





More on Entrepreneurship/Creators

Grace Huang
3 years ago
I sold 100 copies of my book when I had anticipated selling none.
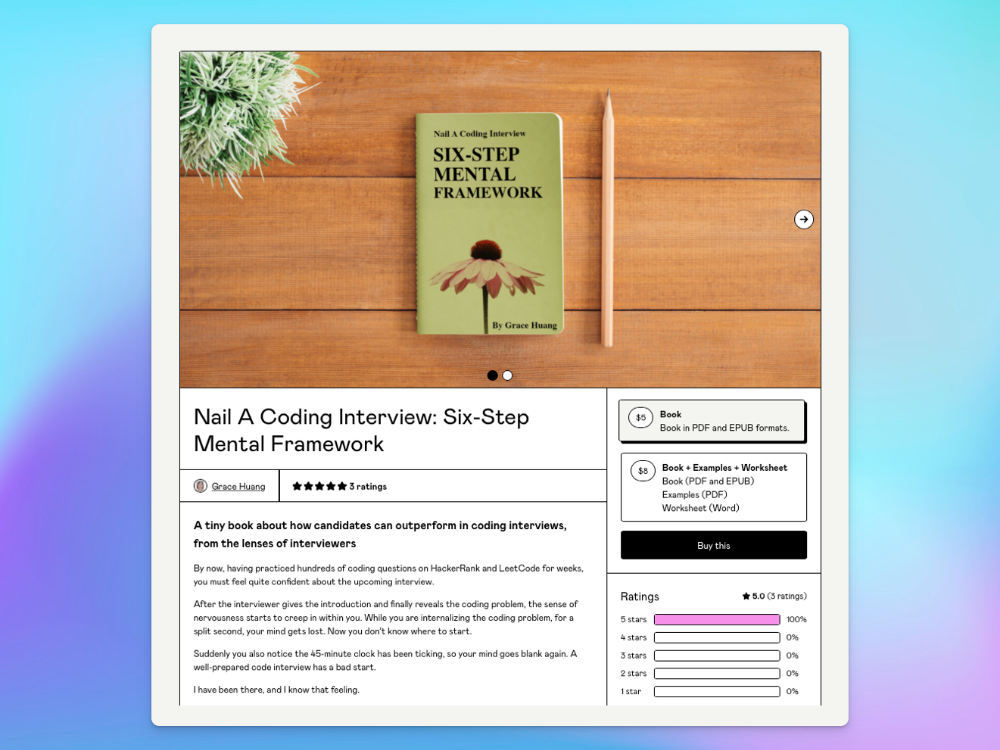
After a decade in large tech, I know how software engineers were interviewed. I've seen outstanding engineers fail interviews because their responses were too vague.
So I wrote Nail A Coding Interview: Six-Step Mental Framework. Give candidates a mental framework for coding questions; help organizations better prepare candidates so they can calibrate traits.
Recently, I sold more than 100 books, something I never expected.
In this essay, I'll describe my publication journey, which included self-doubt and little triumphs. I hope this helps if you want to publish.
It was originally a Medium post.
How did I know to develop a coding interview book? Years ago, I posted on Medium.
Six steps to ace a coding interview Inhale. blog.devgenius.io
This story got a lot of attention and still gets a lot of daily traffic. It indicates this domain's value.
Converted the Medium article into an ebook
The Medium post contains strong bullet points, but it is missing the “flesh”. How to use these strategies in coding interviews, for example. I filled in the blanks and made a book.
I made the book cover for free. It's tidy.
Shared the article with my close friends on my social network WeChat.
I shared the book on Wechat's Friend Circle (朋友圈) after publishing it on Gumroad. Many friends enjoyed my post. It definitely triggered endorphins.
In Friend Circle, I presented a 100% off voucher. No one downloaded the book. Endorphins made my heart sink.
Several days later, my Apple Watch received a Gumroad notification. A friend downloaded it. I majored in finance, he subsequently said. My brother-in-law can get it? He downloaded it to cheer me up.
I liked him, but was disappointed that he didn't read it.
The Tipping Point: Reddit's Free Giving
I trusted the book. It's based on years of interviewing. I felt it might help job-hunting college students. If nobody wants it, it can still have value.
I posted the book's link on /r/leetcode. I told them to DM me for a free promo code.
Momentum shifted everything. Gumroad notifications kept coming when I was out with family. Following orders.
As promised, I sent DMs a promo code. Some consumers ordered without asking for a promo code. Some readers finished the book and posted reviews.
My book was finally on track.
A 5-Star Review, plus More
A reader afterwards DMed me and inquired if I had another book on system design interviewing. I said that was a good idea, but I didn't have one. If you write one, I'll be your first reader.
Later, I asked for a book review. Yes, but how? That's when I learned readers' reviews weren't easy. I built up an email pipeline to solicit customer reviews. Since then, I've gained credibility through ratings.
Learnings
I wouldn't have gotten 100 if I gave up when none of my pals downloaded. Here are some lessons.
Your friends are your allies, but they are not your clients.
Be present where your clients are
Request ratings and testimonials
gain credibility gradually
I did it, so can you. Follow me on Twitter @imgracehuang for my publishing and entrepreneurship adventure.

Keagan Stokoe
3 years ago
Generalists Create Startups; Specialists Scale Them
There’s a funny part of ‘Steve Jobs’ by Walter Isaacson where Jobs says that Bill Gates was more a copier than an innovator:
“Bill is basically unimaginative and has never invented anything, which is why I think he’s more comfortable now in philanthropy than technology. He just shamelessly ripped off other people’s ideas….He’d be a broader guy if he had dropped acid once or gone off to an ashram when he was younger.”
Gates lacked flavor. Nobody ever got excited about a Microsoft launch, despite their good products. Jobs had the world's best product taste. Apple vs. Microsoft.
A CEO's core job functions are all driven by taste: recruiting, vision, and company culture all require good taste. Depending on the type of company you want to build, know where you stand between Microsoft and Apple.
How can you improve your product judgment? How to acquire taste?

Test and refine
Product development follows two parallel paths: the ‘customer obsession’ path and the ‘taste and iterate’ path.
The customer obsession path involves solving customer problems. Lean Startup frameworks show you what to build at each step.
Taste-and-iterate doesn't involve the customer. You iterate internally and rely on product leaders' taste and judgment.
Creative Selection by Ken Kocienda explains this method. In Creative Selection, demos are iterated and presented to product leaders. Your boss presents to their boss, and so on up to Steve Jobs. If you have good product taste, you can be a panelist.
The iPhone follows this path. Before seeing an iPhone, consumers couldn't want one. Customer obsession wouldn't have gotten you far because iPhone buyers didn't know they wanted one.
In The Hard Thing About Hard Things, Ben Horowitz writes:
“It turns out that is exactly what product strategy is all about — figuring out the right product is the innovator’s job, not the customer’s job. The customer only knows what she thinks she wants based on her experience with the current product. The innovator can take into account everything that’s possible, but often must go against what she knows to be true. As a result, innovation requires a combination of knowledge, skill, and courage.“
One path solves a problem the customer knows they have, and the other doesn't. Instead of asking a person what they want, observe them and give them something they didn't know they needed.
It's much harder. Apple is the world's most valuable company because it's more valuable. It changes industries permanently.
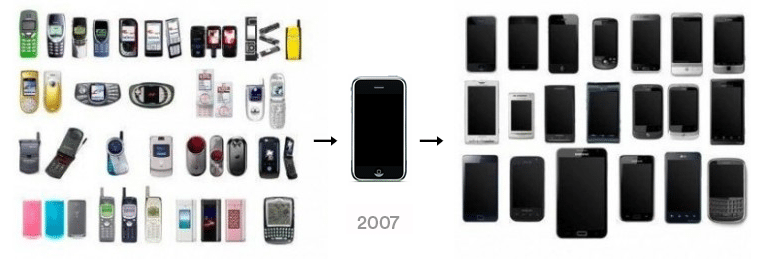
If you want to build superior products, use the iPhone of your industry.
How to Improve Your Taste
I. Work for a company that has taste.
People with the best taste in products, markets, and people are rewarded for building great companies. Tasteful people know quality even when they can't describe it. Taste isn't writable. It's feel-based.
Moving into a community that's already doing what you want to do may be the best way to develop entrepreneurial taste. Most company-building knowledge is tacit.
Joining a company you want to emulate allows you to learn its inner workings. It reveals internal patterns intuitively. Many successful founders come from successful companies.
Consumption determines taste. Excellence will refine you. This is why restauranteurs visit the world's best restaurants and serious painters visit Paris or New York. Joining a company with good taste is beneficial.
2. Possess a wide range of interests
“Edwin Land of Polaroid talked about the intersection of the humanities and science. I like that intersection. There’s something magical about that place… The reason Apple resonates with people is that there’s a deep current of humanity in our innovation. I think great artists and great engineers are similar, in that they both have a desire to express themselves.” — Steve Jobs
I recently discovered Edwin Land. Jobs modeled much of his career after Land's. It makes sense that Apple was inspired by Land.
A Triumph of Genius: Edwin Land, Polaroid, and the Kodak Patent War notes:
“Land was introverted in person, but supremely confident when he came to his ideas… Alongside his scientific passions, lay knowledge of art, music, and literature. He was a cultured person growing even more so as he got older, and his interests filtered into the ethos of Polaroid.”
Founders' philosophies shape companies. Jobs and Land were invested. It showed in the products their companies made. Different. His obsession was spreading Microsoft software worldwide. Microsoft's success is why their products are bland and boring.
Experience is important. It's probably why startups are built by generalists and scaled by specialists.
Jobs combined design, typography, storytelling, and product taste at Apple. Some of the best original Mac developers were poets and musicians. Edwin Land liked broad-minded people, according to his biography. Physicist-musicians or physicist-photographers.
Da Vinci was a master of art, engineering, architecture, anatomy, and more. He wrote and drew at the same desk. His genius is remembered centuries after his death. Da Vinci's statue would stand at the intersection of humanities and science.
We find incredibly creative people here. Superhumans. Designers, creators, and world-improvers. These are the people we need to navigate technology and lead world-changing companies. Generalists lead.

Dani Herrera
3 years ago
What prevents companies from disclosing salary information?

Yes, salary details ought to be mentioned in job postings. Recruiters and candidates both agree, so why doesn't it happen?
The short answer is “Unfortunately, it’s not the Recruiter’s decision”. The longer answer is well… A LOT.
Starting in November 2022, NYC employers must include salary ranges in job postings. It should have started in May, but companies balked.
I'm thrilled about salary transparency. This decision will promote fair, inclusive, and equitable hiring practices, and I'm sure other states will follow suit. Good news!
Candidates, recruiters, and ED&I practitioners have advocated for pay transparency for years. Why the opposition?
Let's quickly review why companies have trouble sharing salary bands.
💰 Pay Parity
Many companies and leaders still oppose pay parity. Yes, even in 2022.
💰 Pay Equity
Many companies believe in pay parity and have reviewed their internal processes and systems to ensure equality.
However, Pay Equity affects who gets roles/promotions/salary raises/bonuses and when. Enter the pay gap!
💰Pay Transparency and its impact on Talent Retention
Sharing salary bands with external candidates (and the world) means current employees will have access to that information, which is one of the main reasons companies don't share salary data.
If a company has Pay Parity and Pay Equity issues, they probably have a Pay Transparency policy as well.
Sharing salary information with external candidates without ensuring current employees understand their own salary bands and how promotions/raises are decided could impact talent retention strategies.
This information should help clarify recent conversations.
You might also like

nft now
3 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here

Emma Jade
3 years ago
6 hacks to create content faster
Content gurus' top time-saving hacks.

I'm a content strategist, writer, and graphic designer. Time is more valuable than money.
Money is always available. Even if you're poor. Ways exist.
Time is passing, and one day we'll run out.
Sorry to be morbid.
In today's digital age, you need to optimize how you create content for your organization. Here are six content creation hacks.
1. Use templates
Use templates to streamline your work whether generating video, images, or documents.
Setup can take hours. Using a free resource like Canva, you can create templates for any type of material.
This will save you hours each month.
2. Make a content calendar
You post without a plan? A content calendar solves 50% of these problems.
You can prepare, organize, and plan your material ahead of time so you're not scrambling when you remember, "Shit, it's Mother's Day!"
3. Content Batching
Batching content means creating a lot in one session. This is helpful for video content that requires a lot of setup time.
Batching monthly content saves hours. Time is a valuable resource.
When working on one type of task, it's easy to get into a flow state. This saves time.
4. Write Caption
On social media, we generally choose the image first and then the caption. Writing captions first sometimes work better, though.
Writing the captions first can allow you more creative flexibility and be easier if you're not excellent with language.
Say you want to tell your followers something interesting.
Writing a caption first is easier than choosing an image and then writing a caption to match.
Not everything works. You may have already-created content that needs captioning. When you don't know what to share, think of a concept, write the description, and then produce a video or graphic.
Cats can be skinned in several ways..
5. Repurpose
Reuse content when possible. You don't always require new stuff. In fact, you’re pretty stupid if you do #SorryNotSorry.
Repurpose old content. All those blog entries, videos, and unfinished content on your desk or hard drive.
This blog post can be turned into a social media infographic. Canva's motion graphic function can animate it. I can record a YouTube video regarding this issue for a podcast. I can make a post on each point in this blog post and turn it into an eBook or paid course.
And it doesn’t stop there.
My point is, to think outside the box and really dig deep into ways you can leverage the content you’ve already created.
6. Schedule Them
If you're still manually posting content, get help. When you batch your content, schedule it ahead of time.
Some scheduling apps are free or cheap. No excuses.
Don't publish and ghost.
Scheduling saves time by preventing you from doing it manually. But if you never engage with your audience, the algorithm won't reward your material.
Be online and engage your audience.
Content Machine
Use these six content creation hacks. They help you succeed and save time.
Daniel Clery
3 years ago
Twisted device investigates fusion alternatives
German stellarator revamped to run longer, hotter, compete with tokamaks

Tokamaks have dominated the search for fusion energy for decades. Just as ITER, the world's largest and most expensive tokamak, nears completion in southern France, a smaller, twistier testbed will start up in Germany.
If the 16-meter-wide stellarator can match or outperform similar-size tokamaks, fusion experts may rethink their future. Stellarators can keep their superhot gases stable enough to fuse nuclei and produce energy. They can theoretically run forever, but tokamaks must pause to reset their magnet coils.
The €1 billion German machine, Wendelstein 7-X (W7-X), is already getting "tokamak-like performance" in short runs, claims plasma physicist David Gates, preventing particles and heat from escaping the superhot gas. If W7-X can go long, "it will be ahead," he says. "Stellarators excel" Eindhoven University of Technology theorist Josefine Proll says, "Stellarators are back in the game." A few of startup companies, including one that Gates is leaving Princeton Plasma Physics Laboratory, are developing their own stellarators.
W7-X has been running at the Max Planck Institute for Plasma Physics (IPP) in Greifswald, Germany, since 2015, albeit only at low power and for brief runs. W7-X's developers took it down and replaced all inner walls and fittings with water-cooled equivalents, allowing for longer, hotter runs. The team reported at a W7-X board meeting last week that the revised plasma vessel has no leaks. It's expected to restart later this month to show if it can get plasma to fusion-igniting conditions.

Wendelstein 7-X's water-cooled inner surface allows for longer runs.
HOSAN/IPP
Both stellarators and tokamaks create magnetic gas cages hot enough to melt metal. Microwaves or particle beams heat. Extreme temperatures create a plasma, a seething mix of separated nuclei and electrons, and cause the nuclei to fuse, releasing energy. A fusion power plant would use deuterium and tritium, which react quickly. Non-energy-generating research machines like W7-X avoid tritium and use hydrogen or deuterium instead.
Tokamaks and stellarators use electromagnetic coils to create plasma-confining magnetic fields. A greater field near the hole causes plasma to drift to the reactor's wall.
Tokamaks control drift by circulating plasma around a ring. Streaming creates a magnetic field that twists and stabilizes ionized plasma. Stellarators employ magnetic coils to twist, not plasma. Once plasma physicists got powerful enough supercomputers, they could optimize stellarator magnets to improve plasma confinement.
W7-X is the first large, optimized stellarator with 50 6- ton superconducting coils. Its construction began in the mid-1990s and cost roughly twice the €550 million originally budgeted.
The wait hasn't disappointed researchers. W7-X director Thomas Klinger: "The machine operated immediately." "It's a friendly machine." It did everything we asked." Tokamaks are prone to "instabilities" (plasma bulging or wobbling) or strong "disruptions," sometimes associated to halted plasma flow. IPP theorist Sophia Henneberg believes stellarators don't employ plasma current, which "removes an entire branch" of instabilities.
In early stellarators, the magnetic field geometry drove slower particles to follow banana-shaped orbits until they collided with other particles and leaked energy. Gates believes W7-X's ability to suppress this effect implies its optimization works.
W7-X loses heat through different forms of turbulence, which push particles toward the wall. Theorists have only lately mastered simulating turbulence. W7-X's forthcoming campaign will test simulations and turbulence-fighting techniques.
A stellarator can run constantly, unlike a tokamak, which pulses. W7-X has run 100 seconds—long by tokamak standards—at low power. The device's uncooled microwave and particle heating systems only produced 11.5 megawatts. The update doubles heating power. High temperature, high plasma density, and extensive runs will test stellarators' fusion power potential. Klinger wants to heat ions to 50 million degrees Celsius for 100 seconds. That would make W7-X "a world-class machine," he argues. The team will push for 30 minutes. "We'll move step-by-step," he says.
W7-X's success has inspired VCs to finance entrepreneurs creating commercial stellarators. Startups must simplify magnet production.
Princeton Stellarators, created by Gates and colleagues this year, has $3 million to build a prototype reactor without W7-X's twisted magnet coils. Instead, it will use a mosaic of 1000 HTS square coils on the plasma vessel's outside. By adjusting each coil's magnetic field, operators can change the applied field's form. Gates: "It moves coil complexity to the control system." The company intends to construct a reactor that can fuse cheap, abundant deuterium to produce neutrons for radioisotopes. If successful, the company will build a reactor.
Renaissance Fusion, situated in Grenoble, France, raised €16 million and wants to coat plasma vessel segments in HTS. Using a laser, engineers will burn off superconductor tracks to carve magnet coils. They want to build a meter-long test segment in 2 years and a full prototype by 2027.
Type One Energy in Madison, Wisconsin, won DOE money to bend HTS cables for stellarator magnets. The business carved twisting grooves in metal with computer-controlled etching equipment to coil cables. David Anderson of the University of Wisconsin, Madison, claims advanced manufacturing technology enables the stellarator.
Anderson said W7-X's next phase will boost stellarator work. “Half-hour discharges are steady-state,” he says. “This is a big deal.”