



More on Technology

Shawn Mordecai
3 years ago
The Apple iPhone 14 Pill is Easier to Swallow
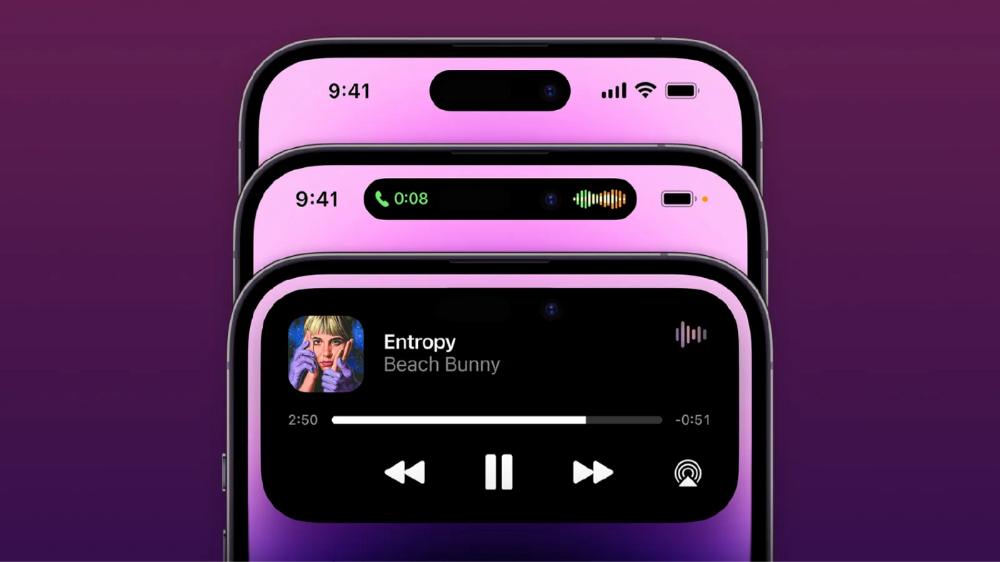
Is iPhone's Dynamic Island invention or a marketing ploy?
First of all, why the notch?
When Apple debuted the iPhone X with the notch, some were surprised, confused, and amused by the goof. Let the Brits keep the new meaning of top-notch.
Apple removed the bottom home button to enhance screen space. The tides couldn't overtake part of the top. This section contained sensors, a speaker, a microphone, and cameras for facial recognition. A town resisted Apple's new iPhone design.
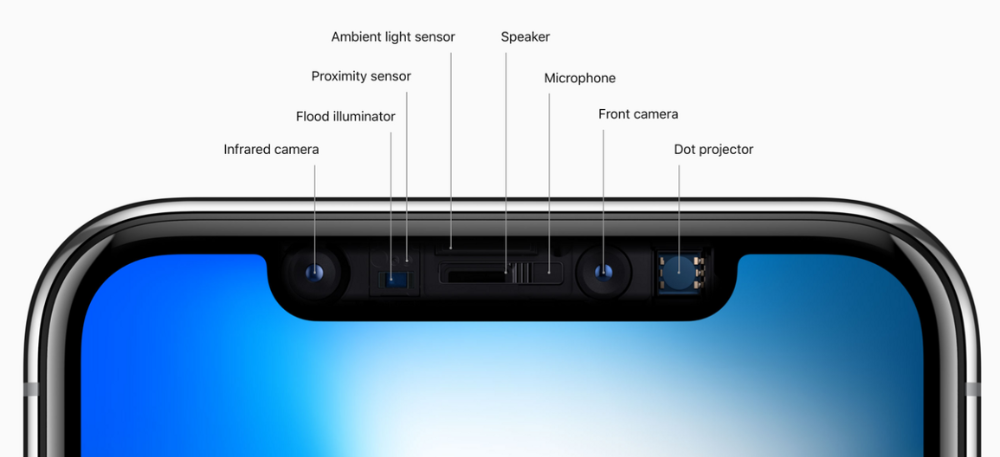
From iPhone X to 13, the notch has gotten smaller. We expected this as technology and engineering progressed, but we hated the notch. Apple approved. They attached it to their other gadgets.
Apple accepted, owned, and ran with the iPhone notch, it has become iconic (or infamous); and that’s intentional.
The Island Where Apple Is
Apple needs to separate itself, but they know how to do it well. The iPhone 14 Pro finally has us oohing and aahing. Life-changing, not just higher pixel density or longer battery.
Dynamic Island turned a visual differentiation into great usefulness, which may not be life-changing. Apple always welcomes the controversy, whether it's $700 for iMac wheels, no charging block with a new phone, or removing the headphone jack.
Apple knows its customers will be loyal, even if they're irritated. Their odd design choices often cause controversy. It's calculated that people blog, review, and criticize Apple's products. We accept what works for them.
While the competition zigs, Apple zags. Sometimes they zag too hard and smash into a wall, but we talk about it anyways, and that’s great publicity for them.
Getting Dependent on the drug
The notch became a crop. Dynamic Island's design is helpful, intuitive, elegant, and useful. It increases iPhone usability, productivity (slightly), and joy. No longer unsightly.
The medication helps with multitasking. It's a compact version of the iPhone's Live Activities lock screen function. Dynamic Island enhances apps and activities with visual effects and animations whether you engage with it or not. As you use the pill, its usefulness lessens. It lowers user notifications and consolidates them with live and permanent feeds, delivering quick app statuses. It uses the black pixels on the iPhone 14's display, which looked like a poor haircut.

The pill may be a gimmick to entice customers to use more Apple products and services. Apps may promote to their users like a live billboard.
Be prepared to get a huge dose of Dynamic Island’s “pill” like you never had before with the notch. It might become so satisfying and addicting to use, that every interaction with it will become habit-forming, and you’re going to forget that it ever existed.
WARNING: A Few Potential Side Effects
Vision blurred Dynamic Island's proximity to the front-facing camera may leave behind grease that blurs photos. Before taking a selfie, wipe the camera clean.
Strained thumb To fully use Dynamic Island, extend your thumb's reach 6.7 inches beyond your typical, comfortable range.
Happiness, contentment The Dynamic Island may enhance Endorphins and Dopamine. Multitasking, interactions, animations, and haptic feedback make you want to use this function again and again.
Motion-sickness Dynamic Island's motions and effects may make some people dizzy. If you can disable animations, you can avoid motion sickness.
I'm not a doctor, therefore they aren't established adverse effects.
Does Dynamic Island Include Multiple Tasks?
Dynamic Islands is a placebo for multitasking. Apple might have compromised on iPhone multitasking. It won't make you super productive, but it's a step up.

iPhone is primarily for personal use, like watching videos, messaging friends, sending money to friends, calling friends about the money you were supposed to send them, taking 50 photos of the same leaf, investing in crypto, driving for Uber because you lost all your money investing in crypto, listening to music and hailing an Uber from a deserted crop field because while you were driving for Uber your passenger stole your car and left you stranded, so you used Apple’s new SOS satellite feature to message your friend, who still didn’t receive their money, to hail you an Uber; now you owe them more money… karma?
We won't be watching videos on iPhones while perusing 10,000-row spreadsheets anytime soon. True multitasking and productivity aren't priorities for Apple's iPhone. Apple doesn't to preserve the iPhone's experience. Like why there's no iPad calculator. Apple doesn't want iPad users to do math, but isn't essential for productivity?
Digressing.
Apple will block certain functions so you must buy and use their gadgets and services, immersing yourself in their ecosystem and dictating how to use their goods.
Dynamic Island is a poor man’s multi-task for iPhone, and that’s fine it works for most iPhone users. For substantial productivity Apple prefers you to get an iPad or a MacBook. That’s part of the reason for restrictive features on certain Apple devices, but sometimes it’s based on principles to preserve the integrity of the product, according to Apple’s definition.
Is Apple using deception?
Dynamic Island may be distracting you from a design decision. The answer is kind of. Elegant distraction
When you pull down a smartphone webpage to refresh it or minimize an app, you get seamless animations. It's not simply because it appears better; it's due to iPhone and smartphone processing speeds. Such limits reduce the system's response to your activity, slowing the experience. Designers and developers use animations and effects to distract us from the time lag (most of the time) and sometimes because it looks cooler and smoother.
Dynamic Island makes apps more useable and interactive. It shows system states visually. Turn signal audio and visual cues, voice assistance, physical and digital haptic feedbacks, heads-up displays, fuel and battery level gauges, and gear shift indicators helped us overcome vehicle design problems.
Dynamic Island is a wonderfully delightful (and temporary) solution to a design “problem” until Apple or other companies can figure out a way to sink the cameras under the smartphone screen.

Apple Has Returned to Being an Innovative & Exciting Company
Now Apple's products are exciting. Next, bring back real Apple events, not pre-recorded demos.
Dynamic Island integrates hardware and software. What will this new tech do? How would this affect device use? Or is it just hype?
Dynamic Island may be an insignificant improvement to the iPhone, but it sure is promising for the future of bridging the human and computer interaction gap.

Nitin Sharma
3 years ago
The result of my side-hustle blog post with ChatGPT is remarkable.
It's free now.

Most content writers—including me—write about side hustles because they do well.
I wrote several articles on a profitable programming side hustle.
Later, I learnt about AI content-generating platforms like Jasper.ai and Copy.ai, which I thought were terrible because they required subscriptions and had bad content. Even I dislike automatic online posting.
Since ChatGPT is becoming more popular, I tried it. It's free now.
Note: I wasn’t compensated to write this piece by this tool. In other words, I don’t receive any payment from their founders. There is no affiliate link, and right now it is free to use. Also, ChatGPT can do a lot more than what I ever did.
Begin.
OpenAI account registration requires visiting the website (if you don’t have one). Just write anything into the chatbot and get a response.
First, I wrote about the top 10 2023 side businesses.
This came in seconds.
2023 is shaping up to be a year of growth and opportunity for entrepreneurs and side hustlers. With the rise of remote work and the growing gig economy, there are many income streams to consider launching in the coming year. Here are the top 10 income streams to launch in 2023:
Virtual Assistant — The demand for virtual assistants is on the rise as more businesses move online. As a virtual assistant, you can offer administrative, technical, or creative services to clients remotely.
Online Tutoring — If you have expertise in a particular subject, consider becoming an online tutor. There are many platforms that connect tutors with students looking for help with their studies.
Freelance Writing — If you have a knack for writing, consider becoming a freelance writer. You can offer your services to businesses, bloggers, and individuals looking for content for their websites or social media platforms.
Graphic Design — If you have a talent for design, consider starting a graphic design side hustle. You can create logos, banners, and other visual content for businesses and individuals.
Social Media Management — Many businesses are looking for help with managing their social media accounts. As a social media manager, you can help businesses create and execute social media strategies to reach their target audience.
Dropshipping — Dropshipping is a business model where you sell products without actually holding any inventory. You can partner with suppliers and ship the products directly to the customer on behalf of the business.
Pet Sitting — If you love animals, consider starting a pet-sitting side hustle. You can offer your services to pet owners who need someone to take care of their pets while they are away.
Home Cleaning — With busy schedules, many people are looking for help with cleaning their homes. As a home cleaning service provider, you can offer your services to help keep homes tidy and organized.
Event Planning — If you have a talent for organization and planning, consider starting an event planning side hustle. You can offer your services to help plan and execute events for businesses and individuals.
Online Teaching — With the rise of online education, there is a growing demand for online teachers. If you have expertise in a particular subject, consider becoming an online teacher and offer your services to students looking for personalized instruction.
In conclusion, 2023 is shaping up to be a great year for launching new income streams. Whether you are looking to start a virtual assistant business, become an online tutor, or offer home cleaning services, there are many opportunities to turn your skills and expertise into a profitable side hustle.
Better than most online side hustle posts, right?
Write about the top 10 programming side hustles to start in 2023.
I got this.
If you are a programmer looking to start a side hustle, 2023 is the perfect time to launch your own business. With the growing demand for software and app development, there are many opportunities for programmers to turn their skills into a profitable side hustle. Here are the top 10 programming side hustles to start in 2023:
App Development — With the rise of smartphones and tablets, there is a growing demand for app development. You can offer your services to businesses and individuals looking to create custom apps for their needs.
Website Development — Many businesses and individuals are looking for help with creating and maintaining their websites. As a website developer, you can offer your services to help design, build, and manage websites for your clients.
Software Development — If you have expertise in a particular programming language, consider starting a software development side hustle. You can offer your services to businesses and individuals looking to create custom software solutions for their needs.
Game Development — The gaming industry is thriving, and there is a growing demand for game development. If you have experience in game development, you can offer your services to businesses and individuals looking to create custom games.
Data Analysis — With the rise of big data, there is a growing demand for data analysts. As a data analyst, you can offer your services to businesses and individuals looking to make sense of their data and gain insights from it.
Machine Learning — Machine learning is a rapidly growing field, and there is a growing demand for machine learning experts. If you have experience in machine learning, you can offer your services to businesses and individuals looking to develop custom machine learning solutions.
Cloud Computing — With the rise of cloud computing, there is a growing demand for cloud experts. If you have experience in cloud computing, you can offer your services to businesses and individuals looking to migrate their applications and data to the cloud.
Blockchain Development — Blockchain technology is gaining popularity, and there is a growing demand for blockchain developers. If you have experience in blockchain development, you can offer your services to businesses and individuals looking to develop custom blockchain solutions.
Artificial Intelligence — Artificial intelligence is a rapidly growing field, and there is a growing demand for AI experts. If you have experience in artificial intelligence, you can offer your services to businesses and individuals looking to develop custom AI solutions.
Virtual Reality — Virtual reality is an exciting and emerging technology, and there is a growing demand for VR developers. If you have experience in VR development, you can offer your services to businesses and individuals looking to create custom VR experiences.
In conclusion, 2023 is a great time to start a programming side hustle. Whether you are interested in app development, website development, or machine learning, there are many opportunities for programmers to turn their skills into a profitable business.
These two blogs show that AI can simplify blog authoring.
I asked some tough programming questions, and most were suitable.
The content may occasionally not be what we want, but it will almost always be very helpful to you.
Enjoy.

Liz Martin
3 years ago
A Search Engine From Apple?

Apple's search engine has long been rumored. Recent Google developments may confirm the rumor. Is Apple about to become Google's biggest rival?
Here's a video:
People noted Apple's changes in 2020. AppleBot, a web crawler that downloads and caches Internet content, was more active than in the last five years.
Apple hired search engine developers, including ex-Googlers, such as John Giannandrea, Google's former search chief.
Apple also changed the way iPhones search. With iOS 14, Apple's search results arrived before Google's.
These facts fueled rumors that Apple was developing a search engine.
Apple and Google Have a Contract
Many skeptics said Apple couldn't compete with Google. This didn't affect the company's competitiveness.
Apple is the only business with the resources and scale to be a Google rival, with 1.8 billion active devices and a $2 trillion market cap.
Still, people doubted that due to a license deal. Google pays Apple $8 to $12 billion annually to be the default iPhone and iPad search engine.
Apple can't build an independent search product under this arrangement.
Why would Apple enter search if it's being paid to stay out?
Ironically, this partnership has many people believing Apple is getting into search.
A New Default Search Engine May Be Needed
Google was sued for antitrust in 2020. It is accused of anticompetitive and exclusionary behavior. Justice wants to end Google's monopoly.
Authorities could restrict Apple and Google's licensing deal due to its likely effect on market competitiveness. Hence Apple needs a new default search engine.
Apple Already Has a Search Engine
The company already has a search engine, Spotlight.

Since 2004, Spotlight has aired. It was developed to help users find photos, documents, apps, music, and system preferences.
Apple's search engine could do more than organize files, texts, and apps.
Spotlight Search was updated in 2014 with iOS 8. Web, App Store, and iTunes searches became available. You could find nearby places, movie showtimes, and news.
This search engine has subsequently been updated and improved. Spotlight added rich search results last year.
If you search for a TV show, movie, or song, photos and carousels will appear at the top of the page.
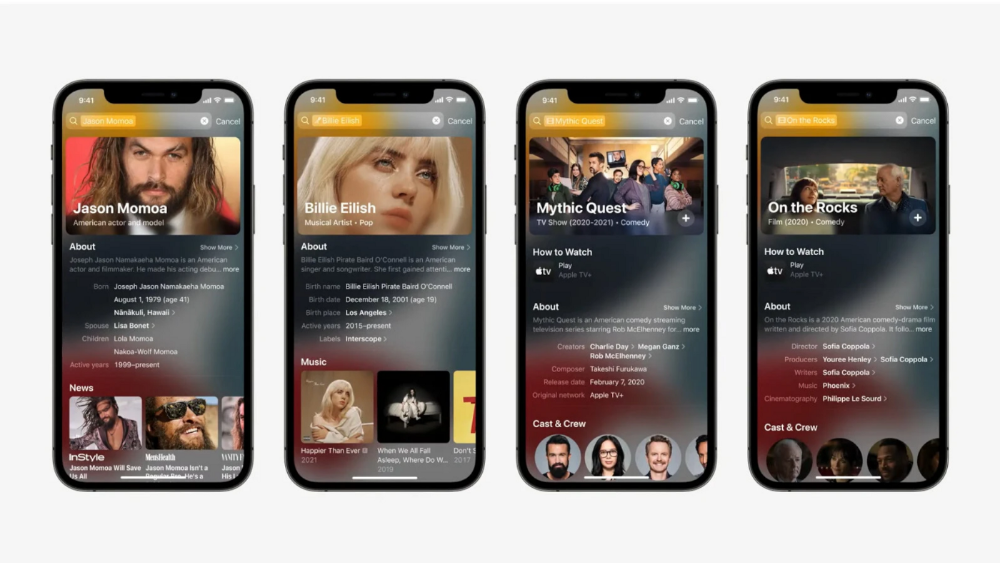
This resembles Google's rich search results.
When Will the Apple Search Engine Be Available?
When will Apple's search launch? Robert Scoble says it's near.
Scoble tweeted a number of hints before this year's Worldwide Developer Conference.
Scoble bases his prediction on insider information and deductive reasoning. January 2023 is expected.
Will you use Apple's search engine?
You might also like

Scrum Ventures
3 years ago
Trends from the Winter 2022 Demo Day at Y Combinators

Y Combinators Winter 2022 Demo Day continues the trend of more startups engaging in accelerator Demo Days. Our team evaluated almost 400 projects in Y Combinator's ninth year.
After Winter 2021 Demo Day, we noticed a hurry pushing shorter rounds, inflated valuations, and larger batches.
Despite the batch size, this event's behavior showed a return to normalcy. Our observations show that investors evaluate and fund businesses more carefully. Unlike previous years, more YC businesses gave investors with data rooms and thorough pitch decks in addition to valuation data before Demo Day.
Demo Day pitches were virtual and fast-paced, limiting unplanned meetings. Investors had more time and information to do their due research before meeting founders. Our staff has more time to study diverse areas and engage with interesting entrepreneurs and founders.
This was one of the most regionally diversified YC cohorts to date. This year's Winter Demo Day startups showed some interesting tendencies.
Trends and Industries to Watch Before Demo Day
Demo day events at any accelerator show how investment competition is influencing startups. As startups swiftly become scale-ups and big success stories in fintech, e-commerce, healthcare, and other competitive industries, entrepreneurs and early-stage investors feel pressure to scale quickly and turn a notion into actual innovation.
Too much eagerness can lead founders to focus on market growth and team experience instead of solid concepts, technical expertise, and market validation. Last year, YC Winter Demo Day funding cycles ended too quickly and valuations were unrealistically high.
Scrum Ventures observed a longer funding cycle this year compared to last year's Demo Day. While that seems promising, many factors could be contributing to change, including:
Market patterns are changing and the economy is becoming worse.
the industries that investors are thinking about.
Individual differences between each event batch and the particular businesses and entrepreneurs taking part
The Winter 2022 Batch's Trends
Each year, we also wish to examine trends among early-stage firms and YC event participants. More international startups than ever were anticipated to present at Demo Day.
Less than 50% of demo day startups were from the U.S. For the S21 batch, firms from outside the US were most likely in Latin America or Europe, however this year's batch saw a large surge in startups situated in Asia and Africa.
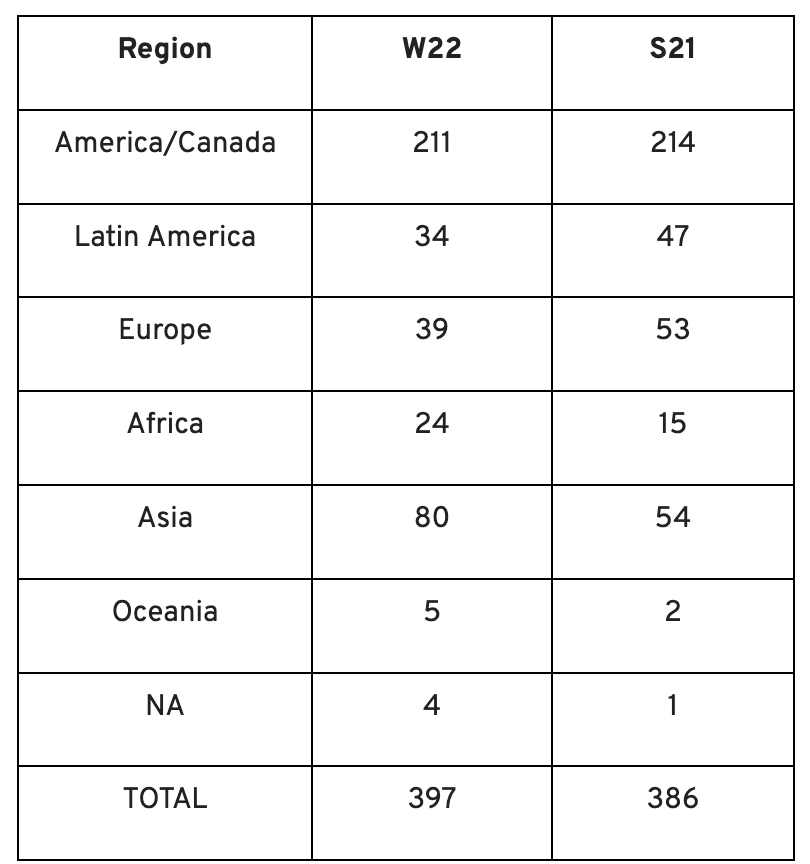
YC Startup Directory
163 out of 399 startups were B2B software and services companies. Financial, healthcare, and consumer startups were common.
Our team doesn't plan to attend every pitch or speak with every startup's founders or team members. Let's look at cleantech, Web3, and health and wellness startup trends.
Our Opinions Following Conversations with 87 Startups at Demo Day
In the lead-up to Demo Day, we spoke with 87 of the 125 startups going. Compared to B2C enterprises, B2B startups had higher average valuations. A few outliers with high valuations pushed B2B and B2C means above the YC-wide mean and median.
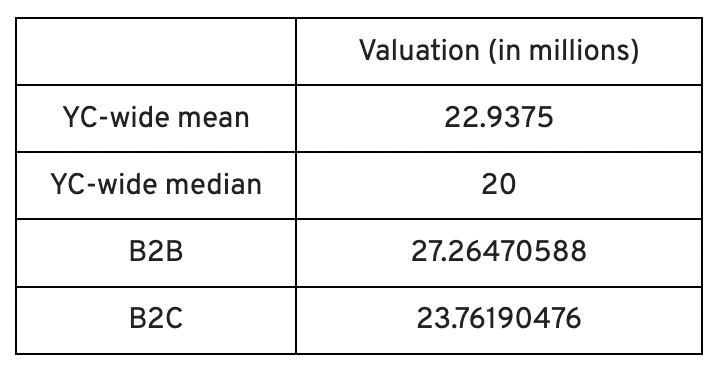
Many of these startups develop business and technology solutions we've previously covered. We've seen API, EdTech, creative platforms, and cybersecurity remain strong and increase each year.
While these persistent tendencies influenced the startups Scrum Ventures looked at and the founders we interacted with on Demo Day, new trends required more research and preparation. Let's examine cleantech, Web3, and health and wellness startups.
Hardware and software that is green
Cleantech enterprises demand varying amounts of funding for hardware and software. Although the same overarching trend is fueling the growth of firms in this category, each subgroup has its own strategy and technique for investigation and identifying successful investments.
Many cleantech startups we spoke to during the YC event are focused on helping industrial operations decrease or recycle carbon emissions.
Carbon Crusher: Creating carbon negative roads
Phase Biolabs: Turning carbon emissions into carbon negative products and carbon neutral e-fuels
Seabound: Capturing carbon dioxide emissions from ships
Fleetzero: Creating electric cargo ships
Impossible Mining: Sustainable seabed mining
Beyond Aero: Creating zero-emission private aircraft
Verdn: Helping businesses automatically embed environmental pledges for product and service offerings, boost customer engagement
AeonCharge: Allowing electric vehicle (EV) drivers to more easily locate and pay for EV charging stations
Phoenix Hydrogen: Offering a hydrogen marketplace and a connected hydrogen hub platform to connect supply and demand for hydrogen fuel and simplify hub planning and partner program expansion
Aklimate: Allowing businesses to measure and reduce their supply chain’s environmental impact
Pina Earth: Certifying and tracking the progress of businesses’ forestry projects
AirMyne: Developing machines that can reverse emissions by removing carbon dioxide from the air
Unravel Carbon: Software for enterprises to track and reduce their carbon emissions
Web3: NFTs, the metaverse, and cryptocurrency
Web3 technologies handle a wide range of business issues. This category includes companies employing blockchain technology to disrupt entertainment, finance, cybersecurity, and software development.
Many of these startups overlap with YC's FinTech trend. Despite this, B2C and B2B enterprises were evenly represented in Web3. We examined:
Stablegains: Offering consistent interest on cash balance from the decentralized finance (DeFi) market
LiquiFi: Simplifying token management with automated vesting contracts, tax reporting, and scheduling. For companies, investors, and finance & accounting
NFTScoring: An NFT trading platform
CypherD Wallet: A multichain wallet for crypto and NFTs with a non-custodial crypto debit card that instantly converts coins to USD
Remi Labs: Allowing businesses to more easily create NFT collections that serve as access to products, memberships, events, and more
Cashmere: A crypto wallet for Web3 startups to collaboratively manage funds
Chaingrep: An API that makes blockchain data human-readable and tokens searchable
Courtyard: A platform for securely storing physical assets and creating 3D representations as NFTs
Arda: “Banking as a Service for DeFi,” an API that FinTech companies can use to embed DeFi products into their platforms
earnJARVIS: A premium cryptocurrency management platform, allowing users to create long-term portfolios
Mysterious: Creating community-specific experiences for Web3 Discords
Winter: An embeddable widget that allows businesses to sell NFTs to users purchasing with a credit card or bank transaction
SimpleHash: An API for NFT data that provides compatibility across blockchains, standardized metadata, accurate transaction info, and simple integration
Lifecast: Tools that address motion sickness issues for 3D VR video
Gym Class: Virtual reality (VR) multiplayer basketball video game
WorldQL: An asset API that allows NFT creators to specify multiple in-game interpretations of their assets, increasing their value
Bonsai Desk: A software development kit (SDK) for 3D analytics
Campfire: Supporting virtual social experiences for remote teams
Unai: A virtual headset and Visual World experience
Vimmerse: Allowing creators to more easily create immersive 3D experiences
Fitness and health
Scrum Ventures encountered fewer health and wellness startup founders than Web3 and Cleantech. The types of challenges these organizations solve are still diverse. Several of these companies are part of a push toward customization in healthcare, an area of biotech set for growth for companies with strong portfolios and experienced leadership.
Here are several startups we considered:
Syrona Health: Personalized healthcare for women in the workplace
Anja Health: Personalized umbilical cord blood banking and stem cell preservation
Alfie: A weight loss program focused on men’s health that coordinates medical care, coaching, and “community-based competition” to help users lose an average of 15% body weight
Ankr Health: An artificial intelligence (AI)-enabled telehealth platform that provides personalized side effect education for cancer patients and data collection for their care teams
Koko — A personalized sleep program to improve at-home sleep analysis and training
Condition-specific telehealth platforms and programs:
Reviving Mind: Chronic care management covered by insurance and supporting holistic, community-oriented health care
Equipt Health: At-home delivery of prescription medical equipment to help manage chronic conditions like obstructive sleep apnea
LunaJoy: Holistic women’s healthcare management for mental health therapy, counseling, and medication
12 Startups from YC's Winter 2022 Demo Day to Watch
Bobidi: 10x faster AI model improvement
Artificial intelligence (AI) models have become a significant tool for firms to improve how well and rapidly they process data. Bobidi helps AI-reliant firms evaluate their models, boosting data insights in less time and reducing data analysis expenditures. The business has created a gamified community that offers a bug bounty for AI, incentivizing community members to test and find weaknesses in clients' AI models.
Magna: DeFi investment management and token vesting
Magna delivers rapid, secure token vesting so consumers may turn DeFi investments into primitives. Carta for Web3 allows enterprises to effortlessly distribute tokens to staff or investors. The Magna team hopes to allow corporations use locked tokens as collateral for loans, facilitate secondary liquidity so investors can sell shares on a public exchange, and power additional DeFi applications.
Perl Street: Funding for infrastructure
This Fintech firm intends to help hardware entrepreneurs get financing by [democratizing] structured finance, unleashing billions for sustainable infrastructure and next-generation hardware solutions. This network has helped hardware entrepreneurs achieve more than $140 million in finance, helping companies working on energy storage devices, EVs, and creating power infrastructure.
CypherD: Multichain cryptocurrency wallet
CypherD seeks to provide a multichain crypto wallet so general customers can explore Web3 products without knowledge hurdles. The startup's beta app lets consumers access crypto from EVM blockchains. The founders have crypto, financial, and startup experience.
Unravel Carbon: Enterprise carbon tracking and offsetting
Unravel Carbon's AI-powered decarbonization technology tracks companies' carbon emissions. Singapore-based startup focuses on Asia. The software can use any company's financial data to trace the supply chain and calculate carbon tracking, which is used to make regulatory disclosures and suggest carbon offsets.
LunaJoy: Precision mental health for women
LunaJoy helped women obtain mental health support throughout life. The platform combines data science to create a tailored experience, allowing women to access psychotherapy, medication management, genetic testing, and health coaching.
Posh: Automated EV battery recycling
Posh attempts to solve one of the EV industry's largest logistical difficulties. Millions of EV batteries will need to be decommissioned in the next decade, and their precious metals and residual capacity will go unused for some time. Posh offers automated, scalable lithium battery disassembly, making EV battery recycling more viable.
Unai: VR headset with 5x higher resolution
Unai stands apart from metaverse companies. Its VR headgear has five times the resolution of existing options and emphasizes human expression and interaction in a remote world. Maxim Perumal's method of latency reduction powers current VR headsets.
Palitronica: Physical infrastructure cybersecurity
Palitronica blends cutting-edge hardware and software to produce networked electronic systems that support crucial physical and supply chain infrastructure. The startup's objective is to build solutions that defend national security and key infrastructure from cybersecurity threats.
Reality Defender: Deepfake detection
Reality Defender alerts firms to bogus users and changed audio, video, and image files. Reality Deference's API and web app score material in real time to prevent fraud, improve content moderation, and detect deception.
Micro Meat: Infrastructure for the manufacture of cell-cultured meat
MicroMeat promotes sustainable meat production. The company has created technologies to scale up bioreactor-grown meat muscle tissue from animal cells. Their goal is to scale up cultured meat manufacturing so cultivated meat products can be brought to market feasibly and swiftly, boosting worldwide meat consumption.
Fleetzero: Electric cargo ships
This startup's battery technology will make cargo ships more sustainable and profitable. Fleetzero's electric cargo ships have five times larger profit margins than fossil fuel ships. Fleetzeros' founder has marine engineering, ship operations, and enterprise sales and business experience.

Alex Mathers
3 years ago
8 guidelines to help you achieve your objectives 5x fast

If you waste time every day, even though you're ambitious, you're not alone.
Many of us could use some new time-management strategies, like these:
Focus on the following three.
You're thinking about everything at once.
You're overpowered.
It's mental. We just have what's in front of us. So savor the moment's beauty.
Prioritize 1-3 things.
To be one of the most productive people you and I know, follow these steps.
Get along with boredom.
Many of us grow bored, sweat, and turn on Netflix.
We shout, "I'm rarely bored!" Look at me! I'm happy.
Shut it, Sally.
You're not making wonderful things for the world. Boredom matters.
If you can sit with it for a second, you'll get insight. Boredom? Breathe.
Go blank.
Then watch your creativity grow.
Check your MacroVision once more.
We don't know what to do with our time, which contributes to time-wasting.
Nobody does, either. Jeff Bezos won't hand-deliver that crap to you.
Daily vision checks are required.
Also:
What are 5 things you'd love to create in the next 5 years?
You're soul-searching. It's food.
Return here regularly, and you'll adore the high you get from doing valuable work.
Improve your thinking.
What's Alex's latest nonsense?
I'm talking about overcoming our own thoughts. Worrying wastes so much time.
Too many of us are assaulted by lies, myths, and insecurity.
Stop letting your worries massage you into a worried coma like a Thai woman.
Optimizing your thoughts requires accepting what you can't control.
It means letting go of unhelpful thoughts and returning to the moment.
Keep your blood sugar level.
I gave up gluten, donuts, and sweets.
This has really boosted my energy.
Blood-sugar-spiking carbs make us irritable and tired.
These day-to-day ups and downs aren't productive. It's crucial.
Know how your diet affects insulin levels. Now I have more energy and can do more without clenching my teeth.
Reduce harmful carbs to boost energy.
Create a focused setting for yourself.
When we optimize the mind, we have more energy and use our time better because we're not tense.
Changing our environment can also help us focus. Disabling alerts is one example.
Too hot makes me procrastinate and irritable.
List five items that hinder your productivity.
You may be amazed at how much you may improve by removing distractions.
Be responsible.
Accountability is a time-saver.
Creating an emotional pull to finish things.
Writing down our goals makes us accountable.
We can engage a coach or work with an accountability partner to feel horrible if we don't show up and finish on time.
‘Hey Jake, I’m going to write 1000 words every day for 30 days — you need to make sure I do.’ ‘Sure thing, Nathan, I’ll be making sure you check in daily with me.’
Tick.
You might also blog about your ambitions to show your dedication.
Now you can't hide when you promised to appear.
Acquire a liking for bravery.
Boldness changes everything.
I sometimes feel lazy and wonder why. If my food and sleep are in order, I should assess my footing.
Most of us live backward. Doubtful. Uncertain. Feelings govern us.
Backfooting isn't living. It's lame, and you'll soon melt. Live boldly now.
Be assertive.
Get disgustingly into everything. Expand.
Even if it's hard, stop being a b*tch.
Those that make Mr. Bold Bear their spirit animal benefit. Save time to maximize your effect.

Caleb Naysmith
3 years ago Draft
A Myth: Decentralization
It’s simply not conceivable, or at least not credible.

One of the most touted selling points of Crypto has always been this grandiose idea of decentralization. Bitcoin first arose in 2009 after the housing crisis and subsequent crash that came with it. It aimed to solve this supposed issue of centralization. Nobody “owns” Bitcoin in theory, so the idea then goes that it won’t be subject to the same downfalls that led to the 2008 crash or similarly speculative events that led to the 2008 disaster. The issue is the banks, not the human nature associated with the greedy individuals running them.
Subsequent blockchains have attempted to fix many of the issues of Bitcoin by increasing capacity, decreasing the costs and processing times associated with Bitcoin, and expanding what can be done with their blockchains. Since nobody owns Bitcoin, it hasn’t really been able to be expanded on. You have people like Vitalk Buterin, however, that actively work on Ethereum though.
The leap from Bitcoin to Ethereum was a massive leap toward centralization, and the trend has only gotten worse. In fact, crypto has since become almost exclusively centralized in recent years.
Decentralization is only good in theory
It’s a good idea. In fact, it’s a wonderful idea. However, like other utopian societies, individuals misjudge human nature and greed. In a perfect world, decentralization would certainly be a wonderful idea because sure, people may function as their own banks, move payments immediately, remain anonymous, and so on. However, underneath this are a couple issues:
You can already send money instantaneously today.
They are not decentralized.
Decentralization is a bad idea.
Being your own bank is a stupid move.
Let’s break these down. Some are quite simple, but lets have a look.
Sending money right away
One thing with crypto is the idea that you can send payments instantly. This has pretty much been entirely solved in current times. You can transmit significant sums of money instantly for a nominal cost and it’s instantaneously cleared. Venmo was launched in 2009 and has since increased to prominence, and currently is on most people's phones. I can directly send ANY amount of money quickly from my bank to another person's Venmo account.
Comparing that with ETH and Bitcoin, Venmo wins all around. I can send money to someone for free instantly in dollars and the only fee paid is optional depending on when you want it.
Both Bitcoin and Ethereum are subject to demand. If the blockchains have a lot of people trying to process transactions fee’s go up, and the time that it takes to receive your crypto takes longer. When Ethereum gets bad, people have reported spending several thousand of dollars on just 1 transaction.
These transactions take place via “miners” bundling and confirming transactions, then recording them on the blockchain to confirm that the transaction did indeed happen. They charge fees to do this and are also paid in Bitcoin/ETH. When a transaction is confirmed, it's then sent to the other users wallet. This within itself is subject to lots of controversy because each transaction needs to be confirmed 6 times, this takes massive amounts of power, and most of the power is wasted because this is an adversarial system in which the person that mines the transaction gets paid, and everyone else is out of luck. Also, these could theoretically be subject to a “51% attack” in which anyone with over 51% of the mining hash rate could effectively control all of the transactions, and reverse transactions while keeping the BTC resulting in “double spending”.
There are tons of other issues with this, but essentially it means: They rely on these third parties to confirm the transactions. Without people confirming these transactions, Bitcoin stalls completely, and if anyone becomes too dominant they can effectively control bitcoin.
Not to mention, these transactions are in Bitcoin and ETH, not dollars. So, you need to convert them to dollars still, and that's several more transactions, and likely to take several days anyway as the centralized exchange needs to send you the money by traditional methods.
They are not distributed
That takes me to the following point. This isn’t decentralized, at all. Bitcoin is the closest it gets because Satoshi basically closed it to new upgrades, although its still subject to:
Whales
Miners
It’s vital to realize that these are often the same folks. While whales aren’t centralized entities typically, they can considerably effect the price and outcome of Bitcoin. If the largest wallets holding as much as 1 million BTC were to sell, it’d effectively collapse the price perhaps beyond repair. However, Bitcoin can and is pretty much controlled by the miners. Further, Bitcoin is more like an oligarchy than decentralized. It’s been effectively used to make the rich richer, and both the mining and price is impacted by the rich. The overwhelming minority of those actually using it are retail investors. The retail investors are basically never the ones generating money from it either.
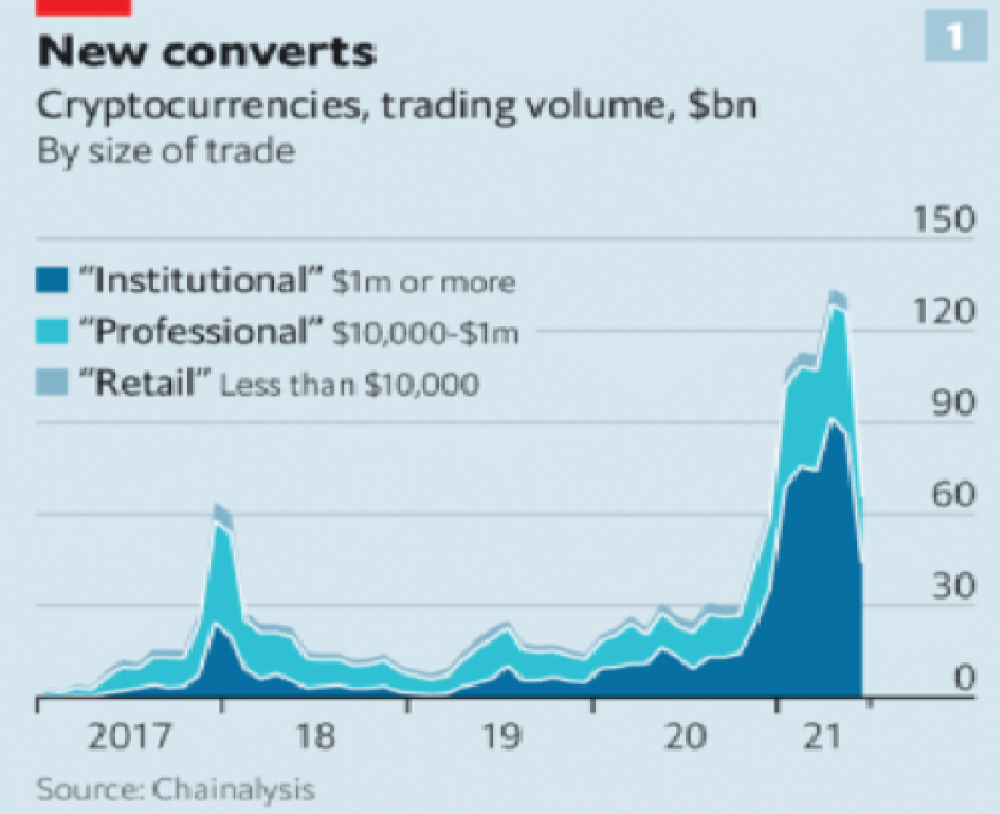
As far as ETH and other cryptos go, there is realistically 0 case for them being decentralized. Vitalik could not only kill it but even walking away from it would likely lead to a significant decline. It has tons of issues right now that Vitalik has promised to fix with the eventual Ethereum 2.0., and stepping away from it wouldn’t help.
Most tokens as well are generally tied to some promise of future developments and creators. The same is true for most NFT projects. The reason 99% of crypto and NFT projects fail is because they failed to deliver on various promises or bad dev teams, or poor innovation, or the founders just straight up stole from everyone. I could go more in-depth than this but go find any project and if there is a dev team, company, or person tied to it then it's likely, not decentralized. The success of that project is directly tied to the dev team, and if they wanted to, most hold large wallets and could sell it all off effectively killing the project. Not to mention, any crypto project that doesn’t have a locked contract can 100% be completely rugged and they can run off with all of the money.
Decentralization is undesirable
Even if they were decentralized then it would not be a good thing. The graphic above indicates this is effectively a rich person’s unregulated playground… so it’s exactly like… the very issue it tried to solve?
Not to mention, it’s supposedly meant to prevent things like 2008, but is regularly subjected to 50–90% drawdowns in value? Back when Bitcoin was only known in niche parts of the dark web and illegal markets, it would regularly drop as much as 90% and has a long history of massive drawdowns.
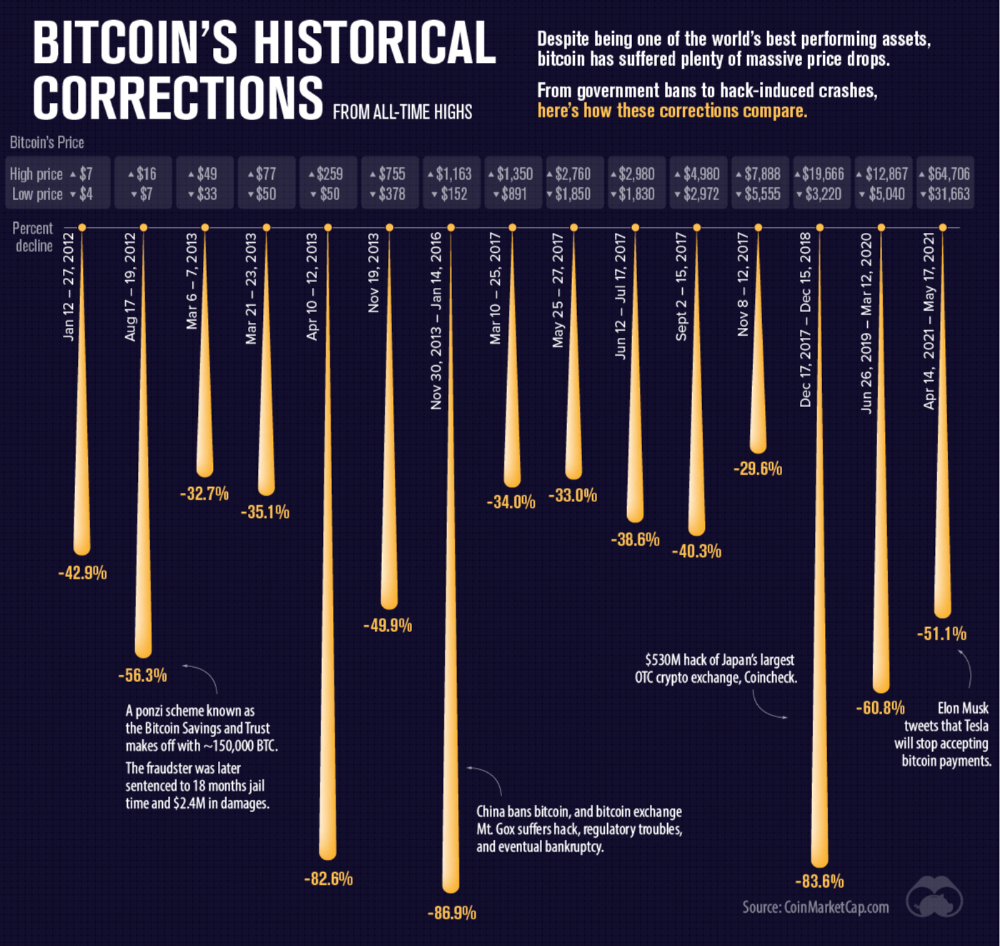
The majority of crypto is blatant scams, and ALL of crypto is a “zero” or “negative” sum game in that it relies on the next person buying for people to make money. This is not a good thing. This has yet to solve any issues around what caused the 2008 crisis. Rather, it seemingly amplified all of the bad parts of it actually. Crypto is the ultimate speculative asset and realistically has no valuation metric. People invest in Apple because it has revenue and cash on hand. People invest in crypto purely for speculation. The lack of regulation or accountability means this is amplified to the most extreme degree where anything goes: Fraud, deception, pump and dumps, scams, etc. This results in a pure speculative madhouse where, unsurprisingly, only the rich win. Not only that but the deck is massively stacked in against the everyday investor because you can’t do a pump and dump without money.
At the heart of all of this is still the same issues: greed and human nature. However, in setting out to solve the issues that allowed 2008 to happen, they made something that literally took all of the bad parts of 2008 and then amplified it. 2008, similarly, was due to greed and human nature but was allowed to happen due to lack of oversite, rich people's excessive leverage over the poor, and excessive speculation. Crypto trades SOLELY on human emotion, has 0 oversite, is pure speculation, and the power dynamic is just as bad or worse.
Why should each individual be their own bank?
This is the last one, and it's short and basic. Why do we want people functioning as their own bank? Everything we do relies on another person. Without the internet, and internet providers there is no crypto. We don’t have people functioning as their own home and car manufacturers or internet service providers. Sure, you might specialize in some of these things, but masquerading as your own bank is a horrible idea.
I am not in the banking industry so I don’t know all the issues with banking. Most people aren’t in banking or crypto, so they don’t know the ENDLESS scams associated with it, and they are bound to lose their money eventually.
If you appreciate this article and want to read more from me and authors like me, without any limits, consider buying me a coffee: buymeacoffee.com/calebnaysmith