

More on Leadership

Sammy Abdullah
3 years ago
Payouts to founders at IPO
How much do startup founders make after an IPO? We looked at 2018's major tech IPOs. Paydays aren't what founders took home at the IPO (shares are normally locked up for 6 months), but what they were worth at the IPO price on the day the firm went public. It's not cash, but it's nice. Here's the data.
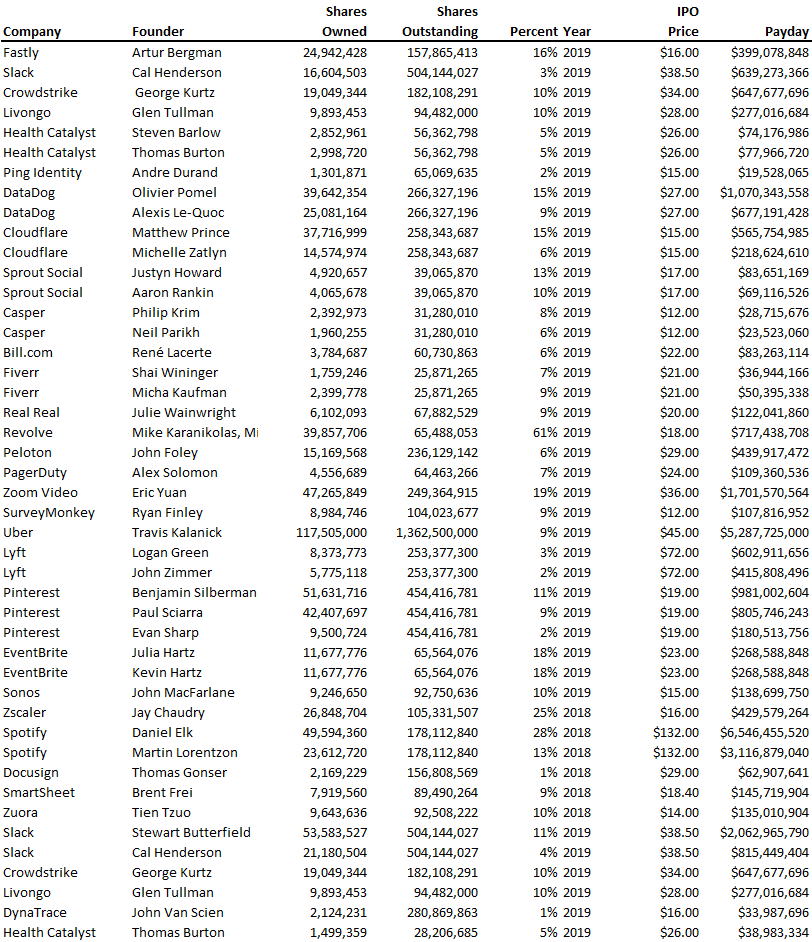
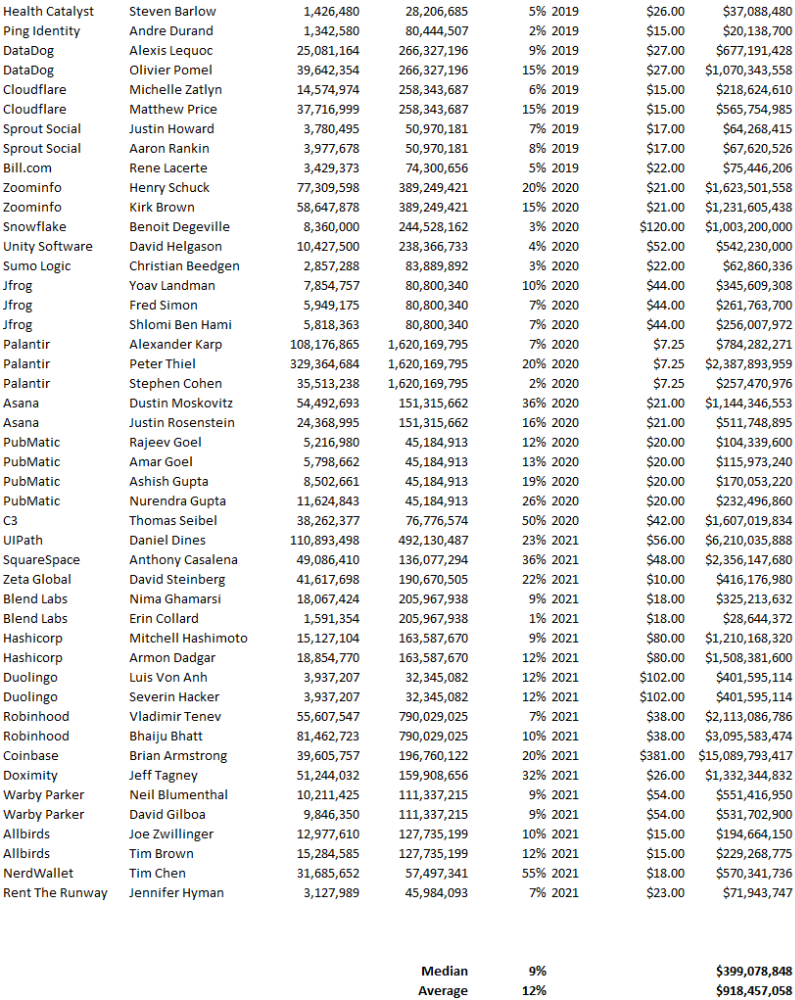
Several points are noteworthy.
Huge payoffs. Median and average pay were $399m and $918m. Average and median homeownership were 9% and 12%.
Coinbase, Uber, UI Path. Uber, Zoom, Spotify, UI Path, and Coinbase founders raised billions. Zoom's founder owned 19% and Spotify's 28% and 13%. Brian Armstrong controlled 20% of Coinbase at IPO and was worth $15bn. Preserving as much equity as possible by staying cash-efficient or raising at high valuations also helps.
The smallest was Ping. Ping's compensation was the smallest. Andre Duand owned 2% but was worth $20m at IPO. That's less than some billion-dollar paydays, but still good.
IPOs can be lucrative, as you can see. Preserving equity could be the difference between a $20mm and $15bln payday (Coinbase).

Al Anany
2 years ago
Because of this covert investment that Bezos made, Amazon became what it is today.
He kept it under wraps for years until he legally couldn’t.

His shirt is incomplete. I can’t stop thinking about this…
Actually, ignore the article. Look at it. JUST LOOK at it… It’s quite disturbing, isn’t it?
Ughh…
Me: “Hey, what up?” Friend: “All good, watching lord of the rings on amazon prime video.” Me: “Oh, do you know how Amazon grew and became famous?” Friend: “Geek alert…Can I just watch in peace?” Me: “But… Bezos?” Friend: “Let it go, just let it go…”
I can question you, the reader, and start answering instantly without his consent. This far.
Reader, how did Amazon succeed? You'll say, Of course, it was an internet bookstore, then it sold everything.
Mistaken. They moved from zero to one because of this. How did they get from one to thousand? AWS-some. Understand? It's geeky and lame. If not, I'll explain my geekiness.
Over an extended period of time, Amazon was not profitable.
Business basics. You want customers if you own a bakery, right?
Well, 100 clients per day order $5 cheesecakes (because cheesecakes are awesome.)
$5 x 100 consumers x 30 days Equals $15,000 monthly revenue. You proudly work here.
Now you have to pay the barista (unless ChatGPT is doing it haha? Nope..)
The barista is requesting $5000 a month.
Each cheesecake costs the cheesecake maker $2.5 ($2.5 × 100 x 30 = $7500).
The monthly cost of running your bakery, including power, is about $5000.
Assume no extra charges. Your operating costs are $17,500.
Just $15,000? You have income but no profit. You might make money selling coffee with your cheesecake next month.
Is losing money bad? You're broke. Losing money. It's bad for financial statements.
It's almost a business ultimatum. Most startups fail. Amazon took nine years.
I'm reading Amazon Unbound: Jeff Bezos and the Creation of a Global Empire to comprehend how a company has a $1 trillion market cap.
Many things made Amazon big. The book claims that Bezos and Amazon kept a specific product secret for a long period.
Clouds above the bald head.
In 2006, Bezos started a cloud computing initiative. They believed many firms like Snapchat would pay for reliable servers.
In 2006, cloud computing was not what it is today. I'll simplify. 2006 had no iPhone.
Bezos invested in Amazon Web Services (AWS) without disclosing its revenue. That's permitted till a certain degree.
Google and Microsoft would realize Amazon is heavily investing in this market and worry.
Bezos anticipated high demand for this product. Microsoft built its cloud in 2010, and Google in 2008.
If you managed Google or Microsoft, you wouldn't know how much Amazon makes from their cloud computing service. It's enough. Yet, Amazon is an internet store, so they'll focus on that.
All but Bezos were wrong.
Time to come clean now.
They revealed AWS revenue in 2015. Two things were apparent:
Bezos made the proper decision to bet on the cloud and keep it a secret.
In this race, Amazon is in the lead.
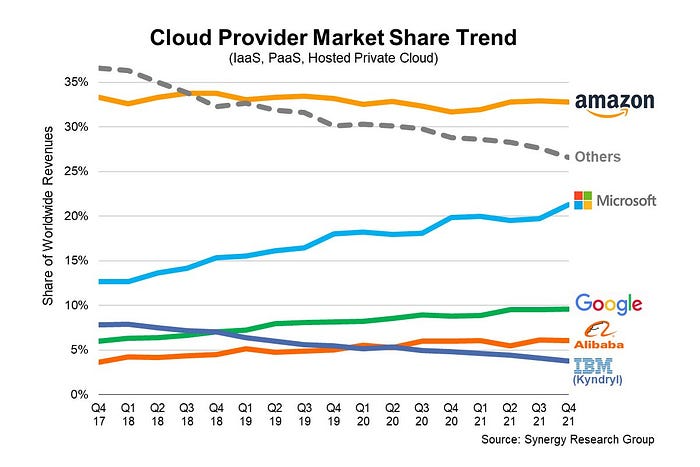
They continued. Let me list some AWS users today.
Netflix
Airbnb
Twitch
More. Amazon was unprofitable for nine years, remember? This article's main graph.
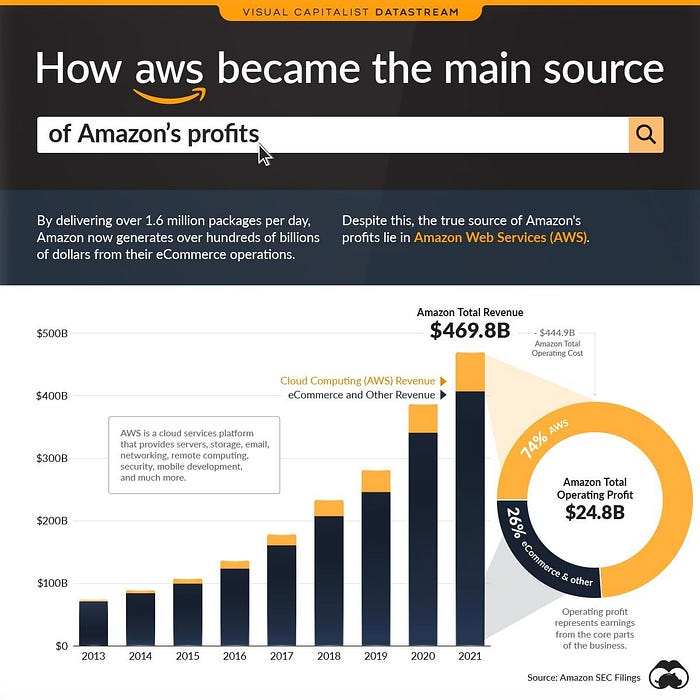
AWS accounted for 74% of Amazon's profit in 2021. This 74% might not exist if they hadn't invested in AWS.
Bring this with you home.
Amazon predated AWS. Yet, it helped the giant reach $1 trillion. Bezos' secrecy? Perhaps, until a time machine is invented (they might host the time machine software on AWS, though.)
Without AWS, Amazon would have been profitable but unimpressive. They may have invested in anything else that would have returned more (like crypto? No? Ok.)
Bezos has business flaws. His success. His failures include:
introducing the Fire Phone and suffering a $170 million loss.
Amazon's failure in China In 2011, Amazon had a about 15% market share in China. 2019 saw a decrease of about 1%.
not offering a higher price to persuade the creator of Netflix to sell the company to him. He offered a rather reasonable $15 million in his proposal. But what if he had offered $30 million instead (Amazon had over $100 million in revenue at the time)? He might have owned Netflix, which has a $156 billion market valuation (and saved billions rather than invest in Amazon Prime Video).
Some he could control. Some were uncontrollable. Nonetheless, every action he made in the foregoing circumstances led him to invest in AWS.

Will Lockett
3 years ago
Tesla recently disclosed its greatest secret.

The VP has revealed a secret that should frighten the rest of the EV world.
Tesla led the EV revolution. Elon Musk's invention offers a viable alternative to gas-guzzlers. Tesla has lost ground in recent years. VW, BMW, Mercedes, and Ford offer EVs with similar ranges, charging speeds, performance, and cost. Tesla's next-generation 4680 battery pack, Roadster, Cybertruck, and Semi were all delayed. CATL offers superior batteries than the 4680. Martin Viecha, Tesla's Vice President, recently told Business Insider something that startled the EV world and will establish Tesla as the EV king.
Viecha mentioned that Tesla's production costs have dropped 57% since 2017. This isn't due to cheaper batteries or devices like Model 3. No, this is due to amazing factory efficiency gains.
Musk wasn't crazy to want a nearly 100% automated production line, and Tesla's strategy of sticking with one model and improving it has paid off. Others change models every several years. This implies they must spend on new R&D, set up factories, and modernize service and parts systems. All of this costs a ton of money and prevents them from refining production to cut expenses.
Meanwhile, Tesla updates its vehicles progressively. Everything from the backseats to the screen has been enhanced in a 2022 Model 3. Tesla can refine, standardize, and cheaply produce every part without changing the production line.
In 2017, Tesla's automobile production averaged $84,000. In 2022, it'll be $36,000.
Mr. Viecha also claimed that new factories in Shanghai and Berlin will be significantly cheaper to operate once fully operating.
Tesla's hand is visible. Tesla selling $36,000 cars for $60,000 This barely beats the competition. Model Y long-range costs just over $60,000. Tesla makes $24,000+ every sale, giving it a 40% profit margin, one of the best in the auto business.
VW I.D4 costs about the same but makes no profit. Tesla's rivals face similar challenges. Their EVs make little or no profit.
Tesla costs the same as other EVs, but they're in a different league.
But don't forget that the battery pack accounts for 40% of an EV's cost. Tesla may soon fully utilize its 4680 battery pack.
The 4680 battery pack has larger cells and a unique internal design. This means fewer cells are needed for a car, making it cheaper to assemble and produce (per kWh). Energy density and charge speeds increase slightly.
Tesla underestimated the difficulty of making this revolutionary new cell. Each time they try to scale up production, quality drops and rejected cells rise.
Tesla recently installed this battery pack in Model Ys and is scaling production. If they succeed, Tesla battery prices will plummet.
Tesla's Model Ys 2170 battery costs $11,000. The same size pack with 4680 cells costs $3,400 less. Once scaled, it could be $5,500 (50%) less. The 4680 battery pack could reduce Tesla production costs by 20%.
With these cost savings, Tesla could sell Model Ys for $40,000 while still making a profit. They could offer a $25,000 car.
Even with new battery technology, it seems like other manufacturers will struggle to make EVs profitable.
Teslas cost about the same as competitors, so don't be fooled. Behind the scenes, they're still years ahead, and the 4680 battery pack and new factories will only increase that lead. Musk faces a first. He could sell Teslas at current prices and make billions while other manufacturers struggle. Or, he could massively undercut everyone and crush the competition once and for all. Tesla and Elon win.
You might also like

Neeramitra Reddy
3 years ago
The best life advice I've ever heard could very well come from 50 Cent.
He built a $40M hip-hop empire from street drug dealing.

50 Cent was nearly killed by 9mm bullets.
Before 50 Cent, Curtis Jackson sold drugs.
He sold coke to worried addicts after being orphaned at 8.
Pursuing police. Murderous hustlers and gangs. Unwitting informers.
Despite his hard life, his hip-hop career was a success.
An assassination attempt ended his career at the start.
What sane producer would want to deal with a man entrenched in crime?
Most would have drowned in self-pity and drank themselves to death.
But 50 Cent isn't most people. Life on the streets had given him fearlessness.
“Having a brush with death, or being reminded in a dramatic way of the shortness of our lives, can have a positive, therapeutic effect. So it is best to make every moment count, to have a sense of urgency about life.” ― 50 Cent, The 50th Law
50 released a series of mixtapes that caught Eminem's attention and earned him a $50 million deal!
50 Cents turned death into life.
Things happen; that is life.
We want problems solved.
Every human has problems, whether it's Jeff Bezos swimming in his billions, Obama in his comfortable retirement home, or Dan Bilzerian with his hired bikini models.
All problems.
Problems churn through life. solve one, another appears.
It's harsh. Life's unfair. We can face reality or run from it.
The latter will worsen your issues.
“The firmer your grasp on reality, the more power you will have to alter it for your purposes.” — 50 Cent, The 50th Law
In a fantasy-obsessed world, 50 Cent loves reality.
Wish for better problem-solving skills rather than problem-free living.
Don't wish, work.
We All Have the True Power of Alchemy
Humans are arrogant enough to think the universe cares about them.
That things happen as if the universe notices our nanosecond existences.
Things simply happen. Period.
By changing our perspective, we can turn good things bad.
The alchemists' search for the philosopher's stone may have symbolized the ability to turn our lead-like perceptions into gold.
Negativity bias tints our perceptions.
Normal sparring broke your elbow? Rest and rethink your training. Fired? You can improve your skills and get a better job.
Consider Curtis if he had fallen into despair.
The legend we call 50 Cent wouldn’t have existed.
The Best Lesson in Life Ever?
Neither avoid nor fear your reality.
That simple sentence contains every self-help tip and life lesson on Earth.
When reality is all there is, why fear it? avoidance?
Or worse, fleeing?
To accept reality, we must eliminate the words should be, could be, wish it were, and hope it will be.
It is. Period.
Only by accepting reality's chaos can you shape your life.
“Behind me is infinite power. Before me is endless possibility, around me is boundless opportunity. My strength is mental, physical and spiritual.” — 50 Cent

Victoria Kurichenko
3 years ago
My Blog Is in Google's Top 10—Here's How to Compete

"Competition" is beautiful and hateful.
Some people bury their dreams because they are afraid of competition. Others challenge themselves, shaping our world.
Competition is normal.
It spurs innovation and progress.
I wish more people agreed.
As a marketer, content writer, and solopreneur, my readers often ask:
"I want to create a niche website, but I have no ideas. Everything's done"
"Is a website worthwhile?"
I can't count how many times I said, "Yes, it makes sense, and you can succeed in a competitive market."
I encourage and share examples, but it's not enough to overcome competition anxiety.
I launched an SEO writing website for content creators a year ago, knowing it wouldn't beat Ahrefs, Semrush, Backlinko, etc.
Not needed.
Many of my website's pages rank highly on Google.
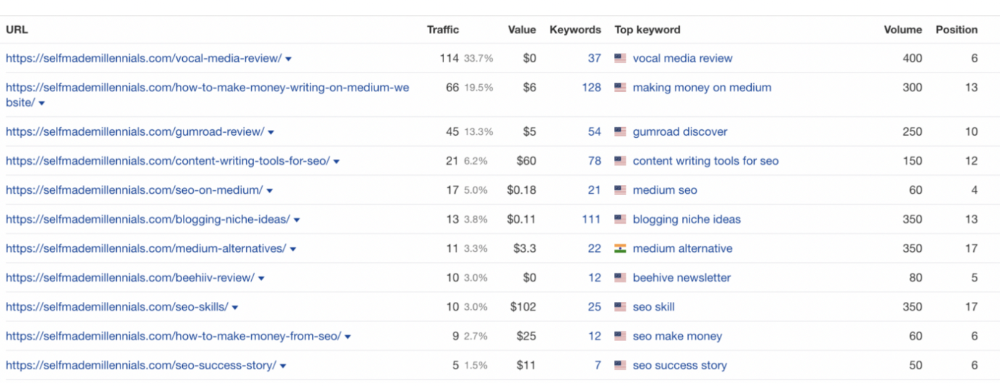
Everyone can eat the pie.
In a competitive niche, I took a different approach.
Look farther
When chatting with bloggers that want a website, I discovered something fascinating.
They want to launch a website but have no ideas. As a next step, they start listing the interests they believe they should work on, like wellness, lifestyle, investments, etc. I could keep going.
Too many generalists who claim to know everything confuse many.
Generalists aren't trusted.
We want someone to fix our problems immediately.
I don't think broad-spectrum experts are undervalued. People have many demands that go beyond generalists' work. Narrow-niche experts can help.
I've done SEO for three years. I learned from experts and courses. I couldn't find a comprehensive SEO writing resource.
I read tons of articles before realizing that wasn't it. I took courses that covered SEO basics eventually.
I had a demand for learning SEO writing, but there was no solution on the market. My website fills this micro-niche.
Have you ever had trouble online?
Professional courses too general, boring, etc.?
You've bought off-topic books, right?
You're not alone.
Niche ideas!
Big players often disregard new opportunities. Too small. Individual content creators can succeed here.
In a competitive market:
Never choose wide subjects
Think about issues you can relate to and have direct experience with.
Be a consumer to discover both the positive and negative aspects of a good or service.
Merchandise your annoyances.
Consider ways to transform your frustrations into opportunities.
The right niche is half-success. Here is what else I did to hit the Google front page with my website.
An innovative method for choosing subjects
Why publish on social media and websites?
Want likes, shares, followers, or fame?
Some people do it for fun. No judgment.
I bet you want more.
You want to make decent money from blogging.
Writing about random topics, even if they are related to your niche, won’t help you attract an audience from organic search. I'm a marketer and writer.
I worked at companies with dead blogs because they posted for themselves, not readers. They did not follow SEO writing rules; that’s why most of their content flopped.
I learned these hard lessons and grew my website from 0 to 3,000+ visitors per month while working on it a few hours a week only. Evidence:
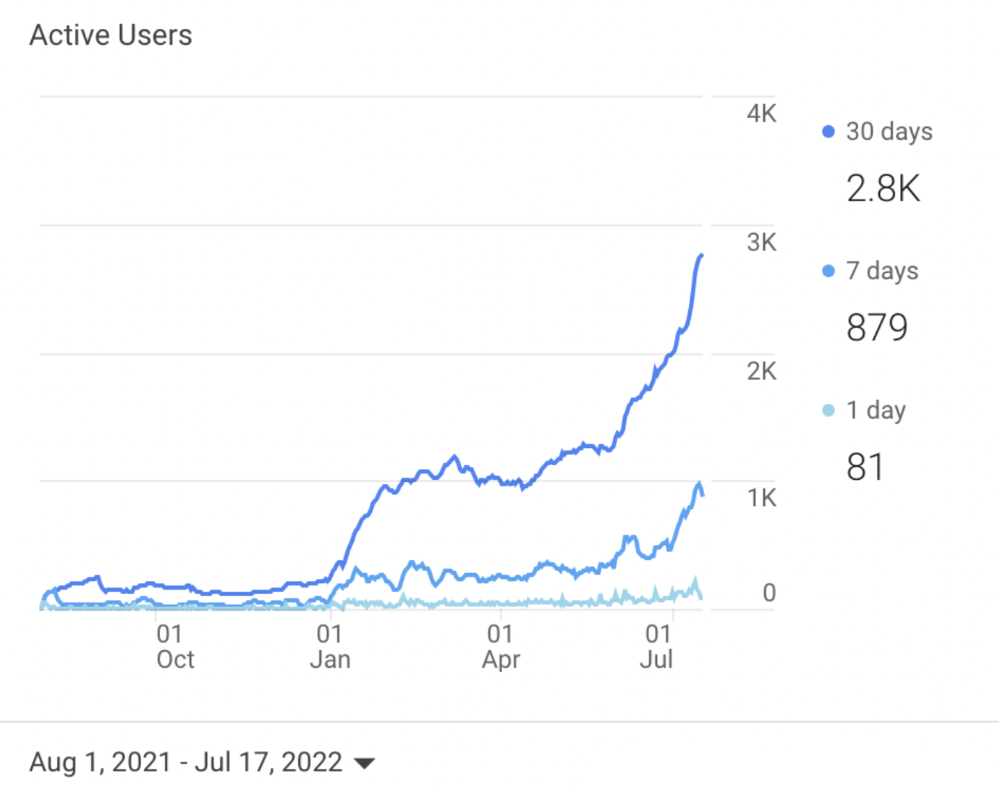
I choose website topics using these criteria:
- Business potential. The information should benefit my audience and generate revenue. There would be no use in having it otherwise.
My topics should help me:
Attract organic search traffic with my "fluff-free" content -> Subscribers > SEO ebook sales.
Simple and effective.
- traffic on search engines. The number of monthly searches reveals how popular my topic is all across the world. If I find that no one is interested in my suggested topic, I don't write a blog article.
- Competition. Every search term is up against rivals. Some are more popular (thus competitive) since more websites target them in organic search. A new website won't score highly for keywords that are too competitive. On the other side, keywords with moderate to light competition can help you rank higher on Google more quickly.
- Search purpose. The "why" underlying users' search requests is revealed. I analyze search intent to understand what users need when they plug various queries in the search bar and what content can perfectly meet their needs.
My specialty website produces money, ranks well, and attracts the target audience because I handpick high-traffic themes.
Following these guidelines, even a new website can stand out.
I wrote a 50-page SEO writing guide where I detailed topic selection and share my front-page Google strategy.
My guide can help you run a successful niche website.
In summary
You're not late to the niche-website party.
The Internet offers many untapped opportunities.
We need new solutions and are willing to listen.
There are unexplored niches in any topic.
Don't fight giants. They have their piece of the pie. They might overlook new opportunities while trying to keep that piece of the pie. You should act now.

Leon Ho
3 years ago
Digital Brainbuilding (Your Second Brain)

The human brain is amazing. As more scientists examine the brain, we learn how much it can store.
The human brain has 1 billion neurons, according to Scientific American. Each neuron creates 1,000 connections, totaling over a trillion. If each neuron could store one memory, we'd run out of room. [1]
What if you could store and access more info, freeing up brain space for problem-solving and creativity?
Build a second brain to keep up with rising knowledge (what I refer to as a Digital Brain). Effectively managing information entails realizing you can't recall everything.
Every action requires information. You need the correct information to learn a new skill, complete a project at work, or establish a business. You must manage information properly to advance your profession and improve your life.
How to construct a second brain to organize information and achieve goals.
What Is a Second Brain?
How often do you forget an article or book's key point? Have you ever wasted hours looking for a saved file?
If so, you're not alone. Information overload affects millions of individuals worldwide. Information overload drains mental resources and causes anxiety.
This is when the second brain comes in.
Building a second brain doesn't involve duplicating the human brain. Building a system that captures, organizes, retrieves, and archives ideas and thoughts. The second brain improves memory, organization, and recall.
Digital tools are preferable to analog for building a second brain.
Digital tools are portable and accessible. Due to these benefits, we'll focus on digital second-brain building.
Brainware
Digital Brains are external hard drives. It stores, organizes, and retrieves. This means improving your memory won't be difficult.
Memory has three components in computing:
Recording — storing the information
Organization — archiving it in a logical manner
Recall — retrieving it again when you need it
For example:
Due to rigorous security settings, many websites need you to create complicated passwords with special characters.
You must now memorize (Record), organize (Organize), and input this new password the next time you check in (Recall).
Even in this simple example, there are many pieces to remember. We can't recognize this new password with our usual patterns. If we don't use the password every day, we'll forget it. You'll type the wrong password when you try to remember it.
It's common. Is it because the information is complicated? Nope. Passwords are basically letters, numbers, and symbols.
It happens because our brains aren't meant to memorize these. Digital Brains can do heavy lifting.
Why You Need a Digital Brain
Dual minds are best. Birth brain is limited.
The cerebral cortex has 125 trillion synapses, according to a Stanford Study. The human brain can hold 2.5 million terabytes of digital data. [2]
Building a second brain improves learning and memory.
Learn and store information effectively
Faster information recall
Organize information to see connections and patterns
Build a Digital Brain to learn more and reach your goals faster. Building a second brain requires time and work, but you'll have more time for vital undertakings.
Why you need a Digital Brain:
1. Use Brainpower Effectively
Your brain has boundaries, like any organ. This is true while solving a complex question or activity. If you can't focus on a work project, you won't finish it on time.
Second brain reduces distractions. A robust structure helps you handle complicated challenges quickly and stay on track. Without distractions, it's easy to focus on vital activities.
2. Staying Organized
Professional and personal duties must be balanced. With so much to do, it's easy to neglect crucial duties. This is especially true for skill-building. Digital Brain will keep you organized and stress-free.
Life success requires action. Organized people get things done. Organizing your information will give you time for crucial tasks.
You'll finish projects faster with good materials and methods. As you succeed, you'll gain creative confidence. You can then tackle greater jobs.
3. Creativity Process
Creativity drives today's world. Creativity is mysterious and surprising for millions worldwide. Immersing yourself in others' associations, triggers, thoughts, and ideas can generate inspiration and creativity.
Building a second brain is crucial to establishing your creative process and building habits that will help you reach your goals. Creativity doesn't require perfection or overthinking.
4. Transforming Your Knowledge Into Opportunities
This is the age of entrepreneurship. Today, you can publish online, build an audience, and make money.
Whether it's a business or hobby, you'll have several job alternatives. Knowledge can boost your economy with ideas and insights.
5. Improving Thinking and Uncovering Connections
Modern career success depends on how you think. Instead of overthinking or perfecting, collect the best images, stories, metaphors, anecdotes, and observations.
This will increase your creativity and reveal connections. Increasing your imagination can help you achieve your goals, according to research. [3]
Your ability to recognize trends will help you stay ahead of the pack.
6. Credibility for a New Job or Business
Your main asset is experience-based expertise. Others won't be able to learn without your help. Technology makes knowledge tangible.
This lets you use your time as you choose while helping others. Changing professions or establishing a new business become learning opportunities when you have a Digital Brain.
7. Using Learning Resources
Millions of people use internet learning materials to improve their lives. Online resources abound. These include books, forums, podcasts, articles, and webinars.
These resources are mostly free or inexpensive. Organizing your knowledge can save you time and money. Building a Digital Brain helps you learn faster. You'll make rapid progress by enjoying learning.
How does a second brain feel?
Digital Brain has helped me arrange my job and family life for years.
No need to remember 1001 passwords. I never forget anything on my wife's grocery lists. Never miss a meeting. I can access essential information and papers anytime, anywhere.
Delegating memory to a second brain reduces tension and anxiety because you'll know what to do with every piece of information.
No information will be forgotten, boosting your confidence. Better manage your fears and concerns by writing them down and establishing a strategy. You'll understand the plethora of daily information and have a clear head.
How to Develop Your Digital Brain (Your Second Brain)
It's cheap but requires work.
Digital Brain development requires:
Recording — storing the information
Organization — archiving it in a logical manner
Recall — retrieving it again when you need it
1. Decide what information matters before recording.
To succeed in today's environment, you must manage massive amounts of data. Articles, books, webinars, podcasts, emails, and texts provide value. Remembering everything is impossible and overwhelming.
What information do you need to achieve your goals?
You must consolidate ideas and create a strategy to reach your aims. Your biological brain can imagine and create with a Digital Brain.
2. Use the Right Tool
We usually record information without any preparation - we brainstorm in a word processor, email ourselves a message, or take notes while reading.
This information isn't used. You must store information in a central location.
Different information needs different instruments.
Evernote is a top note-taking program. Audio clips, Slack chats, PDFs, text notes, photos, scanned handwritten pages, emails, and webpages can be added.
Pocket is a great software for saving and organizing content. Images, videos, and text can be sorted. Web-optimized design
Calendar apps help you manage your time and enhance your productivity by reminding you of your most important tasks. Calendar apps flourish. The best calendar apps are easy to use, have many features, and work across devices. These calendars include Google, Apple, and Outlook.
To-do list/checklist apps are useful for managing tasks. Easy-to-use, versatility, budget, and cross-platform compatibility are important when picking to-do list apps. Google Keep, Google Tasks, and Apple Notes are good to-do apps.
3. Organize data for easy retrieval
How should you organize collected data?
When you collect and organize data, you'll see connections. An article about networking can assist you comprehend web marketing. Saved business cards can help you find new clients.
Choosing the correct tools helps organize data. Here are some tools selection criteria:
Can the tool sync across devices?
Personal or team?
Has a search function for easy information retrieval?
Does it provide easy data categorization?
Can users create lists or collections?
Does it offer easy idea-information connections?
Does it mind map and visually organize thoughts?
Conclusion
Building a Digital Brain (second brain) helps us save information, think creatively, and implement ideas. Your second brain is a biological extension. It prevents amnesia, allowing you to tackle bigger creative difficulties.
People who love learning often consume information without using it. Every day, they postpone life-improving experiences until they're forgotten. Useful information becomes strength.
Reference
[1] ^ Scientific American: What Is the Memory Capacity of the Human Brain?
[2] ^ Clinical Neurology Specialists: What is the Memory Capacity of a Human Brain?
[3] ^ National Library of Medicine: Imagining Success: Multiple Achievement Goals and the Effectiveness of Imagery