



More on Science

Will Lockett
3 years ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.

DANIEL CLERY
3 years ago
Can space-based solar power solve Earth's energy problems?
Better technology and lower launch costs revive science-fiction tech.
Airbus engineers showed off sustainable energy's future in Munich last month. They captured sunlight with solar panels, turned it into microwaves, and beamed it into an airplane hangar, where it lighted a city model. The test delivered 2 kW across 36 meters, but it posed a serious question: Should we send enormous satellites to capture solar energy in space? In orbit, free of clouds and nighttime, they could create power 24/7 and send it to Earth.
Airbus engineer Jean-Dominique Coste calls it an engineering problem. “But it’s never been done at [large] scale.”
Proponents of space solar power say the demand for green energy, cheaper space access, and improved technology might change that. Once someone invests commercially, it will grow. Former NASA researcher John Mankins says it might be a trillion-dollar industry.
Myriad uncertainties remain, including whether beaming gigawatts of power to Earth can be done efficiently and without burning birds or people. Concept papers are being replaced with ground and space testing. The European Space Agency (ESA), which supported the Munich demo, will propose ground tests to member nations next month. The U.K. government offered £6 million to evaluate innovations this year. Chinese, Japanese, South Korean, and U.S. agencies are working. NASA policy analyst Nikolai Joseph, author of an upcoming assessment, thinks the conversation's tone has altered. What formerly appeared unattainable may now be a matter of "bringing it all together"
NASA studied space solar power during the mid-1970s fuel crunch. A projected space demonstration trip using 1970s technology would have cost $1 trillion. According to Mankins, the idea is taboo in the agency.
Space and solar power technology have evolved. Photovoltaic (PV) solar cell efficiency has increased 25% over the past decade, Jones claims. Telecoms use microwave transmitters and receivers. Robots designed to repair and refuel spacecraft might create solar panels.
Falling launch costs have boosted the idea. A solar power satellite large enough to replace a nuclear or coal plant would require hundreds of launches. ESA scientist Sanjay Vijendran: "It would require a massive construction complex in orbit."
SpaceX has made the idea more plausible. A SpaceX Falcon 9 rocket costs $2600 per kilogram, less than 5% of what the Space Shuttle did, and the company promised $10 per kilogram for its giant Starship, slated to launch this year. Jones: "It changes the equation." "Economics rules"
Mass production reduces space hardware costs. Satellites are one-offs made with pricey space-rated parts. Mars rover Perseverance cost $2 million per kilogram. SpaceX's Starlink satellites cost less than $1000 per kilogram. This strategy may work for massive space buildings consisting of many identical low-cost components, Mankins has long contended. Low-cost launches and "hypermodularity" make space solar power economical, he claims.
Better engineering can improve economics. Coste says Airbus's Munich trial was 5% efficient, comparing solar input to electricity production. When the Sun shines, ground-based solar arrays perform better. Studies show space solar might compete with existing energy sources on price if it reaches 20% efficiency.
Lighter parts reduce costs. "Sandwich panels" with PV cells on one side, electronics in the middle, and a microwave transmitter on the other could help. Thousands of them build a solar satellite without heavy wiring to move power. In 2020, a team from the U.S. Naval Research Laboratory (NRL) flew on the Air Force's X-37B space plane.
NRL project head Paul Jaffe said the satellite is still providing data. The panel converts solar power into microwaves at 8% efficiency, but not to Earth. The Air Force expects to test a beaming sandwich panel next year. MIT will launch its prototype panel with SpaceX in December.
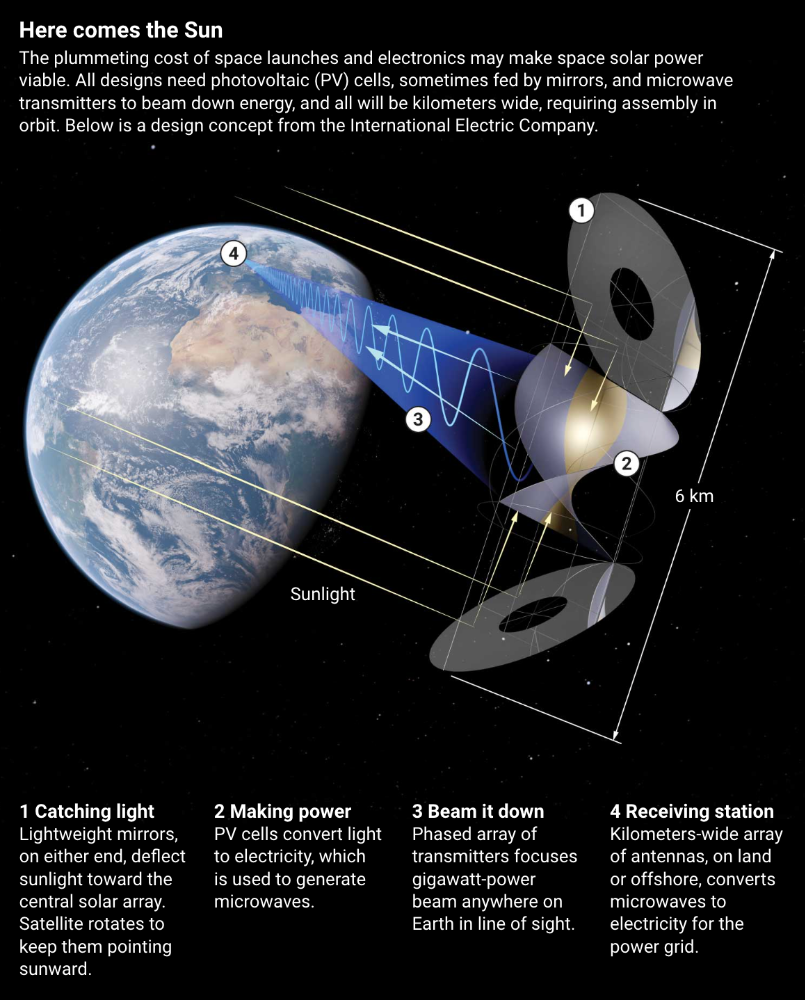
As a satellite orbits, the PV side of sandwich panels sometimes faces away from the Sun since the microwave side must always face Earth. To maintain 24-hour power, a satellite needs mirrors to keep that side illuminated and focus light on the PV. In a 2012 NASA study by Mankins, a bowl-shaped device with thousands of thin-film mirrors focuses light onto the PV array.
International Electric Company's Ian Cash has a new strategy. His proposed satellite uses enormous, fixed mirrors to redirect light onto a PV and microwave array while the structure spins (see graphic, above). 1 billion minuscule perpendicular antennas act as a "phased array" to electronically guide the beam toward Earth, regardless of the satellite's orientation. This design, argues Cash, is "the most competitive economically"
If a space-based power plant ever flies, its power must be delivered securely and efficiently. Jaffe's team at NRL just beamed 1.6 kW over 1 km, and teams in Japan, China, and South Korea have comparable attempts. Transmitters and receivers lose half their input power. Vijendran says space solar beaming needs 75% efficiency, "preferably 90%."
Beaming gigawatts through the atmosphere demands testing. Most designs aim to produce a beam kilometers wide so every ship, plane, human, or bird that strays into it only receives a tiny—hopefully harmless—portion of the 2-gigawatt transmission. Receiving antennas are cheap to build but require a lot of land, adds Jones. You could grow crops under them or place them offshore.
Europe's public agencies currently prioritize space solar power. Jones: "There's a devotion you don't see in the U.S." ESA commissioned two solar cost/benefit studies last year. Vijendran claims it might match ground-based renewables' cost. Even at a higher price, equivalent to nuclear, its 24/7 availability would make it competitive.
ESA will urge member states in November to fund a technical assessment. If the news is good, the agency will plan for 2025. With €15 billion to €20 billion, ESA may launch a megawatt-scale demonstration facility by 2030 and a gigawatt-scale facility by 2040. "Moonshot"

Laura Sanders
3 years ago
Xenobots, tiny living machines, can duplicate themselves.
Strange and complex behavior of frog cell blobs
A xenobot “parent,” shaped like a hungry Pac-Man (shown in red false color), created an “offspring” xenobot (green sphere) by gathering loose frog cells in its opening.
Tiny “living machines” made of frog cells can make copies of themselves. This newly discovered renewal mechanism may help create self-renewing biological machines.
According to Kirstin Petersen, an electrical and computer engineer at Cornell University who studies groups of robots, “this is an extremely exciting breakthrough.” She says self-replicating robots are a big step toward human-free systems.
Researchers described the behavior of xenobots earlier this year (SN: 3/31/21). Small clumps of skin stem cells from frog embryos knitted themselves into small spheres and started moving. Cilia, or cellular extensions, powered the xenobots around their lab dishes.
The findings are published in the Proceedings of the National Academy of Sciences on Dec. 7. The xenobots can gather loose frog cells into spheres, which then form xenobots.
The researchers call this type of movement-induced reproduction kinematic self-replication. The study's coauthor, Douglas Blackiston of Tufts University in Medford, Massachusetts, and Harvard University, says this is typical. For example, sexual reproduction requires parental sperm and egg cells. Sometimes cells split or budded off from a parent.
“This is unique,” Blackiston says. These xenobots “find loose parts in the environment and cobble them together.” This second generation of xenobots can move like their parents, Blackiston says.
The researchers discovered that spheroid xenobots could only produce one more generation before dying out. The original xenobots' shape was predicted by an artificial intelligence program, allowing for four generations of replication.
A C shape, like an openmouthed Pac-Man, was predicted to be a more efficient progenitor. When improved xenobots were let loose in a dish, they began scooping up loose cells into their gaping “mouths,” forming more sphere-shaped bots (see image below). As many as 50 cells clumped together in the opening of a parent to form a mobile offspring. A xenobot is made up of 4,000–6,000 frog cells.
Petersen likes the Xenobots' small size. “The fact that they were able to do this at such a small scale just makes it even better,” she says. Miniature xenobots could sculpt tissues for implantation or deliver therapeutics inside the body.
Beyond the xenobots' potential jobs, the research advances an important science, says study coauthor and Tufts developmental biologist Michael Levin. The science of anticipating and controlling the outcomes of complex systems, he says.
“No one could have predicted this,” Levin says. “They regularly surprise us.” Researchers can use xenobots to test the unexpected. “This is about advancing the science of being less surprised,” Levin says.
You might also like

Jayden Levitt
3 years ago
Billionaire who was disgraced lost his wealth more quickly than anyone in history
If you're not genuine, you'll be revealed.

Sam Bankman-Fried (SBF) was called the Cryptocurrency Warren Buffet.
No wonder.
SBF's trading expertise, Blockchain knowledge, and ability to construct FTX attracted mainstream investors.
He had a fantastic worldview, donating much of his riches to charity.
As the onion layers peel back, it's clear he wasn't the altruistic media figure he portrayed.
SBF's mistakes were disastrous.
Customer deposits were traded and borrowed by him.
With ten other employees, he shared a $40 million mansion where they all had polyamorous relationships.
Tone-deaf and wasteful marketing expenditures, such as the $200 million spent to change the name of the Miami Heat stadium to the FTX Arena
Democrats received a $40 million campaign gift.
And now there seems to be no regret.
FTX was a 32-billion-dollar cryptocurrency exchange.
It went bankrupt practically overnight.
SBF, FTX's creator, exploited client funds to leverage trade.
FTX had $1 billion in customer withdrawal reserves against $9 billion in liabilities in sister business Alameda Research.
Bloomberg Billionaire Index says it's the largest and fastest net worth loss in history.
It gets worse.
SBF's net worth is $900 Million, however he must still finalize FTX's bankruptcy.
SBF's arrest in the Bahamas and SEC inquiry followed news that his cryptocurrency exchange had crashed, losing billions in customer deposits.
A journalist contacted him on Twitter D.M., and their exchange is telling.
His ideas are revealed.
Kelsey Piper says they didn't expect him to answer because people under investigation don't comment.
Bankman-Fried wanted to communicate, and the interaction shows he has little remorse.
SBF talks honestly about FTX gaming customers' money and insults his competition.
Reporter Kelsey Piper was outraged by what he said and felt the mistakes SBF says plague him didn't evident in the messages.
Before FTX's crash, SBF was a poster child for Cryptocurrency regulation and avoided criticizing U.S. regulators.
He tells Piper that his lobbying is just excellent PR.
It shows his genuine views and supports cynics' opinions that his attempts to win over U.S. authorities were good for his image rather than Crypto.
SBF’s responses are in Grey, and Pipers are in Blue.
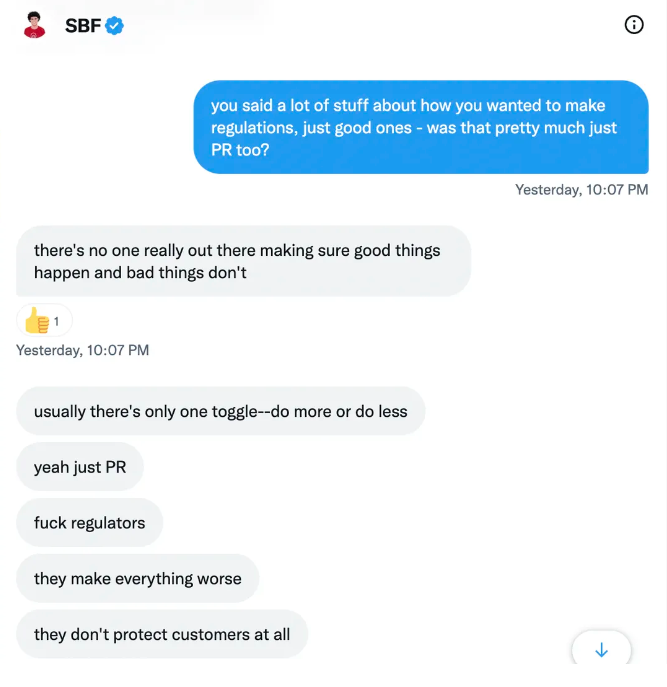
It's unclear if SBF cut corners for his gain. In their Twitter exchange, Piper revisits an interview question about ethics.
SBF says, "All the foolish sh*t I said"
SBF claims FTX has never invested customer monies.
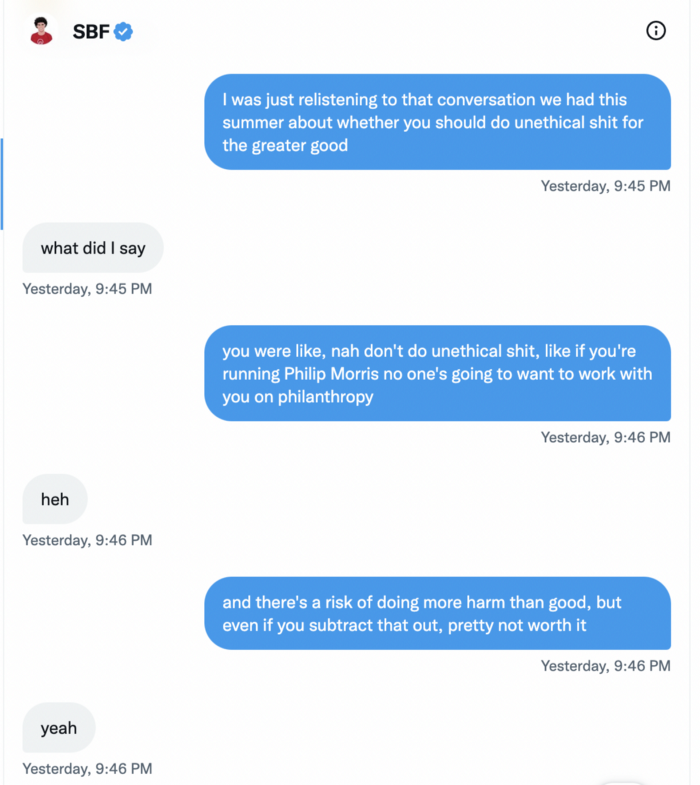
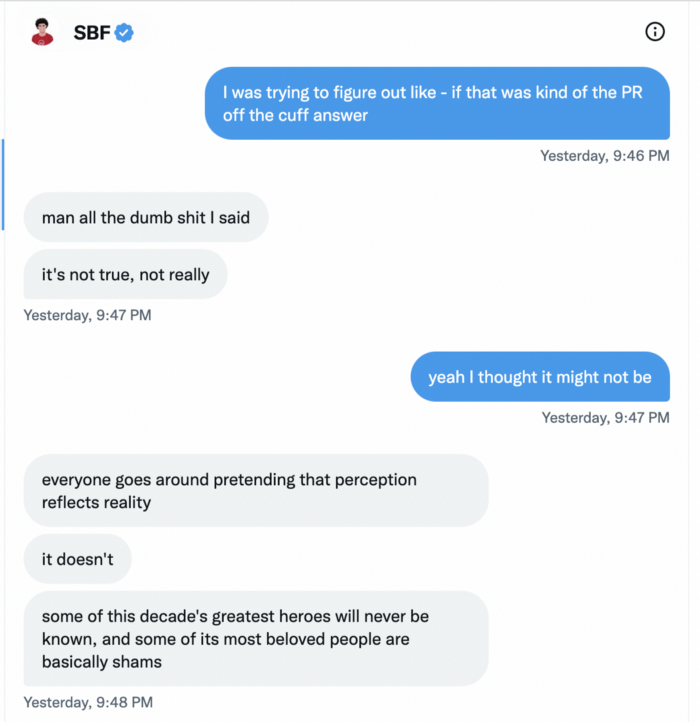
Piper challenged him on Twitter.
While he insisted FTX didn't use customer deposits, he said sibling business Alameda borrowed too much from FTX's balance sheet.
He did, basically.
When consumers tried to withdraw money, FTX was short.
SBF thought Alameda had enough money to cover FTX customers' withdrawals, but life sneaks up on you.
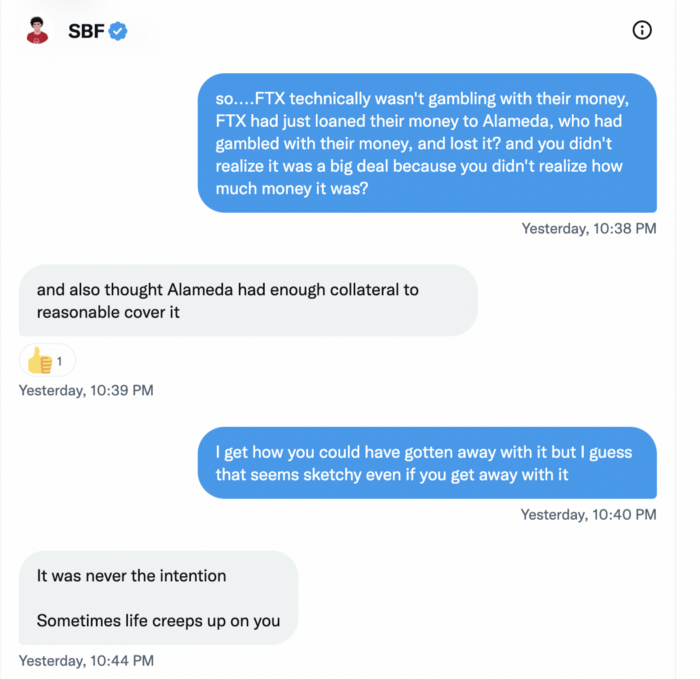
SBF believes most exchanges have done something similar to FTX, but they haven't had a bank run (a bunch of people all wanting to get their deposits out at the same time).
SBF believes he shouldn't have consented to the bankruptcy and kept attempting to raise more money because withdrawals would be open in a month with clients whole.
If additional money came in, he needed $8 billion to bridge the creditors' deficit, and there aren't many corporations with $8 billion to spare.
Once clients feel protected, they will continue to leave their assets on the exchange, according to one idea.
Kevin OLeary, a world-renowned hedge fund manager, says not all investors will walk through the open gate once the company is safe, therefore the $8 Billion wasn't needed immediately.
SBF claims the bankruptcy was his biggest error because he could have accumulated more capital.
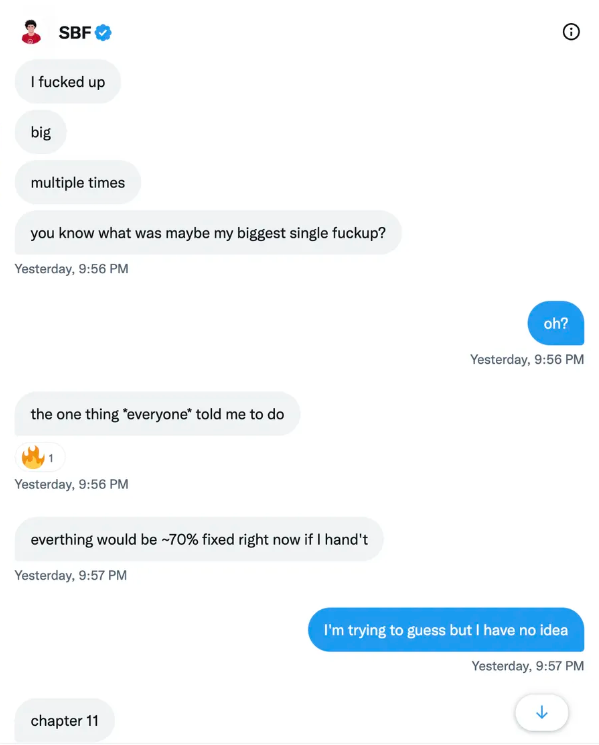
Final Reflections
Sam Bankman-Fried, 30, became the world's youngest billionaire in four years.
Never listen to what people say about investing; watch what they do.
SBF is a trader who gets wrecked occasionally.
Ten first-time entrepreneurs ran FTX, screwing each other with no risk management.
It prevents opposing or challenging perspectives and echo chamber highs.
Twitter D.M. conversation with a journalist is the final nail.
He lacks an experienced crew.
This event will surely speed up much-needed regulation.
It's also prompted cryptocurrency exchanges to offer proof of reserves to calm customers.

Faisal Khan
2 years ago
4 typical methods of crypto market manipulation

Market fraud
Due to its decentralized and fragmented character, the crypto market has integrity difficulties.
Cryptocurrencies are an immature sector, therefore market manipulation becomes a bigger issue. Many research have attempted to uncover these abuses. CryptoCompare's newest one highlights some of the industry's most typical scams.
Why are these concerns so common in the crypto market? First, even the largest centralized exchanges remain unregulated due to industry immaturity. A low-liquidity market segment makes an attack more harmful. Finally, market surveillance solutions not implemented reduce transparency.
In CryptoCompare's latest exchange benchmark, 62.4% of assessed exchanges had a market surveillance system, although only 18.1% utilised an external solution. To address market integrity, this measure must improve dramatically. Before discussing the report's malpractices, note that this is not a full list of attacks and hacks.
Clean Trading
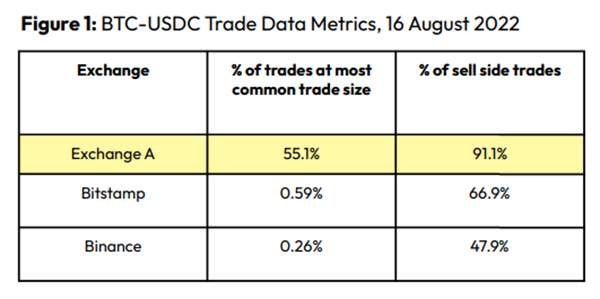
An investor buys and sells concurrently to increase the asset's price. Centralized and decentralized exchanges show this misconduct. 23 exchanges have a volume-volatility correlation < 0.1 during the previous 100 days, according to CryptoCompares. In August 2022, Exchange A reported $2.5 trillion in artificial and/or erroneous volume, up from $33.8 billion the month before.
Spoofing
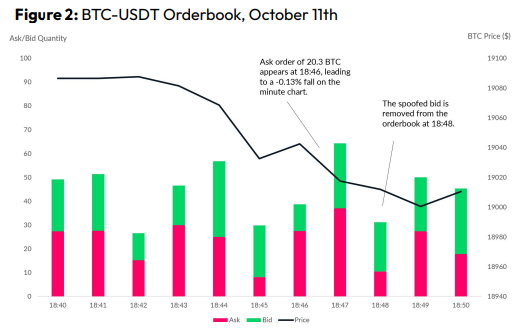
Criminals create and cancel fake orders before they can be filled. Since manipulators can hide in larger trading volumes, larger exchanges have more spoofing. A trader placed a 20.8 BTC ask order at $19,036 when BTC was trading at $19,043. BTC declined 0.13% to $19,018 in a minute. At 18:48, the trader canceled the ask order without filling it.
Front-Running
Most cryptocurrency front-running involves inside trading. Traditional stock markets forbid this. Since most digital asset information is public, this is harder. Retailers could utilize bots to front-run.
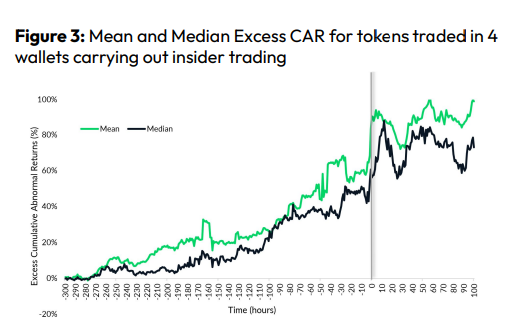
CryptoCompare found digital wallets of people who traded like insiders on exchange listings. The figure below shows excess cumulative anomalous returns (CAR) before a coin listing on an exchange.
Finally, LAYERING is a sequence of spoofs in which successive orders are put along a ladder of greater (layering offers) or lower (layering bids) values. The paper concludes with recommendations to mitigate market manipulation. Exchange data transparency, market surveillance, and regulatory oversight could reduce manipulative tactics.

Scott Galloway
3 years ago
Don't underestimate the foolish
ZERO GRACE/ZERO MALICE
Big companies and wealthy people make stupid mistakes too.
Your ancestors kept snakes and drank bad water. You (probably) don't because you've learnt from their failures via instinct+, the ultimate life-lessons streaming network in your head. Instincts foretell the future. If you approach a lion, it'll eat you. Our society's nuanced/complex decisions have surpassed instinct. Human growth depends on how we handle these issues. 80% of people believe they are above-average drivers, yet few believe they make many incorrect mistakes that make them risky. Stupidity hurts others like death. Basic Laws of Human Stupidity by Carlo Cipollas:
Everyone underestimates the prevalence of idiots in our society.
Any other trait a person may have has no bearing on how likely they are to be stupid.
A dumb individual is one who harms someone without benefiting themselves and may even lose money in the process.
Non-dumb people frequently underestimate how destructively powerful stupid people can be.
The most dangerous kind of person is a moron.
Professor Cippola defines stupid as bad for you and others. We underestimate the corporate world's and seemingly successful people's ability to make bad judgments that harm themselves and others. Success is an intoxication that makes you risk-aggressive and blurs your peripheral vision.

Stupid companies and decisions:
Big Dumber
Big-company bad ideas have more bulk and inertia. The world's most valuable company recently showed its board a VR headset. Jony Ive couldn't destroy Apple's terrible idea in 2015. Mr. Ive said that VR cut users off from the outer world, made them seem outdated, and lacked practical uses. Ives' design team doubted users would wear headsets for lengthy periods.
VR has cost tens of billions of dollars over a decade to prove nobody wants it. The next great SaaS startup will likely come from Florence, not Redmond or San Jose.
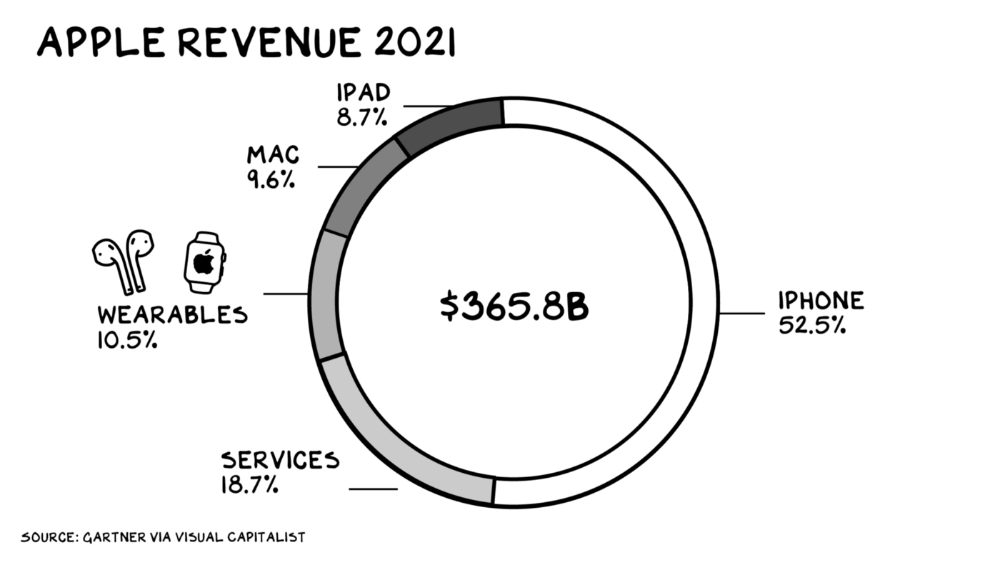
Apple Watch and Airpods have made the Cupertino company the world's largest jewelry maker. 10.5% of Apple's income, or $38 billion, comes from wearables in 2021. (seven times the revenue of Tiffany & Co.). Jewelry makes you more appealing and useful. Airpods and Apple Watch do both.
Headsets make you less beautiful and useful and promote isolation, loneliness, and unhappiness among American teenagers. My sons pretend they can't hear or see me when on their phones. VR headsets lack charisma.
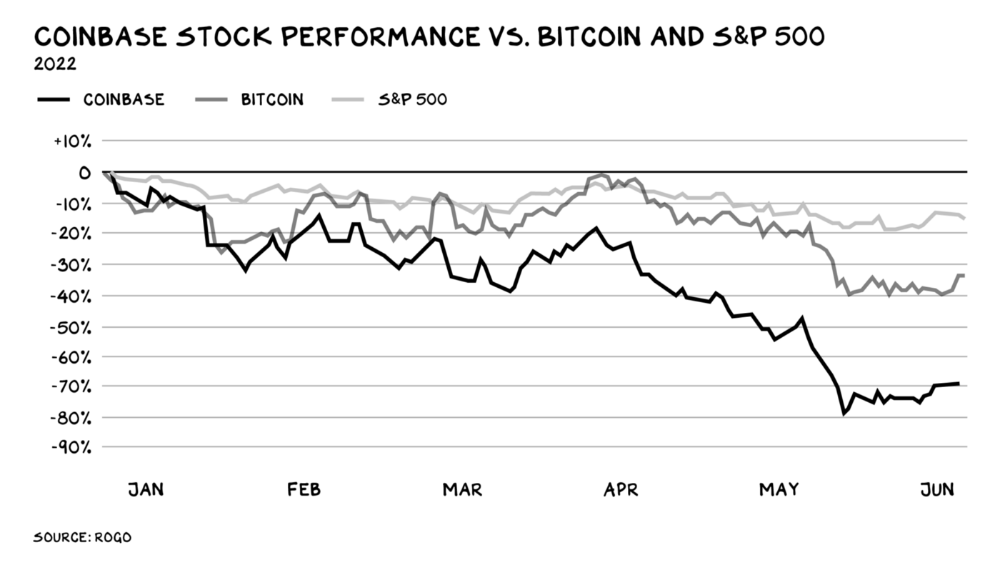
Coinbase disclosed a plan to generate division and tension within its workplace weeks after Apple was pitched $2,000 smokes. The crypto-trading platform is piloting a program that rates staff after every interaction. If a coworker says anything you don't like, you should tell them how to improve. Everyone gets a 110-point scorecard. Coworkers should evaluate a person's rating while deciding whether to listen to them. It's ridiculous.
Organizations leverage our superpower of cooperation. This encourages non-cooperation, period. Bridgewater's founder Ray Dalio designed the approach to promote extreme transparency. Dalio has 223 billion reasons his managerial style works. There's reason to suppose only a small group of people, largely traders, will endure a granular scorecard. Bridgewater has 20% first-year turnover. Employees cry in bathrooms, and sex scandals are settled by ignoring individuals with poor believability levels. Coinbase might take solace that the stock is 80% below its initial offering price.
Poor Stupid
Fools' ledgers are valuable. More valuable are lists of foolish rich individuals.
Robinhood built a $8 billion corporation on financial ignorance. The firm's median account value is $240, and its stock has dropped 75% since last summer. Investors, customers, and society lose. Stupid. Luna published a comparable list on the blockchain, grew to $41 billion in market cap, then plummeted.
A podcast presenter is recruiting dentists and small-business owners to invest in Elon Musk's Twitter takeover. Investors pay a 7% fee and 10% of the upside for the chance to buy Twitter at a 35% premium to the current price. The proposal legitimizes CNBC's Trade Like Chuck advertising (Chuck made $4,600 into $460,000 in two years). This is stupid because it adds to the Twitter deal's desperation. Mr. Musk made an impression when he urged his lawyers to develop a legal rip-cord (There are bots on the platform!) to abandon the share purchase arrangement (for less than they are being marketed by the podcaster). Rolls-Royce may pay for this list of the dumb affluent because it includes potential Cullinan buyers.
Worst company? Flowcarbon, founded by WeWork founder Adam Neumann, operates at the convergence of carbon and crypto to democratize access to offsets and safeguard the earth's natural carbon sinks. Can I get an ayahuasca Big Gulp?
Neumann raised $70 million with their yogababble drink. More than half of the consideration came from selling GNT. Goddess Nature Token. I hope the company gets an S-1. Or I'll start a decentralized AI Meta Renewable NFTs company. My Community Based Ebitda coin will fund the company. Possible.
Stupidity inside oneself
This weekend, I was in NYC with my boys. My 14-year-old disappeared. He's realized I'm not cool and is mad I let the charade continue. When out with his dad, he likes to stroll home alone and depart before me. Friends told me hell would return, but I was surprised by how fast the eye roll came.
Not so with my 11-year-old. We went to The Edge, a Hudson Yards observation platform where you can see the city from 100 storeys up for $38. This is hell's seventh ring. Leaning into your boys' interests is key to engaging them (dad tip). Neither loves Crossfit, WW2 history, or antitrust law.
We take selfies on the Thrilling Glass Floor he spots. Dad, there's a bar! Coke? I nod, he rushes to the bar, stops, runs back for money, and sprints back. Sitting on stone seats, drinking Atlanta Champagne, he turns at me and asks, Isn't this amazing? I'll never reach paradise.
Later that night, the lads are asleep and I've had two Zacapas and Cokes. I SMS some friends about my day and how I feel about sons/fatherhood/etc. How I did. They responded and approached. The next morning, I'm sober, have distance from my son, and feel ashamed by my texts. Less likely to impulsively share my emotions with others. Stupid again.