


How to sell 10,000 NFTs on OpenSea for FREE (Puppeteer/NodeJS)
So you've finished your NFT collection and are ready to sell it. Except you can't figure out how to mint them! Not sure about smart contracts or want to avoid rising gas prices. You've tried and failed with apps like Mini mouse macro, and you're not familiar with Selenium/Python. Worry no more, NodeJS and Puppeteer have arrived!
Learn how to automatically post and sell all 1000 of my AI-generated word NFTs (Nakahana) on OpenSea for FREE!
My NFT project — Nakahana |
NOTE: Only NFTs on the Polygon blockchain can be sold for free; Ethereum requires an initiation charge. NFTs can still be bought with (wrapped) ETH.
If you want to go right into the code, here's the GitHub link: https://github.com/Yusu-f/nftuploader
Let's start with the knowledge and tools you'll need.
What you should know
You must be able to write and run simple NodeJS programs. You must also know how to utilize a Metamask wallet.
Tools needed
- NodeJS. You'll need NodeJs to run the script and NPM to install the dependencies.
- Puppeteer – Use Puppeteer to automate your browser and go to sleep while your computer works.
- Metamask – Create a crypto wallet and sign transactions using Metamask (free). You may learn how to utilize Metamask here.
- Chrome – Puppeteer supports Chrome.
Let's get started now!
Starting Out
Clone Github Repo to your local machine. Make sure that NodeJS, Chrome, and Metamask are all installed and working. Navigate to the project folder and execute npm install. This installs all requirements.
Replace the “extension path” variable with the Metamask chrome extension path. Read this tutorial to find the path.
Substitute an array containing your NFT names and metadata for the “arr” variable and the “collection_name” variable with your collection’s name.
Run the script.
After that, run node nftuploader.js.
Open a new chrome instance (not chromium) and Metamask in it. Import your Opensea wallet using your Secret Recovery Phrase or create a new one and link it. The script will be unable to continue after this but don’t worry, it’s all part of the plan.
Next steps
Open your terminal again and copy the route that starts with “ws”, e.g. “ws:/localhost:53634/devtools/browser/c07cb303-c84d-430d-af06-dd599cf2a94f”. Replace the path in the connect function of the nftuploader.js script.
const browser = await puppeteer.connect({ browserWSEndpoint: "ws://localhost:58533/devtools/browser/d09307b4-7a75-40f6-8dff-07a71bfff9b3", defaultViewport: null });
Rerun node nftuploader.js. A second tab should open in THE SAME chrome instance, navigating to your Opensea collection. Your NFTs should now start uploading one after the other! If any errors occur, the NFTs and errors are logged in an errors.log file.
Error Handling
The errors.log file should show the name of the NFTs and the error type. The script has been changed to allow you to simply check if an NFT has already been posted. Simply set the “searchBeforeUpload” setting to true.
We're done!
If you liked it, you can buy one of my NFTs! If you have any concerns or would need a feature added, please let me know.
Thank you to everyone who has read and liked. I never expected it to be so popular.
More on Web3 & Crypto

Trent Lapinski
4 years ago
What The Hell Is A Crypto Punk?
We are Crypto Punks, and we are changing your world.
A “Crypto Punk” is a new generation of entrepreneurs who value individual liberty and collective value creation and co-creation through decentralization. While many Crypto Punks were born and raised in a digital world, some of the early pioneers in the crypto space are from the Oregon Trail generation. They were born to an analog world, but grew up simultaneously alongside the birth of home computing, the Internet, and mobile computing.
A Crypto Punk’s world view is not the same as previous generations. By the time most Crypto Punks were born everything from fiat currency, the stock market, pharmaceuticals, the Internet, to advanced operating systems and microprocessing were already present or emerging. Crypto Punks were born into pre-existing conditions and systems of control, not governed by logic or reason but by greed, corporatism, subversion, bureaucracy, censorship, and inefficiency.
All Systems Are Human Made
Crypto Punks understand that all systems were created by people and that previous generations did not have access to information technologies that we have today. This is why Crypto Punks have different values than their parents, and value liberty, decentralization, equality, social justice, and freedom over wealth, money, and power. They understand that the only path forward is to work together to build new and better systems that make the old world order obsolete.
Unlike the original cypher punks and cyber punks, Crypto Punks are a new iteration or evolution of these previous cultures influenced by cryptography, blockchain technology, crypto economics, libertarianism, holographics, democratic socialism, and artificial intelligence. They are tasked with not only undoing the mistakes of previous generations, but also innovating and creating new ways of solving complex problems with advanced technology and solutions.
Where Crypto Punks truly differ is in their understanding that computer systems can exist for more than just engagement and entertainment, but actually improve the human condition by automating bureaucracy and inefficiency by creating more efficient economic incentives and systems.
Crypto Punks Value Transparency and Do Not Trust Flawed, Unequal, and Corrupt Systems
Crypto Punks have a strong distrust for inherently flawed and corrupt systems. This why Crypto Punks value transparency, free speech, privacy, and decentralization. As well as arguably computer systems over human powered systems.
Crypto Punks are the children of the Great Recession, and will never forget the economic corruption that still enslaves younger generations.
Crypto Punks were born to think different, and raised by computers to view reality through an LED looking glass. They will not surrender to the flawed systems of economic wage slavery, inequality, censorship, and subjection. They will literally engineer their own unstoppable financial systems and trade in cryptography over fiat currency merely to prove that belief systems are more powerful than corruption.
Crypto Punks are here to help achieve freedom from world governments, corporations and bankers who monetizine our data to control our lives.
Crypto Punks Decentralize
Despite all the evils of the world today, Crypto Punks know they have the power to create change. This is why Crypto Punks are optimistic about the future despite all the indicators that humanity is destined for failure.
Crypto Punks believe in systems that prioritize people and the planet above profit. Even so, Crypto Punks still believe in capitalistic systems, but only capitalistic systems that incentivize good behaviors that do not violate the common good for the sake of profit.
Cyber Punks Are Co-Creators
We are Crypto Punks, and we will build a better world for all of us. For the true price of creation is not in US dollars, but through working together as equals to replace the unequal and corrupt greedy systems of previous generations.
Where they have failed, Crypto Punks will succeed. Not because we want to, but because we have to. The world we were born into is so corrupt and its systems so flawed and unequal we were never given a choice.
We have to be the change we seek.
We are Crypto Punks.
Either help us, or get out of our way.
Are you a Crypto Punk?

William Brucee
3 years ago
This person is probably Satoshi Nakamoto.

Who founded bitcoin is the biggest mystery in technology today, not how it works.
On October 31, 2008, Satoshi Nakamoto posted a whitepaper to a cryptography email list. Still confused by the mastermind who changed monetary history.
Journalists and bloggers have tried in vain to uncover bitcoin's creator. Some candidates self-nominated. We're still looking for the mystery's perpetrator because none of them have provided proof.
One person. I'm confident he invented bitcoin. Let's assess Satoshi Nakamoto before I reveal my pick. Or what he wants us to know.
Satoshi's P2P Foundation biography says he was born in 1975. He doesn't sound or look Japanese. First, he wrote the whitepaper and subsequent articles in flawless English. His sleeping habits are unusual for a Japanese person.
Stefan Thomas, a Bitcoin Forum member, displayed Satoshi's posting timestamps. Satoshi Nakamoto didn't publish between 2 and 8 p.m., Japanese time. Satoshi's identity may not be real.
Why would he disguise himself?
There is a legitimate explanation for this
Phil Zimmermann created PGP to give dissidents an open channel of communication, like Pretty Good Privacy. US government seized this technology after realizing its potential. Police investigate PGP and Zimmermann.
This technology let only two people speak privately. Bitcoin technology makes it possible to send money for free without a bank or other intermediary, removing it from government control.
How much do we know about the person who invented bitcoin?
Here's what we know about Satoshi Nakamoto now that I've covered my doubts about his personality.
Satoshi Nakamoto first appeared with a whitepaper on metzdowd.com. On Halloween 2008, he presented a nine-page paper on a new peer-to-peer electronic monetary system.

Using the nickname satoshi, he created the bitcointalk forum. He kept developing bitcoin and created bitcoin.org. Satoshi mined the genesis block on January 3, 2009.
Satoshi Nakamoto worked with programmers in 2010 to change bitcoin's protocol. He engaged with the bitcoin community. Then he gave Gavin Andresen the keys and codes and transferred community domains. By 2010, he'd abandoned the project.
The bitcoin creator posted his goodbye on April 23, 2011. Mike Hearn asked Satoshi if he planned to rejoin the group.
“I’ve moved on to other things. It’s in good hands with Gavin and everyone.”
Nakamoto Satoshi
The man who broke the banking system vanished. Why?

Satoshi's wallets held 1,000,000 BTC. In December 2017, when the price peaked, he had over US$19 billion. Nakamoto had the 44th-highest net worth then. He's never cashed a bitcoin.
This data suggests something happened to bitcoin's creator. I think Hal Finney is Satoshi Nakamoto .
Hal Finney had ALS and died in 2014. I suppose he created the future of money, then he died, leaving us with only rumors about his identity.
Hal Finney, who was he?
Hal Finney graduated from Caltech in 1979. Student peers voted him the smartest. He took a doctoral-level gravitational field theory course as a freshman. Finney's intelligence meets the first requirement for becoming Satoshi Nakamoto.
Students remember Finney holding an Ayn Rand book. If he'd read this, he may have developed libertarian views.
His beliefs led him to a small group of freethinking programmers. In the 1990s, he joined Cypherpunks. This action promoted the use of strong cryptography and privacy-enhancing technologies for social and political change. Finney helped them achieve a crypto-anarchist perspective as self-proclaimed privacy defenders.
Zimmermann knew Finney well.
Hal replied to a Cypherpunk message about Phil Zimmermann and PGP. He contacted Phil and became PGP Corporation's first member, retiring in 2011. Satoshi Nakamoto quit bitcoin in 2011.
Finney improved the new PGP protocol, but he had to do so secretly. He knew about Phil's PGP issues. I understand why he wanted to hide his identity while creating bitcoin.
Why did he pretend to be from Japan?
His envisioned persona was spot-on. He resided near scientist Dorian Prentice Satoshi Nakamoto. Finney could've assumed Nakamoto's identity to hide his. Temple City has 36,000 people, so what are the chances they both lived there? A cryptographic genius with the same name as Bitcoin's creator: coincidence?
Things went differently, I think.
I think Hal Finney sent himself Satoshis messages. I know it's odd. If you want to conceal your involvement, do as follows. He faked messages and transferred the first bitcoins to himself to test the transaction mechanism, so he never returned their money.
Hal Finney created the first reusable proof-of-work system. The bitcoin protocol. In the 1990s, Finney was intrigued by digital money. He invented CRypto cASH in 1993.
Legacy
Hal Finney's contributions should not be forgotten. Even if I'm wrong and he's not Satoshi Nakamoto, we shouldn't forget his bitcoin contribution. He helped us achieve a better future.

Ashraful Islam
4 years ago
Clean API Call With React Hooks
| Photo by Juanjo Jaramillo on Unsplash |
Calling APIs is the most common thing to do in any modern web application. When it comes to talking with an API then most of the time we need to do a lot of repetitive things like getting data from an API call, handling the success or error case, and so on.
When calling tens of hundreds of API calls we always have to do those tedious tasks. We can handle those things efficiently by putting a higher level of abstraction over those barebone API calls, whereas in some small applications, sometimes we don’t even care.
The problem comes when we start adding new features on top of the existing features without handling the API calls in an efficient and reusable manner. In that case for all of those API calls related repetitions, we end up with a lot of repetitive code across the whole application.
In React, we have different approaches for calling an API. Nowadays mostly we use React hooks. With React hooks, it’s possible to handle API calls in a very clean and consistent way throughout the application in spite of whatever the application size is. So let’s see how we can make a clean and reusable API calling layer using React hooks for a simple web application.
I’m using a code sandbox for this blog which you can get here.
import "./styles.css";
import React, { useEffect, useState } from "react";
import axios from "axios";
export default function App() {
const [posts, setPosts] = useState(null);
const [error, setError] = useState("");
const [loading, setLoading] = useState(false);
useEffect(() => {
handlePosts();
}, []);
const handlePosts = async () => {
setLoading(true);
try {
const result = await axios.get(
"https://jsonplaceholder.typicode.com/posts"
);
setPosts(result.data);
} catch (err) {
setError(err.message || "Unexpected Error!");
} finally {
setLoading(false);
}
};
return (
<div className="App">
<div>
<h1>Posts</h1>
{loading && <p>Posts are loading!</p>}
{error && <p>{error}</p>}
<ul>
{posts?.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
</div>
</div>
);
}
I know the example above isn’t the best code but at least it’s working and it’s valid code. I will try to improve that later. For now, we can just focus on the bare minimum things for calling an API.
Here, you can try to get posts data from JsonPlaceholer. Those are the most common steps we follow for calling an API like requesting data, handling loading, success, and error cases.
If we try to call another API from the same component then how that would gonna look? Let’s see.
500: Internal Server Error
Now it’s going insane! For calling two simple APIs we’ve done a lot of duplication. On a top-level view, the component is doing nothing but just making two GET requests and handling the success and error cases. For each request, it’s maintaining three states which will periodically increase later if we’ve more calls.
Let’s refactor to make the code more reusable with fewer repetitions.
Step 1: Create a Hook for the Redundant API Request Codes
Most of the repetitions we have done so far are about requesting data, handing the async things, handling errors, success, and loading states. How about encapsulating those things inside a hook?
The only unique things we are doing inside handleComments and handlePosts are calling different endpoints. The rest of the things are pretty much the same. So we can create a hook that will handle the redundant works for us and from outside we’ll let it know which API to call.
500: Internal Server Error
Here, this request function is identical to what we were doing on the handlePosts and handleComments. The only difference is, it’s calling an async function apiFunc which we will provide as a parameter with this hook. This apiFunc is the only independent thing among any of the API calls we need.
With hooks in action, let’s change our old codes in App component, like this:
500: Internal Server Error
How about the current code? Isn’t it beautiful without any repetitions and duplicate API call handling things?
Let’s continue our journey from the current code. We can make App component more elegant. Now it knows a lot of details about the underlying library for the API call. It shouldn’t know that. So, here’s the next step…
Step 2: One Component Should Take Just One Responsibility
Our App component knows too much about the API calling mechanism. Its responsibility should just request the data. How the data will be requested under the hood, it shouldn’t care about that.
We will extract the API client-related codes from the App component. Also, we will group all the API request-related codes based on the API resource. Now, this is our API client:
import axios from "axios";
const apiClient = axios.create({
// Later read this URL from an environment variable
baseURL: "https://jsonplaceholder.typicode.com"
});
export default apiClient;
All API calls for comments resource will be in the following file:
import client from "./client";
const getComments = () => client.get("/comments");
export default {
getComments
};
All API calls for posts resource are placed in the following file:
import client from "./client";
const getPosts = () => client.get("/posts");
export default {
getPosts
};
Finally, the App component looks like the following:
import "./styles.css";
import React, { useEffect } from "react";
import commentsApi from "./api/comments";
import postsApi from "./api/posts";
import useApi from "./hooks/useApi";
export default function App() {
const getPostsApi = useApi(postsApi.getPosts);
const getCommentsApi = useApi(commentsApi.getComments);
useEffect(() => {
getPostsApi.request();
getCommentsApi.request();
}, []);
return (
<div className="App">
{/* Post List */}
<div>
<h1>Posts</h1>
{getPostsApi.loading && <p>Posts are loading!</p>}
{getPostsApi.error && <p>{getPostsApi.error}</p>}
<ul>
{getPostsApi.data?.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
</div>
{/* Comment List */}
<div>
<h1>Comments</h1>
{getCommentsApi.loading && <p>Comments are loading!</p>}
{getCommentsApi.error && <p>{getCommentsApi.error}</p>}
<ul>
{getCommentsApi.data?.map((comment) => (
<li key={comment.id}>{comment.name}</li>
))}
</ul>
</div>
</div>
);
}
Now it doesn’t know anything about how the APIs get called. Tomorrow if we want to change the API calling library from axios to fetch or anything else, our App component code will not get affected. We can just change the codes form client.js This is the beauty of abstraction.
Apart from the abstraction of API calls, Appcomponent isn’t right the place to show the list of the posts and comments. It’s a high-level component. It shouldn’t handle such low-level data interpolation things.
So we should move this data display-related things to another low-level component. Here I placed those directly in the App component just for the demonstration purpose and not to distract with component composition-related things.
Final Thoughts
The React library gives the flexibility for using any kind of third-party library based on the application’s needs. As it doesn’t have any predefined architecture so different teams/developers adopted different approaches to developing applications with React. There’s nothing good or bad. We choose the development practice based on our needs/choices. One thing that is there beyond any choices is writing clean and maintainable codes.
You might also like

Will Leitch
3 years ago
Don't treat Elon Musk like Trump.
He’s not the President. Stop treating him like one.
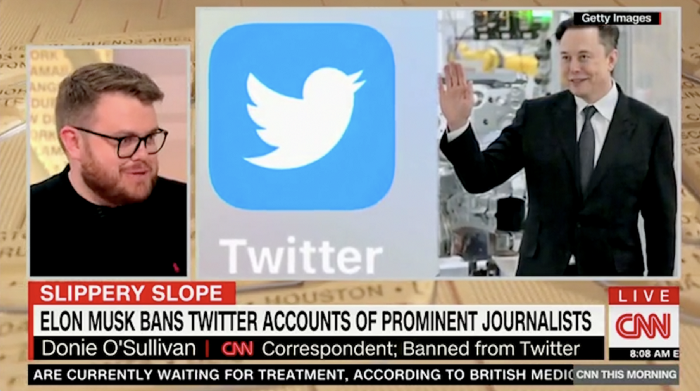
Elon Musk tweeted from Qatar, where he was watching the World Cup Final with Jared Kushner.
Musk's subsequent Tweets were as normal, basic, and bland as anyone's from a World Cup Final: It's depressing to see the world's richest man looking at his phone during a grand ceremony. Rich guy goes to rich guy event didn't seem important.
Before Musk posted his should-I-step-down-at-Twitter poll, CNN ran a long segment asking if it was hypocritical for him to reveal his real-time location after defending his (very dumb) suspension of several journalists for (supposedly) revealing his assassination coordinates by linking to a site that tracks Musks private jet. It was hard to ignore CNN's hypocrisy: It covered Musk as Twitter CEO like President Trump. EVERY TRUMP STORY WAS BASED ON HIM SAYING X, THEN DOING Y. Trump would do something horrific, lie about it, then pretend it was fine, then condemn a political rival who did the same thing, be called hypocritical, and so on. It lasted four years. Exhausting.
It made sense because Trump was the President of the United States. The press's main purpose is to relentlessly cover and question the president.
It's strange to say this out. Twitter isn't America. Elon Musk isn't a president. He maintains a money-losing social media service to harass and mock people he doesn't like. Treating Musk like Trump, as if he should be held accountable like Trump, shows a startling lack of perspective. Some journalists treat Twitter like a country.
The compulsive, desperate way many journalists utilize the site suggests as much. Twitter isn't the town square, despite popular belief. It's a place for obsessives to meet and converse. Journalists say they're breaking news. Their careers depend on it. They can argue it's a public service. Nope. It's a place lonely people go to speak all day. Twitter. So do journalists, Trump, and Musk. Acting as if it has a greater purpose, as if it's impossible to break news without it, or as if the republic is in peril is ludicrous. Only 23% of Americans are on Twitter, while 25% account for 97% of Tweets. I'd think a large portion of that 25% are journalists (or attention addicts) chatting to other journalists. Their loudness makes Twitter seem more important than it is. Nope. It's another stupid website. They were there before Twitter; they will be there after Twitter. It’s just a website. We can all get off it if we want. Most of us aren’t even on it in the first place.
Musk is a website-owner. No world leader. He's not as accountable as Trump was. Musk is cable news's primary character now that Trump isn't (at least for now). Becoming a TV news anchor isn't as significant as being president. Elon Musk isn't as important as we all pretend, and Twitter isn't even close. Twitter is a dumb website, Elon Musk is a rich guy going through a midlife crisis, and cable news is lazy because its leaders thought the entire world was on Twitter and are now freaking out that their playground is being disturbed.
I’ve said before that you need to leave Twitter, now. But even if you’re still on it, we need to stop pretending it matters more than it does. It’s a site for lonely attention addicts, from the man who runs it to the journalists who can’t let go of it. It’s not a town square. It’s not a country. It’s not even a successful website. Let’s stop pretending any of it’s real. It’s not.

Rajesh Gupta
3 years ago
Why Is It So Difficult to Give Up Smoking?

I started smoking in 2002 at IIT BHU. Most of us thought it was enjoyable at first. I didn't realize the cost later.
In 2005, during my final semester, I lost my father. Suddenly, I felt more accountable for my mother and myself.
I quit before starting my first job in Bangalore. I didn't see any smoking friends in my hometown for 2 months before moving to Bangalore.
For the next 5-6 years, I had no regimen and smoked only when drinking.
Due to personal concerns, I started smoking again after my 2011 marriage. Now smoking was a constant guilty pleasure.
I smoked 3-4 cigarettes a day, but never in front of my family or on weekends. I used to excuse this with pride! First office ritual: smoking. Even with guilt, I couldn't stop this time because of personal concerns.
After 8-9 years, in mid 2019, a personal development program solved all my problems. I felt complete in myself. After this, I just needed one cigarette each day.
The hardest thing was leaving this final cigarette behind, even though I didn't want it.
James Clear's Atomic Habits was published last year. I'd only read 2-3 non-tech books before reading this one in August 2021. I knew everything but couldn't use it.
In April 2022, I realized the compounding effect of a bad habit thanks to my subconscious mind. 1 cigarette per day (excluding weekends) equals 240 = 24 packs per year, which is a lot. No matter how much I did, it felt negative.
Then I applied the 2nd principle of this book, identifying the trigger. I tried to identify all the major triggers of smoking. I found social drinking is one of them & If I am able to control it during that time, I can easily control it in other situations as well. Going further whenever I drank, I was pre-determined to ignore the craving at any cost. Believe me, it was very hard initially but gradually this craving started fading away even with drinks.
I've been smoke-free for 3 months. Now I know a bad habit's effects. After realizing the power of habits, I'm developing other good habits which I ignored all my life.

The woman
3 years ago
Why Google's Hiring Process is Brilliant for Top Tech Talent
Without a degree and experience, you can get a high-paying tech job.

Most organizations follow this hiring rule: you chat with HR, interview with your future boss and other senior managers, and they make the final hiring choice.
If you've ever applied for a job, you know how arduous it can be. A newly snapped photo and a glossy resume template can wear you out. Applying to Google can change this experience.
According to an Universum report, Google is one of the world's most coveted employers. It's not simply the search giant's name and reputation that attract candidates, but its role requirements or lack thereof.
Candidates no longer need a beautiful resume, cover letter, Ivy League laurels, or years of direct experience. The company requires no degree or experience.
Elon Musk started it. He employed the two-hands test to uncover talented non-graduates. The billionaire eliminated the requirement for experience.
Google is deconstructing traditional employment with programs like the Google Project Management Degree, a free online and self-paced professional credential course.
Google's hiring is interesting. After its certification course, applicants can work in project management. Instead of academic degrees and experience, the company analyzes coursework.
Google finds the best project managers and technical staff in exchange. Google uses three strategies to find top talent.
Chase down the innovators
Google eliminates restrictions like education, experience, and others to find the polar bear amid the snowfall. Google's free project management education makes project manager responsibilities accessible to everyone.
Many jobs don't require a degree. Overlooking individuals without a degree can make it difficult to locate a candidate who can provide value to a firm.
Firsthand knowledge follows the same rule. A lack of past information might be an employer's benefit. This is true for creative teams or businesses that prefer to innovate.
Or when corporations conduct differently from the competition. No-experience candidates can offer fresh perspectives. Fast Company reports that people with no sales experience beat those with 10 to 15 years of experience.
Give the aptitude test first priority.
Google wants the best candidates. Google wouldn't be able to receive more applications if it couldn't screen them for fit. Its well-organized online training program can be utilized as a portfolio.
Google learns a lot about an applicant through completed assignments. It reveals their ability, leadership style, communication capability, etc. The course mimics the job to assess candidates' suitability.
Basic screening questions might provide information to compare candidates. Any size small business can use screening questions and test projects to evaluate prospective employees.
Effective training for employees
Businesses must train employees regardless of their hiring purpose. Formal education and prior experience don't guarantee success. Maintaining your employees' professional knowledge gaps is key to their productivity and happiness. Top-notch training can do that. Learning and development are key to employee engagement, says Bob Nelson, author of 1,001 Ways to Engage Employees.
Google's online certification program isn't available everywhere. Improving the recruiting process means emphasizing aptitude over experience and a degree. Instead of employing new personnel and having them work the way their former firm trained them, train them how you want them to function.
If you want to know more about Google’s recruiting process, we recommend you watch the movie “Internship.”