








More on Technology

Farhad Malik
3 years ago
How This Python Script Makes Me Money Every Day
Starting a passive income stream with data science and programming
My website is fresh. But how do I monetize it?
Creating a passive-income website is difficult. Advertise first. But what useful are ads without traffic?
Let’s Generate Traffic And Put Our Programming Skills To Use
SEO boosts traffic (Search Engine Optimisation). Traffic generation is complex. Keywords matter more than text, URL, photos, etc.
My Python skills helped here. I wanted to find relevant, Google-trending keywords (tags) for my topic.
First The Code
I wrote the script below here.
import re
from string import punctuation
import nltk
from nltk import TreebankWordTokenizer, sent_tokenize
from nltk.corpus import stopwords
class KeywordsGenerator:
def __init__(self, pytrends):
self._pytrends = pytrends
def generate_tags(self, file_path, top_words=30):
file_text = self._get_file_contents(file_path)
clean_text = self._remove_noise(file_text)
top_words = self._get_top_words(clean_text, top_words)
suggestions = []
for top_word in top_words:
suggestions.extend(self.get_suggestions(top_word))
suggestions.extend(top_words)
tags = self._clean_tokens(suggestions)
return ",".join(list(set(tags)))
def _remove_noise(self, text):
#1. Convert Text To Lowercase and remove numbers
lower_case_text = str.lower(text)
just_text = re.sub(r'\d+', '', lower_case_text)
#2. Tokenise Paragraphs To words
list = sent_tokenize(just_text)
tokenizer = TreebankWordTokenizer()
tokens = tokenizer.tokenize(just_text)
#3. Clean text
clean = self._clean_tokens(tokens)
return clean
def _clean_tokens(self, tokens):
clean_words = [w for w in tokens if w not in punctuation]
stopwords_to_remove = stopwords.words('english')
clean = [w for w in clean_words if w not in stopwords_to_remove and not w.isnumeric()]
return clean
def get_suggestions(self, keyword):
print(f'Searching pytrends for {keyword}')
result = []
self._pytrends.build_payload([keyword], cat=0, timeframe='today 12-m')
data = self._pytrends.related_queries()[keyword]['top']
if data is None or data.values is None:
return result
result.extend([x[0] for x in data.values.tolist()][:2])
return result
def _get_file_contents(self, file_path):
return open(file_path, "r", encoding='utf-8',errors='ignore').read()
def _get_top_words(self, words, top):
counts = dict()
for word in words:
if word in counts:
counts[word] += 1
else:
counts[word] = 1
return list({k: v for k, v in sorted(counts.items(), key=lambda item: item[1])}.keys())[:top]
if __name__ == "1__main__":
from pytrends.request import TrendReq
nltk.download('punkt')
nltk.download('stopwords')
pytrends = TrendReq(hl='en-GB', tz=360)
tags = KeywordsGenerator(pytrends)\
.generate_tags('text_file.txt')
print(tags)Then The Dependencies
This script requires:
nltk==3.7
pytrends==4.8.0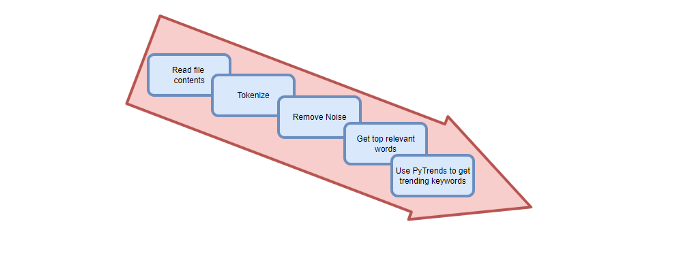
Analysis of the Script
I copy and paste my article into text file.txt, and the code returns the keywords as a comma-separated string.
To achieve this:
A class I made is called KeywordsGenerator.
This class has a function:
generate_tagsThe function
generate_tagsperforms the following tasks:
retrieves text file contents
uses NLP to clean the text by tokenizing sentences into words, removing punctuation, and other elements.
identifies the most frequent words that are relevant.
The
pytrendsAPI is then used to retrieve related phrases that are trending for each word from Google.finally adds a comma to the end of the word list.
4. I then use the keywords and paste them into the SEO area of my website.
These terms are trending on Google and relevant to my topic. My site's rankings and traffic have improved since I added new keywords. This little script puts our knowledge to work. I shared the script in case anyone faces similar issues.
I hope it helps readers sell their work.

Nikhil Vemu
3 years ago
7 Mac Tips You Never Knew You Needed
Unleash the power of the Option key ⌥

#1 Open a link in the Private tab first.
Previously, if I needed to open a Safari link in a private window, I would:
copied the URL with the right click command,
choose File > New Private Window to open a private window, and
clicked return after pasting the URL.
I've found a more straightforward way.
Right-clicking a link shows this, right?
Hold option (⌥) for:
Click Open Link in New Private Window while holding.
Finished!
#2. Instead of searching for specific characters, try this
You may use unicode for business or school. Most people Google them when they need them.
That is lengthy!
You can type some special characters just by pressing ⌥ and a key.
For instance
• ⌥+2 -> ™ (Trademark)
• ⌥+0 -> ° (Degree)
• ⌥+G -> © (Copyright)
• ⌥+= -> ≠ (Not equal to)
• ⌥+< -> ≤ (Less than or equal to)
• ⌥+> -> ≥ (Greater then or equal to)
• ⌥+/ -> ÷ (Different symbol for division)#3 Activate Do Not Disturb silently.
Do Not Disturb when sharing my screen is awkward for me (because people may think Im trying to hide some secret notifications).
Here's another method.
Hold ⌥ and click on Time (at the extreme right on the menu-bar).

Now, DND is activated (secretly!). To turn it off, do it again.
Note: This works only for DND focus.#4. Resize a window starting from its center
Although this is rarely useful, it is still a hidden trick.
When you resize a window, the opposite edge or corner is used as the pivot, right?
However, if you want to resize it with its center as the pivot, hold while doing so.
#5. Yes, Cut-Paste is available on Macs as well (though it is slightly different).
I call it copy-move rather than cut-paste. This is how it works.
Carry it out.
Choose a file (by clicking on it), then copy it (⌘+C).
Go to a new location on your Mac. Do you use ⌘+V to paste it? However, to move it, press ⌘+⌥+V.
This removes the file from its original location and copies it here. And it works exactly like cut-and-paste on Windows.
#6. Instantly expand all folders
Set your Mac's folders to List view.
Assume you have one folder with multiple subfolders, each of which contains multiple files. And you wanted to look at every single file that was over there.
How would you do?
You're used to clicking the ⌄ glyph near the folder and each subfolder to expand them all, right? Instead, hold down ⌥ while clicking ⌄ on the parent folder.
This is what happens next.
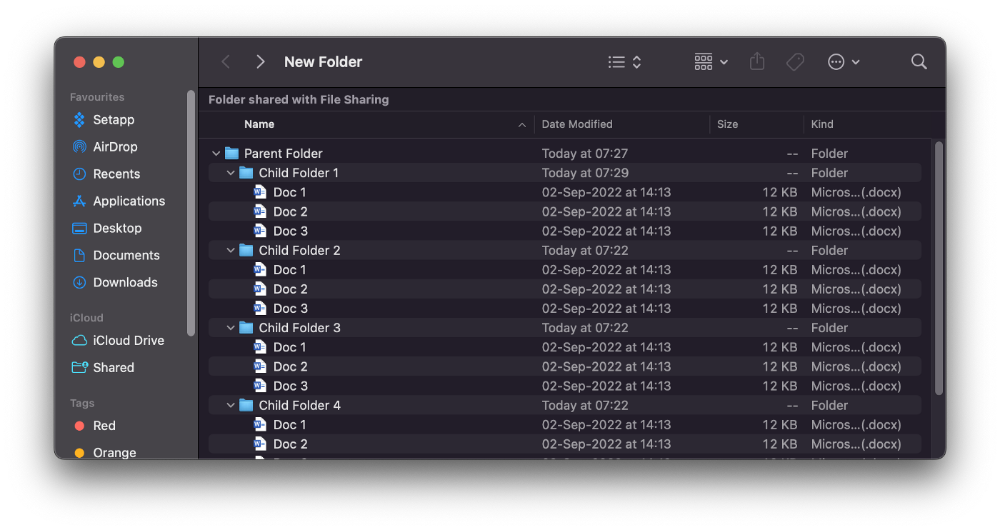
Everything expands.
View/Copy a file's path as an added bonus
If you want to see the path of a file in Finder, select it and hold ⌥, and you'll see it at the bottom for a moment.
To copy its path, right-click on the folder and hold down ⌥ to see this
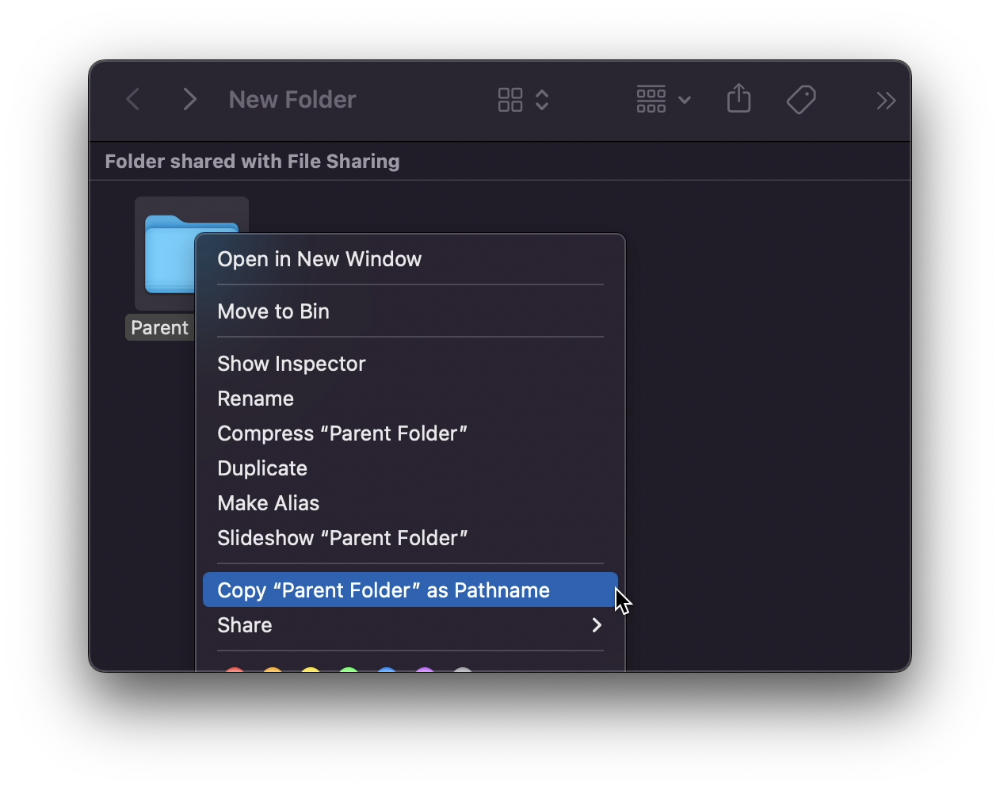
Click on Copy <"folder name"> as Pathname to do it.
#7 "Save As"
I was irritated by the lack of "Save As" in Pages when I first got a Mac (after 15 years of being a Windows guy).
It was necessary for me to save the file as a new file, in a different location, with a different name, or both.
Unfortunately, I couldn't do it on a Mac.
However, I recently discovered that it appears when you hold ⌥ when in the File menu.
Yay!

Will Lockett
3 years ago
The world will be changed by this molten salt battery.

Four times the energy density and a fraction of lithium-cost ion's
As the globe abandons fossil fuels, batteries become more important. EVs, solar, wind, tidal, wave, and even local energy grids will use them. We need a battery revolution since our present batteries are big, expensive, and detrimental to the environment. A recent publication describes a battery that solves these problems. But will it be enough?
Sodium-sulfur molten salt battery. It has existed for a long time and uses molten salt as an electrolyte (read more about molten salt batteries here). These batteries are cheaper, safer, and more environmentally friendly because they use less eco-damaging materials, are non-toxic, and are non-flammable.
Previous molten salt batteries used aluminium-sulphur chemistries, which had a low energy density and required high temperatures to keep the salt liquid. This one uses a revolutionary sodium-sulphur chemistry and a room-temperature-melting salt, making it more useful, affordable, and eco-friendly. To investigate this, researchers constructed a button-cell prototype and tested it.
First, the battery was 1,017 mAh/g. This battery is four times as energy dense as high-density lithium-ion batteries (250 mAh/g).
No one knows how much this battery would cost. A more expensive molten-salt battery costs $15 per kWh. Current lithium-ion batteries cost $132/kWh. If this new molten salt battery costs the same as present cells, it will be 90% cheaper.
This room-temperature molten salt battery could be utilized in an EV. Cold-weather heaters just need a modest backup battery.
The ultimate EV battery? If used in a Tesla Model S, you could install four times the capacity with no weight gain, offering a 1,620-mile range. This huge battery pack would cost less than Tesla's. This battery would nearly perfect EVs.
Or would it?
The battery's capacity declined by 50% after 1,000 charge cycles. This means that our hypothetical Model S would suffer this decline after 1.6 million miles, but for more cheap vehicles that use smaller packs, this would be too short. This test cell wasn't supposed to last long, so this is shocking. Future versions of this cell could be modified to live longer.
This affordable and eco-friendly cell is best employed as a grid-storage battery for renewable energy. Its safety and affordable price outweigh its short lifespan. Because this battery is made of easily accessible materials, it may be utilized to boost grid-storage capacity without causing supply chain concerns or EV battery prices to skyrocket.
Researchers are designing a bigger pouch cell (like those in phones and laptops) for this purpose. The battery revolution we need could be near. Let’s just hope it isn’t too late.
You might also like

Aldric Chen
3 years ago
Jack Dorsey's Meeting Best Practice was something I tried. It Performs Exceptionally Well in Consulting Engagements.

Yes, client meetings are difficult. Especially when I'm alone.
Clients must tell us their problems so we can help.
In-meeting challenges contribute nothing to our work. Consider this:
Clients are unprepared.
Clients are distracted.
Clients are confused.
Introducing Jack Dorsey's Google Doc approach
I endorse his approach to meetings.
Not Google Doc-related. Jack uses it for meetings.
This is what his meetings look like.
Prior to the meeting, the Chair creates the agenda, structure, and information using Google Doc.
Participants in the meeting would have 5-10 minutes to read the Google Doc.
They have 5-10 minutes to type their comments on the document.
In-depth discussion begins
There is elegance in simplicity. Here's how Jack's approach is fantastic.
Unprepared clients are given time to read.
During the meeting, they think and work on it.
They can see real-time remarks from others.
Discussion ensues.
Three months ago, I fell for this strategy. After trying it with a client, I got good results.
I conducted social control experiments in a few client workshops.
Context matters.
I am sure Jack Dorsey’s method works well in meetings. What about client workshops?
So, I tested Enterprise of the Future with a consulting client.
I sent multiple emails to client stakeholders describing the new approach.
No PowerPoints that day. I spent the night setting up the Google Doc with conversation topics, critical thinking questions, and a Before and After section.
The client was shocked. First, a Google Doc was projected. Second surprise was a verbal feedback.
“No pre-meeting materials?”
“Don’t worry. I know you are not reading it before our meeting, anyway.”
We laughed. The experiment started.
Observations throughout a 90-minute engagement workshop from beginning to end
For 10 minutes, the workshop was silent.
People read the Google Doc. For some, the silence was unnerving.
“Are you not going to present anything to us?”
I said everything's in Google Doc. I asked them to read, remark, and add relevant paragraphs.
As they unlocked their laptops, they were annoyed.
Ten client stakeholders are typing on the Google Doc. My laptop displays comment bubbles, red lines, new paragraphs, and strikethroughs.
The first 10 minutes were productive. Everyone has seen and contributed to the document.
I was silent.
The move to a classical workshop was smooth. I didn't stimulate dialogue. They did.
Stephanie asked Joe why a blended workforce hinders company productivity. She questioned his comments and additional paragraphs.
That is when a light bulb hit my head. Yes, you want to speak to the right person to resolve issues!
Not only that was discussed. Others discussed their remark bubbles with neighbors. Debate circles sprung up one after the other.
The best part? I asked everyone to add their post-discussion thoughts on a Google Doc.
After the workshop, I have:
An agreement-based working document
A post-discussion minutes that are prepared for publication
A record of the discussion points that were brought up, argued, and evaluated critically
It showed me how stakeholders viewed their Enterprise of the Future. It allowed me to align with them.
Finale Keynotes
Client meetings are a hit-or-miss. I know that.
Jack Dorsey's meeting strategy works for consulting. It promotes session alignment.
It relieves clients of preparation.
I get the necessary information to advance this consulting engagement.
It is brilliant.

Joseph Mavericks
3 years ago
You Don't Have to Spend $250 on TikTok Ads Because I Did
900K impressions, 8K clicks, and $$$ orders…

I recently started dropshipping. Now that I own my business and can charge it as a business expense, it feels less like money wasted if it doesn't work. I also made t-shirts to sell. I intended to open a t-shirt store and had many designs on a hard drive. I read that Tiktok advertising had a high conversion rate and low cost because they were new. According to many, the advertising' cost/efficiency ratio would plummet and become as bad as Google or Facebook Ads. Now felt like the moment to try Tiktok marketing and dropshipping. I work in marketing for a SaaS firm and have seen how poorly ads perform. I wanted to try it alone.
I set up $250 and ran advertising for a week. Before that, I made my own products, store, and marketing. In this post, I'll show you my process and results.
Setting up the store
Dropshipping is a sort of retail business in which the manufacturer ships the product directly to the client through an online platform maintained by a seller. The seller takes orders but has no stock. The manufacturer handles all orders. This no-stock concept increases profitability and flexibility.
In my situation, I used previous t-shirt designs to make my own product. I didn't want to handle order fulfillment logistics, so I looked for a way to print my designs on demand, ship them, and handle order tracking/returns automatically. So I found Printful.
I needed to connect my backend and supplier to a storefront so visitors could buy. 99% of dropshippers use Shopify, but I didn't want to master the difficult application. I wanted a one-day project. I'd previously worked with Big Cartel, so I chose them.
Big Cartel doesn't collect commissions on sales, simply a monthly flat price ($9.99 to $19.99 depending on your plan).
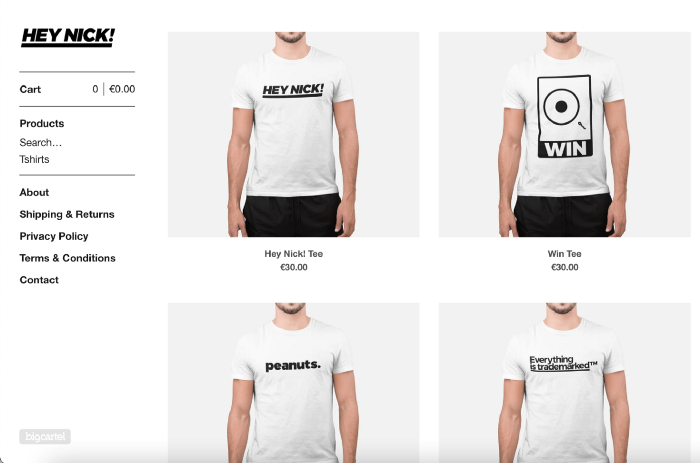
After opening a Big Cartel account, I uploaded 21 designs and product shots, then synced each product with Printful.
Developing the ads
I mocked up my designs on cool people photographs from placeit.net, a great tool for creating product visuals when you don't have a studio, camera gear, or models to wear your t-shirts.
I opened an account on the website and had advertising visuals within 2 hours.
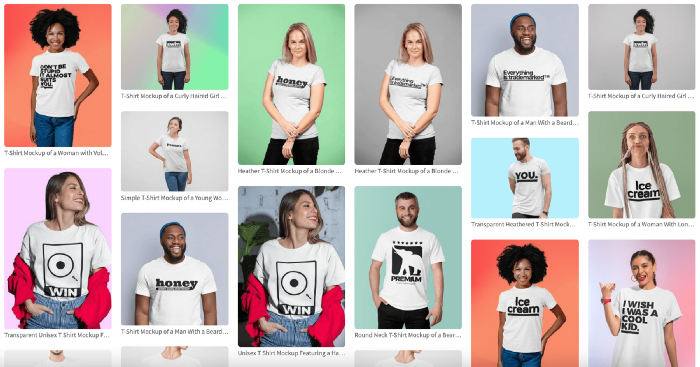
Because my designs are simple (black design on white t-shirt), I chose happy, stylish people on plain-colored backdrops. After that, I had to develop an animated slideshow.
Because I'm a graphic designer, I chose to use Adobe Premiere to create animated Tiktok advertising.
Premiere is a fancy video editing application used for more than advertisements. Premiere is used to edit movies, not social media marketing. I wanted this experiment to be quick, so I got 3 social media ad templates from motionarray.com and threw my visuals in. All the transitions and animations were pre-made in the files, so it only took a few hours to compile. The result:
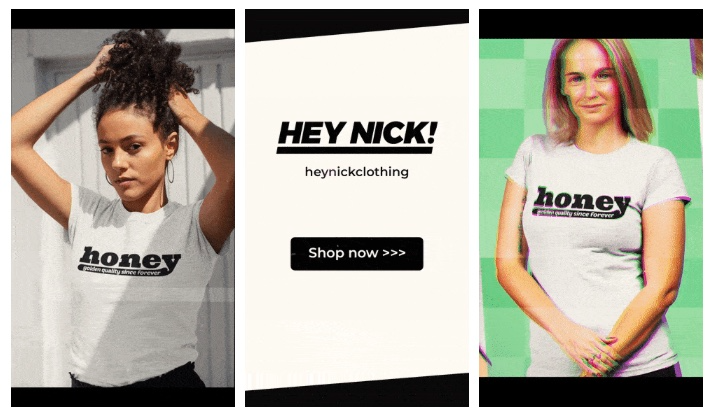
I downloaded 3 different soundtracks for the videos to determine which would convert best.
After that, I opened a Tiktok business account, uploaded my films, and inserted ad info. They went live within one hour.
The (poor) outcomes
As a European company, I couldn't deliver ads in the US. All of my advertisements' material (title, description, and call to action) was in English, hence they continued getting rejected in Europe for countries that didn't speak English. There are a lot of them:
I lost a lot of quality traffic, but I felt that if the images were engaging, people would check out the store and buy my t-shirts. I was wrong.
51,071 impressions on Day 1. 0 orders after 411 clicks
114,053 impressions on Day 2. 1.004 clicks and no orders
Day 3: 987 clicks, 103,685 impressions, and 0 orders
101,437 impressions on Day 4. 0 orders after 963 clicks
115,053 impressions on Day 5. 1,050 clicks and no purchases
125,799 impressions on day 6. 1,184 clicks, no purchases
115,547 impressions on Day 7. 1,050 clicks and no purchases
121,456 impressions on day 8. 1,083 clicks, no purchases
47,586 impressions on Day 9. 419 Clicks. No orders
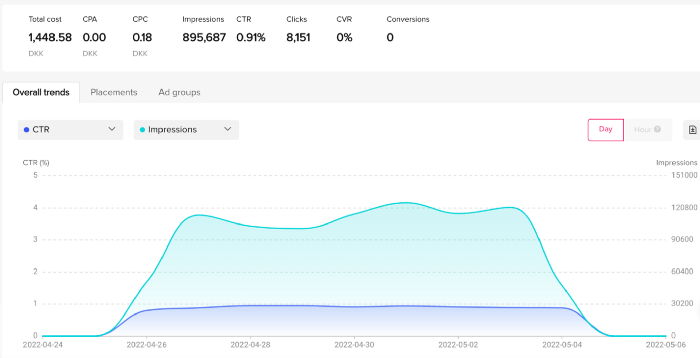
My overall conversion rate for video advertisements was 0.9%. TikTok's paid ad formats all result in strong engagement rates (ads average 3% to 12% CTR to site), therefore a 1 to 2% CTR should have been doable.
My one-week experiment yielded 8,151 ad clicks but no sales. Even if 0.1% of those clicks converted, I should have made 8 sales. Even companies with horrible web marketing would get one download or trial sign-up for every 8,151 clicks. I knew that because my advertising were in English, I had no impressions in the main EU markets (France, Spain, Italy, Germany), and that this impacted my conversion potential. I still couldn't believe my numbers.
I dug into the statistics and found that Tiktok's stats didn't match my store traffic data.
Looking more closely at the numbers
My ads were approved on April 26 but didn't appear until April 27. My store dashboard showed 440 visitors but 1,004 clicks on Tiktok. This happens often while tracking campaign results since different platforms handle comparable user activities (click, view) differently. In online marketing, residual data won't always match across tools.
My data gap was too large. Even if half of the 1,004 persons who clicked closed their browser or left before the store site loaded, I would have gained 502 visitors. The significant difference between Tiktok clicks and Big Cartel store visits made me suspicious. It happened all week:
Day 1: 440 store visits and 1004 ad clicks
Day 2: 482 store visits, 987 ad clicks
3rd day: 963 hits on ads, 452 store visits
443 store visits and 1,050 ad clicks on day 4.
Day 5: 459 store visits and 1,184 ad clicks
Day 6: 430 store visits and 1,050 ad clicks
Day 7: 409 store visits and 1,031 ad clicks
Day 8: 166 store visits and 418 ad clicks
The disparity wasn't related to residual data or data processing. The disparity between visits and clicks looked regular, but I couldn't explain it.
After the campaign concluded, I discovered all my creative assets (the videos) had a 0% CTR and a $0 expenditure in a separate dashboard. Whether it's a dashboard reporting issue or a budget allocation bug, online marketers shouldn't see this.
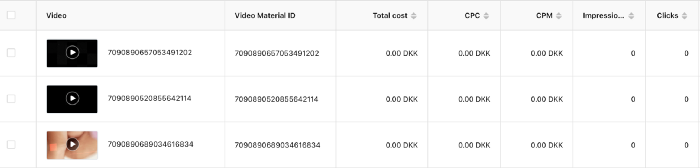
Tiktok can present any stats they want on their dashboard, just like any other platform that runs advertisements to promote content to its users. I can't verify that 895,687 individuals saw and clicked on my ad. I invested $200 for what appears to be around 900K impressions, which is an excellent ROI. No one bought a t-shirt, even an unattractive one, out of 900K people?
Would I do it again?
Nope. Whether I didn't make sales because Tiktok inflated the dashboard numbers or because I'm horrible at producing advertising and items that sell, I’ll stick to writing content and making videos. If setting up a business and ads in a few days was all it took to make money online, everyone would do it.
Video advertisements and dropshipping aren't dead. As long as the internet exists, people will click ads and buy stuff. Converting ads and selling stuff takes a lot of work, and I want to focus on other things.
I had always wanted to try dropshipping and I’m happy I did, I just won’t stick to it because that’s not something I’m interested in getting better at.
If I want to sell t-shirts again, I'll avoid Tiktok advertisements and find another route.

Emma Jade
3 years ago
6 hacks to create content faster
Content gurus' top time-saving hacks.

I'm a content strategist, writer, and graphic designer. Time is more valuable than money.
Money is always available. Even if you're poor. Ways exist.
Time is passing, and one day we'll run out.
Sorry to be morbid.
In today's digital age, you need to optimize how you create content for your organization. Here are six content creation hacks.
1. Use templates
Use templates to streamline your work whether generating video, images, or documents.
Setup can take hours. Using a free resource like Canva, you can create templates for any type of material.
This will save you hours each month.
2. Make a content calendar
You post without a plan? A content calendar solves 50% of these problems.
You can prepare, organize, and plan your material ahead of time so you're not scrambling when you remember, "Shit, it's Mother's Day!"
3. Content Batching
Batching content means creating a lot in one session. This is helpful for video content that requires a lot of setup time.
Batching monthly content saves hours. Time is a valuable resource.
When working on one type of task, it's easy to get into a flow state. This saves time.
4. Write Caption
On social media, we generally choose the image first and then the caption. Writing captions first sometimes work better, though.
Writing the captions first can allow you more creative flexibility and be easier if you're not excellent with language.
Say you want to tell your followers something interesting.
Writing a caption first is easier than choosing an image and then writing a caption to match.
Not everything works. You may have already-created content that needs captioning. When you don't know what to share, think of a concept, write the description, and then produce a video or graphic.
Cats can be skinned in several ways..
5. Repurpose
Reuse content when possible. You don't always require new stuff. In fact, you’re pretty stupid if you do #SorryNotSorry.
Repurpose old content. All those blog entries, videos, and unfinished content on your desk or hard drive.
This blog post can be turned into a social media infographic. Canva's motion graphic function can animate it. I can record a YouTube video regarding this issue for a podcast. I can make a post on each point in this blog post and turn it into an eBook or paid course.
And it doesn’t stop there.
My point is, to think outside the box and really dig deep into ways you can leverage the content you’ve already created.
6. Schedule Them
If you're still manually posting content, get help. When you batch your content, schedule it ahead of time.
Some scheduling apps are free or cheap. No excuses.
Don't publish and ghost.
Scheduling saves time by preventing you from doing it manually. But if you never engage with your audience, the algorithm won't reward your material.
Be online and engage your audience.
Content Machine
Use these six content creation hacks. They help you succeed and save time.