




More on Web3 & Crypto

Ajay Shrestha
3 years ago
Bitcoin's technical innovation: addressing the issue of the Byzantine generals
The 2008 Bitcoin white paper solves the classic computer science consensus problem.
Issue Statement
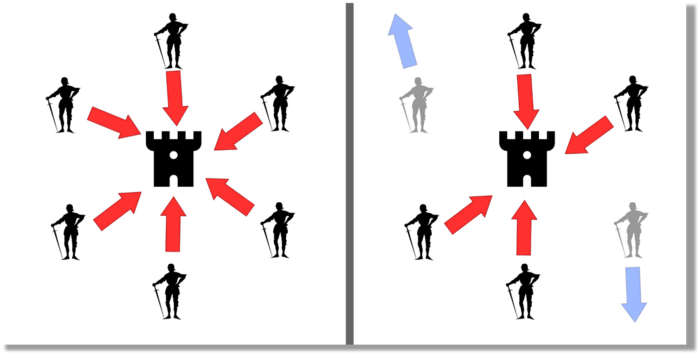
The Byzantine Generals Problem (BGP) is called after an allegory in which several generals must collaborate and attack a city at the same time to win (figure 1-left). Any general who retreats at the last minute loses the fight (figure 1-right). Thus, precise messengers and no rogue generals are essential. This is difficult without a trusted central authority.
In their 1982 publication, Leslie Lamport, Robert Shostak, and Marshall Please termed this topic the Byzantine Generals Problem to simplify distributed computer systems.
Consensus in a distributed computer network is the issue. Reaching a consensus on which systems work (and stay in the network) and which don't makes maintaining a network tough (i.e., needs to be removed from network). Challenges include unreliable communication routes between systems and mis-reporting systems.
Solving BGP can let us construct machine learning solutions without single points of failure or trusted central entities. One server hosts model parameters while numerous workers train the model. This study describes fault-tolerant Distributed Byzantine Machine Learning.
Bitcoin invented a mechanism for a distributed network of nodes to agree on which transactions should go into the distributed ledger (blockchain) without a trusted central body. It solved BGP implementation. Satoshi Nakamoto, the pseudonymous bitcoin creator, solved the challenge by cleverly combining cryptography and consensus mechanisms.
Disclaimer
This is not financial advice. It discusses a unique computer science solution.
Bitcoin
Bitcoin's white paper begins:
“A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution.” Source: https://www.ussc.gov/sites/default/files/pdf/training/annual-national-training-seminar/2018/Emerging_Tech_Bitcoin_Crypto.pdf
Bitcoin's main parts:
The open-source and versioned bitcoin software that governs how nodes, miners, and the bitcoin token operate.
The native kind of token, known as a bitcoin token, may be created by mining (up to 21 million can be created), and it can be transferred between wallet addresses in the bitcoin network.
Distributed Ledger, which contains exact copies of the database (or "blockchain") containing each transaction since the first one in January 2009.
distributed network of nodes (computers) running the distributed ledger replica together with the bitcoin software. They broadcast the transactions to other peer nodes after validating and accepting them.
Proof of work (PoW) is a cryptographic requirement that must be met in order for a miner to be granted permission to add a new block of transactions to the blockchain of the cryptocurrency bitcoin. It takes the form of a valid hash digest. In order to produce new blocks on average every 10 minutes, Bitcoin features a built-in difficulty adjustment function that modifies the valid hash requirement (length of nonce). PoW requires a lot of energy since it must continually generate new hashes at random until it satisfies the criteria.
The competing parties known as miners carry out continuous computing processing to address recurrent cryptography issues. Transaction fees and some freshly minted (mined) bitcoin are the rewards they receive. The amount of hashes produced each second—or hash rate—is a measure of mining capacity.
Cryptography, decentralization, and the proof-of-work consensus method are Bitcoin's most unique features.
Bitcoin uses encryption
Bitcoin employs this established cryptography.
Hashing
digital signatures based on asymmetric encryption
Hashing (SHA-256) (SHA-256)
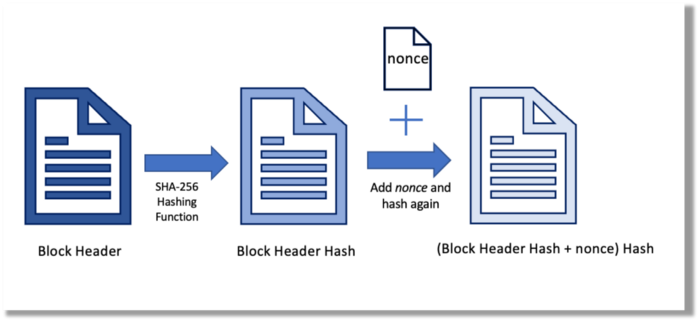
Hashing converts unique plaintext data into a digest. Creating the plaintext from the digest is impossible. Bitcoin miners generate new hashes using SHA-256 to win block rewards.
A new hash is created from the current block header and a variable value called nonce. To achieve the required hash, mining involves altering the nonce and re-hashing.
The block header contains the previous block hash and a Merkle root, which contains hashes of all transactions in the block. Thus, a chain of blocks with increasing hashes links back to the first block. Hashing protects new transactions and makes the bitcoin blockchain immutable. After a transaction block is mined, it becomes hard to fabricate even a little entry.
Asymmetric Cryptography Digital Signatures
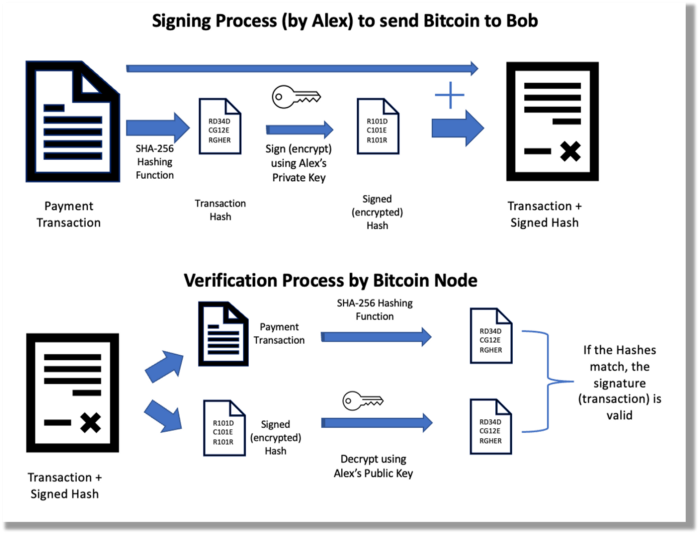
Asymmetric cryptography (public-key encryption) requires each side to have a secret and public key. Public keys (wallet addresses) can be shared with the transaction party, but private keys should not. A message (e.g., bitcoin payment record) can only be signed by the owner (sender) with the private key, but any node or anybody with access to the public key (visible in the blockchain) can verify it. Alex will submit a digitally signed transaction with a desired amount of bitcoin addressed to Bob's wallet to a node to send bitcoin to Bob. Alex alone has the secret keys to authorize that amount. Alex's blockchain public key allows anyone to verify the transaction.
Solution
Now, apply bitcoin to BGP. BGP generals resemble bitcoin nodes. The generals' consensus is like bitcoin nodes' blockchain block selection. Bitcoin software on all nodes can:
Check transactions (i.e., validate digital signatures)
2. Accept and propagate just the first miner to receive the valid hash and verify it accomplished the task. The only way to guess the proper hash is to brute force it by repeatedly producing one with the fixed/current block header and a fresh nonce value.
Thus, PoW and a dispersed network of nodes that accept blocks from miners that solve the unfalsifiable cryptographic challenge solve consensus.
Suppose:
Unreliable nodes
Unreliable miners
Bitcoin accepts the longest chain if rogue nodes cause divergence in accepted blocks. Thus, rogue nodes must outnumber honest nodes in accepting/forming the longer chain for invalid transactions to reach the blockchain. As of November 2022, 7000 coordinated rogue nodes are needed to takeover the bitcoin network.
Dishonest miners could also try to insert blocks with falsified transactions (double spend, reverse, censor, etc.) into the chain. This requires over 50% (51% attack) of miners (total computational power) to outguess the hash and attack the network. Mining hash rate exceeds 200 million (source). Rewards and transaction fees encourage miners to cooperate rather than attack. Quantum computers may become a threat.
Visit my Quantum Computing post.
Quantum computers—what are they? Quantum computers will have a big influence. towardsdatascience.com
Nodes have more power than miners since they can validate transactions and reject fake blocks. Thus, the network is secure if honest nodes are the majority.
Summary
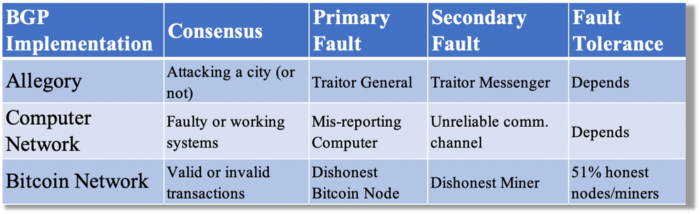
Table 1 compares three Byzantine Generals Problem implementations.
Bitcoin white paper and implementation solved the consensus challenge of distributed systems without central governance. It solved the illusive Byzantine Generals Problem.
Resources
Resources
Source-code for Bitcoin Core Software — https://github.com/bitcoin/bitcoin
Bitcoin white paper — https://bitcoin.org/bitcoin.pdf
https://www.microsoft.com/en-us/research/publication/byzantine-generals-problem/
https://www.microsoft.com/en-us/research/uploads/prod/2016/12/The-Byzantine-Generals-Problem.pdf
Genuinely Distributed Byzantine Machine Learning, El-Mahdi El-Mhamdi et al., 2020. ACM, New York, NY, https://doi.org/10.1145/3382734.3405695

Elnaz Sarraf
4 years ago
Why Bitcoin's Crash Could Be Good for Investors

The crypto market crashed in June 2022. Bitcoin and other cryptocurrencies hit their lowest prices in over a year, causing market panic. Some believe this crash will benefit future investors.
Before I discuss how this crash might help investors, let's examine why it happened. Inflation in the U.S. reached a 30-year high in 2022 after Russia invaded Ukraine. In response, the U.S. Federal Reserve raised interest rates by 0.5%, the most in almost 20 years. This hurts cryptocurrencies like Bitcoin. Higher interest rates make people less likely to invest in volatile assets like crypto, so many investors sold quickly.
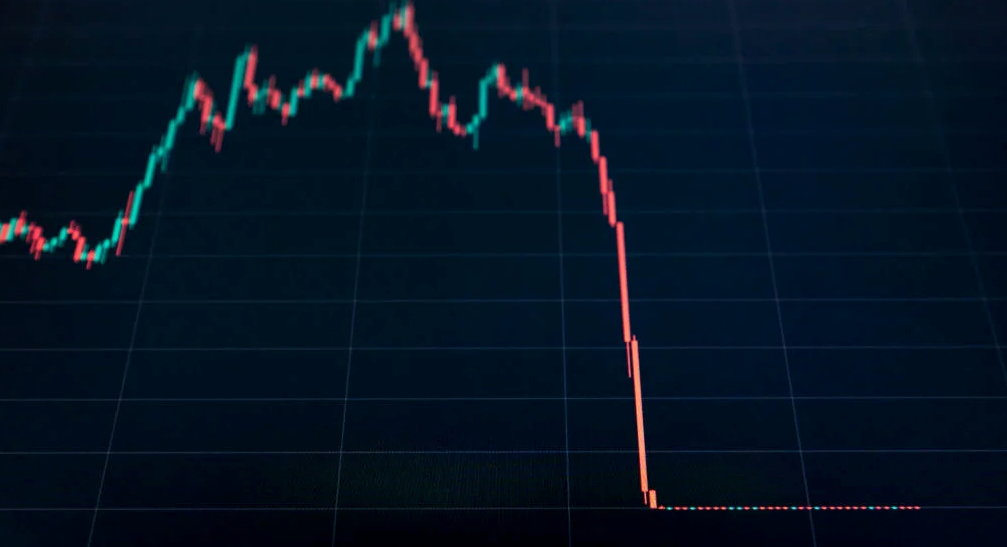
The crypto market collapsed. Bitcoin, Ethereum, and Binance dropped 40%. Other cryptos crashed so hard they were delisted from almost every exchange. Bitcoin peaked in April 2022 at $41,000, but after the May interest rate hike, it crashed to $28,000. Bitcoin investors were worried. Even in bad times, this crash is unprecedented.
Bitcoin wasn't "doomed." Before the crash, LUNA was one of the top 5 cryptos by market cap. LUNA was trading around $80 at the start of May 2022, but after the rate hike?
Less than 1 cent. LUNA lost 99.99% of its value in days and was removed from every crypto exchange. Bitcoin's "crash" isn't as devastating when compared to LUNA.
Many people said Bitcoin is "due" for a LUNA-like crash and that the only reason it hasn't crashed is because it's bigger. Still false. If so, Bitcoin should be worth zero by now. We didn't. Instead, Bitcoin reached 28,000, then 29k, 30k, and 31k before falling to 18k. That's not the world's greatest recovery, but it shows Bitcoin's safety.
Bitcoin isn't falling constantly. It fell because of the initial shock of interest rates, but not further. Now, Bitcoin's value is more likely to rise than fall. Bitcoin's low price also attracts investors. They know what prices Bitcoin can reach with enough hype, and they want to capitalize on low prices before it's too late.

Bitcoin's crash was bad, but in a way it wasn't. To understand, consider 2021. In March 2021, Bitcoin surpassed $60k for the first time. Elon Musk's announcement in May that he would no longer support Bitcoin caused a massive crash in the crypto market. In May 2017, Bitcoin's price hit $29,000. Elon Musk's statement isn't worth more than the Fed raising rates. Many expected this big announcement to kill Bitcoin.

Not so. Bitcoin crashed from $58k to $31k in 2021. Bitcoin fell from $41k to $28k in 2022. This crash is smaller. Bitcoin's price held up despite tensions and stress, proving investors still believe in it. What happened after the initial crash in the past?
Bitcoin fell until mid-July. This is also something we’re not seeing today. After a week, Bitcoin began to improve daily. Bitcoin's price rose after mid-July. Bitcoin's price fluctuated throughout the rest of 2021, but it topped $67k in November. Despite no major changes, the peak occurred after the crash. Elon Musk seemed uninterested in crypto and wasn't likely to change his mind soon. What triggered this peak? Nothing, really. What really happened is that people got over the initial statement. They forgot.
Internet users have goldfish-like attention spans. People quickly forgot the crash's cause and were back investing in crypto months later. Despite the market's setbacks, more crypto investors emerged by the end of 2017. Who gained from these peaks? Bitcoin investors who bought low. Bitcoin not only recovered but also doubled its ROI. It was like a movie, and it shows us what to expect from Bitcoin in the coming months.
The current Bitcoin crash isn't as bad as the last one. LUNA is causing market panic. LUNA and Bitcoin are different cryptocurrencies. LUNA crashed because Terra wasn’t able to keep its peg with the USD. Bitcoin is unanchored. It's one of the most decentralized investments available. LUNA's distrust affected crypto prices, including Bitcoin, but it won't last forever.
This is why Bitcoin will likely rebound in the coming months. In 2022, people will get over the rise in interest rates and the crash of LUNA, just as they did with Elon Musk's crypto stance in 2021. When the world moves on to the next big controversy, Bitcoin's price will soar.
Bitcoin may recover for another reason. Like controversy, interest rates fluctuate. The Russian invasion caused this inflation. World markets will stabilize, prices will fall, and interest rates will drop.
Next, lower interest rates could boost Bitcoin's price. Eventually, it will happen. The U.S. economy can't sustain such high interest rates. Investors will put every last dollar into Bitcoin if interest rates fall again.
Bitcoin has proven to be a stable investment. This boosts its investment reputation. Even if Ethereum dethrones Bitcoin as crypto king one day (or any other crypto, for that matter). Bitcoin may stay on top of the crypto ladder for a while. We'll have to wait a few months to see if any of this is true.
This post is a summary. Read the full article here.

Trent Lapinski
4 years ago
What The Hell Is A Crypto Punk?
We are Crypto Punks, and we are changing your world.
A “Crypto Punk” is a new generation of entrepreneurs who value individual liberty and collective value creation and co-creation through decentralization. While many Crypto Punks were born and raised in a digital world, some of the early pioneers in the crypto space are from the Oregon Trail generation. They were born to an analog world, but grew up simultaneously alongside the birth of home computing, the Internet, and mobile computing.
A Crypto Punk’s world view is not the same as previous generations. By the time most Crypto Punks were born everything from fiat currency, the stock market, pharmaceuticals, the Internet, to advanced operating systems and microprocessing were already present or emerging. Crypto Punks were born into pre-existing conditions and systems of control, not governed by logic or reason but by greed, corporatism, subversion, bureaucracy, censorship, and inefficiency.
All Systems Are Human Made
Crypto Punks understand that all systems were created by people and that previous generations did not have access to information technologies that we have today. This is why Crypto Punks have different values than their parents, and value liberty, decentralization, equality, social justice, and freedom over wealth, money, and power. They understand that the only path forward is to work together to build new and better systems that make the old world order obsolete.
Unlike the original cypher punks and cyber punks, Crypto Punks are a new iteration or evolution of these previous cultures influenced by cryptography, blockchain technology, crypto economics, libertarianism, holographics, democratic socialism, and artificial intelligence. They are tasked with not only undoing the mistakes of previous generations, but also innovating and creating new ways of solving complex problems with advanced technology and solutions.
Where Crypto Punks truly differ is in their understanding that computer systems can exist for more than just engagement and entertainment, but actually improve the human condition by automating bureaucracy and inefficiency by creating more efficient economic incentives and systems.
Crypto Punks Value Transparency and Do Not Trust Flawed, Unequal, and Corrupt Systems
Crypto Punks have a strong distrust for inherently flawed and corrupt systems. This why Crypto Punks value transparency, free speech, privacy, and decentralization. As well as arguably computer systems over human powered systems.
Crypto Punks are the children of the Great Recession, and will never forget the economic corruption that still enslaves younger generations.
Crypto Punks were born to think different, and raised by computers to view reality through an LED looking glass. They will not surrender to the flawed systems of economic wage slavery, inequality, censorship, and subjection. They will literally engineer their own unstoppable financial systems and trade in cryptography over fiat currency merely to prove that belief systems are more powerful than corruption.
Crypto Punks are here to help achieve freedom from world governments, corporations and bankers who monetizine our data to control our lives.
Crypto Punks Decentralize
Despite all the evils of the world today, Crypto Punks know they have the power to create change. This is why Crypto Punks are optimistic about the future despite all the indicators that humanity is destined for failure.
Crypto Punks believe in systems that prioritize people and the planet above profit. Even so, Crypto Punks still believe in capitalistic systems, but only capitalistic systems that incentivize good behaviors that do not violate the common good for the sake of profit.
Cyber Punks Are Co-Creators
We are Crypto Punks, and we will build a better world for all of us. For the true price of creation is not in US dollars, but through working together as equals to replace the unequal and corrupt greedy systems of previous generations.
Where they have failed, Crypto Punks will succeed. Not because we want to, but because we have to. The world we were born into is so corrupt and its systems so flawed and unequal we were never given a choice.
We have to be the change we seek.
We are Crypto Punks.
Either help us, or get out of our way.
Are you a Crypto Punk?
You might also like

William Anderson
4 years ago
When My Remote Leadership Skills Took Off
4 Ways To Manage Remote Teams & Employees
The wheels hit the ground as I landed in Rochester.
Our six-person satellite office was now part of my team.
Their manager only reported to me the day before, but I had my ticket booked ahead of time.
I had managed remote employees before but this was different. Engineers dialed into headquarters for every meeting.
So when I learned about the org chart change, I knew a strong first impression would set the tone for everything else.
I was either their boss, or their boss's boss, and I needed them to know I was committed.
Managing a fleet of satellite freelancers or multiple offices requires treating others as more than just a face behind a screen.
You must comprehend each remote team member's perspective and daily interactions.
The good news is that you can start using these techniques right now to better understand and elevate virtual team members.
1. Make Visits To Other Offices
If budgeted, visit and work from offices where teams and employees report to you. Only by living alongside them can one truly comprehend their problems with communication and other aspects of modern life.
2. Have Others Come to You
• Having remote, distributed, or satellite employees and teams visit headquarters every quarter or semi-quarterly allows the main office culture to rub off on them.
When remote team members visit, more people get to meet them, which builds empathy.
If you can't afford to fly everyone, at least bring remote managers or leaders. Hopefully they can resurrect some culture.
3. Weekly Work From Home
No home office policy?
Make one.
WFH is a team-building, problem-solving, and office-viewing opportunity.
For dial-in meetings, I started working from home on occasion.
It also taught me which teams “forget” or “skip” calls.
As a remote team member, you experience all the issues first hand.
This isn't as accurate for understanding teams in other offices, but it can be done at any time.
4. Increase Contact Even If It’s Just To Chat
Don't underestimate office banter.
Sometimes it's about bonding and trust, other times it's about business.
If you get all this information in real-time, please forward it.
Even if nothing critical is happening, call remote team members to check in and chat.
I guarantee that building relationships and rapport will increase both their job satisfaction and yours.

Caspar Mahoney
3 years ago
Changing Your Mindset From a Project to a Product
Product game mindsets? How do these vary from Project mindset?
1950s spawned the Iron Triangle. Project people everywhere know and live by it. In stakeholder meetings, it is used to stretch the timeframe, request additional money, or reduce scope.
Quality was added to this triangle as things matured.
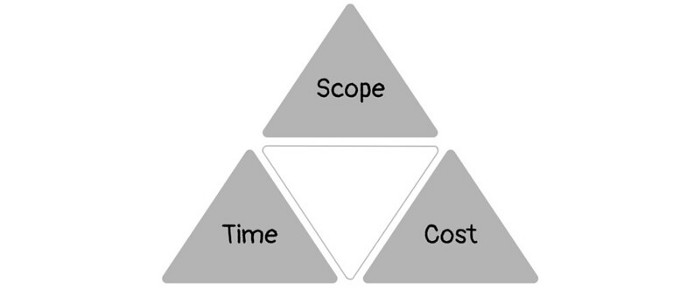
Quality was intended to be transformative, but none of these principles addressed why we conduct projects.
Value and benefits are key.
Product value is quantified by ROI, revenue, profit, savings, or other metrics. For me, every project or product delivery is about value.
Most project managers, especially those schooled 5-10 years or more ago (thousands working in huge corporations worldwide), understand the world in terms of the iron triangle. What does that imply? They worry about:
a) enough time to get the thing done.
b) have enough resources (budget) to get the thing done.
c) have enough scope to fit within (a) and (b) >> note, they never have too little scope, not that I have ever seen! although, theoretically, this could happen.
Boom—iron triangle.
To make the triangle function, project managers will utilize formal governance (Steering) to move those things. Increase money, scope, or both if time is short. Lacking funds? Increase time, scope, or both.
In current product development, shifting each item considerably may not yield value/benefit.
Even terrible. This approach will fail because it deprioritizes Value/Benefit by focusing the major stakeholders (Steering participants) and delivery team(s) on Time, Scope, and Budget restrictions.
Pre-agile, this problem was terrible. IT projects failed wildly. History is here.
Value, or benefit, is central to the product method. Product managers spend most of their time planning value-delivery paths.
Product people consider risk, schedules, scope, and budget, but value comes first. Let me illustrate.
Imagine managing internal products in an enterprise. Your core customer team needs a rapid text record of a chat to fix a problem. The consumer wants a feature/features added to a product you're producing because they think it's the greatest spot.
Project-minded, I may say;
Ok, I have budget as this is an existing project, due to run for a year. This is a new requirement to add to the features we’re already building. I think I can keep the deadline, and include this scope, as it sounds related to the feature set we’re building to give the desired result”.
This attitude repeats Scope, Time, and Budget.
Since it meets those standards, a project manager will likely approve it. If they have a backlog, they may add it and start specking it out assuming it will be built.
Instead, think like a product;
What problem does this feature idea solve? Is that problem relevant to the product I am building? Can that problem be solved quicker/better via another route ? Is it the most valuable problem to solve now? Is the problem space aligned to our current or future strategy? or do I need to alter/update the strategy?
A product mindset allows you to focus on timing, resource/cost, feasibility, feature detail, and so on after answering the aforementioned questions.
The above oversimplifies because
Leadership in discovery

Project managers are facilitators of ideas. This is as far as they normally go in the ‘idea’ space.
Business Requirements collection in classic project delivery requires extensive upfront documentation.
Agile project delivery analyzes requirements iteratively.
However, the project manager is a facilitator/planner first and foremost, therefore topic knowledge is not expected.
I mean business domain, not technical domain (to confuse matters, it is true that in some instances, it can be both technical and business domains that are important for a single individual to master).
Product managers are domain experts. They will become one if they are training/new.
They lead discovery.
Product Manager-led discovery is much more than requirements gathering.
Requirements gathering involves a Business Analyst interviewing people and documenting their requests.
The project manager calculates what fits and what doesn't using their Iron Triangle (presumably in their head) and reports back to Steering.
If this requirements-gathering exercise failed to identify requirements, what would a project manager do? or bewildered by project requirements and scope?
They would tell Steering they need a Business SME or Business Lead assigning or more of their time.
Product discovery requires the Product Manager's subject knowledge and a new mindset.
How should a Product Manager handle confusing requirements?
Product Managers handle these challenges with their talents and tools. They use their own knowledge to fill in ambiguity, but they have the discipline to validate those assumptions.
To define the problem, they may perform qualitative or quantitative primary research.
They might discuss with UX and Engineering on a whiteboard and test assumptions or hypotheses.
Do Product Managers escalate confusing requirements to Steering/Senior leaders? They would fix that themselves.
Product managers raise unclear strategy and outcomes to senior stakeholders. Open talks, soft skills, and data help them do this. They rarely raise requirements since they have their own means of handling them without top stakeholder participation.
Discovery is greenfield, exploratory, research-based, and needs higher-order stakeholder management, user research, and UX expertise.
Product Managers also aid discovery. They lead discovery. They will not leave customer/user engagement to a Business Analyst. Administratively, a business analyst could aid. In fact, many product organizations discourage business analysts (rely on PM, UX, and engineer involvement with end-users instead).
The Product Manager must drive user interaction, research, ideation, and problem analysis, therefore a Product professional must be skilled and confident.
Creating vs. receiving and having an entrepreneurial attitude

Product novices and project managers focus on details rather than the big picture. Project managers prefer spreadsheets to strategy whiteboards and vision statements.
These folks ask their manager or senior stakeholders, "What should we do?"
They then elaborate (in Jira, in XLS, in Confluence or whatever).
They want that plan populated fast because it reduces uncertainty about what's going on and who's supposed to do what.
Skilled Product Managers don't only ask folks Should we?
They're suggesting this, or worse, Senior stakeholders, here are some options. After asking and researching, they determine what value this product adds, what problems it solves, and what behavior it changes.
Therefore, to move into Product, you need to broaden your view and have courage in your ability to discover ideas, find insightful pieces of information, and collate them to form a valuable plan of action. You are constantly defining RoI and building Business Cases, so much so that you no longer create documents called Business Cases, it is simply ingrained in your work through metrics, intelligence, and insights.
Product Management is not a free lunch.
Plateless.
Plates and food must be prepared.
In conclusion, Product Managers must make at least three mentality shifts:
You put value first in all things. Time, money, and scope are not as important as knowing what is valuable.
You have faith in the field and have the ability to direct the search. YYou facilitate, but you don’t just facilitate. You wouldn't want to limit your domain expertise in that manner.
You develop concepts, strategies, and vision. You are not a waiter or an inbox where other people can post suggestions; you don't merely ask folks for opinion and record it. However, you excel at giving things that aren't clearly spoken or written down physical form.

Carter Kilmann
3 years ago
I finally achieved a $100K freelance income. Here's what I wish I knew.

We love round numbers, don't we? $100,000 is a frequent freelancing milestone. You feel like six figures means you're doing something properly.
You've most likely already conquered initial freelancing challenges like finding clients, setting fair pricing, coping with criticism, getting through dry spells, managing funds, etc.
You think I must be doing well. Last month, my freelance income topped $100,000.
That may not sound impressive considering I've been freelancing for 2.75 years, but I made 30% of that in the previous four months, which is crazy.
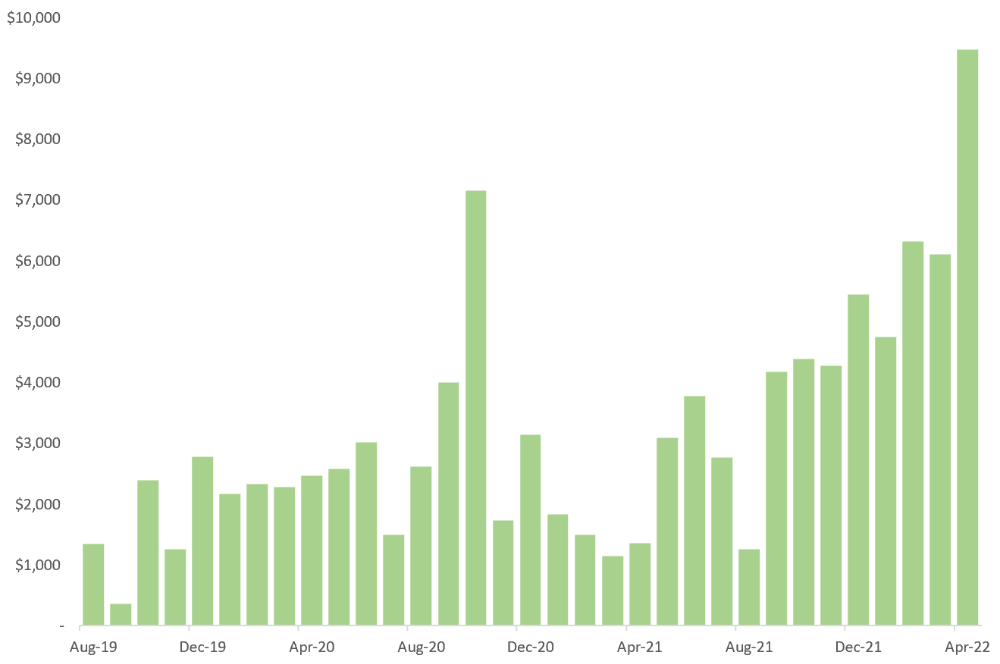
Here are the things I wish I'd known during the early days of self-employment that would have helped me hit $100,000 faster.
1. The Volatility of Freelancing Will Stabilize.
Freelancing is risky. No surprise.
Here's an example.
October 2020 was my best month, earning $7,150. Between $4,004 in September and $1,730 in November. Unsteady.
Freelancing is regrettably like that. Moving clients. Content requirements change. Allocating so much time to personal pursuits wasn't smart, but yet.
Stabilizing income takes time. Consider my rolling three-month average income since I started freelancing. My three-month average monthly income. In February, this metric topped $5,000. Now, it's in the mid-$7,000s, but it took a while to get there.
Finding freelance gigs that provide high pay, high volume, and recurring revenue is difficult. But it's not impossible.
TLDR: Don't expect a steady income increase at first. Be patient.
2. You Have More Value Than You Realize.
Writing is difficult. Assembling words, communicating a message, and provoking action are a puzzle.
People are willing to pay you for it because they can't do what you do or don't have enough time.
Keeping that in mind can have huge commercial repercussions.
When talking to clients, don't tiptoe. You can ignore ridiculous deadlines. You don't have to take unmanageable work.
You solve an issue, so make sure you get rightly paid.
TLDR: Frame services as problem-solutions. This will let you charge more and set boundaries.
3. Increase Your Prices.
I studied hard before freelancing. I read articles and watched videos about writing businesses.
I didn't want to work for pennies. Despite this clarity, I had no real strategy to raise my rates.
I then luckily stumbled into higher-paying work. We discussed fees and hours with a friend who launched a consulting business. It's subjective and speculative because value isn't standardized. One company may laugh at your charges. If your solution helps them create a solid ROI, another client may pay $200 per hour.
When he told me he charged his first client $125 per hour, I thought, Why not?
A new-ish client wanted to discuss a huge forthcoming project, so I raised my rates. They knew my worth, so they didn't blink when I handed them my new number.
TLDR: Increase rates periodically (e.g., every 6 or 12 months). Writing skill develops with practice. You'll gain value over time.
4. Remember Your Limits.
If you can squeeze additional time into a day, let me know. I can't manipulate time yet.
We all have time and economic limits. You could theoretically keep boosting rates, but your prospect pool diminishes. Outsourcing and establishing extra revenue sources might boost monthly revenues.
I've devoted a lot of time to side projects (hopefully extra cash sources), but I've only just started outsourcing. I wish I'd tried this earlier.
If you can discover good freelancers, you can grow your firm without sacrificing time.
TLDR: Expand your writing network immediately. You'll meet freelancers who understand your daily grind and locate reference sources.
5. Every Action You Take Involves an Investment. Be Certain to Select Correctly.
Investing in stocks or crypto requires paying money, right?
In business, time is your currency (and maybe money too). Your daily habits define your future. If you spend time collecting software customers and compiling content in the space, you'll end up with both. So be sure.
I only spend around 50% of my time on client work, therefore it's taken me nearly three years to earn $100,000. I spend the remainder of my time on personal projects including a freelance book, an investment newsletter, and this blog.
Why? I don't want to rely on client work forever. So, I'm working on projects that could pay off later and help me live a more fulfilling life.
TLDR: Consider the long-term impact of your time commitments, and don't overextend. You can only make so many "investments" in a given time.
6. LinkedIn Is an Endless Mine of Gold. Use It.
Why didn't I use LinkedIn earlier?
I designed a LinkedIn inbound lead strategy that generates 12 leads a month and a few high-quality offers. As a result, I've turned down good gigs. Wish I'd begun earlier.
If you want to create a freelance business, prioritize LinkedIn. Too many freelancers ignore this site, missing out on high-paying clients. Build your profile, post often, and interact.
TLDR: Study LinkedIn's top creators. Once you understand their audiences, start posting and participating daily.
For 99% of People, Freelancing is Not a Get-Rich-Quick Scheme.
Here's a list of things I wish I'd known when I started freelancing.
Although it is erratic, freelancing eventually becomes stable.
You deserve respect and discretion over how you conduct business because you have solved an issue.
Increase your charges rather than undervaluing yourself. If necessary, add a reminder to your calendar. Your worth grows with time.
In order to grow your firm, outsource jobs. After that, you can work on the things that are most important to you.
Take into account how your present time commitments may affect the future. It will assist in putting things into perspective and determining whether what you are doing is indeed worthwhile.
Participate on LinkedIn. You'll get better jobs as a result.
If I could give my old self (and other freelancers) one bit of advice, it's this:
Despite appearances, you're making progress.
Each job. Tweets. Newsletters. Progress. It's simpler to see retroactively than in the moment.
Consistent, intentional work pays off. No good comes from doing nothing. You must set goals, divide them into time-based targets, and then optimize your calendar.
Then you'll understand you're doing well.
Want to learn more? I’ll teach you.