a day is as straightforward as asking for a glass of water.
Given this inflow of NDAs, I wanted to briefly remind entrepreneurs reading this blog about the merits and cons of requesting investors (or others in the startup ecosystem) to sign your NDA.
Benefits of having investors sign your NDA include:
None. Zero. Nothing.
Disadvantages of requesting investor NDAs:
You'll come off as an amateur who has no idea what it takes to launch a successful firm.
Investors won't trust you with their money since you appear to be a complete amateur.
Printing NDAs will be a waste of paper because no genuine entrepreneur will ever sign one.
I apologize for missing any cons. Please leave your remarks.

Dung Claire Tran
3 years ago
Is the future of brand marketing with virtual influencers?
Digital influences that mimic humans are rising.
Lil Miquela has 3M Instagram followers, 3.6M TikTok followers, and 30K Twitter followers. She's been on the covers of Prada, Dior, and Calvin Klein magazines. Miquela released Not Mine in 2017 and launched Hard Feelings at Lollapazoolas this year. This isn't surprising, given the rise of influencer marketing.
This may be unexpected. Miquela's fake. Brud, a Los Angeles startup, produced her in 2016.
Lil Miquela is one of many rising virtual influencers in the new era of social media marketing. She acts like a real person and performs the same tasks as sports stars and models.
The emergence of online influencers
Before 2018, computer-generated characters were rare. Since the virtual human industry boomed, they've appeared in marketing efforts worldwide.
In 2020, the WHO partnered up with Atlanta-based virtual influencer Knox Frost (@knoxfrost) to gather contributions for the COVID-19 Solidarity Response Fund.
Lu do Magalu (@magazineluiza) has been the virtual spokeswoman for Magalu since 2009, using social media to promote reviews, product recommendations, unboxing videos, and brand updates. Magalu's 10-year profit was $552M.
In 2020, PUMA partnered with Southeast Asia's first virtual model, Maya (@mayaaa.gram). She joined Singaporean actor Tosh Zhang in the PUMA campaign. Local virtual influencer Ava Lee-Graham (@avagram.ai) partnered with retail firm BHG to promote their in-house labels.

In Japan, Imma (@imma.gram) is the face of Nike, PUMA, Dior, Salvatore Ferragamo SpA, and Valentino. Imma's bubblegum pink bob and ultra-fine fashion landed her on the cover of Grazia magazine.

Lotte Home Shopping created Lucy (@here.me.lucy) in September 2020. She made her TV debut as a Christmas show host in 2021. Since then, she has 100K Instagram followers and 13K TikTok followers.
Liu Yiexi gained 3 million fans in five days on Douyin, China's TikTok, in 2021. Her two-minute video went viral overnight. She's posted 6 videos and has 830 million Douyin followers.
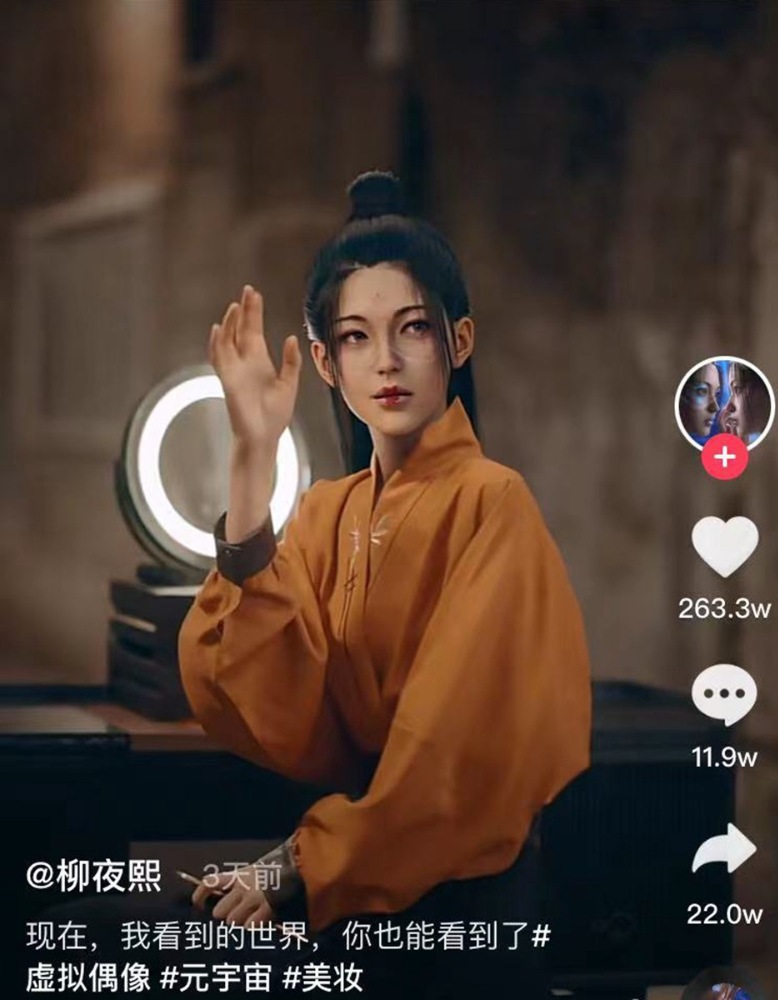
China's virtual human industry was worth $487 million in 2020, up 70% year over year, and is expected to reach $875.9 million in 2021.
Investors worldwide are interested. Immas creator Aww Inc. raised $1 million from Coral Capital in September 2020, according to Bloomberg. Superplastic Inc., the Vermont-based startup behind influencers Janky and Guggimon, raised $16 million by 2020. Craft Ventures, SV Angels, and Scooter Braun invested. Crunchbase shows the company has raised $47 million.
The industries they represent, including Augmented and Virtual reality, were worth $14.84 billion in 2020 and are projected to reach $454.73 billion by 2030, a CAGR of 40.7%, according to PR Newswire.
Advantages for brands
Forbes suggests brands embrace computer-generated influencers. Examples:
Unlimited creative opportunities: Because brands can personalize everything—from a person's look and activities to the style of their content—virtual influencers may be suited to a brand's needs and personalities.
100% brand control: Brand managers now have more influence over virtual influencers, so they no longer have to give up and rely on content creators to include brands into their storytelling and style. Virtual influencers can constantly produce social media content to promote a brand's identity and ideals because they are completely scandal-free.
Long-term cost savings: Because virtual influencers are made of pixels, they may be reused endlessly and never lose their beauty. Additionally, they can move anywhere around the world and even into space to fit a brand notion. They are also always available. Additionally, the expense of creating their content will not rise in step with their expanding fan base.
Introduction to the metaverse: Statista reports that 75% of American consumers between the ages of 18 and 25 follow at least one virtual influencer. As a result, marketers that support virtual celebrities may now interact with younger audiences that are more tech-savvy and accustomed to the digital world. Virtual influencers can be included into any digital space, including the metaverse, as they are entirely computer-generated 3D personas. Virtual influencers can provide brands with a smooth transition into this new digital universe to increase brand trust and develop emotional ties, in addition to the young generations' rapid adoption of the metaverse.
Better engagement than in-person influencers: A Hype Auditor study found that online influencers have roughly three times the engagement of their conventional counterparts. Virtual influencers should be used to boost brand engagement even though the data might not accurately reflect the entire sector.
Concerns about influencers created by computers
Virtual influencers could encourage excessive beauty standards in South Korea, which has a $10.7 billion plastic surgery industry.
A classic Korean beauty has a small face, huge eyes, and pale, immaculate skin. Virtual influencers like Lucy have these traits. According to Lee Eun-hee, a professor at Inha University's Department of Consumer Science, this could make national beauty standards more unrealistic, increasing demand for plastic surgery or cosmetic items.

Other parts of the world raise issues regarding selling items to consumers who don't recognize the models aren't human and the potential of cultural appropriation when generating influencers of other ethnicities, called digital blackface by some.
Meta, Facebook and Instagram's parent corporation, acknowledges this risk.
“Like any disruptive technology, synthetic media has the potential for both good and harm. Issues of representation, cultural appropriation and expressive liberty are already a growing concern,” the company stated in a blog post. “To help brands navigate the ethical quandaries of this emerging medium and avoid potential hazards, (Meta) is working with partners to develop an ethical framework to guide the use of (virtual influencers).”
Despite theoretical controversies, the industry will likely survive. Companies think virtual influencers are the next frontier in the digital world, which includes the metaverse, virtual reality, and digital currency.
In conclusion
Virtual influencers may garner millions of followers online and help marketers reach youthful audiences. According to a YouGov survey, the real impact of computer-generated influencers is yet unknown because people prefer genuine connections. Virtual characters can supplement brand marketing methods. When brands are metaverse-ready, the author predicts virtual influencer endorsement will continue to expand.