


Fairness alternatives to selling below market clearing prices (or community sentiment, or fun)
When a seller has a limited supply of an item in high (or uncertain and possibly high) demand, they frequently set a price far below what "the market will bear." As a result, the item sells out quickly, with lucky buyers being those who tried to buy first. This has happened in the Ethereum ecosystem, particularly with NFT sales and token sales/ICOs. But this phenomenon is much older; concerts and restaurants frequently make similar choices, resulting in fast sell-outs or long lines.
Why do sellers do this? Economists have long wondered. A seller should sell at the market-clearing price if the amount buyers are willing to buy exactly equals the amount the seller has to sell. If the seller is unsure of the market-clearing price, they should sell at auction and let the market decide. So, if you want to sell something below market value, don't do it. It will hurt your sales and it will hurt your customers. The competitions created by non-price-based allocation mechanisms can sometimes have negative externalities that harm third parties, as we will see.
However, the prevalence of below-market-clearing pricing suggests that sellers do it for good reason. And indeed, as decades of research into this topic has shown, there often are. So, is it possible to achieve the same goals with less unfairness, inefficiency, and harm?
Selling at below market-clearing prices has large inefficiencies and negative externalities
An item that is sold at market value or at an auction allows someone who really wants it to pay the high price or bid high in the auction. So, if a seller sells an item below market value, some people will get it and others won't. But the mechanism deciding who gets the item isn't random, and it's not always well correlated with participant desire. It's not always about being the fastest at clicking buttons. Sometimes it means waking up at 2 a.m. (but 11 p.m. or even 2 p.m. elsewhere). Sometimes it's just a "auction by other means" that's more chaotic, less efficient, and has far more negative externalities.
There are many examples of this in the Ethereum ecosystem. Let's start with the 2017 ICO craze. For example, an ICO project would set the price of the token and a hard maximum for how many tokens they are willing to sell, and the sale would start automatically at some point in time. The sale ends when the cap is reached.
So what? In practice, these sales often ended in 30 seconds or less. Everyone would start sending transactions in as soon as (or just before) the sale started, offering higher and higher fees to encourage miners to include their transaction first. Instead of the token seller receiving revenue, miners receive it, and the sale prices out all other applications on-chain.
The most expensive transaction in the BAT sale set a fee of 580,000 gwei, paying a fee of $6,600 to get included in the sale.
Many ICOs after that tried various strategies to avoid these gas price auctions; one ICO notably had a smart contract that checked the transaction's gasprice and rejected it if it exceeded 50 gwei. But that didn't solve the issue. Buyers hoping to game the system sent many transactions hoping one would get through. An auction by another name, clogging the chain even more.
ICOs have recently lost popularity, but NFTs and NFT sales have risen in popularity. But the NFT space didn't learn from 2017; they do fixed-quantity sales just like ICOs (eg. see the mint function on lines 97-108 of this contract here). So what?
That's not the worst; some NFT sales have caused gas price spikes of up to 2000 gwei.
High gas prices from users fighting to get in first by sending higher and higher transaction fees. An auction renamed, pricing out all other applications on-chain for 15 minutes.
So why do sellers sometimes sell below market price?
Selling below market value is nothing new, and many articles, papers, and podcasts have written (and sometimes bitterly complained) about the unwillingness to use auctions or set prices to market-clearing levels.
Many of the arguments are the same for both blockchain (NFTs and ICOs) and non-blockchain examples (popular restaurants and concerts). Fairness and the desire not to exclude the poor, lose fans or create tension by being perceived as greedy are major concerns. The 1986 paper by Kahneman, Knetsch, and Thaler explains how fairness and greed can influence these decisions. I recall that the desire to avoid perceptions of greed was also a major factor in discouraging the use of auction-like mechanisms in 2017.
Aside from fairness concerns, there is the argument that selling out and long lines create a sense of popularity and prestige, making the product more appealing to others. Long lines should have the same effect as high prices in a rational actor model, but this is not the case in reality. This applies to ICOs and NFTs as well as restaurants. Aside from increasing marketing value, some people find the game of grabbing a limited set of opportunities first before everyone else is quite entertaining.
But there are some blockchain-specific factors. One argument for selling ICO tokens below market value (and one that persuaded the OmiseGo team to adopt their capped sale strategy) is community dynamics. The first rule of community sentiment management is to encourage price increases. People are happy if they are "in the green." If the price drops below what the community members paid, they are unhappy and start calling you a scammer, possibly causing a social media cascade where everyone calls you a scammer.
This effect can only be avoided by pricing low enough that post-launch market prices will almost certainly be higher. But how do you do this without creating a rush for the gates that leads to an auction?
Interesting solutions
It's 2021. We have a blockchain. The blockchain is home to a powerful decentralized finance ecosystem, as well as a rapidly expanding set of non-financial tools. The blockchain also allows us to reset social norms. Where decades of economists yelling about "efficiency" failed, blockchains may be able to legitimize new uses of mechanism design. If we could use our more advanced tools to create an approach that more directly solves the problems, with fewer side effects, wouldn't that be better than fiddling with a coarse-grained one-dimensional strategy space of selling at market price versus below market price?
Begin with the goals. We'll try to cover ICOs, NFTs, and conference tickets (really a type of NFT) all at the same time.
1. Fairness: don't completely exclude low-income people from participation; give them a chance. The goal of token sales is to avoid high initial wealth concentration and have a larger and more diverse initial token holder community.
2. Don’t create races: Avoid situations where many people rush to do the same thing and only a few get in (this is the type of situation that leads to the horrible auctions-by-another-name that we saw above).
3. Don't require precise market knowledge: the mechanism should work even if the seller has no idea how much demand exists.
4. Fun: The process of participating in the sale should be fun and game-like, but not frustrating.
5. Give buyers positive expected returns: in the case of a token (or an NFT), buyers should expect price increases rather than decreases. This requires selling below market value.
Let's start with (1). From Ethereum's perspective, there is a simple solution. Use a tool designed for the job: proof of personhood protocols! Here's one quick idea:
Mechanism 1 Each participant (verified by ID) can buy up to ‘’X’’ tokens at price P, with the option to buy more at an auction.
With the per-person mechanism, buyers can get positive expected returns for the portion sold through the per-person mechanism, and the auction part does not require sellers to understand demand levels. Is it race-free? The number of participants buying through the per-person pool appears to be high. But what if the per-person pool isn't big enough to accommodate everyone?
Make the per-person allocation amount dynamic.
Mechanism 2 Each participant can deposit up to X tokens into a smart contract to declare interest. Last but not least, each buyer receives min(X, N / buyers) tokens, where N is the total sold through the per-person pool (some other amount can also be sold by auction). The buyer gets their deposit back if it exceeds the amount needed to buy their allocation.
No longer is there a race condition based on the number of buyers per person. No matter how high the demand, it's always better to join sooner rather than later.
Here's another idea if you like clever game mechanics with fancy quadratic formulas.
Mechanism 3 Each participant can buy X units at a price P X 2 up to a maximum of C tokens per buyer. C starts low and gradually increases until enough units are sold.
The quantity allocated to each buyer is theoretically optimal, though post-sale transfers will degrade this optimality over time. Mechanisms 2 and 3 appear to meet all of the above objectives. They're not perfect, but they're good starting points.
One more issue. For fixed and limited supply NFTs, the equilibrium purchased quantity per participant may be fractional (in mechanism 2, number of buyers > N, and in mechanism 3, setting C = 1 may already lead to over-subscription). With fractional sales, you can offer lottery tickets: if there are N items available, you have a chance of N/number of buyers of getting the item, otherwise you get a refund. For a conference, groups could bundle their lottery tickets to guarantee a win or a loss. The certainty of getting the item can be auctioned.
The bottom tier of "sponsorships" can be used to sell conference tickets at market rate. You may end up with a sponsor board full of people's faces, but is that okay? After all, John Lilic was on EthCC's sponsor board!
Simply put, if you want to be reliably fair to people, you need an input that explicitly measures people. Authentication protocols do this (and if desired can be combined with zero knowledge proofs to ensure privacy). So we should combine the efficiency of market and auction-based pricing with the equality of proof of personhood mechanics.
Answers to possible questions
Q: Won't people who don't care about your project buy the item and immediately resell it?
A: Not at first. Meta-games take time to appear in practice. If they do, making them untradeable for a while may help mitigate the damage. Using your face to claim that your previous account was hacked and that your identity, including everything in it, should be moved to another account works because proof-of-personhood identities are untradeable.
Q: What if I want to make my item available to a specific community?
A: Instead of ID, use proof of participation tokens linked to community events. Another option, also serving egalitarian and gamification purposes, is to encrypt items within publicly available puzzle solutions.
Q: How do we know they'll accept? Strange new mechanisms have previously been resisted.
A: Having economists write screeds about how they "should" accept a new mechanism that they find strange is difficult (or even "equity"). However, abrupt changes in context effectively reset people's expectations. So the blockchain space is the best place to try this. You could wait for the "metaverse", but it's possible that the best version will run on Ethereum anyway, so start now.
More on Web3 & Crypto

Scott Hickmann
4 years ago
YouTube
This is a YouTube video:

mbvissers.eth
3 years ago
Why does every smart contract seem to implement ERC165?

ERC165 (or EIP-165) is a standard utilized by various open-source smart contracts like Open Zeppelin or Aavegotchi.
What's it? You must implement? Why do we need it? I'll describe the standard and answer any queries.
What is ERC165
ERC165 detects and publishes smart contract interfaces. Meaning? It standardizes how interfaces are recognized, how to detect if they implement ERC165, and how a contract publishes the interfaces it implements. How does it work?
Why use ERC165? Sometimes it's useful to know which interfaces a contract implements, and which version.
Identifying interfaces
An interface function's selector. This verifies an ABI function. XORing all function selectors defines an interface in this standard. The following code demonstrates.
// SPDX-License-Identifier: UNLICENCED
pragma solidity >=0.8.0 <0.9.0;
interface Solidity101 {
function hello() external pure;
function world(int) external pure;
}
contract Selector {
function calculateSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector ^ i.world.selector;
// Returns 0xc6be8b58
}
function getHelloSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector;
// Returns 0x19ff1d21
}
function getWorldSelector() public pure returns (bytes4) {
Solidity101 i;
return i.world.selector;
// Returns 0xdf419679
}
}This code isn't necessary to understand function selectors and how an interface's selector can be determined from the functions it implements.
Run that sample in Remix to see how interface function modifications affect contract function output.
Contracts publish their implemented interfaces.
We can identify interfaces. Now we must disclose the interfaces we're implementing. First, import IERC165 like so.
pragma solidity ^0.4.20;
interface ERC165 {
/// @notice Query if a contract implements an interface
/// @param interfaceID The interface identifier, as specified in ERC-165
/// @dev Interface identification is specified in ERC-165.
/// @return `true` if the contract implements `interfaceID` and
/// `interfaceID` is not 0xffffffff, `false` otherwise
function supportsInterface(bytes4 interfaceID) external view returns (bool);
}We still need to build this interface in our smart contract. ERC721 from OpenZeppelin is a good example.
// SPDX-License-Identifier: MIT
// OpenZeppelin Contracts (last updated v4.5.0) (token/ERC721/ERC721.sol)
pragma solidity ^0.8.0;
import "./IERC721.sol";
import "./extensions/IERC721Metadata.sol";
import "../../utils/introspection/ERC165.sol";
// ...
contract ERC721 is Context, ERC165, IERC721, IERC721Metadata {
// ...
function supportsInterface(bytes4 interfaceId) public view virtual override(ERC165, IERC165) returns (bool) {
return
interfaceId == type(IERC721).interfaceId ||
interfaceId == type(IERC721Metadata).interfaceId ||
super.supportsInterface(interfaceId);
}
// ...
}I deleted unnecessary code. The smart contract imports ERC165, IERC721 and IERC721Metadata. The is keyword at smart contract declaration implements all three.
Kind (interface).
Note that type(interface).interfaceId returns the same as the interface selector.
We override supportsInterface in the smart contract to return a boolean that checks if interfaceId is the same as one of the implemented contracts.
Super.supportsInterface() calls ERC165 code. Checks if interfaceId is IERC165.
function supportsInterface(bytes4 interfaceId) public view virtual override returns (bool) {
return interfaceId == type(IERC165).interfaceId;
}So, if we run supportsInterface with an interfaceId, our contract function returns true if it's implemented and false otherwise. True for IERC721, IERC721Metadata, andIERC165.
Conclusion
I hope this post has helped you understand and use ERC165 and why it's employed.
Have a great day, thanks for reading!
Isobel Asher Hamilton
3 years ago
$181 million in bitcoin buried in a dump. $11 million to get them back

James Howells lost 8,000 bitcoins. He has $11 million to get them back.
His life altered when he threw out an iPhone-sized hard drive.
Howells, from the city of Newport in southern Wales, had two identical laptop hard drives squirreled away in a drawer in 2013. One was blank; the other had 8,000 bitcoins, currently worth around $181 million.
He wanted to toss out the blank one, but the drive containing the Bitcoin went to the dump.
He's determined to reclaim his 2009 stash.
Howells, 36, wants to arrange a high-tech treasure hunt for bitcoins. He can't enter the landfill.

Newport's city council has rebuffed Howells' requests to dig for his hard drive for almost a decade, stating it would be expensive and environmentally destructive.
I got an early look at his $11 million idea to search 110,000 tons of trash. He expects submitting it to the council would convince it to let him recover the hard disk.
110,000 tons of trash, 1 hard drive
Finding a hard disk among heaps of trash may seem Herculean.
Former IT worker Howells claims it's possible with human sorters, robot dogs, and an AI-powered computer taught to find hard drives on a conveyor belt.
His idea has two versions, depending on how much of the landfill he can search.
His most elaborate solution would take three years and cost $11 million to sort 100,000 metric tons of waste. Scaled-down version costs $6 million and takes 18 months.
He's created a team of eight professionals in AI-powered sorting, landfill excavation, garbage management, and data extraction, including one who recovered Columbia's black box data.
The specialists and their companies would be paid a bonus if they successfully recovered the bitcoin stash.
Howells: "We're trying to commercialize this project."
Howells claimed rubbish would be dug up by machines and sorted near the landfill.
Human pickers and a Max-AI machine would sort it. The machine resembles a scanner on a conveyor belt.
Remi Le Grand of Max-AI told us it will train AI to recognize Howells-like hard drives. A robot arm would select candidates.
Howells has added security charges to his scheme because he fears people would steal the hard drive.
He's budgeted for 24-hour CCTV cameras and two robotic "Spot" canines from Boston Dynamics that would patrol at night and look for his hard drive by day.
Howells said his crew met in May at the Celtic Manor Resort outside Newport for a pitch rehearsal.
Richard Hammond's narrative swings from banal to epic.
Richard Hammond filmed the meeting and created a YouTube documentary on Howells.
Hammond said of Howells' squad, "They're committed and believe in him and the idea."
Hammond: "It goes from banal to gigantic." "If I were in his position, I wouldn't have the strength to answer the door."
Howells said trash would be cleaned and repurposed after excavation. Reburying the rest.
"We won't pollute," he declared. "We aim to make everything better."

After the project is finished, he hopes to develop a solar or wind farm on the dump site. The council is unlikely to accept his vision soon.
A council representative told us, "Mr. Howells can't convince us of anything." "His suggestions constitute a significant ecological danger, which we can't tolerate and are forbidden by our permit."
Will the recovered hard drive work?
The "platter" is a glass or metal disc that holds the hard drive's data. Howells estimates 80% to 90% of the data will be recoverable if the platter isn't damaged.
Phil Bridge, a data-recovery expert who consulted Howells, confirmed these numbers.

If the platter is broken, Bridge adds, data recovery is unlikely.
Bridge says he was intrigued by the proposal. "It's an intriguing case," he added. Helping him get it back and proving everyone incorrect would be a great success story.
Who'd pay?
Swiss and German venture investors Hanspeter Jaberg and Karl Wendeborn told us they would fund the project if Howells received council permission.
Jaberg: "It's a needle in a haystack and a high-risk investment."
Howells said he had no contract with potential backers but had discussed the proposal in Zoom meetings. "Until Newport City Council gives me something in writing, I can't commit," he added.
Suppose he finds the bitcoins.
Howells said he would keep 30% of the data, worth $54 million, if he could retrieve it.
A third would go to the recovery team, 30% to investors, and the remainder to local purposes, including gifting £50 ($61) in bitcoin to each of Newport's 150,000 citizens.
Howells said he opted to spend extra money on "professional firms" to help convince the council.
What if the council doesn't approve?
If Howells can't win the council's support, he'll sue, claiming its actions constitute a "illegal embargo" on the hard drive. "I've avoided that path because I didn't want to cause complications," he stated. I wanted to cooperate with Newport's council.
Howells never met with the council face-to-face. He mentioned he had a 20-minute Zoom meeting in May 2021 but thought his new business strategy would help.
He met with Jessica Morden on June 24. Morden's office confirmed meeting.
After telling the council about his proposal, he can only wait. "I've never been happier," he said. This is our most professional operation, with the best employees.
The "crypto proponent" buys bitcoin every month and sells it for cash.
Howells tries not to think about what he'd do with his part of the money if the hard disk is found functional. "Otherwise, you'll go mad," he added.
This post is a summary. Read the full article here.
You might also like

Liz Martin
3 years ago
What Motivated Amazon to Spend $1 Billion for The Rings of Power?

Amazon's Rings of Power is the most costly TV series ever made. This is merely a down payment towards Amazon's grand goal.
Here's a video:
Amazon bought J.R.R. Tolkien's fantasy novels for $250 million in 2017. This agreement allows Amazon to create a Tolkien series for Prime Video.
The business spent years developing and constructing a Lord of the Rings prequel. Rings of Power premiered on September 2, 2022.
It drew 25 million global viewers in 24 hours. Prime Video's biggest debut.
An Exorbitant Budget
The most expensive. First season cost $750 million to $1 billion, making it the most costly TV show ever.
Jeff Bezos has spent years looking for the next Game of Thrones, a critically and commercially successful original series. Rings of Power could help.
Why would Amazon bet $1 billion on one series?
It's Not Just About the Streaming War
It's simple to assume Amazon just wants to win. Since 2018, the corporation has been fighting Hulu, Netflix, HBO, Apple, Disney, and NBC. Each wants your money, talent, and attention. Amazon's investment goes beyond rivalry.
Subscriptions Are the Bait
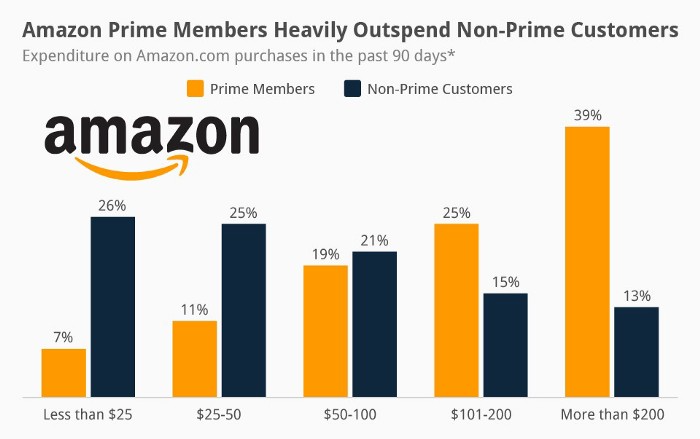
Audible, Amazon Music, and Prime Video are subscription services, although the company's fundamental business is retail. Amazon's online stores contribute over 50% of company revenue. Subscription services contribute 6.8%. The company's master plan depends on these subscriptions.
Streaming videos on Prime increases membership renewals. Free trial participants are more likely to join. Members buy twice as much as non-members.
Amazon Studios doesn't generate original programming to earn from Prime Video subscriptions. It aims to retain and attract clients.
Amazon can track what you watch and buy. Its algorithm recommends items and services. Mckinsey says you'll use more Amazon products, shop at Amazon stores, and watch Amazon entertainment.
In 2015, the firm launched the first season of The Man in the High Castle, a dystopian alternate history TV series depicting a world ruled by Nazi Germany and Japan after World War II.

This $72 million production earned two Emmys. It garnered 1.15 million new Prime users globally.
When asked about his Hollywood investment, Bezos said, "A Golden Globe helps us sell more shoes."
Selling more footwear
Amazon secured a deal with DirecTV to air Thursday Night Football in restaurants and bars. First streaming service to have exclusive NFL games.

This isn't just about Thursday night football, says media analyst Ritchie Greenfield. This sells t-shirts. This may be a ticket. Amazon does more than stream games.
The Rings of Power isn't merely a production showcase, either. This sells Tolkien's fantasy novels such Lord of the Rings, The Hobbit, and The Silmarillion.
This tiny commitment keeps you in Amazon's ecosystem.

Luke Plunkett
4 years ago
Gran Turismo 7 Update Eases Up On The Grind After Fan Outrage
Polyphony Digital has changed the game after apologizing in March.
To make amends for some disastrous downtime, Gran Turismo 7 director Kazunori Yamauchi announced a credits handout and promised to “dramatically change GT7's car economy to help make amends” last month. The first of these has arrived.
The game's 1.11 update includes the following concessions to players frustrated by the economy and its subsequent grind:
-
The last half of the World Circuits events have increased in-game credit rewards.
-
Modified Arcade and Custom Race rewards
-
Clearing all circuit layouts with Gold or Bronze now rewards In-game Credits. Exiting the Sector selection screen with the Exit button will award Credits if an event has already been cleared.
-
Increased Credits Rewards in Lobby and Daily Races
-
Increased the free in-game Credits cap from 20,000,000 to 100,000,000.
Additionally, “The Human Comedy” missions are one-hour endurance races that award “up to 1,200,000” credits per event.
This isn't everything Yamauchi promised last month; he said it would take several patches and updates to fully implement the changes. Here's a list of everything he said would happen, some of which have already happened (like the World Cup rewards and credit cap):
- Increase rewards in the latter half of the World Circuits by roughly 100%.
- Added high rewards for all Gold/Bronze results clearing the Circuit Experience.
- Online Races rewards increase.
- Add 8 new 1-hour Endurance Race events to Missions. So expect higher rewards.
- Increase the non-paid credit limit in player wallets from 20M to 100M.
- Expand the number of Used and Legend cars available at any time.
- With time, we will increase the payout value of limited time rewards.
- New World Circuit events.
- Missions now include 24-hour endurance races.
- Online Time Trials added, with rewards based on the player's time difference from the leader.
- Make cars sellable.
The full list of updates and changes can be found here.
Read the original post.

Mircea Iosif
3 years ago
How To Start An Online Business That Will Be Profitable Without Investing A Lot Of Time

Don't know how to start an online business? Here's a guide. By following these recommendations, you can build a lucrative and profitable online business.
What Are Online Businesses Used For?
Most online businesses are websites. A self-created, self-managed website. You may sell things and services online.
To establish an internet business, you must locate a host and set up accounts with numerous companies. Once your accounts are set up, you may start publishing content and selling products or services.
How to Make Money from Your Online Business
Advertising and marketing are the best ways to make money online. You must develop strategies to contact new customers and generate leads. Make sure your website is search engine optimized so people can find you online.
Top 5 Online Business Tips for Startups:
1. Know your target audience's needs.
2. Make your website as appealing as possible.
3. Generate leads and sales with marketing.
4. Track your progress and learn from your mistakes to improve.
5. Be prepared to expand into new markets or regions.
How to Launch a Successful Online Business Without Putting in a Lot of Work
Build with a solid business model to start a profitable online business. By using these tips, you can start your online business without paying much.
First, develop a user-friendly website. You can use an internet marketing platform or create your own website. Once your website is live, optimize it for search engines and add relevant content.
Second, sell online. This can be done through ads or direct sales to website visitors. Finally, use social media to advertise your internet business. By accomplishing these things, you'll draw visitors to your website and make money.
When launching a business, invest long-term. This involves knowing your goals and how you'll pay for them. Volatility can have several effects on your business. If you offer things online, you may need to examine if the market is ready for them.
Invest wisely
Investing all your money in one endeavor can lead to too much risk and little ROI. Diversify your investments to take advantage of all available chances. So, your investments won't encounter unexpected price swings and you'll be immune to economic upheavals.
Financial news updates
When launching or running a thriving online business, financial news is crucial. By knowing current trends and upcoming developments, you can keep your business lucrative.
Keeping up with financial news can also help you avoid potential traps that could harm your bottom line. If you don't know about new legislation that could affect your industry, potential customers may choose another store when they learn about your business's problems.
Volatility ahead
You should expect volatility in the financial sector. Without a plan for coping with volatility, you could run into difficulty. If your organization relies on client input, you may not be able to exploit customer behavior shifts.
Your company could go bankrupt if you don't understand how fickle the stock market can be. By preparing for volatility, you can ensure your organization survives difficult times and market crashes.
Conclusion
Many internet businesses can be profitable. Start quickly with a few straightforward steps. Diversify your investments, follow financial news, and be prepared for volatility to develop a successful business.
Thanks for reading!