

More on Entrepreneurship/Creators

Alex Mathers
3 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.

Matthew O'Riordan
3 years ago
Trends in SaaS Funding from 2016 to 2022
Christopher Janz of Point Nine Capital created the SaaS napkin in 2016. This post shows how founders have raised cash in the last 6 years. View raw data.
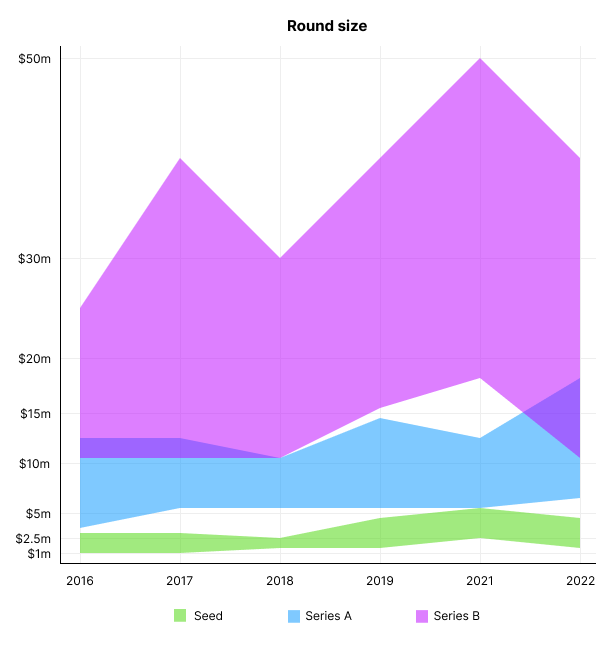
Round size
Unsurprisingly, round sizes have expanded and will taper down in 2022. In 2016, pre-seed rounds were $200k to $500k; currently, they're $1-$2m. Despite the macroeconomic scenario, Series A have expanded from $3m to $12m in 2016 to $6m and $18m in 2022.
Valuation
There are hints that valuations are rebounding this year. Pre-seed valuations in 2022 are $12m from $3m in 2016, and Series B prices are $270m from $100m in 2016.
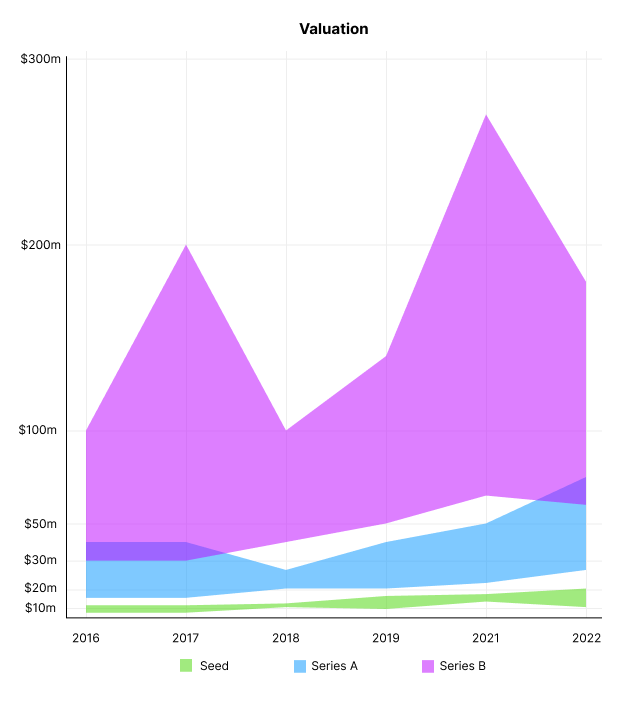
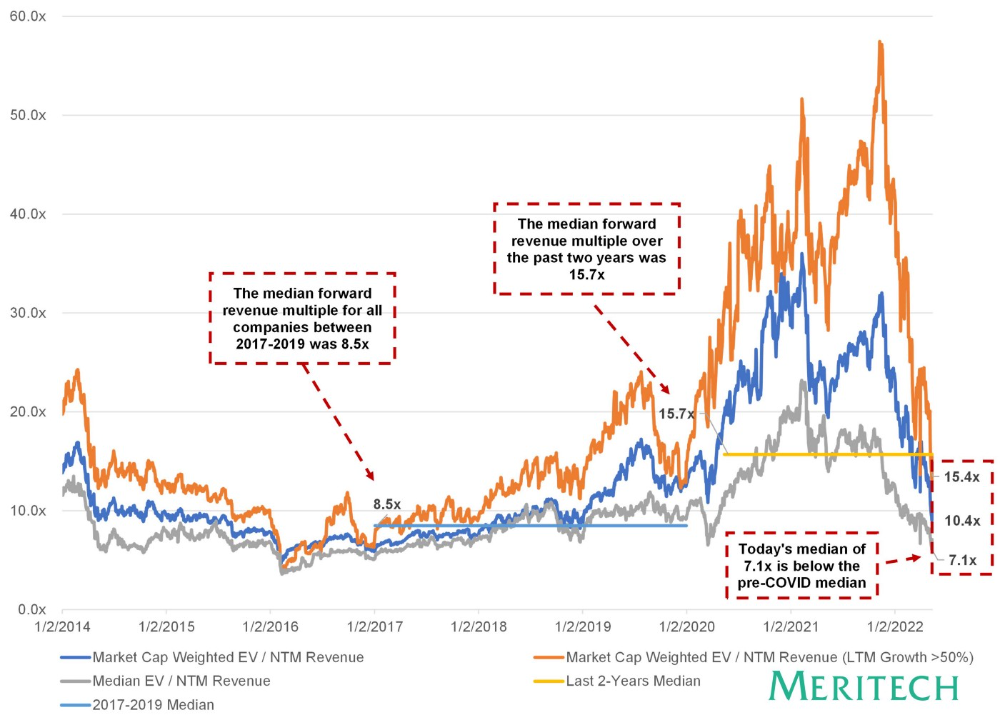
Compared to public SaaS multiples, Series B valuations more closely reflect the market, but Seed and Series A prices seem to be inflated regardless of the market.
I'd like to know how each annual cohort performed for investors, based on the year they invested and the valuations. I can't access this information.
ARR
Seed firms' ARR forecasts have risen from $0 to $0.6m to $0 to $1m. 2016 expected $1.2m to $3m, 2021 $0.5m to $4m, and this year $0.5m to $2.5m, suggesting that Series A firms may raise with less ARR today. Series B minutes fell from $4.2m to $3m.
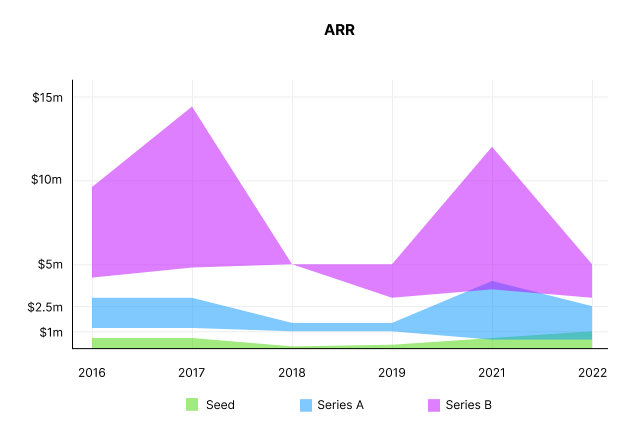
Capitalization Rate
2022 is the year that VCs start discussing capital efficiency in portfolio meetings. Given the economic shift in the markets and the stealthy VC meltdown, it's not surprising. Christopher Janz added capital efficiency to the SaaS Napkin as a new statistic for Series A (3.5x) and Series B. (2.5x). Your investors must live under a rock if they haven't asked about capital efficiency. If you're unsure:
The Capital Efficiency Ratio is the ratio of how much a company has spent growing revenue and how much they’re receiving in return. It is the broadest measure of company effectiveness in generating ARR
What next?
No one knows what's next, including me. All startup and growing enterprises around me are tightening their belts and extending their runways in anticipation of a difficult fundraising ride. If you're wanting to raise money but can wait, wait till the market is more stable and access to money is easier.

Sammy Abdullah
3 years ago
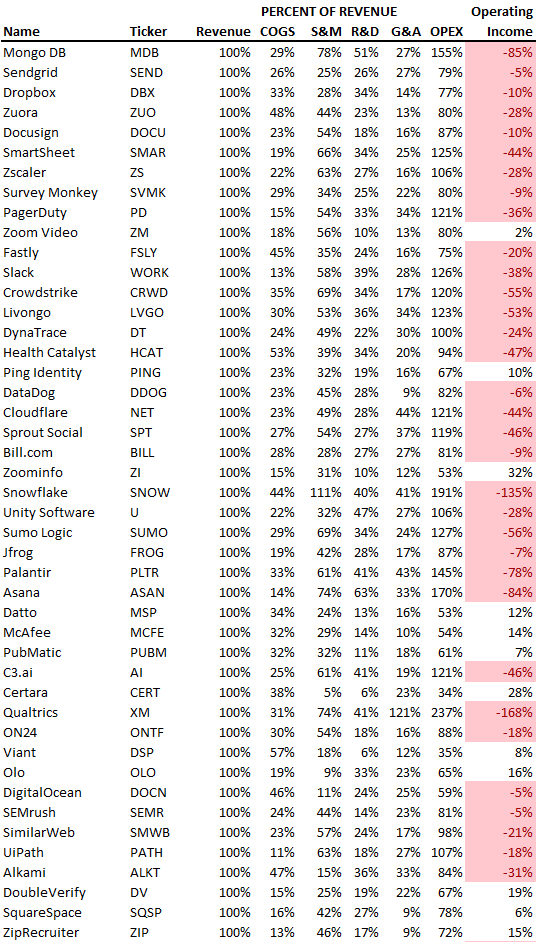
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
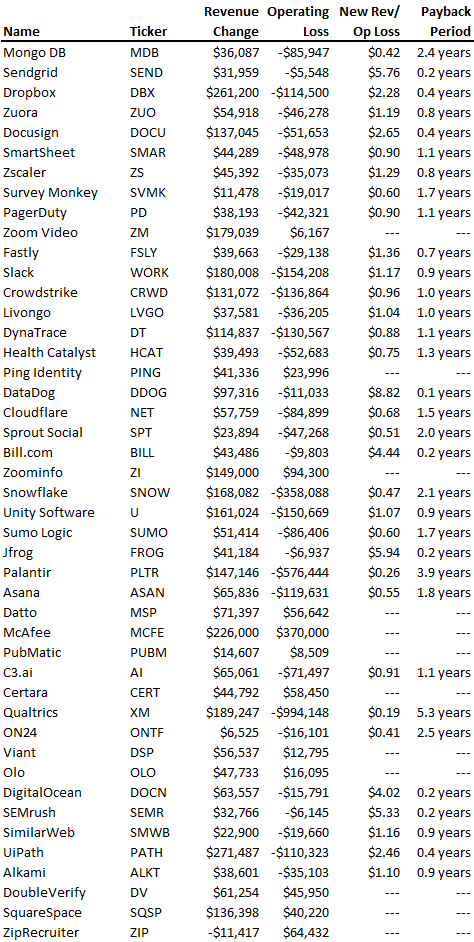
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.
You might also like

CyberPunkMetalHead
3 years ago
I talked to ChatGPT about the adoption of cryptocurrencies.

OpenAI's ChatGPT is an amazing AI-powered chatbot. It can write poetry, fiction, and marketing ideas. I was impressed how well ChatGPT followed the interview, albeit there were a few classics “I’m afraid I can’t do that”.
Full interview below.
Me: I'm your interviewer. We'll discuss crypto. Thanks for being interviewed. What do you think about cryptocurrency?
CGPT: Cryptocurrency is an innovative technology that could transform money and financial activities. It might boost the efficiency and security of financial institutions and let consumers deal directly without banks. Cryptocurrency is still a new and untested technology with many unknowns and hurdles before it can be broadly accepted.
Me: Over 22,000 cryptocurrencies exist, and many have little use. We need how much cryptocurrencies?
CGPT: The appropriate quantity will rely on a multitude of factors, including each cryptocurrency's use cases, adoption rate, and market rivalry. Only a few cryptocurrencies will likely receive widespread adoption and be successful. Many existing cryptocurrencies may not survive since they can't deliver new or valued solutions or compete with more established cryptocurrencies.
Me: Will cryptocurrencies grow? What's next for worldwide adoption?
CGPT: It's hard to forecast the future of cryptocurrencies because the acceptance of new technologies is unpredictable. I believe cryptocurrencies will expand and acquire popularity in the future years. Regulatory ambiguity, security concerns, and scalability issues must be overcome for this to happen. Cryptocurrency companies and organizations must engage together with governments and authorities to address these obstacles and establish a growth-friendly climate. Continued innovation and improvement of the technology, including public education and awareness, will drive acceptance.
Me: Do bear markets affect bitcoin adoption?
CGPT: On the one hand, a bear market might induce uncertainty and hesitation among potential consumers. Bear markets can present opportunities for long-term investors who can acquire cryptocurrencies at cheaper prices and are more likely to hang onto their assets. A bear market can also test the tenacity and power of the underlying technology and community, which can boost long-term confidence and adoption. A bear market might have profound and nuanced effects on bitcoin adoption.
Me: What are some likely outcomes if Bitcoin reaches $100,000 by next year?
CGPT: If Bitcoin saw rapid growth, it would undoubtedly have repercussions for the cryptocurrency market and economy. Possible scenarios include increased public interest and awareness of cryptocurrency, a surge in demand for Bitcoin and other cryptocurrencies, and a growth in the cryptocurrency industry's market value. By shifting their focus and cash to the cryptocurrency market, investors and traders may also affect other asset classes, such as traditional equities and commodities. Governments and financial organizations may focus more on the cryptocurrency sector as they try to grasp Bitcoin's rapid rise.
Me: Will other countries accept crypto as currency?
CGPT: It's hard to say if additional governments will adopt cryptocurrencies as legal tender. Some countries have recognized the promise of bitcoin and are exploring its use, while others are cautious. Adoption of bitcoin as legal cash may vary by country, based on financial infrastructure, rules, and political atmosphere. As cryptocurrency technology evolves and becomes more accepted, more governments may embrace it as legal tender.
Me: Final question: will the recent cryptocurrency hacks affect long term adoption?
CGPT: Hacks might tarnish cryptocurrency's reputation and public faith in its security, the technology underpinning it is continually improving. Many cryptocurrency projects have developed strong security mechanisms to prevent hacks and other dangers, and these safeguards will undoubtedly improve over time. The decentralized nature of cryptocurrency makes it more resistant to attacks. Hacks and other security breaches are a concern, but they may not affect cryptocurrency adoption.
CyberPunkMetalHead
3 years ago
195 countries want Terra Luna founder Do Kwon
Interpol has issued a red alert on Terraform Labs' CEO, South Korean prosecutors said.

After the May crash of Terra Luna revealed tax evasion issues, South Korean officials filed an arrest warrant for Do Kwon, but he is missing.
Do Kwon is now a fugitive in 195 countries after Seoul prosecutors placed him to Interpol's red list. Do Kwon hasn't commented since then. The red list allows any country's local authorities to apprehend Do Kwon.
Do Dwon and Terraform Labs were believed to have moved to Singapore days before the $40 billion wipeout, but Singapore authorities said he fled the country on September 17. Do Kwon tweeted that he wasn't on the run and cited privacy concerns.
Do Kwon was not on the red list at the time and said he wasn't "running," only to reply to his own tweet saying he hasn't jogged in a while and needed to trim calories.
Whether or not it makes sense to read too much into this, the reality is that Do Kwon is now on Interpol red list, despite the firmly asserts on twitter that he does absolutely nothing to hide.
UPDATE:
South Korean authorities are investigating alleged withdrawals of over $60 million U.S. and seeking to freeze these assets. Korean authorities believe a new wallet exchanged over 3000 BTC through OKX and Kucoin.
Do Kwon and the Luna Foundation Guard (of whom Do Kwon is a key member of) have declined all charges and dubbed this disinformation.
Singapore's Luna Foundation Guard (LFG) manages the Terra Ecosystem.
The Legal Situation
Multiple governments are searching for Do Kwon and five other Terraform Labs employees for financial markets legislation crimes.
South Korean authorities arrested a man suspected of tax fraud and Ponzi scheme.
The U.S. SEC is also examining Terraform Labs on how UST was advertised as a stablecoin. No legal precedent exists, so it's unclear what's illegal.
The future of Terraform Labs, Terra, and Terra 2 is unknown, and despite what Twitter shills say about LUNC, the company remains in limbo awaiting a decision that will determine its fate. This project isn't a wise investment.
Alex Mathers
3 years ago
12 habits of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have mastered the art of self-humor.
Protectors take their job seriously, draining the room's energy.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Don’t hold their breath.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are aware of their own dietary requirements.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.