





More on Marketing

Jano le Roux
3 years ago
Here's What I Learned After 30 Days Analyzing Apple's Microcopy
Move people with tiny words.

Apple fanboy here.
Macs are awesome.
Their iPhones rock.
$19 cloths are great.
$999 stands are amazing.
I love Apple's microcopy even more.
It's like the marketing goddess bit into the Apple logo and blessed the world with microcopy.
I took on a 30-day micro-stalking mission.
Every time I caught myself wasting time on YouTube, I had to visit Apple’s website to learn the secrets of the marketing goddess herself.
We've learned. Golden apples are calling.
Cut the friction
Benefit-first, not commitment-first.
Brands lose customers through friction.
Most brands don't think like customers.
Brands want sales.
Brands want newsletter signups.
Here's their microcopy:
“Buy it now.”
“Sign up for our newsletter.”
Both are difficult. They ask for big commitments.
People are simple creatures. Want pleasure without commitment.
Apple nails this.
So, instead of highlighting the commitment, they highlight the benefit of the commitment.
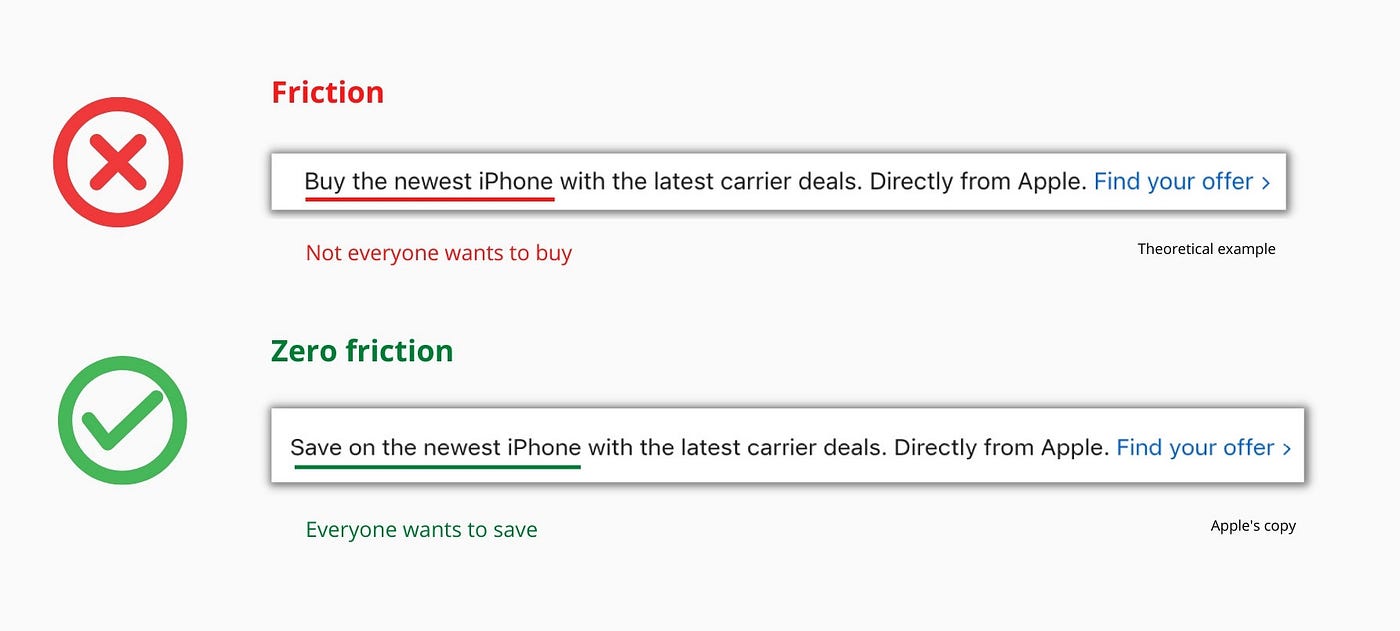
Saving on the latest iPhone sounds easier than buying it. Everyone saves, but not everyone buys.
A subtle change in framing reduces friction.
Apple eliminates customer objections to reduce friction.
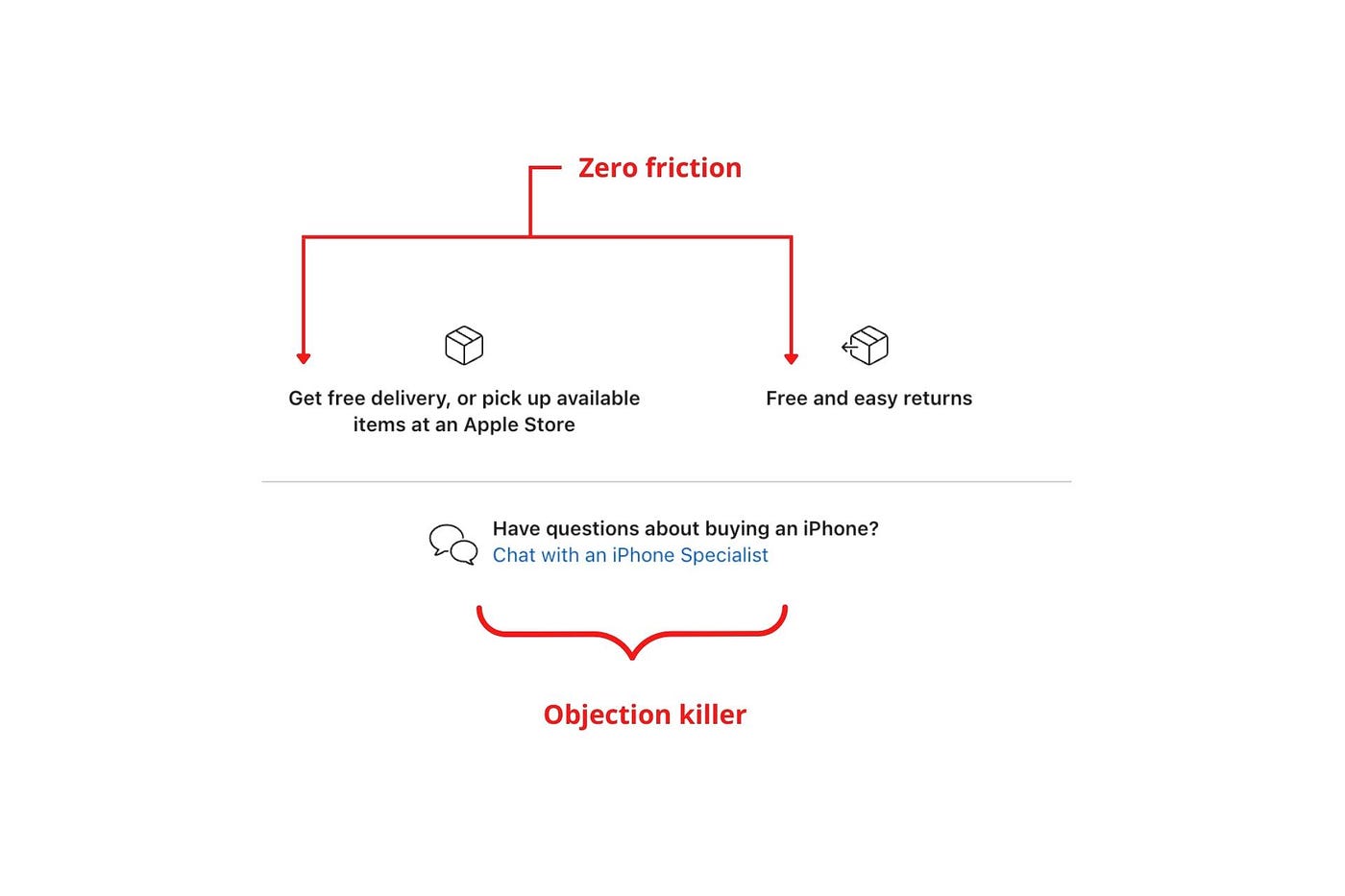
Less customer friction means simpler processes.
Apple's copy expertly reassures customers about shipping fees and not being home. Apple assures customers that returning faulty products is easy.
Apple knows that talking to a real person is the best way to reduce friction and improve their copy.
Always rhyme
Learn about fine rhyme.
Poets make things beautiful with rhyme.
Copywriters use rhyme to stand out.
Apple’s copywriters have mastered the art of corporate rhyme.
Two techniques are used.
1. Perfect rhyme
Here, rhymes are identical.

2. Imperfect rhyme
Here, rhyming sounds vary.

Apple prioritizes meaning over rhyme.
Apple never forces rhymes that don't fit.
It fits so well that the copy seems accidental.
Add alliteration
Alliteration always entertains.
Alliteration repeats initial sounds in nearby words.
Apple's copy uses alliteration like no other brand I've seen to create a rhyming effect or make the text more fun to read.
For example, in the sentence "Sam saw seven swans swimming," the initial "s" sound is repeated five times. This creates a pleasing rhythm.
Microcopy overuse is like pouring ketchup on a Michelin-star meal.
Alliteration creates a memorable phrase in copywriting. It's subtler than rhyme, and most people wouldn't notice; it simply resonates.

I love how Apple uses alliteration and contrast between "wonders" and "ease".
Assonance, or repeating vowels, isn't Apple's thing.
You ≠ Hero, Customer = Hero
Your brand shouldn't be the hero.
Because they'll be using your product or service, your customer should be the hero of your copywriting. With your help, they should feel like they can achieve their goals.
I love how Apple emphasizes what you can do with the machine in this microcopy.

It's divine how they position their tools as sidekicks to help below.

This one takes the cake:

Dialogue-style writing
Conversational copy engages.
Excellent copy Like sharing gum with a friend.
This helps build audience trust.

Apple does this by using natural connecting words like "so" and phrases like "But that's not all."
Snowclone-proof
The mother of all microcopy techniques.
A snowclone uses an existing phrase or sentence to create a new one. The new phrase or sentence uses the same structure but different words.
It’s usually a well know saying like:
To be or not to be.
This becomes a formula:
To _ or not to _.
Copywriters fill in the blanks with cause-related words. Example:
To click or not to click.

Apple turns "survival of the fittest" into "arrival of the fittest."
It's unexpected and surprises the reader.
So this was fun.
But my fun has just begun.
Microcopy is 21st-century poetry.
I came as an Apple fanboy.
I leave as an Apple fanatic.
Now I’m off to find an apple tree.
Cause you know how it goes.
(Apples, trees, etc.)
This post is a summary. Original post available here.

Guillaume Dumortier
3 years ago
Mastering the Art of Rhetoric: A Guide to Rhetorical Devices in Successful Headlines and Titles
Unleash the power of persuasion and captivate your audience with compelling headlines.
As the old adage goes, "You never get a second chance to make a first impression."
In the world of content creation and social ads, headlines and titles play a critical role in making that first impression.
A well-crafted headline can make the difference between an article being read or ignored, a video being clicked on or bypassed, or a product being purchased or passed over.
To make an impact with your headlines, mastering the art of rhetoric is essential. In this post, we'll explore various rhetorical devices and techniques that can help you create headlines that captivate your audience and drive engagement.
tl;dr : Headline Magician will help you craft the ultimate headline titles powered by rhetoric devices
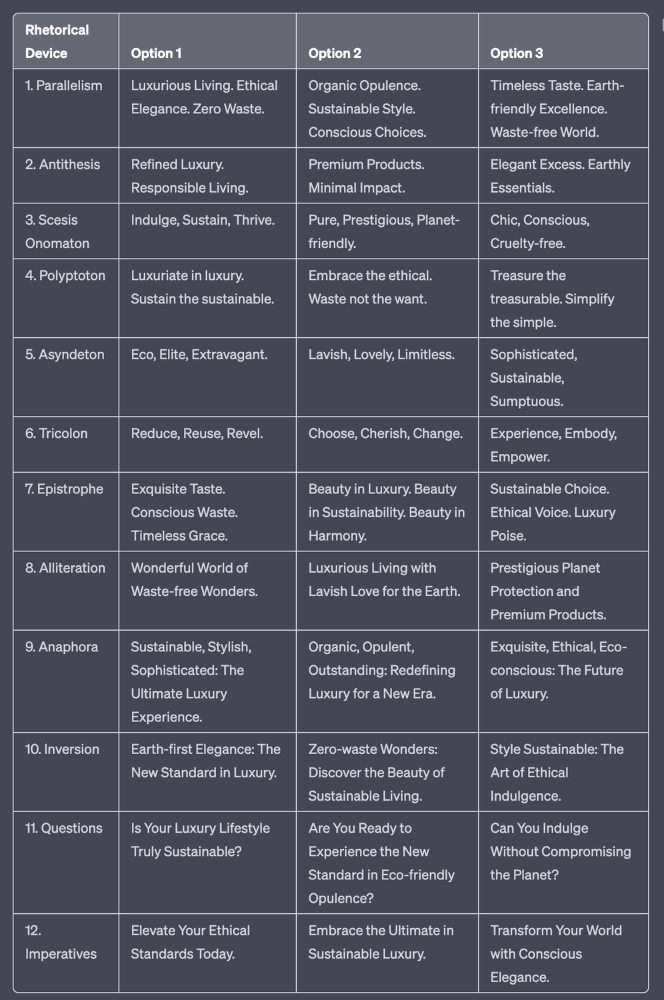
Example with a high-end luxury organic zero-waste skincare brand
✍️ The Power of Alliteration
Alliteration is the repetition of the same consonant sound at the beginning of words in close proximity. This rhetorical device lends itself well to headlines, as it creates a memorable, rhythmic quality that can catch a reader's attention.
By using alliteration, you can make your headlines more engaging and easier to remember.
Examples:
"Crafting Compelling Content: A Comprehensive Course"
"Mastering the Art of Memorable Marketing"
🔁 The Appeal of Anaphora
Anaphora is the repetition of a word or phrase at the beginning of successive clauses. This rhetorical device emphasizes a particular idea or theme, making it more memorable and persuasive.
In headlines, anaphora can be used to create a sense of unity and coherence, which can draw readers in and pique their interest.
Examples:
"Create, Curate, Captivate: Your Guide to Social Media Success"
"Innovation, Inspiration, and Insight: The Future of AI"
🔄 The Intrigue of Inversion
Inversion is a rhetorical device where the normal order of words is reversed, often to create an emphasis or achieve a specific effect.
In headlines, inversion can generate curiosity and surprise, compelling readers to explore further.
Examples:
"Beneath the Surface: A Deep Dive into Ocean Conservation"
"Beyond the Stars: The Quest for Extraterrestrial Life"
⚖️ The Persuasive Power of Parallelism
Parallelism is a rhetorical device that involves using similar grammatical structures or patterns to create a sense of balance and symmetry.
In headlines, parallelism can make your message more memorable and impactful, as it creates a pleasing rhythm and flow that can resonate with readers.
Examples:
"Eat Well, Live Well, Be Well: The Ultimate Guide to Wellness"
"Learn, Lead, and Launch: A Blueprint for Entrepreneurial Success"
⏭️ The Emphasis of Ellipsis
Ellipsis is the omission of words, typically indicated by three periods (...), which suggests that there is more to the story.
In headlines, ellipses can create a sense of mystery and intrigue, enticing readers to click and discover what lies behind the headline.
Examples:
"The Secret to Success... Revealed"
"Unlocking the Power of Your Mind... A Step-by-Step Guide"
🎭 The Drama of Hyperbole
Hyperbole is a rhetorical device that involves exaggeration for emphasis or effect.
In headlines, hyperbole can grab the reader's attention by making bold, provocative claims that stand out from the competition. Be cautious with hyperbole, however, as overuse or excessive exaggeration can damage your credibility.
Examples:
"The Ultimate Guide to Mastering Any Skill in Record Time"
"Discover the Revolutionary Technique That Will Transform Your Life"
❓The Curiosity of Questions
Posing questions in your headlines can be an effective way to pique the reader's curiosity and encourage engagement.
Questions compel the reader to seek answers, making them more likely to click on your content. Additionally, questions can create a sense of connection between the content creator and the audience, fostering a sense of dialogue and discussion.
Examples:
"Are You Making These Common Mistakes in Your Marketing Strategy?"
"What's the Secret to Unlocking Your Creative Potential?"
💥 The Impact of Imperatives
Imperatives are commands or instructions that urge the reader to take action. By using imperatives in your headlines, you can create a sense of urgency and importance, making your content more compelling and actionable.
Examples:
"Master Your Time Management Skills Today"
"Transform Your Business with These Innovative Strategies"
💢 The Emotion of Exclamations
Exclamations are powerful rhetorical devices that can evoke strong emotions and convey a sense of excitement or urgency.
Including exclamations in your headlines can make them more attention-grabbing and shareable, increasing the chances of your content being read and circulated.
Examples:
"Unlock Your True Potential: Find Your Passion and Thrive!"
"Experience the Adventure of a Lifetime: Travel the World on a Budget!"
🎀 The Effectiveness of Euphemisms
Euphemisms are polite or indirect expressions used in place of harsher, more direct language.
In headlines, euphemisms can make your message more appealing and relatable, helping to soften potentially controversial or sensitive topics.
Examples:
"Navigating the Challenges of Modern Parenting"
"Redefining Success in a Fast-Paced World"
⚡Antithesis: The Power of Opposites
Antithesis involves placing two opposite words side-by-side, emphasizing their contrasts. This device can create a sense of tension and intrigue in headlines.
Examples:
"Once a day. Every day"
"Soft on skin. Kill germs"
"Mega power. Mini size."
To utilize antithesis, identify two opposing concepts related to your content and present them in a balanced manner.
🎨 Scesis Onomaton: The Art of Verbless Copy
Scesis onomaton is a rhetorical device that involves writing verbless copy, which quickens the pace and adds emphasis.
Example:
"7 days. 7 dollars. Full access."
To use scesis onomaton, remove verbs and focus on the essential elements of your headline.
🌟 Polyptoton: The Charm of Shared Roots
Polyptoton is the repeated use of words that share the same root, bewitching words into memorable phrases.
Examples:
"Real bread isn't made in factories. It's baked in bakeries"
"Lose your knack for losing things."
To employ polyptoton, identify words with shared roots that are relevant to your content.
✨ Asyndeton: The Elegance of Omission
Asyndeton involves the intentional omission of conjunctions, adding crispness, conviction, and elegance to your headlines.
Examples:
"You, Me, Sushi?"
"All the latte art, none of the environmental impact."
To use asyndeton, eliminate conjunctions and focus on the core message of your headline.
🔮 Tricolon: The Magic of Threes
Tricolon is a rhetorical device that uses the power of three, creating memorable and impactful headlines.
Examples:
"Show it, say it, send it"
"Eat Well, Live Well, Be Well."
To use tricolon, craft a headline with three key elements that emphasize your content's main message.
🔔 Epistrophe: The Chime of Repetition
Epistrophe involves the repetition of words or phrases at the end of successive clauses, adding a chime to your headlines.
Examples:
"Catch it. Bin it. Kill it."
"Joint friendly. Climate friendly. Family friendly."
To employ epistrophe, repeat a key phrase or word at the end of each clause.

Tim Denning
3 years ago
I Posted Six Times a Day for 210 Days on Twitter. Here's What Happened.
I'd spend hours composing articles only to find out they were useless. Twitter solved the problem.

Twitter is wrinkled, say critics.
Nope. Writing is different. It won't make sense until you write there.
Twitter is resurgent. People are reading again. 15-second TikToks overloaded our senses.
After nuking my 20,000-follower Twitter account and starting again, I wrote every day for 210 days.
I'll explain.
I came across the strange world of microblogging.
Traditional web writing is filler-heavy.
On Twitter, you must be brief. I played Wordle.
Twitter Threads are the most popular writing format. Like a blog post. It reminds me of the famous broetry posts on LinkedIn a few years ago.

Threads combine tweets into an article.
Sharp, concise sentences
No regard for grammar
As important as the information is how the text looks.
Twitter Threads are like Michael Angelo's David monument. He chipped away at an enormous piece of marble until a man with a big willy appeared.
That's Twitter Threads.
I tried to remove unnecessary layers from several of my Wordpress blog posts. Then I realized something.
Tweeting from scratch is easier and more entertaining. It's quicker and makes you think more concisely.
Superpower: saying much with little words. My long-form writing has improved. My article sentences resemble tweets.
You never know what will happen.
Twitter's subcultures are odd. Best-performing tweets are strange.
Unusual trend: working alone and without telling anyone. It's a rebellion against Instagram influencers who share their every moment.
Early on, random thoughts worked:
My friend’s wife is Ukrainian. Her family are trapped in the warzone. He is devastated. And here I was complaining about my broken garage door. War puts everything in perspective. Today is a day to be grateful for peace.
Documenting what's happening triggers writing. It's not about viral tweets. Helping others matters.
There are numerous anonymous users.
Twitter uses pseudonyms.
You don't matter. On sites like LinkedIn, you must use your real name. Welcome to the Cyberpunk metaverse of Twitter :)
One daily piece of writing is a powerful habit.
Habits build creator careers. Read that again.
Twitter is an easy habit to pick up. If you can't tweet in one sentence, something's wrong. Easy-peasy-japanese.
Not what I tweeted, but my constancy, made the difference.
Daily writing is challenging, especially if your supervisor is on your back. Twitter encourages writing.
Tweets evolved as the foundation of all other material.
During my experiment, I enjoyed Twitter's speed.
Tweets get immediate responses, comments, and feedback. My popular tweets become newspaper headlines. I've also written essays from tweet discussions.
Sometimes the tweet and article were clear. Twitter sometimes helped me overcome writer's block.
I used to spend hours composing big things that had little real-world use.
Twitter helped me. No guessing. Data guides my coverage and validates concepts.
Test ideas on Twitter.
It took some time for my email list to grow.
Subscribers are a writer's lifeblood.
Without them, you're broke and homeless when Mark Zuckerberg tweaks the algorithms for ad dollars. Twitter has three ways to obtain email subscribers:
1. Add a link to your bio.
Twitter allows bio links (LinkedIn now does too). My eBook's landing page is linked. I collect emails there.
2. Start an online newsletter.
Twitter bought newsletter app Revue. They promote what they own.
I just established up a Revue email newsletter. I imported them weekly into my ConvertKit email list.
3. Create Twitter threads and include a link to your email list in the final tweet.
Write Twitter Threads and link the last tweet to your email list (example below).
Initial email subscribers were modest.
Numbers are growing. Twitter provides 25% of my new email subscribers. Some days, 50 people join.
Without them, my writing career is over. I'd be back at a 9-5 job begging for time off to spend with my newborn daughter. Nope.
Collect email addresses or die trying.
As insurance against unsubscribes and Zucks, use a second email list or Discord community.
What I still need to do
Twitter's fun. I'm wiser. I need to enable auto-replies and auto-DMs (direct messages).
This adds another way to attract subscribers. I schedule tweets with Tweet Hunter.
It’s best to go slow. People assume you're an internet marketer if you spam them with click requests.
A human internet marketer is preferable to a robot. My opinion.
210 days on Twitter taught me that. I plan to use the platform until I'm a grandfather unless Elon ruins it.
You might also like

CNET
4 years ago
How a $300K Bored Ape Yacht Club NFT was accidentally sold for $3K
The Bored Ape Yacht Club is one of the most prestigious NFT collections in the world. A collection of 10,000 NFTs, each depicting an ape with different traits and visual attributes, Jimmy Fallon, Steph Curry and Post Malone are among their star-studded owners. Right now the price of entry is 52 ether, or $210,000.
Which is why it's so painful to see that someone accidentally sold their Bored Ape NFT for $3,066.
Unusual trades are often a sign of funny business, as in the case of the person who spent $530 million to buy an NFT from themselves. In Saturday's case, the cause was a simple, devastating "fat-finger error." That's when people make a trade online for the wrong thing, or for the wrong amount. Here the owner, real name Max or username maxnaut, meant to list his Bored Ape for 75 ether, or around $300,000. Instead he accidentally listed it for 0.75. One hundredth the intended price.
It was bought instantaneously. The buyer paid an extra $34,000 to speed up the transaction, ensuring no one could snap it up before them. The Bored Ape was then promptly listed for $248,000. The transaction appears to have been done by a bot, which can be coded to immediately buy NFTs listed below a certain price on behalf of their owners in order to take advantage of these exact situations.
"How'd it happen? A lapse of concentration I guess," Max told me. "I list a lot of items every day and just wasn't paying attention properly. I instantly saw the error as my finger clicked the mouse but a bot sent a transaction with over 8 eth [$34,000] of gas fees so it was instantly sniped before I could click cancel, and just like that, $250k was gone."
"And here within the beauty of the Blockchain you can see that it is both honest and unforgiving," he added.
Fat finger trades happen sporadically in traditional finance -- like the Japanese trader who almost bought 57% of Toyota's stock in 2014 -- but most financial institutions will stop those transactions if alerted quickly enough. Since cryptocurrency and NFTs are designed to be decentralized, you essentially have to rely on the goodwill of the buyer to reverse the transaction.
Fat finger errors in cryptocurrency trades have made many a headline over the past few years. Back in 2019, the company behind Tether, a cryptocurrency pegged to the US dollar, nearly doubled its own coin supply when it accidentally created $5 billion-worth of new coins. In March, BlockFi meant to send 700 Gemini Dollars to a set of customers, worth roughly $1 each, but mistakenly sent out millions of dollars worth of bitcoin instead. Last month a company erroneously paid a $24 million fee on a $100,000 transaction.
Similar incidents are increasingly being seen in NFTs, now that many collections have accumulated in market value over the past year. Last month someone tried selling a CryptoPunk NFT for $19 million, but accidentally listed it for $19,000 instead. Back in August, someone fat finger listed their Bored Ape for $26,000, an error that someone else immediately capitalized on. The original owner offered $50,000 to the buyer to return the Bored Ape -- but instead the opportunistic buyer sold it for the then-market price of $150,000.
"The industry is so new, bad things are going to happen whether it's your fault or the tech," Max said. "Once you no longer have control of the outcome, forget and move on."
The Bored Ape Yacht Club launched back in April 2021, with 10,000 NFTs being sold for 0.08 ether each -- about $190 at the time. While NFTs are often associated with individual digital art pieces, collections like the Bored Ape Yacht Club, which allow owners to flaunt their NFTs by using them as profile pictures on social media, are becoming increasingly prevalent. The Bored Ape Yacht Club has since become the second biggest NFT collection in the world, second only to CryptoPunks, which launched in 2017 and is considered the "original" NFT collection.

Ajay Shrestha
3 years ago
Bitcoin's technical innovation: addressing the issue of the Byzantine generals
The 2008 Bitcoin white paper solves the classic computer science consensus problem.
Issue Statement
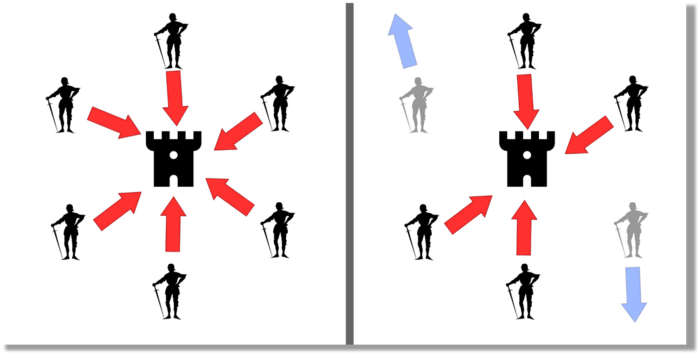
The Byzantine Generals Problem (BGP) is called after an allegory in which several generals must collaborate and attack a city at the same time to win (figure 1-left). Any general who retreats at the last minute loses the fight (figure 1-right). Thus, precise messengers and no rogue generals are essential. This is difficult without a trusted central authority.
In their 1982 publication, Leslie Lamport, Robert Shostak, and Marshall Please termed this topic the Byzantine Generals Problem to simplify distributed computer systems.
Consensus in a distributed computer network is the issue. Reaching a consensus on which systems work (and stay in the network) and which don't makes maintaining a network tough (i.e., needs to be removed from network). Challenges include unreliable communication routes between systems and mis-reporting systems.
Solving BGP can let us construct machine learning solutions without single points of failure or trusted central entities. One server hosts model parameters while numerous workers train the model. This study describes fault-tolerant Distributed Byzantine Machine Learning.
Bitcoin invented a mechanism for a distributed network of nodes to agree on which transactions should go into the distributed ledger (blockchain) without a trusted central body. It solved BGP implementation. Satoshi Nakamoto, the pseudonymous bitcoin creator, solved the challenge by cleverly combining cryptography and consensus mechanisms.
Disclaimer
This is not financial advice. It discusses a unique computer science solution.
Bitcoin
Bitcoin's white paper begins:
“A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution.” Source: https://www.ussc.gov/sites/default/files/pdf/training/annual-national-training-seminar/2018/Emerging_Tech_Bitcoin_Crypto.pdf
Bitcoin's main parts:
The open-source and versioned bitcoin software that governs how nodes, miners, and the bitcoin token operate.
The native kind of token, known as a bitcoin token, may be created by mining (up to 21 million can be created), and it can be transferred between wallet addresses in the bitcoin network.
Distributed Ledger, which contains exact copies of the database (or "blockchain") containing each transaction since the first one in January 2009.
distributed network of nodes (computers) running the distributed ledger replica together with the bitcoin software. They broadcast the transactions to other peer nodes after validating and accepting them.
Proof of work (PoW) is a cryptographic requirement that must be met in order for a miner to be granted permission to add a new block of transactions to the blockchain of the cryptocurrency bitcoin. It takes the form of a valid hash digest. In order to produce new blocks on average every 10 minutes, Bitcoin features a built-in difficulty adjustment function that modifies the valid hash requirement (length of nonce). PoW requires a lot of energy since it must continually generate new hashes at random until it satisfies the criteria.
The competing parties known as miners carry out continuous computing processing to address recurrent cryptography issues. Transaction fees and some freshly minted (mined) bitcoin are the rewards they receive. The amount of hashes produced each second—or hash rate—is a measure of mining capacity.
Cryptography, decentralization, and the proof-of-work consensus method are Bitcoin's most unique features.
Bitcoin uses encryption
Bitcoin employs this established cryptography.
Hashing
digital signatures based on asymmetric encryption
Hashing (SHA-256) (SHA-256)
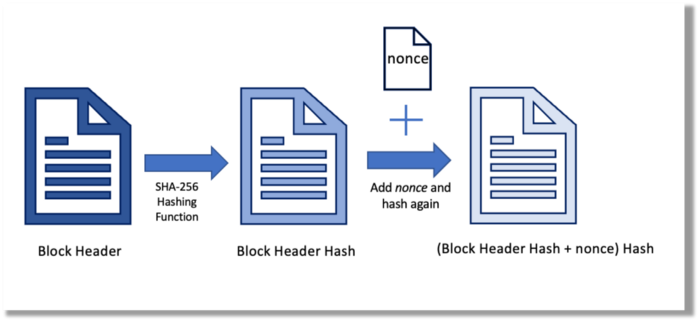
Hashing converts unique plaintext data into a digest. Creating the plaintext from the digest is impossible. Bitcoin miners generate new hashes using SHA-256 to win block rewards.
A new hash is created from the current block header and a variable value called nonce. To achieve the required hash, mining involves altering the nonce and re-hashing.
The block header contains the previous block hash and a Merkle root, which contains hashes of all transactions in the block. Thus, a chain of blocks with increasing hashes links back to the first block. Hashing protects new transactions and makes the bitcoin blockchain immutable. After a transaction block is mined, it becomes hard to fabricate even a little entry.
Asymmetric Cryptography Digital Signatures
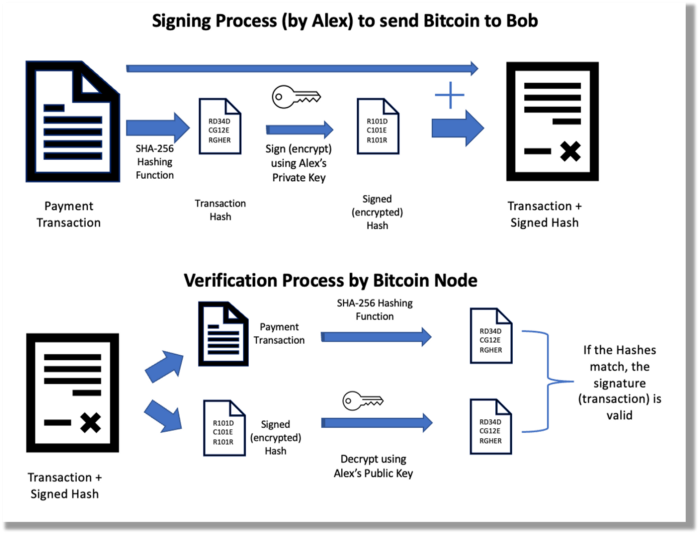
Asymmetric cryptography (public-key encryption) requires each side to have a secret and public key. Public keys (wallet addresses) can be shared with the transaction party, but private keys should not. A message (e.g., bitcoin payment record) can only be signed by the owner (sender) with the private key, but any node or anybody with access to the public key (visible in the blockchain) can verify it. Alex will submit a digitally signed transaction with a desired amount of bitcoin addressed to Bob's wallet to a node to send bitcoin to Bob. Alex alone has the secret keys to authorize that amount. Alex's blockchain public key allows anyone to verify the transaction.
Solution
Now, apply bitcoin to BGP. BGP generals resemble bitcoin nodes. The generals' consensus is like bitcoin nodes' blockchain block selection. Bitcoin software on all nodes can:
Check transactions (i.e., validate digital signatures)
2. Accept and propagate just the first miner to receive the valid hash and verify it accomplished the task. The only way to guess the proper hash is to brute force it by repeatedly producing one with the fixed/current block header and a fresh nonce value.
Thus, PoW and a dispersed network of nodes that accept blocks from miners that solve the unfalsifiable cryptographic challenge solve consensus.
Suppose:
Unreliable nodes
Unreliable miners
Bitcoin accepts the longest chain if rogue nodes cause divergence in accepted blocks. Thus, rogue nodes must outnumber honest nodes in accepting/forming the longer chain for invalid transactions to reach the blockchain. As of November 2022, 7000 coordinated rogue nodes are needed to takeover the bitcoin network.
Dishonest miners could also try to insert blocks with falsified transactions (double spend, reverse, censor, etc.) into the chain. This requires over 50% (51% attack) of miners (total computational power) to outguess the hash and attack the network. Mining hash rate exceeds 200 million (source). Rewards and transaction fees encourage miners to cooperate rather than attack. Quantum computers may become a threat.
Visit my Quantum Computing post.
Quantum computers—what are they? Quantum computers will have a big influence. towardsdatascience.com
Nodes have more power than miners since they can validate transactions and reject fake blocks. Thus, the network is secure if honest nodes are the majority.
Summary
Table 1 compares three Byzantine Generals Problem implementations.
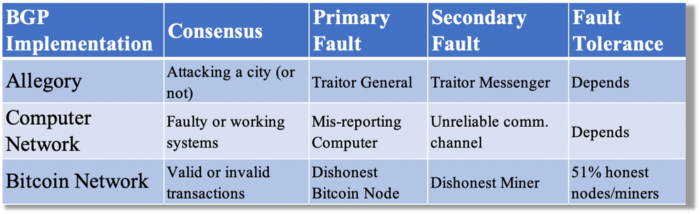
Bitcoin white paper and implementation solved the consensus challenge of distributed systems without central governance. It solved the illusive Byzantine Generals Problem.
Resources
Resources
Source-code for Bitcoin Core Software — https://github.com/bitcoin/bitcoin
Bitcoin white paper — https://bitcoin.org/bitcoin.pdf
https://www.microsoft.com/en-us/research/publication/byzantine-generals-problem/
https://www.microsoft.com/en-us/research/uploads/prod/2016/12/The-Byzantine-Generals-Problem.pdf
Genuinely Distributed Byzantine Machine Learning, El-Mahdi El-Mhamdi et al., 2020. ACM, New York, NY, https://doi.org/10.1145/3382734.3405695

Khoi Ho
3 years ago
After working at seven startups, here are the early-stage characteristics that contributed to profitability, unicorn status or successful acquisition.

I've worked in a People role at seven early-stage firms for over 15 years (I enjoy chasing a dream!). Few of the seven achieved profitability, including unicorn status or acquisition.
Did early-stage startups share anything? Was there a difference between winners and losers? YES.
I support founders and entrepreneurs building financially sustainable enterprises with a compelling cause. This isn't something everyone would do. A company's success demands more than guts. Founders drive startup success.
Six Qualities of Successful Startups
Successful startup founders either innately grasped the correlation between strong team engagement and a well-executed business model, or they knew how to ask and listen to others (executive coaches, other company leaders, the team itself) to learn about it.
Successful startups:
1. Co-founders agreed and got along personally.
Multi-founder startups are common. When co-founders agree on strategic decisions and are buddies, there's less friction and politics at work.
As a co-founder, ask your team if you're aligned. They'll explain.
I've seen C-level leaders harbor personal resentments over disagreements. A co-departure founder's caused volatile leadership and work disruptions that the team struggled to manage during and after.
2. Team stayed.
Successful startups have low turnover. Nobody is leaving. There may be a termination for performance, but other team members will have observed the issues and agreed with the decision.
You don't want organizational turnover of 30%+, with leaders citing performance issues but the team not believing them. This breeds suspicion.
Something is wrong if many employees leave voluntarily or involuntarily. You may hear about lack of empowerment, support, or toxic leadership in exit interviews and from the existing team. Intellectual capital loss and resource instability harm success.
3. Team momentum.
A successful startup's team is excited about its progress. Consistently achieving goals and having trackable performance metrics. Some describe this period of productivity as magical, with great talents joining the team and the right people in the right places. Increasing momentum.
I've also seen short-sighted decisions where only some departments, like sales and engineering, had goals. Lack of a unified goals system created silos and miscommunication. Some employees felt apathetic because they didn't know how they contributed to team goals.
4. Employees advanced in their careers.
Even if you haven't created career pathing or professional development programs, early-stage employees will grow and move into next-level roles. If you hire more experienced talent and leaders, expect them to mentor existing team members. Growing companies need good performers.
New talent shouldn't replace and discard existing talent. This creates animosity and makes existing employees feel unappreciated for their early contributions to the company.
5. The company lived its values.
Culture and identity are built on lived values. A company's values affect hiring, performance management, rewards, and other processes. Identify, practice, and believe in company values. Starting with team values instead of management or consultants helps achieve this. When a company's words and actions match, it builds trust.
When company values are beautifully displayed on a wall but few employees understand them, the opposite is true. If an employee can't name the company values, they're useless.
6. Communication was clear.
When necessary information is shared with the team, they feel included, trusted, and like owners. Transparency means employees have the needed information to do their jobs. Disclosure builds trust. The founders answer employees' questions honestly.
Information accessibility decreases office politics. Without transparency, even basic information is guarded and many decisions are made in secret. I've seen founders who don't share financial, board meeting, or compensation and equity information. The founders' lack of trust in the team wasn't surprising, so it was reciprocated.
The Choices
Finally. All six of the above traits (leadership alignment, minimal turnover, momentum, professional advancement, values, and transparency) were high in the profitable startups I've worked at, including unicorn status or acquisition.
I've seen these as the most common and constant signals of startup success or failure.
These characteristics are the product of founders' choices. These decisions lead to increased team engagement and business execution.
Here's something to consider for startup employees and want-to-bes. 90% of startups fail, despite the allure of building something new and gaining ownership. With the emotional and time investment in startup formation, look for startups with these traits to reduce your risk.
Both you and the startup will thrive in these workplaces.