



More on Marketing

Shruti Mishra
3 years ago
How to get 100k profile visits on Twitter each month without spending a dime

As a marketer, I joined Twitter on August 31, 2022 to use it.
Growth has been volatile, causing up-and-down engagements. 500 followers in 11 days.
I met amazing content creators, marketers, and people.
Those who use Twitter may know that one-liners win the algorithm, especially if they're funny or humorous, but as a marketer I can't risk posting content that my audience won't like.
I researched, learned some strategies, and A/B tested; some worked, some didn't.
In this article, I share what worked for me so you can do the same.
Thanks for reading!
Let's check my Twitter stats.

Tweets: how many tweets I sent in the first 28 days.
A user may be presented with a Tweet in their timeline or in search results.
In-person visits how many times my Twitter profile was viewed in the first 28 days.
Mentions: the number of times a tweet has mentioned my name.
Number of followers: People who were following me
Getting 500 Twitter followers isn't difficult.
Not easy, but doable.
Follow these steps to begin:
Determine your content pillars in step 1.
My formula is Growth = Content + Marketing + Community.
I discuss growth strategies.
My concept for growth is : 1. Content = creating / writing + sharing content in my niche. 2. Marketing = Marketing everything in business + I share my everyday learnings in business, marketing & entrepreneurship. 3. Community = Building community of like minded individuals (Also,I share how to’s) + supporting marketers to build & grow through community building.
Identify content pillars to create content for your audience.
2. Make your profile better
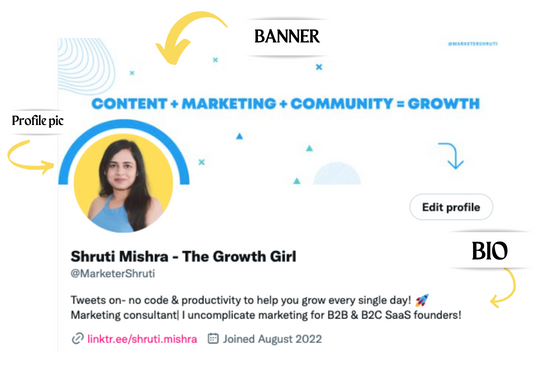
Create a profile picture. Your recognition factor is this.
Professional headshots are worthwhile.
This tool can help you create a free, eye-catching profile pic.
Use a niche-appropriate avatar if you don't want to show your face.
2. Create a bio that converts well mainly because first impressions count.
what you're sharing + why + +social proof what are you making
Be brief and precise. (155 characters)
3. Configure your banner
Banners complement profile pictures.
Use this space to explain what you do and how Twitter followers can benefit.
Canva's Twitter header maker is free.
Birdy can test multiple photo, bio, and banner combinations to optimize your profile.
Versions A and B of your profile should be completed.
Find the version that converts the best.
Use the profile that converts the best.
4. Special handle
If your username/handle is related to your niche, it will help you build authority and presence among your audience. Mine on Twitter is @marketershruti.
5. Participate expertly
Proficiently engage while you'll have no audience at first. Borrow your dream audience for free.
Steps:
Find a creator who has the audience you want.
Activate their post notifications and follow them.
Add a valuable comment first.
6. Create fantastic content
Use:
Medium (Read articles about your topic.)
Podcasts (Listen to experts on your topics)
YouTube (Follow channels in your niche)
Tweet what?
Listicle ( Hacks, Books, Tools, Podcasts)
Lessons (Teach your audience how to do 1 thing)
Inspirational (Inspire people to take action)
Consistent writing?
You MUST plan ahead and schedule your Tweets.
Use a scheduling tool that is effective for you; hypefury is mine.
Lastly, consistency is everything that attracts growth. After optimizing your profile, stay active to gain followers, engagements, and clients.
If you found this helpful, please like and comment below.

M.G. Siegler
3 years ago
Apple: Showing Ads on Your iPhone
This report from Mark Gurman has stuck with me:
In the News and Stocks apps, the display ads are no different than what you might get on an ad-supported website. In the App Store, the ads are for actual apps, which are probably more useful for Apple users than mortgage rates. Some people may resent Apple putting ads in the News and Stocks apps. After all, the iPhone is supposed to be a premium device. Let’s say you shelled out $1,000 or more to buy one, do you want to feel like Apple is squeezing more money out of you just to use its standard features? Now, a portion of ad revenue from the News app’s Today tab goes to publishers, but it’s not clear how much. Apple also lets publishers advertise within their stories and keep the vast majority of that money. Surprisingly, Today ads also appear if you subscribe to News+ for $10 per month (though it’s a smaller number).
I use Apple News often. It's a good general news catch-up tool, like Twitter without the BS. Customized notifications are helpful. Fast and lovely. Except for advertisements. I have Apple One, which includes News+, and while I understand why the magazines still have brand ads, it's ridiculous to me that Apple enables web publishers to introduce awful ads into this experience. Apple's junky commercials are ridiculous.
We know publishers want and probably requested this. Let's keep Apple News ad-free for the much smaller percentage of paid users, and here's your portion. (Same with Stocks, which is more sillier.)
Paid app placement in the App Store is a wonderful approach for developers to find new users (though far too many of those ads are trying to trick users, in my opinion).
Apple is also planning to increase ads in its Maps app. This sounds like Google Maps, and I don't like it. I never find these relevant, and they clutter up the user experience. Apple Maps now has a UI advantage (though not a data/search one, which matters more).
Apple is nickel-and-diming its customers. We spend thousands for their products and premium services like Apple One. We all know why: income must rise, and new firms are needed to scale. This will eventually backfire.

Victoria Kurichenko
3 years ago
What Happened After I Posted an AI-Generated Post on My Website
This could cost you.

Content creators may have heard about Google's "Helpful content upgrade."
This change is another Google effort to remove low-quality, repetitive, and AI-generated content.
Why should content creators care?
Because too much content manipulates search results.
My experience includes the following.
Website admins seek high-quality guest posts from me. They send me AI-generated text after I say "yes." My readers are irrelevant. Backlinks are needed.
Companies copy high-ranking content to boost their Google rankings. Unfortunately, it's common.
What does this content offer?
Nothing.
Despite Google's updates and efforts to clean search results, webmasters create manipulative content.
As a marketer, I knew about AI-powered content generation tools. However, I've never tried them.
I use old-fashioned content creation methods to grow my website from 0 to 3,000 monthly views in one year.
Last year, I launched a niche website.
I do keyword research, analyze search intent and competitors' content, write an article, proofread it, and then optimize it.
This strategy is time-consuming.
But it yields results!
Here's proof from Google Analytics:
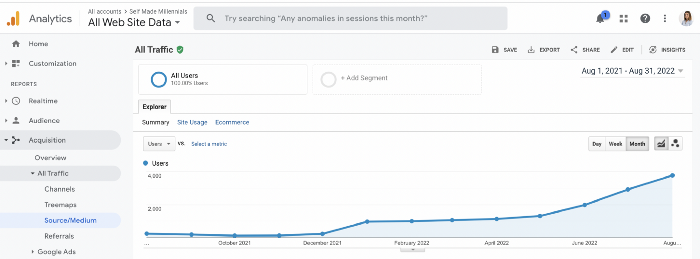
Proven strategies yield promising results.
To validate my assumptions and find new strategies, I run many experiments.
I tested an AI-powered content generator.
I used a tool to write this Google-optimized article about SEO for startups.
I wanted to analyze AI-generated content's Google performance.
Here are the outcomes of my test.
First, quality.
I dislike "meh" content. I expect articles to answer my questions. If not, I've wasted my time.
My essays usually include research, personal anecdotes, and what I accomplished and achieved.
AI-generated articles aren't as good because they lack individuality.
Read my AI-generated article about startup SEO to see what I mean.

It's dry and shallow, IMO.
It seems robotic.
I'd use quotes and personal experience to show how SEO for startups is different.
My article paraphrases top-ranked articles on a certain topic.
It's readable but useless. Similar articles abound online. Why read it?
AI-generated content is low-quality.
Let me show you how this content ranks on Google.
The Google Search Console report shows impressions, clicks, and average position.
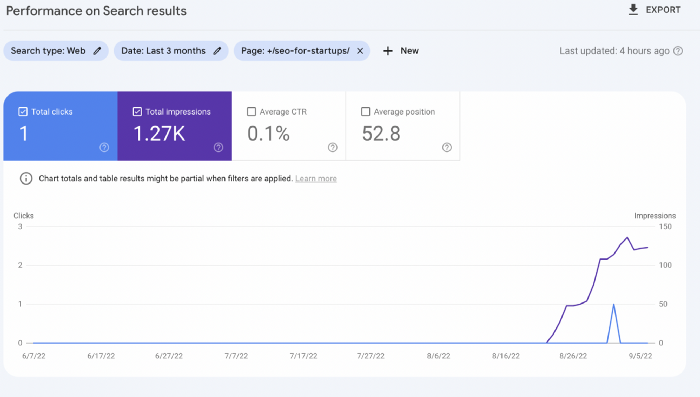
Low numbers.
No one opens the 5th Google search result page to read the article. Too far!
You may say the new article will improve.
Marketing-wise, I doubt it.
This article is shorter and less comprehensive than top-ranking pages. It's unlikely to win because of this.
AI-generated content's terrible reality.
I'll compare how this content I wrote for readers and SEO performs.
Both the AI and my article are fresh, but trends are emerging.
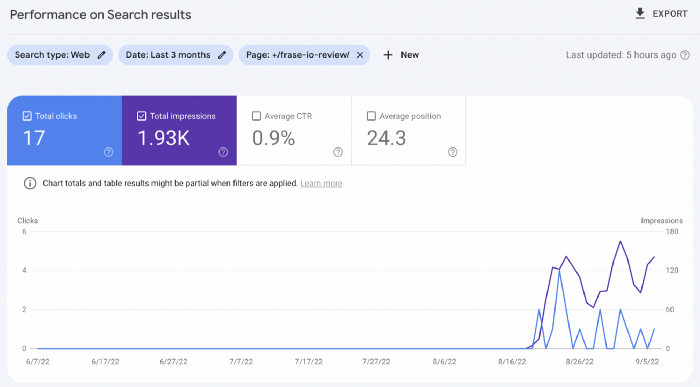
My article's CTR and average position are higher.
I spent a week researching and producing that piece, unlike AI-generated content. My expert perspective and unique consequences make it interesting to read.
Human-made.
In summary
No content generator can duplicate a human's tone, writing style, or creativity. Artificial content is always inferior.
Not "bad," but inferior.
Demand for content production tools will rise despite Google's efforts to eradicate thin content.
Most won't spend hours producing link-building articles. Costly.
As guest and sponsored posts, artificial content will thrive.
Before accepting a new arrangement, content creators and website owners should consider this.
You might also like

Sammy Abdullah
3 years ago
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
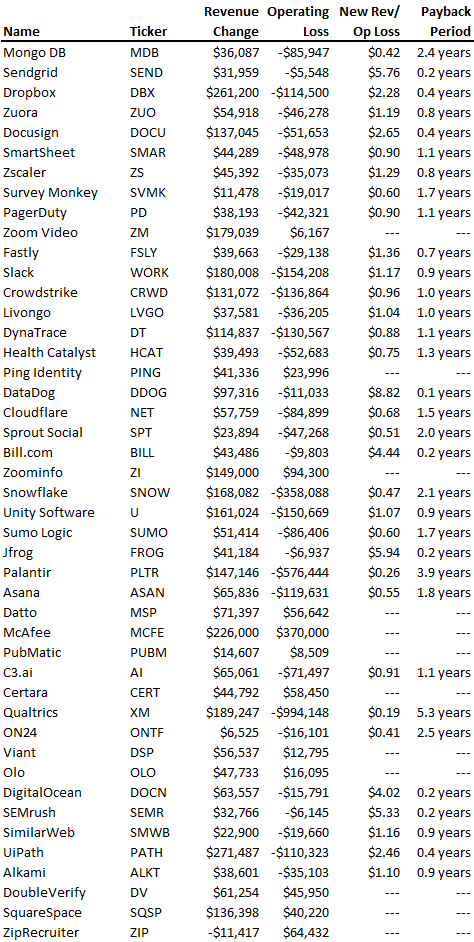
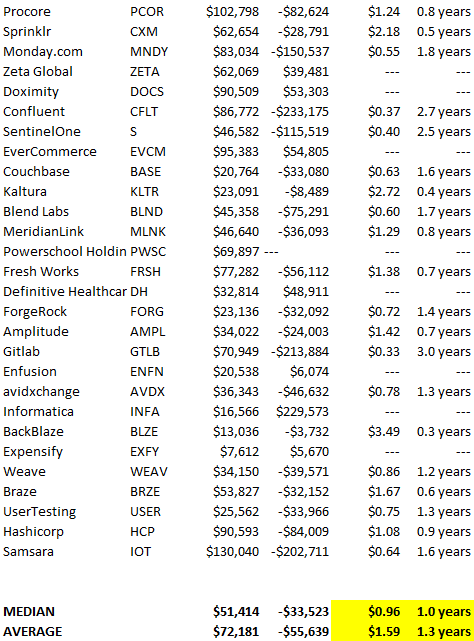
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.

Shan Vernekar
3 years ago
How the Ethereum blockchain's transactions are carried out
Overview
Ethereum blockchain is a network of nodes that validate transactions. Any network node can be queried for blockchain data for free. To write data as a transition requires processing and writing to each network node's storage. Fee is paid in ether and is also called as gas.
We'll examine how user-initiated transactions flow across the network and into the blockchain.
Flow of transactions
A user wishes to move some ether from one external account to another. He utilizes a cryptocurrency wallet for this (like Metamask), which is a browser extension.
The user enters the desired transfer amount and the external account's address. He has the option to choose the transaction cost he is ready to pay.
Wallet makes use of this data, signs it with the user's private key, and writes it to an Ethereum node. Services such as Infura offer APIs that enable writing data to nodes. One of these services is used by Metamask. An example transaction is shown below. Notice the “to” address and value fields.
var rawTxn = {
nonce: web3.toHex(txnCount),
gasPrice: web3.toHex(100000000000),
gasLimit: web3.toHex(140000),
to: '0x633296baebc20f33ac2e1c1b105d7cd1f6a0718b',
value: web3.toHex(0),
data: '0xcc9ab24952616d6100000000000000000000000000000000000000000000000000000000'
};The transaction is written to the target Ethereum node's local TRANSACTION POOL. It informed surrounding nodes of the new transaction, and those nodes reciprocated. Eventually, this transaction is received by and written to each node's local TRANSACTION pool.
The miner who finds the following block first adds pending transactions (with a higher gas cost) from the nearby TRANSACTION POOL to the block.
The transactions written to the new block are verified by other network nodes.
A block is added to the main blockchain after there is consensus and it is determined to be genuine. The local blockchain is updated with the new node by additional nodes as well.
Block mining begins again next.
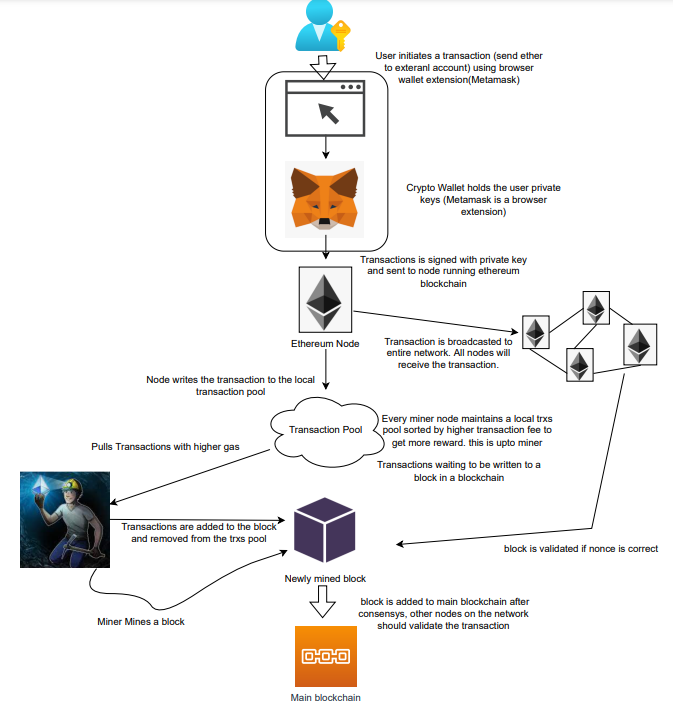
The image above shows how transactions go via the network and what's needed to submit them to the main block chain.
References
ethereum.org/transactions How Ethereum transactions function, their data structure, and how to send them via app. ethereum.org

Ben Carlson
3 years ago
Bear market duration and how to invest during one

Bear markets don't last forever, but that's hard to remember. Jamie Cullen's illustration
A bear market is a 20% decline from peak to trough in stock prices.
The S&P 500 was down 24% from its January highs at its low point this year. Bear market.
The U.S. stock market has had 13 bear markets since WWII (including the current one). Previous 12 bear markets averaged –32.7% losses. From peak to trough, the stock market averaged 12 months. The average time from bottom to peak was 21 months.
In the past seven decades, a bear market roundtrip to breakeven has averaged less than three years.
Long-term averages can vary widely, as with all historical market data. Investors can learn from past market crashes.
Historical bear markets offer lessons.
Bear market duration
A bear market can cost investors money and time. Most of the pain comes from stock market declines, but bear markets can be long.
Here are the longest U.S. stock bear markets since World war 2:
Stock market crashes can make it difficult to break even. After the 2008 financial crisis, the stock market took 4.5 years to recover. After the dotcom bubble burst, it took seven years to break even.
The longer you're underwater in the market, the more suffering you'll experience, according to research. Suffering can lead to selling at the wrong time.
Bear markets require patience because stocks can take a long time to recover.
Stock crash recovery
Bear markets can end quickly. The Corona Crash in early 2020 is an example.
The S&P 500 fell 34% in 23 trading sessions, the fastest bear market from a high in 90 years. The entire crash lasted one month. Stocks broke even six months after bottoming. Stocks rose 100% from those lows in 15 months.
Seven bear markets have lasted two years or less since 1945.
The 2020 recovery was an outlier, but four other bear markets have made investors whole within 18 months.
During a bear market, you don't know if it will end quickly or feel like death by a thousand cuts.
Recessions vs. bear markets
Many people believe the U.S. economy is in or heading for a recession.
I agree. Four-decade high inflation. Since 1945, inflation has exceeded 5% nine times. Each inflationary spike caused a recession. Only slowing economic demand seems to stop price spikes.
This could happen again. Stocks seem to be pricing in a recession.
Recessions almost always cause a bear market, but a bear market doesn't always equal a recession. In 1946, the stock market fell 27% without a recession in sight. Without an economic slowdown, the stock market fell 22% in 1966. Black Monday in 1987 was the most famous stock market crash without a recession. Stocks fell 30% in less than a week. Many believed the stock market signaled a depression. The crash caused no slowdown.
Economic cycles are hard to predict. Even Wall Street makes mistakes.
Bears vs. bulls
Bear markets for U.S. stocks always end. Every stock market crash in U.S. history has been followed by new all-time highs.
How should investors view the recession? Investing risk is subjective.
You don't have as long to wait out a bear market if you're retired or nearing retirement. Diversification and liquidity help investors with limited time or income. Cash and short-term bonds drag down long-term returns but can ensure short-term spending.
Young people with years or decades ahead of them should view this bear market as an opportunity. Stock market crashes are good for net savers in the future. They let you buy cheap stocks with high dividend yields.
You need discipline, patience, and planning to buy stocks when it doesn't feel right.
Bear markets aren't fun because no one likes seeing their portfolio fall. But stock market downturns are a feature, not a bug. If stocks never crashed, they wouldn't offer such great long-term returns.