




More on Web3 & Crypto

Sam Bourgi
4 years ago
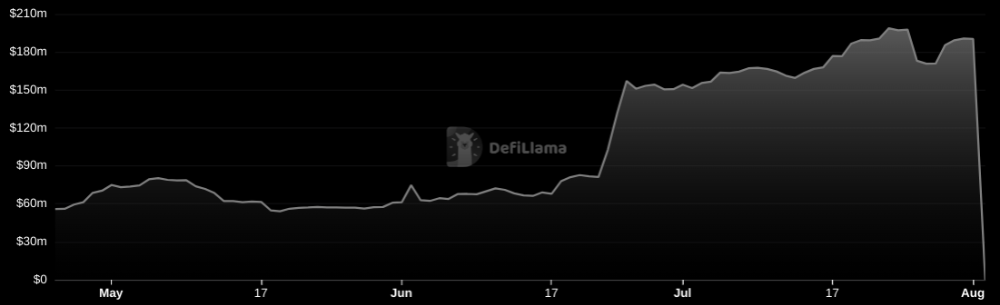
DAOs are legal entities in Marshall Islands.
The Pacific island state recognizes decentralized autonomous organizations.
The Republic of the Marshall Islands has recognized decentralized autonomous organizations (DAOs) as legal entities, giving collectively owned and managed blockchain projects global recognition.
The Marshall Islands' amended the Non-Profit Entities Act 2021 that now recognizes DAOs, which are blockchain-based entities governed by self-organizing communities. Incorporating Admiralty LLC, the island country's first DAO, was made possible thanks to the amendement. MIDAO Directory Services Inc., a domestic organization established to assist DAOs in the Marshall Islands, assisted in the incorporation.
The new law currently allows any DAO to register and operate in the Marshall Islands.
“This is a unique moment to lead,” said Bobby Muller, former Marshall Islands chief secretary and co-founder of MIDAO. He believes DAOs will help create “more efficient and less hierarchical” organizations.
A global hub for DAOs, the Marshall Islands hopes to become a global hub for DAO registration, domicile, use cases, and mass adoption. He added:
"This includes low-cost incorporation, a supportive government with internationally recognized courts, and a technologically open environment."
According to the World Bank, the Marshall Islands is an independent island state in the Pacific Ocean near the Equator. To create a blockchain-based cryptocurrency that would be legal tender alongside the US dollar, the island state has been actively exploring use cases for digital assets since at least 2018.
In February 2018, the Marshall Islands approved the creation of a new cryptocurrency, Sovereign (SOV). As expected, the IMF has criticized the plan, citing concerns that a digital sovereign currency would jeopardize the state's financial stability. They have also criticized El Salvador, the first country to recognize Bitcoin (BTC) as legal tender.
Marshall Islands senator David Paul said the DAO legislation does not pose the same issues as a government-backed cryptocurrency. “A sovereign digital currency is financial and raises concerns about money laundering,” . This is more about giving DAOs legal recognition to make their case to regulators, investors, and consumers.

Shan Vernekar
3 years ago
How the Ethereum blockchain's transactions are carried out
Overview
Ethereum blockchain is a network of nodes that validate transactions. Any network node can be queried for blockchain data for free. To write data as a transition requires processing and writing to each network node's storage. Fee is paid in ether and is also called as gas.
We'll examine how user-initiated transactions flow across the network and into the blockchain.
Flow of transactions
A user wishes to move some ether from one external account to another. He utilizes a cryptocurrency wallet for this (like Metamask), which is a browser extension.
The user enters the desired transfer amount and the external account's address. He has the option to choose the transaction cost he is ready to pay.
Wallet makes use of this data, signs it with the user's private key, and writes it to an Ethereum node. Services such as Infura offer APIs that enable writing data to nodes. One of these services is used by Metamask. An example transaction is shown below. Notice the “to” address and value fields.
var rawTxn = {
nonce: web3.toHex(txnCount),
gasPrice: web3.toHex(100000000000),
gasLimit: web3.toHex(140000),
to: '0x633296baebc20f33ac2e1c1b105d7cd1f6a0718b',
value: web3.toHex(0),
data: '0xcc9ab24952616d6100000000000000000000000000000000000000000000000000000000'
};The transaction is written to the target Ethereum node's local TRANSACTION POOL. It informed surrounding nodes of the new transaction, and those nodes reciprocated. Eventually, this transaction is received by and written to each node's local TRANSACTION pool.
The miner who finds the following block first adds pending transactions (with a higher gas cost) from the nearby TRANSACTION POOL to the block.
The transactions written to the new block are verified by other network nodes.
A block is added to the main blockchain after there is consensus and it is determined to be genuine. The local blockchain is updated with the new node by additional nodes as well.
Block mining begins again next.
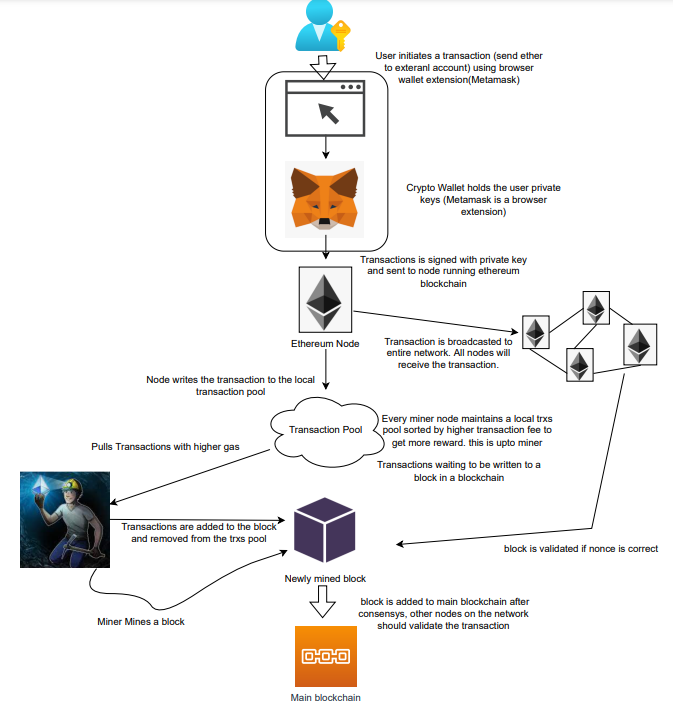
The image above shows how transactions go via the network and what's needed to submit them to the main block chain.
References
ethereum.org/transactions How Ethereum transactions function, their data structure, and how to send them via app. ethereum.org

CyberPunkMetalHead
3 years ago
195 countries want Terra Luna founder Do Kwon
Interpol has issued a red alert on Terraform Labs' CEO, South Korean prosecutors said.

After the May crash of Terra Luna revealed tax evasion issues, South Korean officials filed an arrest warrant for Do Kwon, but he is missing.
Do Kwon is now a fugitive in 195 countries after Seoul prosecutors placed him to Interpol's red list. Do Kwon hasn't commented since then. The red list allows any country's local authorities to apprehend Do Kwon.
Do Dwon and Terraform Labs were believed to have moved to Singapore days before the $40 billion wipeout, but Singapore authorities said he fled the country on September 17. Do Kwon tweeted that he wasn't on the run and cited privacy concerns.
Do Kwon was not on the red list at the time and said he wasn't "running," only to reply to his own tweet saying he hasn't jogged in a while and needed to trim calories.
Whether or not it makes sense to read too much into this, the reality is that Do Kwon is now on Interpol red list, despite the firmly asserts on twitter that he does absolutely nothing to hide.
UPDATE:
South Korean authorities are investigating alleged withdrawals of over $60 million U.S. and seeking to freeze these assets. Korean authorities believe a new wallet exchanged over 3000 BTC through OKX and Kucoin.
Do Kwon and the Luna Foundation Guard (of whom Do Kwon is a key member of) have declined all charges and dubbed this disinformation.
Singapore's Luna Foundation Guard (LFG) manages the Terra Ecosystem.
The Legal Situation
Multiple governments are searching for Do Kwon and five other Terraform Labs employees for financial markets legislation crimes.
South Korean authorities arrested a man suspected of tax fraud and Ponzi scheme.
The U.S. SEC is also examining Terraform Labs on how UST was advertised as a stablecoin. No legal precedent exists, so it's unclear what's illegal.
The future of Terraform Labs, Terra, and Terra 2 is unknown, and despite what Twitter shills say about LUNC, the company remains in limbo awaiting a decision that will determine its fate. This project isn't a wise investment.
You might also like

Tech With Dom
3 years ago
6 Awesome Desk Accessories You Must Have!

I'm gadget-obsessed. So I shared my top 6 desk gadgets.
These gadgets improve my workflow and are handy for working from home.
Without further ado...
Computer light bar Xiaomi Mi

I've previously recommended the Xiaomi Mi Light Bar, and I still do. It's stylish and convenient.
The Mi bar is a monitor-mounted desk lamp. The lamp's hue and brightness can be changed with a stylish wireless remote.
Changeable hue and brightness make it ideal for late-night work.
Desk Mat 2.

I wasn't planning to include a desk surface in this article, but I find it improves computer use.
The mouse feels smoother and is a better palm rest than wood or glass.
I'm currently using the overkill Razer Goliathus Extended Chroma RGB Gaming Surface, but I like RGB.
Using a desk surface or mat makes computer use more comfortable, and it's not expensive.
Third, the Logitech MX Master 3 Mouse

The Logitech MX Master 3 or any from the MX Master series is my favorite mouse.
The side scroll wheel on these mice is a feature I've never seen on another mouse.
Side scroll wheels are great for spreadsheets and video editing. It would be hard for me to switch from my Logitech MX Master 3 to another mouse. Only gaming is off-limits.
Google Nest 4.

Without a smart assistant, my desk is useless. I'm currently using the second-generation Google Nest Hub, but I've also used the Amazon Echo Dot, Echo Spot, and Apple HomePod Mini.
As a Pixel 6 Pro user, the Nest Hub works best with my phone.
My Nest Hub plays news, music, and calendar events. It also lets me control lights and switches with my smartphone. It plays YouTube videos.
Google Pixel Stand, No. 5

A wireless charger on my desk is convenient for charging my phone and other devices while I work. My desk has two wireless chargers. I have a Satechi aluminum fast charger and a second-generation Google Pixel Stand.
If I need to charge my phone and earbuds simultaneously, I use two wireless chargers. Satechi chargers are well-made and fast. Micro-USB is my only complaint.
The Pixel Stand converts compatible devices into a smart display for adjusting charging speeds and controlling other smart devices. My Pixel 6 Pro charges quickly. Here's my video review.
6. Anker Power Bank

Anker's 65W charger is my final recommendation. This online find was a must-have. This can charge my laptop and several non-wireless devices, perfect for any techie!
The charger has two USB-A ports and two USB-C ports, one with 45W and the other with 20W, so it can charge my iPad Pro and Pixel 6 Pro simultaneously.
Summary
These are some of my favorite office gadgets. My kit page has an updated list.
Links to the products mentioned in this article are in the appropriate sections. These are affiliate links.
You're up! Share the one desk gadget you can't live without and why.

Jano le Roux
3 years ago
Never Heard Of: The Apple Of Email Marketing Tools
Unlimited everything for $19 monthly!?
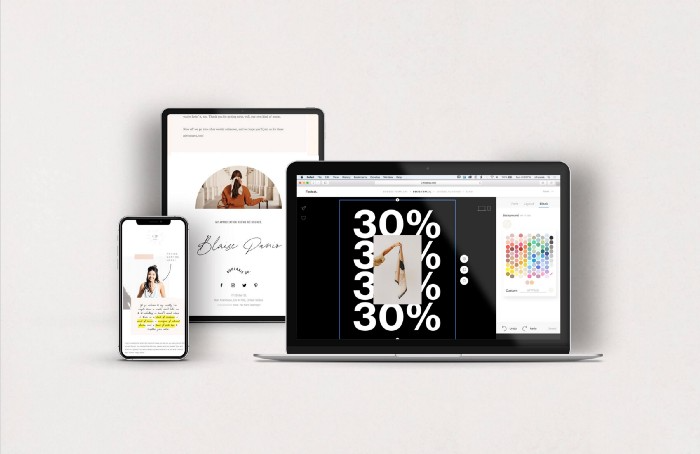
Even with pretty words, no one wants to read an ugly email.
Not Gen Z
Not Millennials
Not Gen X
Not Boomers
I am a minimalist.
I like Mozart. I like avos. I love Apple.
When I hear seamlessly, effortlessly, or Apple's new adverb fluidly, my toes curl.
No email marketing tool gave me that feeling.
As a marketing consultant helping high-growth brands create marketing that doesn't feel like marketing, I've worked with every email marketing platform imaginable, including that naughty monkey and the expensive platform whose sales teams don't stop calling.
Most email marketing platforms are flawed.
They are overpriced.
They use dreadful templates.
They employ a poor visual designer.
The user experience there is awful.
Too many useless buttons are present. (Similar to the TV remote!)
I may have finally found the perfect email marketing tool. It creates strong flows. It helps me focus on storytelling.
It’s called Flodesk.
It’s effortless. It’s seamless. It’s fluid.
Here’s why it excites me.
Unlimited everything for $19 per month
Sends unlimited. Emails unlimited. Signups unlimited.
Most email platforms penalize success.
Pay for performance?
$87 for 10k contacts
$605 for 100K contacts
$1,300+ for 200K contacts
In the 1990s, this made sense, but not now. It reminds me of when ISPs capped internet usage at 5 GB per month.
Flodesk made unlimited email for a low price a reality. Affordable, attractive email marketing isn't just for big companies.
Flodesk doesn't penalize you for growing your list. Price stays the same as lists grow.
Flodesk plans cost $38 per month, but I'll give you a 30-day trial for $19.
Amazingly strong flows
Foster different people's flows.
Email marketing isn't one-size-fits-all.
Different times require different emails.
People don't open emails because they're irrelevant, in my experience. A colder audience needs a nurturing sequence.
Flodesk automates your email funnels so top-funnel prospects fall in love with your brand and values before mid- and bottom-funnel email flows nudge them to take action.
I wish I could save more custom audience fields to further customize the experience.
Dynamic editor
Easy. Effortless.
Flodesk's editor is Apple-like.
You understand how it works almost instantly.
Like many Apple products, it's intentionally limited. No distractions. You can focus on emotional email writing.
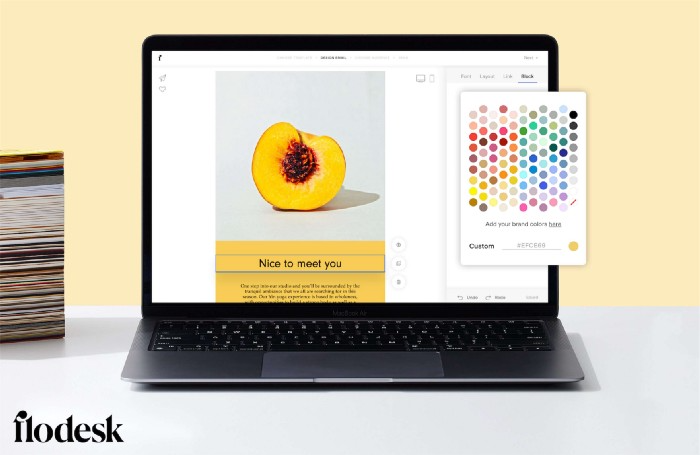
Flodesk's inability to add inline HTML to emails is my biggest issue with larger projects. I wish I could upload HTML emails.
Simple sign-up procedures
Dream up joining.
I like how easy it is to create conversion-focused landing pages. Linkly lets you easily create 5 landing pages and A/B test messaging.
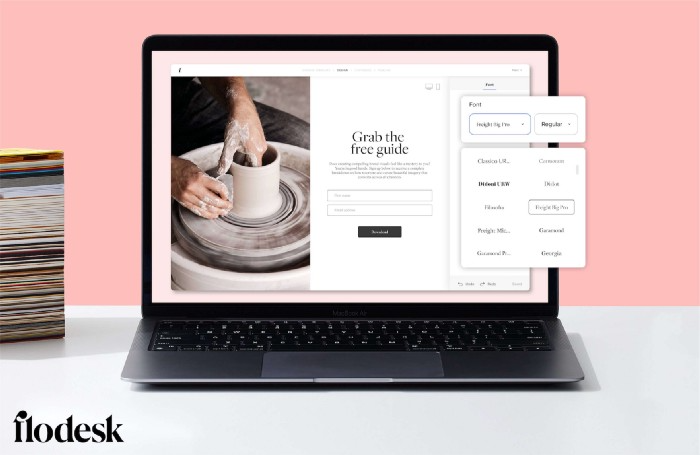
I like that you can use signup forms to ask people what they're interested in so they get relevant emails instead of mindless mass emails nobody opens.
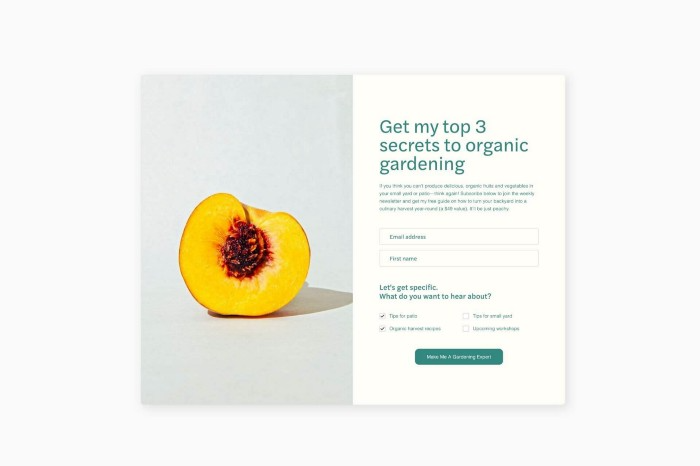
I love how easy it is to embed in-line on a website.
Wonderful designer templates
Beautiful, connecting emails.
Flodesk has calm email templates. My designer's eye felt at rest when I received plain text emails with big impacts.
As a typography nerd, I love Flodesk's handpicked designer fonts. It gives emails a designer feel that is hard to replicate on other platforms without coding and custom font licenses.
Small adjustments can have a big impact
Details matter.
Flodesk remembers your brand colors. Flodesk automatically adds your logo and social handles to emails after signup.
Flodesk uses Zapier. This lets you send emails based on a user's action.
A bad live chat can trigger a series of emails to win back a customer.
Flodesk isn't for everyone.
Flodesk is great for Apple users like me.

Guillaume Dumortier
3 years ago
Mastering the Art of Rhetoric: A Guide to Rhetorical Devices in Successful Headlines and Titles
Unleash the power of persuasion and captivate your audience with compelling headlines.
As the old adage goes, "You never get a second chance to make a first impression."
In the world of content creation and social ads, headlines and titles play a critical role in making that first impression.
A well-crafted headline can make the difference between an article being read or ignored, a video being clicked on or bypassed, or a product being purchased or passed over.
To make an impact with your headlines, mastering the art of rhetoric is essential. In this post, we'll explore various rhetorical devices and techniques that can help you create headlines that captivate your audience and drive engagement.
tl;dr : Headline Magician will help you craft the ultimate headline titles powered by rhetoric devices
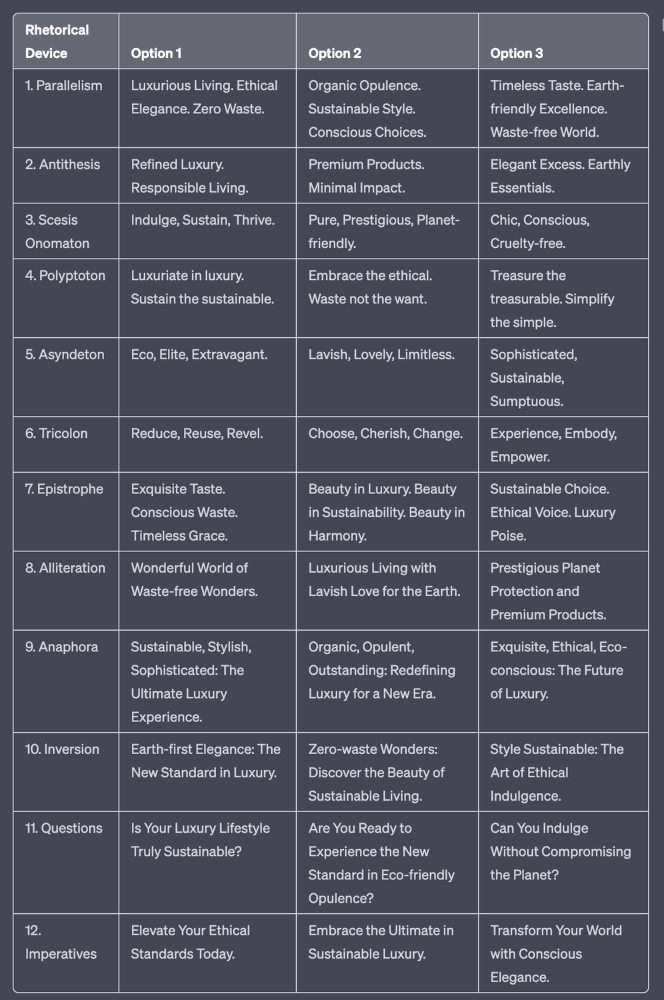
Example with a high-end luxury organic zero-waste skincare brand
✍️ The Power of Alliteration
Alliteration is the repetition of the same consonant sound at the beginning of words in close proximity. This rhetorical device lends itself well to headlines, as it creates a memorable, rhythmic quality that can catch a reader's attention.
By using alliteration, you can make your headlines more engaging and easier to remember.
Examples:
"Crafting Compelling Content: A Comprehensive Course"
"Mastering the Art of Memorable Marketing"
🔁 The Appeal of Anaphora
Anaphora is the repetition of a word or phrase at the beginning of successive clauses. This rhetorical device emphasizes a particular idea or theme, making it more memorable and persuasive.
In headlines, anaphora can be used to create a sense of unity and coherence, which can draw readers in and pique their interest.
Examples:
"Create, Curate, Captivate: Your Guide to Social Media Success"
"Innovation, Inspiration, and Insight: The Future of AI"
🔄 The Intrigue of Inversion
Inversion is a rhetorical device where the normal order of words is reversed, often to create an emphasis or achieve a specific effect.
In headlines, inversion can generate curiosity and surprise, compelling readers to explore further.
Examples:
"Beneath the Surface: A Deep Dive into Ocean Conservation"
"Beyond the Stars: The Quest for Extraterrestrial Life"
⚖️ The Persuasive Power of Parallelism
Parallelism is a rhetorical device that involves using similar grammatical structures or patterns to create a sense of balance and symmetry.
In headlines, parallelism can make your message more memorable and impactful, as it creates a pleasing rhythm and flow that can resonate with readers.
Examples:
"Eat Well, Live Well, Be Well: The Ultimate Guide to Wellness"
"Learn, Lead, and Launch: A Blueprint for Entrepreneurial Success"
⏭️ The Emphasis of Ellipsis
Ellipsis is the omission of words, typically indicated by three periods (...), which suggests that there is more to the story.
In headlines, ellipses can create a sense of mystery and intrigue, enticing readers to click and discover what lies behind the headline.
Examples:
"The Secret to Success... Revealed"
"Unlocking the Power of Your Mind... A Step-by-Step Guide"
🎭 The Drama of Hyperbole
Hyperbole is a rhetorical device that involves exaggeration for emphasis or effect.
In headlines, hyperbole can grab the reader's attention by making bold, provocative claims that stand out from the competition. Be cautious with hyperbole, however, as overuse or excessive exaggeration can damage your credibility.
Examples:
"The Ultimate Guide to Mastering Any Skill in Record Time"
"Discover the Revolutionary Technique That Will Transform Your Life"
❓The Curiosity of Questions
Posing questions in your headlines can be an effective way to pique the reader's curiosity and encourage engagement.
Questions compel the reader to seek answers, making them more likely to click on your content. Additionally, questions can create a sense of connection between the content creator and the audience, fostering a sense of dialogue and discussion.
Examples:
"Are You Making These Common Mistakes in Your Marketing Strategy?"
"What's the Secret to Unlocking Your Creative Potential?"
💥 The Impact of Imperatives
Imperatives are commands or instructions that urge the reader to take action. By using imperatives in your headlines, you can create a sense of urgency and importance, making your content more compelling and actionable.
Examples:
"Master Your Time Management Skills Today"
"Transform Your Business with These Innovative Strategies"
💢 The Emotion of Exclamations
Exclamations are powerful rhetorical devices that can evoke strong emotions and convey a sense of excitement or urgency.
Including exclamations in your headlines can make them more attention-grabbing and shareable, increasing the chances of your content being read and circulated.
Examples:
"Unlock Your True Potential: Find Your Passion and Thrive!"
"Experience the Adventure of a Lifetime: Travel the World on a Budget!"
🎀 The Effectiveness of Euphemisms
Euphemisms are polite or indirect expressions used in place of harsher, more direct language.
In headlines, euphemisms can make your message more appealing and relatable, helping to soften potentially controversial or sensitive topics.
Examples:
"Navigating the Challenges of Modern Parenting"
"Redefining Success in a Fast-Paced World"
⚡Antithesis: The Power of Opposites
Antithesis involves placing two opposite words side-by-side, emphasizing their contrasts. This device can create a sense of tension and intrigue in headlines.
Examples:
"Once a day. Every day"
"Soft on skin. Kill germs"
"Mega power. Mini size."
To utilize antithesis, identify two opposing concepts related to your content and present them in a balanced manner.
🎨 Scesis Onomaton: The Art of Verbless Copy
Scesis onomaton is a rhetorical device that involves writing verbless copy, which quickens the pace and adds emphasis.
Example:
"7 days. 7 dollars. Full access."
To use scesis onomaton, remove verbs and focus on the essential elements of your headline.
🌟 Polyptoton: The Charm of Shared Roots
Polyptoton is the repeated use of words that share the same root, bewitching words into memorable phrases.
Examples:
"Real bread isn't made in factories. It's baked in bakeries"
"Lose your knack for losing things."
To employ polyptoton, identify words with shared roots that are relevant to your content.
✨ Asyndeton: The Elegance of Omission
Asyndeton involves the intentional omission of conjunctions, adding crispness, conviction, and elegance to your headlines.
Examples:
"You, Me, Sushi?"
"All the latte art, none of the environmental impact."
To use asyndeton, eliminate conjunctions and focus on the core message of your headline.
🔮 Tricolon: The Magic of Threes
Tricolon is a rhetorical device that uses the power of three, creating memorable and impactful headlines.
Examples:
"Show it, say it, send it"
"Eat Well, Live Well, Be Well."
To use tricolon, craft a headline with three key elements that emphasize your content's main message.
🔔 Epistrophe: The Chime of Repetition
Epistrophe involves the repetition of words or phrases at the end of successive clauses, adding a chime to your headlines.
Examples:
"Catch it. Bin it. Kill it."
"Joint friendly. Climate friendly. Family friendly."
To employ epistrophe, repeat a key phrase or word at the end of each clause.