



More on Science

Bob Service
3 years ago
Did volcanic 'glasses' play a role in igniting early life?
Quenched lava may have aided in the formation of long RNA strands required by primitive life.
It took a long time for life to emerge. Microbes were present 3.7 billion years ago, just a few hundred million years after the 4.5-billion-year-old Earth had cooled enough to sustain biochemistry, according to fossils, and many scientists believe RNA was the genetic material for these first species. RNA, while not as complicated as DNA, would be difficult to forge into the lengthy strands required to transmit genetic information, raising the question of how it may have originated spontaneously.
Researchers may now have a solution. They demonstrate how basaltic glasses assist individual RNA letters, also known as nucleoside triphosphates, join into strands up to 200 letters long in lab studies. The glasses are formed when lava is quenched in air or water, or when melted rock generated by asteroid strikes cools rapidly, and they would have been plentiful in the early Earth's fire and brimstone.
The outcome has caused a schism among top origin-of-life scholars. "This appears to be a great story that finally explains how nucleoside triphosphates react with each other to create RNA strands," says Thomas Carell, a scientist at Munich's Ludwig Maximilians University. However, Harvard University's Jack Szostak, an RNA expert, says he won't believe the results until the study team thoroughly describes the RNA strands.
Researchers interested in the origins of life like the idea of a primordial "RNA universe" since the molecule can perform two different functions that are essential for life. It's made up of four chemical letters, just like DNA, and can carry genetic information. RNA, like proteins, can catalyze chemical reactions that are necessary for life.
However, RNA can cause headaches. No one has yet discovered a set of plausible primordial conditions that would cause hundreds of RNA letters—each of which is a complicated molecule—to join together into strands long enough to support the intricate chemistry required to kick-start evolution.
Basaltic glasses may have played a role, according to Stephen Mojzsis, a geologist at the University of Colorado, Boulder. They're high in metals like magnesium and iron, which help to trigger a variety of chemical reactions. "Basaltic glass was omnipresent on Earth at the time," he adds.
He provided the Foundation for Applied Molecular Evolution samples of five different basalt glasses. Each sample was ground into a fine powder, sanitized, and combined with a solution of nucleoside triphosphates by molecular biologist Elisa Biondi and her colleagues. The RNA letters were unable to link up without the presence of glass powder. However, when the molecules were mixed with the glass particles, they formed long strands of hundreds of letters, according to the researchers, who published their findings in Astrobiology this week. There was no need for heat or light. Biondi explains, "All we had to do was wait." After only a day, little RNA strands produced, yet the strands continued to grow for months. Jan Paek, a molecular biologist at Firebird Biomolecular Sciences, says, "The beauty of this approach is its simplicity." "Mix the components together, wait a few days, and look for RNA."
Nonetheless, the findings pose a slew of problems. One of the questions is how nucleoside triphosphates came to be in the first place. Recent study by Biondi's colleague Steven Benner suggests that the same basaltic glasses may have aided in the creation and stabilization of individual RNA letters.
The form of the lengthy RNA strands, according to Szostak, is a significant challenge. Enzymes in modern cells ensure that most RNAs form long linear chains. RNA letters, on the other hand, can bind in complicated branching sequences. Szostak wants the researchers to reveal what kind of RNA was produced by the basaltic glasses. "It irritates me that the authors made an intriguing initial finding but then chose to follow the hype rather than the research," Szostak says.
Biondi acknowledges that her team's experiment almost probably results in some RNA branching. She does acknowledge, however, that some branched RNAs are seen in species today, and that analogous structures may have existed before the origin of life. Other studies carried out by the study also confirmed the presence of lengthy strands with connections, indicating that they are most likely linear. "It's a healthy argument," says Dieter Braun, a Ludwig Maximilian University origin-of-life chemist. "It will set off the next series of tests."

Katrina Paulson
3 years ago
Dehumanization Against Anthropomorphization
We've fought for humanity's sake. We need equilibrium.

We live in a world of opposites (black/white, up/down, love/hate), thus life is a game of achieving equilibrium. We have a universe of paradoxes within ourselves, not just in physics.
Individually, you balance your intellect and heart, but as a species, we're full of polarities. They might be gentle and compassionate, then ruthless and unsympathetic.
We desire for connection so much that we personify non-human beings and objects while turning to violence and hatred toward others. These contrasts baffle me. Will we find balance?
Anthropomorphization
Assigning human-like features or bonding with objects is common throughout childhood. Cartoons often give non-humans human traits. Adults still anthropomorphize this trait. Researchers agree we start doing it as infants and continue throughout life.
Humans of all ages are good at humanizing stuff. We build emotional attachments to weather events, inanimate objects, animals, plants, and locales. Gods, goddesses, and fictitious figures are anthropomorphized.
Cast Away, starring Tom Hanks, features anthropization. Hanks is left on an island, where he builds an emotional bond with a volleyball he calls Wilson.
We became emotionally invested in Wilson, including myself.
Why do we do it, though?
Our instincts and traits helped us survive and thrive. Our brain is alert to other people's thoughts, feelings, and intentions to assist us to determine who is safe or hazardous. We can think about others and our own mental states, or about thinking. This is the Theory of Mind.
Neurologically, specialists believe the Theory of Mind has to do with our mirror neurons, which exhibit the same activity while executing or witnessing an action.
Mirror neurons may contribute to anthropization, but they're not the only ones. In 2021, Harvard Medical School researchers at MGH and MIT colleagues published a study on the brain's notion of mind.
“Our study provides evidence to support theory of mind by individual neurons. Until now, it wasn’t clear whether or how neurons were able to perform these social cognitive computations.”
Neurons have particular functions, researchers found. Others encode information that differentiates one person's beliefs from another's. Some neurons reflect tale pieces, whereas others aren't directly involved in social reasoning but may multitask contributing factors.
Combining neuronal data gives a precise portrait of another's beliefs and comprehension. The theory of mind describes how we judge and understand each other in our species, and it likely led to anthropomorphism. Neuroscience indicates identical brain regions react to human or non-human behavior, like mirror neurons.
Some academics believe we're wired for connection, which explains why we anthropomorphize. When we're alone, we may anthropomorphize non-humans.
Humanizing non-human entities may make them deserving of moral care, according to another theory. Animamorphizing something makes it responsible for its actions and deserves punishments or rewards. This mental shift is typically apparent in our connections with pets and leads to deanthropomorphization.
Dehumanization
Dehumanizing involves denying someone or anything ethical regard, the opposite of anthropomorphizing.
Dehumanization occurs throughout history. We do it to everything in nature, including ourselves. We experiment on and torture animals. We enslave, hate, and harm other groups of people.
Race, immigrant status, dress choices, sexual orientation, social class, religion, gender, politics, need I go on? Our degrading behavior is promoting fascism and division everywhere.
Dehumanizing someone or anything reduces their agency and value. Many assume they're immune to this feature, but tests disagree.
It's inevitable. Humans are wired to have knee-jerk reactions to differences. We are programmed to dehumanize others, and it's easier than we'd like to admit.
Why do we do it, though?
Dehumanizing others is simpler than humanizing things for several reasons. First, we consider everything unusual as harmful, which has helped our species survive for hundreds of millions of years. Our propensity to be distrustful of others, like our fear of the unknown, promotes an us-vs.-them mentality.
Since WWII, various studies have been done to explain how or why the holocaust happened. How did so many individuals become radicalized to commit such awful actions and feel morally justified? Researchers quickly showed how easily the mind can turn gloomy.
Stanley Milgram's 1960s electroshock experiment highlighted how quickly people bow to authority to injure others. Philip Zimbardo's 1971 Stanford Prison Experiment revealed how power may be abused.
The us-versus-them attitude is natural and even young toddlers act on it. Without a relationship, empathy is more difficult.
It's terrifying how quickly dehumanizing behavior becomes commonplace. The current pandemic is an example. Most countries no longer count deaths. Long Covid is a major issue, with predictions of a handicapped tsunami in the future years. Mostly, we shrug.
In 2020, we panicked. Remember everyone's caution? Now Long Covid is ruining more lives, threatening to disable an insane amount of our population for months or their entire lives.
There's little research. Experts can't even classify or cure it. The people should be outraged, but most have ceased caring. They're over covid.
We're encouraged to find a method to live with a terrible pandemic that will cause years of damage. People aren't worried about infection anymore. They shrug and say, "We'll all get it eventually," then hope they're not one of the 30% who develops Long Covid.
We can correct course before further damage. Because we can recognize our urges and biases, we're not captives to them. We can think critically about our thoughts and behaviors, then attempt to improve. We can recognize our deficiencies and work to attain balance.
Changing perspectives
We're currently attempting to find equilibrium between opposites. It's superficial to defend extremes by stating we're only human or wired this way because both imply we have no control.
Being human involves having self-awareness, and by being careful of our thoughts and acts, we can find balance and recognize opposites' purpose.
Extreme anthropomorphizing and dehumanizing isolate and imperil us. We anthropomorphize because we desire connection and dehumanize because we're terrified, frequently of the connection we crave. Will we find balance?
Katrina Paulson ponders humanity, unanswered questions, and discoveries. Please check out her newsletters, Curious Adventure and Curious Life.

Sara_Mednick
3 years ago
Since I'm a scientist, I oppose biohacking
Understanding your own energy depletion and restoration is how to truly optimize

Hack has meant many bad things for centuries. In the 1800s, a hack was a meager horse used to transport goods.
Modern usage describes a butcher or ax murderer's cleaver chop. The 1980s programming boom distinguished elegant code from "hacks". Both got you to your goal, but the latter made any programmer cringe and mutter about changing the code. From this emerged the hacker trope, the friendless anti-villain living in a murky hovel lit by the computer monitor, eating junk food and breaking into databases to highlight security system failures or steal hotdog money.

Now, start-a-billion-dollar-business-from-your-garage types have shifted their sights from app development to DIY biology, coining the term "bio-hack". This is a required keyword and meta tag for every fitness-related podcast, book, conference, app, or device.
Bio-hacking involves bypassing your body and mind's security systems to achieve a goal. Many biohackers' initial goals were reasonable, like lowering blood pressure and weight. Encouraged by their own progress, self-determination, and seemingly exquisite control of their biology, they aimed to outsmart aging and death to live 180 to 1000 years (summarized well in this vox.com article).
With this grandiose north star, the hunt for novel supplements and genetic engineering began.
Companies selling do-it-yourself biological manipulations cite lab studies in mice as proof of their safety and success in reversing age-related diseases or promoting longevity in humans (the goal changes depending on whether a company is talking to the federal government or private donors).
The FDA is slower than science, they say. Why not alter your biochemistry by buying pills online, editing your DNA with a CRISPR kit, or using a sauna delivered to your home? How about a microchip or electrical stimulator?
What could go wrong?
I'm not the neo-police, making citizen's arrests every time someone introduces a new plumbing gadget or extrapolates from animal research on resveratrol or catechins that we should drink more red wine or eat more chocolate. As a scientist who's spent her career asking, "Can we get better?" I've come to view bio-hacking as misguided, profit-driven, and counterproductive to its followers' goals.
We're creatures of nature. Despite all the new gadgets and bio-hacks, we still use Roman plumbing technology, and the best way to stay fit, sharp, and happy is to follow a recipe passed down since the beginning of time. Bacteria, plants, and all natural beings are rhythmic, with alternating periods of high activity and dormancy, whether measured in seconds, hours, days, or seasons. Nature repeats successful patterns.
During the Upstate, every cell in your body is naturally primed and pumped full of glycogen and ATP (your cells' energy currencies), as well as cortisol, which supports your muscles, heart, metabolism, cognitive prowess, emotional regulation, and general "get 'er done" attitude. This big energy release depletes your batteries and requires the Downstate, when your subsystems recharge at the cellular level.
Downstates are when you give your heart a break from pumping nutrient-rich blood through your body; when you give your metabolism a break from inflammation, oxidative stress, and sympathetic arousal caused by eating fast food — or just eating too fast; or when you give your mind a chance to wander, think bigger thoughts, and come up with new creative solutions. When you're responding to notifications, emails, and fires, you can't relax.
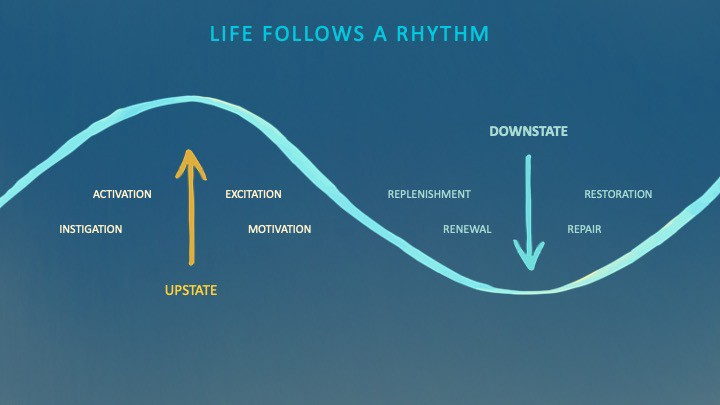
Downstates aren't just for consistently recharging your battery. By spending time in the Downstate, your body and brain get extra energy and nutrients, allowing you to grow smarter, faster, stronger, and more self-regulated. This state supports half-marathon training, exam prep, and mediation. As we age, spending more time in the Downstate is key to mental and physical health, well-being, and longevity.
When you prioritize energy-demanding activities during Upstate periods and energy-replenishing activities during Downstate periods, all your subsystems, including cardiovascular, metabolic, muscular, cognitive, and emotional, hum along at their optimal settings. When you synchronize the Upstates and Downstates of these individual rhythms, their functioning improves. A hard workout causes autonomic stress, which triggers Downstate recovery.
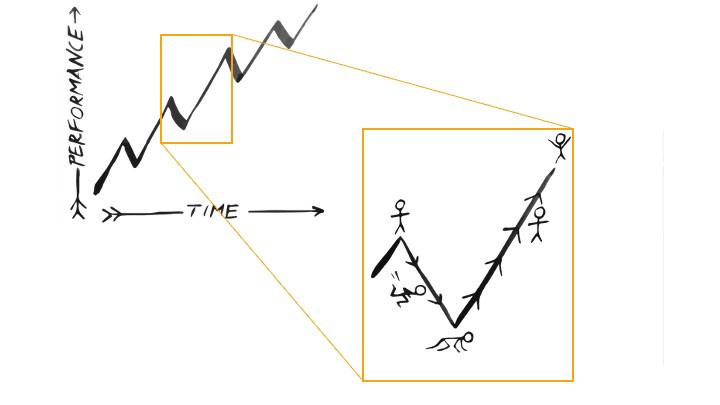
By choosing the right timing and type of exercise during the day, you can ensure a deeper recovery and greater readiness for the next workout by working with your natural rhythms and strengthening your autonomic and sleep Downstates.
Morning cardio workouts increase deep sleep compared to afternoon workouts. Timing and type of meals determine when your sleep hormone melatonin is released, ushering in sleep.
Rhythm isn't a hack. It's not a way to cheat the system or the boss. Nature has honed its optimization wisdom over trillions of days and nights. Stop looking for quick fixes. You're a whole system made of smaller subsystems that must work together to function well. No one pill or subsystem will make it all work. Understanding and coordinating your rhythms is free, easy, and only benefits you.
Dr. Sara C. Mednick is a cognitive neuroscientist at UC Irvine and author of The Power of the Downstate (HachetteGO)
You might also like

Franz Schrepf
3 years ago
What I Wish I'd Known About Web3 Before Building
Cryptoland rollercoaster

I've lost money in crypto.
Unimportant.
The real issue: I didn’t understand how.
I'm surrounded with winners. To learn more, I created my own NFTs, currency, and DAO.
Web3 is a hilltop castle. Everything is valuable, decentralized, and on-chain.
The castle is Disneyland: beautiful in images, but chaotic with lengthy lines and kids spending too much money on dressed-up animals.
When the throng and businesses are gone, Disneyland still has enchantment.

The Real Story of Web3
NFTs
Scarcity. Scarce NFTs. That's their worth.
Skull. Rare-looking!
Nonsense.
Bored Ape Yacht Club vs. my NFTs?
Marketing.
BAYC is amazing, but not for the reasons people believe. Apecoin and Otherside's art, celebrity following, and innovation? Stunning.
No other endeavor captured the zeitgeist better. Yet how long did you think it took to actually mint the NFTs?
1 hour? Maybe a week for the website?
Minting NFTs is incredibly easy. Kid-friendly. Developers are rare. Think about that next time somebody posts “DevS dO SMt!?”
NFTs will remain popular. These projects are like our Van Goghs and Monets. Still, be wary. It still uses exclusivity and wash selling like the OG art market.
Not all NFTs are art-related.
Soulbound and anonymous NFTs could offer up new use cases. Property rights, privacy-focused ID, open-source project verification. Everything.
NFTs build online trust through ownership.
We just need to evolve from the apes first.
NFTs' superpower is marketing until then.
Crypto currency
What the hell is a token?
99% of people are clueless.
So I invested in both coins and tokens. Same same. Only that they are not.
Coins have their own blockchain and developer/validator community. It's hard.
Creating a token on top of a blockchain? Five minutes.
Most consumers don’t understand the difference, creating an arbitrage opportunity: pretend you’re a serious project without having developers on your payroll.
Few market sites help. Take a look. See any tokens?
There's a hint one click deeper.

Some tokens are legitimate. Some coins are bad investments.
Tokens are utilized for DAO governance and DApp payments. Still, know who's behind a token. They might be 12 years old.
Coins take time and money. The recent LUNA meltdown indicates that currency investing requires research.
DAOs
Decentralized Autonomous Organizations (DAOs) don't work as you assume.
Yes, members can vote.
A productive organization requires more.
I've observed two types of DAOs.
Total decentralization total dysfunction
Centralized just partially. Community-driven.
A core team executes the DAO's strategy and roadmap in successful DAOs. The community owns part of the organization, votes on decisions, and holds the team accountable.
DAOs are public companies.
Amazing.
A shareholder meeting's logistics are staggering. DAOs may hold anonymous, secure voting quickly. No need for intermediaries like banks to chase up every shareholder.
Successful DAOs aren't totally decentralized. Large-scale voting and collaboration have never been easier.
And that’s all that matters.
Scale, speed.
My Web3 learnings
Disneyland is enchanting. Web3 too.
In a few cycles, NFTs may be used to build trust, not clout. Not speculating with coins. DAOs run organizations, not themselves.
Finally, some final thoughts:
NFTs will be a very helpful tool for building trust online. NFTs are successful now because of excellent marketing.
Tokens are not the same as coins. Look into any project before making a purchase. Make sure it isn't run by three 9-year-olds piled on top of one another in a trench coat, at the very least.
Not entirely decentralized, DAOs. We shall see a future where community ownership becomes the rule rather than the exception once we acknowledge this fact.
Crypto Disneyland is a rollercoaster with loops that make you sick.
Always buckle up.
Have fun!

Rita McGrath
3 years ago
Flywheels and Funnels
Traditional sales organizations used the concept of a sales “funnel” to describe the process through which potential customers move, ending up with sales at the end. Winners today have abandoned that way of thinking in favor of building flywheels — business models in which every element reinforces every other.
Ah, the marketing funnel…
Prospective clients go through a predictable set of experiences, students learn in business school marketing classes. It looks like this:

Understanding the funnel helps evaluate sales success indicators. Gail Goodwin, former CEO of small business direct mail provider Constant Contact, said managing the pipeline was key to escaping the sluggish SaaS ramp of death.
Like the funnel concept. To predict how well your business will do, measure how many potential clients are aware of it (awareness) and how many take the next step. If 1,000 people heard about your offering and 10% showed interest, you'd have 100 at that point. If 50% of these people made buyer-like noises, you'd know how many were, etc. It helped model buying trends.
TV, magazine, and radio advertising are pricey for B2C enterprises. Traditional B2B marketing involved armies of sales reps, which was expensive and a barrier to entry.
Cracks in the funnel model
Digital has exposed the funnel's limitations. Hubspot was born at a time when buyers and sellers had huge knowledge asymmetries, according to co-founder Brian Halligan. Those selling a product could use the buyer's lack of information to become a trusted partner.
As the world went digital, getting information and comparing offerings became faster, easier, and cheaper. Buyers didn't need a seller to move through a funnel. Interactions replaced transactions, and the relationship didn't end with a sale.
Instead, buyers and sellers interacted in a constant flow. In many modern models, the sale is midway through the process (particularly true with subscription and software-as-a-service models). Example:
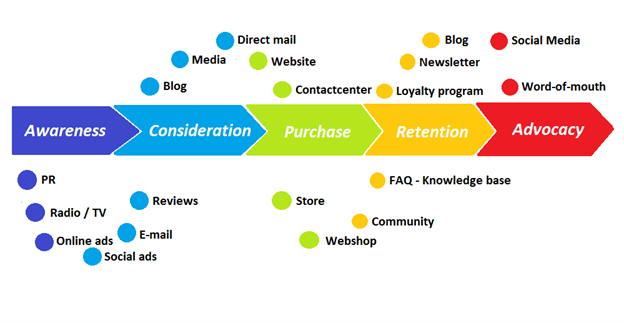
You're creating a winding journey with many touch points, not a funnel (and lots of opportunities for customers to get lost).
From winding journey to flywheel
Beyond this revised view of an interactive customer journey, a company can create what Jim Collins famously called a flywheel. Imagine rolling a heavy disc on its axis. The first few times you roll it, you put in a lot of effort for a small response. The same effort yields faster turns as it gains speed. Over time, the flywheel gains momentum and turns without your help.
Modern digital organizations have created flywheel business models, in which any additional force multiplies throughout the business. The flywheel becomes a force multiplier, according to Collins.
Amazon is a famous flywheel example. Collins explained the concept to Amazon CEO Jeff Bezos at a corporate retreat in 2001. In The Everything Store, Brad Stone describes in his book The Everything Store how he immediately understood Amazon's levers.
The result (drawn on a napkin):
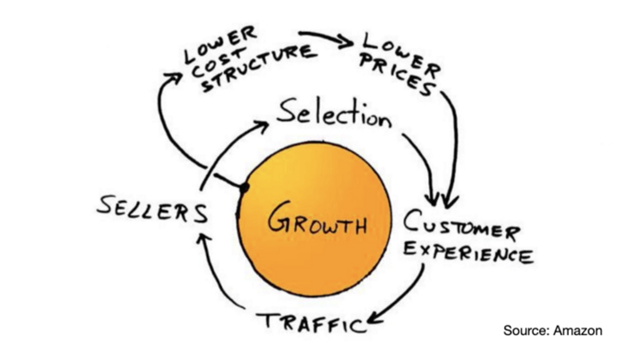
Low prices and a large selection of products attracted customers, while a focus on customer service kept them coming back, increasing traffic. Third-party sellers then increased selection. Low-cost structure supports low-price commitment. It's brilliant! Every wheel turn creates acceleration.
Where from here?
Flywheel over sales funnel! Consider these business terms.

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.