



More on Marketing

Victoria Kurichenko
3 years ago
My Blog Is in Google's Top 10—Here's How to Compete

"Competition" is beautiful and hateful.
Some people bury their dreams because they are afraid of competition. Others challenge themselves, shaping our world.
Competition is normal.
It spurs innovation and progress.
I wish more people agreed.
As a marketer, content writer, and solopreneur, my readers often ask:
"I want to create a niche website, but I have no ideas. Everything's done"
"Is a website worthwhile?"
I can't count how many times I said, "Yes, it makes sense, and you can succeed in a competitive market."
I encourage and share examples, but it's not enough to overcome competition anxiety.
I launched an SEO writing website for content creators a year ago, knowing it wouldn't beat Ahrefs, Semrush, Backlinko, etc.
Not needed.
Many of my website's pages rank highly on Google.
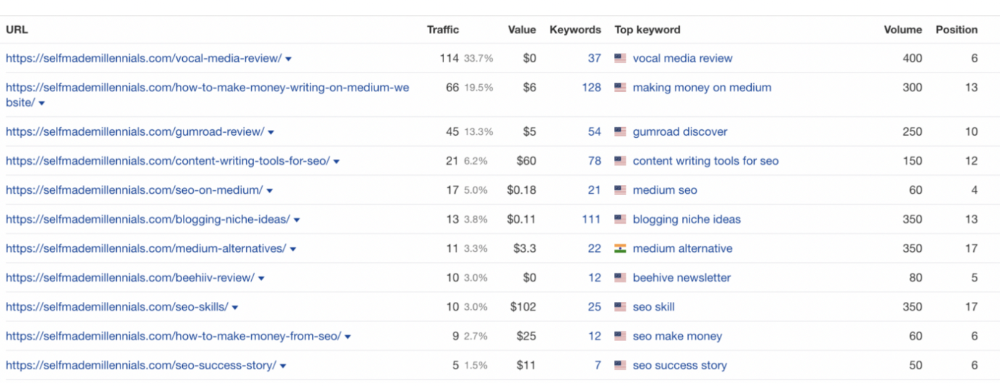
Everyone can eat the pie.
In a competitive niche, I took a different approach.
Look farther
When chatting with bloggers that want a website, I discovered something fascinating.
They want to launch a website but have no ideas. As a next step, they start listing the interests they believe they should work on, like wellness, lifestyle, investments, etc. I could keep going.
Too many generalists who claim to know everything confuse many.
Generalists aren't trusted.
We want someone to fix our problems immediately.
I don't think broad-spectrum experts are undervalued. People have many demands that go beyond generalists' work. Narrow-niche experts can help.
I've done SEO for three years. I learned from experts and courses. I couldn't find a comprehensive SEO writing resource.
I read tons of articles before realizing that wasn't it. I took courses that covered SEO basics eventually.
I had a demand for learning SEO writing, but there was no solution on the market. My website fills this micro-niche.
Have you ever had trouble online?
Professional courses too general, boring, etc.?
You've bought off-topic books, right?
You're not alone.
Niche ideas!
Big players often disregard new opportunities. Too small. Individual content creators can succeed here.
In a competitive market:
Never choose wide subjects
Think about issues you can relate to and have direct experience with.
Be a consumer to discover both the positive and negative aspects of a good or service.
Merchandise your annoyances.
Consider ways to transform your frustrations into opportunities.
The right niche is half-success. Here is what else I did to hit the Google front page with my website.
An innovative method for choosing subjects
Why publish on social media and websites?
Want likes, shares, followers, or fame?
Some people do it for fun. No judgment.
I bet you want more.
You want to make decent money from blogging.
Writing about random topics, even if they are related to your niche, won’t help you attract an audience from organic search. I'm a marketer and writer.
I worked at companies with dead blogs because they posted for themselves, not readers. They did not follow SEO writing rules; that’s why most of their content flopped.
I learned these hard lessons and grew my website from 0 to 3,000+ visitors per month while working on it a few hours a week only. Evidence:
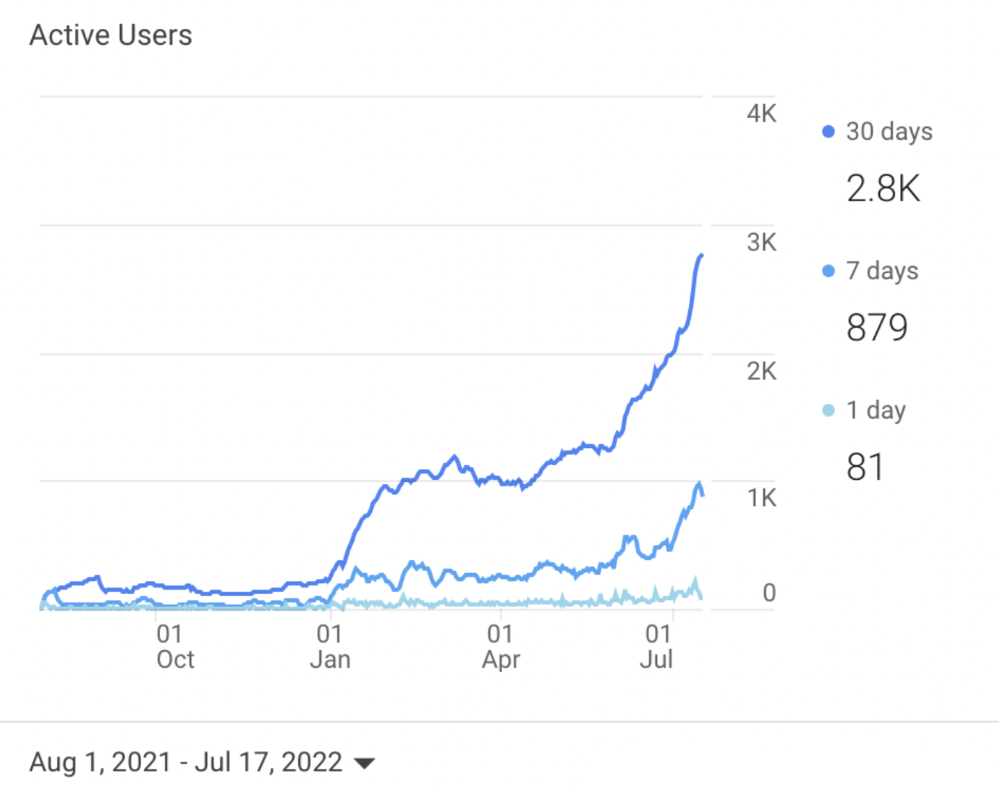
I choose website topics using these criteria:
- Business potential. The information should benefit my audience and generate revenue. There would be no use in having it otherwise.
My topics should help me:
Attract organic search traffic with my "fluff-free" content -> Subscribers > SEO ebook sales.
Simple and effective.
- traffic on search engines. The number of monthly searches reveals how popular my topic is all across the world. If I find that no one is interested in my suggested topic, I don't write a blog article.
- Competition. Every search term is up against rivals. Some are more popular (thus competitive) since more websites target them in organic search. A new website won't score highly for keywords that are too competitive. On the other side, keywords with moderate to light competition can help you rank higher on Google more quickly.
- Search purpose. The "why" underlying users' search requests is revealed. I analyze search intent to understand what users need when they plug various queries in the search bar and what content can perfectly meet their needs.
My specialty website produces money, ranks well, and attracts the target audience because I handpick high-traffic themes.
Following these guidelines, even a new website can stand out.
I wrote a 50-page SEO writing guide where I detailed topic selection and share my front-page Google strategy.
My guide can help you run a successful niche website.
In summary
You're not late to the niche-website party.
The Internet offers many untapped opportunities.
We need new solutions and are willing to listen.
There are unexplored niches in any topic.
Don't fight giants. They have their piece of the pie. They might overlook new opportunities while trying to keep that piece of the pie. You should act now.

Camilla Dudley
3 years ago
How to gain Twitter followers: A 101 Guide

No wonder brands use Twitter to reach their audience. 53% of Twitter users buy new products first.
Twitter growth does more than make your brand look popular. It helps clients trust your business. It boosts your industry standing. It shows clients, prospects, and even competitors you mean business.
How can you naturally gain Twitter followers?
Share useful information
Post visual content
Tweet consistently
Socialize
Spread your @name everywhere.
Use existing customers
Promote followers
Share useful information
Twitter users join conversations and consume material. To build your followers, make sure your material appeals to them and gives value, whether it's sales, product lessons, or current events.
Use Twitter Analytics to learn what your audience likes.
Explore popular topics by utilizing relevant keywords and hashtags. Check out this post on how to use Twitter trends.
Post visual content
97% of Twitter users focus on images, so incorporating media can help your Tweets stand out. Visuals and videos make content more engaging and memorable.
Tweet often
Your audience should expect regular content updates. Plan your ideas and tweet during crucial seasons and events with a content calendar.
Socialize
Twitter connects people. Do more than tweet. Follow industry leaders. Retweet influencers, engage with thought leaders, and reply to mentions and customers to boost engagement.
Micro-influencers can promote your brand or items. They can help you gain new audiences' trust.
Spread your @name everywhere.
Maximize brand exposure. Add a follow button on your website, link to it in your email signature and newsletters, and promote it on business cards or menus.
Use existing customers
Emails can be used to find existing Twitter clients. Upload your email contacts and follow your customers on Twitter to start a dialogue.
Promote followers
Run a followers campaign to boost your organic growth. Followers campaigns promote your account to a particular demographic, and you only pay when someone follows you.
Consider short campaigns to enhance momentum or an always-on campaign to gain new followers.
Increasing your brand's Twitter followers takes effort and experimentation, but the payback is huge.
👋 Follow me on twitter

Yucel F. Sahan
3 years ago
How I Created the Day's Top Product on Product Hunt
In this article, I'll describe a weekend project I started to make something. It was Product Hunt's #1 of the Day, #2 Weekly, and #4 Monthly product.


How did I make Landing Page Checklist so simple? Building and launching took 3 weeks. I worked 3 hours a day max. Weekends were busy.
It's sort of a long story, so scroll to the bottom of the page to see what tools I utilized to create Landing Page Checklist :x
As a matter of fact, it all started with the startups-investments blog; Startup Bulletin, that I started writing in 2018. No, don’t worry, I won’t be going that far behind. The twitter account where I shared the blog posts of this newsletter was inactive for a looong time. I was holding this Twitter account since 2009, I couldn’t bear to destroy it. At the same time, I was thinking how to evaluate this account.
So I looked for a weekend assignment.
Weekend undertaking: Generate business names
Barash and I established a weekend effort to stay current. Building things helped us learn faster.
Simple. Startup Name Generator The utility generated random startup names. After market research for SEO purposes, we dubbed it Business Name Generator.
Backend developer Barash dislikes frontend work. He told me to write frontend code. Chakra UI and Tailwind CSS were recommended.
It was the first time I have heard about Tailwind CSS.
Before this project, I made mobile-web app designs in Sketch and shared them via Zeplin. I can read HTML-CSS or React code, but not write it. I didn't believe myself but followed Barash's advice.
My home page wasn't responsive when I started. Here it was:)
And then... Product Hunt had something I needed. Me-only! A website builder that gives you clean Tailwind CSS code and pre-made web components (like Elementor). Incredible.
I bought it right away because it was so easy to use. Best part: It's not just index.html. It includes all needed files. Like
postcss.config.js
README.md
package.json
among other things, tailwind.config.js
This is for non-techies.
Tailwind.build; which is Shuffle now, allows you to create and export projects for free (with limited features). You can try it by visiting their website.
After downloading the project, you can edit the text and graphics in Visual Studio (or another text editor). This HTML file can be hosted whenever.
Github is an easy way to host a landing page.
your project via Shuffle for export
your website's content, edit
Create a Gitlab, Github, or Bitbucket account.
to Github, upload your project folder.
Integrate Vercel with your Github account (or another platform below)
Allow them to guide you in steps.
Finally. If you push your code to Github using Github Desktop, you'll do it quickly and easily.
Speaking of; here are some hosting and serverless backend services for web applications and static websites for you host your landing pages for FREE!
I host landingpage.fyi on Vercel but all is fine. You can choose any platform below with peace in mind.
Vercel
Render
Netlify
After connecting your project/repo to Vercel, you don’t have to do anything on Vercel. Vercel updates your live website when you update Github Desktop. Wow!
Tails came out while I was using tailwind.build. Although it's prettier, tailwind.build is more mobile-friendly. I couldn't resist their lovely parts. Tails :)
Tails have several well-designed parts. Some components looked awful on mobile, but this bug helped me understand Tailwind CSS.
Unlike Shuffle, Tails does not include files when you export such as config.js, main.js, README.md. It just gives you the HTML code. Suffle.dev is a bit ahead in this regard and with mobile-friendly blocks if you ask me. Of course, I took advantage of both.
creativebusinessnames.co is inactive, but I'll leave a deployment link :)
Adam Wathan's YouTube videos and Tailwind's official literature helped me, but I couldn't have done it without Tails and Shuffle. These tools helped me make landing pages. I shouldn't have started over.
So began my Tailwind CSS adventure. I didn't build landingpage. I didn't plan it to be this long; sorry.
I learnt a lot while I was playing around with Shuffle and Tails Builders.
Long story short I built landingpage.fyi with the help of these tools;
Learning, building, and distribution
Shuffle (Started with a Shuffle Template)
Tails (Used components from here)
Sketch (to handle icons, logos, and .svg’s)
metatags.io (Auto Generator Meta Tags)
Vercel (Hosting)
Github Desktop (Pushing code to Github -super easy-)
Visual Studio Code (Edit my code)
Mailerlite (Capture Emails)
Jarvis / Conversion.ai (%90 of the text on website written by AI 😇 )
CookieHub (Consent Management)
That's all. A few things:
The Outcome
.fyi Domain: Why?

I'm often asked this.
I don't know, but I wanted to include the landing page term. Popular TLDs are gone. I saw my alternatives. brief and catchy.
CSS Tailwind Resources
I'll share project resources like Tails and Shuffle.
Beginner Tailwind (I lately enrolled in this course but haven’t completed it yet.)
Thanks for reading my blog's first post. Please share if you like it.
You might also like

Karthik Rajan
4 years ago
11 Cooking Hacks I Wish I Knew Earlier
Quick, easy and tasty (and dollops of parenting around food).

My wife and mom are both great mothers. They're super-efficient planners. They soak and ferment food. My 104-year-old grandfather loved fermented foods.
When I'm hungry and need something fast, I waffle to the pantry. Like most people, I like to improvise. I wish I knew these 11 hacks sooner.
1. The world's best pasta sauce only has 3 ingredients.
You watch recipe videos with prepped ingredients. In reality, prepping and washing take time. The food's taste isn't guaranteed. The raw truth at a sublime level is not talked about often.
Sometimes a radical recipe comes along that's so easy and tasty, you're dumbfounded. The Classic Italian Cook Book has a pasta recipe.
One 28-ounce can of whole, peeled tomatoes, one medium peeled onion, and 5 tablespoons of butter. And salt to taste.
Combine everything in a single pot and simmer for 45 minutes, uncovered. Stir occasionally. Toss the onion halves after 45 minutes and pour the sauce over pasta. Finish!
This simple recipe fights our deepest fears.
Salt to taste! Customized to perfection, no frills.
2. Reheating rice with ice. Magical.
Most of the world eats rice. I was raised in south India. My grandfather farmed rice in the Cauvery river delta.
The problem with rice With growing kids, you can't cook just enough. Leftovers are a norm. Microwaves help most people. Ice cubes are the frosting.
Before reheating rice in the microwave, add an ice cube. The ice will steam the rice, making it fluffy and delicious again.
3. Pineapple leaf
if it comes off easy, it is ripe enough to cut. No rethinking.
My daughter loves pineapples like her dad. One daddy task is cutting them. Sharing immediate results is therapeutic.
Timing the cut has been the most annoying part over the years. The pineapple leaf tip reveals the fruitiness inside. Always loved it.
4. Magic knife words (rolling and curling)
Cutting hand: Roll the blade's back, not its tip, to cut.
Other hand: If you can’t see your finger tips, you can’t cut them. So curl your fingers.
I dislike that schools don't teach financial literacy or cutting skills.
My wife and I used scissors differently for 25 years. We both used the thumb. My index finger, her middle. We googled the difference when I noticed it and laughed. She's right.
This video teaches knifing skills:
5. Best advice about heat
If it's done in the pan, it's overdone on the plate.
This simple advice stands out when we worry about ingredients and proportions.
6. The truth about pasta water
Pasta water should be sea-salty.
Properly seasoning food separates good from great. Salt depends is a good line.
Want delicious pasta? Well, then kind of a lot, to be perfectly honest.
7. Clean as you go
Clean blender as you go by blending water and dish soap.
I find clean as you go easier than clean afterwords. This easy tip is gold.
8. Clean as you go (bis)
Microwave a bowl of water, vinegar, and a toothpick for 5 minutes.
2 cups water, 2 tablespoons vinegar, and a toothpick to prevent overflow.
5-minute microwave. Let the steam work for another 2 minutes. Sponge-off dirt and food. Simple.
9 and 10. Tools,tools, tools
Immersion blender and pressure cooker save time and money.
Narrative: I experienced fatherly pride. My middle-schooler loves science. We discussed boiling. I spoke. Water doesn't need 100°C to boil. She looked confused. 100 degrees assume something. The world around the water is a normal room. Changing water pressure affects its boiling point. This saves energy. Pressure cooker magic.
I captivated her. She's into science and sustainable living.
Whistling is a subliminal form of self-expression when done right. Pressure cookers remind me of simple pleasures.
Your handiness depends on your home tools. Immersion blenders are great for pre- and post-cooking. It eliminates chopping and washing. Second to the dishwasher, in my opinion.
11. One pepper is plenty
A story I share with my daughters.
Once, everyone thought about spice (not spicy). More valuable than silk. One of the three mighty oceans was named after a source country. Columbus sailed the wrong way and found America. The explorer called the natives after reaching his spice destination.
It was pre-internet days. His Google wasn't working.
My younger daughter listens in awe. Strong roots. Image cast. She can contextualize one of the ocean names.
I struggle with spices in daily life. Combinations are mind-boggling. I have more spices than Columbus. Flavor explosion has repercussions. You must closely follow the recipe without guarantees. Best aha. Double down on one spice and move on. If you like it, it's great.
I naturally gravitate towards cumin soups, fennel dishes, mint rice, oregano pasta, basil thai curry and cardamom pudding.
Variety enhances life. Each of my dishes is unique.
To each their own comfort food and nostalgic memories.
Happy living!
Colin Faife
3 years ago
The brand-new USB Rubber Ducky is much riskier than before.
The brand-new USB Rubber Ducky is much riskier than before.

With its own programming language, the well-liked hacking tool may now pwn you.
With a vengeance, the USB Rubber Ducky is back.
This year's Def Con hacking conference saw the release of a new version of the well-liked hacking tool, and its author, Darren Kitchen, was on hand to explain it. We put a few of the new features to the test and discovered that the most recent version is riskier than ever.
WHAT IS IT?
The USB Rubber Ducky seems to the untrained eye to be an ordinary USB flash drive. However, when you connect it to a computer, the computer recognizes it as a USB keyboard and will accept keystroke commands from the device exactly like a person would type them in.
Kitchen explained to me, "It takes use of the trust model built in, where computers have been taught to trust a human, in that anything it types is trusted to the same degree as the user is trusted. And a computer is aware that clicks and keystrokes are how people generally connect with it.

Over ten years ago, the first Rubber Ducky was published, quickly becoming a hacker favorite (it was even featured in a Mr. Robot scene). Since then, there have been a number of small upgrades, but the most recent Rubber Ducky takes a giant step ahead with a number of new features that significantly increase its flexibility and capability.
WHERE IS ITS USE?
The options are nearly unlimited with the proper strategy.
The Rubber Ducky has already been used to launch attacks including making a phony Windows pop-up window to collect a user's login information or tricking Chrome into sending all saved passwords to an attacker's web server. However, these attacks lacked the adaptability to operate across platforms and had to be specifically designed for particular operating systems and software versions.

The nuances of DuckyScript 3.0 are described in a new manual.
The most recent Rubber Ducky seeks to get around these restrictions. The DuckyScript programming language, which is used to construct the commands that the Rubber Ducky will enter into a target machine, receives a significant improvement with it. DuckyScript 3.0 is a feature-rich language that allows users to write functions, store variables, and apply logic flow controls, in contrast to earlier versions that were primarily limited to scripting keystroke sequences (i.e., if this... then that).
This implies that, for instance, the new Ducky can check to see if it is hooked into a Windows or Mac computer and then conditionally run code specific to each one, or it can disable itself if it has been attached to the incorrect target. In order to provide a more human effect, it can also generate pseudorandom numbers and utilize them to add a configurable delay between keystrokes.
The ability to steal data from a target computer by encoding it in binary code and transferring it through the signals intended to instruct a keyboard when the CapsLock or NumLock LEDs should light up is perhaps its most astounding feature. By using this technique, a hacker may plug it in for a brief period of time, excuse themselves by saying, "Sorry, I think that USB drive is faulty," and then take it away with all the credentials stored on it.
HOW SERIOUS IS THE RISK?
In other words, it may be a significant one, but because physical device access is required, the majority of people aren't at risk of being a target.
The 500 or so new Rubber Duckies that Hak5 brought to Def Con, according to Kitchen, were his company's most popular item at the convention, and they were all gone on the first day. It's safe to suppose that hundreds of hackers already possess one, and demand is likely to persist for some time.
Additionally, it has an online development toolkit that can be used to create attack payloads, compile them, and then load them onto the target device. A "payload hub" part of the website makes it simple for hackers to share what they've generated, and the Hak5 Discord is also busy with conversation and helpful advice. This makes it simple for users of the product to connect with a larger community.
It's too expensive for most individuals to distribute in volume, so unless your favorite cafe is renowned for being a hangout among vulnerable targets, it's doubtful that someone will leave a few of them there. To that end, if you intend to plug in a USB device that you discovered outside in a public area, pause to consider your decision.
WOULD IT WORK FOR ME?
Although the device is quite straightforward to use, there are a few things that could cause you trouble if you have no prior expertise writing or debugging code. For a while, during testing on a Mac, I was unable to get the Ducky to press the F4 key to activate the launchpad, but after forcing it to identify itself using an alternative Apple keyboard device ID, the problem was resolved.
From there, I was able to create a script that, when the Ducky was plugged in, would instantly run Chrome, open a new browser tab, and then immediately close it once more without requiring any action from the laptop user. Not bad for only a few hours of testing, and something that could be readily changed to perform duties other than reading technology news.

Christian Soschner
3 years ago
Steve Jobs' Secrets Revealed
From 1984 until 2011, he ran Apple using the same template.

What is a founder CEO's most crucial skill?
Presentation, communication, and sales
As a Business Angel Investor, I saw many pitch presentations and met with investors one-on-one to promote my companies.
There is always the conception of “Investors have to invest,” so there is no need to care about the presentation.
It's false. Nobody must invest. Many investors believe that entrepreneurs must convince them to invest in their business.
Sometimes — like in 2018–2022 — too much money enters the market, and everyone makes good money.
Do you recall the Buy Now, Pay Later Movement? This amazing narrative had no return potential. Only buyers who couldn't acquire financing elsewhere shopped at these companies.
Klarna's failing business concept led to high valuations.
Investors become more cautious when the economy falters. 2022 sees rising inflation, interest rates, wars, and civil instability. It's like the apocalypse's four horsemen have arrived.
Storytelling is important in rough economies.
When investors draw back, how can entrepreneurs stand out?
In Q2/2022, every study I've read said:
Investors cease investing
Deals are down in almost all IT industries from previous quarters.
What do founders need to do?
Differentiate yourself.
Storytelling talents help.
The Steve Jobs Way
Every time I watch a Steve Jobs presentation, I'm enthralled.
I'm a techie. Everything technical interests me. But, I skim most presentations.
What's Steve Jobs's secret?
Steve Jobs created Apple in 1976 and made it a profitable software and hardware firm in the 1980s. Macintosh goods couldn't beat IBM's. This mistake sacked him in 1985.
Before rejoining Apple in 1997, Steve Jobs founded Next Inc. and Pixar.
From then on, Apple became America's most valuable firm.
Steve Jobs understood people's needs. He said:
“People don’t know what they want until you show it to them. That’s why I never rely on market research. Our task is to read things that are not yet on the page.”
In his opinion, people talk about problems. A lot. Entrepreneurs must learn what the population's pressing problems are and create a solution.
Steve Jobs showed people what they needed before they realized it.
I'll explain:
Present a Big Vision
Steve Jobs starts every presentation by describing his long-term goals for Apple.
1984's Macintosh presentation set up David vs. Goliath. In a George Orwell-style dystopia, IBM computers were bad. It was 1984.
Apple will save the world, like Jedis.
Why do customers and investors like Big Vision?
People want a wider perspective, I think. Humans love improving the planet.
Apple users often cite emotional reasons for buying the brand.
Revolutionizing several industries with breakthrough inventions
Establish Authority
Everyone knows Apple in 2022. It's hard to find folks who confuse Apple with an apple around the world.
Apple wasn't as famous as it is today until Steve Jobs left in 2011.
Most entrepreneurs lack experience. They may market their company or items to folks who haven't heard of it.
Steve Jobs presented the company's historical accomplishments to overcome opposition.
In his presentation of the first iPhone, he talked about the Apple Macintosh, which altered the computing sector, and the iPod, which changed the music industry.
People who have never heard of Apple feel like they're seeing a winner. It raises expectations that the new product will be game-changing and must-have.
The Big Reveal
A pitch or product presentation always has something new.
Steve Jobs doesn't only demonstrate the product. I don't think he'd skip the major point of a company presentation.
He consistently discusses present market solutions, their faults, and a better consumer solution.
No solution exists yet.
It's a multi-faceted play:
It's comparing the new product to something familiar. This makes novelty and the product more relatable.
Describe a desirable solution.
He's funny. He demonstrated an iPod with an 80s phone dial in his iPhone presentation.
Then he reveals the new product. Macintosh presented itself.
Show the benefits
He outlines what Apple is doing differently after demonstrating the product.
How do you distinguish from others? The Big Breakthrough Presentation.
A few hundred slides might list all benefits.
Everyone would fall asleep. Have you ever had similar presentations?
When the brain is overloaded with knowledge, the limbic system changes to other duties, like lunch planning.
What should a speaker do? There's a classic proverb:
“Tell me and I forget, teach me and I may remember, involve me and I learn” (— Not Benjamin Franklin).
Steve Jobs showcased the product live.
Again, using ordinary scenarios to highlight the product's benefits makes it relatable.
The 2010 iPad Presentation uses this technique.
Invite the Team and Let Them Run the Presentation
CEOs spend most time outside the organization. Many companies elect to have only one presenter.
It sends the incorrect message to investors. Product presentations should always include the whole team.
Let me explain why.
Companies needing investment money frequently have shaky business strategies or no product-market fit or robust corporate structure.
Investors solely bet on a team's ability to implement ideas and make a profit.
Early team involvement helps investors understand the company's drivers. Travel costs are worthwhile.
But why for product presentations?
Presenters of varied ages, genders, social backgrounds, and skillsets are relatable. CEOs want relatable products.
Some customers may not believe a white man's message. A black woman's message may be more accepted.
Make the story relatable when you have the best product that solves people's concerns.
Best example: 1984 Macintosh presentation with development team panel.
What is the largest error people make when companies fail?
Saving money on the corporate and product presentation.
Invite your team to five partner meetings when five investors are shortlisted.
Rehearse the presentation till it's natural. Let the team speak.
Successful presentations require structure, rehearsal, and a team. Steve Jobs nailed it.