



More on Leadership

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.

Nir Zicherman
3 years ago
The Great Organizational Conundrum
Only two of the following three options can be achieved: consistency, availability, and partition tolerance

Someone told me that growing from 30 to 60 is the biggest adjustment for a team or business.
I remember thinking, That's random. Each company is unique. I've seen teams of all types confront the same issues during development periods. With new enterprises starting every year, we should be better at navigating growing difficulties.
As a team grows, its processes and systems break down, requiring reorganization or declining results. Why always? Why isn't there a perfect scaling model? Why hasn't that been found?
The Three Things Productive Organizations Must Have
Any company should be efficient and productive. Three items are needed:
First, it must verify that no two team members have conflicting information about the roadmap, strategy, or any input that could affect execution. Teamwork is required.
Second, it must ensure that everyone can receive the information they need from everyone else quickly, especially as teams become more specialized (an inevitability in a developing organization). It requires everyone's accessibility.
Third, it must ensure that the organization can operate efficiently even if a piece is unavailable. It's partition-tolerant.
From my experience with the many teams I've been on, invested in, or advised, achieving all three is nearly impossible. Why a perfect organization model cannot exist is clear after analysis.
The CAP Theorem: What is it?
Eric Brewer of Berkeley discovered the CAP Theorem, which argues that a distributed data storage should have three benefits. One can only have two at once.
The three benefits are consistency, availability, and partition tolerance, which implies that even if part of the system is offline, the remainder continues to work.
This notion is usually applied to computer science, but I've realized it's also true for human organizations. In a post-COVID world, many organizations are hiring non-co-located staff as they grow. CAP Theorem is more important than ever. Growing teams sometimes think they can develop ways to bypass this law, dooming themselves to a less-than-optimal team dynamic. They should adopt CAP to maximize productivity.
Path 1: Consistency and availability equal no tolerance for partitions
Let's imagine you want your team to always be in sync (i.e., for someone to be the source of truth for the latest information) and to be able to share information with each other. Only division into domains will do.
Numerous developing organizations do this, especially after the early stage (say, 30 people) when everyone may wear many hats and be aware of all the moving elements. After a certain point, it's tougher to keep generalists aligned than to divide them into specialized tasks.
In a specialized, segmented team, leaders optimize consistency and availability (i.e. every function is up-to-speed on the latest strategy, no one is out of sync, and everyone is able to unblock and inform everyone else).
Partition tolerance suffers. If any component of the organization breaks down (someone goes on vacation, quits, underperforms, or Gmail or Slack goes down), productivity stops. There's no way to give the team stability, availability, and smooth operation during a hiccup.
Path 2: Partition Tolerance and Availability = No Consistency
Some businesses avoid relying too heavily on any one person or sub-team by maximizing availability and partition tolerance (the organization continues to function as a whole even if particular components fail). Only redundancy can do that. Instead of specializing each member, the team spreads expertise so people can work in parallel. I switched from Path 1 to Path 2 because I realized too much reliance on one person is risky.
What happens after redundancy? Unreliable. The more people may run independently and in parallel, the less anyone can be the truth. Lack of alignment or updated information can lead to people executing slightly different strategies. So, resources are squandered on the wrong work.
Path 3: Partition and Consistency "Tolerance" equates to "absence"
The third, least-used path stresses partition tolerance and consistency (meaning answers are always correct and up-to-date). In this organizational style, it's most critical to maintain the system operating and keep everyone aligned. No one is allowed to read anything without an assurance that it's up-to-date (i.e. there’s no availability).
Always short-lived. In my experience, a business that prioritizes quality and scalability over speedy information transmission can get bogged down in heavy processes that hinder production. Large-scale, this is unsustainable.
Accepting CAP
When two puzzle pieces fit, the third won't. I've watched developing teams try to tackle these difficulties, only to find, as their ancestors did, that they can never be entirely solved. Idealized solutions fail in reality, causing lost effort, confusion, and lower production.
As teams develop and change, they should embrace CAP, acknowledge there is a limit to productivity in a scaling business, and choose the best two-out-of-three path.

Alison Randel
3 years ago
Raising the Bar on Your 1:1s

Managers spend much time in 1:1s. Most team members meet with supervisors regularly. 1:1s can help create relationships and tackle tough topics. Few appreciate the 1:1 format's potential. Most of the time, that potential is spent on small talk, surface-level updates, and ranting (Ugh, the marketing team isn’t stepping up the way I want them to).
What if you used that time to have deeper conversations and important insights? What if change was easy?
This post introduces a new 1:1 format to help you dive deeper, faster, and develop genuine relationships without losing impact.
A 1:1 is a chat, you would assume. Why use structure to talk to a coworker? Go! I know how to talk to people. I can write. I've always written. Also, This article was edited by Zoe.
Before you discard something, ask yourself if there's a good reason not to try anything new. Is the 1:1 only a talk, or do you want extra benefits? Try the steps below to discover more.
I. Reflection (5 minutes)
Context-free, broad comments waste time and are useless. Instead, give team members 5 minutes to write these 3 prompts.
What's effective?
What is decent but could be improved?
What is broken or missing?
Why these? They encourage people to be honest about all their experiences. Answering these questions helps people realize something isn't working. These prompts let people consider what's working.
Why take notes? Because you get more in less time. Will you feel awkward sitting quietly while your coworker writes? Probably. Persevere. Multi-task. Take a break from your afternoon meeting marathon. Any awkwardness will pay off.
What happens? After a few minutes of light conversation, create a template like the one given here and have team members fill in their replies. You can pre-share the template (with the caveat that this isn’t meant to take much prep time). Do this with your coworker: Answer the prompts. Everyone can benefit from pondering and obtaining guidance.
This step's output.

Part II: Talk (10-20 minutes)
Most individuals can explain what they see but not what's behind an answer. You don't like a meeting. Why not? Marketing partnership is difficult. What makes working with them difficult? I don't recommend slandering coworkers. Consider how your meetings, decisions, and priorities make work harder. The excellent stuff too. You want to know what's humming so you can reproduce the magic.
First, recognize some facts.
Real power dynamics exist. To encourage individuals to be honest, you must provide a safe environment and extend clear invites. Even then, it may take a few 1:1s for someone to feel secure enough to go there in person. It is part of your responsibility to admit that it is normal.
Curiosity and self-disclosure are crucial. Most leaders have received training to present themselves as the authorities. However, you will both benefit more from the dialogue if you can be open and honest about your personal experience, ask questions out of real curiosity, and acknowledge the pertinent sacrifices you're making as a leader.
Honesty without bias is difficult and important. Due to concern for the feelings of others, people frequently hold back. Or if they do point anything out, they do so in a critical manner. The key is to be open and unapologetic about what you observe while not presuming that your viewpoint is correct and that of the other person is incorrect.
Let's go into some prompts (based on genuine conversations):
“What do you notice across your answers?”
“What about the way you/we/they do X, Y, or Z is working well?”
“ Will you say more about item X in ‘What’s not working?’”
“I’m surprised there isn’t anything about Z. Why is that?”
“All of us tend to play some role in maintaining certain patterns. How might you/we be playing a role in this pattern persisting?”
“How might the way we meet, make decisions, or collaborate play a role in what’s currently happening?”
Consider the preceding example. What about the Monday meeting isn't working? Why? or What about the way we work with marketing makes collaboration harder? Remember to share your honest observations!
Third section: observe patterns (10-15 minutes)
Leaders desire to empower their people but don't know how. We also have many preconceptions about what empowerment means to us and how it works. The next phase in this 1:1 format will assist you and your team member comprehend team power and empowerment. This understanding can help you support and shift your team member's behavior, especially where you disagree.
How to? After discussing the stated responses, ask each team member what they can control, influence, and not control. Mark their replies. You can do the same, adding colors where you disagree.
This step's output.

Next, consider the color constellation. Discuss these questions:
Is one color much more prevalent than the other? Why, if so?
Are the colors for the "what's working," "what's fine," and "what's not working" categories clearly distinct? Why, if so?
Do you have any disagreements? If yes, specifically where does your viewpoint differ? What activities do you object to? (Remember, there is no right or wrong in this. Give explicit details and ask questions with curiosity.)
Example: Based on the colors, you can ask, Is the marketing meeting's quality beyond your control? Were our marketing partners consulted? Are there any parts of team decisions we can control? We can't control people, but have we explored another decision-making method? How can we collaborate and generate governance-related information to reduce work, even if the requirement for prep can't be eliminated?
Consider the top one or two topics for this conversation. No 1:1 can cover everything, and that's OK. Focus on the present.
Part IV: Determine the next step (5 minutes)
Last, examine what this conversation means for you and your team member. It's easy to think we know the next moves when we don't.
Like what? You and your teammate answer these questions.
What does this signify moving ahead for me? What can I do to change this? Make requests, for instance, and see how people respond before thinking they won't be responsive.
What demands do I have on other people or my partners? What should I do first? E.g. Make a suggestion to marketing that we hold a monthly retrospective so we can address problems and exchange input more frequently. Include it on the meeting's agenda for next Monday.
Close the 1:1 by sharing what you noticed about the chat. Observations? Learn anything?
Yourself, you, and the 1:1
As a leader, you either reinforce or disrupt habits. Try this template if you desire greater ownership, empowerment, or creativity. Consider how you affect surrounding dynamics. How can you expect others to try something new in high-stakes scenarios, like meetings with cross-functional partners or senior stakeholders, if you won't? How can you expect deep thought and relationship if you don't encourage it in 1:1s? What pattern could this new format disrupt or reinforce?
Fight reluctance. First attempts won't be ideal, and that's OK. You'll only learn by trying.
You might also like

1eth1da
3 years ago
6 Rules to build a successful NFT Community in 2022

Too much NFT, Discord, and shitposting.
How do you choose?
How do you recruit more members to join your NFT project?
In 2021, a successful NFT project required:
Monkey/ape artwork
Twitter and Discord bot-filled
Roadmap overpromise
Goal was quick cash.
2022 and the years after will change that.
These are 6 Rules for a Strong NFT Community in 2022:
THINK LONG TERM
This relates to roadmap planning. Hype and dumb luck may drive NFT projects (ahem, goblins) but rarely will your project soar.
Instead, consider sustainability.
Plan your roadmap based on your team's abilities.
Do what you're already doing, but with NFTs, make it bigger and better.
You shouldn't copy a project's roadmap just because it was profitable.
This will lead to over-promising, team burnout, and an RUG NFT project.
OFFER VALUE
Building a great community starts with giving.
Why are musicians popular?
Because they offer entertainment for everyone, a random person becomes a fan, and more fans become a cult.
That's how you should approach your community.
TEAM UP
A great team helps.
An NFT project could have 3 or 2 people.
Credibility trumps team size.
Make sure your team can answer community questions, resolve issues, and constantly attend to them.
Don't overwork and burn out.
Your community will be able to recognize that you are trying too hard and give up on the project.
BUILD A GREAT PRODUCT
Bored Ape Yacht Club altered the NFT space.
Cryptopunks transformed NFTs.
Many others did, including Okay Bears.
What made them that way?
Because they answered a key question.
What is my NFT supposed to be?
Before planning art, this question must be answered.
NFTs can't be just jpegs.
What does it represent?
Is it a Metaverse-ready project?
What blockchain are you going to be using and why?
Set some ground rules for yourself. This helps your project's direction.
These questions will help you and your team set a direction for blockchain, NFT, and Web3 technology.
EDUCATE ON WEB3
The more the team learns about Web3 technology, the more they can offer their community.
Think tokens, metaverse, cross-chain interoperability and more.
BUILD A GREAT COMMUNITY
Several projects mistreat their communities.
They treat their community like "customers" and try to sell them NFT.
Providing Whitelists and giveaways aren't your only community-building options.
Think bigger.
Consider them family and friends, not wallets.
Consider them fans.
These are some tips to start your NFT project.

Sofien Kaabar, CFA
2 years ago
Innovative Trading Methods: The Catapult Indicator
Python Volatility-Based Catapult Indicator
As a catapult, this technical indicator uses three systems: Volatility (the fulcrum), Momentum (the propeller), and a Directional Filter (Acting as the support). The goal is to get a signal that predicts volatility acceleration and direction based on historical patterns. We want to know when the market will move. and where. This indicator outperforms standard indicators.
Knowledge must be accessible to everyone. This is why my new publications Contrarian Trading Strategies in Python and Trend Following Strategies in Python now include free PDF copies of my first three books (Therefore, purchasing one of the new books gets you 4 books in total). GitHub-hosted advanced indications and techniques are in the two new books above.
The Foundation: Volatility
The Catapult predicts significant changes with the 21-period Relative Volatility Index.
The Average True Range, Mean Absolute Deviation, and Standard Deviation all assess volatility. Standard Deviation will construct the Relative Volatility Index.
Standard Deviation is the most basic volatility. It underpins descriptive statistics and technical indicators like Bollinger Bands. Before calculating Standard Deviation, let's define Variance.
Variance is the squared deviations from the mean (a dispersion measure). We take the square deviations to compel the distance from the mean to be non-negative, then we take the square root to make the measure have the same units as the mean, comparing apples to apples (mean to standard deviation standard deviation). Variance formula:
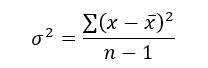
As stated, standard deviation is:
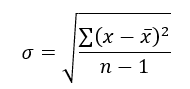
# The function to add a number of columns inside an array
def adder(Data, times):
for i in range(1, times + 1):
new_col = np.zeros((len(Data), 1), dtype = float)
Data = np.append(Data, new_col, axis = 1)
return Data
# The function to delete a number of columns starting from an index
def deleter(Data, index, times):
for i in range(1, times + 1):
Data = np.delete(Data, index, axis = 1)
return Data
# The function to delete a number of rows from the beginning
def jump(Data, jump):
Data = Data[jump:, ]
return Data
# Example of adding 3 empty columns to an array
my_ohlc_array = adder(my_ohlc_array, 3)
# Example of deleting the 2 columns after the column indexed at 3
my_ohlc_array = deleter(my_ohlc_array, 3, 2)
# Example of deleting the first 20 rows
my_ohlc_array = jump(my_ohlc_array, 20)
# Remember, OHLC is an abbreviation of Open, High, Low, and Close and it refers to the standard historical data file
def volatility(Data, lookback, what, where):
for i in range(len(Data)):
try:
Data[i, where] = (Data[i - lookback + 1:i + 1, what].std())
except IndexError:
pass
return Data
The RSI is the most popular momentum indicator, and for good reason—it excels in range markets. Its 0–100 range simplifies interpretation. Fame boosts its potential.
The more traders and portfolio managers look at the RSI, the more people will react to its signals, pushing market prices. Technical Analysis is self-fulfilling, therefore this theory is obvious yet unproven.
RSI is determined simply. Start with one-period pricing discrepancies. We must remove each closing price from the previous one. We then divide the smoothed average of positive differences by the smoothed average of negative differences. The RSI algorithm converts the Relative Strength from the last calculation into a value between 0 and 100.
def ma(Data, lookback, close, where):
Data = adder(Data, 1)
for i in range(len(Data)):
try:
Data[i, where] = (Data[i - lookback + 1:i + 1, close].mean())
except IndexError:
pass
# Cleaning
Data = jump(Data, lookback)
return Data
def ema(Data, alpha, lookback, what, where):
alpha = alpha / (lookback + 1.0)
beta = 1 - alpha
# First value is a simple SMA
Data = ma(Data, lookback, what, where)
# Calculating first EMA
Data[lookback + 1, where] = (Data[lookback + 1, what] * alpha) + (Data[lookback, where] * beta)
# Calculating the rest of EMA
for i in range(lookback + 2, len(Data)):
try:
Data[i, where] = (Data[i, what] * alpha) + (Data[i - 1, where] * beta)
except IndexError:
pass
return Datadef rsi(Data, lookback, close, where, width = 1, genre = 'Smoothed'):
# Adding a few columns
Data = adder(Data, 7)
# Calculating Differences
for i in range(len(Data)):
Data[i, where] = Data[i, close] - Data[i - width, close]
# Calculating the Up and Down absolute values
for i in range(len(Data)):
if Data[i, where] > 0:
Data[i, where + 1] = Data[i, where]
elif Data[i, where] < 0:
Data[i, where + 2] = abs(Data[i, where])
# Calculating the Smoothed Moving Average on Up and Down
absolute values
lookback = (lookback * 2) - 1 # From exponential to smoothed
Data = ema(Data, 2, lookback, where + 1, where + 3)
Data = ema(Data, 2, lookback, where + 2, where + 4)
# Calculating the Relative Strength
Data[:, where + 5] = Data[:, where + 3] / Data[:, where + 4]
# Calculate the Relative Strength Index
Data[:, where + 6] = (100 - (100 / (1 + Data[:, where + 5])))
# Cleaning
Data = deleter(Data, where, 6)
Data = jump(Data, lookback)
return Data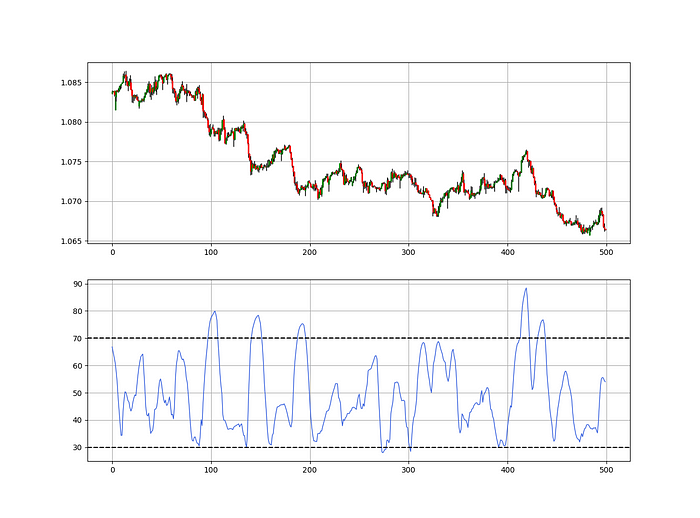
def relative_volatility_index(Data, lookback, close, where):
# Calculating Volatility
Data = volatility(Data, lookback, close, where)
# Calculating the RSI on Volatility
Data = rsi(Data, lookback, where, where + 1)
# Cleaning
Data = deleter(Data, where, 1)
return DataThe Arm Section: Speed
The Catapult predicts momentum direction using the 14-period Relative Strength Index.
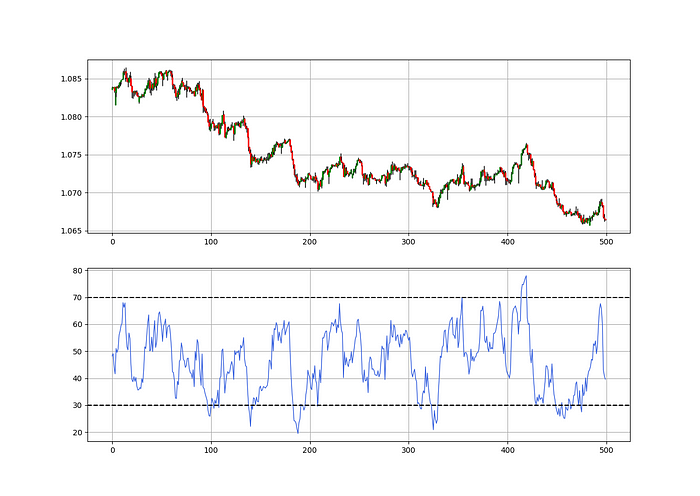
As a reminder, the RSI ranges from 0 to 100. Two levels give contrarian signals:
A positive response is anticipated when the market is deemed to have gone too far down at the oversold level 30, which is 30.
When the market is deemed to have gone up too much, at overbought level 70, a bearish reaction is to be expected.
Comparing the RSI to 50 is another intriguing use. RSI above 50 indicates bullish momentum, while below 50 indicates negative momentum.
The direction-finding filter in the frame
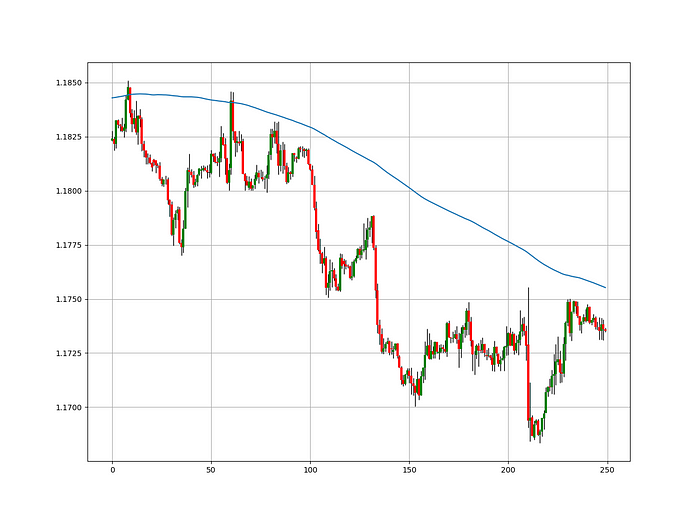
The Catapult's directional filter uses the 200-period simple moving average to keep us trending. This keeps us sane and increases our odds.
Moving averages confirm and ride trends. Its simplicity and track record of delivering value to analysis make them the most popular technical indicator. They help us locate support and resistance, stops and targets, and the trend. Its versatility makes them essential trading tools.
This is the plain mean, employed in statistics and everywhere else in life. Simply divide the number of observations by their total values. Mathematically, it's:
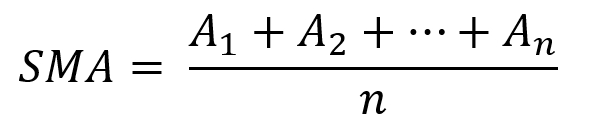
We defined the moving average function above. Create the Catapult indication now.
Indicator of the Catapult
The indicator is a healthy mix of the three indicators:
The first trigger will be provided by the 21-period Relative Volatility Index, which indicates that there will now be above average volatility and, as a result, it is possible for a directional shift.
If the reading is above 50, the move is likely bullish, and if it is below 50, the move is likely bearish, according to the 14-period Relative Strength Index, which indicates the likelihood of the direction of the move.
The likelihood of the move's direction will be strengthened by the 200-period simple moving average. When the market is above the 200-period moving average, we can infer that bullish pressure is there and that the upward trend will likely continue. Similar to this, if the market falls below the 200-period moving average, we recognize that there is negative pressure and that the downside is quite likely to continue.
lookback_rvi = 21
lookback_rsi = 14
lookback_ma = 200
my_data = ma(my_data, lookback_ma, 3, 4)
my_data = rsi(my_data, lookback_rsi, 3, 5)
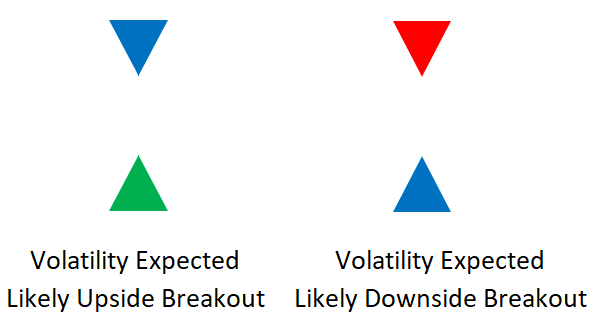
my_data = relative_volatility_index(my_data, lookback_rvi, 3, 6)Two-handled overlay indicator Catapult. The first exhibits blue and green arrows for a buy signal, and the second shows blue and red for a sell signal.
The chart below shows recent EURUSD hourly values.
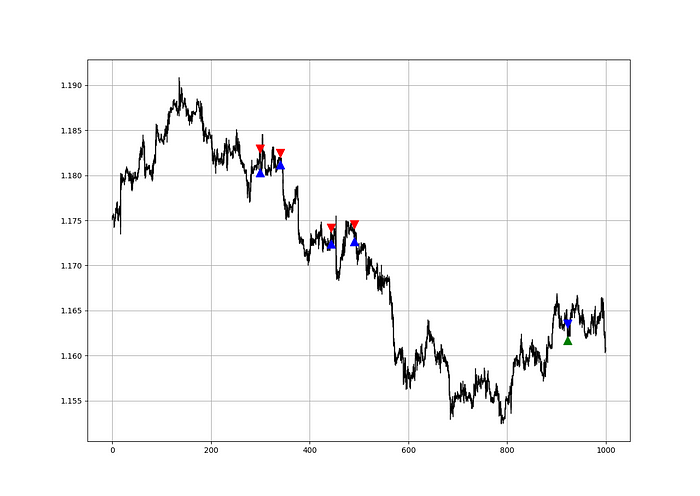
def signal(Data, rvi_col, signal):
Data = adder(Data, 10)
for i in range(len(Data)):
if Data[i, rvi_col] < 30 and \
Data[i - 1, rvi_col] > 30 and \
Data[i - 2, rvi_col] > 30 and \
Data[i - 3, rvi_col] > 30 and \
Data[i - 4, rvi_col] > 30 and \
Data[i - 5, rvi_col] > 30:
Data[i, signal] = 1
return Data
Signals are straightforward. The indicator can be utilized with other methods.
my_data = signal(my_data, 6, 7)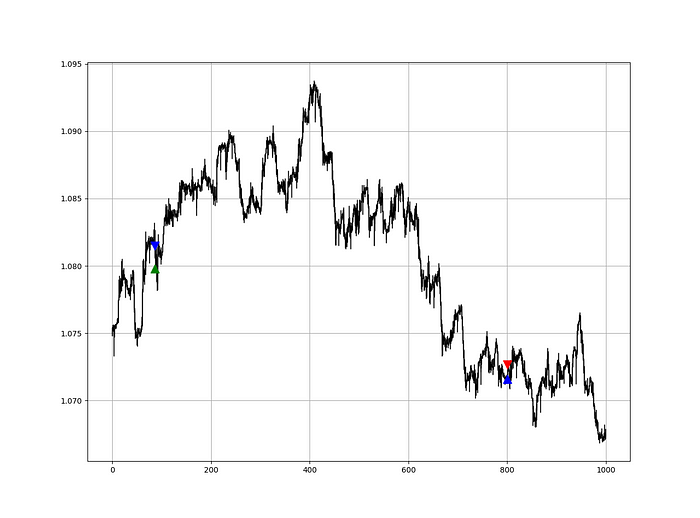
Lumiwealth shows how to develop all kinds of algorithms. I recommend their hands-on courses in algorithmic trading, blockchain, and machine learning.
Summary
To conclude, my goal is to contribute to objective technical analysis, which promotes more transparent methods and strategies that must be back-tested before implementation. Technical analysis will lose its reputation as subjective and unscientific.
After you find a trading method or approach, follow these steps:
Put emotions aside and adopt an analytical perspective.
Test it in the past in conditions and simulations taken from real life.
Try improving it and performing a forward test if you notice any possibility.
Transaction charges and any slippage simulation should always be included in your tests.
Risk management and position sizing should always be included in your tests.
After checking the aforementioned, monitor the plan because market dynamics may change and render it unprofitable.
Matthew Royse
3 years ago
These 10 phrases are unprofessional at work.
Successful workers don't talk this way.

"I know it's unprofessional, but I can't stop." — Author Sandy Hall
Do you realize your unprofessionalism? Do you care? Self-awareness?
Everyone can improve their unprofessionalism. Some workplace phrases and words shouldn't be said.
People often say out loud what they're thinking. They show insecurity, incompetence, and disrespect.
"Think before you speak," goes the saying.
Some of these phrases are "okay" in certain situations, but you'll lose colleagues' respect if you use them often.
Your word choice. Your tone. Your intentions. They matter.
Choose your words carefully to build work relationships and earn peer respect. You should build positive relationships with coworkers and clients.
These 10 phrases are unprofessional.
1. That Meeting Really Sucked
Wow! Were you there? You should be responsible if you attended. You can influence every conversation.
Alternatives
Improve the meeting instead of complaining afterward. Make it more meaningful and productive.
2. Not Sure if You Saw My Last Email
Referencing a previous email irritates people. Email follow-up can be difficult. Most people get tons of emails a day, so it may have been buried, forgotten, or low priority.
Alternatives
It's okay to follow up, but be direct, short, and let the recipient "save face"
3. Any Phrase About Sex, Politics, and Religion
Discussing sex, politics, and religion at work is foolish. If you discuss these topics, you could face harassment lawsuits.
Alternatives
Keep quiet about these contentious issues. Don't touch them.
4. I Know What I’m Talking About
Adding this won't persuade others. Research, facts, and topic mastery are key to persuasion. If you're knowledgeable, you don't need to say this.
Alternatives
Please don’t say it at all. Justify your knowledge.
5. Per Our Conversation
This phrase sounds like legal language. You seem to be documenting something legally. Cold, stern, and distant. "As discussed" sounds inauthentic.
Alternatives
It was great talking with you earlier; here's what I said.
6. Curse-Word Phrases
Swearing at work is unprofessional. You never know who's listening, so be careful. A child may be at work or on a Zoom or Teams call. Workplace cursing is unacceptable.
Alternatives
Avoid adult-only words.
7. I Hope This Email Finds You Well
This is a unique way to wish someone well. This phrase isn't as sincere as the traditional one. When you talk about the email, you're impersonal.
Alternatives
Genuinely care for others.
8. I Am Really Stressed
Happy, strong, stress-managing coworkers are valued. Manage your own stress. Exercise, sleep, and eat better.
Alternatives
Everyone has stress, so manage it. Don't talk about your stress.
9. I Have Too Much to Do
You seem incompetent. People think you can't say "no" or have poor time management. If you use this phrase, you're telling others you may need to change careers.
Alternatives
Don't complain about your workload; just manage it.
10. Bad Closing Salutations
"Warmly," "best," "regards," and "warm wishes" are common email closings. This conclusion sounds impersonal. Why use "warmly" for finance's payment status?
Alternatives
Personalize the closing greeting to the message and recipient. Use "see you tomorrow" or "talk soon" as closings.
Bringing It All Together
These 10 phrases are unprofessional at work. That meeting sucked, not sure if you saw my last email, and sex, politics, and religion phrases.
Also, "I know what I'm talking about" and any curse words. Also, avoid phrases like I hope this email finds you well, I'm stressed, and I have too much to do.
Successful workers communicate positively and foster professionalism. Don't waste chances to build strong work relationships by being unprofessional.
“Unprofessionalism damages the business reputation and tarnishes the trust of society.” — Pearl Zhu, an American author
This post is a summary. Read full article here