



More on Leadership
Jason Kottke
3 years ago
Lessons on Leadership from the Dancing Guy
This is arguably the best three-minute demonstration I've ever seen of anything. Derek Sivers turns a shaky video of a lone dancing guy at a music festival into a leadership lesson.
A leader must have the courage to stand alone and appear silly. But what he's doing is so straightforward that it's almost instructive. This is critical. You must be simple to follow!
Now comes the first follower, who plays an important role: he publicly demonstrates how to follow. The leader embraces him as an equal, so it's no longer about the leader — it's about them, plural. He's inviting his friends to join him. It takes courage to be the first follower! You stand out and dare to be mocked. Being a first follower is a style of leadership that is underappreciated. The first follower elevates a lone nut to the position of leader. If the first follower is the spark that starts the fire, the leader is the flint.
This link was sent to me by @ottmark, who noted its resemblance to Kurt Vonnegut's three categories of specialists required for revolution.
The rarest of these specialists, he claims, is an actual genius – a person capable generating seemingly wonderful ideas that are not widely known. "A genius working alone is generally dismissed as a crazy," he claims.
The second type of specialist is much easier to find: a highly intellectual person in good standing in his or her community who understands and admires the genius's new ideas and can attest that the genius is not insane. "A person like him working alone can only crave loudly for changes, but fail to say what their shapes should be," Slazinger argues.
Jeff Veen reduced the three personalities to "the inventor, the investor, and the evangelist" on Twitter.

Hunter Walk
3 years ago
Is it bad of me to want our portfolio companies to generate greater returns for outside investors than they did for us as venture capitalists?
Wishing for Lasting Companies, Not Penny Stocks or Goodwill Write-Downs
Get me a NASCAR-style company-logoed cremation urn (notice to the executor of my will, theres gonna be a lot of weird requests). I believe in working on projects that would be on your tombstone. As the Homebrew logo is tattooed on my shoulder, expanding the portfolio to my posthumous commemoration is easy. But this isn't an IRR victory lap; it's a hope that the firms we worked for would last beyond my lifetime.
![a little boy planting a dollar bill in the ground and pouring a watering can out on it, digital art [DALL-E]](https://storage.googleapis.com/int3grity/posts/V62hkReDx56S/images/vMwzqrYeXaYnUIMXAdTY9)
Venture investors too often take credit or distance themselves from startups based on circumstances. Successful companies tell stories of crucial introductions, strategy conversations, and other value. Defeats Even whether our term involves Board service or systematic ethical violations, I'm just a little investment, so there's not much I can do. Since I'm guilty, I'm tossing stones from within the glass home (although we try to own our decisions through the lifecycle).
Post-exit company trajectories are usually unconfounded. Off the cap table, no longer a shareholder (or a diminishing one as you sell off/distribute), eventually leaving the Board. You can cheer for the squad or forget about it, but you've freed the corporation and it's back to portfolio work.
As I look at the downward track of most SPACs and other tarnished IPOs from the last few years, I wonder how I would feel if those were my legacy. Is my job done? Yes. When investing in a business, the odds are against it surviving, let alone thriving and being able to find sunlight. SPAC sponsors, institutional buyers, retail investments. Free trade in an open market is their right. Risking and losing capital is the system working! But
We were lead or co-lead investors in our first three funds, but as additional VCs joined the company, we were pushed down the cap table. Voting your shares rarely matters; supporting the firm when they need it does. Being valuable, consistent, and helping the company improve builds trust with the founders.
I hope every startup we sponsor becomes a successful public company before, during, and after we benefit. My perspective of American capitalism. Well, a stock ticker has a lot of garbage, and I support all types of regulation simplification (in addition to being a person investor in the Long-Term Stock Exchange). Yet being owned by a large group of investors and making actual gains for them is great. Likewise does seeing someone you met when they were just starting out become a public company CEO without losing their voice, leadership, or beliefs.
I'm just thinking about what we can do from the start to realize value from our investments and build companies with bright futures. Maybe seed venture financing shouldn't impact those outcomes, but I'm not comfortable giving up that obligation.

Nir Zicherman
3 years ago
The Great Organizational Conundrum
Only two of the following three options can be achieved: consistency, availability, and partition tolerance

Someone told me that growing from 30 to 60 is the biggest adjustment for a team or business.
I remember thinking, That's random. Each company is unique. I've seen teams of all types confront the same issues during development periods. With new enterprises starting every year, we should be better at navigating growing difficulties.
As a team grows, its processes and systems break down, requiring reorganization or declining results. Why always? Why isn't there a perfect scaling model? Why hasn't that been found?
The Three Things Productive Organizations Must Have
Any company should be efficient and productive. Three items are needed:
First, it must verify that no two team members have conflicting information about the roadmap, strategy, or any input that could affect execution. Teamwork is required.
Second, it must ensure that everyone can receive the information they need from everyone else quickly, especially as teams become more specialized (an inevitability in a developing organization). It requires everyone's accessibility.
Third, it must ensure that the organization can operate efficiently even if a piece is unavailable. It's partition-tolerant.
From my experience with the many teams I've been on, invested in, or advised, achieving all three is nearly impossible. Why a perfect organization model cannot exist is clear after analysis.
The CAP Theorem: What is it?
Eric Brewer of Berkeley discovered the CAP Theorem, which argues that a distributed data storage should have three benefits. One can only have two at once.
The three benefits are consistency, availability, and partition tolerance, which implies that even if part of the system is offline, the remainder continues to work.
This notion is usually applied to computer science, but I've realized it's also true for human organizations. In a post-COVID world, many organizations are hiring non-co-located staff as they grow. CAP Theorem is more important than ever. Growing teams sometimes think they can develop ways to bypass this law, dooming themselves to a less-than-optimal team dynamic. They should adopt CAP to maximize productivity.
Path 1: Consistency and availability equal no tolerance for partitions
Let's imagine you want your team to always be in sync (i.e., for someone to be the source of truth for the latest information) and to be able to share information with each other. Only division into domains will do.
Numerous developing organizations do this, especially after the early stage (say, 30 people) when everyone may wear many hats and be aware of all the moving elements. After a certain point, it's tougher to keep generalists aligned than to divide them into specialized tasks.
In a specialized, segmented team, leaders optimize consistency and availability (i.e. every function is up-to-speed on the latest strategy, no one is out of sync, and everyone is able to unblock and inform everyone else).
Partition tolerance suffers. If any component of the organization breaks down (someone goes on vacation, quits, underperforms, or Gmail or Slack goes down), productivity stops. There's no way to give the team stability, availability, and smooth operation during a hiccup.
Path 2: Partition Tolerance and Availability = No Consistency
Some businesses avoid relying too heavily on any one person or sub-team by maximizing availability and partition tolerance (the organization continues to function as a whole even if particular components fail). Only redundancy can do that. Instead of specializing each member, the team spreads expertise so people can work in parallel. I switched from Path 1 to Path 2 because I realized too much reliance on one person is risky.
What happens after redundancy? Unreliable. The more people may run independently and in parallel, the less anyone can be the truth. Lack of alignment or updated information can lead to people executing slightly different strategies. So, resources are squandered on the wrong work.
Path 3: Partition and Consistency "Tolerance" equates to "absence"
The third, least-used path stresses partition tolerance and consistency (meaning answers are always correct and up-to-date). In this organizational style, it's most critical to maintain the system operating and keep everyone aligned. No one is allowed to read anything without an assurance that it's up-to-date (i.e. there’s no availability).
Always short-lived. In my experience, a business that prioritizes quality and scalability over speedy information transmission can get bogged down in heavy processes that hinder production. Large-scale, this is unsustainable.
Accepting CAP
When two puzzle pieces fit, the third won't. I've watched developing teams try to tackle these difficulties, only to find, as their ancestors did, that they can never be entirely solved. Idealized solutions fail in reality, causing lost effort, confusion, and lower production.
As teams develop and change, they should embrace CAP, acknowledge there is a limit to productivity in a scaling business, and choose the best two-out-of-three path.
You might also like
Atown Research
3 years ago
Meet the One-Person Businesses Earning Millions in Sales from Solo Founders
I've spent over 50 hours researching one-person firms, which interest me. I've found countless one-person enterprises that made millions on the founder's determination and perseverance.
Throughout my investigation, I found three of the most outstanding one-person enterprises. These enterprises show that people who work hard and dedicate themselves to their ideas may succeed.
Eric Barone (@ConcernedApe) created Stardew Valley in 2011 to better his job prospects. Eric loved making the game, in which players inherit a farm, grow crops, raise livestock, make friends with the villagers, and form a family.
Eric handled complete game production, including 3D graphics, animations, and music, to maintain creative control. He stopped job hunting and worked 8-15 hours a day on the game.
Eric developed a Stardew Valley website and subreddit to engage with gamers and get feedback. Eric's devoted community helped him meet Steam's minimum vote requirement for single creators.
Stardew Valley sold 1 million copies in two months after Eric launched it for $15 in 2016. The game has sold 20 million copies and made $300 million.
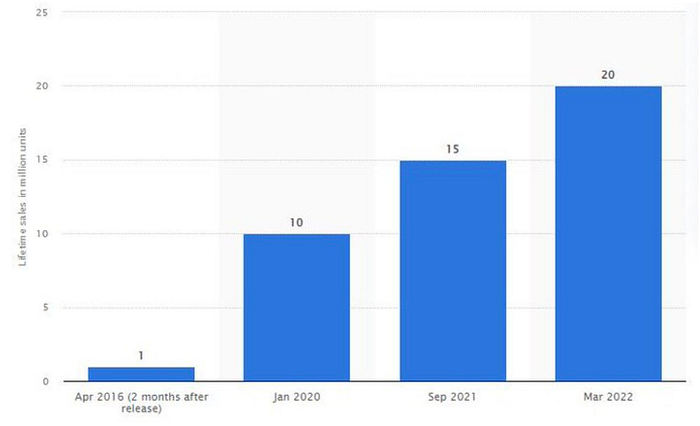
The game's inexpensive price, outsourcing of PR, marketing, and publication, and loyal player base helped it succeed. Eric has turned down million-dollar proposals from Sony and Nintendo to sell the game and instead updates and improves it. Haunted Chocolatier is Eric's new game.
Is farming not profitable? Ask Stardew Valley creator Eric Barone.
Gary Brewer established BuiltWith to assist users find website technologies and services. BuiltWith boasts 3000 paying customers and $14 million in yearly revenue, making it a significant resource for businesses wishing to generate leads, do customer analytics, obtain business insight, compare websites, or search websites by keyword.
BuiltWith has one full-time employee, Gary, and one or two part-time contractors that help with the blog. Gary handles sales, customer service, and other company functions alone.
BuiltWith acquired popularity through blog promotions and a top Digg ranking. About Us, a domain directory, connected to BuiltWith on every domain page, boosting it. Gary introduced $295–$995 monthly subscriptions to search technology, keywords, and potential consumers in response to customer demand.
Gary uses numerous methods to manage a firm without staff. He spends one to two hours every day answering user queries, most of which are handled quickly by linking to BuiltWiths knowledge store. Gary creates step-by-step essays or videos for complex problems. Gary can focus on providing new features based on customer comments and requests since he makes it easy to unsubscribe.
BuiltWith is entirely automated and successful due to its unique approach and useful offerings. It works for Google, Meta, Amazon, and Twitter.
Digital Inspiration develops Google Documents, Sheets, and Slides plugins. Digital Inspiration, founded by Amit Agarwal, receives 5 million monthly visits and earns $10 million. 40 million individuals have downloaded Digital Inspirations plugins.
Amit started Digital Inspiration by advertising his blog at tech events and getting Indian filter blogs and other newspapers to promote his articles. Amit built plugins and promoted them on the blog once the blog acquired popularity, using ideas from comments, friends, and Reddit. Digital Inspiration has over 20 free and premium plugins.
Mail Merge, Notifications for Google Forms, YouTube Uploader, and Document Studio are some of Digital Inspiration's most popular plugins. Mail Merge allows users to send personalized emails in bulk and track email opens and clicks.
Since Amits manages Digital Inspiration alone, his success is astounding. Amit developed a successful company via hard work and creativity, despite platform dependence. His tale inspires entrepreneurs.

DC Palter
3 years ago
How Will You Generate $100 Million in Revenue? The Startup Business Plan
A top-down company plan facilitates decision-making and impresses investors.

A startup business plan starts with the product, the target customers, how to reach them, and how to grow the business.
Bottom-up is terrific unless venture investors fund it.
If it can prove how it can exceed $100M in sales, investors will invest. If not, the business may be wonderful, but it's not venture capital-investable.
As a rule, venture investors only fund firms that expect to reach $100M within 5 years.
Investors get nothing until an acquisition or IPO. To make up for 90% of failed investments and still generate 20% annual returns, portfolio successes must exit with a 25x return. A $20M-valued company must be acquired for $500M or more.
This requires $100M in sales (or being on a nearly vertical trajectory to get there). The company has 5 years to attain that milestone and create the requisite ROI.
This motivates venture investors (venture funds and angel investors) to hunt for $100M firms within 5 years. When you pitch investors, you outline how you'll achieve that aim.
I'm wary of pitches after seeing a million hockey sticks predicting $5M to $100M in year 5 that never materialized. Doubtful.
Startups fail because they don't have enough clients, not because they don't produce a great product. That jump from $5M to $100M never happens. The company reaches $5M or $10M, growing at 10% or 20% per year. That's great, but not enough for a $500 million deal.
Once it becomes clear the company won’t reach orbit, investors write it off as a loss. When a corporation runs out of money, it's shut down or sold in a fire sale. The company can survive if expenses are trimmed to match revenues, but investors lose everything.
When I hear a pitch, I'm not looking for bright income projections but a viable plan to achieve them. Answer these questions in your pitch.
Is the market size sufficient to generate $100 million in revenue?
Will the initial beachhead market serve as a springboard to the larger market or as quicksand that hinders progress?
What marketing plan will bring in $100 million in revenue? Is the market diffuse and will cost millions of dollars in advertising, or is it one, focused market that can be tackled with a team of salespeople?
Will the business be able to bridge the gap from a small but fervent set of early adopters to a larger user base and avoid lock-in with their current solution?
Will the team be able to manage a $100 million company with hundreds of people, or will hypergrowth force the organization to collapse into chaos?
Once the company starts stealing market share from the industry giants, how will it deter copycats?
The requirement to reach $100M may be onerous, but it provides a context for difficult decisions: What should the product be? Where should we concentrate? who should we hire? Every strategic choice must consider how to reach $100M in 5 years.
Focusing on $100M streamlines investor pitches. Instead of explaining everything, focus on how you'll attain $100M.
As an investor, I know I'll lose my money if the startup doesn't reach this milestone, so the revenue prediction is the first thing I look at in a pitch deck.
Reaching the $100M goal needs to be the first thing the entrepreneur thinks about when putting together the business plan, the central story of the pitch, and the criteria for every important decision the company makes.

Scott Stockdale
3 years ago
A Day in the Life of Lex Fridman Can Help You Hit 6-Month Goals

The Lex Fridman podcast host has interviewed Elon Musk.
Lex is a minimalist YouTuber. His videos are sloppy. Suits are his trademark.
In a video, he shares a typical day. I've smashed my 6-month goals using its ideas.
Here's his schedule.
Morning Mantra
Not woo-woo. Lex's mantra reflects his practicality.
Four parts.
Rulebook
"I remember the game's rules," he says.
Among them:
Sleeping 6–8 hours nightly
1–3 times a day, he checks social media.
Every day, despite pain, he exercises. "I exercise uninjured body parts."
Visualize
He imagines his day. "Like Sims..."
He says three things he's grateful for and contemplates death.
"Today may be my last"
Objectives
Then he visualizes his goals. He starts big. Five-year goals.
Short-term goals follow. Lex says they're year-end goals.
Near but out of reach.
Principles
He lists his principles. Assertions. His goals.
He acknowledges his cliche beliefs. Compassion, empathy, and strength are key.
Here's my mantra routine:

Four-Hour Deep Work
Lex begins a four-hour deep work session after his mantra routine. Today's toughest.
AI is Lex's specialty. His video doesn't explain what he does.
Clearly, he works hard.
Before starting, he has water, coffee, and a bathroom break.
"During deep work sessions, I minimize breaks."
He's distraction-free. Phoneless. Silence. Nothing. Any loose ideas are typed into a Google doc for later. He wants to work.
"Just get the job done. Don’t think about it too much and feel good once it’s complete." — Lex Fridman
30-Minute Social Media & Music
After his first deep work session, Lex rewards himself.
10 minutes on social media, 20 on music. Upload content and respond to comments in 10 minutes. 20 minutes for guitar or piano.
"In the real world, I’m currently single, but in the music world, I’m in an open relationship with this beautiful guitar. Open relationship because sometimes I cheat on her with the acoustic." — Lex Fridman
Two-hour exercise
Then exercise for two hours.
Daily runs six miles. Then he chooses how far to go. Run time is an hour.
He does bodyweight exercises. Every minute for 15 minutes, do five pull-ups and ten push-ups. It's David Goggins-inspired. He aims for an hour a day.
He's hungry. Before running, he takes a salt pill for electrolytes.
He'll then take a one-minute cold shower while listening to cheesy songs. Afterward, he might eat.
Four-Hour Deep Work
Lex's second work session.
He works 8 hours a day.
Again, zero distractions.
Eating
The video's meal doesn't look appetizing, but it's healthy.
It's ground beef with vegetables. Cauliflower is his "ground-floor" veggie. "Carrots are my go-to party food."
Lex's keto diet includes 1800–2000 calories.
He drinks a "nutrient-packed" Atheltic Greens shake and takes tablets. It's:
One daily tablet of sodium.
Magnesium glycinate tablets stopped his keto headaches.
Potassium — "For electrolytes"
Fish oil: healthy joints
“So much of nutrition science is barely a science… I like to listen to my own body and do a one-person, one-subject scientific experiment to feel good.” — Lex Fridman
Four-hour shallow session
This work isn't as mentally taxing.
Lex planned to:
Finish last session's deep work (about an hour)
Adobe Premiere podcasting (about two hours).
Email-check (about an hour). Three times a day max. First, check for emergencies.
If he's sick, he may watch Netflix or YouTube documentaries or visit friends.
“The possibilities of chaos are wide open, so I can do whatever the hell I want.” — Lex Fridman
Two-hour evening reading
Nonstop work.
Lex ends the day reading academic papers for an hour. "Today I'm skimming two machine learning and neuroscience papers"
This helps him "think beyond the paper."
He reads for an hour.
“When I have a lot of energy, I just chill on the bed and read… When I’m feeling tired, I jump to the desk…” — Lex Fridman
Takeaways
Lex's day-in-the-life video is inspiring.
He has positive energy and works hard every day.
Schedule:
Mantra Routine includes rules, visualizing, goals, and principles.
Deep Work Session #1: Four hours of focus.
10 minutes social media, 20 minutes guitar or piano. "Music brings me joy"
Six-mile run, then bodyweight workout. Two hours total.
Deep Work #2: Four hours with no distractions. Google Docs stores random thoughts.
Lex supplements his keto diet.
This four-hour session is "open to chaos."
Evening reading: academic papers followed by fiction.
"I value some things in life. Work is one. The other is loving others. With those two things, life is great." — Lex Fridman