



More on Entrepreneurship/Creators

The woman
3 years ago
Because he worked on his side projects during working hours, my junior was fired and sued.
Many developers do it, but I don't approve.

Aren't many programmers part-time? Many work full-time but also freelance. If the job agreement allows it, I see no problem.
Tech businesses' policies vary. I have a friend in Google, Germany. According to his contract, he couldn't do an outside job. Google owns any code he writes while employed.
I was shocked. Later, I found that different Google regions have different policies.
A corporation can normally establish any agreement before hiring you. They're negotiable. When there's no agreement, state law may apply. In court, law isn't so simple.
I won't delve into legal details. Instead, let’s talk about the incident.
How he was discovered
In one month, he missed two deadlines. His boss was frustrated because the assignment wasn't difficult to miss twice. When a team can't finish work on time, they all earn bad grades.
He annoyed the whole team. One team member (anonymous) told the project manager he worked on side projects during office hours. He may have missed deadlines because of this.
The project manager was furious. He needed evidence. The manager caught him within a week. The manager told higher-ups immediately.
The company wanted to set an example
Management could terminate him and settle the problem. But the company wanted to set an example for those developers who breached the regulation.
Because dismissal isn't enough. Every organization invests heavily in developer hiring. If developers depart or are fired after a few months, the company suffers.
The developer spent 10 months there. The employer sacked him and demanded ten months' pay. Or they'd sue him.
It was illegal and unethical. The youngster paid the fine and left the company quietly to protect his career.
Right or wrong?
Is the developer's behavior acceptable? Let's discuss developer malpractice.
During office hours, may developers work on other projects? If they're bored during office hours, they might not. Check the employment contract or state law.
If there's no employment clause, check country/state law. Because you can't justify breaking the law. Always. Most employers own their employees' work hours unless it's a contractual position.
If the company agrees, it's fine.
I also oppose companies that force developers to work overtime without pay.
Most states and countries have laws that help companies and workers. Law supports employers in this case. If any of the following are true, the company/employer owns the IP under California law.
using the business's resources
any equipment, including a laptop used for business.
company's mobile device.
offices of the company.
business time as well. This is crucial. Because this occurred in the instance of my junior.
Company resources are dangerous. Because your company may own the product's IP. If you have seen the TV show Silicon Valley, you have seen a similar situation there, right?
Conclusion
Simple rule. I avoid big side projects. I work on my laptop on weekends for side projects. I'm safe. But I also know that my company might not be happy with that.
As an employee, I suppose I can. I can make side money. I won't promote it, but I'll respect their time, resources, and task. I also sometimes work extra time to finish my company’s deadlines.

Ben Chino
3 years ago
100-day SaaS buildout.
We're opening up Maki through a series of Medium posts. We'll describe what Maki is building and how. We'll explain how we built a SaaS in 100 days. This isn't a step-by-step guide to starting a business, but a product philosophy to help you build quickly.
Focus on end-users.
This may seem obvious, but it's important to talk to users first. When we started thinking about Maki, we interviewed 100 HR directors from SMBs, Next40 scale-ups, and major Enterprises to understand their concerns. We initially thought about the future of employment, but most of their worries centered on Recruitment. We don't have a clear recruiting process, it's time-consuming, we recruit clones, we don't support diversity, etc. And as hiring managers, we couldn't help but agree.
Co-create your product with your end-users.
We went to the drawing board, read as many books as possible (here, here, and here), and when we started getting a sense for a solution, we questioned 100 more operational HR specialists to corroborate the idea and get a feel for our potential answer. This confirmed our direction to help hire more objectively and efficiently.
Back to the drawing board, we designed our first flows and screens. We organized sessions with certain survey respondents to show them our early work and get comments. We got great input that helped us build Maki, and we met some consumers. Obsess about users and execute alongside them.
Don’t shoot for the moon, yet. Make pragmatic choices first.
Once we were convinced, we began building. To launch a SaaS in 100 days, we needed an operating principle that allowed us to accelerate while still providing a reliable, secure, scalable experience. We focused on adding value and outsourced everything else. Example:
Concentrate on adding value. Reuse existing bricks.
When determining which technology to use, we looked at our strengths and the future to see what would last. Node.js for backend, React for frontend, both with typescript. We thought this technique would scale well since it would attract more talent and the surrounding mature ecosystem would help us go quicker.

We explored for ways to bootstrap services while setting down strong foundations that might support millions of users. We built our backend services on NestJS so we could extend into microservices later. Hasura, a GraphQL APIs engine, automates Postgres data exposing through a graphQL layer. MUI's ready-to-use components powered our design-system. We used well-maintained open-source projects to speed up certain tasks.
We outsourced important components of our platform (Auth0 for authentication, Stripe for billing, SendGrid for notifications) because, let's face it, we couldn't do better. We choose to host our complete infrastructure (SQL, Cloud run, Logs, Monitoring) on GCP to simplify our work between numerous providers.
Focus on your business, use existing bricks for the rest. For the curious, we'll shortly publish articles detailing each stage.
Most importantly, empower people and step back.
We couldn't have done this without the incredible people who have supported us from the start. Since Powership is one of our key values, we provided our staff the power to make autonomous decisions from day one. Because we believe our firm is its people, we hired smart builders and let them build.

Nicolas left Spendesk to create scalable interfaces using react-router, react-queries, and MUI. JD joined Swile and chose Hasura as our GraphQL engine. Jérôme chose NestJS to build our backend services. Since then, Justin, Ben, Anas, Yann, Benoit, and others have followed suit.
If you consider your team a collective brain, you should let them make decisions instead of directing them what to do. You'll make mistakes, but you'll go faster and learn faster overall.
Invest in great talent and develop a strong culture from the start. Here's how to establish a SaaS in 100 days.

cdixon
4 years ago
2000s Toys, Secrets, and Cycles
During the dot-com bust, I started my internet career. People used the internet intermittently to check email, plan travel, and do research. The average internet user spent 30 minutes online a day, compared to 7 today. To use the internet, you had to "log on" (most people still used dial-up), unlike today's always-on, high-speed mobile internet. In 2001, Amazon's market cap was $2.2B, 1/500th of what it is today. A study asked Americans if they'd adopt broadband, and most said no. They didn't see a need to speed up email, the most popular internet use. The National Academy of Sciences ranked the internet 13th among the 100 greatest inventions, below radio and phones. The internet was a cool invention, but it had limited uses and wasn't a good place to build a business.
A small but growing movement of developers and founders believed the internet could be more than a read-only medium, allowing anyone to create and publish. This is web 2. The runner up name was read-write web. (These terms were used in prominent publications and conferences.)
Web 2 concepts included letting users publish whatever they want ("user generated content" was a buzzword), social graphs, APIs and mashups (what we call composability today), and tagging over hierarchical navigation. Technical innovations occurred. A seemingly simple but important one was dynamically updating web pages without reloading. This is now how people expect web apps to work. Mobile devices that could access the web were niche (I was an avid Sidekick user).
The contrast between what smart founders and engineers discussed over dinner and on weekends and what the mainstream tech world took seriously during the week was striking. Enterprise security appliances, essentially preloaded servers with security software, were a popular trend. Many of the same people would talk about "serious" products at work, then talk about consumer internet products and web 2. It was tech's biggest news. Web 2 products were seen as toys, not real businesses. They were hobbies, not work-related.
There's a strong correlation between rich product design spaces and what smart people find interesting, which took me some time to learn and led to blog posts like "The next big thing will start out looking like a toy" Web 2's novel product design possibilities sparked dinner and weekend conversations. Imagine combining these features. What if you used this pattern elsewhere? What new product ideas are next? This excited people. "Serious stuff" like security appliances seemed more limited.
The small and passionate web 2 community also stood out. I attended the first New York Tech meetup in 2004. Everyone fit in Meetup's small conference room. Late at night, people demoed their software and chatted. I have old friends. Sometimes I get asked how I first met old friends like Fred Wilson and Alexis Ohanian. These topics didn't interest many people, especially on the east coast. We were friends. Real community. Alex Rampell, who now works with me at a16z, is someone I met in 2003 when a friend said, "Hey, I met someone else interested in consumer internet." Rare. People were focused and enthusiastic. Revolution seemed imminent. We knew a secret nobody else did.
My web 2 startup was called SiteAdvisor. When my co-founders and I started developing the idea in 2003, web security was out of control. Phishing and spyware were common on Internet Explorer PCs. SiteAdvisor was designed to warn users about security threats like phishing and spyware, and then, using web 2 concepts like user-generated reviews, add more subjective judgments (similar to what TrustPilot seems to do today). This staged approach was common at the time; I called it "Come for the tool, stay for the network." We built APIs, encouraged mashups, and did SEO marketing.
Yahoo's 2005 acquisitions of Flickr and Delicious boosted web 2 in 2005. By today's standards, the amounts were small, around $30M each, but it was a signal. Web 2 was assumed to be a fun hobby, a way to build cool stuff, but not a business. Yahoo was a savvy company that said it would make web 2 a priority.
As I recall, that's when web 2 started becoming mainstream tech. Early web 2 founders transitioned successfully. Other entrepreneurs built on the early enthusiasts' work. Competition shifted from ideation to execution. You had to decide if you wanted to be an idealistic indie bar band or a pragmatic stadium band.
Web 2 was booming in 2007 Facebook passed 10M users, Twitter grew and got VC funding, and Google bought YouTube. The 2008 financial crisis tested entrepreneurs' resolve. Smart people predicted another great depression as tech funding dried up.
Many people struggled during the recession. 2008-2011 was a golden age for startups. By 2009, talented founders were flooding Apple's iPhone app store. Mobile apps were booming. Uber, Venmo, Snap, and Instagram were all founded between 2009 and 2011. Social media (which had replaced web 2), cloud computing (which enabled apps to scale server side), and smartphones converged. Even if social, cloud, and mobile improve linearly, the combination could improve exponentially.
This chart shows how I view product and financial cycles. Product and financial cycles evolve separately. The Nasdaq index is a proxy for the financial sentiment. Financial sentiment wildly fluctuates.
Next row shows iconic startup or product years. Bottom-row product cycles dictate timing. Product cycles are more predictable than financial cycles because they follow internal logic. In the incubation phase, enthusiasts build products for other enthusiasts on nights and weekends. When the right mix of technology, talent, and community knowledge arrives, products go mainstream. (I show the biggest tech cycles in the chart, but smaller ones happen, like web 2 in the 2000s and fintech and SaaS in the 2010s.)
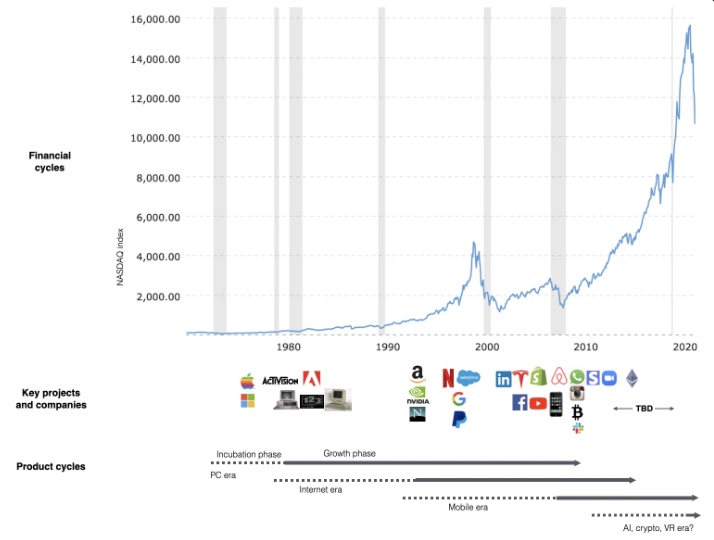
Tech has changed since the 2000s. Few tech giants dominate the internet, exerting economic and cultural influence. In the 2000s, web 2 was ignored or dismissed as trivial. Entrenched interests respond aggressively to new movements that could threaten them. Creative patterns from the 2000s continue today, driven by enthusiasts who see possibilities where others don't. Know where to look. Crypto and web 3 are where I'd start.
Today's negative financial sentiment reminds me of 2008. If we face a prolonged downturn, we can learn from 2008 by preserving capital and focusing on the long term. Keep an eye on the product cycle. Smart people are interested in things with product potential. This becomes true. Toys become necessities. Hobbies become mainstream. Optimists build the future, not cynics.
Full article is available here
You might also like

Chris Moyse
4 years ago
Sony and LEGO raise $2 billion for Epic Games' metaverse
‘Kid-friendly’ project holds $32 billion valuation
Epic Games announced today that it has raised $2 billion USD from Sony Group Corporation and KIRKBI (holding company of The LEGO Group). Both companies contributed $1 billion to Epic Games' upcoming ‘metaverse' project.
“We need partners who share our vision as we reimagine entertainment and play. Our partnership with Sony and KIRKBI has found this,” said Epic Games CEO Tim Sweeney. A new metaverse will be built where players can have fun with friends and brands create creative and immersive experiences, as well as creators thrive.
Last week, LEGO and Epic Games announced their plans to create a family-friendly metaverse where kids can play, interact, and create in digital environments. The service's users' safety and security will be prioritized.
With this new round of funding, Epic Games' project is now valued at $32 billion.
“Epic Games is known for empowering creators large and small,” said KIRKBI CEO Sren Thorup Srensen. “We invest in trends that we believe will impact the world we and our children will live in. We are pleased to invest in Epic Games to support their continued growth journey, with a long-term focus on the future metaverse.”
Epic Games is expected to unveil its metaverse plans later this year, including its name, details, services, and release date.

nft now
4 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here

Ben "The Hosk" Hosking
3 years ago
The Yellow Cat Test Is Typically Failed by Software Developers.
Believe what you see, what people say

It’s sad that we never get trained to leave assumptions behind. - Sebastian Thrun
Many problems in software development are not because of code but because developers create the wrong software. This isn't rare because software is emergent and most individuals only realize what they want after it's built.
Inquisitive developers who pass the yellow cat test can improve the process.
Carpenters measure twice and cut the wood once. Developers are rarely so careful.
The Yellow Cat Test
Game of Thrones made dragons cool again, so I am reading The Game of Thrones book.
The yellow cat exam is from Syrio Forel, Arya Stark's fencing instructor.
Syrio tells Arya he'll strike left when fencing. He hits her after she dodges left. Arya says “you lied”. Syrio says his words lied, but his eyes and arm told the truth.
Arya learns how Syrio became Bravos' first sword.
“On the day I am speaking of, the first sword was newly dead, and the Sealord sent for me. Many bravos had come to him, and as many had been sent away, none could say why. When I came into his presence, he was seated, and in his lap was a fat yellow cat. He told me that one of his captains had brought the beast to him, from an island beyond the sunrise. ‘Have you ever seen her like?’ he asked of me.
“And to him I said, ‘Each night in the alleys of Braavos I see a thousand like him,’ and the Sealord laughed, and that day I was named the first sword.”
Arya screwed up her face. “I don’t understand.”
Syrio clicked his teeth together. “The cat was an ordinary cat, no more. The others expected a fabulous beast, so that is what they saw. How large it was, they said. It was no larger than any other cat, only fat from indolence, for the Sealord fed it from his own table. What curious small ears, they said. Its ears had been chewed away in kitten fights. And it was plainly a tomcat, yet the Sealord said ‘her,’ and that is what the others saw. Are you hearing?” Reddit discussion.
Development teams should not believe what they are told.
We created an appointment booking system. We thought it was an appointment-booking system. Later, we realized the software's purpose was to book the right people for appointments and discourage the unneeded ones.
The first 3 months of the project had half-correct requirements and software understanding.
Open your eyes
“Open your eyes is all that is needed. The heart lies and the head plays tricks with us, but the eyes see true. Look with your eyes, hear with your ears. Taste with your mouth. Smell with your nose. Feel with your skin. Then comes the thinking afterwards, and in that way, knowing the truth” Syrio Ferel
We must see what exists, not what individuals tell the development team or how developers think the software should work. Initial criteria cover 50/70% and change.
Developers build assumptions problems by assuming how software should work. Developers must quickly explain assumptions.
When a development team's assumptions are inaccurate, they must alter the code, DevOps, documentation, and tests.
It’s always faster and easier to fix requirements before code is written.
First-draft requirements can be based on old software. Development teams must grasp corporate goals and consider needs from many angles.
Testers help rethink requirements. They look at how software requirements shouldn't operate.
Technical features and benefits might misdirect software projects.
The initiatives that focused on technological possibilities developed hard-to-use software that needed extensive rewriting following user testing.
Software development
High-level criteria are different from detailed ones.
The interpretation of words determines their meaning.
Presentations are lofty, upbeat, and prejudiced.
People's perceptions may be unclear, incorrect, or just based on one perspective (half the story)
Developers can be misled by requirements, circumstances, people, plans, diagrams, designs, documentation, and many other things.
Developers receive misinformation, misunderstandings, and wrong assumptions. The development team must avoid building software with erroneous specifications.
Once code and software are written, the development team changes and fixes them.
Developers create software with incomplete information, they need to fill in the blanks to create the complete picture.
Conclusion
Yellow cats are often inaccurate when communicating requirements.
Before writing code, clarify requirements, assumptions, etc.
Everyone will pressure the development team to generate code rapidly, but this will slow down development.
Code changes are harder than requirements.