



More on Society & Culture

The Velocipede
2 years ago
Stolen wallet
How a misplaced item may change your outlook

Losing your wallet means life stops. Money vanishes. No credit. Your identity is unverifiable. As you check your pockets for the missing object, you can't drive. You can't borrow a library book.
Last seen? intuitively. Every kid asks this, including yours. However, you know where you lost it: On the Providence River cycling trail. While pedaling vigorously, the wallet dropped out of your back pocket and onto the pavement.
A woman you know—your son's art teacher—says it will be returned. Faith.
You want that faith. Losing a wallet is all-consuming. You must presume it has been stolen and is being used to buy every diamond and non-fungible token on the market. Your identity may have been used to open bank accounts and fake passports. Because he used your license address, a ski mask-wearing man may be driving slowly past your house.
As you delete yourself by canceling cards, these images run through your head. You wait in limbo for replacements. Digital text on the DMV website promises your new license will come within 60 days and be approved by local and state law enforcement. In the following two months, your only defense is a screenshot.
Your wallet was ordinary. A worn, overstuffed leather rectangle. You understand how tenuous your existence has always been since you've never lost a wallet. You barely breathe without your documents.
Ironically, you wore a wallet-belt chain. You adored being a 1993 slacker for 15 years. Your wife just convinced you last year that your office job wasn't professional. You nodded and hid the chain.
Never lost your wallet. Until now.
Angry. Feeling stupid. How could you drop something vital? Why? Is the world cruel? No more dumb luck. You're always one pedal-stroke from death.
Then you get a call: We have your wallet.
Local post office, not cops.
The clerk said someone returned it. Due to trying to identify you, it's a chaos. It has your cards but no cash.
Your automobile screeches down the highway. You yell at the windshield, amazed. Submitted. Art teacher was right. Have some trust.
You thank the postmaster. You ramble through the story. The clerk doesn't know the customer, simply a neighborhood Good Samaritan. You wish you could thank that person for lifting your spirits.
You get home, beaming with gratitude. You thumb through your wallet, amazed that it’s all intact. Then you dig out your chain and reattach it.
Because even faith could use a little help.

The woman
3 years ago
The renowned and highest-paid Google software engineer
His story will inspire you.

“Google search went down for a few hours in 2002; Jeff Dean handled all the queries by hand and checked quality doubled.”- Jeff Dean Facts.
One of many Jeff Dean jokes, but you get the idea.
Google's top six engineers met in a war room in mid-2000. Google's crawling system, which indexed the Web, stopped working. Users could still enter queries, but results were five months old.
Google just signed a deal with Yahoo to power a ten-times-larger search engine. Tension rose. It was crucial. If they failed, the Yahoo agreement would likely fall through, risking bankruptcy for the firm. Their efforts could be lost.
A rangy, tall, energetic thirty-one-year-old man named Jeff dean was among those six brilliant engineers in the makeshift room. He had just left D. E. C. a couple of months ago and started his career in a relatively new firm Google, which was about to change the world. He rolled his chair over his colleague Sanjay and sat right next to him, cajoling his code like a movie director. The history started from there.
When you think of people who shaped the World Wide Web, you probably picture founders and CEOs like Larry Page and Sergey Brin, Marc Andreesen, Tim Berners-Lee, Bill Gates, and Mark Zuckerberg. They’re undoubtedly the brightest people on earth.
Under these giants, legions of anonymous coders work at keyboards to create the systems and products we use. These computer workers are irreplaceable.
Let's get to know him better.
It's possible you've never heard of Jeff Dean. He's American. Dean created many behind-the-scenes Google products. Jeff, co-founder and head of Google's deep learning research engineering team, is a popular technology, innovation, and AI keynote speaker.
While earning an MS and Ph.D. in computer science at the University of Washington, he was a teaching assistant, instructor, and research assistant. Dean joined the Compaq Computer Corporation Western Research Laboratory research team after graduating.
Jeff co-created ProfileMe and the Continuous Profiling Infrastructure for Digital at Compaq. He co-designed and implemented Swift, one of the fastest Java implementations. He was a senior technical staff member at mySimon Inc., retrieving and caching electronic commerce content.
Dean, a top young computer scientist, joined Google in mid-1999. He was always trying to maximize a computer's potential as a child.
An expert
His high school program for processing massive epidemiological data was 26 times faster than professionals'. Epi Info, in 13 languages, is used by the CDC. He worked on compilers as a computer science Ph.D. These apps make source code computer-readable.
Dean never wanted to work on compilers forever. He left Academia for Google, which had less than 20 employees. Dean helped found Google News and AdSense, which transformed the internet economy. He then addressed Google's biggest issue, scaling.
Growing Google faced a huge computing challenge. They developed PageRank in the late 1990s to return the most relevant search results. Google's popularity slowed machine deployment.
Dean solved problems, his specialty. He and fellow great programmer Sanjay Ghemawat created the Google File System, which distributed large data over thousands of cheap machines.
These two also created MapReduce, which let programmers handle massive data quantities on parallel machines. They could also add calculations to the search algorithm. A 2004 research article explained MapReduce, which became an industry sensation.
Several revolutionary inventions
Dean's other initiatives were also game-changers. BigTable, a petabyte-capable distributed data storage system, was based on Google File. The first global database, Spanner, stores data on millions of servers in dozens of data centers worldwide.
It underpins Gmail and AdWords. Google Translate co-founder Jeff Dean is surprising. He contributes heavily to Google News. Dean is Senior Fellow of Google Research and Health and leads Google AI.
Recognitions
The National Academy of Engineering elected Dean in 2009. He received the 2009 Association for Computing Machinery fellowship and the 2016 American Academy of Arts and Science fellowship. He received the 2007 ACM-SIGOPS Mark Weiser Award and the 2012 ACM-Infosys Foundation Award. Lists could continue.
A sneaky question may arrive in your mind: How much does this big brain earn? Well, most believe he is one of the highest-paid employees at Google. According to a survey, he is paid $3 million a year.
He makes espresso and chats with a small group of Googlers most mornings. Dean steams milk, another grinds, and another brews espresso. They discuss families and technology while making coffee. He thinks this little collaboration and idea-sharing keeps Google going.
“Some of us have been working together for more than 15 years,” Dean said. “We estimate that we’ve collectively made more than 20,000 cappuccinos together.”
We all know great developers and software engineers. It may inspire many.

Will Leitch
3 years ago
Don't treat Elon Musk like Trump.
He’s not the President. Stop treating him like one.
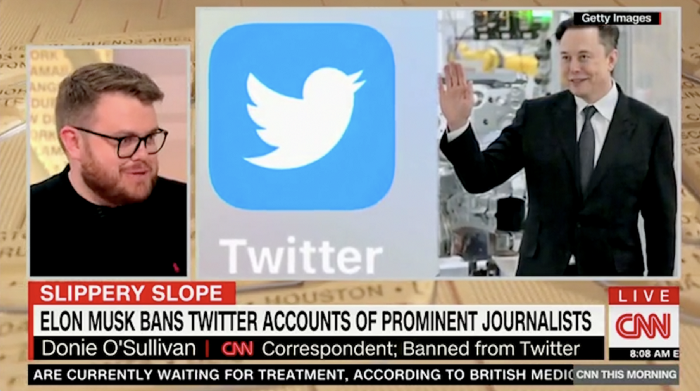
Elon Musk tweeted from Qatar, where he was watching the World Cup Final with Jared Kushner.
Musk's subsequent Tweets were as normal, basic, and bland as anyone's from a World Cup Final: It's depressing to see the world's richest man looking at his phone during a grand ceremony. Rich guy goes to rich guy event didn't seem important.
Before Musk posted his should-I-step-down-at-Twitter poll, CNN ran a long segment asking if it was hypocritical for him to reveal his real-time location after defending his (very dumb) suspension of several journalists for (supposedly) revealing his assassination coordinates by linking to a site that tracks Musks private jet. It was hard to ignore CNN's hypocrisy: It covered Musk as Twitter CEO like President Trump. EVERY TRUMP STORY WAS BASED ON HIM SAYING X, THEN DOING Y. Trump would do something horrific, lie about it, then pretend it was fine, then condemn a political rival who did the same thing, be called hypocritical, and so on. It lasted four years. Exhausting.
It made sense because Trump was the President of the United States. The press's main purpose is to relentlessly cover and question the president.
It's strange to say this out. Twitter isn't America. Elon Musk isn't a president. He maintains a money-losing social media service to harass and mock people he doesn't like. Treating Musk like Trump, as if he should be held accountable like Trump, shows a startling lack of perspective. Some journalists treat Twitter like a country.
The compulsive, desperate way many journalists utilize the site suggests as much. Twitter isn't the town square, despite popular belief. It's a place for obsessives to meet and converse. Journalists say they're breaking news. Their careers depend on it. They can argue it's a public service. Nope. It's a place lonely people go to speak all day. Twitter. So do journalists, Trump, and Musk. Acting as if it has a greater purpose, as if it's impossible to break news without it, or as if the republic is in peril is ludicrous. Only 23% of Americans are on Twitter, while 25% account for 97% of Tweets. I'd think a large portion of that 25% are journalists (or attention addicts) chatting to other journalists. Their loudness makes Twitter seem more important than it is. Nope. It's another stupid website. They were there before Twitter; they will be there after Twitter. It’s just a website. We can all get off it if we want. Most of us aren’t even on it in the first place.
Musk is a website-owner. No world leader. He's not as accountable as Trump was. Musk is cable news's primary character now that Trump isn't (at least for now). Becoming a TV news anchor isn't as significant as being president. Elon Musk isn't as important as we all pretend, and Twitter isn't even close. Twitter is a dumb website, Elon Musk is a rich guy going through a midlife crisis, and cable news is lazy because its leaders thought the entire world was on Twitter and are now freaking out that their playground is being disturbed.
I’ve said before that you need to leave Twitter, now. But even if you’re still on it, we need to stop pretending it matters more than it does. It’s a site for lonely attention addicts, from the man who runs it to the journalists who can’t let go of it. It’s not a town square. It’s not a country. It’s not even a successful website. Let’s stop pretending any of it’s real. It’s not.
You might also like

Mark Shpuntov
3 years ago
How to Produce a Month's Worth of Content for Social Media in a Day
New social media producers' biggest error

The Treadmill of Social Media Content
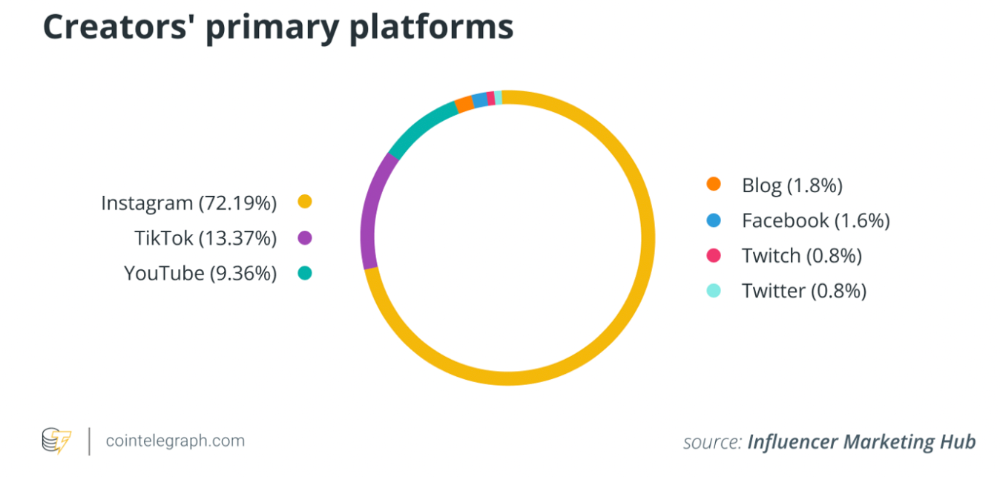
New creators focus on the wrong platforms.
They post to Instagram, Twitter, TikTok, etc.
They create daily material, but it's never enough for social media algorithms.
Creators recognize they're on a content creation treadmill.
They have to keep publishing content daily just to stay on the algorithm’s good side and avoid losing the audience they’ve built on the platform.
This is exhausting and unsustainable, causing creator burnout.
They focus on short-lived platforms, which is an issue.
Comparing low- and high-return social media platforms
Social media networks are great for reaching new audiences.
Their algorithm is meant to viralize material.
Social media can use you for their aims if you're not careful.
To master social media, focus on the right platforms.
To do this, we must differentiate low-ROI and high-ROI platforms:
Low ROI platforms are ones where content has a short lifespan. High ROI platforms are ones where content has a longer lifespan.
A tweet may be shown for 12 days. If you write an article or blog post, it could get visitors for 23 years.
ROI is drastically different.
New creators have limited time and high learning curves.
Nothing is possible.
First create content for high-return platforms.
ROI for social media platforms
Here are high-return platforms:
Your Blog - A single blog article can rank and attract a ton of targeted traffic for a very long time thanks to the power of SEO.
YouTube - YouTube has a reputation for showing search results or sidebar recommendations for videos uploaded 23 years ago. A superb video you make may receive views for a number of years.
Medium - A platform dedicated to excellent writing is called Medium. When you write an article about a subject that never goes out of style, you're building a digital asset that can drive visitors indefinitely.
These high ROI platforms let you generate content once and get visitors for years.
This contrasts with low ROI platforms:
Twitter
Instagram
TikTok
LinkedIn
Facebook
The posts you publish on these networks have a 23-day lifetime. Instagram Reels and TikToks are exceptions since viral content can last months.
If you want to make content creation sustainable and enjoyable, you must focus the majority of your efforts on creating high ROI content first. You can then use the magic of repurposing content to publish content to the lower ROI platforms to increase your reach and exposure.
How To Use Your Content Again
So, you’ve decided to focus on the high ROI platforms.
Great!
You've published an article or a YouTube video.
You worked hard on it.
Now you have fresh stuff.
What now?
If you are not repurposing each piece of content for multiple platforms, you are throwing away your time and efforts.
You've created fantastic material, so why not distribute it across platforms?
Repurposing Content Step-by-Step
For me, it's writing a blog article, but you might start with a video or podcast.
The premise is the same regardless of the medium.
Start by creating content for a high ROI platform (YouTube, Blog Post, Medium). Then, repurpose, edit, and repost it to the lower ROI platforms.
Here's how to repurpose pillar material for other platforms:
Post the article on your blog.
Put your piece on Medium (use the canonical link to point to your blog as the source for SEO)
Create a video and upload it to YouTube using the talking points from the article.
Rewrite the piece a little, then post it to LinkedIn.
Change the article's format to a Thread and share it on Twitter.
Find a few quick quotes throughout the article, then use them in tweets or Instagram quote posts.
Create a carousel for Instagram and LinkedIn using screenshots from the Twitter Thread.
Go through your film and select a few valuable 30-second segments. Share them on LinkedIn, Facebook, Twitter, TikTok, YouTube Shorts, and Instagram Reels.
Your video's audio can be taken out and uploaded as a podcast episode.
If you (or your team) achieve all this, you'll have 20-30 pieces of social media content.
If you're just starting, I wouldn't advocate doing all of this at once.
Instead, focus on a few platforms with this method.
You can outsource this as your company expands. (If you'd want to learn more about content repurposing, contact me.)
You may focus on relevant work while someone else grows your social media on autopilot.
You develop high-ROI pillar content, and it's automatically chopped up and posted on social media.
This lets you use social media algorithms without getting sucked in.
Thanks for reading!

Alison Randel
3 years ago
Raising the Bar on Your 1:1s

Managers spend much time in 1:1s. Most team members meet with supervisors regularly. 1:1s can help create relationships and tackle tough topics. Few appreciate the 1:1 format's potential. Most of the time, that potential is spent on small talk, surface-level updates, and ranting (Ugh, the marketing team isn’t stepping up the way I want them to).
What if you used that time to have deeper conversations and important insights? What if change was easy?
This post introduces a new 1:1 format to help you dive deeper, faster, and develop genuine relationships without losing impact.
A 1:1 is a chat, you would assume. Why use structure to talk to a coworker? Go! I know how to talk to people. I can write. I've always written. Also, This article was edited by Zoe.
Before you discard something, ask yourself if there's a good reason not to try anything new. Is the 1:1 only a talk, or do you want extra benefits? Try the steps below to discover more.
I. Reflection (5 minutes)
Context-free, broad comments waste time and are useless. Instead, give team members 5 minutes to write these 3 prompts.
What's effective?
What is decent but could be improved?
What is broken or missing?
Why these? They encourage people to be honest about all their experiences. Answering these questions helps people realize something isn't working. These prompts let people consider what's working.
Why take notes? Because you get more in less time. Will you feel awkward sitting quietly while your coworker writes? Probably. Persevere. Multi-task. Take a break from your afternoon meeting marathon. Any awkwardness will pay off.
What happens? After a few minutes of light conversation, create a template like the one given here and have team members fill in their replies. You can pre-share the template (with the caveat that this isn’t meant to take much prep time). Do this with your coworker: Answer the prompts. Everyone can benefit from pondering and obtaining guidance.
This step's output.

Part II: Talk (10-20 minutes)
Most individuals can explain what they see but not what's behind an answer. You don't like a meeting. Why not? Marketing partnership is difficult. What makes working with them difficult? I don't recommend slandering coworkers. Consider how your meetings, decisions, and priorities make work harder. The excellent stuff too. You want to know what's humming so you can reproduce the magic.
First, recognize some facts.
Real power dynamics exist. To encourage individuals to be honest, you must provide a safe environment and extend clear invites. Even then, it may take a few 1:1s for someone to feel secure enough to go there in person. It is part of your responsibility to admit that it is normal.
Curiosity and self-disclosure are crucial. Most leaders have received training to present themselves as the authorities. However, you will both benefit more from the dialogue if you can be open and honest about your personal experience, ask questions out of real curiosity, and acknowledge the pertinent sacrifices you're making as a leader.
Honesty without bias is difficult and important. Due to concern for the feelings of others, people frequently hold back. Or if they do point anything out, they do so in a critical manner. The key is to be open and unapologetic about what you observe while not presuming that your viewpoint is correct and that of the other person is incorrect.
Let's go into some prompts (based on genuine conversations):
“What do you notice across your answers?”
“What about the way you/we/they do X, Y, or Z is working well?”
“ Will you say more about item X in ‘What’s not working?’”
“I’m surprised there isn’t anything about Z. Why is that?”
“All of us tend to play some role in maintaining certain patterns. How might you/we be playing a role in this pattern persisting?”
“How might the way we meet, make decisions, or collaborate play a role in what’s currently happening?”
Consider the preceding example. What about the Monday meeting isn't working? Why? or What about the way we work with marketing makes collaboration harder? Remember to share your honest observations!
Third section: observe patterns (10-15 minutes)
Leaders desire to empower their people but don't know how. We also have many preconceptions about what empowerment means to us and how it works. The next phase in this 1:1 format will assist you and your team member comprehend team power and empowerment. This understanding can help you support and shift your team member's behavior, especially where you disagree.
How to? After discussing the stated responses, ask each team member what they can control, influence, and not control. Mark their replies. You can do the same, adding colors where you disagree.
This step's output.

Next, consider the color constellation. Discuss these questions:
Is one color much more prevalent than the other? Why, if so?
Are the colors for the "what's working," "what's fine," and "what's not working" categories clearly distinct? Why, if so?
Do you have any disagreements? If yes, specifically where does your viewpoint differ? What activities do you object to? (Remember, there is no right or wrong in this. Give explicit details and ask questions with curiosity.)
Example: Based on the colors, you can ask, Is the marketing meeting's quality beyond your control? Were our marketing partners consulted? Are there any parts of team decisions we can control? We can't control people, but have we explored another decision-making method? How can we collaborate and generate governance-related information to reduce work, even if the requirement for prep can't be eliminated?
Consider the top one or two topics for this conversation. No 1:1 can cover everything, and that's OK. Focus on the present.
Part IV: Determine the next step (5 minutes)
Last, examine what this conversation means for you and your team member. It's easy to think we know the next moves when we don't.
Like what? You and your teammate answer these questions.
What does this signify moving ahead for me? What can I do to change this? Make requests, for instance, and see how people respond before thinking they won't be responsive.
What demands do I have on other people or my partners? What should I do first? E.g. Make a suggestion to marketing that we hold a monthly retrospective so we can address problems and exchange input more frequently. Include it on the meeting's agenda for next Monday.
Close the 1:1 by sharing what you noticed about the chat. Observations? Learn anything?
Yourself, you, and the 1:1
As a leader, you either reinforce or disrupt habits. Try this template if you desire greater ownership, empowerment, or creativity. Consider how you affect surrounding dynamics. How can you expect others to try something new in high-stakes scenarios, like meetings with cross-functional partners or senior stakeholders, if you won't? How can you expect deep thought and relationship if you don't encourage it in 1:1s? What pattern could this new format disrupt or reinforce?
Fight reluctance. First attempts won't be ideal, and that's OK. You'll only learn by trying.

wordsmithwriter
3 years ago
2023 Will Be the Year of Evernote and Craft Notetaking Apps.
Note-taking is a vital skill. But it's mostly learned.

Recently, innovative note-taking apps have flooded the market.
In the next few years, Evernote and Craft will be important digital note-taking companies.
Evernote is a 2008 note-taking program. It can capture ideas, track tasks, and organize information on numerous platforms.
It's one of the only note-taking app that lets users input text, audio, photos, and videos. It's great for collecting research notes, brainstorming, and remaining organized.
Craft is a popular note-taking app.
Craft is a more concentrated note-taking application than Evernote. It organizes notes into subjects, tags, and relationships, making it ideal for technical or research notes.
Craft's search engine makes it easy to find what you need.
Both Evernote and Craft are likely to be the major players in digital note-taking in the years to come.
Their concentration on gathering and organizing information lets users generate notes quickly and simply. Multimedia elements and a strong search engine make them the note-taking apps of the future.
Evernote and Craft are great note-taking tools for staying organized and tracking ideas and projects.
With their focus on acquiring and organizing information, they'll dominate digital note-taking in 2023.
Pros
Concentrate on gathering and compiling information
special features including a strong search engine and multimedia components
Possibility of subject, tag, and relationship structuring
enables users to incorporate multimedia elements
Excellent tool for maintaining organization, arranging research notes, and brainstorming
Cons
Software may be difficult for folks who are not tech-savvy to utilize.
Limited assistance for hardware running an outdated operating system
Subscriptions could be pricey.
Data loss risk because of security issues
Evernote and Craft both have downsides.
The risk of data loss as a result of security flaws and software defects comes first.
Additionally, their subscription fees could be high, and they might restrict support for hardware that isn't running the newest operating systems.
Finally, folks who need to be tech-savvy may find the software difficult.
Evernote versus. Productivity Titans Evernote will make Notion more useful. medium.com