


More on Entrepreneurship/Creators

Esteban
3 years ago
The Berkus Startup Valuation Method: What Is It?
What Is That?
Berkus is a pre-revenue valuation method based exclusively on qualitative criteria, like Scorecard.
Few firms match their financial estimates, especially in the early stages, so valuation methodologies like the Berkus method are a good way to establish a valuation when the economic measures are not reliable.
How does it work?
This technique evaluates five key success factors.
Fundamental principle
Technology
Execution
Strategic alliances in its primary market
Production, followed by sales
The Berkus technique values the business idea and four success factors. As seen in the matrix below, each of these dimensions poses a danger to the startup's success.
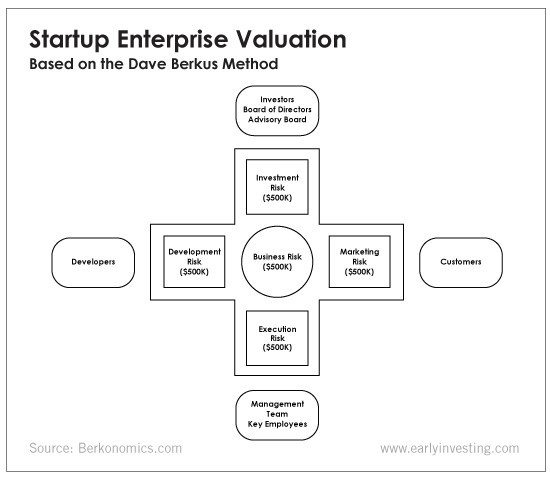
It assigns $0-$500,000 to each of these beginning regions. This approach enables a maximum $2.5M pre-money valuation.
This approach relies significantly on geography and uses the US as a baseline, as it differs in every country in Europe.
A set of standards for analyzing each dimension individually
Fundamental principle (or strength of the idea)
Ideas are worthless; execution matters. Most of us can relate to seeing a new business open in our area or a startup get funded and thinking, "I had this concept years ago!" Someone did it.
The concept remains. To assess the idea's viability, we must consider several criteria.
The concept's exclusivity It is necessary to protect a product or service's concept using patents and copyrights. Additionally, it must be capable of generating large profits.
Planned growth and growth that goes in a specific direction have a lot of potential, therefore incorporating them into a business is really advantageous.
The ability of a concept to grow A venture's ability to generate scalable revenue is a key factor in its emergence and continuation. A startup needs a scalable idea in order to compete successfully in the market.
The attraction of a business idea to a broad spectrum of people is significantly influenced by the current socio-political climate. Thus, the requirement for the assumption of conformity.
Concept Validation Ideas must go through rigorous testing with a variety of audiences in order to lower risk during the implementation phase.
Technology (Prototype)
This aspect reduces startup's technological risk. How good is the startup prototype when facing cyber threats, GDPR compliance (in Europe), tech stack replication difficulty, etc.?
Execution
Check the management team's efficacy. A potential angel investor must verify the founders' experience and track record with previous ventures. Good leadership is needed to chart a ship's course.
Strategic alliances in its primary market
Existing and new relationships will play a vital role in the development of both B2B and B2C startups. What are the startup's synergies? potential ones?
Production, followed by sales (product rollout)
Startup success depends on its manufacturing and product rollout. It depends on the overall addressable market, the startup's ability to market and sell their product, and their capacity to provide consistent, high-quality support.
Example
We're now founders of EyeCaramba, a machine vision-assisted streaming platform. My imagination always goes to poor puns when naming a startup.
Since we're first-time founders and the Berkus technique depends exclusively on qualitative methods and the evaluator's skill, we ask our angel-investor acquaintance for a pre-money appraisal of EyeCaramba.
Our friend offers us the following table:
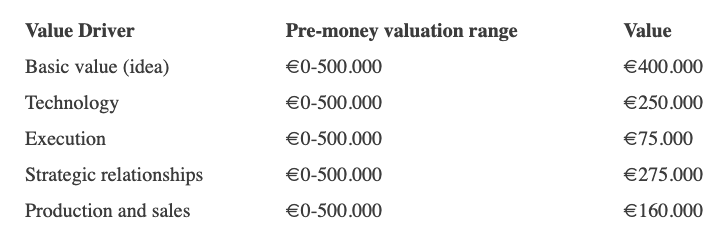
Because we're first-time founders, our pal lowered our Execution score. He knows the idea's value and that the gaming industry is red-hot, with worse startup ideas getting funded, therefore he gave the Basic value the highest value (idea).
EyeCaramba's pre-money valuation is $400,000 + $250,000 + $75,000 + $275,000 + $164,000 (1.16M). Good.
References
https://medium.com/humble-ventures/how-angel-investors-value-pre-revenue-startups-part-iii-8271405f0774#:~:text=pre%2Drevenue%20startups.-,Berkus%20Method,potential%20of%20the%20idea%20itself.%E2%80%9D
https://eqvista.com/berkus-valuation-method-for-startups/
https://www.venionaire.com/early-stage-startup-valuation-part-2-the-berkus-method/

Bradley Vangelder
3 years ago
How we started and then quickly sold our startup
From a simple landing where we tested our MVP to a platform that distributes 20,000 codes per month, we learned a lot.

Starting point
Kwotet was my first startup. Everyone might post book quotes online.
I wanted a change.
Kwotet lacked attention, thus I felt stuck. After experiencing the trials of starting Kwotet, I thought of developing a waitlist service, but I required a strong co-founder.
I knew Dries from school, but we weren't close. He was an entrepreneurial programmer who worked a lot outside school. I needed this.
We brainstormed throughout school hours. We developed features to put us first. We worked until 3 am to launch this product.
Putting in the hours is KEY when building a startup

The instant that we lost our spark
In Belgium, college seniors do their internship in their last semester.
As we both made the decision to pick a quite challenging company, little time was left for Lancero.
Eventually, we lost interest. We lost the spark…
The only logical choice was to find someone with the same spark we started with to acquire Lancero.
And we did @ MicroAcquire.
Sell before your product dies. Make sure to profit from all the gains.
What did we do following the sale?
Not far from selling Lancero I lost my dad. I was about to start a new company. It was focused on positivity. I got none left at the time.
We still didn’t let go of the dream of becoming full-time entrepreneurs. As Dries launched the amazing company Plunk, and I’m still in the discovering stages of my next journey!

Dream!
You’re an entrepreneur if:
You're imaginative.
You enjoy disassembling and reassembling things.
You're adept at making new friends.
YOU HAVE DREAMS.
You don’t need to believe me if I tell you “everything is possible”… I wouldn't believe it myself if anyone told me this 2 years ago.
Until I started doing, living my dreams.

Mangu Solutions
3 years ago
Growing a New App to $15K/mo in 6 Months [SaaS Case Study]
Discover How We Used Facebook Ads to Grow a New Mobile App from $0 to $15K MRR in Just 6 Months and Our Strategy to Hit $100K a Month.
Our client introduced a mobile app for Poshmark resellers in December and wanted as many to experience it and subscribe to the monthly plan.
An Error We Committed
We initiated a Facebook ad campaign with a "awareness" goal, not "installs." This sent them to a landing page that linked to the iPhone App Store and Android Play Store. Smart, right?
We got some installs, but we couldn't tell how many came from the ad versus organic/other channels because the objective we chose only reported landing page clicks, not app installs.
We didn't know which interest groups/audiences had the best cost per install (CPI) to optimize and scale our budget.
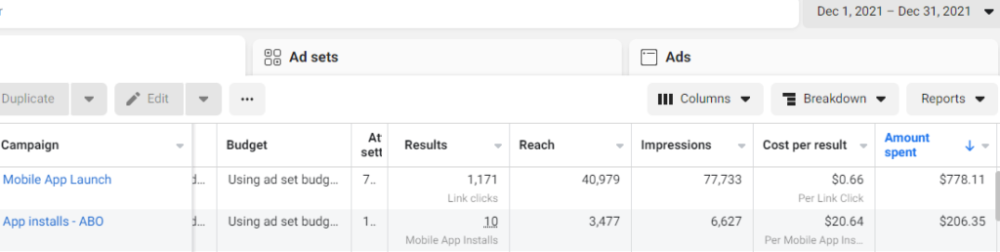
After spending $700 without adequate data (installs and trials report), we stopped the campaign and worked with our client's app developer to set up app events tracking.
This allowed us to create an installs campaign and track installs, trials, and purchases (in some cases).
Finding a Successful Audience
Once we knew what ad sets brought in what installs at what cost, we began optimizing and testing other interest groups and audiences, growing the profitable low CPI ones and eliminating the high CPI ones.
We did all our audience testing using an ABO campaign (Ad Set Budget Optimization), spending $10 to $30 on each ad set for three days and optimizing afterward. All ad sets under $30 were moved to a CBO campaign (Campaign Budget Optimization).
We let Facebook's AI decide how much to spend on each ad set, usually the one most likely to convert at the lowest cost.
If the CBO campaign maintains a nice CPI, we keep increasing the budget by $50 every few days or duplicating it sometimes in order to double the budget. This is how we've scaled to $400/day profitably.

Finding Successful Creatives
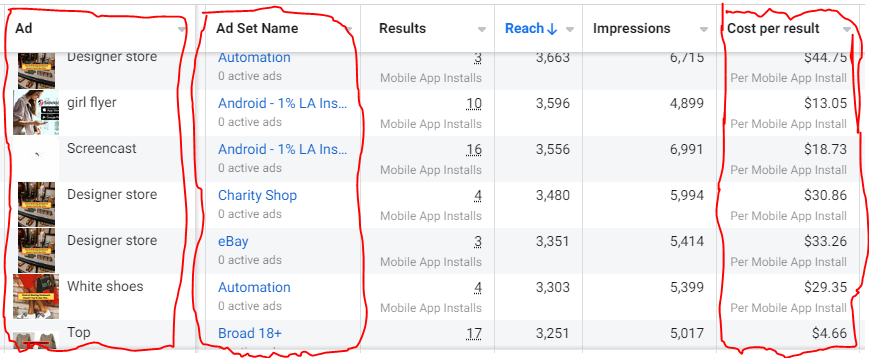
Per campaign, we tested 2-6 images/videos. Same ad copy and CTA. There was no clear winner because some images did better with some interest groups.
The image above with mail packages, for example, got us a cheap CPI of $9.71 from our Goodwill Stores interest group but, a high $48 CPI from our lookalike audience. Once we had statistically significant data, we turned off the high-cost ad.
New marketers who are just discovering A/B testing may assume it's black and white — winner and loser. However, Facebook ads' machine learning and reporting has gotten so sophisticated that it's hard to call a creative a flat-out loser, but rather a 'bad fit' for some audiences, and perfect for others.
You can see how each creative performs across age groups and optimize.
How Many Installs Did It Take Us to Earn $15K Per Month?
Six months after paying $25K, we got 1,940 app installs, 681 free trials, and 522 $30 monthly subscriptions. 522 * $30 gives us $15,660 in monthly recurring revenue (MRR).
Next, what? $100K per month
The conversation above is with the app's owner. We got on a 30-minute call where I shared how I plan to get the app to be making $100K a month like I’ve done for other businesses.
Reverse Engineering $100K
Formula:
For $100K/month, we need 3,334 people to pay $30/month. 522 people pay that. We need 2,812 more paid users.
522 paid users from 1,940 installs is a 27% conversion rate. To hit $100K/month, we need 10,415 more installs. Assuming...
With a $400 daily ad spend, we average 40 installs per day. This means that if everything stays the same, it would take us 260 days (around 9 months) to get to $100K a month (MRR).
Conclusion
You must market your goods to reach your income objective (without waiting forever). Paid ads is the way to go if you hate knocking on doors or irritating friends and family (who aren’t scalable anyways).
You must also test and optimize different angles, audiences, interest groups, and creatives.
You might also like

Mike Tarullo
3 years ago
Even In a Crazy Market, Hire the Best People: The "First Ten" Rules
Hiring is difficult, but you shouldn't compromise on team members. Or it may suggest you need to look beyond years in a similar role/function.
Every hire should be someone we'd want as one of our first ten employees.
If you hire such people, your team will adapt, initiate, and problem-solve, and your company will grow. You'll stay nimble even as you scale, and you'll learn from your colleagues.
If you only hire for a specific role or someone who can execute the job, you'll become a cluster of optimizers, and talent will depart for a more fascinating company. A startup is continually changing, therefore you want individuals that embrace it.
As a leader, establishing ideal conditions for talent and having a real ideology should be high on your agenda. You can't eliminate attrition, nor would you want to, but you can hire people who will become your company's leaders.
In my last four jobs I was employee 2, 5, 3, and 5. So while this is all a bit self serving, you’re the one reading my writing — and I have some experience with who works out in the first ten!
First, we'll examine what they do well (and why they're beneficial for startups), then what they don't, and how to hire them.
First 10 are:
Business partners: Because it's their company, they take care of whatever has to be done and have ideas about how to do it. You can rely on them to always put the success of the firm first because it is their top priority (company success is strongly connected with success for early workers). This approach will eventually take someone to leadership positions.
High Speed Learners: They process knowledge quickly and can reach 80%+ competency in a new subject matter rather quickly. A growing business that is successful tries new things frequently. We have all lost a lot of money and time on employees who follow the wrong playbook or who wait for someone else within the company to take care of them.
Autodidacts learn by trial and error, osmosis, networking with others, applying first principles, and reading voraciously (articles, newsletters, books, and even social media). Although teaching is wonderful, you won't have time.
Self-scaling: They figure out a means to deal with issues and avoid doing the grunt labor over the long haul, increasing their leverage. Great people don't keep doing the same thing forever; as they expand, they use automation and delegation to fill in their lower branches. This is a crucial one; even though you'll still adore them, you'll have to manage their scope or help them learn how to scale on their own.
Free Range: You can direct them toward objectives rather than specific chores. Check-ins can be used to keep them generally on course without stifling invention instead of giving them precise instructions because doing so will obscure their light.
When people are inspired, they bring their own ideas about what a firm can be and become animated during discussions about how to get there.
Novelty Seeking: They look for business and personal growth chances. Give them fresh assignments and new directions to follow around once every three months.
Here’s what the First Ten types may not be:
Domain specialists. When you look at their resumes, you'll almost certainly think they're unqualified. Fortunately, a few strategically positioned experts may empower a number of First Ten types by serving on a leadership team or in advising capacities.
Balanced. These people become very invested, and they may be vulnerable to many types of stress. You may need to assist them in managing their own stress and coaching them through obstacles. If you are reading this and work at Banza, I apologize for not doing a better job of supporting this. I need to be better at it.
Able to handle micromanagement with ease. People who like to be in charge will suppress these people. Good decision-making should be delegated to competent individuals. Generally speaking, if you wish to scale.
Great startup team members have versatility, learning, innovation, and energy. When we hire for the function, not the person, we become dull and staid. Could this person go to another department if needed? Could they expand two levels in a few years?
First Ten qualities and experience level may have a weak inverse association. People with 20+ years of experience who had worked at larger organizations wanted to try something new and had a growth mentality. College graduates may want to be told what to do and how to accomplish it so they can stay in their lane and do what their management asks.
Does the First Ten archetype sound right for your org? Cool, let’s go hiring. How will you know when you’ve found one?
They exhibit adaptive excellence, excelling at a variety of unrelated tasks. It could be hobbies or professional talents. This suggests that they will succeed in the next several endeavors they pursue.
Successful risk-taking is doing something that wasn't certain to succeed, sometimes more than once, and making it do so. It's an attitude.
Rapid Rise: They regularly change roles and get promoted. However, they don't leave companies when the going gets tough. Look for promotions at every stop and at least one position with three or more years of experience.
You can ask them:
Tell me about a time when you started from scratch or achieved success. What occurred en route? You might request a variety of tales from various occupations or even aspects of life. They ought to be energized by this.
What new skills have you just acquired? It is not required to be work-related. They must be able to describe it and unintentionally become enthusiastic about it.
Tell me about a moment when you encountered a challenge and had to alter your strategy. The core of a startup is reinventing itself when faced with obstacles.
Tell me about a moment when you eliminated yourself from a position at work. They've demonstrated they can permanently solve one issue and develop into a new one, as stated above.
Why do you want to leave X position or Y duty? These people ought to be moving forward, not backward, all the time. Instead, they will discuss what they are looking forward to visiting your location.
Any questions? Due to their inherent curiosity and desire to learn new things, they should practically never run out of questions. You can really tell if they are sufficiently curious at this point.
People who see their success as being the same as the success of the organization are the best-case team members, in any market. They’ll grow and change with the company, and always try to prioritize what matters. You’ll find yourself more energized by your work because you’re surrounded by others who are as well. Happy teambuilding!
Nate Kostar
3 years ago
# DeaMau5’s PIXELYNX and Beatport Launch Festival NFTs
Pixelynx, a music metaverse gaming platform, has teamed up with Beatport, an online music retailer focusing in electronic music, to establish a Synth Heads non-fungible token (NFT) Collection.
Richie Hawtin, aka Deadmau5, and Joel Zimmerman, nicknamed Pixelynx, have invented a new music metaverse game platform called Pixelynx. In January 2022, they released their first Beatport NFT drop, which saw 3,030 generative NFTs sell out in seconds.
The limited edition Synth Heads NFTs will be released in collaboration with Junction 2, the largest UK techno festival, and having one will grant fans special access tickets and experiences at the London-based festival.
Membership in the Synth Head community, day passes to the Junction 2 Festival 2022, Junction 2 and Beatport apparel, special vinyl releases, and continued access to future ticket drops are just a few of the experiences available.
Five lucky NFT holders will also receive a Golden Ticket, which includes access to a backstage artist bar and tickets to Junction 2's next large-scale London event this summer, in addition to full festival entrance for both days.
The Junction 2 festival will take place at Trent Park in London on June 18th and 19th, and will feature performances from Four Tet, Dixon, Amelie Lens, Robert Hood, and a slew of other artists. Holders of the original Synth Head NFT will be granted admission to the festival's guestlist as well as line-jumping privileges.
The new Synth Heads NFTs collection contain 300 NFTs.
NFTs that provide IRL utility are in high demand.
The benefits of NFT drops related to In Real Life (IRL) utility aren't limited to Beatport and Pixelynx.
Coachella, a well-known music event, recently partnered with cryptocurrency exchange FTX to offer free NFTs to 2022 pass holders. Access to a dedicated entry lane, a meal and beverage pass, and limited-edition merchandise were all included with the NFTs.
Coachella also has its own NFT store on the Solana blockchain, where fans can buy Coachella NFTs and digital treasures that unlock exclusive on-site experiences, physical objects, lifetime festival passes, and "future adventures."
Individual artists and performers have begun taking advantage of NFT technology outside of large music festivals like Coachella.
DJ Tisto has revealed that he would release a VIP NFT for his upcoming "Eagle" collection during the EDC festival in Las Vegas in 2022. This NFT, dubbed "All Access Eagle," gives collectors the best chance to get NFTs from his first drop, as well as unique access to the music "Repeat It."
NFTs are one-of-a-kind digital assets that can be verified, purchased, sold, and traded on blockchains, opening up new possibilities for artists and businesses alike. Time will tell whether Beatport and Pixelynx's Synth Head NFT collection will be successful, but if it's anything like the first release, it's a safe bet.

Ivona Hirschi
3 years ago
7 LinkedIn Tips That Will Help in Audience Growth
In 8 months, I doubled my audience with them.

LinkedIn's buzz isn't over.
People dream of social proof every day. They want clients, interesting jobs, and field recognition.
LinkedIn coaches will benefit greatly. Sell learning? Probably. Can you use it?
Consistency has been key in my eight-month study of LinkedIn. However, I'll share seven of my tips. 700 to 4500 people followed me.
1. Communication, communication, communication
LinkedIn is a social network. I like to think of it as a cafe. Here, you can share your thoughts, meet friends, and discuss life and work.
Do not treat LinkedIn as if it were a board for your post-its.
More socializing improves relationships. It's about people, like any network.
Consider interactions. Three main areas:
Respond to criticism left on your posts.
Comment on other people's posts
Start and maintain conversations through direct messages.
Engage people. You spend too much time on Facebook if you only read your wall. Keeping in touch and having meaningful conversations helps build your network.
Every day, start a new conversation to make new friends.
2. Stick with those you admire
Interact thoughtfully.
Choose your contacts. Build your tribe is a term. Respectful networking.
I only had past colleagues, family, and friends in my network at the start of this year. Not business-friendly. Since then, I've sought out people I admire or can learn from.
Finding a few will help you. As they connect you to their networks. Friendships can lead to clients.
Don't underestimate network power. Cafe-style. Meet people at each table. But avoid people who sell SEO, web redesign, VAs, mysterious job opportunities, etc.
3. Share eye-catching infographics
Daily infographics flood LinkedIn. Visuals are popular. Use Canva's free templates if you can't draw them.
Last week's:

It's a fun way to visualize your topic.
You can repost and comment on infographics. Involve your network. I prefer making my own because I build my brand around certain designs.
My friend posted infographics consistently for four months and grew his network to 30,000.
If you start, credit the authors. As you steal someone's work.
4. Invite some friends over.
LinkedIn alone can be lonely. Having a few friends who support your work daily will boost your growth.
I was lucky to be invited to a group of networkers. We share knowledge and advice.
Having a few regulars who can discuss your posts is helpful. It's artificial, but it works and engages others.
Consider who you'd support if they were in your shoes.
You can pay for an engagement group, but you risk supporting unrelated people with rubbish posts.
Help each other out.
5. Don't let your feed or algorithm divert you.
LinkedIn's algorithm is magical.
Which time is best? How fast do you need to comment? Which days are best?
Overemphasize algorithms. Consider the user. No need to worry about the best time.
Remember to spend time on LinkedIn actively. Not passively. That is what Facebook is for.
Surely someone would find a LinkedIn recipe. Don't beat the algorithm yet. Consider your audience.
6. The more personal, the better
Personalization isn't limited to selfies. Share your successes and failures.
The more personality you show, the better.
People relate to others, not theories or quotes. Why should they follow you? Everyone posts the same content?
Consider your friends. What's their appeal?
Because they show their work and identity. It's simple. Medium and Linkedin are your platforms. Find out what works.
You can copy others' hooks and structures. You decide how simple to make it, though.
7. Have fun with those who have various post structures.
I like writing, infographics, videos, and carousels. Because you can:
Repurpose your content!
Out of one blog post I make:
Newsletter
Infographics (positive and negative points of view)
Carousel
Personal stories
Listicle
Create less but more variety. Since LinkedIn posts last 24 hours, you can rotate the same topics for weeks without anyone noticing.
Effective!
The final LI snippet to think about
LinkedIn is about consistency. Some say 15 minutes. If you're serious about networking, spend more time there.
The good news is that it is worth it. The bad news is that it takes time.