



More on Entrepreneurship/Creators

Grace Huang
3 years ago
I sold 100 copies of my book when I had anticipated selling none.
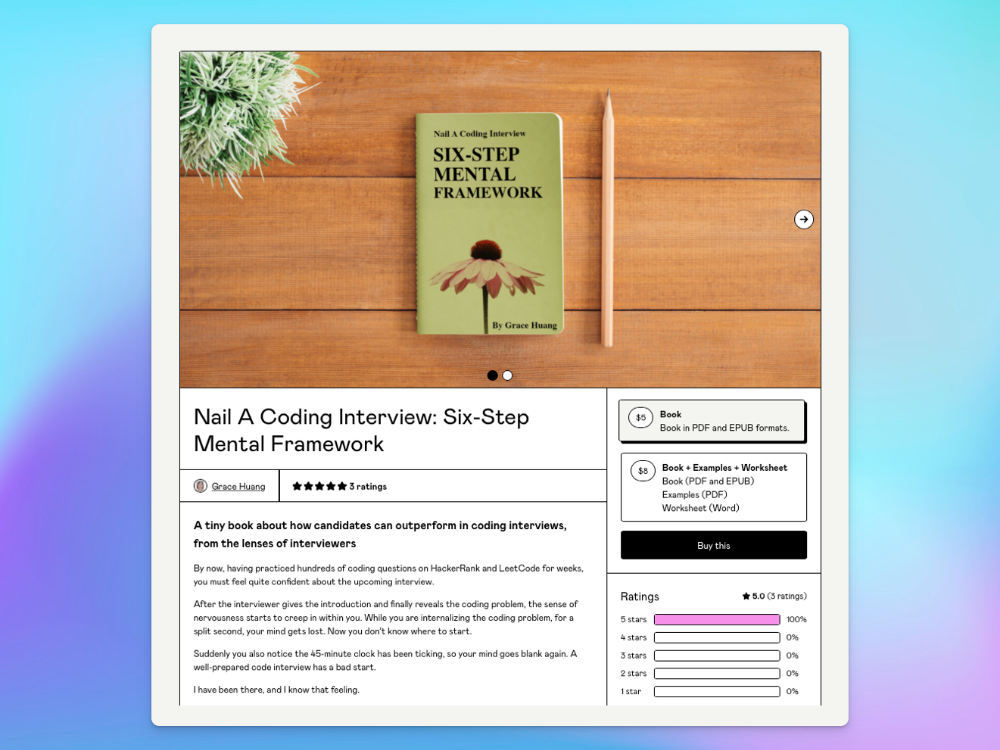
After a decade in large tech, I know how software engineers were interviewed. I've seen outstanding engineers fail interviews because their responses were too vague.
So I wrote Nail A Coding Interview: Six-Step Mental Framework. Give candidates a mental framework for coding questions; help organizations better prepare candidates so they can calibrate traits.
Recently, I sold more than 100 books, something I never expected.
In this essay, I'll describe my publication journey, which included self-doubt and little triumphs. I hope this helps if you want to publish.
It was originally a Medium post.
How did I know to develop a coding interview book? Years ago, I posted on Medium.
Six steps to ace a coding interview Inhale. blog.devgenius.io
This story got a lot of attention and still gets a lot of daily traffic. It indicates this domain's value.
Converted the Medium article into an ebook
The Medium post contains strong bullet points, but it is missing the “flesh”. How to use these strategies in coding interviews, for example. I filled in the blanks and made a book.
I made the book cover for free. It's tidy.
Shared the article with my close friends on my social network WeChat.
I shared the book on Wechat's Friend Circle (朋友圈) after publishing it on Gumroad. Many friends enjoyed my post. It definitely triggered endorphins.
In Friend Circle, I presented a 100% off voucher. No one downloaded the book. Endorphins made my heart sink.
Several days later, my Apple Watch received a Gumroad notification. A friend downloaded it. I majored in finance, he subsequently said. My brother-in-law can get it? He downloaded it to cheer me up.
I liked him, but was disappointed that he didn't read it.
The Tipping Point: Reddit's Free Giving
I trusted the book. It's based on years of interviewing. I felt it might help job-hunting college students. If nobody wants it, it can still have value.
I posted the book's link on /r/leetcode. I told them to DM me for a free promo code.
Momentum shifted everything. Gumroad notifications kept coming when I was out with family. Following orders.
As promised, I sent DMs a promo code. Some consumers ordered without asking for a promo code. Some readers finished the book and posted reviews.
My book was finally on track.
A 5-Star Review, plus More
A reader afterwards DMed me and inquired if I had another book on system design interviewing. I said that was a good idea, but I didn't have one. If you write one, I'll be your first reader.
Later, I asked for a book review. Yes, but how? That's when I learned readers' reviews weren't easy. I built up an email pipeline to solicit customer reviews. Since then, I've gained credibility through ratings.
Learnings
I wouldn't have gotten 100 if I gave up when none of my pals downloaded. Here are some lessons.
Your friends are your allies, but they are not your clients.
Be present where your clients are
Request ratings and testimonials
gain credibility gradually
I did it, so can you. Follow me on Twitter @imgracehuang for my publishing and entrepreneurship adventure.

Owolabi Judah
3 years ago
How much did YouTube pay for 10 million views?
Ali's $1,054,053.74 YouTube Adsense haul.

YouTuber, entrepreneur, and former doctor Ali Abdaal. He began filming productivity and financial videos in 2017. Ali Abdaal has 3 million YouTube subscribers and has crossed $1 million in AdSense revenue. Crazy, no?
Ali will share the revenue of his top 5 youtube videos, things he's learned that you can apply to your side hustle, and how many views it takes to make a livelihood off youtube.
First, "The Long Game."
All good things take time to bear fruit. Compounding improves everything. Long-term work yields better returns. Ali made his first dollar after nine months and 85 videos.
Second, "One piece of content can transform your life, but you never know which one."
Had he abandoned YouTube at 84 videos without making any money, he wouldn't have filmed the 85th video that altered everything.
Third Lesson: Your Industry Choice Can Multiply.
The industry or niche you target as a business owner or side hustler can have a major impact on how much money you make.
Here are the top 5 videos.
1) 9.8m views: $191,258.16 for 9 passive income ideas
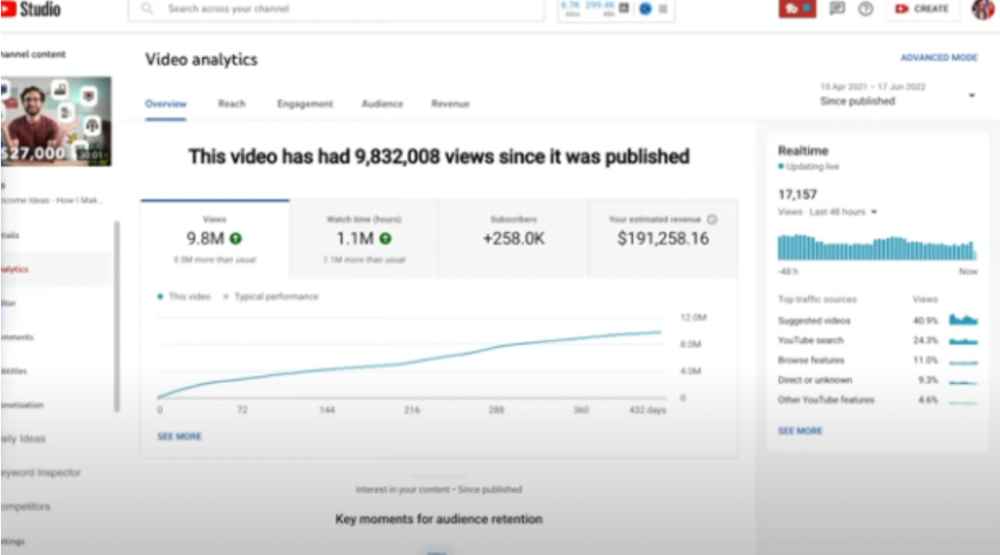
Ali made 2 points.
We should consider YouTube videos digital assets. They're investments, which make us money. His investments are yielding passive income.
Investing extra time and effort in your films can pay off.
2) How to Invest for Beginners — 5.2m Views: $87,200.08.
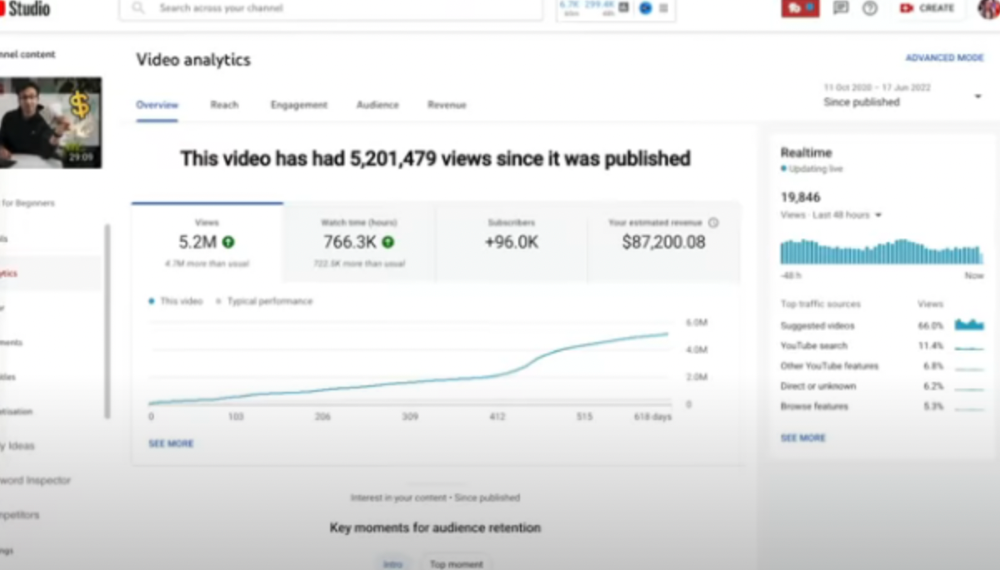
This video did poorly in the first several weeks after it was published; it was his tenth poorest performer. Don't worry about things you can't control. This applies to life, not just YouTube videos.
He stated we constantly have anxieties, fears, and concerns about things outside our control, but if we can find that line, life is easier and more pleasurable.
3) How to Build a Website in 2022— 866.3k views: $42,132.72.
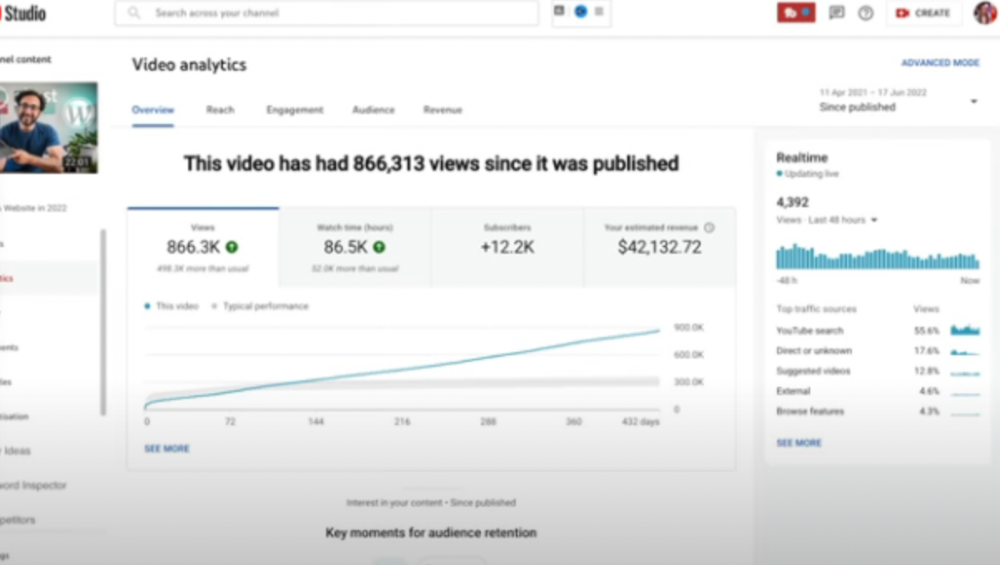
The RPM was $48.86 per thousand views, making it his highest-earning video. Squarespace, Wix, and other website builders are trying to put ads on it and competing against one other, so ad rates go up.
Because it was beyond his niche, Ali almost didn't make the video. He made the video because he wanted to help at least one person.
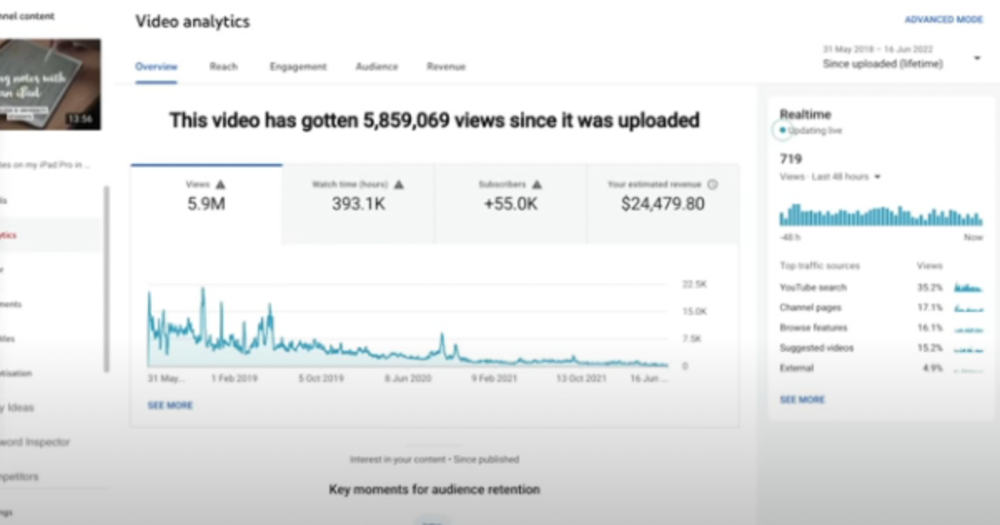
4) How I take notes on my iPad in medical school — 5.9m views: $24,479.80

85th video. It's the video that affected Ali's YouTube channel and his life the most. The video's success wasn't certain.
5) How I Type Fast 156 Words Per Minute — 8.2M views: $25,143.17
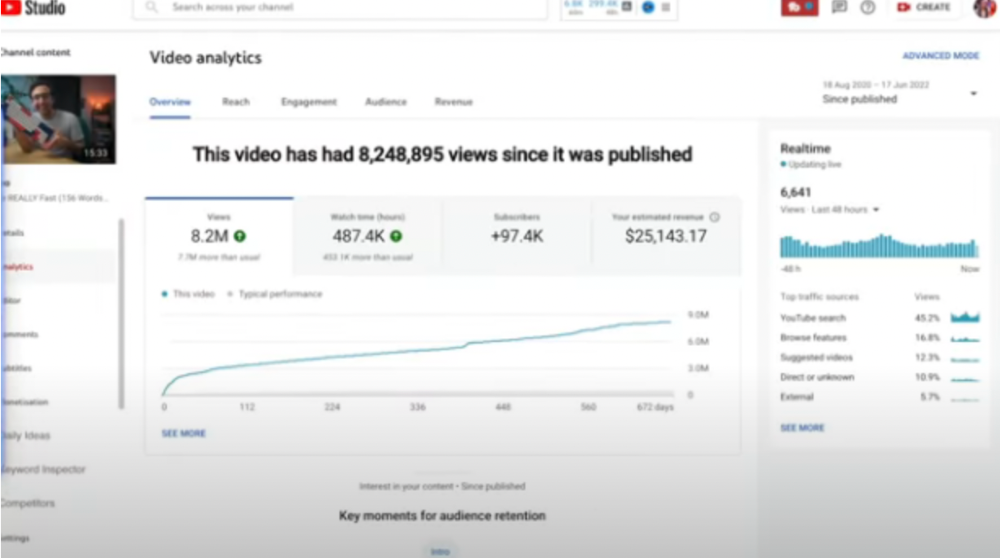
Ali didn't know this video would perform well; he made it because he can type fast and has been practicing for 10 years. So he made a video with his best advice.
How many views to different wealth levels?
It depends on geography, niche, and other monetization sources. To keep things simple, he would solely utilize AdSense.
How many views to generate money?

To generate money on Youtube, you need 1,000 subscribers and 4,000 hours of view time. How much work do you need to make pocket money?

Ali's first 1,000 subscribers took 52 videos and 6 months. The typical channel with 1,000 subscribers contains 152 videos, according to Tubebuddy. It's time-consuming.
After monetizing, you'll need 15,000 views/month to make $5-$10/day.
How many views to go part-time?

Say you make $35,000/year at your day job. If you work 5 days/week, you make $7,000/year each day. If you want to drop down from 5 days to 4 days/week, you need to make an extra $7,000/year from YouTube, or $600/month.
What's the quit-your-job budget?

Silicon Valley Girl is in a highly successful niche targeting tech-focused folks in the west. When her channel had 500k views/month, she made roughly $3,000/month or $47,000/year, enough to quit your work.
Marina has another 1.5m subscriber channel in Russia, which has a lower rpm because fewer corporations advertise there than in the west. 2.3 million views/month is $4,000/month or $50,000/year, enough to quit your employment.
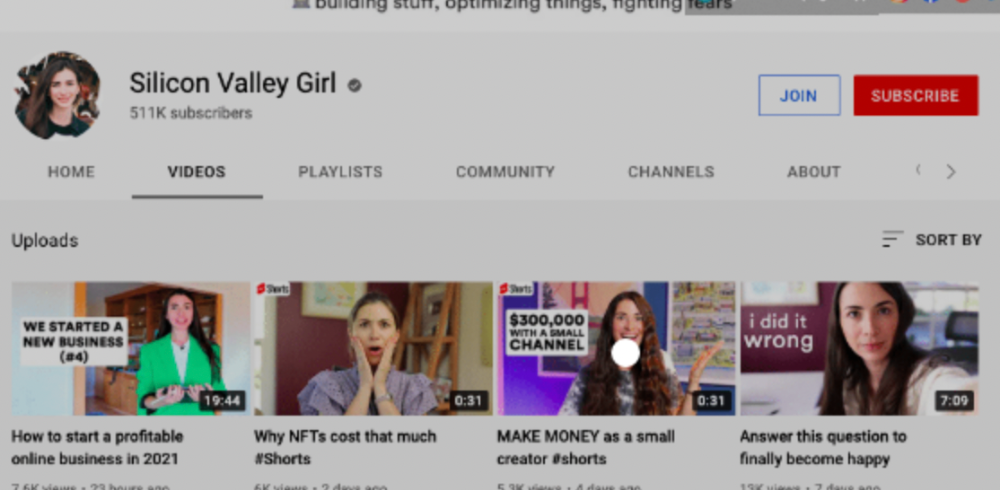
Marina is an intriguing example because she has three YouTube channels with the same skills, but one is 16x more profitable due to the niche she chose.
In Ali's case, he made 100+ videos when his channel was producing enough money to quit his job, roughly $4,000/month.
How many views make you rich?

Depending on how you define rich. Ali felt prosperous with over $100,000/year and 3–5m views/month.
Conclusion
YouTubers and artists don't treat their work like a company, which is a mistake. Businesses have been attempting to figure this out for decades, if not centuries.
We can learn from the business world how to monetize YouTube, Instagram, and Tiktok and make them into sustainable enterprises where we can hire people and delegate tasks.
Bonus
Watch Ali's video explaining all this:
This post is a summary. Read the full article here

Nik Nicholas
3 years ago
A simple go-to-market formula

“Poor distribution, not poor goods, is the main reason for failure” — Peter Thiel.
Here's an easy way to conceptualize "go-to-market" for your distribution plan.
One equation captures the concept:
Distribution = Ecosystem Participants + Incentives
Draw your customers' ecosystem. Set aside your goods and consider your consumer's environment. Who do they deal with daily?
First, list each participant. You want an exhaustive list, but here are some broad categories.
In-person media services
Websites
Events\Networks
Financial education and banking
Shops
Staff
Advertisers
Twitter influencers
Draw influence arrows. Who's affected? I'm not just talking about Instagram selfie-posters. Who has access to your consumer and could promote your product if motivated?
The thicker the arrow, the stronger the relationship. Include more "influencers" if needed. Customer ecosystems are complex.
3. Incentivize ecosystem players. “Show me the incentive and I will show you the result.“, says Warren Buffet's business partner Charlie Munger.
Strong distribution strategies encourage others to promote your product to your target market by incentivizing the most prominent players. Incentives can be financial or non-financial.
Financial rewards
Usually, there's money. If you pay Facebook, they'll run your ad. Salespeople close deals for commission. Giving customers bonus credits will encourage referrals.
Most businesses underuse non-financial incentives.
Non-cash incentives
Motivate key influencers without spending money to expand quickly and cheaply. What can you give a client-connector for free?
Here are some ideas:
Are there any other features or services available?
Titles or status? Tinder paid college "ambassadors" for parties to promote its dating service.
Can I get early/free access? Facebook gave a select group of developers "exclusive" early access to their AR platform.
Are you a good host? Pharell performed at YPlan's New York launch party.
Distribution? Apple's iPod earphones are white so others can see them.
Have an interesting story? PR rewards journalists by giving them a compelling story to boost page views.
Prioritize distribution.
More time spent on distribution means more room in your product design and business plan. Once you've identified the key players in your customer's ecosystem, talk to them.
Money isn't your only resource. Creative non-monetary incentives may be more effective and scalable. Give people something useful and easy to deliver.
You might also like

CyberPunkMetalHead
3 years ago
It's all about the ego with Terra 2.0.
UST depegs and LUNA crashes 99.999% in a fraction of the time it takes the Moon to orbit the Earth.
Fat Man, a Terra whistle-blower, promises to expose Do Kwon's dirty secrets and shady deals.

The Terra community has voted to relaunch Terra LUNA on a new blockchain. The Terra 2.0 Pheonix-1 blockchain went live on May 28, 2022, and people were airdropped the new LUNA, now called LUNA, while the old LUNA became LUNA Classic.
Does LUNA deserve another chance? To answer this, or at least start a conversation about the Terra 2.0 chain's advantages and limitations, we must assess its fundamentals, ideology, and long-term vision.
Whatever the result, our analysis must be thorough and ruthless. A failure of this magnitude cannot happen again, so we must magnify every potential breaking point by 10.
Will UST and LUNA holders be compensated in full?
The obvious. First, and arguably most important, is to restore previous UST and LUNA holders' bags.
Terra 2.0 has 1,000,000,000,000 tokens to distribute.
25% of a community pool
Holders of pre-attack LUNA: 35%
10% of aUST holders prior to attack
Holders of LUNA after an attack: 10%
UST holders as of the attack: 20%
Every LUNA and UST holder has been compensated according to the above proposal.
According to self-reported data, the new chain has 210.000.000 tokens and a $1.3bn marketcap. LUNC and UST alone lost $40bn. The new token must fill this gap. Since launch:
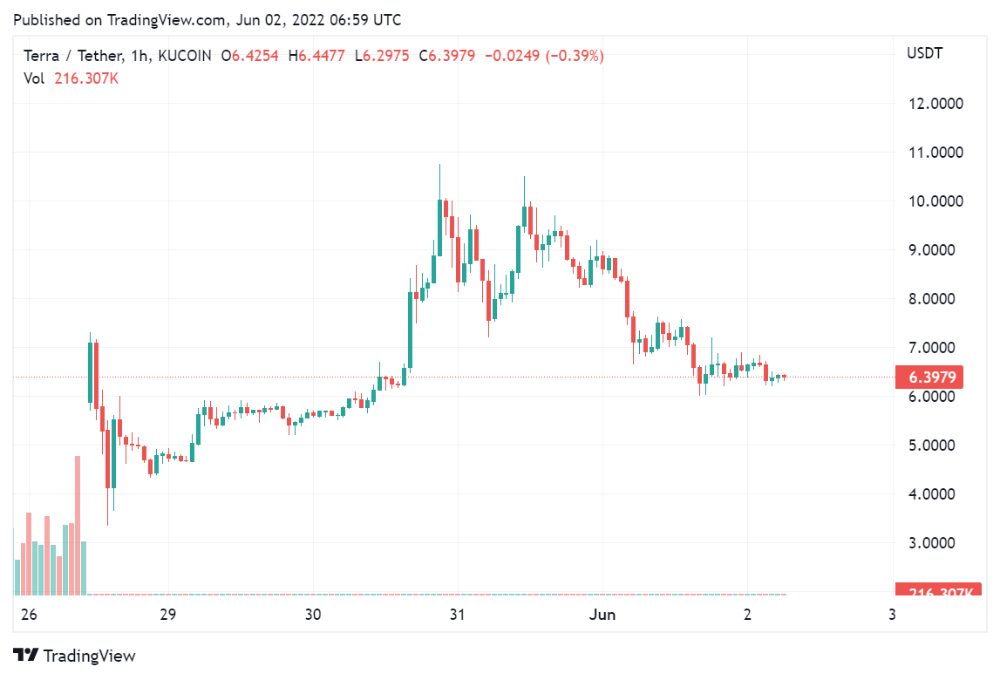
LUNA holders collectively own $1b worth of LUNA if we subtract the 25% community pool airdrop from the current market cap and assume airdropped LUNA was never sold.
At the current supply, the chain must grow 40 times to compensate holders. At the current supply, LUNA must reach $240.
LUNA needs a full-on Bull Market to make LUNC and UST holders whole.
Who knows if you'll be whole? From the time you bought to the amount and price, there are too many variables to determine if Terra can cover individual losses.
The above distribution doesn't consider individual cases. Terra didn't solve individual cases. It would have been huge.
What does LUNA offer in terms of value?
UST's marketcap peaked at $18bn, while LUNC's was $41bn. LUNC and UST drove the Terra chain's value.
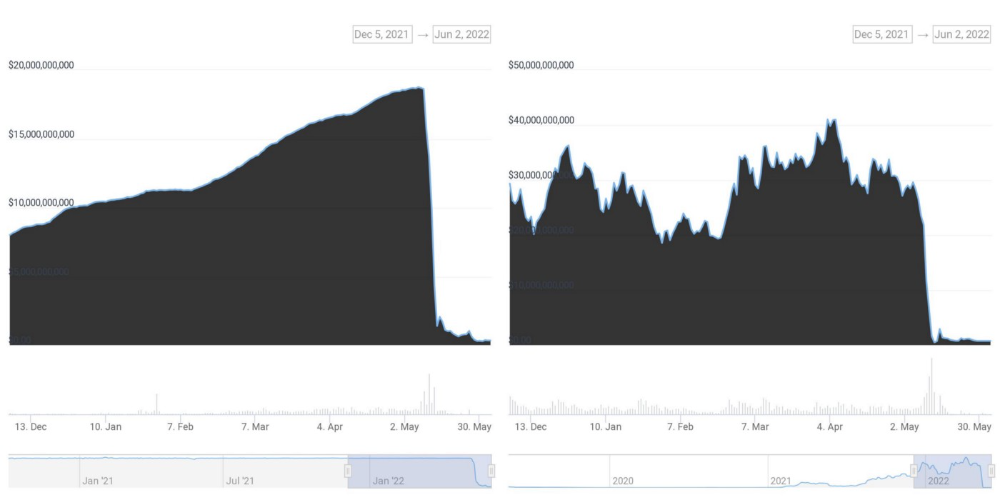
After it was confirmed (again) that algorithmic stablecoins are bad, Terra 2.0 will no longer support them.
Algorithmic stablecoins contributed greatly to Terra's growth and value proposition. Terra 2.0 has no product without algorithmic stablecoins.
Terra 2.0 has an identity crisis because it has no actual product. It's like Volkswagen faking carbon emission results and then stopping car production.
A project that has already lost the trust of its users and nearly all of its value cannot survive without a clear and in-demand use case.
Do Kwon, how about him?
Oh, the Twitter-caller-poor? Who challenges crypto billionaires to break his LUNA chain? Who dissolved Terra Labs South Korea before depeg? Arrogant guy?
That's not a good image for LUNA, especially when making amends. I think he should step down and let a nicer person be Terra 2.0's frontman.
The verdict
Terra has a terrific community with an arrogant, unlikeable leader. The new LUNA chain must grow 40 times before it can start making up its losses, and even then, not everyone's losses will be covered.
I won't invest in Terra 2.0 or other algorithmic stablecoins in the near future. I won't be near any Do Kwon-related project within 100 miles. My opinion.
Can Terra 2.0 be saved? Comment below.

Sam Hickmann
4 years ago
A quick guide to formatting your text on INTΞGRITY
[06/20/2022 update] We have now implemented a powerful text editor, but you can still use markdown.
Markdown:
Headers
SYNTAX:
# This is a heading 1
## This is a heading 2
### This is a heading 3
#### This is a heading 4
RESULT:
This is a heading 1
This is a heading 2
This is a heading 3
This is a heading 4
Emphasis
SYNTAX:
**This text will be bold**
~~Strikethrough~~
*You **can** combine them*
RESULT:
This text will be italic
This text will be bold
You can combine them
Images
SYNTAX:

RESULT:
Videos
SYNTAX:
https://www.youtube.com/watch?v=7KXGZAEWzn0
RESULT:
Links
SYNTAX:
[Int3grity website](https://www.int3grity.com)
RESULT:
Tweets
SYNTAX:
https://twitter.com/samhickmann/status/1503800505864130561
RESULT:
Blockquotes
SYNTAX:
> Human beings face ever more complex and urgent problems, and their effectiveness in dealing with these problems is a matter that is critical to the stability and continued progress of society. \- Doug Engelbart, 1961
RESULT:
Human beings face ever more complex and urgent problems, and their effectiveness in dealing with these problems is a matter that is critical to the stability and continued progress of society. - Doug Engelbart, 1961
Inline code
SYNTAX:
Text inside `backticks` on a line will be formatted like code.
RESULT:
Text inside backticks on a line will be formatted like code.
Code blocks
SYNTAX:
'''js
function fancyAlert(arg) {
if(arg) {
$.facebox({div:'#foo'})
}
}
'''
RESULT:
function fancyAlert(arg) {
if(arg) {
$.facebox({div:'#foo'})
}
}
Maths
We support LaTex to typeset math. We recommend reading the full documentation on the official website
SYNTAX:
$$[x^n+y^n=z^n]$$
RESULT:
[x^n+y^n=z^n]
Tables
SYNTAX:
| header a | header b |
| ---- | ---- |
| row 1 col 1 | row 1 col 2 |
RESULT:
| header a | header b | header c |
|---|---|---|
| row 1 col 1 | row 1 col 2 | row 1 col 3 |

Will Lockett
3 years ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.