



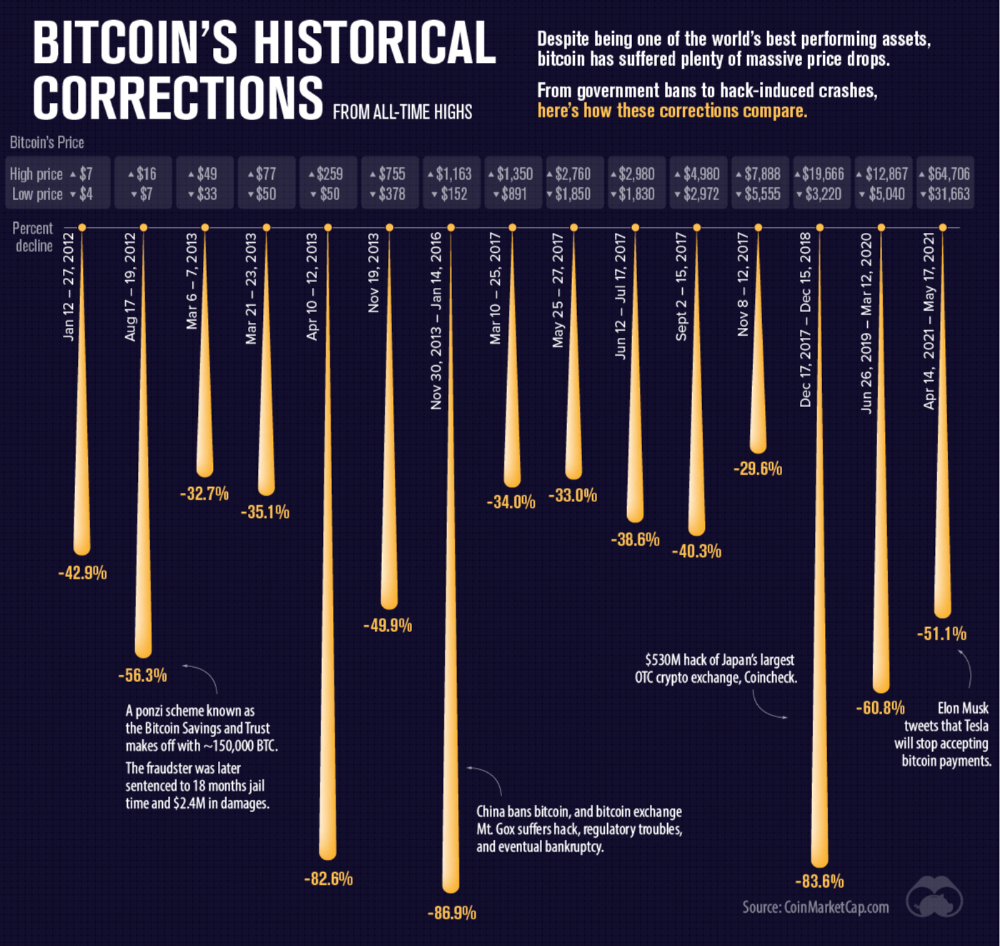
More on Entrepreneurship/Creators

Nick Nolan
3 years ago
In five years, starting a business won't be hip.

People are slowly recognizing entrepreneurship's downside.
Growing up, entrepreneurship wasn't common. High school class of 2012 had no entrepreneurs.
Businesses were different.
They had staff and a lengthy history of achievement.
I never wanted a business. It felt unattainable. My friends didn't care.
Weird.
People desired degrees to attain good jobs at big companies.
When graduated high school:
9 out of 10 people attend college
Earn minimum wage (7%) working in a restaurant or retail establishment
Or join the military (3%)
Later, entrepreneurship became a thing.
2014-ish
I was in the military and most of my high school friends were in college, so I didn't hear anything.
Entrepreneurship soared in 2015, according to Google Trends.
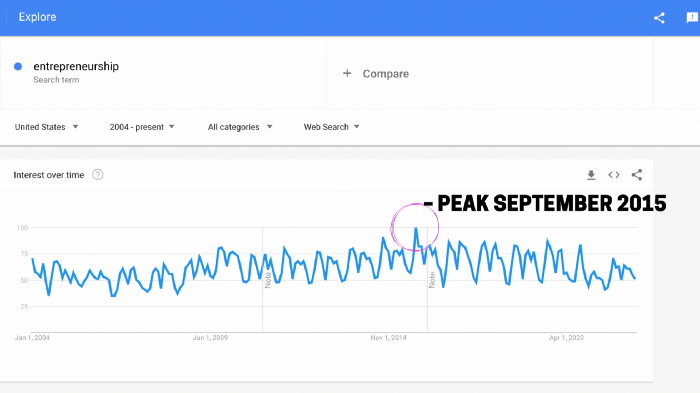
Then more individuals were interested. Entrepreneurship went from unusual to cool.
In 2015, it was easier than ever to build a website, run Facebook advertisements, and achieve organic social media reach.
There were several online business tools.
You didn't need to spend years or money figuring it out. Most entry barriers were gone.
Everyone wanted a side gig to escape the 95.
Small company applications have increased during the previous 10 years.
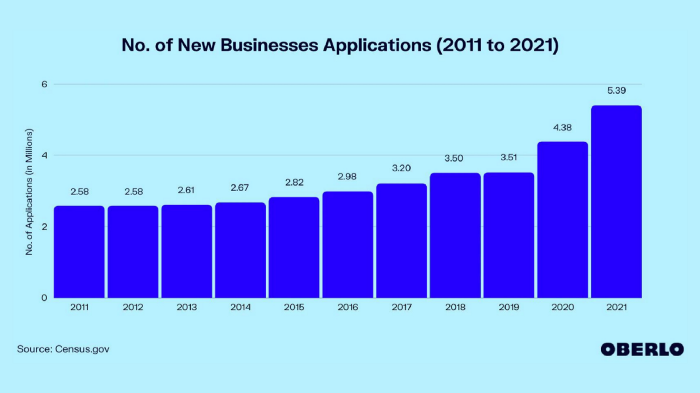
2011-2014 trend continues.
2015 adds 150,000 applications. 2016 adds 200,000. Plus 300,000 in 2017.
The graph makes it look little, but that's a considerable annual spike with no indications of stopping.
By 2021, new business apps had doubled.
Entrepreneurship will return to its early 2010s level.
I think we'll go backward in 5 years.
Entrepreneurship is half as popular as it was in 2015.
In the late 2020s and 30s, entrepreneurship will again be obscure.
Entrepreneurship's decade-long splendor is fading. People will cease escaping 9-5 and launch fewer companies.
That’s not a bad thing.
I think people have a rose-colored vision of entrepreneurship. It's fashionable. People feel that they're missing out if they're not entrepreneurial.
Reality is showing up.
People say on social media, "I knew starting a business would be hard, but not this hard."
More negative posts on entrepreneurship:

Luke adds:
Is being an entrepreneur ‘healthy’? I don’t really think so. Many like Gary V, are not role models for a well-balanced life. Despite what feel-good LinkedIn tells you the odds are against you as an entrepreneur. You have to work your face off. It’s a tough but rewarding lifestyle. So maybe let’s stop glorifying it because it takes a lot of (bleepin) work to survive a pandemic, mental health battles, and a competitive market.
Entrepreneurship is no longer a pipe dream.
It’s hard.
I went full-time in March 2020. I was done by April 2021. I had a good-paying job with perks.
When that fell through (on my start date), I had to continue my entrepreneurial path. I needed money by May 1 to pay rent.
Entrepreneurship isn't as great as many think.
Entrepreneurship is a serious business.
If you have a 9-5, the grass isn't greener here. Most people aren't telling the whole story when they post on social media or quote successful entrepreneurs.
People prefer to communicate their victories than their defeats.
Is this a bad thing?
I don’t think so.
Over the previous decade, entrepreneurship went from impossible to the finest thing ever.
It peaked in 2020-21 and is returning to reality.
Startups aren't for everyone.
If you like your job, don't quit.
Entrepreneurship won't amaze people if you quit your job.
It's irrelevant.
You're doomed.
And you'll probably make less money.
If you hate your job, quit. Change jobs and bosses. Changing jobs could net you a greater pay or better perks.
When you go solo, your paycheck and perks vanish. Did I mention you'll fail, sleep less, and stress more?
Nobody will stop you from pursuing entrepreneurship. You'll face several challenges.
Possibly.
Entrepreneurship may be romanticized for years.
Based on what I see from entrepreneurs on social media and trends, entrepreneurship is challenging and few will succeed.

Aaron Dinin, PhD
3 years ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.

Rick Blyth
3 years ago
Looking for a Reliable Micro SaaS Niche
Niches are rich, as the adage goes.
Micro SaaS requires a great micro-niche; otherwise, it's merely plain old SaaS with a large audience.
Instead of targeting broad markets with few identifying qualities, specialise down to a micro-niche. How would you target these users?

Better go tiny. You'll locate and engage new consumers more readily and serve them better with a customized solution.
Imagine you're a real estate lawyer looking for a case management solution. Because it's so specific to you, you'd be lured to this link:

instead of below:

Next, locate mini SaaS niches that could work for you. You're not yet looking at the problems/solutions in these areas, merely shortlisting them.
The market should be growing, not shrinking
We shouldn't design apps for a declining niche. We intend to target stable or growing niches for the next 5 to 10 years.
If it's a developing market, you may be able to claim a stake early. You must balance this strategy with safer, longer-established niches (accountancy, law, health, etc).
First Micro SaaS apps I designed were for Merch By Amazon creators, a burgeoning niche. I found this niche when searching for passive income.
Graphic designers and entrepreneurs post their art to Amazon to sell on clothes. When Amazon sells their design, they get a royalty. Since 2015, this platform and specialty have grown dramatically.
Amazon doesn't publicize the amount of creators on the platform, but it's possible to approximate by looking at Facebook groups, Reddit channels, etc.
I could see the community growing week by week, with new members joining. Merch was an up-and-coming niche, and designers made money when their designs sold. All I had to do was create tools that let designers focus on making bestselling designs.
Look at the Google Trends graph below to see how this niche has evolved and when I released my apps and resigned my job.
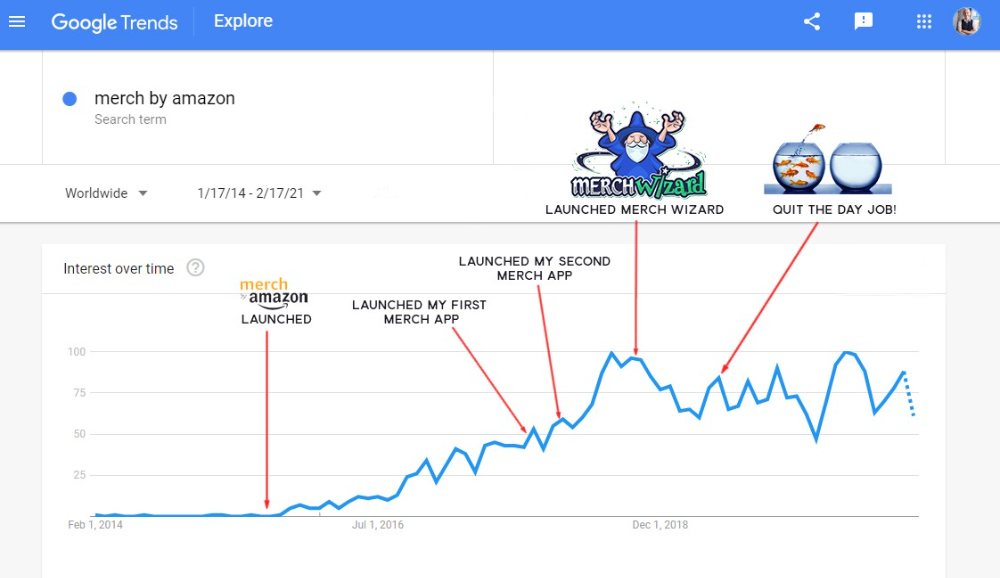
Are the users able to afford the tools?
Who's your average user? Consumer or business? Is your solution budgeted?
If they're students, you'll struggle to convince them to subscribe to your study-system app (ahead of video games and beer).
Let's imagine you designed a Shopify plugin that emails customers when a product is restocked. If your plugin just needs 5 product sales a month to justify its cost, everyone wins (just be mindful that one day Shopify could potentially re-create your plugins functionality within its core offering making your app redundant ).
Do specialized users buy tools? If so, that's comforting. If not, you'd better have a compelling value proposition for your end customer if you're the first.
This should include how much time or money your program can save or make the user.

Are you able to understand the Micro SaaS market?
Ideally, you're already familiar about the industry/niche. Maybe you're fixing a challenge from your day job or freelance work.
If not, evaluate how long it would take to learn the niche's users. Health & Fitness is easier to relate to and understand than hedge fund derivatives trading.
Competing in these complex (and profitable) fields might offer you an edge.

B2C, B2M, or B2B?
Consider your user base's demographics. Will you target businesses, consumers, or both? Let's examine the different consumer types:
B2B refers to business-to-business transactions where customers are other businesses. UpVoty, Plutio, Slingshot, Salesforce, Atlassian, and Hubspot are a few examples of SaaS, ranging from Micro SaaS to SaaS.
Business to Consumer (B2C), in which your clients are people who buy things. For instance, Duolingo, Canva, and Nomad List.
For instance, my tool KDP Wizard has a mixed user base of publishing enterprises and also entrepreneurial consumers selling low-content books on Amazon. This is a case of business to many (B2M), where your users are a mixture of businesses and consumers. There is a large SaaS called Dropbox that offers both personal and business plans.
Targeting a B2B vs. B2C niche is very different. The sales cycle differs.
A B2B sales staff must make cold calls to potential clients' companies. Long sales, legal, and contractual conversations are typically required for each business to get the go-ahead. The cost of obtaining a new customer is substantially more than it is for B2C, despite the fact that the recurring fees are significantly higher.
Since there is typically only one individual making the purchasing decision, B2C signups are virtually always self-service with reduced recurring fees. Since there is typically no outbound sales staff in B2C, acquisition costs are significantly lower than in B2B.
User Characteristics for B2B vs. B2C
Consider where your niche's users congregate if you don't already have a presence there.
B2B users frequent LinkedIn and Twitter. B2C users are on Facebook/Instagram/Reddit/Twitter, etc.
Churn is higher in B2C because consumers haven't gone through all the hoops of a B2B sale. Consumers are more unpredictable than businesses since they let their bank cards exceed limitations or don't update them when they expire.
With a B2B solution, there's a contractual arrangement and the firm will pay the subscription as long as they need it.
Depending on how you feel about the above (sales team vs. income vs. churn vs. targeting), you'll know which niches to pursue.
You ought to respect potential customers.
Would you hang out with customers?
You'll connect with users at conferences (in-person or virtual), webinars, seminars, screenshares, Facebook groups, emails, support calls, support tickets, etc.
If talking to a niche's user base makes you shudder, you're in for a tough road. Whether they're demanding or dull, avoid them if possible.
Merch users are mostly graphic designers, side hustlers, and entrepreneurs. These laid-back users embrace technologies that assist develop their Merch business.
I discovered there was only one annual conference for this specialty, held in Seattle, USA. I decided to organize a conference for UK/European Merch designers, despite never having done so before.

Hosting a conference for over 80 people was stressful, and it turned out to be much bigger than expected, with attendees from the US, Europe, and the UK.
I met many specialized users, built relationships, gained trust, and picked their brains in person. Many of the attendees were already Merch Wizard users, so hearing their feedback and ideas for future features was invaluable.
focused and specific
Instead of building for a generic, hard-to-reach market, target a specific group.
I liken it to fishing in a little, hidden pond. This small pond has only one species of fish, so you learn what bait it likes. Contrast that with trawling for hours to catch as many fish as possible, even if some aren't what you want.
In the case management scenario, it's difficult to target leads because several niches could use the app. Where do your potential customers hang out? Your generic solution: No.
It's easier to join a community of Real Estate Lawyers and see if your software can answer their pain points.
My Success with Micro SaaS
In my case, my Micro SaaS apps have been my chrome extensions. Since I launched them, they've earned me an average $10k MRR, allowing me to quit my lousy full-time job years ago.
I sold my apps after scaling them for a life-changing lump amount. Since then, I've helped unfulfilled software developers escape the 9-5 through Micro SaaS.
Whether it's a profitable side hustle or a liferaft to quit their job and become their own Micro SaaS boss.
Having built my apps to the point where I could quit my job, then scaled and sold them, I feel I can share my skills with software developers worldwide.
Read my free guide on self-funded SaaS to discover more about Micro SaaS, or download your own copy. 12 chapters cover everything from Idea to Exit.

Watch my YouTube video to learn how to construct a Micro SaaS app in 10 steps.
You might also like

Caleb Naysmith
3 years ago Draft
A Myth: Decentralization
It’s simply not conceivable, or at least not credible.

One of the most touted selling points of Crypto has always been this grandiose idea of decentralization. Bitcoin first arose in 2009 after the housing crisis and subsequent crash that came with it. It aimed to solve this supposed issue of centralization. Nobody “owns” Bitcoin in theory, so the idea then goes that it won’t be subject to the same downfalls that led to the 2008 crash or similarly speculative events that led to the 2008 disaster. The issue is the banks, not the human nature associated with the greedy individuals running them.
Subsequent blockchains have attempted to fix many of the issues of Bitcoin by increasing capacity, decreasing the costs and processing times associated with Bitcoin, and expanding what can be done with their blockchains. Since nobody owns Bitcoin, it hasn’t really been able to be expanded on. You have people like Vitalk Buterin, however, that actively work on Ethereum though.
The leap from Bitcoin to Ethereum was a massive leap toward centralization, and the trend has only gotten worse. In fact, crypto has since become almost exclusively centralized in recent years.
Decentralization is only good in theory
It’s a good idea. In fact, it’s a wonderful idea. However, like other utopian societies, individuals misjudge human nature and greed. In a perfect world, decentralization would certainly be a wonderful idea because sure, people may function as their own banks, move payments immediately, remain anonymous, and so on. However, underneath this are a couple issues:
You can already send money instantaneously today.
They are not decentralized.
Decentralization is a bad idea.
Being your own bank is a stupid move.
Let’s break these down. Some are quite simple, but lets have a look.
Sending money right away
One thing with crypto is the idea that you can send payments instantly. This has pretty much been entirely solved in current times. You can transmit significant sums of money instantly for a nominal cost and it’s instantaneously cleared. Venmo was launched in 2009 and has since increased to prominence, and currently is on most people's phones. I can directly send ANY amount of money quickly from my bank to another person's Venmo account.
Comparing that with ETH and Bitcoin, Venmo wins all around. I can send money to someone for free instantly in dollars and the only fee paid is optional depending on when you want it.
Both Bitcoin and Ethereum are subject to demand. If the blockchains have a lot of people trying to process transactions fee’s go up, and the time that it takes to receive your crypto takes longer. When Ethereum gets bad, people have reported spending several thousand of dollars on just 1 transaction.
These transactions take place via “miners” bundling and confirming transactions, then recording them on the blockchain to confirm that the transaction did indeed happen. They charge fees to do this and are also paid in Bitcoin/ETH. When a transaction is confirmed, it's then sent to the other users wallet. This within itself is subject to lots of controversy because each transaction needs to be confirmed 6 times, this takes massive amounts of power, and most of the power is wasted because this is an adversarial system in which the person that mines the transaction gets paid, and everyone else is out of luck. Also, these could theoretically be subject to a “51% attack” in which anyone with over 51% of the mining hash rate could effectively control all of the transactions, and reverse transactions while keeping the BTC resulting in “double spending”.
There are tons of other issues with this, but essentially it means: They rely on these third parties to confirm the transactions. Without people confirming these transactions, Bitcoin stalls completely, and if anyone becomes too dominant they can effectively control bitcoin.
Not to mention, these transactions are in Bitcoin and ETH, not dollars. So, you need to convert them to dollars still, and that's several more transactions, and likely to take several days anyway as the centralized exchange needs to send you the money by traditional methods.
They are not distributed
That takes me to the following point. This isn’t decentralized, at all. Bitcoin is the closest it gets because Satoshi basically closed it to new upgrades, although its still subject to:
Whales
Miners
It’s vital to realize that these are often the same folks. While whales aren’t centralized entities typically, they can considerably effect the price and outcome of Bitcoin. If the largest wallets holding as much as 1 million BTC were to sell, it’d effectively collapse the price perhaps beyond repair. However, Bitcoin can and is pretty much controlled by the miners. Further, Bitcoin is more like an oligarchy than decentralized. It’s been effectively used to make the rich richer, and both the mining and price is impacted by the rich. The overwhelming minority of those actually using it are retail investors. The retail investors are basically never the ones generating money from it either.
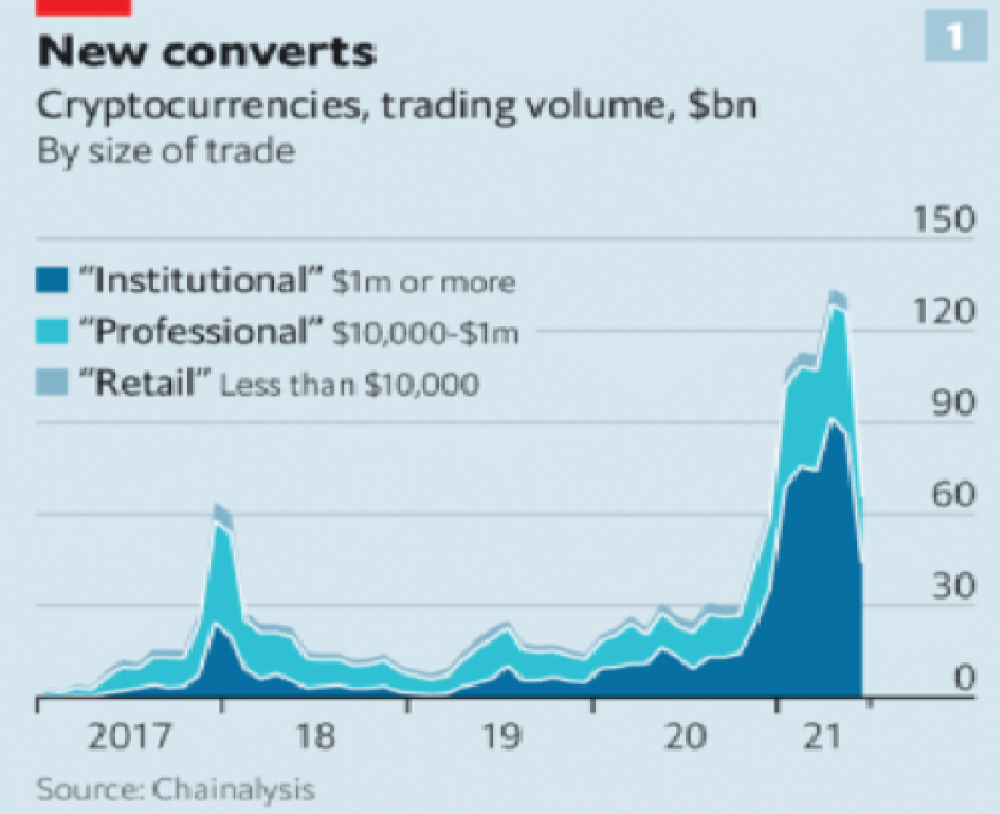
As far as ETH and other cryptos go, there is realistically 0 case for them being decentralized. Vitalik could not only kill it but even walking away from it would likely lead to a significant decline. It has tons of issues right now that Vitalik has promised to fix with the eventual Ethereum 2.0., and stepping away from it wouldn’t help.
Most tokens as well are generally tied to some promise of future developments and creators. The same is true for most NFT projects. The reason 99% of crypto and NFT projects fail is because they failed to deliver on various promises or bad dev teams, or poor innovation, or the founders just straight up stole from everyone. I could go more in-depth than this but go find any project and if there is a dev team, company, or person tied to it then it's likely, not decentralized. The success of that project is directly tied to the dev team, and if they wanted to, most hold large wallets and could sell it all off effectively killing the project. Not to mention, any crypto project that doesn’t have a locked contract can 100% be completely rugged and they can run off with all of the money.
Decentralization is undesirable
Even if they were decentralized then it would not be a good thing. The graphic above indicates this is effectively a rich person’s unregulated playground… so it’s exactly like… the very issue it tried to solve?
Not to mention, it’s supposedly meant to prevent things like 2008, but is regularly subjected to 50–90% drawdowns in value? Back when Bitcoin was only known in niche parts of the dark web and illegal markets, it would regularly drop as much as 90% and has a long history of massive drawdowns.
The majority of crypto is blatant scams, and ALL of crypto is a “zero” or “negative” sum game in that it relies on the next person buying for people to make money. This is not a good thing. This has yet to solve any issues around what caused the 2008 crisis. Rather, it seemingly amplified all of the bad parts of it actually. Crypto is the ultimate speculative asset and realistically has no valuation metric. People invest in Apple because it has revenue and cash on hand. People invest in crypto purely for speculation. The lack of regulation or accountability means this is amplified to the most extreme degree where anything goes: Fraud, deception, pump and dumps, scams, etc. This results in a pure speculative madhouse where, unsurprisingly, only the rich win. Not only that but the deck is massively stacked in against the everyday investor because you can’t do a pump and dump without money.
At the heart of all of this is still the same issues: greed and human nature. However, in setting out to solve the issues that allowed 2008 to happen, they made something that literally took all of the bad parts of 2008 and then amplified it. 2008, similarly, was due to greed and human nature but was allowed to happen due to lack of oversite, rich people's excessive leverage over the poor, and excessive speculation. Crypto trades SOLELY on human emotion, has 0 oversite, is pure speculation, and the power dynamic is just as bad or worse.
Why should each individual be their own bank?
This is the last one, and it's short and basic. Why do we want people functioning as their own bank? Everything we do relies on another person. Without the internet, and internet providers there is no crypto. We don’t have people functioning as their own home and car manufacturers or internet service providers. Sure, you might specialize in some of these things, but masquerading as your own bank is a horrible idea.
I am not in the banking industry so I don’t know all the issues with banking. Most people aren’t in banking or crypto, so they don’t know the ENDLESS scams associated with it, and they are bound to lose their money eventually.
If you appreciate this article and want to read more from me and authors like me, without any limits, consider buying me a coffee: buymeacoffee.com/calebnaysmith
Dmytro Spilka
3 years ago
Why NFTs Have a Bright Future Away from Collectible Art After Punks and Apes

After a crazy second half of 2021 and significant trade volumes into 2022, the market for NFT artworks like Bored Ape Yacht Club, CryptoPunks, and Pudgy Penguins has begun a sharp collapse as market downturns hit token values.
DappRadar data shows NFT monthly sales have fallen below $1 billion since June 2021. OpenSea, the world's largest NFT exchange, has seen sales volume decline 75% since May and is trading like July 2021.
Prices of popular non-fungible tokens have also decreased. Bored Ape Yacht Club (BAYC) has witnessed volume and sales drop 63% and 15%, respectively, in the past month.
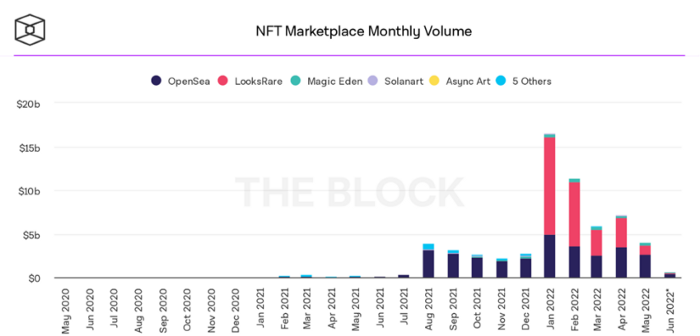
BeInCrypto analysis shows market decline. May 2022 cryptocurrency marketplace volume was $4 billion, according to a news platform. This is a sharp drop from April's $7.18 billion.
OpenSea, a big marketplace, contributed $2.6 billion, while LooksRare, Magic Eden, and Solanart also contributed.
NFT markets are digital platforms for buying and selling tokens, similar stock trading platforms. Although some of the world's largest exchanges offer NFT wallets, most users store their NFTs on their favorite marketplaces.
In January 2022, overall NFT sales volume was $16.57 billion, with LooksRare contributing $11.1 billion. May 2022's volume was $12.57 less than January, a 75% drop, and June's is expected to be considerably smaller.
A World Based on Utility
Despite declines in NFT trading volumes, not all investors are negative on NFTs. Although there are uncertainties about the sustainability of NFT-based art collections, there are fewer reservations about utility-based tokens and their significance in technology's future.
In June, business CEO Christof Straub said NFTs may help artists monetize unreleased content, resuscitate catalogs, establish deeper fan connections, and make processes more efficient through technology.
We all know NFTs can't be JPEGs. Straub noted that NFT music rights can offer more equitable rewards to musicians.
Music NFTs are here to stay if they have real value, solve real problems, are trusted and lawful, and have fair and sustainable business models.
NFTs can transform numerous industries, including music. Market opinion is shifting towards tokens with more utility than the social media artworks we're used to seeing.
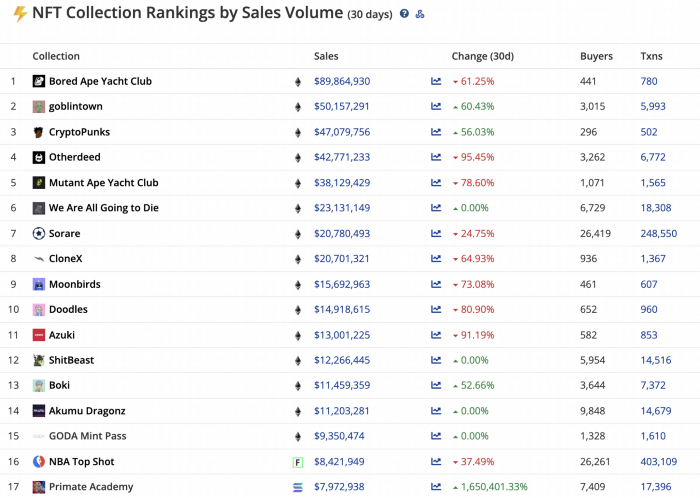
While the major NFT names remain dominant in terms of volume, new utility-based initiatives are emerging as top 20 collections.
Otherdeed, Sorare, and NBA Top Shot are NFT-based games that rank above Bored Ape Yacht Club and Cryptopunks.
Users can switch video NFTs of basketball players in NBA Top Shot. Similar efforts are emerging in the non-fungible landscape.
Sorare shows how NFTs can support a new way of playing fantasy football, where participants buy and swap trading cards to create a 5-player team that wins rewards based on real-life performances.
Sorare raised 579.7 million in one of Europe's largest Series B financing deals in September 2021. Recently, the platform revealed plans to expand into Major League Baseball.
Strong growth indications suggest a promising future for NFTs. The value of art-based collections like BAYC and CryptoPunks may be questioned as markets become diluted by new limited collections, but the potential for NFTs to become intrinsically linked to tangible utility like online gaming, music and art, and even corporate reward schemes shows the industry has a bright future.

Nabil Alouani
3 years ago
Why Cryptocurrency Is Not Dead Despite the FTX Scam
A fraud, free-market, antifragility tale

Crypto's only rival is public opinion.
In less than a week, mainstream media, bloggers, and TikTokers turned on FTX's founder.
While some were surprised, almost everyone with a keyboard and a Twitter account predicted the FTX collapse. These financial oracles should have warned the 1.2 million people Sam Bankman-Fried duped.
After happening, unexpected events seem obvious to our brains. It's a bug and a feature because it helps us cope with disasters and makes our reasoning suck.
Nobody predicted the FTX debacle. Bloomberg? Politicians. Non-famous. No cryptologists. Who?
When FTX imploded, taking billions of dollars with it, an outrage bomb went off, and the resulting shockwave threatens the crypto market's existence.
As someone who lost more than $78,000 in a crypto scam in 2020, I can only understand people’s reactions. When the dust settles and rationality returns, we'll realize this is a natural occurrence in every free market.
What specifically occurred with FTX? (Skip if you are aware.)
FTX is a cryptocurrency exchange where customers can trade with cash. It reached #3 in less than two years as the fastest-growing platform of its kind.
FTX's performance helped make SBF the crypto poster boy. Other reasons include his altruistic public image, his support for the Democrats, and his company Alameda Research.
Alameda Research made a fortune arbitraging Bitcoin.
Arbitrage trading uses small price differences between two markets to make money. Bitcoin costs $20k in Japan and $21k in the US. Alameda Research did that for months, making $1 million per day.
Later, as its capital grew, Alameda expanded its trading activities and began investing in other companies.
Let's now discuss FTX.
SBF's diabolic master plan began when he used FTX-created FTT coins to inflate his trading company's balance sheets. He used inflated Alameda numbers to secure bank loans.
SBF used money he printed himself as collateral to borrow billions for capital. Coindesk exposed him in a report.
One of FTX's early investors tweeted that he planned to sell his FTT coins over the next few months. This would be a minor event if the investor wasn't Binance CEO Changpeng Zhao (CZ).
The crypto space saw a red WARNING sign when CZ cut ties with FTX. Everyone with an FTX account and a brain withdrew money. Two events followed. FTT fell from $20 to $4 in less than 72 hours, and FTX couldn't meet withdrawal requests, spreading panic.
SBF reassured FTX users on Twitter. Good assets.
He lied.
SBF falsely claimed FTX had a liquidity crunch. At the time of his initial claims, FTX owed about $8 billion to its customers. Liquidity shortages are usually minor. To get cash, sell assets. In the case of FTX, the main asset was printed FTT coins.
Sam wouldn't get out of trouble even if he slashed the discount (from $20 to $4) and sold every FTT. He'd flood the crypto market with his homemade coins, causing the price to crash.
SBF was trapped. He approached Binance about a buyout, which seemed good until Binance looked at FTX's books.
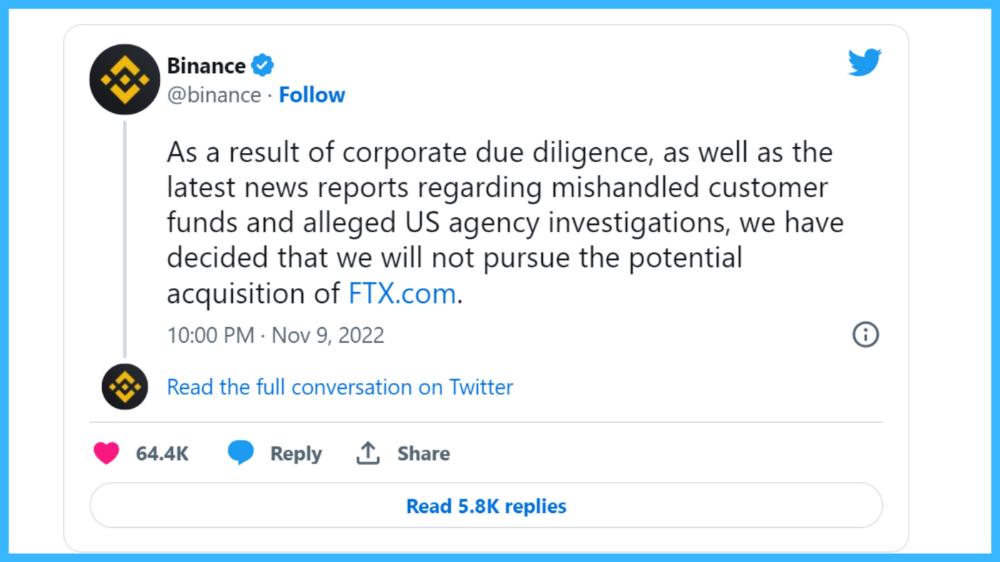
Binance's tweet ended SBF, and he had to apologize, resign as CEO, and file for bankruptcy.
Bloomberg estimated Sam's net worth to be zero by the end of that week. 0!
But that's not all. Twitter investigations exposed fraud at FTX and Alameda Research. SBF used customer funds to trade and invest in other companies.
Thanks to the Twitter indie reporters who made the mainstream press look amateurish. Some Twitter detectives didn't sleep for 30 hours to find answers. Others added to existing threads. Memes were hilarious.
One question kept repeating in my bald head as I watched the Blue Bird. Sam, WTF?
Then I understood.
SBF wanted that FTX becomes a bank.
Think about this. FTX seems healthy a few weeks ago. You buy 2 bitcoins using FTX. You'd expect the platform to take your dollars and debit your wallet, right?
No. They give I-Owe-Yous.
FTX records owing you 2 bitcoins in its internal ledger but doesn't credit your account. Given SBF's tricks, I'd bet on nothing.
What happens if they don't credit my account with 2 bitcoins? Your money goes into FTX's capital, where SBF and his friends invest in marketing, political endorsements, and buying other companies.
Over its two-year existence, FTX invested in 130 companies. Once they make a profit on their purchases, they'll pay you and keep the rest.
One detail makes their strategy dumb. If all FTX customers withdraw at once, everything collapses.
Financially savvy people think FTX's collapse resembles a bank run, and they're right. SBF designed FTX to operate like a bank.
You expect your bank to open a drawer with your name and put $1,000 in it when you deposit $1,000. They deposit $100 in your drawer and create an I-Owe-You for $900. What happens to $900?
Let's sum it up: It's boring and headache-inducing.
When you deposit money in a bank, they can keep 10% and lend the rest. Fractional Reserve Banking is a popular method. Fractional reserves operate within and across banks.
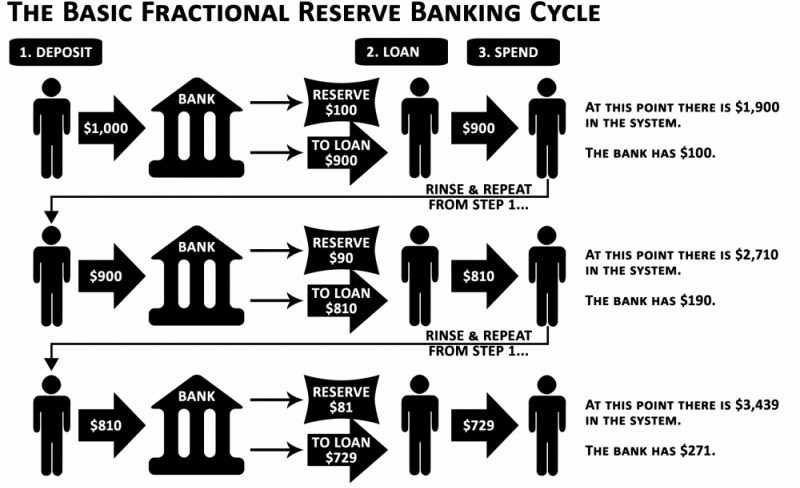
Fractional reserve banking generates $10,000 for every $1,000 deposited. People will pay off their debt plus interest.
As long as banks work together and the economy grows, their model works well.
SBF tried to replicate the system but forgot two details. First, traditional banks need verifiable collateral like real estate, jewelry, art, stocks, and bonds, not digital coupons. Traditional banks developed a liquidity buffer. The Federal Reserve (or Central Bank) injects massive cash into troubled banks.
Massive cash injections come from taxpayers. You and I pay for bankers' mistakes and annual bonuses. Yes, you may think banking is rigged. It's rigged, but it's the best financial game in 150 years. We accept its flaws, including bailouts for too-big-to-fail companies.
Anyway.
SBF wanted Binance's bailout. Binance said no, which was good for the crypto market.
Free markets are resilient.
Nassim Nicholas Taleb coined the term antifragility.
“Some things benefit from shocks; they thrive and grow when exposed to volatility, randomness, disorder, and stressors and love adventure, risk, and uncertainty. Yet, in spite of the ubiquity of the phenomenon, there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better.”
The easiest way to understand how antifragile systems behave is to compare them with other types of systems.
Glass is like a fragile system. It snaps when shocked.
Similar to rubber, a resilient system. After a stressful episode, it bounces back.
A system that is antifragile is similar to a muscle. As it is torn in the gym, it gets stronger.
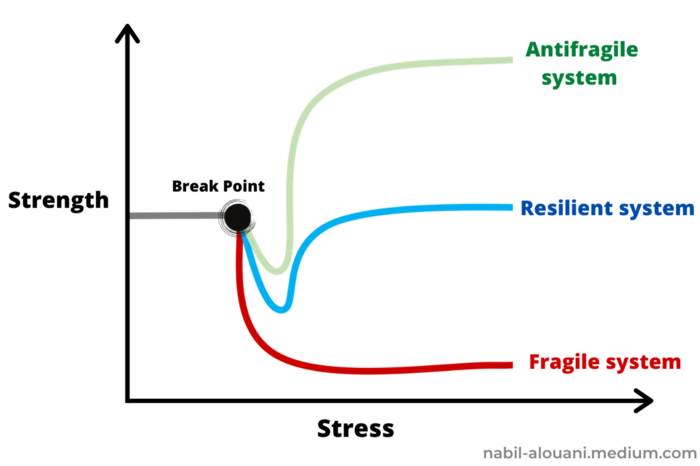
Time-changed things are antifragile. Culture, tech innovation, restaurants, revolutions, book sales, cuisine, economic success, and even muscle shape. These systems benefit from shocks and randomness in different ways, but they all pay a price for antifragility.
Same goes for the free market and financial institutions. Taleb's book uses restaurants as an example and ends with a reference to the 2008 crash.
“Restaurants are fragile. They compete with each other. But the collective of local restaurants is antifragile for that very reason. Had restaurants been individually robust, hence immortal, the overall business would be either stagnant or weak and would deliver nothing better than cafeteria food — and I mean Soviet-style cafeteria food. Further, it [the overall business] would be marred with systemic shortages, with once in a while a complete crisis and government bailout.”
Imagine the same thing with banks.
Independent banks would compete to offer the best services. If one of these banks fails, it will disappear. Customers and investors will suffer, but the market will recover from the dead banks' mistakes.
This idea underpins a free market. Bitcoin and other cryptocurrencies say this when criticizing traditional banking.
The traditional banking system's components never die. When a bank fails, the Federal Reserve steps in with a big taxpayer-funded check. This hinders bank evolution. If you don't let banking cells die and be replaced, your financial system won't be antifragile.
The interdependence of banks (centralization) means that one bank's mistake can sink the entire fleet, which brings us to SBF's ultimate travesty with FTX.
FTX has left the cryptocurrency gene pool.
FTX should be decentralized and independent. The super-star scammer invested in more than 130 crypto companies and linked them, creating a fragile banking-like structure. FTX seemed to say, "We exist because centralized banks are bad." But we'll be good, unlike the centralized banking system.
FTX saved several companies, including BlockFi and Voyager Digital.
FTX wanted to be a crypto bank conglomerate and Federal Reserve. SBF wanted to monopolize crypto markets. FTX wanted to be in bed with as many powerful people as possible, so SBF seduced politicians and celebrities.
Worst? People who saw SBF's plan flaws praised him. Experts, newspapers, and crypto fans praised FTX. When billions pour in, it's hard to realize FTX was acting against its nature.
Then, they act shocked when they realize FTX's fall triggered a domino effect. Some say the damage could wipe out the crypto market, but that's wrong.
Cell death is different from body death.
FTX is out of the game despite its size. Unfit, it fell victim to market natural selection.
Next?
The challengers keep coming. The crypto economy will improve with each failure.
Free markets are antifragile because their fragile parts compete, fostering evolution. With constructive feedback, evolution benefits customers and investors.
FTX shows that customers don't like being scammed, so the crypto market's health depends on them. Charlatans and con artists are eliminated quickly or slowly.
Crypto isn't immune to collapse. Cryptocurrencies can go extinct like biological species. Antifragility isn't immortality. A few more decades of evolution may be enough for humans to figure out how to best handle money, whether it's bitcoin, traditional banking, gold, or something else.
Keep your BS detector on. Start by being skeptical of this article's finance-related claims. Even if you think you understand finance, join the conversation.
We build a better future through dialogue. So listen, ask, and share. When you think you can't find common ground with the opposing view, remember:
Sam Bankman-Fried lied.