





More on Personal Growth

Alex Mathers
3 years ago Draft
12 practices of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have learned to laugh at themselves.
Those who have something to protect can’t help but make it a very serious business, which drains the energy out of the room.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Hold your breath, please.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are attuned to their personal dietary needs.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.

Jari Roomer
3 years ago
After 240 articles and 2.5M views on Medium, 9 Raw Writing Tips
Late in 2018, I published my first Medium article, but I didn't start writing seriously until 2019. Since then, I've written more than 240 articles, earned over $50,000 through Medium's Partner Program, and had over 2.5 million page views.
Write A Lot
Most people don't have the patience and persistence for this simple writing secret:
Write + Write + Write = possible success
Writing more improves your skills.
The more articles you publish, the more likely one will go viral.
If you only publish once a month, you have no views. If you publish 10 or 20 articles a month, your success odds increase 10- or 20-fold.
Tim Denning, Ayodeji Awosika, Megan Holstein, and Zulie Rane. Medium is their jam. How are these authors alike? They're productive and consistent. They're prolific.
80% is publishable
Many writers battle perfectionism.
To succeed as a writer, you must publish often. You'll never publish if you aim for perfection.
Adopt the 80 percent-is-good-enough mindset to publish more. It sounds terrible, but it'll boost your writing success.
Your work won't be perfect. Always improve. Waiting for perfection before publishing will take a long time.
Second, readers are your true critics, not you. What you consider "not perfect" may be life-changing for the reader. Don't let perfectionism hinder the reader.
Don't let perfectionism hinder the reader. ou don't want to publish mediocre articles. When the article is 80% done, publish it. Don't spend hours editing. Realize it. Get feedback. Only this will work.
Make Your Headline Irresistible
We all judge books by their covers, despite the saying. And headlines. Readers, including yourself, judge articles by their titles. We use it to decide if an article is worth reading.
Make your headlines irresistible. Want more article views? Then, whether you like it or not, write an attractive article title.
Many high-quality articles are collecting dust because of dull, vague headlines. It didn't make the reader click.
As a writer, you must do more than produce quality content. You must also make people click on your article. This is a writer's job. How to create irresistible headlines:
Curiosity makes readers click. Here's a tempting example...
Example: What Women Actually Look For in a Guy, According to a Huge Study by Luba Sigaud
Use Numbers: Click-bait lists. I mean, which article would you click first? ‘Some ways to improve your productivity’ or ’17 ways to improve your productivity.’ Which would I click?
Example: 9 Uncomfortable Truths You Should Accept Early in Life by Sinem Günel
Most headlines are dull. If you want clicks, get 'sexy'. Buzzword-ify. Invoke emotion. Trendy words.
Example: 20 Realistic Micro-Habits To Live Better Every Day by Amardeep Parmar
Concise paragraphs
Our culture lacks focus. If your headline gets a click, keep paragraphs short to keep readers' attention.
Some writers use 6–8 lines per paragraph, but I prefer 3–4. Longer paragraphs lose readers' interest.
A writer should help the reader finish an article, in my opinion. I consider it a job requirement. You can't force readers to finish an article, but you can make it 'snackable'
Help readers finish an article with concise paragraphs, interesting subheadings, exciting images, clever formatting, or bold attention grabbers.
Work And Move On
I've learned over the years not to get too attached to my articles. Many writers report a strange phenomenon:
The articles you're most excited about usually bomb, while the ones you're not tend to do well.
This isn't always true, but I've noticed it in my own writing. My hopes for an article usually make it worse. The more objective I am, the better an article does.
Let go of a finished article. 40 or 40,000 views, whatever. Now let the article do its job. Onward. Next story. Start another project.
Disregard Haters
Online content creators will encounter haters, whether on YouTube, Instagram, or Medium. More views equal more haters. Fun, right?
As a web content creator, I learned:
Don't debate haters. Never.
It's a mistake I've made several times. It's tempting to prove haters wrong, but they'll always find a way to be 'right'. Your response is their fuel.
I smile and ignore hateful comments. I'm indifferent. I won't enter a negative environment. I have goals, money, and a life to build. "I'm not paid to argue," Drake once said.
Use Grammarly
Grammarly saves me as a non-native English speaker. You know Grammarly. It shows writing errors and makes article suggestions.
As a writer, you need Grammarly. I have a paid plan, but their free version works. It improved my writing greatly.
Put The Reader First, Not Yourself
Many writers write for themselves. They focus on themselves rather than the reader.
Ask yourself:
This article teaches what? How can they be entertained or educated?
Personal examples and experiences improve writing quality. Don't focus on yourself.
It's not about you, the content creator. Reader-focused. Putting the reader first will change things.
Extreme ownership: Stop blaming others
I remember writing a lot on Medium but not getting many views. I blamed Medium first. Poor algorithm. Poor publishing. All sucked.
Instead of looking at what I could do better, I blamed others.
When you blame others, you lose power. Owning your results gives you power.
As a content creator, you must take full responsibility. Extreme ownership means 100% responsibility for work and results.
You don’t blame others. You don't blame the economy, president, platform, founders, or audience. Instead, you look for ways to improve. Few people can do this.
Blaming is useless. Zero. Taking ownership of your work and results will help you progress. It makes you smarter, better, and stronger.
Instead of blaming others, you'll learn writing, marketing, copywriting, content creation, productivity, and other skills. Game-changer.

James White
3 years ago
Ray Dalio suggests reading these three books in 2022.
An inspiring reading list

I'm no billionaire or hedge-fund manager. My bank account doesn't have millions. Ray Dalio's love of reading motivates me to think differently.
Here are some books recommended by Ray Dalio. Each influenced me. Hope they'll help you.
Sapiens by Yuval Noah Harari
Page Count: 512
Rating on Goodreads: 4.39
My favorite nonfiction book.
Sapiens explores human evolution. It explains how Homo Sapiens developed from hunter-gatherers to a dominant species. Amazing!
Sapiens will teach you about human history. Yuval Noah Harari has a follow-up book on human evolution.

My favorite book quotes are:
The tendency for luxuries to turn into necessities and give rise to new obligations is one of history's few unbreakable laws.
Happiness is not dependent on material wealth, physical health, or even community. Instead, it depends on how closely subjective expectations and objective circumstances align.
The romantic comparison between today's industry, which obliterates the environment, and our forefathers, who coexisted well with nature, is unfounded. Homo sapiens held the record among all organisms for eradicating the most plant and animal species even before the Industrial Revolution. The unfortunate distinction of being the most lethal species in the history of life belongs to us.
The Power Of Habit by Charles Duhigg
Page Count: 375
Rating on Goodreads: 4.13
Great book: The Power Of Habit. It illustrates why habits are everything. The book explains how healthier habits can improve your life, career, and society.
The Power of Habit rocks. It's a great book on productivity. Its suggestions helped me build healthier behaviors (and drop bad ones).
Read ASAP!

My favorite book quotes are:
Change may not occur quickly or without difficulty. However, almost any behavior may be changed with enough time and effort.
People who exercise begin to eat better and produce more at work. They are less smokers and are more patient with friends and family. They claim to feel less anxious and use their credit cards less frequently. A fundamental habit that sparks broad change is exercise.
Habits are strong but also delicate. They may develop independently of our awareness or may be purposefully created. They frequently happen without our consent, but they can be altered by changing their constituent pieces. They have a much greater influence on how we live than we realize; in fact, they are so powerful that they cause our brains to adhere to them above all else, including common sense.
Tribe Of Mentors by Tim Ferriss
Page Count: 561
Rating on Goodreads: 4.06
Unusual book structure. It's worth reading if you want to learn from successful people.
The book is Q&A-style. Tim questions everyone. Each chapter features a different person's life-changing advice. In the book, Pressfield, Willink, Grylls, and Ravikant are interviewed.
Amazing!

My favorite book quotes are:
According to one's courage, life can either get smaller or bigger.
Don't engage in actions that you are aware are immoral. The reputation you have with yourself is all that constitutes self-esteem. Always be aware.
People mistakenly believe that focusing means accepting the task at hand. However, that is in no way what it represents. It entails rejecting the numerous other worthwhile suggestions that exist. You must choose wisely. Actually, I'm just as proud of the things we haven't accomplished as I am of what I have. Saying no to 1,000 things is what innovation is.
You might also like

caroline sinders
3 years ago
Holographic concerts are the AI of the Future.

A few days ago, I was discussing dall-e with two art and tech pals. One artist acquaintance said she knew a frightened illustrator. Would the ability to create anything with a click derail her career? The artist feared this. My curator friend smiled and said this has always been a dread among artists. When the camera was invented, didn't painters say this? Even in the Instagram era, painting exists.
When art and technology collide, there's room for innovation, experimentation, and fear — especially if the technology replicates or replaces art making. What is art's future with dall-e? How does technology affect music, beyond visual art? Recently, I saw "ABBA Voyage," a holographic ABBA concert in London.
"Abba voyage?" my phone asked in early March. A Gen X friend I met through a fashion blogging ring texted me.
"What's abba Voyage?" I asked while opening my front door with keys and coffee.
We're going! Marti, visiting London, took me to a show.
"Absolutely no ABBA songs here." I responded.
My parents didn't play ABBA much, so I don't know much about them. Dad liked Jimi Hendrix, Cream, Deep Purple, and New Orleans jazz. Marti told me ABBA Voyage was a holographic ABBA show with a live band.
The show was fun, extraordinary fun. Nearly everyone on the dance floor wore wigs, ankle-breaking platforms, sequins, and bellbottoms. I saw some millennials and Zoomers among the boomers.
I was intoxicated by the experience.
Automatons date back to the 18th-century mechanical turk. The mechanical turk was a chess automaton operated by a person. The mechanical turk seemed to perform like a human without human intervention, but it required a human in the loop to work properly.
Humans have used non-humans in entertainment for centuries, such as puppets, shadow play, and smoke and mirrors. A show can have animatronic, technological, and non-technological elements, and a live show can blur real and illusion. From medieval puppet shows to mechanical turks to AI filters, bots, and holograms, entertainment has evolved over time.
I'm not a hologram skeptic, but I'm skeptical of technology, especially since I work with it. I love live performances, I love hearing singers breathe, forget lines, and make jokes. Live shows are my favorite because I love watching performers make mistakes or interact with the audience. ABBA Voyage was different.
Marti and I traveled to Manchester after ABBA Voyage to see Liam Gallagher. Similar but different vibe. Similar in that thousands dressed up for the show. ABBA's energy was dizzying. 90s chic replaced sequins in the crowd. Doc Martens, nylon jackets, bucket hats, shaggy hair. The Charlatans and Liam Gallagher opened and closed, respectively. Fireworks. Incredible. People went crazy. Yelling exhausted my voice.
This week in music featured AI-enabled holograms and a decades-old rocker. Both are warm and gooey in our memories.
After seeing both, I'm wondering if we need AI hologram shows. Why? Is it good?
Like everything tech-related, my answer is "maybe." Because context and performance matter. Liam Gallagher and ABBA both had great, different shows.
For a hologram to work, it must be impossible and big. It must be big, showy, and improbable to justify a hologram. It must feel...expensive, like a stadium pop show. According to a quick search, ABBA broke up on bad terms. Reuniting is unlikely. This is also why Prince or Tupac hologram shows work. We can only engage with their legacy through covers or...holograms.
I drove around listening to the radio a few weeks ago. "Dreaming of You" by Selena played. Selena's music defined my childhood. I sang along and turned up the volume (or as loud as my husband would allow me while driving on the highway).
I discovered Selena's music six months after her death, so I never saw her perform live. My babysitter Melissa played me her album after I moved to Houston. Melissa took me to see the Selena movie five times when it came out. I quickly wore out my VHS copy. I constantly sang "Bibi Bibi Bom Bom" and "Como la Flor." I love Selena. A Selena hologram? Yes, probably.
Instagram advertised a cellist's Arthur Russell tribute show. Russell is another deceased artist I love. I almost walked down the aisle to "This is How We Walk on the Moon," but our cellist couldn't find it. Instead, I walked to Magnetic Fields' "The Book of Love." I "discovered" Russell after a friend introduced me to his music a few years ago.
I use these as analogies for the Liam Gallagher and ABBA concerts.
You have no idea how much I'd pay to see a hologram of Selena's 1995 Houston Livestock Show and Rodeo concert. Arthur Russell's hologram is unnecessary. Russell's work was intimate and performance-based. We can't separate his life from his legacy; popular audiences overlooked his genius. He died of AIDS broke. Like Selena, he died prematurely. Given his music and history, another performer would be a better choice than a hologram. He's no Selena. Selena could have rivaled Beyonce.
Pop shows' size works for holograms. Along with ABBA holograms, there was an anime movie and a light show that would put Tron to shame. ABBA created a tourable stadium show. The event was lavish, expensive, and well-planned. Pop, unlike rock, isn't gritty. Liam Gallagher hologram? No longer impossible, it wouldn't work. He's touring. I'm not sure if a rockstar alone should be rendered as a hologram; it was the show that made ABBA a hologram.
Holograms, like AI, are part of the future of entertainment, but not all of it. Because only modern interpretations of Arthur Russell's work reveal his legacy. That's his legacy.

Large-scale arena performers may use holograms in the future, but the experience must be impossible. A teacher once said that the only way to convey emotion in opera is through song, and I feel the same way about holograms, AR, VR, and mixed reality. A story's impossibility must make sense, like in opera. Impossibility and bombastic performance must be present for an immersive element to "work." ABBA was an impossible and improbable experience, which made it magical. It helped the holographic show work.
Marti told me about ABBA Voyage. She said it was a great concert. Marti has worked in music since the 1990s. She's a music expert; she's seen many shows.
Ai isn't a god or sentient, and the ABBA holograms aren't real. The renderings were glassy-eyed, flat, and robotic, like the Polar Express or the Jaws shark. Even today, the uncanny valley is insurmountable. We know it's not real because it's not about reality. It was about a suspended moment and performance feelings.
I knew this was impossible, an 'unreal' experience, but the emotions I felt were real, like watching a movie or tv show. Perhaps this is one of the better uses of AI, like CGI and special effects, like the beauty of entertainment- we were enraptured and entertained for hours. I've been playing ABBA since then.

Caspar Mahoney
3 years ago
Changing Your Mindset From a Project to a Product
Product game mindsets? How do these vary from Project mindset?
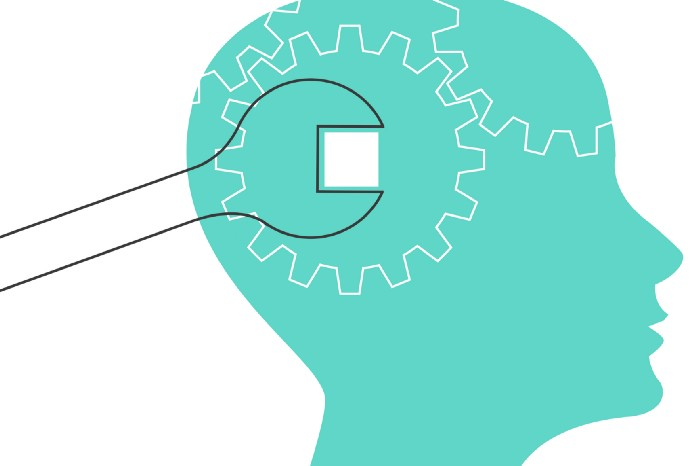
1950s spawned the Iron Triangle. Project people everywhere know and live by it. In stakeholder meetings, it is used to stretch the timeframe, request additional money, or reduce scope.
Quality was added to this triangle as things matured.
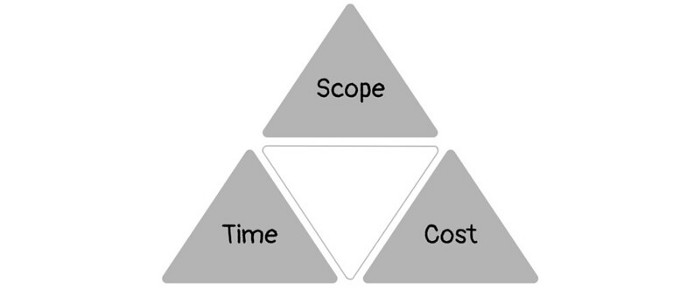
Quality was intended to be transformative, but none of these principles addressed why we conduct projects.
Value and benefits are key.
Product value is quantified by ROI, revenue, profit, savings, or other metrics. For me, every project or product delivery is about value.
Most project managers, especially those schooled 5-10 years or more ago (thousands working in huge corporations worldwide), understand the world in terms of the iron triangle. What does that imply? They worry about:
a) enough time to get the thing done.
b) have enough resources (budget) to get the thing done.
c) have enough scope to fit within (a) and (b) >> note, they never have too little scope, not that I have ever seen! although, theoretically, this could happen.
Boom—iron triangle.
To make the triangle function, project managers will utilize formal governance (Steering) to move those things. Increase money, scope, or both if time is short. Lacking funds? Increase time, scope, or both.
In current product development, shifting each item considerably may not yield value/benefit.
Even terrible. This approach will fail because it deprioritizes Value/Benefit by focusing the major stakeholders (Steering participants) and delivery team(s) on Time, Scope, and Budget restrictions.
Pre-agile, this problem was terrible. IT projects failed wildly. History is here.
Value, or benefit, is central to the product method. Product managers spend most of their time planning value-delivery paths.
Product people consider risk, schedules, scope, and budget, but value comes first. Let me illustrate.
Imagine managing internal products in an enterprise. Your core customer team needs a rapid text record of a chat to fix a problem. The consumer wants a feature/features added to a product you're producing because they think it's the greatest spot.
Project-minded, I may say;
Ok, I have budget as this is an existing project, due to run for a year. This is a new requirement to add to the features we’re already building. I think I can keep the deadline, and include this scope, as it sounds related to the feature set we’re building to give the desired result”.
This attitude repeats Scope, Time, and Budget.
Since it meets those standards, a project manager will likely approve it. If they have a backlog, they may add it and start specking it out assuming it will be built.
Instead, think like a product;
What problem does this feature idea solve? Is that problem relevant to the product I am building? Can that problem be solved quicker/better via another route ? Is it the most valuable problem to solve now? Is the problem space aligned to our current or future strategy? or do I need to alter/update the strategy?
A product mindset allows you to focus on timing, resource/cost, feasibility, feature detail, and so on after answering the aforementioned questions.
The above oversimplifies because
Leadership in discovery

Project managers are facilitators of ideas. This is as far as they normally go in the ‘idea’ space.
Business Requirements collection in classic project delivery requires extensive upfront documentation.
Agile project delivery analyzes requirements iteratively.
However, the project manager is a facilitator/planner first and foremost, therefore topic knowledge is not expected.
I mean business domain, not technical domain (to confuse matters, it is true that in some instances, it can be both technical and business domains that are important for a single individual to master).
Product managers are domain experts. They will become one if they are training/new.
They lead discovery.
Product Manager-led discovery is much more than requirements gathering.
Requirements gathering involves a Business Analyst interviewing people and documenting their requests.
The project manager calculates what fits and what doesn't using their Iron Triangle (presumably in their head) and reports back to Steering.
If this requirements-gathering exercise failed to identify requirements, what would a project manager do? or bewildered by project requirements and scope?
They would tell Steering they need a Business SME or Business Lead assigning or more of their time.
Product discovery requires the Product Manager's subject knowledge and a new mindset.
How should a Product Manager handle confusing requirements?
Product Managers handle these challenges with their talents and tools. They use their own knowledge to fill in ambiguity, but they have the discipline to validate those assumptions.
To define the problem, they may perform qualitative or quantitative primary research.
They might discuss with UX and Engineering on a whiteboard and test assumptions or hypotheses.
Do Product Managers escalate confusing requirements to Steering/Senior leaders? They would fix that themselves.
Product managers raise unclear strategy and outcomes to senior stakeholders. Open talks, soft skills, and data help them do this. They rarely raise requirements since they have their own means of handling them without top stakeholder participation.
Discovery is greenfield, exploratory, research-based, and needs higher-order stakeholder management, user research, and UX expertise.
Product Managers also aid discovery. They lead discovery. They will not leave customer/user engagement to a Business Analyst. Administratively, a business analyst could aid. In fact, many product organizations discourage business analysts (rely on PM, UX, and engineer involvement with end-users instead).
The Product Manager must drive user interaction, research, ideation, and problem analysis, therefore a Product professional must be skilled and confident.
Creating vs. receiving and having an entrepreneurial attitude

Product novices and project managers focus on details rather than the big picture. Project managers prefer spreadsheets to strategy whiteboards and vision statements.
These folks ask their manager or senior stakeholders, "What should we do?"
They then elaborate (in Jira, in XLS, in Confluence or whatever).
They want that plan populated fast because it reduces uncertainty about what's going on and who's supposed to do what.
Skilled Product Managers don't only ask folks Should we?
They're suggesting this, or worse, Senior stakeholders, here are some options. After asking and researching, they determine what value this product adds, what problems it solves, and what behavior it changes.
Therefore, to move into Product, you need to broaden your view and have courage in your ability to discover ideas, find insightful pieces of information, and collate them to form a valuable plan of action. You are constantly defining RoI and building Business Cases, so much so that you no longer create documents called Business Cases, it is simply ingrained in your work through metrics, intelligence, and insights.
Product Management is not a free lunch.
Plateless.
Plates and food must be prepared.
In conclusion, Product Managers must make at least three mentality shifts:
You put value first in all things. Time, money, and scope are not as important as knowing what is valuable.
You have faith in the field and have the ability to direct the search. YYou facilitate, but you don’t just facilitate. You wouldn't want to limit your domain expertise in that manner.
You develop concepts, strategies, and vision. You are not a waiter or an inbox where other people can post suggestions; you don't merely ask folks for opinion and record it. However, you excel at giving things that aren't clearly spoken or written down physical form.

Jeff John Roberts
3 years ago
Jack Dorsey and Jay-Z Launch 'Bitcoin Academy' in Brooklyn rapper's home
The new Bitcoin Academy will teach Jay-Marcy Z's Houses neighbors "What is Cryptocurrency."
Jay-Z grew up in Brooklyn's Marcy Houses. The rapper and Block CEO Jack Dorsey are giving back to his hometown by creating the Bitcoin Academy.
The Bitcoin Academy will offer online and in-person classes, including "What is Money?" and "What is Blockchain?"
The program will provide participants with a mobile hotspot and a small amount of Bitcoin for hands-on learning.
Students will receive dinner and two evenings of instruction until early September. The Shawn Carter Foundation will help with on-the-ground instruction.
Jay-Z and Dorsey announced the program Thursday morning. It will begin at Marcy Houses but may be expanded.
Crypto Blockchain Plug and Black Bitcoin Billionaire, which has received a grant from Block, will teach the classes.
Jay-Z, Dorsey reunite
Jay-Z and Dorsey have previously worked together to promote a Bitcoin and crypto-based future.
In 2021, Dorsey's Block (then Square) acquired the rapper's streaming music service Tidal, which they propose using for NFT distribution.
Dorsey and Jay-Z launched an endowment in 2021 to fund Bitcoin development in Africa and India.
Dorsey is funding the new Bitcoin Academy out of his own pocket (as is Jay-Z), but he's also pushed crypto-related charitable endeavors at Block, including a $5 million fund backed by corporate Bitcoin interest.
This post is a summary. Read full article here