



More on Personal Growth

NonConformist
3 years ago
Before 6 AM, read these 6 quotations.
These quotes will change your perspective.

I try to reflect on these quotes daily. Reading it in the morning can affect your day, decisions, and priorities. Let's start.
1. Friedrich Nietzsche once said, "He who has a why to live for can bear almost any how."
What's your life goal?
80% of people don't know why they live or what they want to accomplish in life if you ask them randomly.
Even those with answers may not pursue their why. Without a purpose, life can be dull.
Your why can guide you through difficult times.
Create a life goal. Growing may change your goal. Having a purpose in life prevents feeling lost.

2. Seneca said, "He who fears death will never do anything fit for a man in life."
FAILURE STINKS Yes.
This quote is great if you're afraid to try because of failure. What if I'm not made for it? What will they think if I fail?
This wastes most of our lives. Many people prefer not failing over trying something with a better chance of success, according to studies.
Failure stinks in the short term, but it can transform our lives over time.

3. Two men peered through the bars of their cell windows; one saw mud, the other saw stars. — Dale Carnegie
It’s not what you look at that matters; it’s what you see.
The glass-full-or-empty meme is everywhere. It's hard to be positive when facing adversity.
This is a skill. Positive thinking can change our future.
We should stop complaining about our life and how easy success is for others.
Seductive pessimism. Realize this and start from first principles.

4. “Smart people learn from everything and everyone, average people from their experiences, and stupid people already have all the answers.” — Socrates.
Knowing we're ignorant can be helpful.
Every person and situation teaches you something. You can learn from others' experiences so you don't have to. Analyzing your and others' actions and applying what you learn can be beneficial.
Reading (especially non-fiction or biographies) is a good use of time. Walter Issacson wrote Benjamin Franklin's biography. Ben Franklin's early mistakes and successes helped me in some ways.
Knowing everything leads to disaster. Every incident offers lessons.

5. “We must all suffer one of two things: the pain of discipline or the pain of regret or disappointment.“ — James Rohn
My favorite Jim Rohn quote.
Exercise hurts. Healthy eating can be painful. But they're needed to get in shape. Avoiding pain can ruin our lives.
Always choose progress over hopelessness. Myth: overnight success Everyone who has mastered a craft knows that mastery comes from overcoming laziness.
Turn off your inner critic and start working. Try Can't Hurt Me by David Goggins.

6. “A champion is defined not by their wins, but by how they can recover when they fail.“ — Serena Williams
Have you heard of Traf-o-Data?
Gates and Allen founded Traf-O-Data. After some success, it failed. Traf-o-Data's failure led to Microsoft.
Allen said Traf-O-Data's setback was important for Microsoft's first product a few years later. Traf-O-Data was a business failure, but it helped them understand microprocessors, he wrote in 2017.
“The obstacle in the path becomes the path. Never forget, within every obstacle is an opportunity to improve our condition.” — Ryan Holiday.
Bonus Quotes
More helpful quotes:
“Those who cannot change their minds cannot change anything.” — George Bernard Shaw.
“Do something every day that you don’t want to do; this is the golden rule for acquiring the habit of doing your duty without pain.” — Mark Twain.
“Never give up on a dream just because of the time it will take to accomplish it. The time will pass anyway.” — Earl Nightingale.
“A life spent making mistakes is not only more honorable, but more useful than a life spent doing nothing.” — George Bernard Shaw.
“We don’t stop playing because we grow old; we grow old because we stop playing.” — George Bernard Shaw.
Conclusion
Words are powerful. Utilize it. Reading these inspirational quotes will help you.

Leon Ho
3 years ago
Digital Brainbuilding (Your Second Brain)

The human brain is amazing. As more scientists examine the brain, we learn how much it can store.
The human brain has 1 billion neurons, according to Scientific American. Each neuron creates 1,000 connections, totaling over a trillion. If each neuron could store one memory, we'd run out of room. [1]
What if you could store and access more info, freeing up brain space for problem-solving and creativity?
Build a second brain to keep up with rising knowledge (what I refer to as a Digital Brain). Effectively managing information entails realizing you can't recall everything.
Every action requires information. You need the correct information to learn a new skill, complete a project at work, or establish a business. You must manage information properly to advance your profession and improve your life.
How to construct a second brain to organize information and achieve goals.
What Is a Second Brain?
How often do you forget an article or book's key point? Have you ever wasted hours looking for a saved file?
If so, you're not alone. Information overload affects millions of individuals worldwide. Information overload drains mental resources and causes anxiety.
This is when the second brain comes in.
Building a second brain doesn't involve duplicating the human brain. Building a system that captures, organizes, retrieves, and archives ideas and thoughts. The second brain improves memory, organization, and recall.
Digital tools are preferable to analog for building a second brain.
Digital tools are portable and accessible. Due to these benefits, we'll focus on digital second-brain building.
Brainware
Digital Brains are external hard drives. It stores, organizes, and retrieves. This means improving your memory won't be difficult.
Memory has three components in computing:
Recording — storing the information
Organization — archiving it in a logical manner
Recall — retrieving it again when you need it
For example:
Due to rigorous security settings, many websites need you to create complicated passwords with special characters.
You must now memorize (Record), organize (Organize), and input this new password the next time you check in (Recall).
Even in this simple example, there are many pieces to remember. We can't recognize this new password with our usual patterns. If we don't use the password every day, we'll forget it. You'll type the wrong password when you try to remember it.
It's common. Is it because the information is complicated? Nope. Passwords are basically letters, numbers, and symbols.
It happens because our brains aren't meant to memorize these. Digital Brains can do heavy lifting.
Why You Need a Digital Brain
Dual minds are best. Birth brain is limited.
The cerebral cortex has 125 trillion synapses, according to a Stanford Study. The human brain can hold 2.5 million terabytes of digital data. [2]
Building a second brain improves learning and memory.
Learn and store information effectively
Faster information recall
Organize information to see connections and patterns
Build a Digital Brain to learn more and reach your goals faster. Building a second brain requires time and work, but you'll have more time for vital undertakings.
Why you need a Digital Brain:
1. Use Brainpower Effectively
Your brain has boundaries, like any organ. This is true while solving a complex question or activity. If you can't focus on a work project, you won't finish it on time.
Second brain reduces distractions. A robust structure helps you handle complicated challenges quickly and stay on track. Without distractions, it's easy to focus on vital activities.
2. Staying Organized
Professional and personal duties must be balanced. With so much to do, it's easy to neglect crucial duties. This is especially true for skill-building. Digital Brain will keep you organized and stress-free.
Life success requires action. Organized people get things done. Organizing your information will give you time for crucial tasks.
You'll finish projects faster with good materials and methods. As you succeed, you'll gain creative confidence. You can then tackle greater jobs.
3. Creativity Process
Creativity drives today's world. Creativity is mysterious and surprising for millions worldwide. Immersing yourself in others' associations, triggers, thoughts, and ideas can generate inspiration and creativity.
Building a second brain is crucial to establishing your creative process and building habits that will help you reach your goals. Creativity doesn't require perfection or overthinking.
4. Transforming Your Knowledge Into Opportunities
This is the age of entrepreneurship. Today, you can publish online, build an audience, and make money.
Whether it's a business or hobby, you'll have several job alternatives. Knowledge can boost your economy with ideas and insights.
5. Improving Thinking and Uncovering Connections
Modern career success depends on how you think. Instead of overthinking or perfecting, collect the best images, stories, metaphors, anecdotes, and observations.
This will increase your creativity and reveal connections. Increasing your imagination can help you achieve your goals, according to research. [3]
Your ability to recognize trends will help you stay ahead of the pack.
6. Credibility for a New Job or Business
Your main asset is experience-based expertise. Others won't be able to learn without your help. Technology makes knowledge tangible.
This lets you use your time as you choose while helping others. Changing professions or establishing a new business become learning opportunities when you have a Digital Brain.
7. Using Learning Resources
Millions of people use internet learning materials to improve their lives. Online resources abound. These include books, forums, podcasts, articles, and webinars.
These resources are mostly free or inexpensive. Organizing your knowledge can save you time and money. Building a Digital Brain helps you learn faster. You'll make rapid progress by enjoying learning.
How does a second brain feel?
Digital Brain has helped me arrange my job and family life for years.
No need to remember 1001 passwords. I never forget anything on my wife's grocery lists. Never miss a meeting. I can access essential information and papers anytime, anywhere.
Delegating memory to a second brain reduces tension and anxiety because you'll know what to do with every piece of information.
No information will be forgotten, boosting your confidence. Better manage your fears and concerns by writing them down and establishing a strategy. You'll understand the plethora of daily information and have a clear head.
How to Develop Your Digital Brain (Your Second Brain)
It's cheap but requires work.
Digital Brain development requires:
Recording — storing the information
Organization — archiving it in a logical manner
Recall — retrieving it again when you need it
1. Decide what information matters before recording.
To succeed in today's environment, you must manage massive amounts of data. Articles, books, webinars, podcasts, emails, and texts provide value. Remembering everything is impossible and overwhelming.
What information do you need to achieve your goals?
You must consolidate ideas and create a strategy to reach your aims. Your biological brain can imagine and create with a Digital Brain.
2. Use the Right Tool
We usually record information without any preparation - we brainstorm in a word processor, email ourselves a message, or take notes while reading.
This information isn't used. You must store information in a central location.
Different information needs different instruments.
Evernote is a top note-taking program. Audio clips, Slack chats, PDFs, text notes, photos, scanned handwritten pages, emails, and webpages can be added.
Pocket is a great software for saving and organizing content. Images, videos, and text can be sorted. Web-optimized design
Calendar apps help you manage your time and enhance your productivity by reminding you of your most important tasks. Calendar apps flourish. The best calendar apps are easy to use, have many features, and work across devices. These calendars include Google, Apple, and Outlook.
To-do list/checklist apps are useful for managing tasks. Easy-to-use, versatility, budget, and cross-platform compatibility are important when picking to-do list apps. Google Keep, Google Tasks, and Apple Notes are good to-do apps.
3. Organize data for easy retrieval
How should you organize collected data?
When you collect and organize data, you'll see connections. An article about networking can assist you comprehend web marketing. Saved business cards can help you find new clients.
Choosing the correct tools helps organize data. Here are some tools selection criteria:
Can the tool sync across devices?
Personal or team?
Has a search function for easy information retrieval?
Does it provide easy data categorization?
Can users create lists or collections?
Does it offer easy idea-information connections?
Does it mind map and visually organize thoughts?
Conclusion
Building a Digital Brain (second brain) helps us save information, think creatively, and implement ideas. Your second brain is a biological extension. It prevents amnesia, allowing you to tackle bigger creative difficulties.
People who love learning often consume information without using it. Every day, they postpone life-improving experiences until they're forgotten. Useful information becomes strength.
Reference
[1] ^ Scientific American: What Is the Memory Capacity of the Human Brain?
[2] ^ Clinical Neurology Specialists: What is the Memory Capacity of a Human Brain?
[3] ^ National Library of Medicine: Imagining Success: Multiple Achievement Goals and the Effectiveness of Imagery

Suzie Glassman
3 years ago
How I Stay Fit Despite Eating Fast Food and Drinking Alcohol
Here's me. Perfectionism is unnecessary.

This post isn't for people who gag at the prospect of eating french fries. I've been ridiculed for stating you can lose weight eating carbs and six-pack abs aren't good.
My family eats frozen processed meals and quick food most weeks (sometimes more). Clean eaters may think I'm unqualified to give fitness advice. I get it.
Hear me out, though. I’m a 44-year-old raising two busy kids with a weekly-traveling husband. Tutoring, dance, and guitar classes fill weeknights. I'm also juggling my job and freelancing.
I'm as worried and tired as my clients. I wish I ate only kale smoothies and salads. I can’t. Despite my mistakes, I'm fit. I won't promise you something just because it worked for me. But here’s a look at how I manage.
What I largely get right about eating
I have a flexible diet and track my daily intake. I count protein, fat, and carbs. Only on vacation or exceptional occasions do I not track.
My protein goal is 1 g per lb. I consume a lot of chicken breasts, eggs, turkey, and lean ground beef. I also occasionally drink protein shakes.
I eat 220–240 grams of carbs daily. My carb count depends on training volume and goals. I'm trying to lose weight slowly. If I want to lose weight faster, I cut carbs to 150-180.
My carbs include white rice, Daves Killer Bread, fruit, pasta, and veggies. I don't eat enough vegetables, so I take Athletic Greens. Also, V8.
Fat grams over 50 help me control my hormones. Recently, I've reached 70-80 grams. Cooking with olive oil. I eat daily dark chocolate. Eggs, butter, milk, and cheese contribute to the rest.
Those frozen meals? What can I say? Stouffer’s lasagna is sometimes needed. I order the healthiest fast food I can find (although I can never bring myself to order the salad). That's a chicken sandwich or a kid's hamburger. I rarely order fries. I eat slowly and savor each bite to feel full.
Potato chips and sugary cereals are in the pantry, but I'm not tempted. My kids eat them because I'd rather teach them moderation than total avoidance. If I eat them, I only eat one portion.
If you're not hungry and eating enough protein and fat, you won't want to eat everything in sight.
I drink once or twice a week. As a result, I rarely overdo it.
Food tracking is tedious and frustrating for many. Taking breaks and using estimates when eating out help. Not perfect, but realistic.
I practice a prolonged fast to enhance metabolic adaptability
Metabolic flexibility is the ability to switch between fuel sources (fat and carbs) based on activity intensity and time since eating. At rest or during low to moderate exertion, your body burns fat. Your body burns carbs after eating and during intense exercise.
Our metabolic flexibility can be hampered by lack of exercise, overeating, and stress. Our bodies become lousy fat burners, making weight loss difficult.
Once a week, I skip dinner (usually around 24 hours). Long-term fasting teaches my body to burn fat. It provides me one low-calorie day a week (I break the fast with a normal-sized dinner).
Fasting day helps me maintain my weight on weekends, when I typically overeat and drink.
Try an extended fast slowly. Delay breakfast by two hours. Next week, add two hours, etc. It takes practice to go that long without biting off your arm. I also suggest consulting your doctor.
I stay active.
I've always been active. As a child, I danced many nights a week, was on the high school dance team, and ran marathons in my 20s.
Often, I feel driven by an internal engine. Working from home makes it easy to exercise. If that’s not you, I get it. Everyone can benefit from raising their baseline.
After taking the kids to school, I walk two miles around the neighborhood. When I need to think, I switch off podcasts. First thing in the morning, I go for a walk.
I lift weights Monday, Wednesday, and Friday. 45 minutes is typical. I run 45-90 minutes on Tuesday and Thursday. I'm slow but reliable. On Saturdays and Sundays, I walk and add a short spin class if I'm not too tired.
I almost never forgo sleep.
I rarely stay up past 10 p.m., much to my night-owl husband's dismay. My 7-8-hour nights help me recover from workouts and handle stress. Without it, I'm grumpy.
I suppose sleep duration matters more than bedtime. Some people just can't fall asleep early. Internal clock and genetics determine sleep and wake hours.
Prioritize sleep.
Last thoughts
Fitness and diet advice is often useless. Some of the advice is inaccurate, dangerous, or difficult to follow if you have a life. I want to throw a shoe at my screen when I see headlines promising to speed up my metabolism or help me lose fat.
I studied exercise physiology for years. No shortcuts exist. No medications or cleanses reset metabolism. I play the hand I'm dealt. I realize that just because something works for me, it won't for you.
If I wanted 15% body fat and ripped abs, I'd have to be stricter. I occasionally think I’d like to get there. But then I remember I’m happy with my life. I like fast food and beer. Pizza and margaritas are favorites (not every day).
You can get it mostly right and live a healthy life.
You might also like

Thomas Tcheudjio
3 years ago
If you don't crush these 3 metrics, skip the Series A.
I recently wrote about getting VCs excited about Marketplace start-ups. SaaS founders became envious!
Understanding how people wire tens of millions is the only Series A hack I recommend.
Few people understand the intellectual process behind investing.
VC is risk management.
Series A-focused VCs must cover two risks.
1. Market risk
You need a large market to cross a threshold beyond which you can build defensibilities. Series A VCs underwrite market risk.
They must see you have reached product-market fit (PMF) in a large total addressable market (TAM).
2. Execution risk
When evaluating your growth engine's blitzscaling ability, execution risk arises.
When investors remove operational uncertainty, they profit.
Series A VCs like businesses with derisked revenue streams. Don't raise unless you have a predictable model, pipeline, and growth.
Please beat these 3 metrics before Series A:
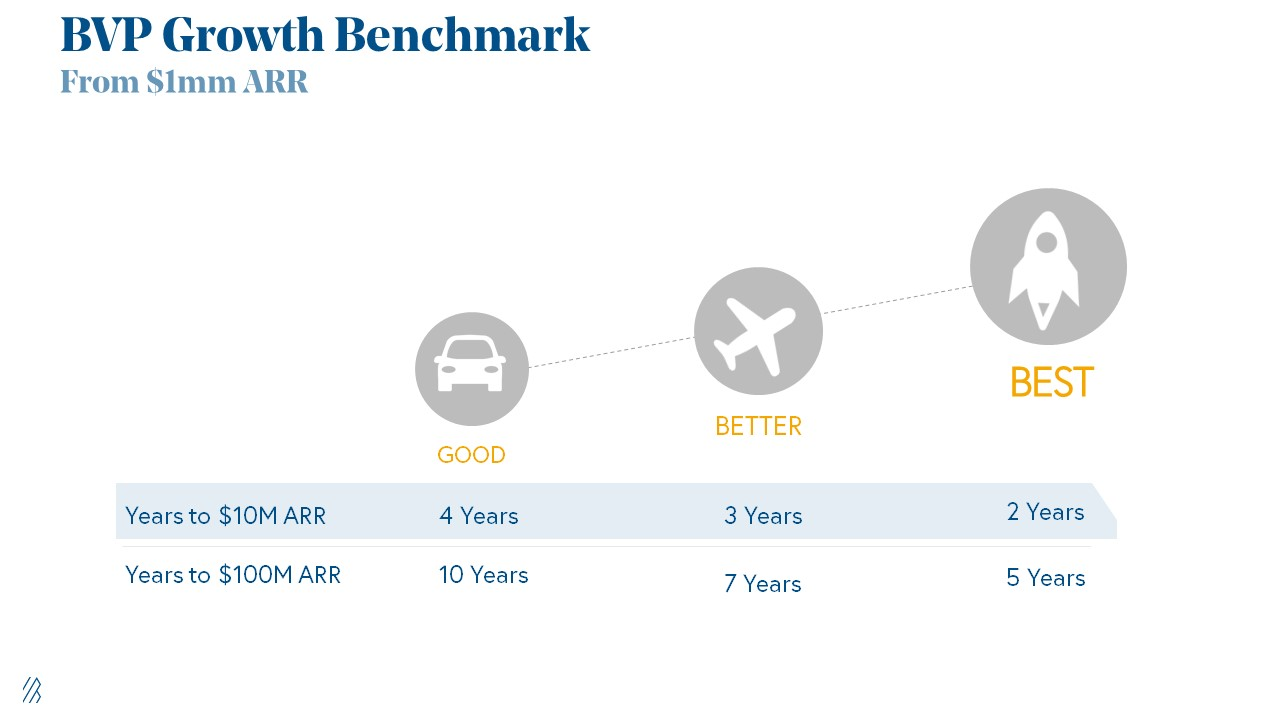
Achieve $1.5m ARR in 12-24 months (Market risk)
Above 100% Net Dollar Retention. (Market danger)
Lead Velocity Rate supporting $10m ARR in 2–4 years (Execution risk)
Hit the 3 and you'll raise $10M in 4 months. Discussing 2/3 may take 6–7 months.
If none, don't bother raising and focus on becoming a capital-efficient business (Topics for other posts).
Let's examine these 3 metrics for the brave ones.
1. Lead Velocity Rate supporting €$10m ARR in 2 to 4 years
Last because it's the least discussed. LVR is the most reliable data when evaluating a growth engine, in my opinion.
SaaS allows you to see the future.
Monthly Sales and Sales Pipelines, two predictive KPIs, have poor data quality. Both are lagging indicators, and minor changes can cause huge modeling differences.
Analysts and Associates will trash your forecasts if they're based only on Monthly Sales and Sales Pipeline.
LVR, defined as month-over-month growth in qualified leads, is rock-solid. There's no lag. You can See The Future if you use Qualified Leads and a consistent formula and process to qualify them.
With this metric in your hand, scaling your company turns into an execution play on which VCs are able to perform calculations risk.
2. Above-100% Net Dollar Retention.
Net Dollar Retention is a better-known SaaS health metric than LVR.
Net Dollar Retention measures a SaaS company's ability to retain and upsell customers. Ask what $1 of net new customer spend will be worth in years n+1, n+2, etc.
Depending on the business model, SaaS businesses can increase their share of customers' wallets by increasing users, selling them more products in SaaS-enabled marketplaces, other add-ons, and renewing them at higher price tiers.
If a SaaS company's annualized Net Dollar Retention is less than 75%, there's a problem with the business.
Slack's ARR chart (below) shows how powerful Net Retention is. Layer chart shows how existing customer revenue grows. Slack's S1 shows 171% Net Dollar Retention for 2017–2019.

Slack S-1
3. $1.5m ARR in the last 12-24 months.
According to Point 9, $0.5m-4m in ARR is needed to raise a $5–12m Series A round.
Target at least what you raised in Pre-Seed/Seed. If you've raised $1.5m since launch, don't raise before $1.5m ARR.
Capital efficiency has returned since Covid19. After raising $2m since inception, it's harder to raise $1m in ARR.

P9's 2016-2021 SaaS Funding Napkin
In summary, less than 1% of companies VCs meet get funded. These metrics can help you win.
If there’s demand for it, I’ll do one on direct-to-consumer.
Cheers!

Camilla Dudley
3 years ago
How to gain Twitter followers: A 101 Guide

No wonder brands use Twitter to reach their audience. 53% of Twitter users buy new products first.
Twitter growth does more than make your brand look popular. It helps clients trust your business. It boosts your industry standing. It shows clients, prospects, and even competitors you mean business.
How can you naturally gain Twitter followers?
Share useful information
Post visual content
Tweet consistently
Socialize
Spread your @name everywhere.
Use existing customers
Promote followers
Share useful information
Twitter users join conversations and consume material. To build your followers, make sure your material appeals to them and gives value, whether it's sales, product lessons, or current events.
Use Twitter Analytics to learn what your audience likes.
Explore popular topics by utilizing relevant keywords and hashtags. Check out this post on how to use Twitter trends.
Post visual content
97% of Twitter users focus on images, so incorporating media can help your Tweets stand out. Visuals and videos make content more engaging and memorable.
Tweet often
Your audience should expect regular content updates. Plan your ideas and tweet during crucial seasons and events with a content calendar.
Socialize
Twitter connects people. Do more than tweet. Follow industry leaders. Retweet influencers, engage with thought leaders, and reply to mentions and customers to boost engagement.
Micro-influencers can promote your brand or items. They can help you gain new audiences' trust.
Spread your @name everywhere.
Maximize brand exposure. Add a follow button on your website, link to it in your email signature and newsletters, and promote it on business cards or menus.
Use existing customers
Emails can be used to find existing Twitter clients. Upload your email contacts and follow your customers on Twitter to start a dialogue.
Promote followers
Run a followers campaign to boost your organic growth. Followers campaigns promote your account to a particular demographic, and you only pay when someone follows you.
Consider short campaigns to enhance momentum or an always-on campaign to gain new followers.
Increasing your brand's Twitter followers takes effort and experimentation, but the payback is huge.
👋 Follow me on twitter

M.G. Siegler
3 years ago
G3nerative
Generative AI hype: some thoughts

The sudden surge in "generative AI" startups and projects feels like the inverse of the recent "web3" boom. Both came from hyped-up pots. But while web3 hyped idealistic tech and an easy way to make money, generative AI hypes unsettling tech and questions whether it can be used to make money.
Web3 is technology looking for problems to solve, while generative AI is technology creating almost too many solutions. Web3 has been evangelists trying to solve old problems with new technology. As Generative AI evolves, users are resolving old problems in stunning new ways.
It's a jab at web3, but it's true. Web3's hype, including crypto, was unhealthy. Always expected a tech crash and shakeout. Tech that won't look like "web3" but will enhance "web2"
But that doesn't mean AI hype is healthy. There'll be plenty of bullshit here, too. As moths to a flame, hype attracts charlatans. Again, the difference is the different starting point. People want to use it. Try it.
With the beta launch of Dall-E 2 earlier this year, a new class of consumer product took off. Midjourney followed suit (despite having to jump through the Discord server hoops). Twelve more generative art projects. Lensa, Prisma Labs' generative AI self-portrait project, may have topped the hype (a startup which has actually been going after this general space for quite a while). This week, ChatGPT went off-topic.
This has a "fake-it-till-you-make-it" vibe. We give these projects too much credit because they create easy illusions. This also unlocks new forms of creativity. And faith in new possibilities.
As a user, it's thrilling. We're just getting started. These projects are not only fun to play with, but each week brings a new breakthrough. As an investor, it's all happening so fast, with so much hype (and ethical and societal questions), that no one knows how it will turn out. Web3's demand won't be the issue. Too much demand may cause servers to melt down, sending costs soaring. Companies will try to mix rapidly evolving tech to meet user demand and create businesses. Frustratingly difficult.
Anyway, I wanted an excuse to post some Lensa selfies.

These are really weird. I recognize them as me or a version of me, but I have no memory of them being taken. It's surreal, out-of-body. Uncanny Valley.