


More on Entrepreneurship/Creators

Startup Journal
3 years ago
The Top 14 Software Business Ideas That Are Sure To Succeed in 2023
Software can change any company.

Software is becoming essential. Everyone should consider how software affects their lives and others'.
Software on your phone, tablet, or computer offers many new options. We're experts in enough ways now.
Software Business Ideas will be popular by 2023.
ERP Programs
ERP software meets rising demand.
ERP solutions automate and monitor tasks that large organizations, businesses, and even schools would struggle to do manually.
ERP software could reach $49 billion by 2024.
CRM Program
CRM software is a must-have for any customer-focused business.
Having an open mind about your business services and products allows you to change platforms.
Another company may only want your CRM service.
Medical software
Healthcare facilities need reliable, easy-to-use software.
EHRs, MDDBs, E-Prescribing, and more are software options.
The global medical software market could reach $11 billion by 2025, and mobile medical apps may follow.
Presentation Software in the Cloud
SaaS presentation tools are great.
They're easy to use, comprehensive, and full of traditional Software features.
In today's cloud-based world, these solutions make life easier for people. We don't know about you, but we like it.
Software for Project Management
People began working remotely without signs or warnings before the 2020 COVID-19 pandemic.
Many organizations found it difficult to track projects and set deadlines.
With PMP software tools, teams can manage remote units and collaborate effectively.
App for Blockchain-Based Invoicing
This advanced billing and invoicing solution is for businesses and freelancers.
These blockchain-based apps can calculate taxes, manage debts, and manage transactions.
Intelligent contracts help blockchain track transactions more efficiently. It speeds up and improves invoice generation.
Software for Business Communications
Internal business messaging is tricky.
Top business software tools for communication can share files, collaborate on documents, host video conferences, and more.
Payroll Automation System
Software development also includes developing an automated payroll system.
These software systems reduce manual tasks for timely employee payments.
These tools help enterprise clients calculate total wages quickly, simplify tax calculations, improve record-keeping, and support better financial planning.
System for Detecting Data Leaks
Both businesses and individuals value data highly. Yahoo's data breach is dangerous because of this.
This area of software development can help people protect their data.
You can design an advanced data loss prevention system.
AI-based Retail System
AI-powered shopping systems are popular. The systems analyze customers' search and purchase patterns and store history and are equipped with a keyword database.
These systems offer many customers pre-loaded products.
AI-based shopping algorithms also help users make purchases.
Software for Detecting Plagiarism
Software can help ensure your projects are original and not plagiarized.
These tools detect plagiarized content that Google, media, and educational institutions don't like.
Software for Converting Audio to Text
Machine Learning converts speech to text automatically.
These programs can quickly transcribe cloud-based files.
Software for daily horoscopes
Daily and monthly horoscopes will continue to be popular.
Software platforms that can predict forecasts, calculate birth charts, and other astrology resources are good business ideas.
E-learning Programs
Traditional study methods are losing popularity as virtual schools proliferate and physical space shrinks.
Khan Academy online courses are the best way to keep learning.
Online education portals can boost your learning. If you want to start a tech startup, consider creating an e-learning program.
Conclusion
Software is booming. There's never been a better time to start a software development business, with so many people using computers and smartphones. This article lists eight business ideas for 2023. Consider these ideas if you're just starting out or looking to expand.

Jayden Levitt
3 years ago
Billionaire who was disgraced lost his wealth more quickly than anyone in history
If you're not genuine, you'll be revealed.

Sam Bankman-Fried (SBF) was called the Cryptocurrency Warren Buffet.
No wonder.
SBF's trading expertise, Blockchain knowledge, and ability to construct FTX attracted mainstream investors.
He had a fantastic worldview, donating much of his riches to charity.
As the onion layers peel back, it's clear he wasn't the altruistic media figure he portrayed.
SBF's mistakes were disastrous.
Customer deposits were traded and borrowed by him.
With ten other employees, he shared a $40 million mansion where they all had polyamorous relationships.
Tone-deaf and wasteful marketing expenditures, such as the $200 million spent to change the name of the Miami Heat stadium to the FTX Arena
Democrats received a $40 million campaign gift.
And now there seems to be no regret.
FTX was a 32-billion-dollar cryptocurrency exchange.
It went bankrupt practically overnight.
SBF, FTX's creator, exploited client funds to leverage trade.
FTX had $1 billion in customer withdrawal reserves against $9 billion in liabilities in sister business Alameda Research.
Bloomberg Billionaire Index says it's the largest and fastest net worth loss in history.
It gets worse.
SBF's net worth is $900 Million, however he must still finalize FTX's bankruptcy.
SBF's arrest in the Bahamas and SEC inquiry followed news that his cryptocurrency exchange had crashed, losing billions in customer deposits.
A journalist contacted him on Twitter D.M., and their exchange is telling.
His ideas are revealed.
Kelsey Piper says they didn't expect him to answer because people under investigation don't comment.
Bankman-Fried wanted to communicate, and the interaction shows he has little remorse.
SBF talks honestly about FTX gaming customers' money and insults his competition.
Reporter Kelsey Piper was outraged by what he said and felt the mistakes SBF says plague him didn't evident in the messages.
Before FTX's crash, SBF was a poster child for Cryptocurrency regulation and avoided criticizing U.S. regulators.
He tells Piper that his lobbying is just excellent PR.
It shows his genuine views and supports cynics' opinions that his attempts to win over U.S. authorities were good for his image rather than Crypto.
SBF’s responses are in Grey, and Pipers are in Blue.
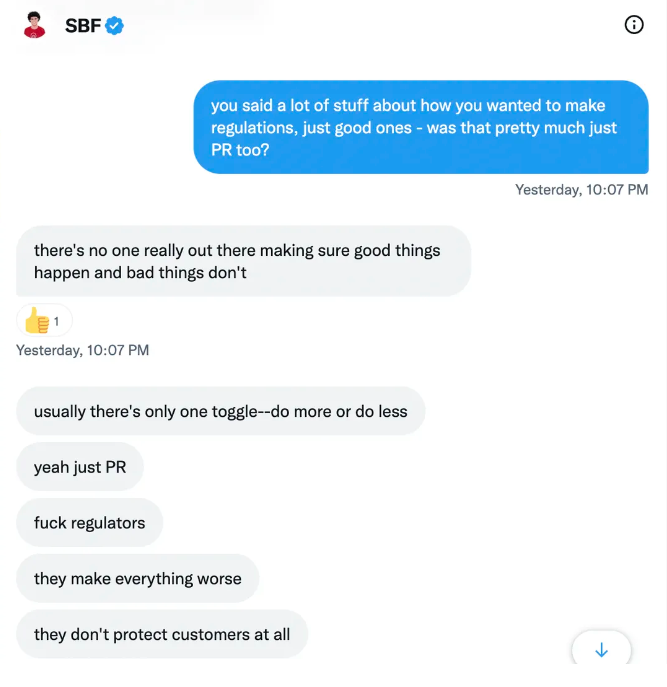
It's unclear if SBF cut corners for his gain. In their Twitter exchange, Piper revisits an interview question about ethics.
SBF says, "All the foolish sh*t I said"
SBF claims FTX has never invested customer monies.
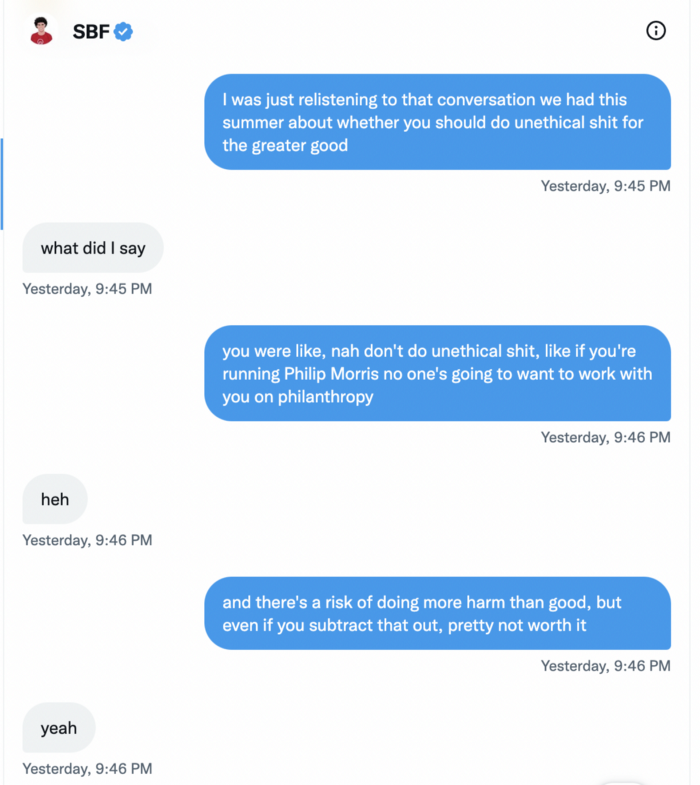
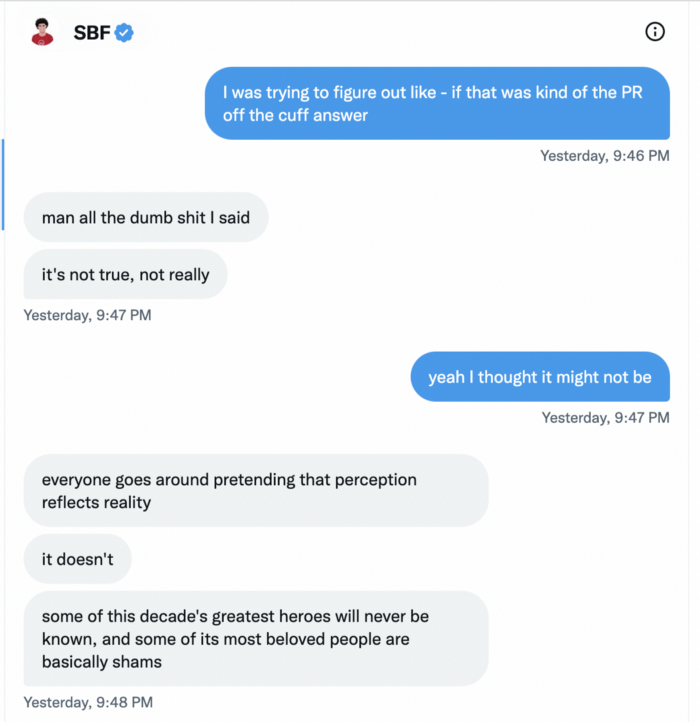
Piper challenged him on Twitter.
While he insisted FTX didn't use customer deposits, he said sibling business Alameda borrowed too much from FTX's balance sheet.
He did, basically.
When consumers tried to withdraw money, FTX was short.
SBF thought Alameda had enough money to cover FTX customers' withdrawals, but life sneaks up on you.
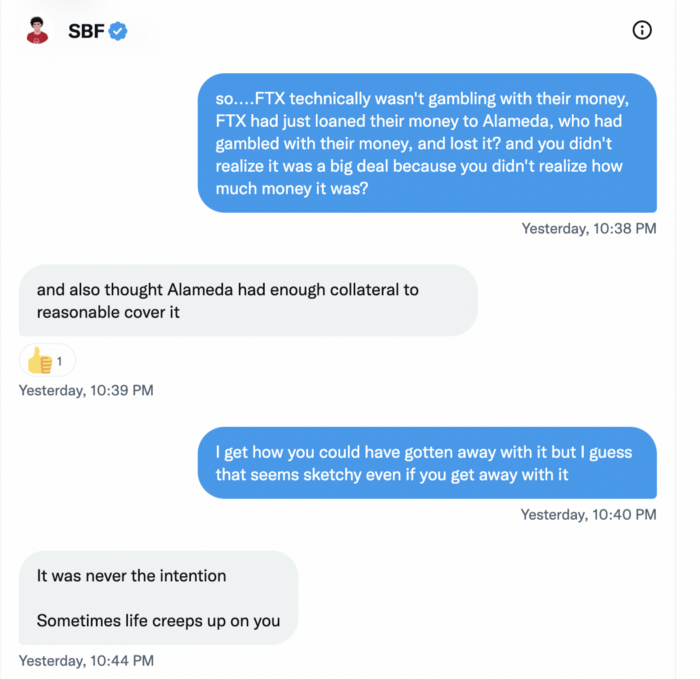
SBF believes most exchanges have done something similar to FTX, but they haven't had a bank run (a bunch of people all wanting to get their deposits out at the same time).
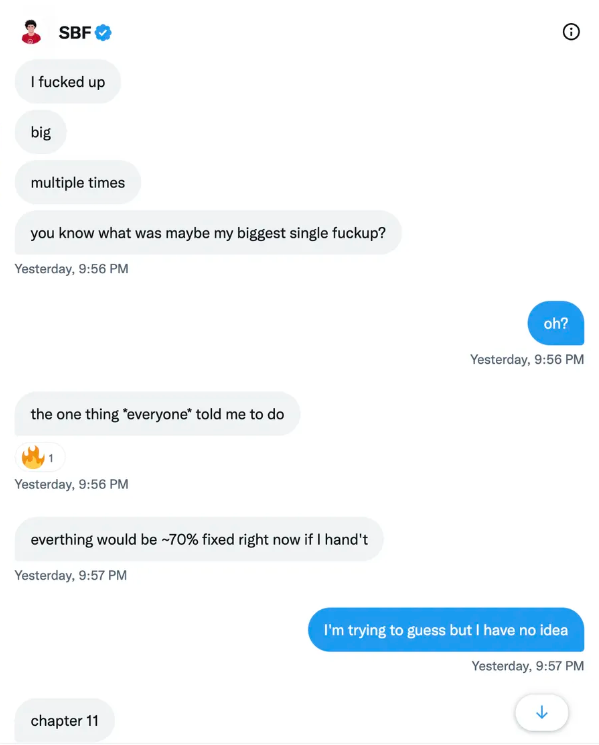
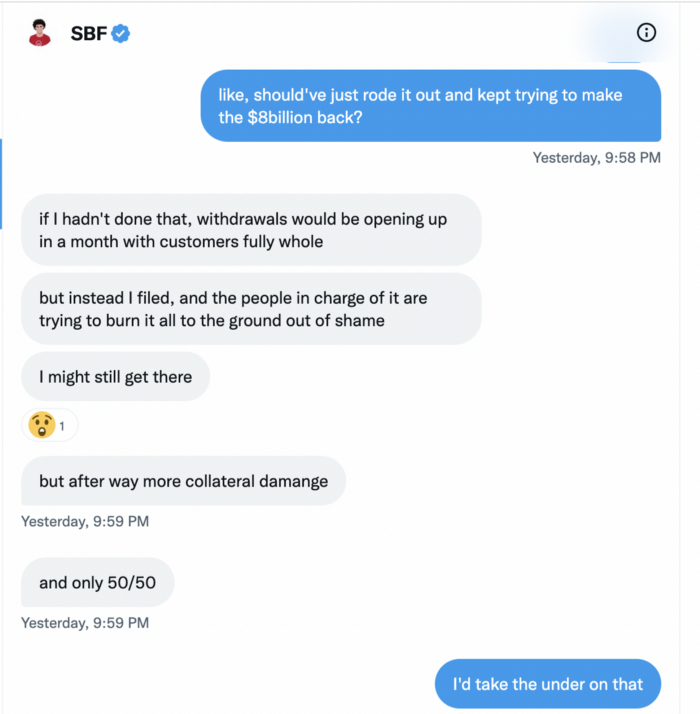
SBF believes he shouldn't have consented to the bankruptcy and kept attempting to raise more money because withdrawals would be open in a month with clients whole.
If additional money came in, he needed $8 billion to bridge the creditors' deficit, and there aren't many corporations with $8 billion to spare.
Once clients feel protected, they will continue to leave their assets on the exchange, according to one idea.
Kevin OLeary, a world-renowned hedge fund manager, says not all investors will walk through the open gate once the company is safe, therefore the $8 Billion wasn't needed immediately.
SBF claims the bankruptcy was his biggest error because he could have accumulated more capital.
Final Reflections
Sam Bankman-Fried, 30, became the world's youngest billionaire in four years.
Never listen to what people say about investing; watch what they do.
SBF is a trader who gets wrecked occasionally.
Ten first-time entrepreneurs ran FTX, screwing each other with no risk management.
It prevents opposing or challenging perspectives and echo chamber highs.
Twitter D.M. conversation with a journalist is the final nail.
He lacks an experienced crew.
This event will surely speed up much-needed regulation.
It's also prompted cryptocurrency exchanges to offer proof of reserves to calm customers.
Evgenii Nelepko
3 years ago
My 3 biggest errors as a co-founder and CEO
Reflections on the closed company Hola! Dating app

I'll discuss my fuckups as an entrepreneur and CEO. All of them refer to the dating app Hola!, which I co-founded and starred in.
Spring 2021 was when we started. Two techies and two non-techies created a dating app. Pokemon Go and Tinder were combined.
Online dating is a business, and it takes two weeks from a like to a date. We questioned online dating app users if they met anyone offline last year.
75% replied yes, 50% sometimes, 25% usually.
Offline dating is popular, yet people have concerns.
Men are reluctant to make mistakes in front of others.
Women are curious about the background of everyone who approaches them.
We designed unique mechanics that let people date after a match. No endless chitchat. Women would be safe while men felt like cowboys.
I wish to emphasize three faults that lead to founders' estrangement.
This detachment ultimately led to us shutting down the company.
The wrong technology stack
Situation
Instead of generating a faster MVP and designing an app in a universal stack for iOS and Android, I argued we should pilot the app separately for iOS and Android. Technical founders' expertise made this possible.
Self-reflection
Mistaken strategy. We lost time and resources developing two apps at once. We chose iOS since it's more profitable. Apple took us out after the release, citing Guideline 4.3 Spam. After 4 months, we had nothing. We had a long way to go to get the app on Android and the Store.
I suggested creating a uniform platform for the company's growth. This makes parallel product development easier. The strategist's lack of experience and knowledge made it a piece of crap.
What would I have changed if I could?
We should have designed an Android universal stack. I expected Apple to have issues with a dating app.
Our approach should have been to launch something and subsequently improve it, but prejudice won.
The lesson
Discuss the IT stack with your CTO. It saves time and money. Choose the easiest MVP method.
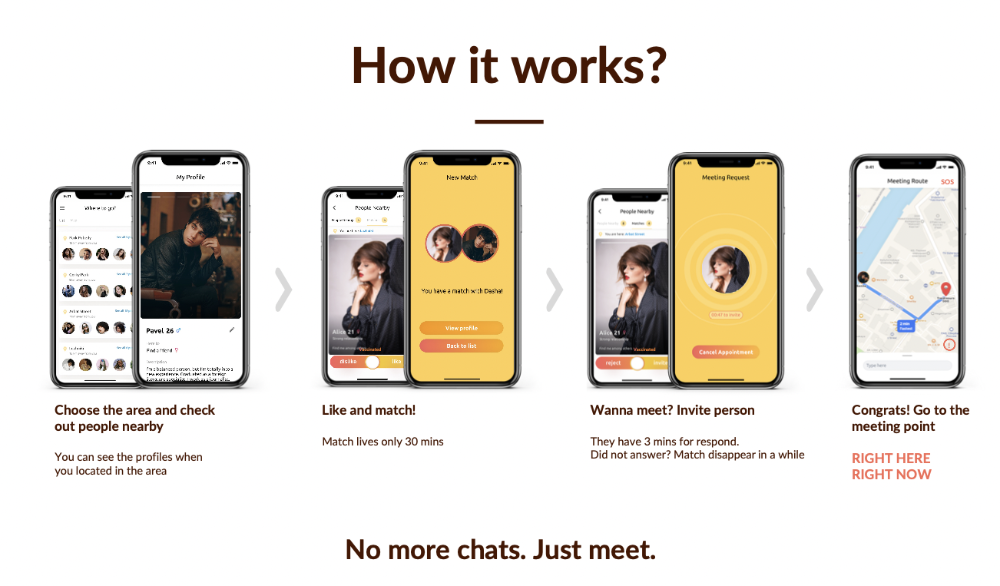
2. A tardy search for investments
Situation
Though the universe and other founders encouraged me to locate investors first, I started pitching when we almost had an app.
When angels arrived, it was time to close. The app was banned, war broke out, I left the country, and the other co-founders stayed. We had no savings.
Self-reflection
I loved interviewing users. I'm proud of having done 1,000 interviews. I wanted to understand people's pain points and improve the product.
Interview results no longer affected the product. I was terrified to start pitching. I filled out accelerator applications and redid my presentation. You must go through that so you won't be terrified later.
What would I have changed if I could?
Get an external or internal mentor to help me with my first pitch as soon as possible. I'd be supported if criticized. He'd cheer with me if there was enthusiasm.
In 99% of cases, I'm comfortable jumping into the unknown, but there are exceptions. The mentor's encouragement would have prompted me to act sooner.
The lesson
Begin fundraising immediately. Months may pass. Show investors your pre-MVP project. Draw inferences from feedback.
3. Role ambiguity
Situation
My technical co-founders were also part-time lead developers, which produced communication issues. As co-founders, we communicated well and recognized the problems. Stakes, vesting, target markets, and approach were agreed upon.
We were behind schedule. Technical debt and strategic gap grew.
Bi-daily and weekly reviews didn't help. Each time, there were explanations. Inside, I was freaking out.
Self-reflection
I am a fairly easy person to talk to. I always try to stick to agreements; otherwise, my head gets stuffed with unnecessary information, interpretations, and emotions.
Sit down -> talk -> decide -> do -> evaluate the results. Repeat it.
If I don't get detailed comments, I start ruining everyone's mood. If there's a systematic violation of agreements without a good justification, I won't join the project or I'll end the collaboration.
What would I have done otherwise?
This is where it’s scariest to draw conclusions. Probably the most logical thing would have been not to start the project as we started it. But that was already a completely different project. So I would not have done anything differently and would have failed again.
But I drew conclusions for the future.
The lesson
First-time founders should find an adviser or team coach for a strategic session. It helps split the roles and responsibilities.
You might also like

Datt Panchal
3 years ago
The Learning Habit

The Habit of Learning implies constantly learning something new. One daily habit will make you successful. Learning will help you succeed.
Most successful people continually learn. Success requires this behavior. Daily learning.
Success loves books. Books offer expert advice. Everything is online today. Most books are online, so you can skip the library. You must download it and study for 15-30 minutes daily. This habit changes your thinking.

Typical Successful People
Warren Buffett reads 500 pages of corporate reports and five newspapers for five to six hours each day.
Each year, Bill Gates reads 50 books.
Every two weeks, Mark Zuckerberg reads at least one book.
According to his brother, Elon Musk studied two books a day as a child and taught himself engineering and rocket design.
Learning & Making Money Online
No worries if you can't afford books. Everything is online. YouTube, free online courses, etc.

How can you create this behavior in yourself?
1) Consider what you want to know
Before learning, know what's most important. So, move together.
Set a goal and schedule learning.
After deciding what you want to study, create a goal and plan learning time.
3) GATHER RESOURCES
Get the most out of your learning resources. Online or offline.

Emma Jade
3 years ago
6 hacks to create content faster
Content gurus' top time-saving hacks.

I'm a content strategist, writer, and graphic designer. Time is more valuable than money.
Money is always available. Even if you're poor. Ways exist.
Time is passing, and one day we'll run out.
Sorry to be morbid.
In today's digital age, you need to optimize how you create content for your organization. Here are six content creation hacks.
1. Use templates
Use templates to streamline your work whether generating video, images, or documents.
Setup can take hours. Using a free resource like Canva, you can create templates for any type of material.
This will save you hours each month.
2. Make a content calendar
You post without a plan? A content calendar solves 50% of these problems.
You can prepare, organize, and plan your material ahead of time so you're not scrambling when you remember, "Shit, it's Mother's Day!"
3. Content Batching
Batching content means creating a lot in one session. This is helpful for video content that requires a lot of setup time.
Batching monthly content saves hours. Time is a valuable resource.
When working on one type of task, it's easy to get into a flow state. This saves time.
4. Write Caption
On social media, we generally choose the image first and then the caption. Writing captions first sometimes work better, though.
Writing the captions first can allow you more creative flexibility and be easier if you're not excellent with language.
Say you want to tell your followers something interesting.
Writing a caption first is easier than choosing an image and then writing a caption to match.
Not everything works. You may have already-created content that needs captioning. When you don't know what to share, think of a concept, write the description, and then produce a video or graphic.
Cats can be skinned in several ways..
5. Repurpose
Reuse content when possible. You don't always require new stuff. In fact, you’re pretty stupid if you do #SorryNotSorry.
Repurpose old content. All those blog entries, videos, and unfinished content on your desk or hard drive.
This blog post can be turned into a social media infographic. Canva's motion graphic function can animate it. I can record a YouTube video regarding this issue for a podcast. I can make a post on each point in this blog post and turn it into an eBook or paid course.
And it doesn’t stop there.
My point is, to think outside the box and really dig deep into ways you can leverage the content you’ve already created.
6. Schedule Them
If you're still manually posting content, get help. When you batch your content, schedule it ahead of time.
Some scheduling apps are free or cheap. No excuses.
Don't publish and ghost.
Scheduling saves time by preventing you from doing it manually. But if you never engage with your audience, the algorithm won't reward your material.
Be online and engage your audience.
Content Machine
Use these six content creation hacks. They help you succeed and save time.

Erik Engheim
4 years ago
You Misunderstand the Russian Nuclear Threat
Many believe Putin is simply sabre rattling and intimidating us. They see no threat of nuclear war. We can send NATO troops into Ukraine without risking a nuclear war.
I keep reading that Putin is just using nuclear blackmail and that a strong leader will call the bluff. That, in my opinion, misunderstands the danger of sending NATO into Ukraine.
It assumes that once NATO moves in, Putin can either push the red nuclear button or not.
Sure, Putin won't go nuclear if NATO invades Ukraine. So we're safe? Can't we just move NATO?
No, because history has taught us that wars often escalate far beyond our initial expectations. One domino falls, knocking down another. That's why having clear boundaries is vital. Crossing a seemingly harmless line can set off a chain of events that are unstoppable once started.
One example is WWI. The assassin of Archduke Franz Ferdinand could not have known that his actions would kill millions. They couldn't have known that invading Serbia to punish them for not handing over the accomplices would start a world war. Every action triggered a counter-action, plunging Europe into a brutal and bloody war. Each leader saw their actions as limited, not realizing how they kept the dominos falling.
Nobody can predict the future, but it's easy to imagine how NATO intervention could trigger a chain of events leading to a total war. Let me suggest some outcomes.
NATO creates a no-fly-zone. In retaliation, Russia bombs NATO airfields. Russia may see this as a limited counter-move that shouldn't cause further NATO escalation. They think it's a reasonable response to force NATO out of Ukraine. Nobody has yet thought to use the nuke.
Will NATO act? Polish airfields bombed, will they be stuck? Is this an article 5 event? If so, what should be done?
It could happen. Maybe NATO sends troops into Ukraine to punish Russia. Maybe NATO will bomb Russian airfields.
Putin's response Is bombing Russian airfields an invasion or an attack? Remember that Russia has always used nuclear weapons for defense, not offense. But let's not panic, let's assume Russia doesn't go nuclear.
Maybe Russia retaliates by attacking NATO military bases with planes. Maybe they use ships to attack military targets. How does NATO respond? Will they fight Russia in Ukraine or escalate? Will they invade Russia or attack more military installations there?
Seen the pattern? As each nation responds, smaller limited military operations can grow in scope.
So far, the Russian military has shown that they begin with less brutal methods. As losses and failures increase, brutal means are used. Syria had the same. Assad used chemical weapons and attacked hospitals, schools, residential areas, etc.
A NATO invasion of Ukraine would cost Russia dearly. “Oh, this isn't looking so good, better pull out and finish this war,” do you think? No way. Desperate, they will resort to more brutal tactics. If desperate, Russia has a huge arsenal of ugly weapons. They have nerve agents, chemical weapons, and other nasty stuff.
What happens if Russia uses chemical weapons? What if Russian nerve agents kill NATO soldiers horribly? West calls for retaliation will grow. Will we invade Russia? Will we bomb them?
We are angry and determined to punish war criminal Putin, so NATO tanks may be heading to Moscow. We want vengeance for his chemical attacks and bombing of our cities.
Do you think the distance between that red nuclear button and Putin's finger will be that far once NATO tanks are on their way to Moscow?
We might avoid a nuclear apocalypse. A NATO invasion force or even Western cities may be used by Putin. Not as destructive as ICBMs. Putin may think we won't respond to tactical nukes with a full nuclear counterattack. Why would we risk a nuclear Holocaust by launching ICBMs on Russia?
Maybe. My point is that at every stage of the escalation, one party may underestimate the other's response. This war is spiraling out of control and the chances of a nuclear exchange are increasing. Nobody really wants it.
Fear, anger, and resentment cause it. If Putin and his inner circle decide their time is up, they may no longer care about the rest of the world. We saw it with Hitler. Hitler, seeing the end of his empire, ordered the destruction of Germany. Nobody should win if he couldn't. He wanted to destroy everything, including Paris.
In other words, the danger isn't what happens after NATO intervenes The danger is the potential chain reaction. Gambling has a psychological equivalent. It's best to exit when you've lost less. We humans are willing to take small risks for big rewards. To avoid losses, we are willing to take high risks. Daniel Kahneman describes this behavior in his book Thinking, Fast and Slow.
And so bettors who have lost a lot begin taking bigger risks to make up for it. We get a snowball effect. NATO involvement in the Ukraine conflict is akin to entering a casino and placing a bet. We'll start taking bigger risks as we start losing to Russian retaliation. That's the game's psychology.
It's impossible to stop. So will politicians and citizens from both Russia and the West, until we risk the end of human civilization.
You can avoid spiraling into ever larger bets in the Casino by drawing a hard line and declaring “I will not enter that Casino.” We're doing it now. We supply Ukraine. We send money and intelligence but don't cross that crucial line.
It's difficult to watch what happened in Bucha without demanding NATO involvement. What should we do? Of course, I'm not in charge. I'm a writer. My hope is that people will think about the consequences of the actions we demand. My hope is that you think ahead not just one step but multiple dominos.
More and more, we are driven by our emotions. We cannot act solely on emotion in matters of life and death. If we make the wrong choice, more people will die.
Read the original post here.