



More on Web3 & Crypto

Vitalik
4 years ago
An approximate introduction to how zk-SNARKs are possible (part 1)
You can make a proof for the statement "I know a secret number such that if you take the word ‘cow', add the number to the end, and SHA256 hash it 100 million times, the output starts with 0x57d00485aa". The verifier can verify the proof far more quickly than it would take for them to run 100 million hashes themselves, and the proof would also not reveal what the secret number is.
In the context of blockchains, this has 2 very powerful applications: Perhaps the most powerful cryptographic technology to come out of the last decade is general-purpose succinct zero knowledge proofs, usually called zk-SNARKs ("zero knowledge succinct arguments of knowledge"). A zk-SNARK allows you to generate a proof that some computation has some particular output, in such a way that the proof can be verified extremely quickly even if the underlying computation takes a very long time to run. The "ZK" part adds an additional feature: the proof can keep some of the inputs to the computation hidden.
You can make a proof for the statement "I know a secret number such that if you take the word ‘cow', add the number to the end, and SHA256 hash it 100 million times, the output starts with 0x57d00485aa". The verifier can verify the proof far more quickly than it would take for them to run 100 million hashes themselves, and the proof would also not reveal what the secret number is.
In the context of blockchains, this has two very powerful applications:
- Scalability: if a block takes a long time to verify, one person can verify it and generate a proof, and everyone else can just quickly verify the proof instead
- Privacy: you can prove that you have the right to transfer some asset (you received it, and you didn't already transfer it) without revealing the link to which asset you received. This ensures security without unduly leaking information about who is transacting with whom to the public.
But zk-SNARKs are quite complex; indeed, as recently as in 2014-17 they were still frequently called "moon math". The good news is that since then, the protocols have become simpler and our understanding of them has become much better. This post will try to explain how ZK-SNARKs work, in a way that should be understandable to someone with a medium level of understanding of mathematics.
Why ZK-SNARKs "should" be hard
Let us take the example that we started with: we have a number (we can encode "cow" followed by the secret input as an integer), we take the SHA256 hash of that number, then we do that again another 99,999,999 times, we get the output, and we check what its starting digits are. This is a huge computation.
A "succinct" proof is one where both the size of the proof and the time required to verify it grow much more slowly than the computation to be verified. If we want a "succinct" proof, we cannot require the verifier to do some work per round of hashing (because then the verification time would be proportional to the computation). Instead, the verifier must somehow check the whole computation without peeking into each individual piece of the computation.
One natural technique is random sampling: how about we just have the verifier peek into the computation in 500 different places, check that those parts are correct, and if all 500 checks pass then assume that the rest of the computation must with high probability be fine, too?
Such a procedure could even be turned into a non-interactive proof using the Fiat-Shamir heuristic: the prover computes a Merkle root of the computation, uses the Merkle root to pseudorandomly choose 500 indices, and provides the 500 corresponding Merkle branches of the data. The key idea is that the prover does not know which branches they will need to reveal until they have already "committed to" the data. If a malicious prover tries to fudge the data after learning which indices are going to be checked, that would change the Merkle root, which would result in a new set of random indices, which would require fudging the data again... trapping the malicious prover in an endless cycle.
But unfortunately there is a fatal flaw in naively applying random sampling to spot-check a computation in this way: computation is inherently fragile. If a malicious prover flips one bit somewhere in the middle of a computation, they can make it give a completely different result, and a random sampling verifier would almost never find out.
It only takes one deliberately inserted error, that a random check would almost never catch, to make a computation give a completely incorrect result.
If tasked with the problem of coming up with a zk-SNARK protocol, many people would make their way to this point and then get stuck and give up. How can a verifier possibly check every single piece of the computation, without looking at each piece of the computation individually? There is a clever solution.
see part 2

Robert Kim
4 years ago
Crypto Legislation Might Progress Beyond Talk in 2022
Financial regulators have for years attempted to apply existing laws to the multitude of issues created by digital assets. In 2021, leading federal regulators and members of Congress have begun to call for legislation to address these issues. As a result, 2022 may be the year when federal legislation finally addresses digital asset issues that have been growing since the mining of the first Bitcoin block in 2009.
Digital Asset Regulation in the Absence of Legislation
So far, Congress has left the task of addressing issues created by digital assets to regulatory agencies. Although a Congressional Blockchain Caucus formed in 2016, House and Senate members introduced few bills addressing digital assets until 2018. As of October 2021, Congress has not amended federal laws on financial regulation, which were last significantly revised by the Dodd-Frank Act in 2010, to address digital asset issues.
In the absence of legislation, issues that do not fit well into existing statutes have created problems. An example is the legal status of digital assets, which can be considered to be either securities or commodities, and can even shift from one to the other over time. Years after the SEC’s 2017 report applying the definition of a security to digital tokens, the SEC and the CFTC have yet to clarify the distinction between securities and commodities for the thousands of digital assets in existence.
SEC Chair Gary Gensler has called for Congress to act, stating in August, “We need additional Congressional authorities to prevent transactions, products, and platforms from falling between regulatory cracks.” Gensler has reached out to Sen. Elizabeth Warren (D-Ma.), who has expressed her own concerns about the need for legislation.
Legislation on Digital Assets in 2021
While regulators and members of Congress talked about the need for legislation, and the debate over cryptocurrency tax reporting in the 2021 infrastructure bill generated headlines, House and Senate bills proposing specific solutions to various issues quietly started to emerge.
Digital Token Sales
Several House bills attempt to address securities law barriers to digital token sales—some of them by building on ideas proposed by regulators in past years.
Exclusion from the definition of a security. Congressional Blockchain Caucus members have been introducing bills to exclude digital tokens from the definition of a security since 2018, and they have revived those bills in 2021. They include the Token Taxonomy Act of 2021 (H.R. 1628), successor to identically named bills in 2018 and 2019, and the Securities Clarity Act (H.R. 4451), successor to a 2020 namesake.
Safe harbor. SEC Commissioner Hester Peirce proposed a regulatory safe harbor for token sales in 2020, and two 2021 bills have proposed statutory safe harbors. Rep. Patrick McHenry (R-N.C.), Republican leader of the House Financial Services Committee, introduced a Clarity for Digital Tokens Act of 2021 (H.R. 5496) that would amend the Securities Act to create a safe harbor providing a grace period of exemption from Securities Act registration requirements. The Digital Asset Market Structure and Investor Protection Act (H.R. 4741) from Rep. Don Beyer (D-Va.) would amend the Securities Exchange Act to define a new type of security—a “digital asset security”—and add issuers of digital asset securities to an existing provision for delayed registration of securities.
Stablecoins
Stablecoins—digital currencies linked to the value of the U.S. dollar or other fiat currencies—have not yet been the subject of regulatory action, although Treasury Secretary Janet Yellen and Federal Reserve Chair Jerome Powell have each underscored the need to create a regulatory framework for them. The Beyer bill proposes to create a regulatory regime for stablecoins by amending Title 31 of the U.S. Code. Treasury Department approval would be required for any “digital asset fiat-based stablecoin” to be issued or used, under an application process to be established by Treasury in consultation with the Federal Reserve, the SEC, and the CFTC.
Serious consideration for any of these proposals in the current session of Congress may be unlikely. A spate of autumn bills on crypto ransom payments (S. 2666, S. 2923, S. 2926, H.R. 5501) shows that Congress is more inclined to pay attention first to issues that are more spectacular and less arcane. Moreover, the arcaneness of digital asset regulatory issues is likely only to increase further, now that major industry players such as Coinbase and Andreessen Horowitz are starting to roll out their own regulatory proposals.
Digital Dollar vs. Digital Yuan
Impetus to pass legislation on another type of digital asset, a central bank digital currency (CBDC), may come from a different source: rivalry with China.
China established itself as a world leader in developing a CBDC with a pilot project launched in 2020, and in 2021, the People’s Bank of China announced that its CBDC will be used at the Beijing Winter Olympics in February 2022. Republican Senators responded by calling for the U.S. Olympic Committee to forbid use of China’s CBDC by U.S. athletes in Beijing and introducing a bill (S. 2543) to require a study of its national security implications.
The Beijing Olympics could motivate a legislative mandate to accelerate implementation of a U.S. digital dollar, which the Federal Reserve has been in the process of considering in 2021. Antecedents to such legislation already exist. A House bill sponsored by 46 Republicans (H.R. 4792) has a provision that would require the Treasury Department to assess China’s CBDC project and report on the status of Federal Reserve work on a CBDC, and the Beyer bill includes a provision amending the Federal Reserve Act to authorize issuing a digital dollar.
Both parties are likely to support creating a digital dollar. The Covid-19 pandemic made a digital dollar for delivery of relief payments a popular idea in 2020, and House Democrats introduced bills with provisions for creating one in 2020 and 2021. Bipartisan support for a bill on a digital dollar, based on concerns both foreign and domestic in nature, could result.
International rivalry and bipartisan support may make the digital dollar a gateway issue for digital asset legislation in 2022. Legislative work on a digital dollar may open the door for considering further digital asset issues—including the regulatory issues that have been emerging for years—in 2022 and beyond.

Sam Bourgi
4 years ago
NFT was used to serve a restraining order on an anonymous hacker.
The international law firm Holland & Knight used an NFT built and airdropped by its asset recovery team to serve a defendant in a hacking case.
The law firms Holland & Knight and Bluestone used a nonfungible token to serve a defendant in a hacking case with a temporary restraining order, marking the first documented legal process assisted by an NFT.
The so-called "service token" or "service NFT" was served to an unknown defendant in a hacking case involving LCX, a cryptocurrency exchange based in Liechtenstein that was hacked for over $8 million in January. The attack compromised the platform's hot wallets, resulting in the loss of Ether (ETH), USD Coin (USDC), and other cryptocurrencies, according to Cointelegraph at the time.
On June 7, LCX claimed that around 60% of the stolen cash had been frozen, with investigations ongoing in Liechtenstein, Ireland, Spain, and the United States. Based on a court judgment from the New York Supreme Court, Centre Consortium, a company created by USDC issuer Circle and crypto exchange Coinbase, has frozen around $1.3 million in USDC.
The monies were laundered through Tornado Cash, according to LCX, but were later tracked using "algorithmic forensic analysis." The organization was also able to identify wallets linked to the hacker as a result of the investigation.
In light of these findings, the law firms representing LCX, Holland & Knight and Bluestone, served the unnamed defendant with a temporary restraining order issued on-chain using an NFT. According to LCX, this system "was allowed by the New York Supreme Court and is an example of how innovation can bring legitimacy and transparency to a market that some say is ungovernable."
You might also like

Sammy Abdullah
3 years ago
R&D, S&M, and G&A expense ratios for SaaS
SaaS spending is 40/40/20. 40% of operating expenses should be R&D, 40% sales and marketing, and 20% G&A. We wanted to see the statistics behind the rules of thumb. Since October 2017, 73 SaaS startups have gone public. Perhaps the rule of thumb should be 30/50/20. The data is below.
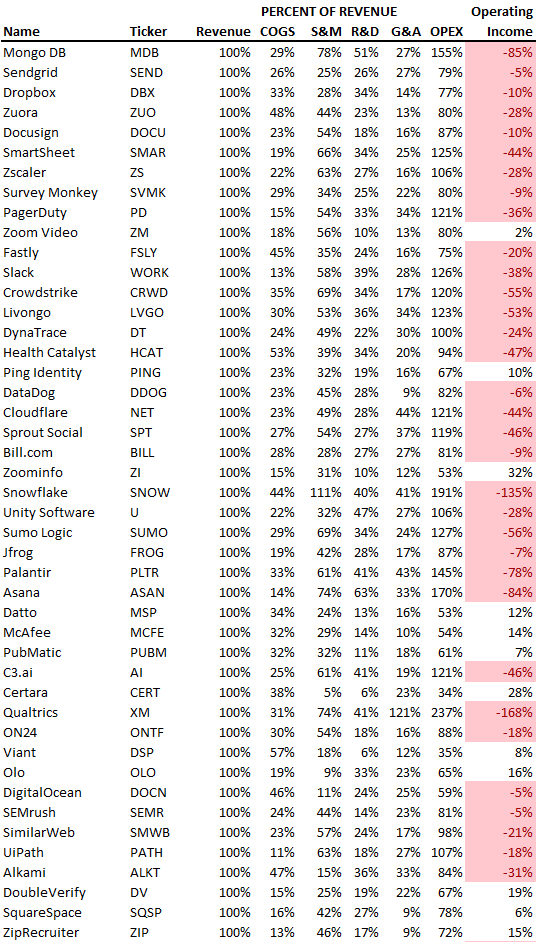
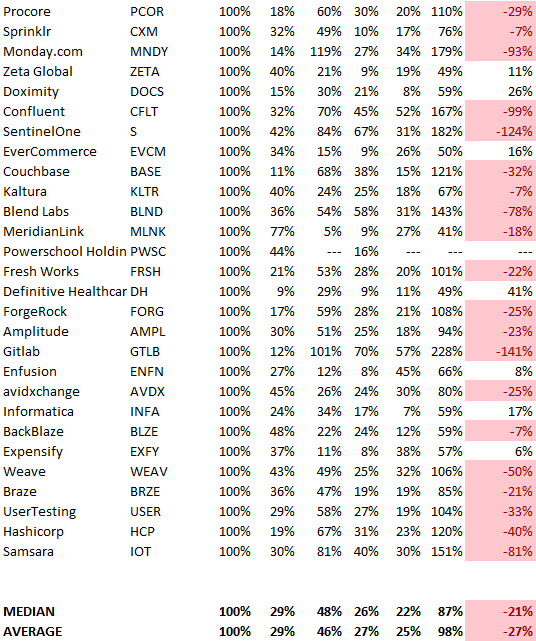
30/50/20. R&D accounts for 26% of opex, sales and marketing 48%, and G&A 22%. We think R&D/S&M/G&A should be 30/50/20.
There are outliers. There are exceptions to rules of thumb. Dropbox spent 45% on R&D whereas Zoom spent 13%. Zoom spent 73% on S&M, Dropbox 37%, and Bill.com 28%. Snowflake spent 130% of revenue on S&M, while their EBITDA margin is -192%.
G&A shouldn't stand out. Minimize G&A spending. Priorities should be product development and sales. Cloudflare, Sendgrid, Snowflake, and Palantir spend 36%, 34%, 37%, and 43% on G&A.
Another myth is that COGS is 20% of revenue. Median and averages are 29%.
Where is the profitability? Data-driven operating income calculations were simplified (Revenue COGS R&D S&M G&A). 20 of 73 IPO businesses reported operational income. Median and average operating income margins are -21% and -27%.
As long as you're growing fast, have outstanding retention, and marquee clients, you can burn cash since recurring income that doesn't churn is a valuable annuity.
The data was compelling overall. 30/50/20 is the new 40/40/20 for more established SaaS enterprises, unprofitability is alright as long as your business is expanding, and COGS can be somewhat more than 20% of revenue.

Muthinja
3 years ago
Why don't you relaunch my startup projects?
Open to ideas or acquisitions
Failure is an unavoidable aspect of life, yet many recoil at the word.

I've worked on unrelated startup projects. This is a list of products I developed (often as the tech lead or co-founder) and why they failed to launch.
Chess Bet (Betting)
As a chess player who plays 5 games a day and has an ELO rating of 2100, I tried to design a chess engine to rival stockfish and Houdini.
While constructing my chess engine, my cofounder asked me about building a p2p chess betting app. Chess Bet. There couldn't be a better time.
Two people in different locations could play a staked game. The winner got 90% of the bet and we got 10%. The business strategy was clear, but our mini-launch was unusual.
People started employing the same cheat engines I mentioned, causing user churn and defaming our product.
It was the first programming problem I couldn't solve after building a cheat detection system based on player move strengths and prior games. Chess.com, the most famous online chess software, still suffers from this.
We decided to pivot because we needed an expensive betting license.
We relaunched as Chess MVP after deciding to focus on chess learning. A platform for teachers to create chess puzzles and teach content. Several chess students used our product, but the target market was too tiny.
We chose to quit rather than persevere or pivot.
BodaCare (Insure Tech)
‘BodaBoda’ in Swahili means Motorcycle. My Dad approached me in 2019 (when I was working for a health tech business) about establishing an Insurtech/fintech solution for motorbike riders to pay for insurance using SNPL.
We teamed up with an underwriter to market motorcycle insurance. Once they had enough premiums, they'd get an insurance sticker in the mail. We made it better by splitting the cover in two, making it more reasonable for motorcyclists struggling with lump-sum premiums.
Lack of capital and changing customer behavior forced us to close, with 100 motorcyclists paying 0.5 USD every day. Our unit econ didn't make sense, and CAC and retention capital only dug us deeper.
Circle (Social Networking)
Having learned from both product failures, I began to understand what worked and what didn't. While reading through Instagram, an idea struck me.
Suppose social media weren't virtual.
Imagine meeting someone on your way home. Like-minded person
People were excited about social occasions after covid restrictions were eased. Anything to escape. I just built a university student-popular experiences startup. Again, there couldn't be a better time.
I started the Android app. I launched it on Google Beta and oh my! 200 people joined in two days.
It works by signaling if people are in a given place and allowing users to IM in hopes of meeting up in near real-time. Playstore couldn't deploy the app despite its success in beta for unknown reasons. I appealed unsuccessfully.
My infrastructure quickly lost users because I lacked funding.
In conclusion
This essay contains many failures, some of which might have been avoided and others not, but they were crucial learning points in my startup path.
If you liked any idea, I have the source code on Github.
Happy reading until then!
Vanessa Karel
3 years ago
10 hard lessons from founding a startup.
Here is the ugly stuff, read this if you have a founder in your life or are trying to become one. Your call.

#1 You'll try to talk yourself to sleep, but it won't always work.
As founders, we're all driven. Good and bad, you're restless. Success requires resistance and discipline. Your startup will be on your mind 24/7, and not everyone will have the patience to listen to your worries, ideas, and coffee runs. You become more self-sufficient than ever before.
#2 No one will understand what you're going through unless they've been a founder.
Some of my closest friends don't understand the work that goes into starting a business, and we can't blame them.
#3 You'll feel alienated.
Your problems aren't common; calling your bestie won't help. You must search hard for the right resources. It alienates you from conversations you no longer relate to. (No 4th of July, no long weekends!)
#4 Since you're your "own boss," people assume you have lots of free time.
Do you agree? I was on a webinar with lots of new entrepreneurs, and one woman said, "I started my own business so I could have more time for myself." This may be true for some lucky people, and you can be flexible with your schedule. If you want your business to succeed, you'll probably be its slave for a while.
#5 No time for illness or family emergencies.
Both last month. Oh, no! Physically and emotionally withdrawing at the worst times will give you perspective. I learned this the hard way because I was too stubborn to postpone an important interview. I thought if I rested all day and only took one call, I'd be fine. Nope. I had a fever and my mind wasn't as sharp, so my performance and audience interaction suffered. Nope. Better to delay than miss out.
Oh, and setting a "OoO" makes you cringe.
#6 Good luck with your mental health, perfectionists.
When building a startup, it's difficult to accept that there won't be enough time to do everything. You can't make them all, not perfectly. You must learn to accept things that are done but not perfect.
#7 As a founder, you'll make mistakes, but you'll want to make them quickly so you can learn.
Hard lessons are learned quicker. You'll need to pivot and try new things often; some won't work, and it's best to discover them sooner rather than later.
#8 Pyramid schemes abound.
I didn't realize how bad it was until I started a company. You must spy and constantly research. As a founder, you'll receive many emails from people claiming to "support" you. Be wary and keep your eyes open. When it's too good to be true. Some "companies" will try to get you to pay for "competitions" to "pitch at events." Don't do it.
#9 Keep your competitor research to a minimum.
Actually, competition is good. It means there's a market for those solutions. However, this can be mentally exhausting too. Learn about their geography and updates, but that's it.
#10 You'll feel guilty taking vacation.
I don't know what to say, but I no longer enjoy watching TV, and that's okay. Pay attention to things that enrich you, bring you joy, and have fun. It boosts creativity.
Being a startup founder may be one of the hardest professional challenges you face, but it's also a great learning experience. Your passion will take you places you never imagined and open doors to opportunities you wouldn't have otherwise. You'll meet amazing people. No regrets, no complaints. It's a roller coaster, but the good days are great.
Miss anything? Comment below