



More on NFTs & Art

xuanling11
3 years ago
Reddit NFT Achievement

Reddit's NFT market is alive and well.
NFT owners outnumber OpenSea on Reddit.
Reddit NFTs flip in OpenSea in days:
Fast-selling.
NFT sales will make Reddit's current communities more engaged.
I don't think NFTs will affect existing groups, but they will build hype for people to acquire them.
The first season of Collectibles is unique, but many missed the first season.
Second-season NFTs are less likely to be sold for a higher price than first-season ones.
If you use Reddit, it's fun to own NFTs.
Dmytro Spilka
3 years ago
Why NFTs Have a Bright Future Away from Collectible Art After Punks and Apes

After a crazy second half of 2021 and significant trade volumes into 2022, the market for NFT artworks like Bored Ape Yacht Club, CryptoPunks, and Pudgy Penguins has begun a sharp collapse as market downturns hit token values.
DappRadar data shows NFT monthly sales have fallen below $1 billion since June 2021. OpenSea, the world's largest NFT exchange, has seen sales volume decline 75% since May and is trading like July 2021.
Prices of popular non-fungible tokens have also decreased. Bored Ape Yacht Club (BAYC) has witnessed volume and sales drop 63% and 15%, respectively, in the past month.
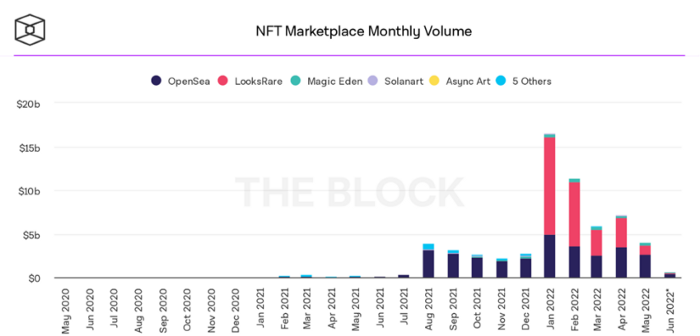
BeInCrypto analysis shows market decline. May 2022 cryptocurrency marketplace volume was $4 billion, according to a news platform. This is a sharp drop from April's $7.18 billion.
OpenSea, a big marketplace, contributed $2.6 billion, while LooksRare, Magic Eden, and Solanart also contributed.
NFT markets are digital platforms for buying and selling tokens, similar stock trading platforms. Although some of the world's largest exchanges offer NFT wallets, most users store their NFTs on their favorite marketplaces.
In January 2022, overall NFT sales volume was $16.57 billion, with LooksRare contributing $11.1 billion. May 2022's volume was $12.57 less than January, a 75% drop, and June's is expected to be considerably smaller.
A World Based on Utility
Despite declines in NFT trading volumes, not all investors are negative on NFTs. Although there are uncertainties about the sustainability of NFT-based art collections, there are fewer reservations about utility-based tokens and their significance in technology's future.
In June, business CEO Christof Straub said NFTs may help artists monetize unreleased content, resuscitate catalogs, establish deeper fan connections, and make processes more efficient through technology.
We all know NFTs can't be JPEGs. Straub noted that NFT music rights can offer more equitable rewards to musicians.
Music NFTs are here to stay if they have real value, solve real problems, are trusted and lawful, and have fair and sustainable business models.
NFTs can transform numerous industries, including music. Market opinion is shifting towards tokens with more utility than the social media artworks we're used to seeing.
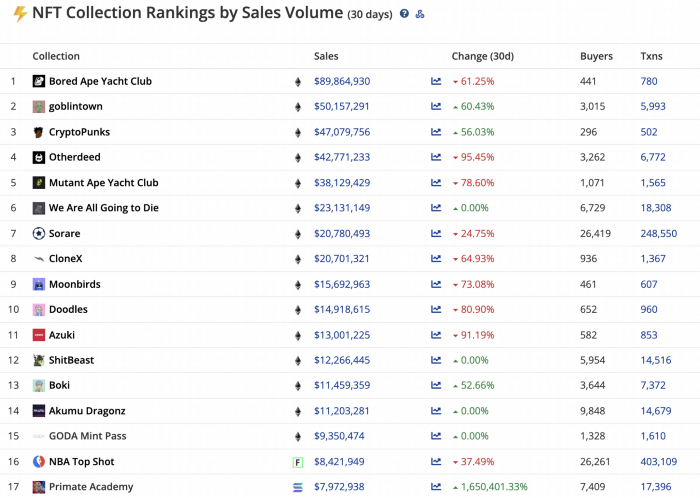
While the major NFT names remain dominant in terms of volume, new utility-based initiatives are emerging as top 20 collections.
Otherdeed, Sorare, and NBA Top Shot are NFT-based games that rank above Bored Ape Yacht Club and Cryptopunks.
Users can switch video NFTs of basketball players in NBA Top Shot. Similar efforts are emerging in the non-fungible landscape.
Sorare shows how NFTs can support a new way of playing fantasy football, where participants buy and swap trading cards to create a 5-player team that wins rewards based on real-life performances.
Sorare raised 579.7 million in one of Europe's largest Series B financing deals in September 2021. Recently, the platform revealed plans to expand into Major League Baseball.
Strong growth indications suggest a promising future for NFTs. The value of art-based collections like BAYC and CryptoPunks may be questioned as markets become diluted by new limited collections, but the potential for NFTs to become intrinsically linked to tangible utility like online gaming, music and art, and even corporate reward schemes shows the industry has a bright future.

Boris Müller
3 years ago
Why Do Websites Have the Same Design?
My kids redesigned the internet because it lacks inventiveness.

Internet today is bland. Everything is generic: fonts, layouts, pages, and visual language. Microtypography is messy.
Web design today seems dictated by technical and ideological constraints rather than creativity and ideas. Text and graphics are in containers on every page. All design is assumed.
Ironically, web technologies can design a lot. We can execute most designs. We make shocking, evocative websites. Experimental typography, generating graphics, and interactive experiences are possible.
Even designer websites use containers in containers. Dribbble and Behance, the two most popular creative websites, are boring. Lead image.
How did this happen?
Several reasons. WordPress and other blogging platforms use templates. These frameworks build web pages by combining graphics, headlines, body content, and videos. Not designs, templates. These rules combine related data types. These platforms don't let users customize pages beyond the template. You filled the template.
Templates are content-neutral. Thus, the issue.
Form should reflect and shape content, which is a design principle. Separating them produces content containers. Templates have no design value.
One of the fundamental principles of design is a deep and meaningful connection between form and content.
Web design lacks imagination for many reasons. Most are pragmatic and economic. Page design takes time. Large websites lack the resources to create a page from scratch due to the speed of internet news and the frequency of new items. HTML, JavaScript, and CSS continue to challenge web designers. Web design can't match desktop publishing's straightforward operations.
Designers may also be lazy. Mobile-first, generic, framework-driven development tends to ignore web page visual and contextual integrity.
How can we overcome this? How might expressive and avant-garde websites look today?
Rediscovering the past helps design the future.
'90s-era web design
At the University of the Arts Bremen's research and development group, I created my first website 23 years ago. Web design was trendy. Young web. Pages inspired me.
We struggled with HTML in the mid-1990s. Arial, Times, and Verdana were the only web-safe fonts. Anything exciting required table layouts, monospaced fonts, or GIFs. HTML was originally content-driven, thus we had to work against it to create a page.
Experimental typography was booming. Designers challenged the established quo from Jan Tschichold's Die Neue Typographie in the twenties to April Greiman's computer-driven layouts in the eighties. By the mid-1990s, an uncommon confluence of technological and cultural breakthroughs enabled radical graphic design. Irma Boom, David Carson, Paula Scher, Neville Brody, and others showed it.
Early web pages were dull compared to graphic design's aesthetic explosion. The Web Design Museum shows this.
Nobody knew how to conduct browser-based graphic design. Web page design was undefined. No standards. No CMS (nearly), CSS, JS, video, animation.
Now is as good a time as any to challenge the internet’s visual conformity.
In 2018, everything is browser-based. Massive layouts to micro-typography, animation, and video. How do we use these great possibilities? Containerized containers. JavaScript-contaminated mobile-first pages. Visually uniform templates. Web design 23 years later would disappoint my younger self.
Our imagination, not technology, restricts web design. We're too conformist to aesthetics, economics, and expectations.
Crisis generates opportunity. Challenge online visual conformity now. I'm too old and bourgeois to develop a radical, experimental, and cutting-edge website. I can ask my students.
I taught web design at the Potsdam Interface Design Programme in 2017. Each team has to redesign a website. Create expressive, inventive visual experiences on the browser. Create with contemporary web technologies. Avoid usability, readability, and flexibility concerns. Act. Ignore Erwartungskonformität.
The class outcome pleased me. This overview page shows all results. Four diverse projects address the challenge.
1. ZKM by Frederic Haase and Jonas Köpfer
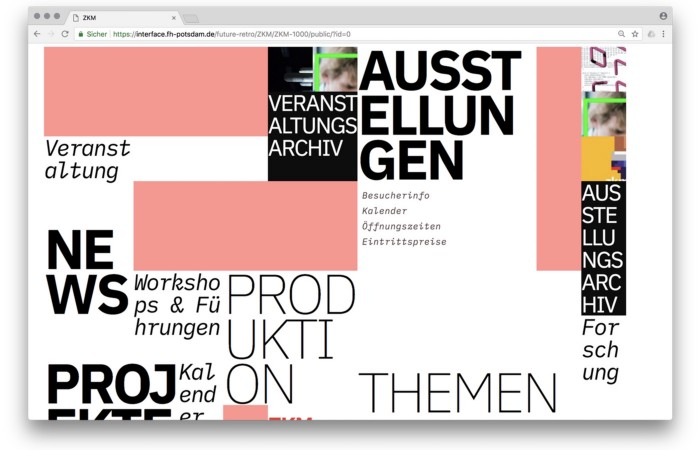
Frederic and Jonas began their experiments on the ZKM website. The ZKM is Germany's leading media art exhibition location, but its website remains conventional. It's useful but not avant-garde like the shows' art.
Frederic and Jonas designed the ZKM site's concept, aesthetic language, and technical configuration to reflect the museum's progressive approach. A generative design engine generates new layouts for each page load.
ZKM redesign.
2. Streem by Daria Thies, Bela Kurek, and Lucas Vogel

Street art magazine Streem. It promotes new artists and societal topics. Streem includes artwork, painting, photography, design, writing, and journalism. Daria, Bela, and Lucas used these influences to develop a conceptual metropolis. They designed four neighborhoods to reflect magazine sections for their prototype. For a legible city, they use powerful illustrative styles and spatial typography.
Streem makeover.
3. Medium by Amelie Kirchmeyer and Fabian Schultz
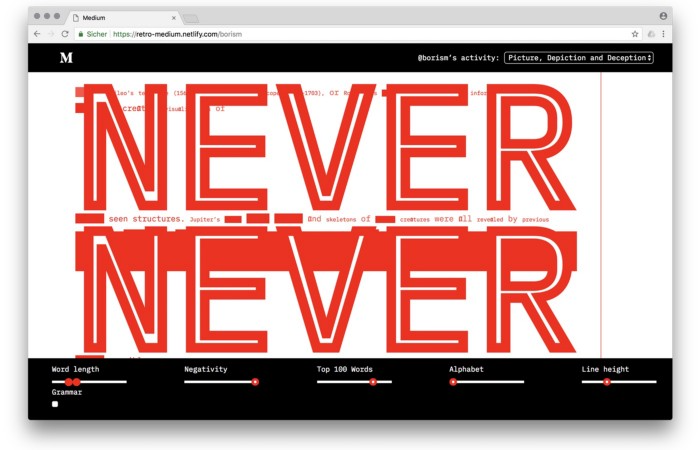
Amelie and Fabian structured. Instead of developing a form for a tale, they dissolved a web page into semantic, syntactical, and statistical aspects. HTML's flexibility was their goal. They broke Medium posts into experimental typographic space.
Medium revamp.
4. Hacker News by Fabian Dinklage and Florian Zia
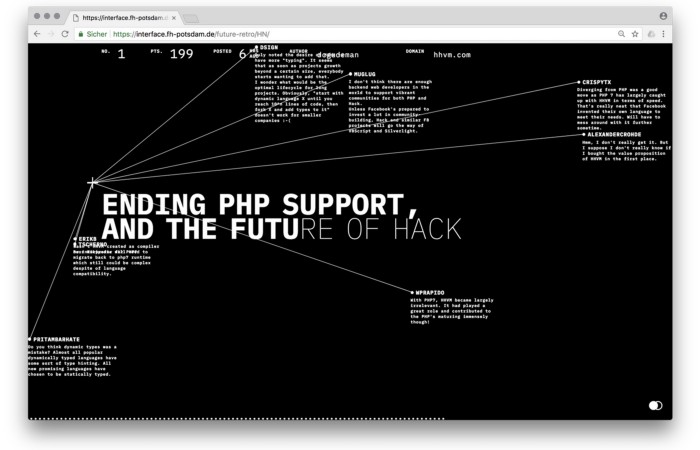
Florian and Fabian made Hacker News interactive. The social networking site aggregates computer science and IT news. Its voting and debate features are extensive despite its simple style. Fabian and Florian transformed the structure into a typographic timeline and network area. News and comments sequence and connect the visuals. To read Hacker News, they connected their design to the API. Hacker News makeover.
Communication is not legibility, said Carson. Apply this to web design today. Modern websites must be legible, usable, responsive, and accessible. They shouldn't limit its visual palette. Visual and human-centered design are not stereotypes.
I want radical, generative, evocative, insightful, adequate, content-specific, and intelligent site design. I want to rediscover web design experimentation. More surprises please. I hope the web will appear different in 23 years.
Update: this essay has sparked a lively discussion! I wrote a brief response to the debate's most common points: Creativity vs. Usability
You might also like

Amelia Winger-Bearskin
3 years ago
Reasons Why AI-Generated Images Remind Me of Nightmares
AI images are like funhouse mirrors.
Google's AI Blog introduced the puppy-slug in the summer of 2015.

Puppy-slug isn't a single image or character. "Puppy-slug" refers to Google's DeepDream's unsettling psychedelia. This tool uses convolutional neural networks to train models to recognize dataset entities. If researchers feed the model millions of dog pictures, the network will learn to recognize a dog.
DeepDream used neural networks to analyze and classify image data as well as generate its own images. DeepDream's early examples were created by training a convolutional network on dog images and asking it to add "dog-ness" to other images. The models analyzed images to find dog-like pixels and modified surrounding pixels to highlight them.
Puppy-slugs and other DeepDream images are ugly. Even when they don't trigger my trypophobia, they give me vertigo when my mind tries to reconcile familiar features and forms in unnatural, physically impossible arrangements. I feel like I've been poisoned by a forbidden mushroom or a noxious toad. I'm a Lovecraft character going mad from extradimensional exposure. They're gross!
Is this really how AIs see the world? This is possibly an even more unsettling topic that DeepDream raises than the blatant abjection of the images.
When these photographs originally circulated online, many friends were startled and scandalized. People imagined a computer's imagination would be literal, accurate, and boring. We didn't expect vivid hallucinations and organic-looking formations.
DeepDream's images didn't really show the machines' imaginations, at least not in the way that scared some people. DeepDream displays data visualizations. DeepDream reveals the "black box" of convolutional network training.
Some of these images look scary because the models don't "know" anything, at least not in the way we do.
These images are the result of advanced algorithms and calculators that compare pixel values. They can spot and reproduce trends from training data, but can't interpret it. If so, they'd know dogs have two eyes and one face per head. If machines can think creatively, they're keeping it quiet.
You could be forgiven for thinking otherwise, given OpenAI's Dall-impressive E's results. From a technological perspective, it's incredible.
Arthur C. Clarke once said, "Any sufficiently advanced technology is indistinguishable from magic." Dall-magic E's requires a lot of math, computer science, processing power, and research. OpenAI did a great job, and we should applaud them.
Dall-E and similar tools match words and phrases to image data to train generative models. Matching text to images requires sorting and defining the images. Untold millions of low-wage data entry workers, content creators optimizing images for SEO, and anyone who has used a Captcha to access a website make these decisions. These people could live and die without receiving credit for their work, even though the project wouldn't exist without them.
This technique produces images that are less like paintings and more like mirrors that reflect our own beliefs and ideals back at us, albeit via a very complex prism. Due to the limitations and biases that these models portray, we must exercise caution when viewing these images.
The issue was succinctly articulated by artist Mimi Onuoha in her piece "On Algorithmic Violence":
As we continue to see the rise of algorithms being used for civic, social, and cultural decision-making, it becomes that much more important that we name the reality that we are seeing. Not because it is exceptional, but because it is ubiquitous. Not because it creates new inequities, but because it has the power to cloak and amplify existing ones. Not because it is on the horizon, but because it is already here.

TheRedKnight
4 years ago
Say goodbye to Ponzi yields - A new era of decentralized perpetual
Decentralized perpetual may be the next crypto market boom; with tons of perpetual popping up, let's look at two protocols that offer organic, non-inflationary yields.
Decentralized derivatives exchanges' market share has increased tenfold in a year, but it's still 2% of CEXs'. DEXs have a long way to go before they can compete with centralized exchanges in speed, liquidity, user experience, and composability.
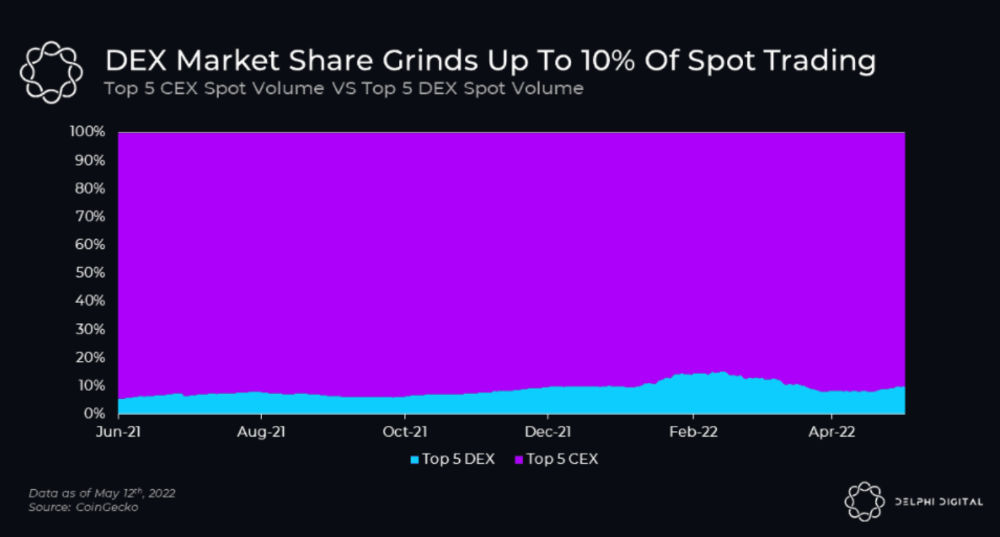
I'll cover gains.trade and GMX protocol in Polygon, Avalanche, and Arbitrum. Both protocols support leveraged perpetual crypto, stock, and Forex trading.
Why these protocols?
Decentralized GMX Gains protocol
Organic yield: path to sustainability
I've never trusted Defi's non-organic yields. Example: XYZ protocol. 20–75% of tokens may be set aside as farming rewards to provide liquidity, according to tokenomics.
Say you provide ETH-USDC liquidity. They advertise a 50% APR reward for this pair, 10% from trading fees and 40% from farming rewards. Only 10% is real, the rest is "Ponzi." The "real" reward is in protocol tokens.
Why keep this token? Governance voting or staking rewards are promoted services.
Most liquidity providers expect compensation for unused tokens. Basic psychological principles then? — Profit.
Nobody wants governance tokens. How many out of 100 care about the protocol's direction and will vote?
Staking increases your token's value. Currently, they're mostly non-liquid. If the protocol is compromised, you can't withdraw funds. Most people are sceptical of staking because of this.
"Free tokens," lack of use cases, and skepticism lead to tokens moving south. No farming reward protocols have lasted.
It may have shown strength in a bull market, but what about a bear market?
What is decentralized perpetual?
A perpetual contract is a type of futures contract that doesn't expire. So one can hold a position forever.
You can buy/sell any leveraged instruments (Long-Short) without expiration.
In centralized exchanges like Binance and coinbase, fees and revenue (liquidation) go to the exchanges, not users.
Users can provide liquidity that traders can use to leverage trade, and the revenue goes to liquidity providers.
Gains.trade and GMX protocol are perpetual trading platforms with a non-inflationary organic yield for liquidity providers.
GMX protocol
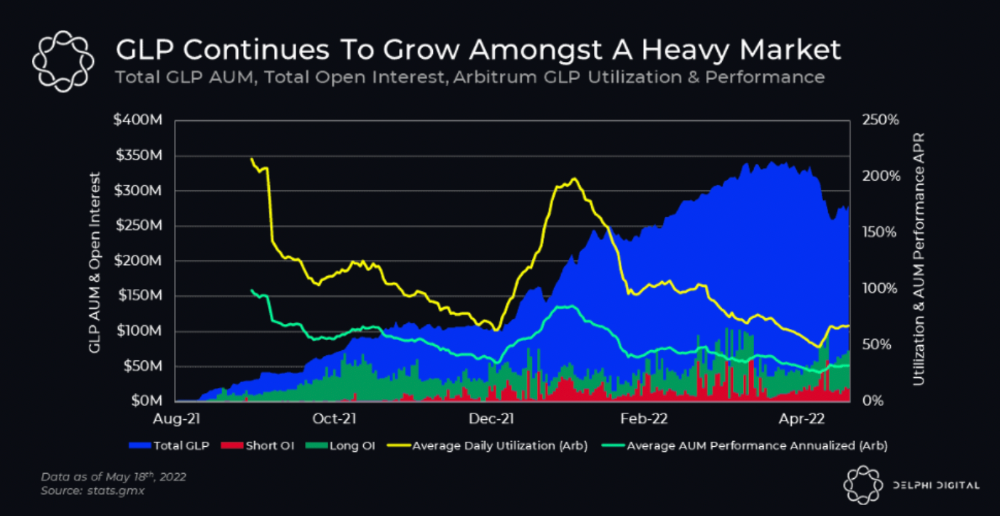
GMX is an Arbitrum and Avax protocol that rewards in ETH and Avax. GLP uses a fast oracle to borrow the "true price" from other trading venues, unlike a traditional AMM.
GLP and GMX are protocol tokens. GLP is used for leveraged trading, swapping, etc.
GLP is a basket of tokens, including ETH, BTC, AVAX, stablecoins, and UNI, LINK, and Stablecoins.
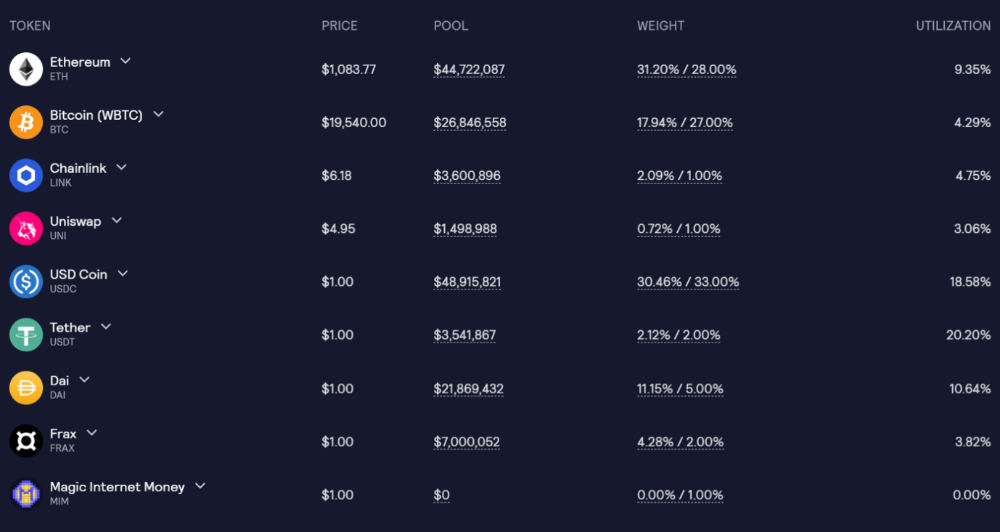
GLP composition on arbitrum
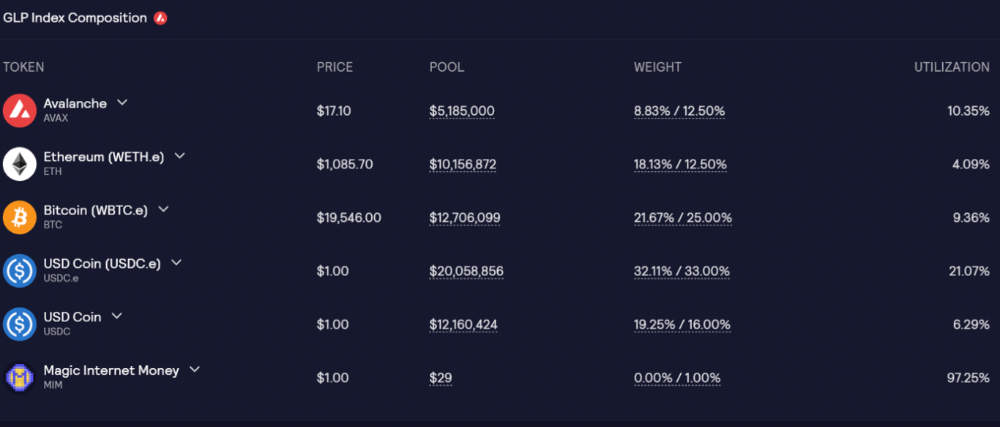
GLP composition on Avalanche
GLP token rebalances based on usage, providing liquidity without loss.
Protocol "runs" on Staking GLP. Depending on their chain, the protocol will reward users with ETH or AVAX. Current rewards are 22 percent (15.71 percent in ETH and the rest in escrowed GMX) and 21 percent (15.72 percent in AVAX and the rest in escrowed GMX). escGMX and ETH/AVAX percentages fluctuate.
Where is the yield coming from?
Swap fees, perpetual interest, and liquidations generate yield. 70% of fees go to GLP stakers, 30% to GMX. Organic yields aren't paid in inflationary farm tokens.
Escrowed GMX is vested GMX that unlocks in 365 days. To fully unlock GMX, you must farm the Escrowed GMX token for 365 days. That means less selling pressure for the GMX token.
GMX's status
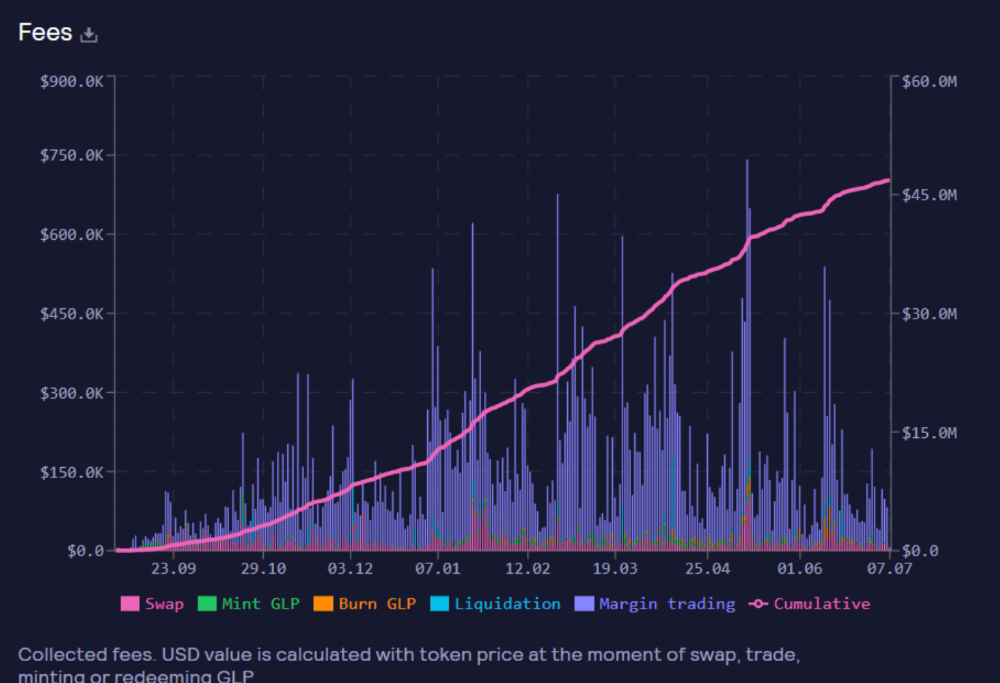
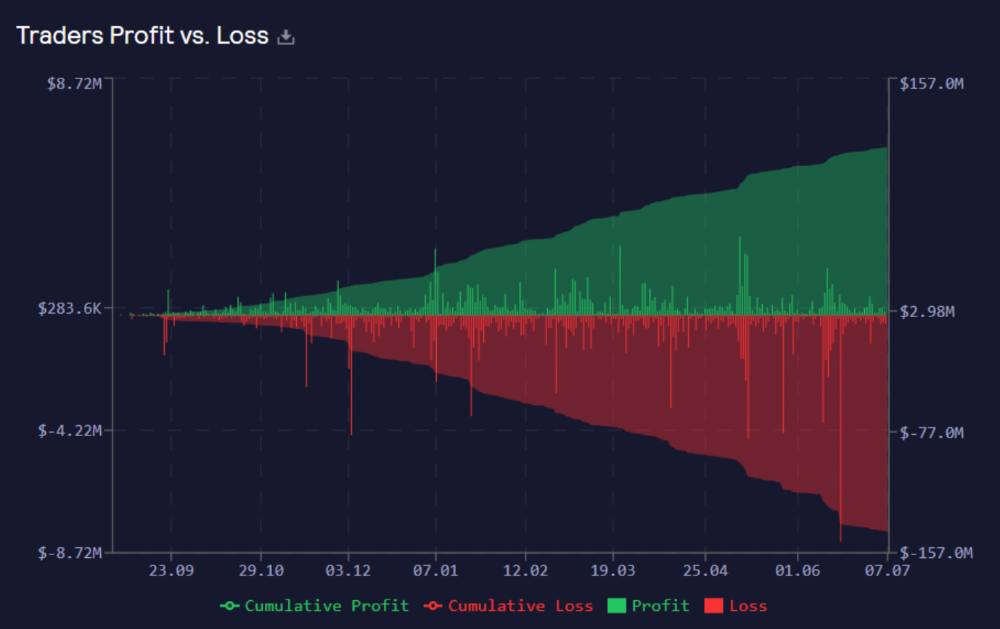
These are the fees in Arbitrum in the past 11 months by GMX.
GMX works like a casino, which increases fees. Most fees come from Margin trading, which means most traders lose money; this money goes to the casino, or GLP stakers.
Strategies
My personal strategy is to DCA into GLP when markets hit bottom and stake it; GLP will be less volatile with extra staking rewards.
GLP YoY return vs. naked buying
Let's say I invested $10,000 in BTC, AVAX, and ETH in January.
BTC price: 47665$
ETH price: 3760$
AVAX price: $145
Current prices
BTC $21,000 (Down 56 percent )
ETH $1233 (Down 67.2 percent )
AVAX $20.36 (Down 85.95 percent )
Your $10,000 investment is now worth around $3,000.
How about GLP? My initial investment is 50% stables and 50% other assets ( Assuming the coverage ratio for stables is 50 percent at that time)
Without GLP staking yield, your value is $6500.
Let's assume the average APR for GLP staking is 23%, or $1500. So 8000$ total. It's 50% safer than holding naked assets in a bear market.
In a bull market, naked assets are preferable to GLP.
Short farming using GLP
Simple GLP short farming.
You use a stable asset as collateral to borrow AVAX. Sell it and buy GLP. Even if GLP rises, it won't rise as fast as AVAX, so we can get yields.
Let's do the maths
You deposit $10,000 USDT in Aave and borrow Avax. Say you borrow $8,000; you sell it, buy GLP, and risk 20%.
After a year, ETH, AVAX, and BTC rise 20%. GLP is $8800. $800 vanishes. 20% yields $1600. You're profitable. Shorting Avax costs $1600. (Assumptions-ETH, AVAX, BTC move the same, GLP yield is 20%. GLP has a 50:50 stablecoin/others ratio. Aave won't liquidate
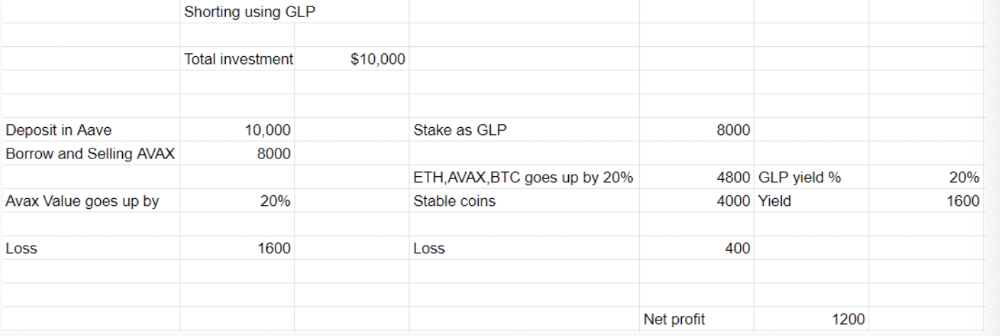
In naked Avax shorting, Avax falls 20% in a year. You'll make $1600. If you buy GLP and stake it using the sold Avax and BTC, ETH and Avax go down by 20% - your profit is 20%, but with the yield, your total gain is $2400.
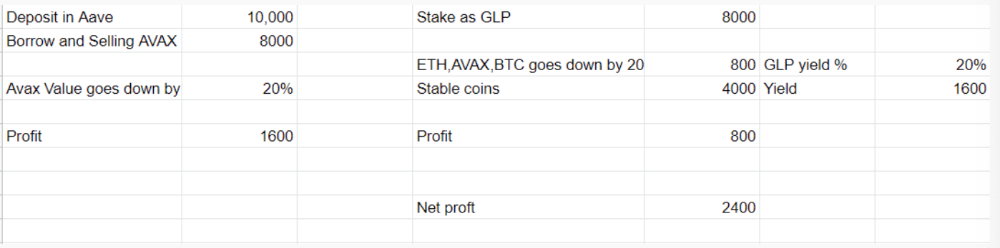
Issues with GMX
GMX's historical funding rates are always net positive, so long always pays short. This makes long-term shorts less appealing.
Oracle price discovery isn't enough. This limitation doesn't affect Bitcoin and ETH, but it affects less liquid assets. Traders can buy and sell less liquid assets at a lower price than their actual cost as long as GMX exists.
As users must provide GLP liquidity, adding more assets to GMX will be difficult. Next iteration will have synthetic assets.
Gains Protocol
Best leveraged trading platform. Smart contract-based decentralized protocol. 46 crypto pairs can be leveraged 5–150x and 10 Forex pairs 5–1000x. $10 DAI @ 150x (min collateral x leverage pos size is $1500 DAI). No funding fees, no KYC, trade DAI from your wallet, keep funds.
DAI single-sided staking and the GNS-DAI pool are important parts of Gains trading. GNS-DAI stakers get 90% of trading fees and 100% swap fees. 10 percent of trading fees go to DAI stakers, which is currently 14 percent!
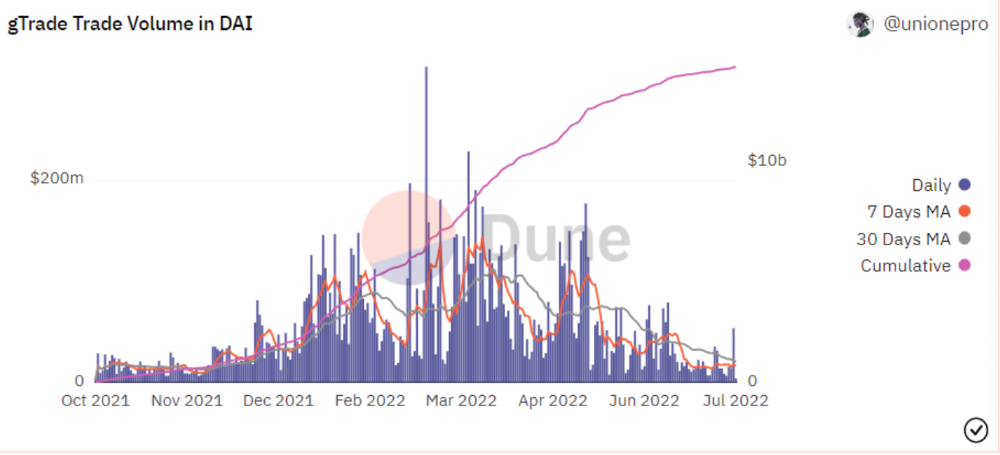
Trade volume
When a trader opens a trade, the leverage and profit are pulled from the DAI pool. If he loses, the protocol yield goes to the stakers.
If the trader's win rate is high and the DAI pool slowly depletes, the GNS token is minted and sold to refill DAI. Trader losses are used to burn GNS tokens. 25%+ of GNS is burned, making it deflationary.
Due to high leverage and volatility of crypto assets, most traders lose money and the protocol always wins, keeping GNS deflationary.
Gains uses a unique decentralized oracle for price feeds, which is better for leverage trading platforms. Let me explain.
Gains uses chainlink price oracles, not its own price feeds. Chainlink oracles only query centralized exchanges for price feeds every minute, which is unsuitable for high-precision trading.
Gains created a custom oracle that queries the eight chainlink nodes for the current price and, on average, for trade confirmation. This model eliminates every-second inquiries, which waste gas but are more efficient than chainlink's per-minute price.
This price oracle helps Gains open and close trades instantly, eliminate scam wicks, etc.
Other benefits include:
Stop-loss guarantee (open positions updated)
No scam wicks
Spot-pricing
Highest possible leverage
Fixed-spreads. During high volatility, a broker can increase the spread, which can hit your stop loss without the price moving.
Trade directly from your wallet and keep your funds.
>90% loss before liquidation (Some platforms liquidate as little as -50 percent)
KYC-free
Directly trade from wallet; keep funds safe
Further improvements
GNS-DAI liquidity providers fear the impermanent loss, so the protocol is migrating to its own liquidity and single staking GNS vaults. This allows users to stake GNS without permanent loss and obtain 90% DAI trading fees by staking. This starts in August.
Their upcoming improvements can be found here.
Gains constantly add new features and change pairs. It's an interesting protocol.
Conclusion
Next bull run, watch decentralized perpetual protocols. Effective tokenomics and non-inflationary yields may attract traders and liquidity providers. But still, there is a long way for them to develop, and I don't see them tackling the centralized exchanges any time soon until they fix their inherent problems and improve fast enough.
Read the full post here.

Datt Panchal
3 years ago
The Learning Habit

The Habit of Learning implies constantly learning something new. One daily habit will make you successful. Learning will help you succeed.
Most successful people continually learn. Success requires this behavior. Daily learning.
Success loves books. Books offer expert advice. Everything is online today. Most books are online, so you can skip the library. You must download it and study for 15-30 minutes daily. This habit changes your thinking.

Typical Successful People
Warren Buffett reads 500 pages of corporate reports and five newspapers for five to six hours each day.
Each year, Bill Gates reads 50 books.
Every two weeks, Mark Zuckerberg reads at least one book.
According to his brother, Elon Musk studied two books a day as a child and taught himself engineering and rocket design.
Learning & Making Money Online
No worries if you can't afford books. Everything is online. YouTube, free online courses, etc.

How can you create this behavior in yourself?
1) Consider what you want to know
Before learning, know what's most important. So, move together.
Set a goal and schedule learning.
After deciding what you want to study, create a goal and plan learning time.
3) GATHER RESOURCES
Get the most out of your learning resources. Online or offline.