

More on Leadership

Alison Randel
1 month ago
Raising the Bar on Your 1:1s

Managers spend much time in 1:1s. Most team members meet with supervisors regularly. 1:1s can help create relationships and tackle tough topics. Few appreciate the 1:1 format's potential. Most of the time, that potential is spent on small talk, surface-level updates, and ranting (Ugh, the marketing team isn’t stepping up the way I want them to).
What if you used that time to have deeper conversations and important insights? What if change was easy?
This post introduces a new 1:1 format to help you dive deeper, faster, and develop genuine relationships without losing impact.
A 1:1 is a chat, you would assume. Why use structure to talk to a coworker? Go! I know how to talk to people. I can write. I've always written. Also, This article was edited by Zoe.
Before you discard something, ask yourself if there's a good reason not to try anything new. Is the 1:1 only a talk, or do you want extra benefits? Try the steps below to discover more.
I. Reflection (5 minutes)
Context-free, broad comments waste time and are useless. Instead, give team members 5 minutes to write these 3 prompts.
What's effective?
What is decent but could be improved?
What is broken or missing?
Why these? They encourage people to be honest about all their experiences. Answering these questions helps people realize something isn't working. These prompts let people consider what's working.
Why take notes? Because you get more in less time. Will you feel awkward sitting quietly while your coworker writes? Probably. Persevere. Multi-task. Take a break from your afternoon meeting marathon. Any awkwardness will pay off.
What happens? After a few minutes of light conversation, create a template like the one given here and have team members fill in their replies. You can pre-share the template (with the caveat that this isn’t meant to take much prep time). Do this with your coworker: Answer the prompts. Everyone can benefit from pondering and obtaining guidance.
This step's output.

Part II: Talk (10-20 minutes)
Most individuals can explain what they see but not what's behind an answer. You don't like a meeting. Why not? Marketing partnership is difficult. What makes working with them difficult? I don't recommend slandering coworkers. Consider how your meetings, decisions, and priorities make work harder. The excellent stuff too. You want to know what's humming so you can reproduce the magic.
First, recognize some facts.
Real power dynamics exist. To encourage individuals to be honest, you must provide a safe environment and extend clear invites. Even then, it may take a few 1:1s for someone to feel secure enough to go there in person. It is part of your responsibility to admit that it is normal.
Curiosity and self-disclosure are crucial. Most leaders have received training to present themselves as the authorities. However, you will both benefit more from the dialogue if you can be open and honest about your personal experience, ask questions out of real curiosity, and acknowledge the pertinent sacrifices you're making as a leader.
Honesty without bias is difficult and important. Due to concern for the feelings of others, people frequently hold back. Or if they do point anything out, they do so in a critical manner. The key is to be open and unapologetic about what you observe while not presuming that your viewpoint is correct and that of the other person is incorrect.
Let's go into some prompts (based on genuine conversations):
“What do you notice across your answers?”
“What about the way you/we/they do X, Y, or Z is working well?”
“ Will you say more about item X in ‘What’s not working?’”
“I’m surprised there isn’t anything about Z. Why is that?”
“All of us tend to play some role in maintaining certain patterns. How might you/we be playing a role in this pattern persisting?”
“How might the way we meet, make decisions, or collaborate play a role in what’s currently happening?”
Consider the preceding example. What about the Monday meeting isn't working? Why? or What about the way we work with marketing makes collaboration harder? Remember to share your honest observations!
Third section: observe patterns (10-15 minutes)
Leaders desire to empower their people but don't know how. We also have many preconceptions about what empowerment means to us and how it works. The next phase in this 1:1 format will assist you and your team member comprehend team power and empowerment. This understanding can help you support and shift your team member's behavior, especially where you disagree.
How to? After discussing the stated responses, ask each team member what they can control, influence, and not control. Mark their replies. You can do the same, adding colors where you disagree.
This step's output.

Next, consider the color constellation. Discuss these questions:
Is one color much more prevalent than the other? Why, if so?
Are the colors for the "what's working," "what's fine," and "what's not working" categories clearly distinct? Why, if so?
Do you have any disagreements? If yes, specifically where does your viewpoint differ? What activities do you object to? (Remember, there is no right or wrong in this. Give explicit details and ask questions with curiosity.)
Example: Based on the colors, you can ask, Is the marketing meeting's quality beyond your control? Were our marketing partners consulted? Are there any parts of team decisions we can control? We can't control people, but have we explored another decision-making method? How can we collaborate and generate governance-related information to reduce work, even if the requirement for prep can't be eliminated?
Consider the top one or two topics for this conversation. No 1:1 can cover everything, and that's OK. Focus on the present.
Part IV: Determine the next step (5 minutes)
Last, examine what this conversation means for you and your team member. It's easy to think we know the next moves when we don't.
Like what? You and your teammate answer these questions.
What does this signify moving ahead for me? What can I do to change this? Make requests, for instance, and see how people respond before thinking they won't be responsive.
What demands do I have on other people or my partners? What should I do first? E.g. Make a suggestion to marketing that we hold a monthly retrospective so we can address problems and exchange input more frequently. Include it on the meeting's agenda for next Monday.
Close the 1:1 by sharing what you noticed about the chat. Observations? Learn anything?
Yourself, you, and the 1:1
As a leader, you either reinforce or disrupt habits. Try this template if you desire greater ownership, empowerment, or creativity. Consider how you affect surrounding dynamics. How can you expect others to try something new in high-stakes scenarios, like meetings with cross-functional partners or senior stakeholders, if you won't? How can you expect deep thought and relationship if you don't encourage it in 1:1s? What pattern could this new format disrupt or reinforce?
Fight reluctance. First attempts won't be ideal, and that's OK. You'll only learn by trying.

Christian Soschner
3 months ago
Steve Jobs' Secrets Revealed
From 1984 until 2011, he ran Apple using the same template.

What is a founder CEO's most crucial skill?
Presentation, communication, and sales
As a Business Angel Investor, I saw many pitch presentations and met with investors one-on-one to promote my companies.
There is always the conception of “Investors have to invest,” so there is no need to care about the presentation.
It's false. Nobody must invest. Many investors believe that entrepreneurs must convince them to invest in their business.
Sometimes — like in 2018–2022 — too much money enters the market, and everyone makes good money.
Do you recall the Buy Now, Pay Later Movement? This amazing narrative had no return potential. Only buyers who couldn't acquire financing elsewhere shopped at these companies.
Klarna's failing business concept led to high valuations.
Investors become more cautious when the economy falters. 2022 sees rising inflation, interest rates, wars, and civil instability. It's like the apocalypse's four horsemen have arrived.
Storytelling is important in rough economies.
When investors draw back, how can entrepreneurs stand out?
In Q2/2022, every study I've read said:
Investors cease investing
Deals are down in almost all IT industries from previous quarters.
What do founders need to do?
Differentiate yourself.
Storytelling talents help.
The Steve Jobs Way
Every time I watch a Steve Jobs presentation, I'm enthralled.
I'm a techie. Everything technical interests me. But, I skim most presentations.
What's Steve Jobs's secret?
Steve Jobs created Apple in 1976 and made it a profitable software and hardware firm in the 1980s. Macintosh goods couldn't beat IBM's. This mistake sacked him in 1985.
Before rejoining Apple in 1997, Steve Jobs founded Next Inc. and Pixar.
From then on, Apple became America's most valuable firm.
Steve Jobs understood people's needs. He said:
“People don’t know what they want until you show it to them. That’s why I never rely on market research. Our task is to read things that are not yet on the page.”
In his opinion, people talk about problems. A lot. Entrepreneurs must learn what the population's pressing problems are and create a solution.
Steve Jobs showed people what they needed before they realized it.
I'll explain:
Present a Big Vision
Steve Jobs starts every presentation by describing his long-term goals for Apple.
1984's Macintosh presentation set up David vs. Goliath. In a George Orwell-style dystopia, IBM computers were bad. It was 1984.
Apple will save the world, like Jedis.
Why do customers and investors like Big Vision?
People want a wider perspective, I think. Humans love improving the planet.
Apple users often cite emotional reasons for buying the brand.
Revolutionizing several industries with breakthrough inventions
Establish Authority
Everyone knows Apple in 2022. It's hard to find folks who confuse Apple with an apple around the world.
Apple wasn't as famous as it is today until Steve Jobs left in 2011.
Most entrepreneurs lack experience. They may market their company or items to folks who haven't heard of it.
Steve Jobs presented the company's historical accomplishments to overcome opposition.
In his presentation of the first iPhone, he talked about the Apple Macintosh, which altered the computing sector, and the iPod, which changed the music industry.
People who have never heard of Apple feel like they're seeing a winner. It raises expectations that the new product will be game-changing and must-have.
The Big Reveal
A pitch or product presentation always has something new.
Steve Jobs doesn't only demonstrate the product. I don't think he'd skip the major point of a company presentation.
He consistently discusses present market solutions, their faults, and a better consumer solution.
No solution exists yet.
It's a multi-faceted play:
It's comparing the new product to something familiar. This makes novelty and the product more relatable.
Describe a desirable solution.
He's funny. He demonstrated an iPod with an 80s phone dial in his iPhone presentation.
Then he reveals the new product. Macintosh presented itself.
Show the benefits
He outlines what Apple is doing differently after demonstrating the product.
How do you distinguish from others? The Big Breakthrough Presentation.
A few hundred slides might list all benefits.
Everyone would fall asleep. Have you ever had similar presentations?
When the brain is overloaded with knowledge, the limbic system changes to other duties, like lunch planning.
What should a speaker do? There's a classic proverb:
“Tell me and I forget, teach me and I may remember, involve me and I learn” (— Not Benjamin Franklin).
Steve Jobs showcased the product live.
Again, using ordinary scenarios to highlight the product's benefits makes it relatable.
The 2010 iPad Presentation uses this technique.
Invite the Team and Let Them Run the Presentation
CEOs spend most time outside the organization. Many companies elect to have only one presenter.
It sends the incorrect message to investors. Product presentations should always include the whole team.
Let me explain why.
Companies needing investment money frequently have shaky business strategies or no product-market fit or robust corporate structure.
Investors solely bet on a team's ability to implement ideas and make a profit.
Early team involvement helps investors understand the company's drivers. Travel costs are worthwhile.
But why for product presentations?
Presenters of varied ages, genders, social backgrounds, and skillsets are relatable. CEOs want relatable products.
Some customers may not believe a white man's message. A black woman's message may be more accepted.
Make the story relatable when you have the best product that solves people's concerns.
Best example: 1984 Macintosh presentation with development team panel.
What is the largest error people make when companies fail?
Saving money on the corporate and product presentation.
Invite your team to five partner meetings when five investors are shortlisted.
Rehearse the presentation till it's natural. Let the team speak.
Successful presentations require structure, rehearsal, and a team. Steve Jobs nailed it.

Joseph Mavericks
3 months ago
5 books my CEO read to make $30M
Offices without books are like bodies without souls.

After 10 years, my CEO sold his company for $30 million. I've shared many of his lessons on medium. You could ask him anything at his always-open office. He also said we could use his office for meetings while he was away. When I used his office for work, I was always struck by how many books he had.
Books are useful in almost every aspect of learning. Building a business, improving family relationships, learning a new language, a new skill... Books teach, guide, and structure. Whether fiction or nonfiction, books inspire, give ideas, and develop critical thinking skills.
My CEO prefers non-fiction and attends a Friday book club. This article discusses 5 books I found in his office that impacted my life/business. My CEO sold his company for $30 million, but I've built a steady business through blogging and video making.
I recall events and lessons I learned from my CEO and how they relate to each book, and I explain how I applied the book's lessons to my business and life.
Note: This post has no affiliate links.
1. The One Thing — Gary Keller

Gary Keller, a real estate agent, wanted more customers. So he and his team brainstormed ways to get more customers. They decided to write a bestseller about work and productivity. The more people who saw the book, the more customers they'd get.
Gary Keller focused on writing the best book on productivity, work, and efficiency for months. His business experience. Keller's business grew after the book's release.
The author summarizes the book in one question.
"What's the one thing that will make everything else easier or unnecessary?"
When I started my blog and business alongside my 9–5, I quickly identified my one thing: writing. My business relied on it, so it had to be great. Without writing, there was no content, traffic, or business.
My CEO focused on funding when he started his business. Even in his final years, he spent a lot of time on the phone with investors, either to get more money or to explain what he was doing with it. My CEO's top concern was money, and the other super important factors were handled by separate teams.
Product tech and design
Incredible customer support team
Excellent promotion team
Profitable sales team
My CEO didn't always focus on one thing and ignore the rest. He was on all of those teams when I started my job. He'd start his day in tech, have lunch with marketing, and then work in sales. He was in his office on the phone at night.
He eventually realized his errors. Investors told him he couldn't do everything for the company. If needed, he had to change internally. He learned to let go, mind his own business, and focus for the next four years. Then he sold for $30 million.
The bigger your project/company/idea, the more you'll need to delegate to stay laser-focused. I started something new every few months for 10 years before realizing this. So much to do makes it easy to avoid progress. Once you identify the most important aspect of your project and enlist others' help, you'll be successful.
2. Eat That Frog — Brian Tracy

The author quote sums up book's essence:
Mark Twain said that if you eat a live frog in the morning, it's probably the worst thing that will happen to you all day. Your "frog" is the biggest, most important task you're most likely to procrastinate on.
"Frog" and "One Thing" are both about focusing on what's most important. Eat That Frog recommends doing the most important task first thing in the morning.
I shared my CEO's calendar in an article 10 months ago. Like this:

CEO's average week (some information crossed out for confidentiality)
Notice anything about 8am-8:45am? Almost every day is the same (except Friday). My CEO started his day with a management check-in for 2 reasons:
Checking in with all managers is cognitively demanding, and my CEO is a morning person.
In a young startup where everyone is busy, the morning management check-in was crucial. After 10 am, you couldn't gather all managers.
When I started my blog, writing was my passion. I'm a morning person, so I woke up at 6 am and started writing by 6:30 am every day for a year. This allowed me to publish 3 articles a week for 52 weeks to build my blog and audience. After 2 years, I'm not stopping.
3. Deep Work — Cal Newport

Deep work is focusing on a cognitively demanding task without distractions (like a morning management meeting). It helps you master complex information quickly and produce better results faster. In a competitive world 10 or 20 years ago, focus wasn't a huge advantage. Smartphones, emails, and social media made focus a rare, valuable skill.
Most people can't focus anymore. Screens light up, notifications buzz, emails arrive, Instagram feeds... Many people don't realize they're interrupted because it's become part of their normal workflow.
Cal Newport mentions Bill Gates' "Think Weeks" in Deep Work.
Microsoft CEO Bill Gates would isolate himself (often in a lakeside cottage) twice a year to read and think big thoughts.
Inside Bill's Brain on Netflix shows Newport's lakeside cottage. I've always wanted a lakeside cabin to work in. My CEO bought a lakehouse after selling his company, but now he's retired.
As a company grows, you can focus less on it. In a previous section, I said investors told my CEO to get back to basics and stop micromanaging. My CEO's commitment and ability to get work done helped save the company. His deep work and new frameworks helped us survive the corona crisis (more on this later).
The ability to deep work will be a huge competitive advantage in the next century. Those who learn to work deeply will likely be successful while everyone else is glued to their screens, Bluetooth-synced to their watches, and playing Candy Crush on their tablets.
4. The 7 Habits of Highly Effective People — Stephen R. Covey

It took me a while to start reading this book because it seemed like another shallow self-help bible. I kept finding this book when researching self-improvement. I tried it because it was everywhere.
Stephen Covey taught me 2 years ago to have a personal mission statement.
A 7 Habits mission statement describes the life you want to lead, the character traits you want to embody, and the impact you want to have on others. shortform.com
I've had many lunches with my CEO and talked about Vipassana meditation and Sunday forest runs, but I've never seen his mission statement. I'm sure his family is important, though. In the above calendar screenshot, you can see he always included family events (in green) so we could all see those time slots. We couldn't book him then. Although he never spent as much time with his family as he wanted, he always made sure to be on time for his kid's birthday rather than a conference call.
My CEO emphasized his company's mission. Your mission statement should answer 3 questions.
What does your company do?
How does it do it?
Why does your company do it?
As a graphic designer, I had to create mission-statement posters. My CEO hung posters in each office.
5. Measure What Matters — John Doerr

This book is about Andrew Grove's OKR strategy, developed in 1968. When he joined Google's early investors board, he introduced it to Larry Page and Sergey Brin. Google still uses OKR.
Objective Key Results
Objective: It explains your goals and desired outcome. When one goal is reached, another replaces it. OKR objectives aren't technical, measured, or numerical. They must be clear.
Key Result should be precise, technical, and measurable, unlike the Objective. It shows if the Goal is being worked on. Time-bound results are quarterly or yearly.
Our company almost sank several times. Sales goals were missed, management failed, and bad decisions were made. On a Monday, our CEO announced we'd implement OKR to revamp our processes.
This was a year before the pandemic, and I'm certain we wouldn't have sold millions or survived without this change. This book impacted the company the most, not just management but all levels. Organization and transparency improved. We reached realistic goals. Happy investors. We used the online tool Gtmhub to implement OKR across the organization.
My CEO's company went from near bankruptcy to being acquired for $30 million in 2 years after implementing OKR.
I hope you enjoyed this booklist. Here's a recap of the 5 books and the lessons I learned from each.
The 7 Habits of Highly Effective People — Stephen R. Covey
Have a mission statement that outlines your goals, character traits, and impact on others.
Deep Work — Cal Newport
Focus is a rare skill; master it. Deep workers will succeed in our hyper-connected, distracted world.
The One Thing — Gary Keller
What can you do that will make everything else easier or unnecessary? Once you've identified it, focus on it.
Eat That Frog — Brian Tracy
Identify your most important task the night before and do it first thing in the morning. You'll have a lighter day.
Measure What Matters — John Doerr
On a timeline, divide each long-term goal into chunks. Divide those slices into daily tasks (your goals). Time-bound results are quarterly or yearly. Objectives aren't measured or numbered.
Thanks for reading. Enjoy the ride!
You might also like

Daniel Vassallo
4 months ago
Why I quit a $500K job at Amazon to work for myself
I quit my 8-year Amazon job last week. I wasn't motivated to do another year despite promotions, pay, recognition, and praise.
In AWS, I built developer tools. I could have worked in that field forever.
I became an Amazon developer. Within 3.5 years, I was promoted twice to senior engineer and would have been promoted to principal engineer if I stayed. The company said I had great potential.
Over time, I became a reputed expert and leader within the company. I was respected.
First year I made $75K, last year $511K. If I stayed another two years, I could have made $1M.
Despite Amazon's reputation, my work–life balance was good. I no longer needed to prove myself and could do everything in 40 hours a week. My team worked from home once a week, and I rarely opened my laptop nights or weekends.
My coworkers were great. I had three generous, empathetic managers. I’m very grateful to everyone I worked with.
Everything was going well and getting better. My motivation to go to work each morning was declining despite my career and income growth.
Another promotion, pay raise, or big project wouldn't have boosted my motivation. Motivation was also waning. It was my freedom.
Demotivation
My motivation was high in the beginning. I worked with someone on an internal tool with little scrutiny. I had more freedom to choose how and what to work on than in recent years. Me and another person improved it, talked to users, released updates, and tested it. Whatever we wanted, we did. We did our best and were mostly self-directed.
In recent years, things have changed. My department's most important project had many stakeholders and complex goals. What I could do depended on my ability to convince others it was the best way to achieve our goals.
Amazon was always someone else's terms. The terms started out simple (keep fixing it), but became more complex over time (maximize all goals; satisfy all stakeholders). Working in a large organization imposed restrictions on how to do the work, what to do, what goals to set, and what business to pursue. This situation forced me to do things I didn't want to do.
Finding New Motivation
What would I do forever? Not something I did until I reached a milestone (an exit), but something I'd do until I'm 80. What could I do for the next 45 years that would make me excited to wake up and pay my bills? Is that too unambitious? Nope. Because I'm motivated by two things.
One is an external carrot or stick. I'm not forced to file my taxes every April, but I do because I don't want to go to jail. Or I may not like something but do it anyway because I need to pay the bills or want a nice car. Extrinsic motivation
One is internal. When there's no carrot or stick, this motivates me. This fuels hobbies. I wanted a job that was intrinsically motivated.
Is this too low-key? Extrinsic motivation isn't sustainable. Getting promoted felt good for a week, then it was over. When I hit $100K, I admired my W2 for a few days, but then it wore off. Same thing happened at $200K, $300K, $400K, and $500K. Earning $1M or $10M wouldn't change anything. I feel the same about every material reward or possession. Getting them feels good at first, but quickly fades.
Things I've done since I was a kid, when no one forced me to, don't wear off. Coding, selling my creations, charting my own path, and being honest. Why not always use my strengths and motivation? I'm lucky to live in a time when I can work independently in my field without large investments. So that’s what I’m doing.
What’s Next?
I'm going all-in on independence and will make a living from scratch. I won't do only what I like, but on my terms. My goal is to cover my family's expenses before my savings run out while doing something I enjoy. What more could I want from my work?
You can now follow me on Twitter as I continue to document my journey.
This post is a summary. Read full article here

Will Lockett
1 month ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.

Jon Brosio
1 month ago
You can learn more about marketing from these 8 copywriting frameworks than from a college education.
Email, landing pages, and digital content

Today's most significant skill:
Copywriting.
Unfortunately, most people don't know how to write successful copy because they weren't taught in school.
I've been obsessed with copywriting for two years. I've read 15 books, completed 3 courses, and studied internet's best digital entrepreneurs.
Here are 8 copywriting frameworks that educate more than a four-year degree.
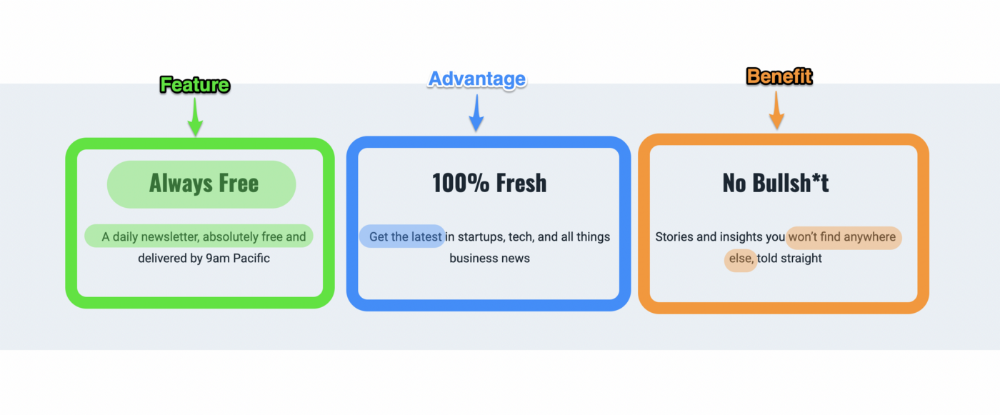
1. Feature — Advantage — Benefit (F.A.B)
This is the most basic copywriting foundation. Email marketing, landing page copy, and digital video ads can use it.
F.A.B says:
How it works (feature)
which is helpful (advantage)
What's at stake (benefit)
The Hustle uses this framework on their landing page to convince people to sign up:
2. P. A. S. T. O. R.
This framework is for longer-form copywriting. PASTOR uses stories to engage with prospects. It explains why people should buy this offer.
PASTOR means:
Problem
Amplify
Story
Testimonial
Offer
Response
Dan Koe's landing page is a great example. It shows PASTOR frame-by-frame.

3. Before — After — Bridge
Before-after-bridge is a copywriting framework that draws attention and shows value quickly.
This framework highlights:
where you are
where you want to be
how to get there
Works great for: Email threads/landing pages
Zain Kahn utilizes this framework to write viral threads.

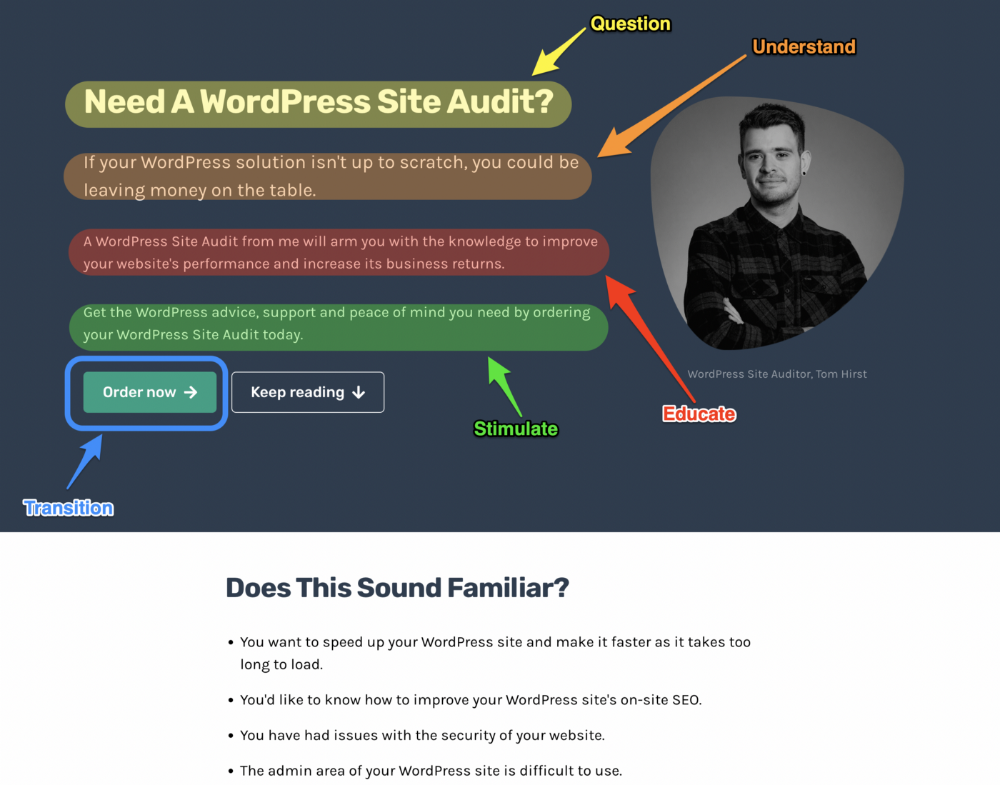
4. Q.U.E.S.T
QUEST is about empathetic writing. You know their issues, obstacles, and headaches. This allows coverups.
QUEST:
Qualifies
Understands
Educates
Stimulates
Transitions
Tom Hirst's landing page uses the QUEST framework.
5. The 4P’s model
The 4P’s approach pushes your prospect to action. It educates and persuades quickly.
4Ps:
The problem the visitor is dealing with
The promise that will help them
The proof the promise works
A push towards action
Mark Manson is a bestselling author, digital creator, and pop-philosopher. He's also a great copywriter, and his membership offer uses the 4P’s framework.

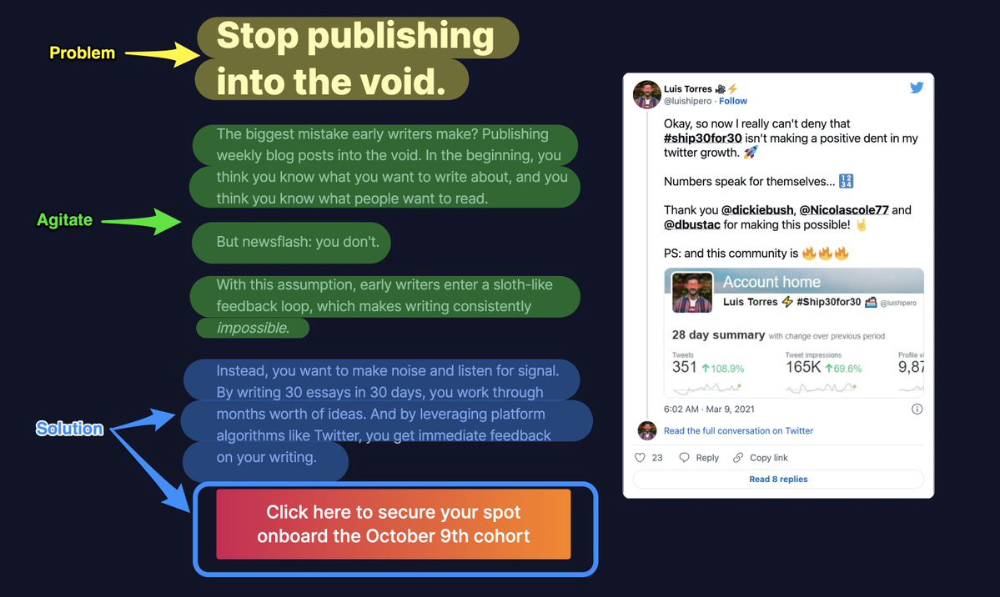
6. Problem — Agitate — Solution (P.A.S)
Up-and-coming marketers should understand problem-agitate-solution copywriting. Once you understand one structure, others are easier. It drives passion and presents a clear solution.
PAS outlines:
The issue the visitor is having
It then intensifies this issue through emotion.
finally offers an answer to that issue (the offer)
The customer's story loops. Nicolas Cole and Dickie Bush use PAS to promote Ship 30 for 30.
7. Star — Story — Solution (S.S.S)
PASTOR + PAS = star-solution-story. Like PAS, it employs stories to persuade.
S.S.S. is effective storytelling:
Star: (Person had a problem)
Story: (until they had a breakthrough)
Solution: (That created a transformation)
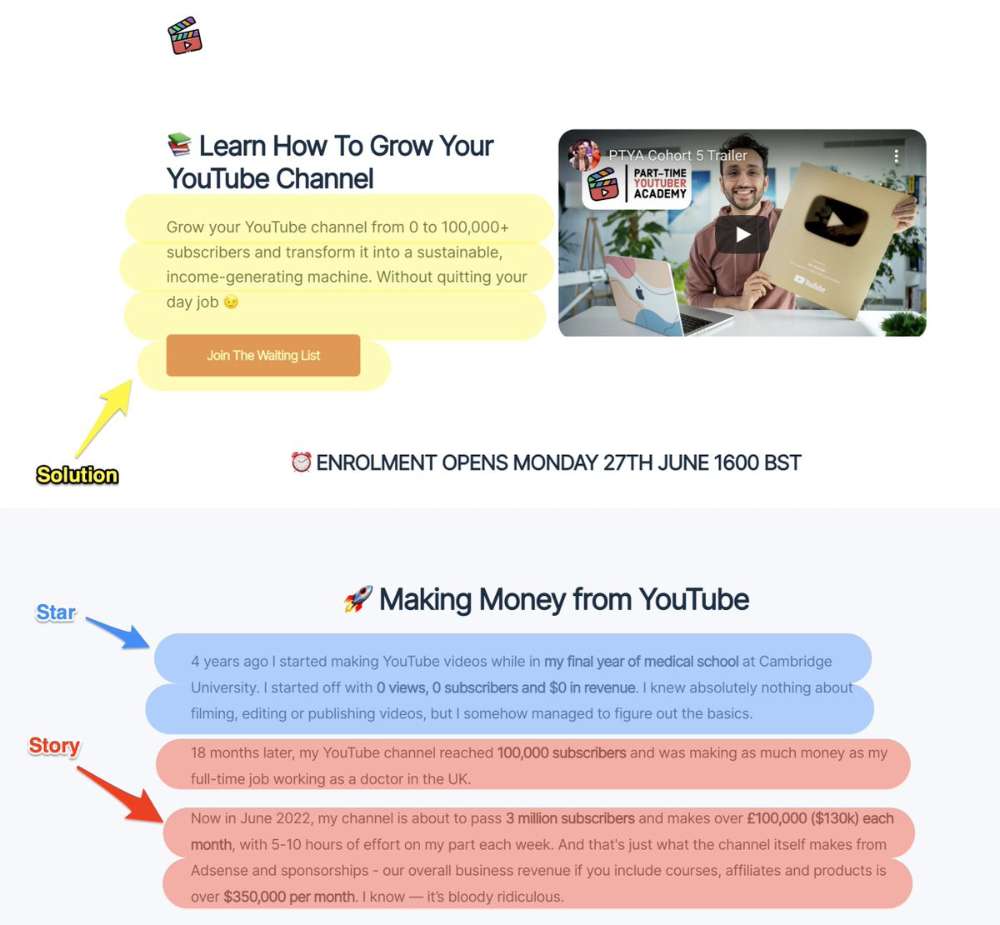
Ali Abdaal is a YouTuber with a great S.S.S copy.
8. Attention — Interest — Desire — Action
AIDA is another classic. This copywriting framework is great for fast-paced environments (think all digital content on Linkedin, Twitter, Medium, etc.).
It works with:
Page landings
writing on thread
Email
It's a good structure since it's concise, attention-grabbing, and action-oriented.
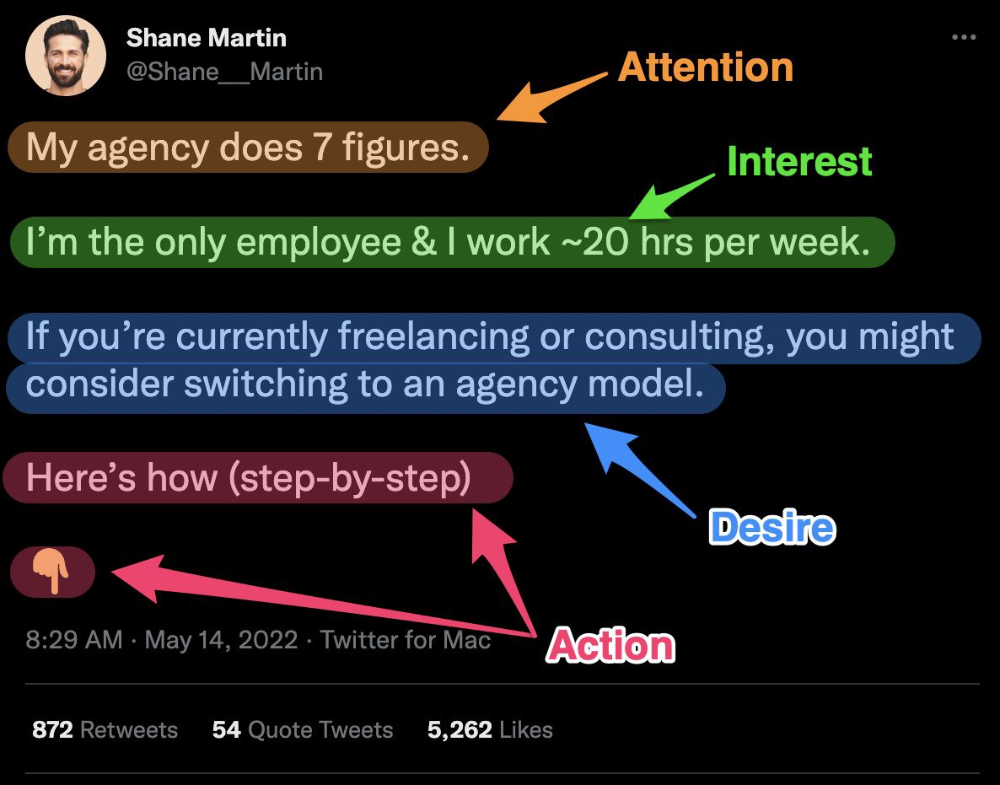
Shane Martin, Twitter's creator, uses this approach to create viral content.
TL;DR
8 copywriting frameworks that teach marketing better than a four-year degree
Feature-advantage-benefit
Before-after-bridge
Star-story-solution
P.A.S.T.O.R
Q.U.E.S.T
A.I.D.A
P.A.S
4P’s