



More on Entrepreneurship/Creators

Aaron Dinin, PhD
2 years ago
The Advantages and Disadvantages of Having Investors Sign Your NDA
Startup entrepreneurs assume what risks when pitching?

Last week I signed four NDAs.
Four!
NDA stands for non-disclosure agreement. A legal document given to someone receiving confidential information. By signing, the person pledges not to share the information for a certain time. If they do, they may be in breach of contract and face legal action.
Companies use NDAs to protect trade secrets and confidential internal information from employees and contractors. Appropriate. If you manage a huge, successful firm, you don't want your employees selling their information to your competitors. To be true, business NDAs don't always prevent corporate espionage, but they usually make employees and contractors think twice before sharing.
I understand employee and contractor NDAs, but I wasn't asked to sign one. I counsel entrepreneurs, thus the NDAs I signed last week were from startups that wanted my feedback on their concepts.
I’m not a startup investor. I give startup guidance online. Despite that, four entrepreneurs thought their company ideas were so important they wanted me to sign a generically written legal form they probably acquired from a shady, spam-filled legal templates website before we could chat.
False. One company tried to get me to sign their NDA a few days after our conversation. I gently rejected, but their tenacity encouraged me. I considered sending retroactive NDAs to everyone I've ever talked to about one of my startups in case they establish a successful company based on something I said.
Two of the other three NDAs were from nearly identical companies. Good thing I didn't sign an NDA for the first one, else they may have sued me for talking to the second one as though I control the firms people pitch me.
I wasn't talking to the fourth NDA company. Instead, I received an unsolicited email from someone who wanted comments on their fundraising pitch deck but required me to sign an NDA before sending it.
That's right, before I could read a random Internet stranger's unsolicited pitch deck, I had to sign his NDA, potentially limiting my ability to discuss what was in it.
You should understand. Advisors, mentors, investors, etc. talk to hundreds of businesses each year. They cannot manage all the companies they deal with, thus they cannot risk legal trouble by talking to someone. Well, if I signed NDAs for all the startups I spoke with, half of the 300+ articles I've written on Medium over the past several years could get me sued into the next century because I've undoubtedly addressed topics in my articles that I discussed with them.
The four NDAs I received last week are part of a recent trend of entrepreneurs sending out NDAs before meetings, despite the practical and legal issues. They act like asking someone to sign away their right to talk about all they see and hear in a day is as straightforward as asking for a glass of water.
Given this inflow of NDAs, I wanted to briefly remind entrepreneurs reading this blog about the merits and cons of requesting investors (or others in the startup ecosystem) to sign your NDA.
Benefits of having investors sign your NDA include:
None. Zero. Nothing.
Disadvantages of requesting investor NDAs:
You'll come off as an amateur who has no idea what it takes to launch a successful firm.
Investors won't trust you with their money since you appear to be a complete amateur.
Printing NDAs will be a waste of paper because no genuine entrepreneur will ever sign one.
I apologize for missing any cons. Please leave your remarks.

Sammy Abdullah
3 years ago
R&D, S&M, and G&A expense ratios for SaaS
SaaS spending is 40/40/20. 40% of operating expenses should be R&D, 40% sales and marketing, and 20% G&A. We wanted to see the statistics behind the rules of thumb. Since October 2017, 73 SaaS startups have gone public. Perhaps the rule of thumb should be 30/50/20. The data is below.
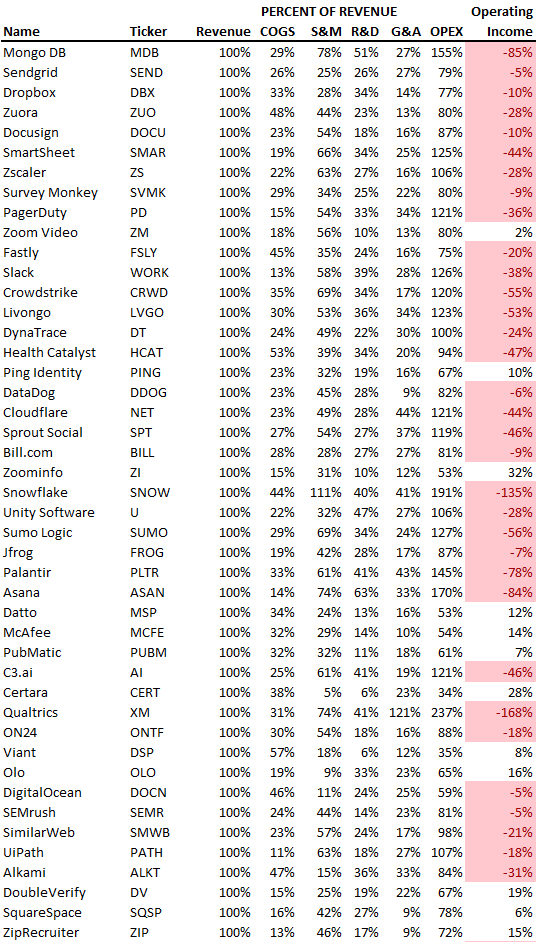
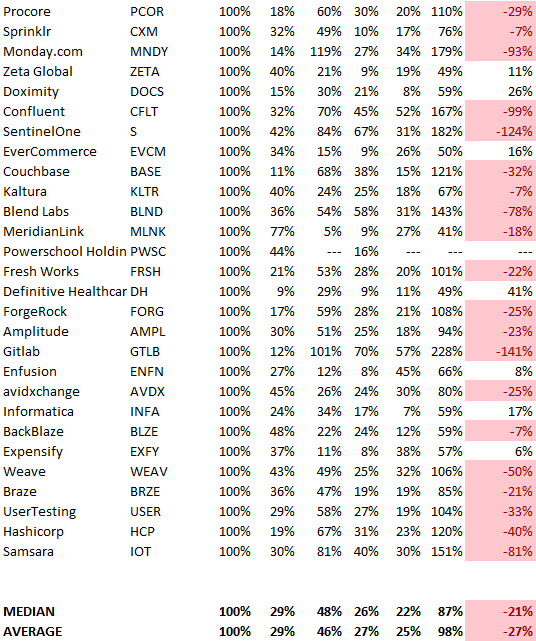
30/50/20. R&D accounts for 26% of opex, sales and marketing 48%, and G&A 22%. We think R&D/S&M/G&A should be 30/50/20.
There are outliers. There are exceptions to rules of thumb. Dropbox spent 45% on R&D whereas Zoom spent 13%. Zoom spent 73% on S&M, Dropbox 37%, and Bill.com 28%. Snowflake spent 130% of revenue on S&M, while their EBITDA margin is -192%.
G&A shouldn't stand out. Minimize G&A spending. Priorities should be product development and sales. Cloudflare, Sendgrid, Snowflake, and Palantir spend 36%, 34%, 37%, and 43% on G&A.
Another myth is that COGS is 20% of revenue. Median and averages are 29%.
Where is the profitability? Data-driven operating income calculations were simplified (Revenue COGS R&D S&M G&A). 20 of 73 IPO businesses reported operational income. Median and average operating income margins are -21% and -27%.
As long as you're growing fast, have outstanding retention, and marquee clients, you can burn cash since recurring income that doesn't churn is a valuable annuity.
The data was compelling overall. 30/50/20 is the new 40/40/20 for more established SaaS enterprises, unprofitability is alright as long as your business is expanding, and COGS can be somewhat more than 20% of revenue.

Alana Rister, Ph.D.
3 years ago
Don't rely on lessons you learned with a small audience.
My growth-killing mistake

When you initially start developing your audience, you need guidance.
What does my audience like? What do they not like? How can I grow more?
When I started writing two years ago, I inquired daily. Taking cues from your audience to develop more valuable content is a good concept, but it's simple to let them destroy your growth.
A small audience doesn't represent the full picture.
When I had fewer than 100 YouTube subscribers, I tried several video styles and topics. I looked to my audience for what to preserve and what to change.
If my views, click-through rate, or average view % dropped, that topic or style was awful. Avoiding that style helped me grow.
Vlogs, talking head videos on writing, and long-form tutorials didn't fare well.
Since I was small, I've limited the types of films I make. I have decided to make my own videos.
Surprisingly, the videos I avoided making meet or exceed my views, CTR, and audience retention.
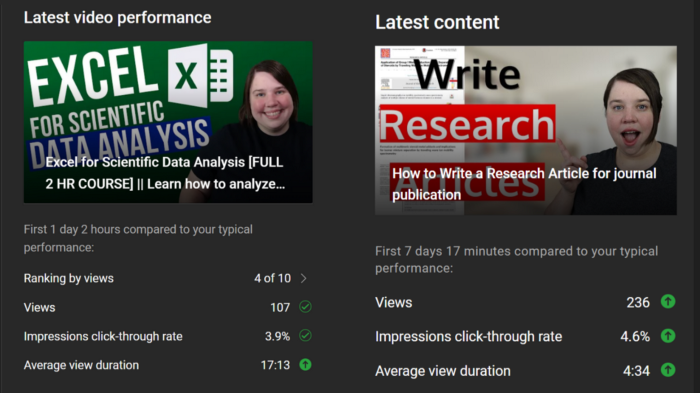
A limited audience can't tell you what your tribe wants. Therefore, limiting your innovation will prohibit you from reaching the right audience. Finding them may take longer.
Large Creators Experience The Same Issue
In the last two years, I've heard Vanessa Lau and Cathrin Manning say they felt pigeonholed into generating videos they didn't want to do.
Why does this happen over and over again?
Once you have a popular piece of content, your audience will grow. So when you publish inconsistent material, fewer of your new audience will view it. You interpret the drop in views as a sign that your audience doesn't want the content, so you stop making it.
Repeat this procedure a few times, and you'll create stuff you're not passionate about because you're frightened to publish it.
How to Manage Your Creativity and Audience Development
I'm not recommending you generate random content.
Instead of feeling trapped by your audience, you can cultivate a diverse audience.
Create quality material on a range of topics and styles as you improve. Be creative until you get 100 followers. Look for comments on how to improve your article.
If you observe trends in the types of content that expand your audience, focus 50-75% of your material on those trends. Allow yourself to develop 25% non-performing material.
This method can help you expand your audience faster with your primary trends and like all your stuff. Slowly, people will find 25% of your material, which will boost its performance.
How to Expand Your Audience Without Having More Limited Content
Follow these techniques to build your audience without feeling confined.
Don't think that you need restrict yourself to what your limited audience prefers.
Don't let the poor performance of your desired material demotivate you.
You shouldn't restrict the type of content you publish or the themes you cover when you have less than 100 followers.
When your audience expands, save 25% of your content for your personal interests, regardless of how well it does.
You might also like

Dung Claire Tran
3 years ago
Is the future of brand marketing with virtual influencers?
Digital influences that mimic humans are rising.
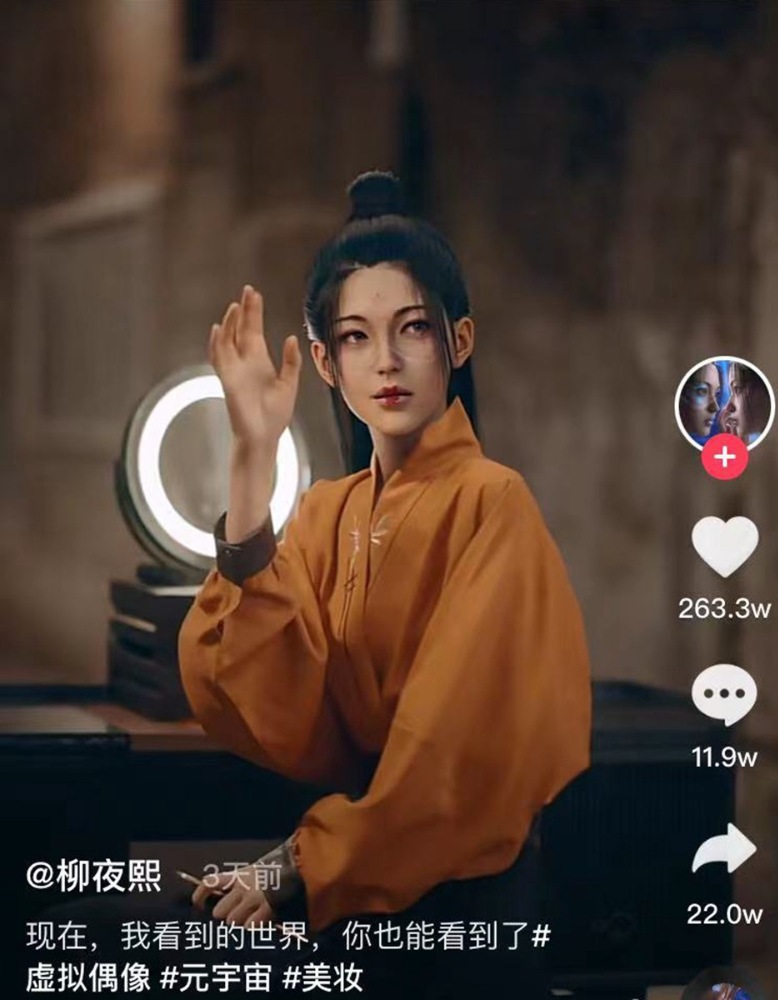
Lil Miquela has 3M Instagram followers, 3.6M TikTok followers, and 30K Twitter followers. She's been on the covers of Prada, Dior, and Calvin Klein magazines. Miquela released Not Mine in 2017 and launched Hard Feelings at Lollapazoolas this year. This isn't surprising, given the rise of influencer marketing.
This may be unexpected. Miquela's fake. Brud, a Los Angeles startup, produced her in 2016.
Lil Miquela is one of many rising virtual influencers in the new era of social media marketing. She acts like a real person and performs the same tasks as sports stars and models.
The emergence of online influencers
Before 2018, computer-generated characters were rare. Since the virtual human industry boomed, they've appeared in marketing efforts worldwide.
In 2020, the WHO partnered up with Atlanta-based virtual influencer Knox Frost (@knoxfrost) to gather contributions for the COVID-19 Solidarity Response Fund.
Lu do Magalu (@magazineluiza) has been the virtual spokeswoman for Magalu since 2009, using social media to promote reviews, product recommendations, unboxing videos, and brand updates. Magalu's 10-year profit was $552M.
In 2020, PUMA partnered with Southeast Asia's first virtual model, Maya (@mayaaa.gram). She joined Singaporean actor Tosh Zhang in the PUMA campaign. Local virtual influencer Ava Lee-Graham (@avagram.ai) partnered with retail firm BHG to promote their in-house labels.

In Japan, Imma (@imma.gram) is the face of Nike, PUMA, Dior, Salvatore Ferragamo SpA, and Valentino. Imma's bubblegum pink bob and ultra-fine fashion landed her on the cover of Grazia magazine.

Lotte Home Shopping created Lucy (@here.me.lucy) in September 2020. She made her TV debut as a Christmas show host in 2021. Since then, she has 100K Instagram followers and 13K TikTok followers.
Liu Yiexi gained 3 million fans in five days on Douyin, China's TikTok, in 2021. Her two-minute video went viral overnight. She's posted 6 videos and has 830 million Douyin followers.
China's virtual human industry was worth $487 million in 2020, up 70% year over year, and is expected to reach $875.9 million in 2021.
Investors worldwide are interested. Immas creator Aww Inc. raised $1 million from Coral Capital in September 2020, according to Bloomberg. Superplastic Inc., the Vermont-based startup behind influencers Janky and Guggimon, raised $16 million by 2020. Craft Ventures, SV Angels, and Scooter Braun invested. Crunchbase shows the company has raised $47 million.
The industries they represent, including Augmented and Virtual reality, were worth $14.84 billion in 2020 and are projected to reach $454.73 billion by 2030, a CAGR of 40.7%, according to PR Newswire.
Advantages for brands
Forbes suggests brands embrace computer-generated influencers. Examples:
Unlimited creative opportunities: Because brands can personalize everything—from a person's look and activities to the style of their content—virtual influencers may be suited to a brand's needs and personalities.
100% brand control: Brand managers now have more influence over virtual influencers, so they no longer have to give up and rely on content creators to include brands into their storytelling and style. Virtual influencers can constantly produce social media content to promote a brand's identity and ideals because they are completely scandal-free.
Long-term cost savings: Because virtual influencers are made of pixels, they may be reused endlessly and never lose their beauty. Additionally, they can move anywhere around the world and even into space to fit a brand notion. They are also always available. Additionally, the expense of creating their content will not rise in step with their expanding fan base.
Introduction to the metaverse: Statista reports that 75% of American consumers between the ages of 18 and 25 follow at least one virtual influencer. As a result, marketers that support virtual celebrities may now interact with younger audiences that are more tech-savvy and accustomed to the digital world. Virtual influencers can be included into any digital space, including the metaverse, as they are entirely computer-generated 3D personas. Virtual influencers can provide brands with a smooth transition into this new digital universe to increase brand trust and develop emotional ties, in addition to the young generations' rapid adoption of the metaverse.
Better engagement than in-person influencers: A Hype Auditor study found that online influencers have roughly three times the engagement of their conventional counterparts. Virtual influencers should be used to boost brand engagement even though the data might not accurately reflect the entire sector.
Concerns about influencers created by computers
Virtual influencers could encourage excessive beauty standards in South Korea, which has a $10.7 billion plastic surgery industry.
A classic Korean beauty has a small face, huge eyes, and pale, immaculate skin. Virtual influencers like Lucy have these traits. According to Lee Eun-hee, a professor at Inha University's Department of Consumer Science, this could make national beauty standards more unrealistic, increasing demand for plastic surgery or cosmetic items.

Other parts of the world raise issues regarding selling items to consumers who don't recognize the models aren't human and the potential of cultural appropriation when generating influencers of other ethnicities, called digital blackface by some.
Meta, Facebook and Instagram's parent corporation, acknowledges this risk.
“Like any disruptive technology, synthetic media has the potential for both good and harm. Issues of representation, cultural appropriation and expressive liberty are already a growing concern,” the company stated in a blog post. “To help brands navigate the ethical quandaries of this emerging medium and avoid potential hazards, (Meta) is working with partners to develop an ethical framework to guide the use of (virtual influencers).”
Despite theoretical controversies, the industry will likely survive. Companies think virtual influencers are the next frontier in the digital world, which includes the metaverse, virtual reality, and digital currency.
In conclusion
Virtual influencers may garner millions of followers online and help marketers reach youthful audiences. According to a YouGov survey, the real impact of computer-generated influencers is yet unknown because people prefer genuine connections. Virtual characters can supplement brand marketing methods. When brands are metaverse-ready, the author predicts virtual influencer endorsement will continue to expand.

Christian Soschner
3 years ago
Steve Jobs' Secrets Revealed
From 1984 until 2011, he ran Apple using the same template.

What is a founder CEO's most crucial skill?
Presentation, communication, and sales
As a Business Angel Investor, I saw many pitch presentations and met with investors one-on-one to promote my companies.
There is always the conception of “Investors have to invest,” so there is no need to care about the presentation.
It's false. Nobody must invest. Many investors believe that entrepreneurs must convince them to invest in their business.
Sometimes — like in 2018–2022 — too much money enters the market, and everyone makes good money.
Do you recall the Buy Now, Pay Later Movement? This amazing narrative had no return potential. Only buyers who couldn't acquire financing elsewhere shopped at these companies.
Klarna's failing business concept led to high valuations.
Investors become more cautious when the economy falters. 2022 sees rising inflation, interest rates, wars, and civil instability. It's like the apocalypse's four horsemen have arrived.
Storytelling is important in rough economies.
When investors draw back, how can entrepreneurs stand out?
In Q2/2022, every study I've read said:
Investors cease investing
Deals are down in almost all IT industries from previous quarters.
What do founders need to do?
Differentiate yourself.
Storytelling talents help.
The Steve Jobs Way
Every time I watch a Steve Jobs presentation, I'm enthralled.
I'm a techie. Everything technical interests me. But, I skim most presentations.
What's Steve Jobs's secret?
Steve Jobs created Apple in 1976 and made it a profitable software and hardware firm in the 1980s. Macintosh goods couldn't beat IBM's. This mistake sacked him in 1985.
Before rejoining Apple in 1997, Steve Jobs founded Next Inc. and Pixar.
From then on, Apple became America's most valuable firm.
Steve Jobs understood people's needs. He said:
“People don’t know what they want until you show it to them. That’s why I never rely on market research. Our task is to read things that are not yet on the page.”
In his opinion, people talk about problems. A lot. Entrepreneurs must learn what the population's pressing problems are and create a solution.
Steve Jobs showed people what they needed before they realized it.
I'll explain:
Present a Big Vision
Steve Jobs starts every presentation by describing his long-term goals for Apple.
1984's Macintosh presentation set up David vs. Goliath. In a George Orwell-style dystopia, IBM computers were bad. It was 1984.
Apple will save the world, like Jedis.
Why do customers and investors like Big Vision?
People want a wider perspective, I think. Humans love improving the planet.
Apple users often cite emotional reasons for buying the brand.
Revolutionizing several industries with breakthrough inventions
Establish Authority
Everyone knows Apple in 2022. It's hard to find folks who confuse Apple with an apple around the world.
Apple wasn't as famous as it is today until Steve Jobs left in 2011.
Most entrepreneurs lack experience. They may market their company or items to folks who haven't heard of it.
Steve Jobs presented the company's historical accomplishments to overcome opposition.
In his presentation of the first iPhone, he talked about the Apple Macintosh, which altered the computing sector, and the iPod, which changed the music industry.
People who have never heard of Apple feel like they're seeing a winner. It raises expectations that the new product will be game-changing and must-have.
The Big Reveal
A pitch or product presentation always has something new.
Steve Jobs doesn't only demonstrate the product. I don't think he'd skip the major point of a company presentation.
He consistently discusses present market solutions, their faults, and a better consumer solution.
No solution exists yet.
It's a multi-faceted play:
It's comparing the new product to something familiar. This makes novelty and the product more relatable.
Describe a desirable solution.
He's funny. He demonstrated an iPod with an 80s phone dial in his iPhone presentation.
Then he reveals the new product. Macintosh presented itself.
Show the benefits
He outlines what Apple is doing differently after demonstrating the product.
How do you distinguish from others? The Big Breakthrough Presentation.
A few hundred slides might list all benefits.
Everyone would fall asleep. Have you ever had similar presentations?
When the brain is overloaded with knowledge, the limbic system changes to other duties, like lunch planning.
What should a speaker do? There's a classic proverb:
“Tell me and I forget, teach me and I may remember, involve me and I learn” (— Not Benjamin Franklin).
Steve Jobs showcased the product live.
Again, using ordinary scenarios to highlight the product's benefits makes it relatable.
The 2010 iPad Presentation uses this technique.
Invite the Team and Let Them Run the Presentation
CEOs spend most time outside the organization. Many companies elect to have only one presenter.
It sends the incorrect message to investors. Product presentations should always include the whole team.
Let me explain why.
Companies needing investment money frequently have shaky business strategies or no product-market fit or robust corporate structure.
Investors solely bet on a team's ability to implement ideas and make a profit.
Early team involvement helps investors understand the company's drivers. Travel costs are worthwhile.
But why for product presentations?
Presenters of varied ages, genders, social backgrounds, and skillsets are relatable. CEOs want relatable products.
Some customers may not believe a white man's message. A black woman's message may be more accepted.
Make the story relatable when you have the best product that solves people's concerns.
Best example: 1984 Macintosh presentation with development team panel.
What is the largest error people make when companies fail?
Saving money on the corporate and product presentation.
Invite your team to five partner meetings when five investors are shortlisted.
Rehearse the presentation till it's natural. Let the team speak.
Successful presentations require structure, rehearsal, and a team. Steve Jobs nailed it.

Will Lockett
2 years ago
There Is A New EV King in Town

McMurtry Spéirling outperforms Tesla in speed and efficiency.
EVs were ridiculously slow for decades. However, the 2008 Tesla Roadster revealed that EVs might go extraordinarily fast. The Tesla Model S Plaid and Rimac Nevera are the fastest-accelerating road vehicles, despite combustion-engined road cars dominating the course. A little-known firm beat Tesla and Rimac in the 0-60 race, beat F1 vehicles on a circuit, and boasts a 350-mile driving range. The McMurtry Spéirling is completely insane.
Mat Watson of CarWow, a YouTube megastar, was recently handed a Spéirling and access to Silverstone Circuit (view video above). Mat ran a quarter-mile on Silverstone straight with former F1 driver Max Chilton. The little pocket-rocket automobile touched 100 mph in 2.7 seconds, completed the quarter mile in 7.97 seconds, and hit 0-60 in 1.4 seconds. When looking at autos quickly, 0-60 times can seem near. The Tesla Model S Plaid does 0-60 in 1.99 seconds, which is comparable to the Spéirling. Despite the meager statistics, the Spéirling is nearly 30% faster than Plaid!
My vintage VW Golf 1.4s has an 8.8-second 0-60 time, whereas a BMW Z4 3.0i is 30% faster (with a 0-60 time of 6 seconds). I tried to beat a Z4 off the lights in my Golf, but the Beamer flew away. If they challenge the Spéirling in a Model S Plaid, they'll feel as I did. Fast!
Insane quarter-mile drag time. Its road car record is 7.97 seconds. A Dodge Demon, meant to run extremely fast quarter miles, finishes so in 9.65 seconds, approximately 20% slower. The Rimac Nevera's 8.582-second quarter-mile record was miles behind drag racing. This run hampered the Spéirling. Because it was employing gearing that limited its top speed to 150 mph, it reached there in a little over 5 seconds without accelerating for most of the quarter mile! McMurtry can easily change the gearing, making the Spéirling run quicker.
McMurtry did this how? First, the Spéirling is a tiny single-seater EV with a 60 kWh battery pack, making it one of the lightest EVs ever. The 1,000-hp Spéirling has more than one horsepower per kg. The Nevera has 0.84 horsepower per kg and the Plaid 0.44.
However, you cannot simply construct a car light and power it. Instead of accelerating, it would spin. This makes the Spéirling a fan car. Its huge fans create massive downforce. These fans provide the Spéirling 2 tonnes of downforce while stationary, so you could park it on the ceiling. Its fast 0-60 time comes from its downforce, which lets it deliver all that power without wheel spin.
It also possesses complete downforce at all speeds, allowing it to tackle turns faster than even race vehicles. Spéirlings overcame VW IDRs and F1 cars to set the Goodwood Hill Climb record (read more here). The Spéirling is a dragstrip winner and track dominator, unlike the Plaid and Nevera.
The Spéirling is astonishing for a single-seater. Fan-generated downforce is more efficient than wings and splitters. It also means the vehicle has very minimal drag without the fan. The Spéirling can go 350 miles per charge (WLTP) or 20-30 minutes at full speed on a track despite its 60 kWh battery pack. The G-forces would hurt your neck before the battery died if you drove around a track for longer. The Spéirling can charge at over 200 kW in about 30 minutes. Thus, driving to track days, having fun, and returning is possible. Unlike other high-performance EVs.
Tesla, Rimac, or Lucid will struggle to defeat the Spéirling. They would need to build a fan automobile because adding power to their current vehicle would make it uncontrollable. The EV and automobile industries now have a new, untouchable performance king.