



More on NFTs & Art
Nate Kostar
4 years ago
# DeaMau5’s PIXELYNX and Beatport Launch Festival NFTs
Pixelynx, a music metaverse gaming platform, has teamed up with Beatport, an online music retailer focusing in electronic music, to establish a Synth Heads non-fungible token (NFT) Collection.
Richie Hawtin, aka Deadmau5, and Joel Zimmerman, nicknamed Pixelynx, have invented a new music metaverse game platform called Pixelynx. In January 2022, they released their first Beatport NFT drop, which saw 3,030 generative NFTs sell out in seconds.
The limited edition Synth Heads NFTs will be released in collaboration with Junction 2, the largest UK techno festival, and having one will grant fans special access tickets and experiences at the London-based festival.
Membership in the Synth Head community, day passes to the Junction 2 Festival 2022, Junction 2 and Beatport apparel, special vinyl releases, and continued access to future ticket drops are just a few of the experiences available.
Five lucky NFT holders will also receive a Golden Ticket, which includes access to a backstage artist bar and tickets to Junction 2's next large-scale London event this summer, in addition to full festival entrance for both days.
The Junction 2 festival will take place at Trent Park in London on June 18th and 19th, and will feature performances from Four Tet, Dixon, Amelie Lens, Robert Hood, and a slew of other artists. Holders of the original Synth Head NFT will be granted admission to the festival's guestlist as well as line-jumping privileges.
The new Synth Heads NFTs collection contain 300 NFTs.
NFTs that provide IRL utility are in high demand.
The benefits of NFT drops related to In Real Life (IRL) utility aren't limited to Beatport and Pixelynx.
Coachella, a well-known music event, recently partnered with cryptocurrency exchange FTX to offer free NFTs to 2022 pass holders. Access to a dedicated entry lane, a meal and beverage pass, and limited-edition merchandise were all included with the NFTs.
Coachella also has its own NFT store on the Solana blockchain, where fans can buy Coachella NFTs and digital treasures that unlock exclusive on-site experiences, physical objects, lifetime festival passes, and "future adventures."
Individual artists and performers have begun taking advantage of NFT technology outside of large music festivals like Coachella.
DJ Tisto has revealed that he would release a VIP NFT for his upcoming "Eagle" collection during the EDC festival in Las Vegas in 2022. This NFT, dubbed "All Access Eagle," gives collectors the best chance to get NFTs from his first drop, as well as unique access to the music "Repeat It."
NFTs are one-of-a-kind digital assets that can be verified, purchased, sold, and traded on blockchains, opening up new possibilities for artists and businesses alike. Time will tell whether Beatport and Pixelynx's Synth Head NFT collection will be successful, but if it's anything like the first release, it's a safe bet.

Adrien Book
3 years ago
What is Vitalik Buterin's newest concept, the Soulbound NFT?
Decentralizing Web3's soul
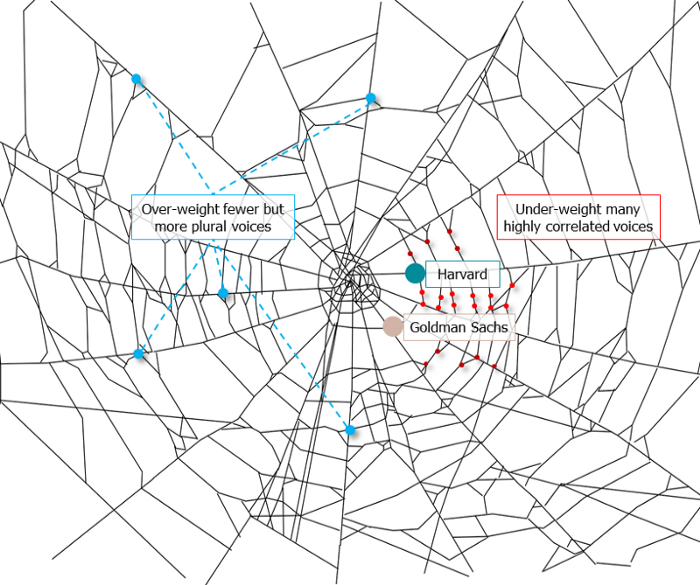
Our tech must reflect our non-transactional connections. Web3 arose from a lack of social links. It must strengthen these linkages to get widespread adoption. Soulbound NFTs help.
This NFT creates digital proofs of our social ties. It embodies G. Simmel's idea of identity, in which individuality emerges from social groups, just as social groups evolve from people.
It's multipurpose. First, gather online our distinctive social features. Second, highlight and categorize social relationships between entities and people to create a spiderweb of networks.
1. 🌐 Reducing online manipulation: Only socially rich or respectable crypto wallets can participate in projects, ensuring that no one can create several wallets to influence decentralized project governance.
2. 🤝 Improving social links: Some sectors of society lack social context. Racism, sexism, and homophobia do that. Public wallets can help identify and connect distinct social groupings.
3. 👩❤️💋👨 Increasing pluralism: Soulbound tokens can ensure that socially connected wallets have less voting power online to increase pluralism. We can also overweight a minority of numerous voices.
4. 💰Making more informed decisions: Taking out an insurance policy requires a life review. Why not loans? Character isn't limited by income, and many people need a chance.
5. 🎶 Finding a community: Soulbound tokens are accessible to everyone. This means we can find people who are like us but also different. This is probably rare among your friends and family.
NFTs are dangerous, and I don't like them. Social credit score, privacy, lost wallet. We must stay informed and keep talking to innovators.
E. Glen Weyl, Puja Ohlhaver and Vitalik Buterin get all the credit for these ideas, having written the very accessible white paper “Decentralized Society: Finding Web3’s Soul”.

nft now
4 years ago
A Guide to VeeFriends and Series 2
VeeFriends is one of the most popular and unique NFT collections. VeeFriends launched around the same time as other PFP NFTs like Bored Ape Yacht Club.
Vaynerchuk (GaryVee) took a unique approach to his large-scale project, which has influenced the NFT ecosystem. GaryVee's VeeFriends is one of the most successful NFT membership use-cases, allowing him to build a community around his creative and business passions.
What is VeeFriends?
GaryVee's NFT collection, VeeFriends, was released on May 11, 2021. VeeFriends [Mini Drops], Book Games, and a forthcoming large-scale "Series 2" collection all stem from the initial drop of 10,255 tokens.
In "Series 1," there are G.O.O. tokens (Gary Originally Owned). GaryVee reserved 1,242 NFTs (over 12% of the supply) for his own collection, so only 9,013 were available at the Series 1 launch.
Each Series 1 token represents one of 268 human traits hand-drawn by Vaynerchuk. Gary Vee's NFTs offer owners incentives.
Who made VeeFriends?
Gary Vaynerchuk, AKA GaryVee, is influential in NFT. Vaynerchuk is the chairman of New York-based communications company VaynerX. Gary Vee, CEO of VaynerMedia, VaynerSports, and bestselling author, is worth $200 million.
GaryVee went from NFT collector to creator, launching VaynerNFT to help celebrities and brands.
Vaynerchuk's influence spans the NFT ecosystem as one of its most prolific voices. He's one of the most influential NFT figures, and his VeeFriends ecosystem keeps growing.
Vaynerchuk, a trend expert, thinks NFTs will be around for the rest of his life and VeeFriends will be a landmark project.
Why use VeeFriends NFTs?
The first VeeFriends collection has sold nearly $160 million via OpenSea. GaryVee insisted that the first 10,255 VeeFriends were just the beginning.
Book Games were announced to the VeeFriends community in August 2021. Mini Drops joined VeeFriends two months later.
Book Games
GaryVee's book "Twelve and a Half: Leveraging the Emotional Ingredients for Business Success" inspired Book Games. Even prior to the announcement Vaynerchuk had mapped out the utility of the book on an NFT scale. Book Games tied his book to the VeeFriends ecosystem and solidified its place in the collection.
GaryVee says Book Games is a layer 2 NFT project with 125,000 burnable tokens. Vaynerchuk's NFT fans were incentivized to buy as many copies of his new book as possible to receive NFT rewards later.
First, a bit about “layer 2.”
Layer 2 blockchain solutions help scale applications by routing transactions away from Ethereum Mainnet (layer 1). These solutions benefit from Mainnet's decentralized security model but increase transaction speed and reduce gas fees.
Polygon (integrated into OpenSea) and Immutable X are popular Ethereum layer 2 solutions. GaryVee chose Immutable X to reduce gas costs (transaction fees). Given the large supply of Book Games tokens, this decision will likely benefit the VeeFriends community, especially if the games run forever.
What's the strategy?
The VeeFriends patriarch announced on Aug. 27, 2021, that for every 12 books ordered during the Book Games promotion, customers would receive one NFT via airdrop. After nearly 100 days, GV sold over a million copies and announced that Book Games would go gamified on Jan. 10, 2022.
Immutable X's trading options make Book Games a "game." Book Games players can trade NFTs for other NFTs, sports cards, VeeCon tickets, and other prizes. Book Games can also whitelist other VeeFirends projects, which we'll cover in Series 2.
VeeFriends Mini Drops
GaryVee launched VeeFriends Mini Drops two months after Book Games, focusing on collaboration, scarcity, and the characters' "cultural longevity."
Spooky Vees, a collection of 31 1/1 Halloween-themed VeeFriends, was released on Halloween. First-come, first-served VeeFriend owners could claim these NFTs.
Mini Drops includes Gift Goat NFTs. By holding the Gift Goat VeeFriends character, collectors will receive 18 exclusive gifts curated by GaryVee and the team. Each gifting experience includes one physical gift and one NFT out of 555, to match the 555 Gift Goat tokens.
Gift Goat holders have gotten NFTs from Danny Cole (Creature World), Isaac "Drift" Wright (Where My Vans Go), Pop Wonder, and more.
GaryVee is poised to release the largest expansion of the VeeFriends and VaynerNFT ecosystem to date with VeeFriends Series 2.
VeeCon 101
By owning VeeFriends NFTs, collectors can join the VeeFriends community and attend VeeCon in 2022. The conference is only open to VeeCon NFT ticket holders (VeeFreinds + possibly more TBA) and will feature Beeple, Steve Aoki, and even Snoop Dogg.
The VeeFreinds floor in 2022 Q1 has remained at 16 ETH ($52,000), making VeeCon unattainable for most NFT enthusiasts. Why would someone spend that much crypto on a Minneapolis "superconference" ticket? Because of Gary Vaynerchuk.
Everything to know about VeeFriends Series 2
Vaynerchuk revealed in April 2022 that the VeeFriends ecosystem will grow by 55,555 NFTs after months of teasing.
With VeeFriends Series 2, each token will cost $995 USD in ETH, allowing NFT enthusiasts to join at a lower cost. The new series will be released on multiple dates in April.
Book Games NFT holders on the Friends List (whitelist) can mint Series 2 NFTs on April 12. Book Games holders have 32,000 NFTs.
VeeFriends Series 1 NFT holders can claim Series 2 NFTs on April 12. This allotment's supply is 10,255, like Series 1's.
On April 25, the public can buy 10,000 Series 2 NFTs. Unminted Friends List NFTs will be sold on this date, so this number may change.
The VeeFriends ecosystem will add 15 new characters (220 tokens each) on April 27. One character will be released per day for 15 days, and the only way to get one is to enter a daily raffle with Book Games tokens.
Series 2 NFTs won't give owners VeeCon access, but they will offer other benefits within the VaynerNFT ecosystem. Book Games and Series 2 will get new token burn mechanics in the upcoming drop.
Visit the VeeFriends blog for the latest collection info.
Where can you buy Gary Vee’s NFTs?
Need a VeeFriend NFT? Gary Vee recommends doing "50 hours of homework" before buying. OpenSea sells VeeFriends NFTs.
You might also like

The Secret Developer
3 years ago
What Elon Musk's Take on Bitcoin Teaches Us

Tesla Q2 earnings revealed unethical dealings.
As of end of Q2, we have converted approximately 75% of our Bitcoin purchases into fiat currency
That’s OK then, isn’t it?
Elon Musk, Tesla's CEO, is now untrustworthy.
It’s not about infidelity, it’s about doing the right thing
And what can we learn?
The Opening Remark
Musk tweets on his (and Tesla's) future goals.
Don’t worry, I’m not expecting you to read it.
What's crucial?
Tesla will not be selling any Bitcoin
The Situation as It Develops
2021 Tesla spent $1.5 billion on Bitcoin. In 2022, they sold 75% of the ownership for $946 million.
That’s a little bit of a waste of money, right?
Musk predicted the reverse would happen.
What gives? Why would someone say one thing, then do the polar opposite?
The Justification For Change
Tesla's public. They must follow regulations. When a corporation trades, they must record what happens.
At least this keeps Musk some way in line.
We now understand Musk and Tesla's actions.
Musk claimed that Tesla sold bitcoins to maximize cash given the unpredictability of COVID lockdowns in China.
Tesla may buy Bitcoin in the future, he said.
That’s fine then. He’s not knocking the NFT at least.
Tesla has moved investments into cash due to China lockdowns.
That doesn’t explain the 180° though
Musk's Tweet isn't company policy. Therefore, the CEO's change of heart reflects the organization. Look.
That's okay, since
Leaders alter their positions when circumstances change.
Leaders must adapt to their surroundings. This isn't embarrassing; it's a leadership prerequisite.
Yet
The Man
Someone stated if you're not in the office full-time, you need to explain yourself. He doesn't treat his employees like adults.
This is the individual mentioned in the quote.
If Elon was not happy, you knew it. Things could get nasty
also, He fired his helper for requesting a raise.
This public persona isn't good. Without mentioning his disastrous performances on Twitter (pedo dude) or Joe Rogan. This image sums up the odd Podcast appearance:

Which describes the man.
I wouldn’t trust this guy to feed a cat
What we can discover
When Musk's company bet on Bitcoin, what happened?
Exactly what we would expect
The company's position altered without the CEO's awareness. He seems uncaring.
This article is about how something happened, not what happened. Change of thinking requires contrition.
This situation is about a lack of respect- although you might argue that followers on Twitter don’t deserve any
Tesla fans call the sale a great move.
It's absurd.
As you were, then.
Conclusion
Good luck if you gamble.
When they pay off, congrats!
When wrong, admit it.
You must take chances if you want to succeed.
Risks don't always pay off.
Mr. Musk lacks insight and charisma to combine these two attributes.
I don’t like him, if you hadn’t figured.
It’s probably all of the cheating.

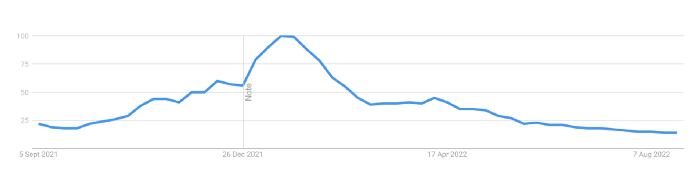
Bastian Hasslinger
3 years ago
Before 2021, most startups had excessive valuations. It is currently causing issues.

Higher startup valuations are often favorable for all parties. High valuations show a business's potential. New customers and talent are attracted. They earn respect.
Everyone benefits if a company's valuation rises.
Founders and investors have always been incentivized to overestimate a company's value.
Post-money valuations were inflated by 2021 market expectations and the valuation model's mechanisms.
Founders must understand both levers to handle a normalizing market.
2021, the year of miracles
2021 must've seemed miraculous to entrepreneurs, employees, and VCs. Valuations rose, and funding resumed after the first Covid-19 epidemic caution.
In 2021, VC investments increased from $335B to $643B. 518 new worldwide unicorns vs. 134 in 2020; 951 US IPOs vs. 431.
Things can change quickly, as 2020-21 showed.
Rising interest rates, geopolitical developments, and normalizing technology conditions drive down share prices and tech company market caps in 2022. Zoom, the poster-child of early lockdown success, is down 37% since 1st Jan.
Once-inflated valuations can become a problem in a normalizing market, especially for founders, employees, and early investors.
the reason why startups are always overvalued
To see why inflated valuations are a problem, consider one of its causes.
Private company values only fluctuate following a new investment round, unlike publicly-traded corporations. The startup's new value is calculated simply:
(Latest round share price) x (total number of company shares)
This is the industry standard Post-Money Valuation model.
Let’s illustrate how it works with an example. If a VC invests $10M for 1M shares (at $10/share), and the company has 10M shares after the round, its Post-Money Valuation is $100M (10/share x 10M shares).
This approach might seem like the most natural way to assess a business, but the model often unintentionally overstates the underlying value of the company even if the share price paid by the investor is fair. All shares aren't equal.
New investors in a corporation will always try to minimize their downside risk, or the amount they lose if things go wrong. New investors will try to negotiate better terms and pay a premium.
How the value of a struggling SpaceX increased
SpaceX's 2008 Series D is an example. Despite the financial crisis and unsuccessful rocket launches, the company's Post-Money Valuation was 36% higher after the investment round. Why?
Series D SpaceX shares were protected. In case of liquidation, Series D investors were guaranteed a 2x return before other shareholders.
Due to downside protection, investors were willing to pay a higher price for this new share class.
The Post-Money Valuation model overpriced SpaceX because it viewed all the shares as equal (they weren't).
Why entrepreneurs, workers, and early investors stand to lose the most
Post-Money Valuation is an effective and sufficient method for assessing a startup's valuation, despite not taking share class disparities into consideration.
In a robust market, where the firm valuation will certainly expand with the next fundraising round or exit, the inflated value is of little significance.
Fairness endures. If a corporation leaves at a greater valuation, each stakeholder will receive a proportional distribution. (i.e., 5% of a $100M corporation yields $5M).
SpaceX's inherent overvaluation was never a problem. Had it been sold for less than its Post-Money Valuation, some shareholders, including founders, staff, and early investors, would have seen their ownership drop.
The unforgiving world of 2022
In 2022, founders, employees, and investors who benefited from inflated values will face below-valuation exits and down-rounds.
For them, 2021 will be a curse, not a blessing.
Some tech giants are worried. Klarna's valuation fell from $45B (Oct 21) to $30B (Jun 22), Canvas from $40B to $27B, and GoPuffs from $17B to $8.3B.
Shazam and Blue Apron have to exit or IPO at a cheaper price. Premium share classes are protected, while others receive less. The same goes for bankrupts.
Those who continue at lower valuations will lose reputation and talent. When their value declines by half, generous employee stock options become less enticing, and their ability to return anything is questioned.
What can we infer about the present situation?
Such techniques to enhance your company's value or stop a normalizing market are fiction.
The current situation is a painful reminder for entrepreneurs and a crucial lesson for future firms.
The devastating market fall of the previous six months has taught us one thing:
Keep in mind that any valuation is speculative. Money Post A startup's valuation is a highly simplified approximation of its true value, particularly in the early phases when it lacks significant income or a cutting-edge product. It is merely a projection of the future and a hypothetical meter. Until it is achieved by an exit, a valuation is nothing more than a number on paper.
Assume the value of your company is lower than it was in the past. Your previous valuation might not be accurate now due to substantial changes in the startup financing markets. There is little reason to think that your company's value will remain the same given the 50%+ decline in many newly listed IT companies. Recognize how the market situation is changing and use caution.
Recognize the importance of the stake you hold. Each share class has a unique value that varies. Know the sort of share class you own and how additional contractual provisions affect the market value of your security. Frameworks have been provided by Metrick and Yasuda (Yale & UC) and Gornall and Strebulaev (Stanford) for comprehending the terms that affect investors' cash-flow rights upon withdrawal. As a result, you will be able to more accurately evaluate your firm and determine the worth of each share class.
Be wary of approving excessively protective share terms.
The trade-offs should be considered while negotiating subsequent rounds. Accepting punitive contractual terms could first seem like a smart option in order to uphold your inflated worth, but you should proceed with caution. Such provisions ALWAYS result in misaligned shareholders, with common shareholders (such as you and your staff) at the bottom of the list.

Alex Mathers
3 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.