



More on NFTs & Art

Vishal Chawla
3 years ago
5 Bored Apes borrowed to claim $1.1 million in APE tokens
Takeaway
Unknown user took advantage of the ApeCoin airdrop to earn $1.1 million.
He used a flash loan to borrow five BAYC NFTs, claim the airdrop, and repay the NFTs.
Yuga Labs, the creators of BAYC, airdropped ApeCoin (APE) to anyone who owns one of their NFTs yesterday.
For the Bored Ape Yacht Club and Mutant Ape Yacht Club collections, the team allocated 150 million tokens, or 15% of the total ApeCoin supply, worth over $800 million. Each BAYC holder received 10,094 tokens worth $80,000 to $200,000.
But someone managed to claim the airdrop using NFTs they didn't own. They used the airdrop's specific features to carry it out. And it worked, earning them $1.1 million in ApeCoin.
The trick was that the ApeCoin airdrop wasn't based on who owned which Bored Ape at a given time. Instead, anyone with a Bored Ape at the time of the airdrop could claim it. So if you gave someone your Bored Ape and you hadn't claimed your tokens, they could claim them.
The person only needed to get hold of some Bored Apes that hadn't had their tokens claimed to claim the airdrop. They could be returned immediately.
So, what happened?
The person found a vault with five Bored Ape NFTs that hadn't been used to claim the airdrop.
A vault tokenizes an NFT or a group of NFTs. You put a bunch of NFTs in a vault and make a token. This token can then be staked for rewards or sold (representing part of the value of the collection of NFTs). Anyone with enough tokens can exchange them for NFTs.
This vault uses the NFTX protocol. In total, it contained five Bored Apes: #7594, #8214, #9915, #8167, and #4755. Nobody had claimed the airdrop because the NFTs were locked up in the vault and not controlled by anyone.
The person wanted to unlock the NFTs to claim the airdrop but didn't want to buy them outright s o they used a flash loan, a common tool for large DeFi hacks. Flash loans are a low-cost way to borrow large amounts of crypto that are repaid in the same transaction and block (meaning that the funds are never at risk of not being repaid).
With a flash loan of under $300,000 they bought a Bored Ape on NFT marketplace OpenSea. A large amount of the vault's token was then purchased, allowing them to redeem the five NFTs. The NFTs were used to claim the airdrop, before being returned, the tokens sold back, and the loan repaid.
During this process, they claimed 60,564 ApeCoin airdrops. They then sold them on Uniswap for 399 ETH ($1.1 million). Then they returned the Bored Ape NFT used as collateral to the same NFTX vault.
Attack or arbitrage?
However, security firm BlockSecTeam disagreed with many social media commentators. A flaw in the airdrop-claiming mechanism was exploited, it said.
According to BlockSecTeam's analysis, the user took advantage of a "vulnerability" in the airdrop.
"We suspect a hack due to a flaw in the airdrop mechanism. The attacker exploited this vulnerability to profit from the airdrop claim" said BlockSecTeam.
For example, the airdrop could have taken into account how long a person owned the NFT before claiming the reward.
Because Yuga Labs didn't take a snapshot, anyone could buy the NFT in real time and claim it. This is probably why BAYC sales exploded so soon after the airdrop announcement.

Ezra Reguerra
3 years ago
Yuga Labs’ Otherdeeds NFT mint triggers backlash from community
Unhappy community members accuse Yuga Labs of fraud, manipulation, and favoritism over Otherdeeds NFT mint.
Following the Otherdeeds NFT mint, disgruntled community members took to Twitter to criticize Yuga Labs' handling of the event.
Otherdeeds NFTs were a huge hit with the community, selling out almost instantly. Due to high demand, the launch increased Ethereum gas fees from 2.6 ETH to 5 ETH.
But the event displeased many people. Several users speculated that the mint was “planned to fail” so the group could advertise launching its own blockchain, as the team mentioned a chain migration in one tweet.
Others like Mark Beylin tweeted that he had "sold out" on all Ape-related NFT investments after Yuga Labs "revealed their true colors." Beylin also advised others to assume Yuga Labs' owners are “bad actors.”
Some users who failed to complete transactions claim they lost ETH. However, Yuga Labs promised to refund lost gas fees.
CryptoFinally, a Twitter user, claimed Yuga Labs gave BAYC members better land than non-members. Others who wanted to participate paid for shittier land, while BAYCS got the only worthwhile land.
The Otherdeed NFT drop also increased Ethereum's burn rate. Glassnode and Data Always reported nearly 70,000 ETH burned on mint day.

Tora Northman
3 years ago
Pixelmon NFTs are so bad, they are almost good!
Bored Apes prices continue to rise, HAPEBEAST launches, Invisible Friends hype continues to grow. Sadly, not all projects are as successful.
Of course, there are many factors to consider when buying an NFT. Is the project a scam? Will the reveal derail the project? Possibly, but when Pixelmon first teased its launch, it generated a lot of buzz.
With a primary sale mint price of 3 ETH ($8,100 USD), it started as an expensive project, with plenty of fans willing to invest in what was sold as a game. After it was revealed, it fell rapidly.
Why? It was overpromised and under delivered.
According to the project's creator[^1], the funds generated will be used to develop the artwork. "The Pixelmon reveal was wrong. This is what our Pixelmon look like in-game. "Despite the fud, I will not go anywhere," he wrote on Twitter. The goal remains. The funds will still be used to build our game. I will finish this project."
The project raised $70 million USD, but the NFTs buyers received were not the project's original teasers. Some call it "the worst NFT project ever," while others call it a complete scam.
But there's hope for some buyers. Kevin emerged from the ashes as the project was roasted over the fire.
A Minecraft character meets Salad Fingers - that's Kevin. He's a frog-like creature whose reveal was such a terrible NFT that it became part of history – and a meme.
If you're laughing at people paying $8K for a silly pixelated image, you might need to take it back. Precisely because of this, lucky holders who minted Kevin have been able to sell the now-memed NFT for over 8 ETH (around $24,000 USD), with some currently listed for 100 ETH.
Of course, Twitter has been awash in memes mocking those who invested in the project, because what else can you do when so many people lose money?
It's still unclear if the NFT project is a scam, but the team behind it was hired on Upwork. There's still hope for redemption, but Kevin's rise to fame appears to be the only positive outcome so far.
[^1] This is not the first time the creator (A 20-yo New Zealanders) has sought money via an online platform and had people claiming he under-delivered. He raised $74,000 on Kickstarter for a card game called Psycho Chicken. There are hundreds of comments on the Kickstarter project saying they haven't received the product and pleading for a refund or an update.
You might also like

Frederick M. Hess
2 years ago
The Lessons of the Last Two Decades for Education Reform
My colleague Ilana Ovental and I examined pandemic media coverage of education at the end of last year. That analysis examined coverage changes. We tracked K-12 topic attention over the previous two decades using Lexis Nexis. See the results here.
I was struck by how cleanly the past two decades can be divided up into three (or three and a half) eras of school reform—a framing that can help us comprehend where we are and how we got here. In a time when epidemic, political unrest, frenetic news cycles, and culture war can make six months seem like a lifetime, it's worth pausing for context.
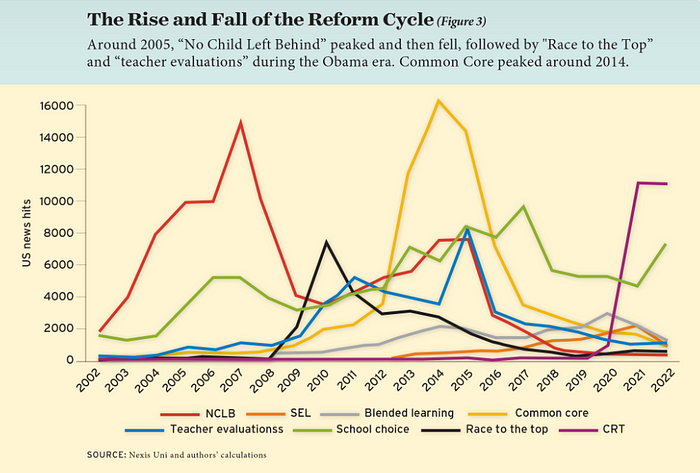
If you look at the peaks in the above graph, the 21st century looks to be divided into periods. The decade-long rise and fall of No Child Left Behind began during the Bush administration. In a few years, NCLB became the dominant K-12 framework. Advocates and financiers discussed achievement gaps and measured success with AYP.
NCLB collapsed under the weight of rigorous testing, high-stakes accountability, and a race to the bottom by the Obama years. Obama's Race to the Top garnered attention, but its most controversial component, the Common Core State Standards, rose quickly.
Academic standards replaced assessment and accountability. New math, fiction, and standards were hotly debated. Reformers and funders chanted worldwide benchmarking and systems interoperability.
We went from federally driven testing and accountability to government encouraged/subsidized/mandated (pick your verb) reading and math standardization. Last year, Checker Finn and I wrote The End of School Reform? The 2010s populist wave thwarted these objectives. The Tea Party, Occupy Wall Street, Black Lives Matter, and Trump/MAGA all attacked established institutions.
Consequently, once the Common Core fell, no alternative program emerged. Instead, school choice—the policy most aligned with populist suspicion of institutional power—reached a half-peak. This was less a case of choice erupting to prominence than of continuous growth in a vacuum. Even with Betsy DeVos' determined, controversial efforts, school choice received only half the media attention that NCLB and Common Core did at their heights.
Recently, culture clash-fueled attention to race-based curriculum and pedagogy has exploded (all playing out under the banner of critical race theory). This third, culture war-driven wave may not last as long as the other waves.
Even though I don't understand it, the move from slow-building policy debate to fast cultural confrontation over two decades is notable. I don't know if it's cyclical or permanent, or if it's about schooling, media, public discourse, or all three.
One final thought: After doing this work for decades, I've noticed how smoothly advocacy groups, associations, and other activists adapt to the zeitgeist. In 2007, mission statements focused on accomplishment disparities. Five years later, they promoted standardization. Language has changed again.
Part of this is unavoidable and healthy. Chasing currents can also make companies look unprincipled, promote scepticism, and keep them spinning the wheel. Bearing in mind that these tides ebb and flow may give educators, leaders, and activists more confidence to hold onto their values and pause when they feel compelled to follow the crowd.

Isaiah McCall
3 years ago
There is a new global currency emerging, but it is not bitcoin.
America should avoid BRICS

Vladimir Putin has watched videos of Muammar Gaddafi's CIA-backed demise.
Gaddafi...
Thief.
Did you know Gaddafi wanted a gold-backed dinar for Africa? Because he considered our global financial system was a Ponzi scheme, he wanted to discontinue trading oil in US dollars.
Or, Gaddafi's Libya enjoyed Africa's highest quality of living before becoming freed. Pictured:

Vladimir Putin is a nasty guy, but he had his reasons for not mentioning NATO assisting Ukraine in resisting US imperialism. Nobody tells you. Sure.
The US dollar's corruption post-2008, debasement by quantitative easing, and lack of value are key factors. BRICS will replace the dollar.
BRICS aren't bricks.
Economy-related.
Brazil, Russia, India, China, and South Africa have cooperated for 14 years to fight U.S. hegemony with a new international currency: BRICS.
BRICS is mostly comical. Now. Saudi Arabia, the second-largest oil hegemon, wants to join.
So what?
The New World Currency is BRICS
Russia was kicked out of G8 for its aggressiveness in Crimea in 2014.
It's now G7.
No biggie, said Putin, he said, and I quote, “Bon appetite.”
He was prepared. China, India, and Brazil lead the New World Order.
Together, they constitute 40% of the world's population and, according to the IMF, 50% of the world's GDP by 2030.
Here’s what the BRICS president Marcos Prado Troyjo had to say earlier this year about no longer needing the US dollar: “We have implemented the mechanism of mutual settlements in rubles and rupees, and there is no need for our countries to use the dollar in mutual settlements. And today a similar mechanism of mutual settlements in rubles and yuan is being developed by China.”
Ick. That's D.C. and NYC warmongers licking their chops for WW3 nasty.
Here's a lovely picture of BRICS to relax you:

If Saudi Arabia joins BRICS, as President Mohammed Bin Salman has expressed interest, a majority of the Middle East will have joined forces to construct a new world order not based on the US currency.
I'm not sure of the new acronym.
SBRICSS? CIRBSS? CRIBSS?
The Reason America Is Harvesting What It Sowed
BRICS began 14 years ago.
14 years ago, what occurred? Concentrate. It involved CDOs, bad subprime mortgages, and Wall Street quants crunching numbers.
2008 recession
When two nations trade, they do so in US dollars, not Euros or gold.
What happened when 2008, an avoidable crisis caused by US banks' cupidity and ignorance, what happened?
Everyone WORLDWIDE felt the pain.
Mostly due to corporate America's avarice.
This should have been a warning that China and Russia had enough of our bs. Like when France sent a battleship to America after Nixon scrapped the gold standard. The US was warned to shape up or be dethroned (or at least try).

Nixon improved in 1971. Kinda. Invented PetroDollar.
Another BS system that unfairly favors America and possibly pushed Russia, China, and Saudi Arabia into BRICS.
The PetroDollar forces oil-exporting nations to trade in US dollars and invest in US Treasury bonds. Brilliant. Genius evil.
Our misdeeds are:
In conflicts that are not its concern, the USA uses the global reserve currency as a weapon.
Targeted nations abandon the dollar, and rightfully so, as do nations that depend on them for trade in vital resources.
The dollar's position as the world's reserve currency is in jeopardy, which could have disastrous economic effects.
Although we have actually sown our own doom, we appear astonished. According to the Bible, whomever sows to appease his sinful nature will reap destruction from that nature whereas whoever sows to appease the Spirit will reap eternal life from the Spirit.
Americans, even our leaders, lack caution and delayed pleasure. When our unsustainable systems fail, we double down. Bailouts of the banks in 2008 were myopic, puerile, and another nail in America's hegemony.
America has screwed everyone.
We're unpopular.
The BRICS's future
It's happened before.
Saddam Hussein sold oil in Euros in 2000, and the US invaded Iraq a month later. The media has devalued the word conspiracy. The Iraq conspiracy.
There were no WMDs, but NYT journalists like Judy Miller drove Americans into a warmongering frenzy because Saddam would ruin the PetroDollar. Does anyone recall that this war spawned ISIS?
I think America has done good for the world. You can make a convincing case that we're many people's villain.
Learn more in Confessions of an Economic Hitman, The Devil's Chessboard, or Tyranny of the Federal Reserve. Or ignore it. That's easier.
We, America, should extend an olive branch, ask for forgiveness, and learn from our faults, as the Tao Te Ching advises. Unlikely. Our population is apathetic and stupid, and our government is corrupt.
Argentina, Iran, Egypt, and Turkey have also indicated interest in joining BRICS. They're also considering making it gold-backed, making it a new world reserve currency.
You should pay attention.
Thanks for reading!
Evgenii Nelepko
3 years ago
My 3 biggest errors as a co-founder and CEO
Reflections on the closed company Hola! Dating app

I'll discuss my fuckups as an entrepreneur and CEO. All of them refer to the dating app Hola!, which I co-founded and starred in.
Spring 2021 was when we started. Two techies and two non-techies created a dating app. Pokemon Go and Tinder were combined.
Online dating is a business, and it takes two weeks from a like to a date. We questioned online dating app users if they met anyone offline last year.
75% replied yes, 50% sometimes, 25% usually.
Offline dating is popular, yet people have concerns.
Men are reluctant to make mistakes in front of others.
Women are curious about the background of everyone who approaches them.
We designed unique mechanics that let people date after a match. No endless chitchat. Women would be safe while men felt like cowboys.
I wish to emphasize three faults that lead to founders' estrangement.
This detachment ultimately led to us shutting down the company.
The wrong technology stack
Situation
Instead of generating a faster MVP and designing an app in a universal stack for iOS and Android, I argued we should pilot the app separately for iOS and Android. Technical founders' expertise made this possible.
Self-reflection
Mistaken strategy. We lost time and resources developing two apps at once. We chose iOS since it's more profitable. Apple took us out after the release, citing Guideline 4.3 Spam. After 4 months, we had nothing. We had a long way to go to get the app on Android and the Store.
I suggested creating a uniform platform for the company's growth. This makes parallel product development easier. The strategist's lack of experience and knowledge made it a piece of crap.
What would I have changed if I could?
We should have designed an Android universal stack. I expected Apple to have issues with a dating app.
Our approach should have been to launch something and subsequently improve it, but prejudice won.
The lesson
Discuss the IT stack with your CTO. It saves time and money. Choose the easiest MVP method.
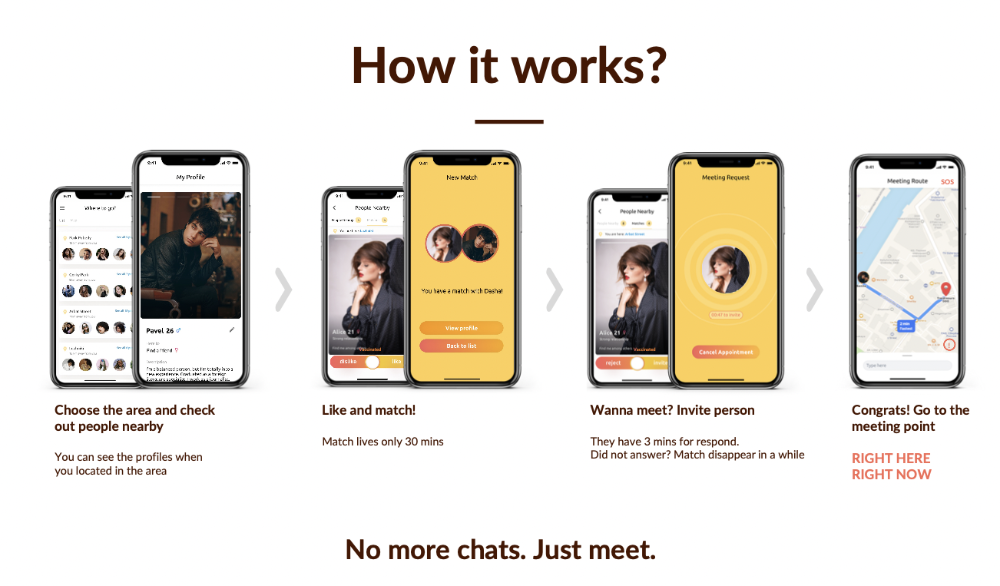
2. A tardy search for investments
Situation
Though the universe and other founders encouraged me to locate investors first, I started pitching when we almost had an app.
When angels arrived, it was time to close. The app was banned, war broke out, I left the country, and the other co-founders stayed. We had no savings.
Self-reflection
I loved interviewing users. I'm proud of having done 1,000 interviews. I wanted to understand people's pain points and improve the product.
Interview results no longer affected the product. I was terrified to start pitching. I filled out accelerator applications and redid my presentation. You must go through that so you won't be terrified later.
What would I have changed if I could?
Get an external or internal mentor to help me with my first pitch as soon as possible. I'd be supported if criticized. He'd cheer with me if there was enthusiasm.
In 99% of cases, I'm comfortable jumping into the unknown, but there are exceptions. The mentor's encouragement would have prompted me to act sooner.
The lesson
Begin fundraising immediately. Months may pass. Show investors your pre-MVP project. Draw inferences from feedback.
3. Role ambiguity
Situation
My technical co-founders were also part-time lead developers, which produced communication issues. As co-founders, we communicated well and recognized the problems. Stakes, vesting, target markets, and approach were agreed upon.
We were behind schedule. Technical debt and strategic gap grew.
Bi-daily and weekly reviews didn't help. Each time, there were explanations. Inside, I was freaking out.
Self-reflection
I am a fairly easy person to talk to. I always try to stick to agreements; otherwise, my head gets stuffed with unnecessary information, interpretations, and emotions.
Sit down -> talk -> decide -> do -> evaluate the results. Repeat it.
If I don't get detailed comments, I start ruining everyone's mood. If there's a systematic violation of agreements without a good justification, I won't join the project or I'll end the collaboration.
What would I have done otherwise?
This is where it’s scariest to draw conclusions. Probably the most logical thing would have been not to start the project as we started it. But that was already a completely different project. So I would not have done anything differently and would have failed again.
But I drew conclusions for the future.
The lesson
First-time founders should find an adviser or team coach for a strategic session. It helps split the roles and responsibilities.