



More on Entrepreneurship/Creators

Navdeep Yadav
3 years ago
31 startup company models (with examples)
Many people find the internet's various business models bewildering.
This article summarizes 31 startup e-books.
1. Using the freemium business model (free plus premium),
The freemium business model offers basic software, games, or services for free and charges for enhancements.
Examples include Slack, iCloud, and Google Drive
Provide a rudimentary, free version of your product or service to users.
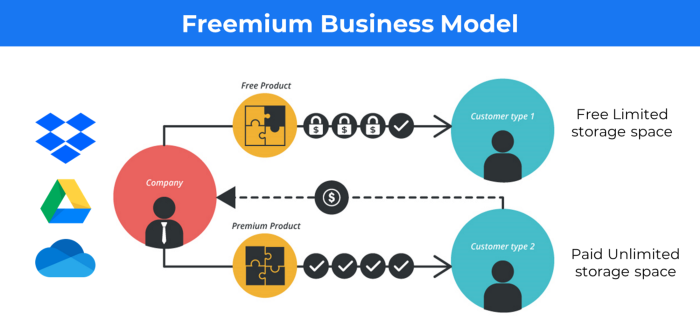
Google Drive and Dropbox offer 15GB and 2GB of free space but charge for more.
Freemium business model details (Click here)
2. The Business Model of Subscription
Subscription business models sell a product or service for recurring monthly or yearly revenue.
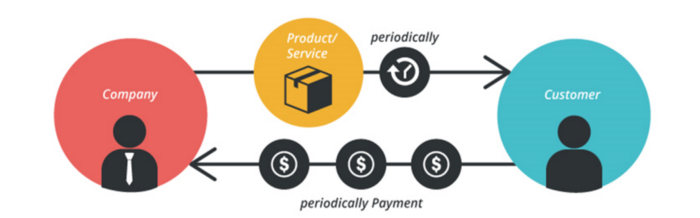
Examples: Tinder, Netflix, Shopify, etc
It's the next step to Freemium if a customer wants to pay monthly for premium features.
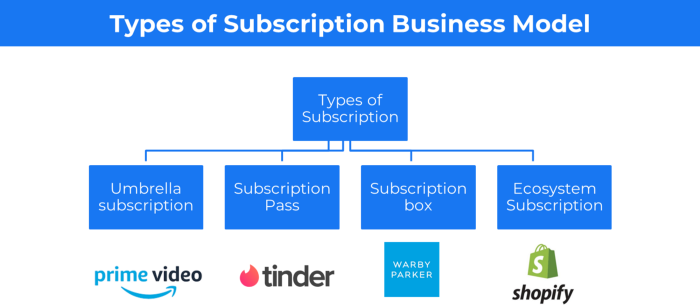
Subscription Business Model (Click here)
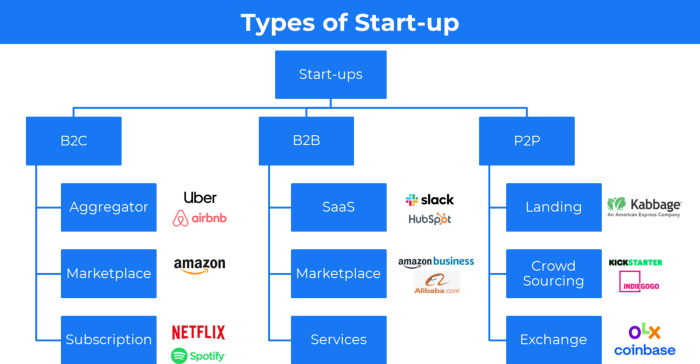
3. A market-based business strategy
It's an e-commerce site or app where third-party sellers sell products or services.
Examples are Amazon and Fiverr.
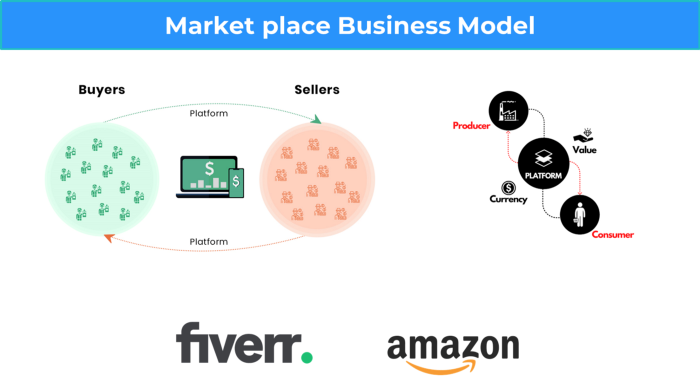
On Amazon's marketplace, a third-party vendor sells a product.
Freelancers on Fiverr offer specialized skills like graphic design.
Marketplace's business concept is explained.
4. Business plans using aggregates
In the aggregator business model, the service is branded.
Uber, Airbnb, and other examples
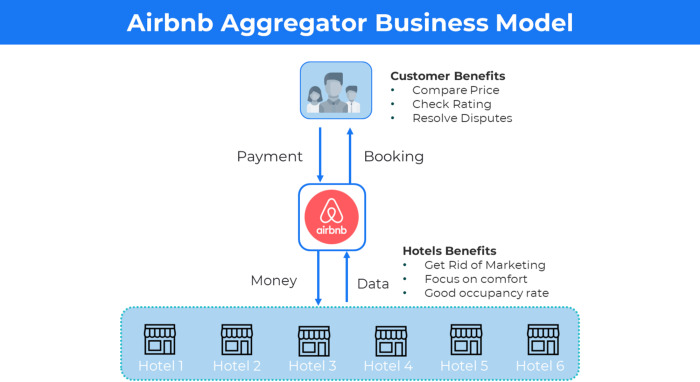
Marketplace and Aggregator business models differ.

Amazon and Fiverr link merchants and customers and take a 10-20% revenue split.
Uber and Airbnb-style aggregator Join these businesses and provide their products.
5. The pay-as-you-go concept of business
This is a consumption-based pricing system. Cloud companies use it.
Example: Amazon Web Service and Google Cloud Platform (GCP) (AWS)
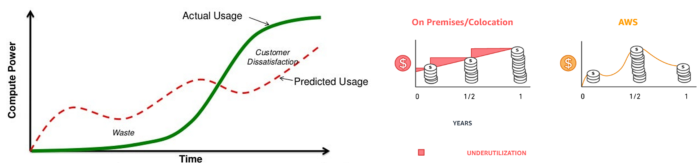
AWS, an Amazon subsidiary, offers over 200 pay-as-you-go cloud services.
“In short, the more you use the more you pay”
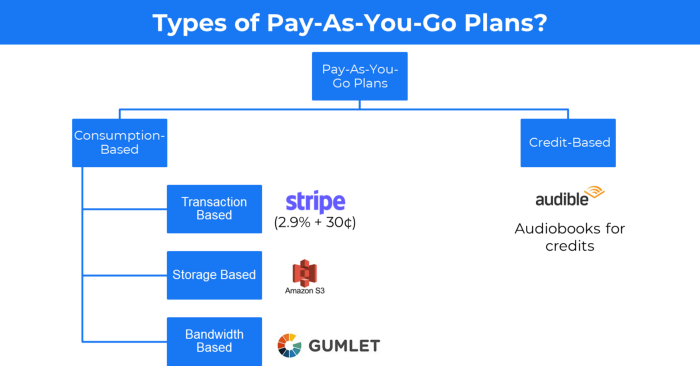
When it's difficult to divide clients into pricing levels, pay-as-you is employed.
6. The business model known as fee-for-service (FFS)
FFS charges fixed and variable fees for each successful payment.
For instance, PayU, Paypal, and Stripe
Stripe charges 2.9% + 30 per payment.
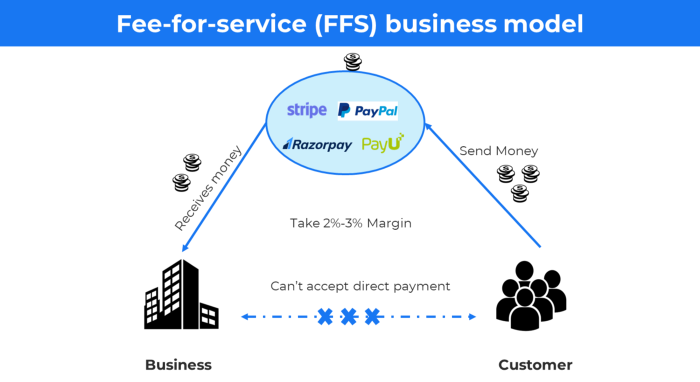
These firms offer a payment gateway to take consumer payments and deposit them to a business account.
Fintech business model
7. EdTech business strategy
In edtech, you generate money by selling material or teaching as a service.
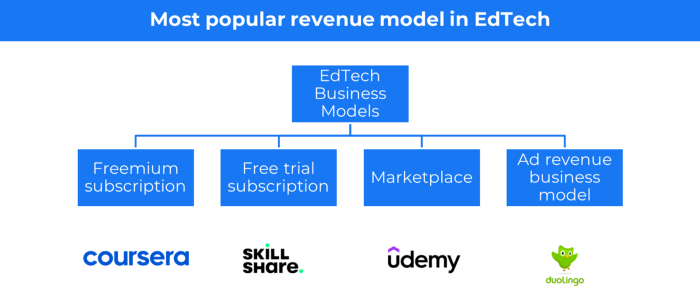
edtech business models
Freemium When course content is free but certification isn't, e.g. Coursera
FREE TRIAL SkillShare offers free trials followed by monthly or annual subscriptions.
Self-serving marketplace approach where you pick what to learn.
Ad-revenue model The company makes money by showing adverts to its huge user base.
Lock-in business strategy
Lock in prevents customers from switching to a competitor's brand or offering.
It uses switching costs or effort to transmit (soft lock-in), improved brand experience, or incentives.
Apple, SAP, and other examples
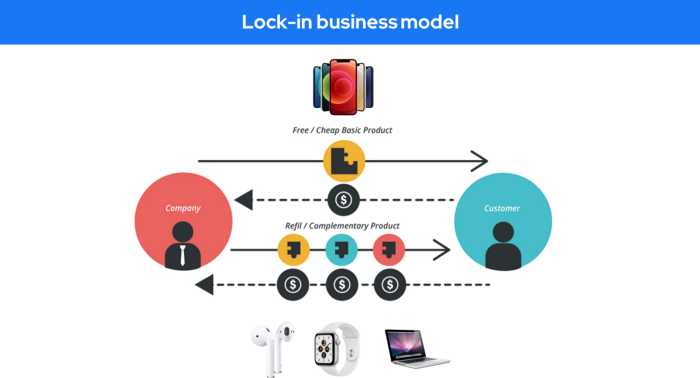
Apple offers an iPhone and then locks you in with extra hardware (Watch, Airpod) and platform services (Apple Store, Apple Music, cloud, etc.).
9. Business Model for API Licensing
APIs let third-party apps communicate with your service.
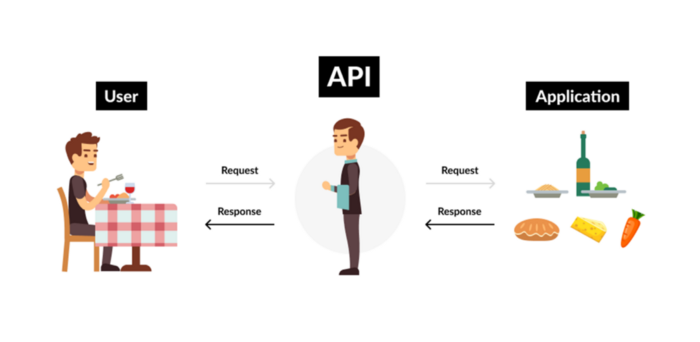
Uber and Airbnb use Google Maps APIs for app navigation.
Examples are Google Map APIs (Map), Sendgrid (Email), and Twilio (SMS).
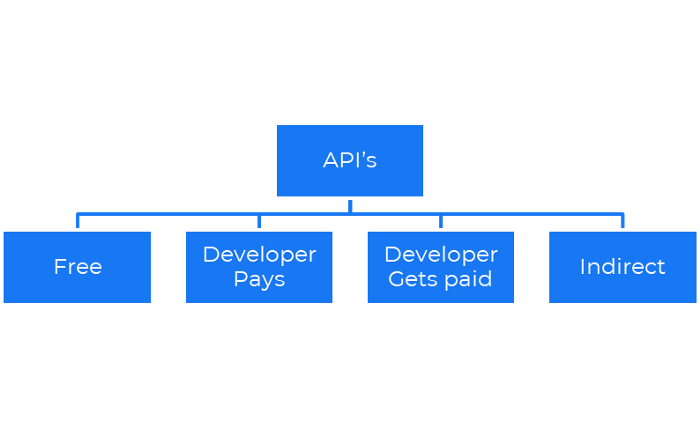
Business models for APIs
Free: The simplest API-driven business model that enables unrestricted API access for app developers. Google Translate and Facebook are two examples.
Developer Pays: Under this arrangement, service providers such as AWS, Twilio, Github, Stripe, and others must be paid by application developers.
The developer receives payment: These are the compensated content producers or developers who distribute the APIs utilizing their work. For example, Amazon affiliate programs
10. Open-source enterprise
Open-source software can be inspected, modified, and improved by anybody.
For instance, use Firefox, Java, or Android.
Google paid Mozilla $435,702 million to be their primary search engine in 2018.
Open-source software profits in six ways.
Paid assistance The Project Manager can charge for customization because he is quite knowledgeable about the codebase.
A full database solution is available as a Software as a Service (MongoDB Atlas), but there is a fee for the monitoring tool.
Open-core design R studio is a better GUI substitute for open-source applications.
sponsors of GitHub Sponsorships benefit the developers in full.
demands for paid features Earn Money By Developing Open Source Add-Ons for Current Products
Open-source business model
11. The business model for data
If the software or algorithm collects client data to improve or monetize the system.
Open AI GPT3 gets smarter with use.
Foursquare allows users to exchange check-in locations.
Later, they compiled large datasets to enable retailers like Starbucks launch new outlets.
12. Business Model Using Blockchain
Blockchain is a distributed ledger technology that allows firms to deploy smart contracts without a central authority.
Examples include Alchemy, Solana, and Ethereum.
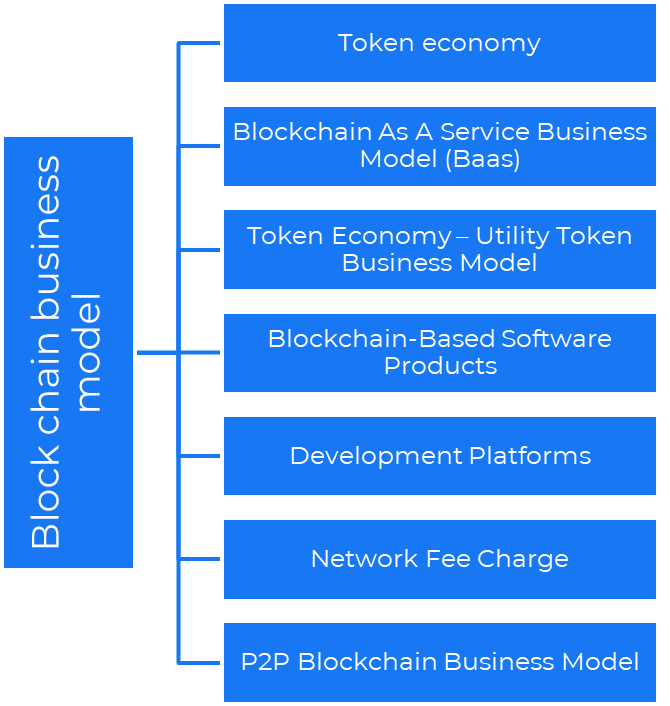
Business models using blockchain
Economy of tokens or utility When a business uses a token business model, it issues some kind of token as one of the ways to compensate token holders or miners. For instance, Solana and Ethereum
Bitcoin Cash P2P Business Model Peer-to-peer (P2P) blockchain technology permits direct communication between end users. as in IPFS
Enterprise Blockchain as a Service (Baas) BaaS focuses on offering ecosystem services similar to those offered by Amazon (AWS) and Microsoft (Azure) in the web 3 sector. Example: Ethereum Blockchain as a Service with Bitcoin (EBaaS).
Blockchain-Based Aggregators With AWS for blockchain, you can use that service by making an API call to your preferred blockchain. As an illustration, Alchemy offers nodes for many blockchains.
13. The free-enterprise model
In the freeterprise business model, free professional accounts are led into the funnel by the free product and later become B2B/enterprise accounts.
For instance, Slack and Zoom
Freeterprise companies flourish through collaboration.
Start with a free professional account to build an enterprise.
14. Business plan for razor blades
It's employed in hardware where one piece is sold at a loss and profits are made through refills or add-ons.
Gillet razor & blades, coffee machine & beans, HP printer & cartridge, etc.
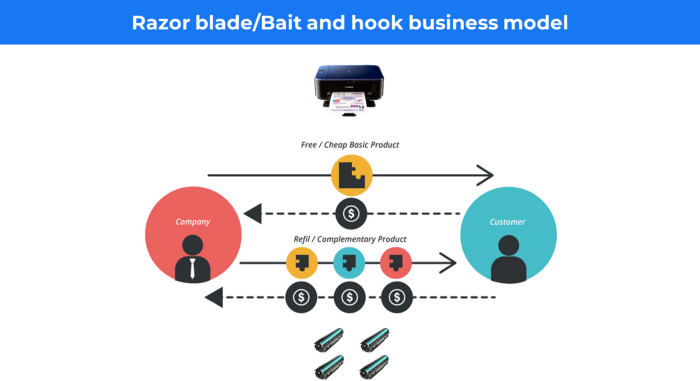
Sony sells the Playstation console at a loss but makes up for it by selling games and charging for online services.
Advantages of the Razor-Razorblade Method
lowers the risk a customer will try a product. enables buyers to test the goods and services without having to pay a high initial investment.
The product's ongoing revenue stream has the potential to generate sales that much outweigh the original investments.
Razor blade business model
15. The business model of direct-to-consumer (D2C)
In D2C, the company sells directly to the end consumer through its website using a third-party logistic partner.
Examples include GymShark and Kylie Cosmetics.
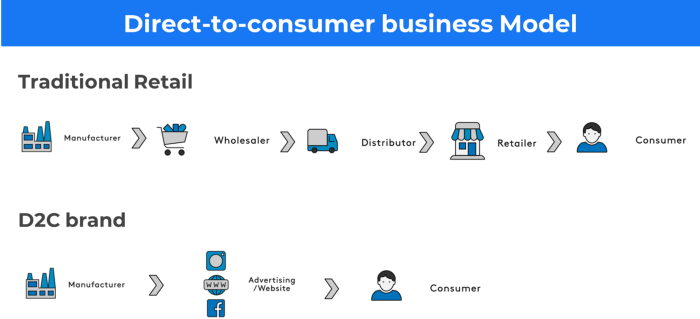
D2C brands can only expand via websites, marketplaces (Amazon, eBay), etc.
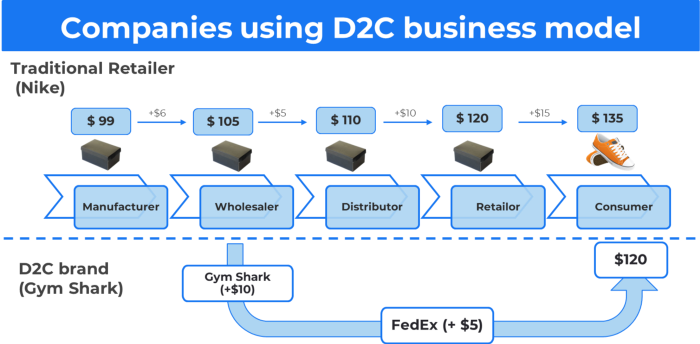
D2C benefits
Lower reliance on middlemen = greater profitability
You now have access to more precise demographic and geographic customer data.
Additional space for product testing
Increased customisation throughout your entire product line-Inventory Less
16. Business model: White Label vs. Private Label
Private label/White label products are made by a contract or third-party manufacturer.
Most amazon electronics are made in china and white-labeled.
Amazon supplements and electronics.
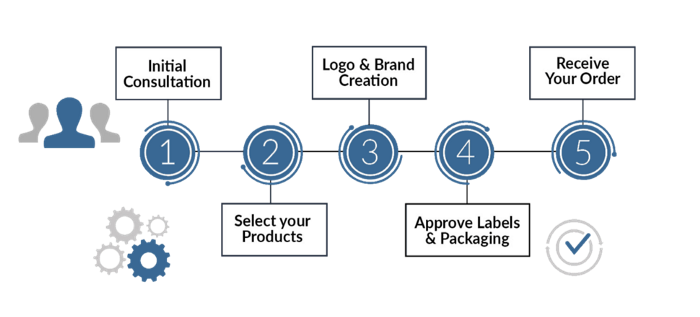
Contract manufacturers handle everything after brands select product quantities on design labels.
17. The franchise model
The franchisee uses the franchisor's trademark, branding, and business strategy (company).
For instance, KFC, Domino's, etc.
Subway, Domino, Burger King, etc. use this business strategy.

Many people pick a franchise because opening a restaurant is risky.
18. Ad-based business model
Social media and search engine giants exploit search and interest data to deliver adverts.
Google, Meta, TikTok, and Snapchat are some examples.
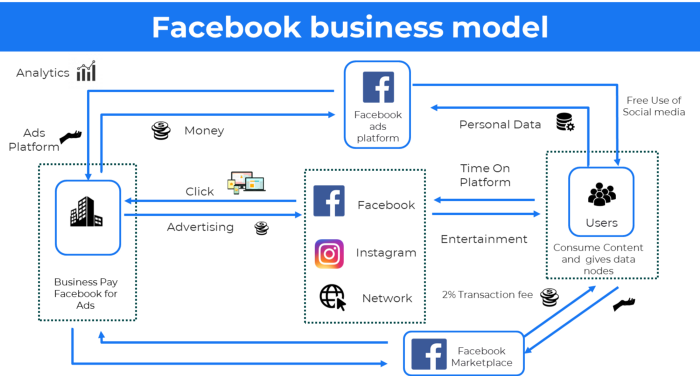
Users don't pay for the service or product given, e.g. Google users don't pay for searches.
In exchange, they collected data and hyper-personalized adverts to maximize revenue.
19. Business plan for octopuses
Each business unit functions separately but is connected to the main body.
Instance: Oyo

OYO is Asia's Airbnb, operating hotels, co-working, co-living, and vacation houses.
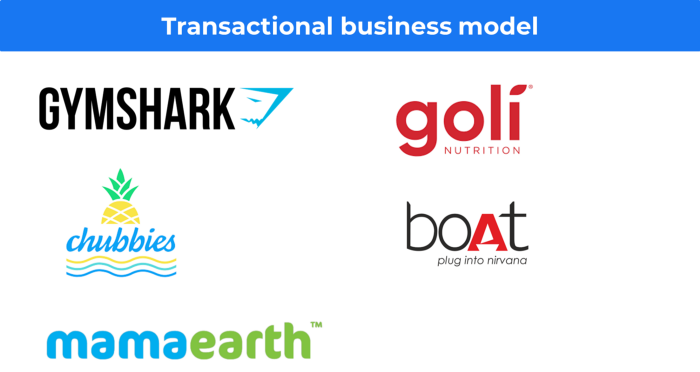
20, Transactional business model, number
Sales to customers produce revenue.
E-commerce sites and online purchases employ SSL.
Goli is an ex-GymShark.
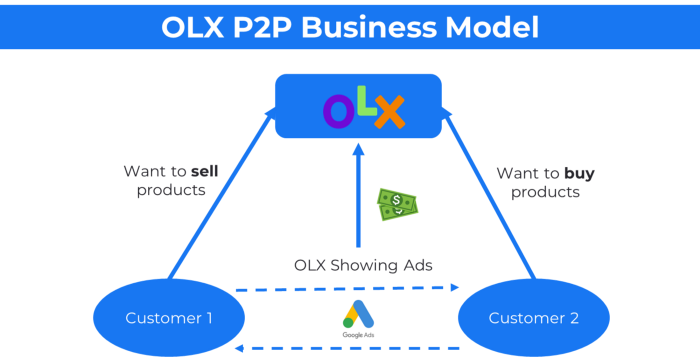
21. The peer-to-peer (P2P) business model
In P2P, two people buy and sell goods and services without a third party or platform.
Consider OLX.
22. P2P lending as a manner of operation
In P2P lending, one private individual (P2P Lender) lends/invests or borrows money from another (P2P Borrower).
Instance: Kabbage
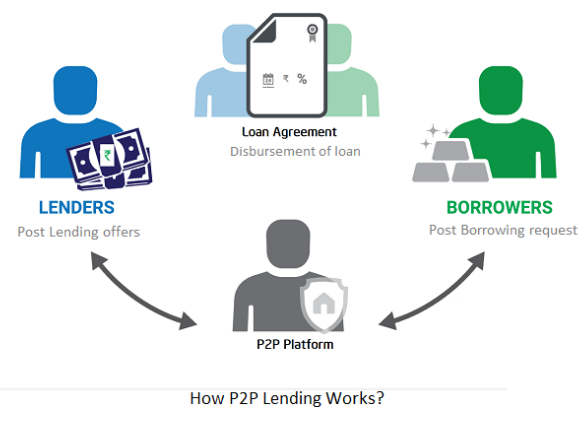
Social lending lets people lend and borrow money directly from each other without an intermediary financial institution.
23. A business model for brokers
Brokerages charge a commission or fee for their services.
Examples include eBay, Coinbase, and Robinhood.
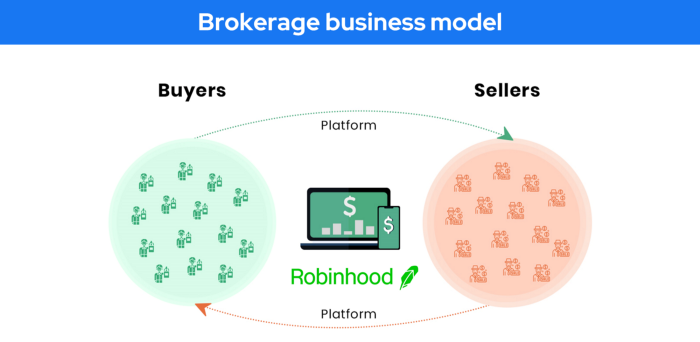
Brokerage businesses are common in Real estate, finance, and online and operate on this model.

Buy/sell similar models Examples include financial brokers, insurance brokers, and others who match purchase and sell transactions and charge a commission.
These brokers charge an advertiser a fee based on the date, place, size, or type of an advertisement. This is known as the classified-advertiser model. For instance, Craiglist
24. Drop shipping as an industry
Dropshipping allows stores to sell things without holding physical inventories.
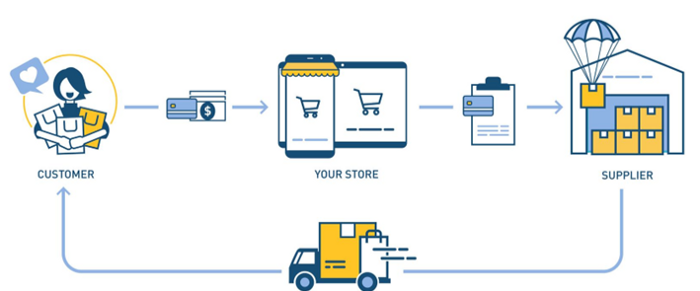
When a customer orders, use a third-party supplier and logistic partners.
Retailer product portfolio and customer experience Fulfiller The consumer places the order.
Dropshipping advantages
Less money is needed (Low overhead-No Inventory or warehousing)
Simple to start (costs under $100)
flexible work environment
New product testing is simpler
25. Business Model for Space as a Service
It's centered on a shared economy that lets millennials live or work in communal areas without ownership or lease.
Consider WeWork and Airbnb.
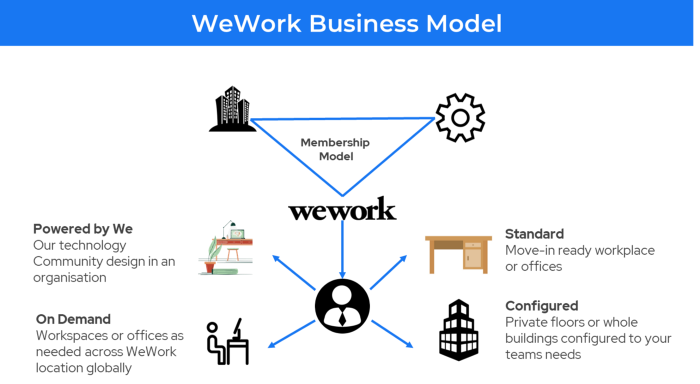
WeWork helps businesses with real estate, legal compliance, maintenance, and repair.
26. The business model for third-party logistics (3PL)
In 3PL, a business outsources product delivery, warehousing, and fulfillment to an external logistics company.
Examples include Ship Bob, Amazon Fulfillment, and more.

3PL partners warehouse, fulfill, and return inbound and outbound items for a charge.
Inbound logistics involves bringing products from suppliers to your warehouse.
Outbound logistics refers to a company's production line, warehouse, and customer.

27. The last-mile delivery paradigm as a commercial strategy
Last-mile delivery is the collection of supply chain actions that reach the end client.
Examples include Rappi, Gojek, and Postmates.
Last-mile is tied to on-demand and has a nighttime peak.
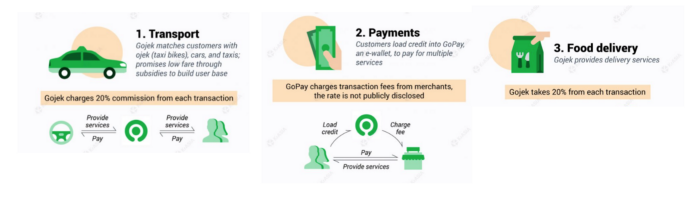
28. The use of affiliate marketing
Affiliate marketing involves promoting other companies' products and charging commissions.
Examples include Hubspot, Amazon, and Skillshare.

Your favorite youtube channel probably uses these short amazon links to get 5% of sales.
Affiliate marketing's benefits
In exchange for a success fee or commission, it enables numerous independent marketers to promote on its behalf.
Ensure system transparency by giving the influencers a specific tracking link and an online dashboard to view their profits.
Learn about the newest bargains and have access to promotional materials.
29. The business model for virtual goods
This is an in-app purchase for an intangible product.
Examples include PubG, Roblox, Candy Crush, etc.
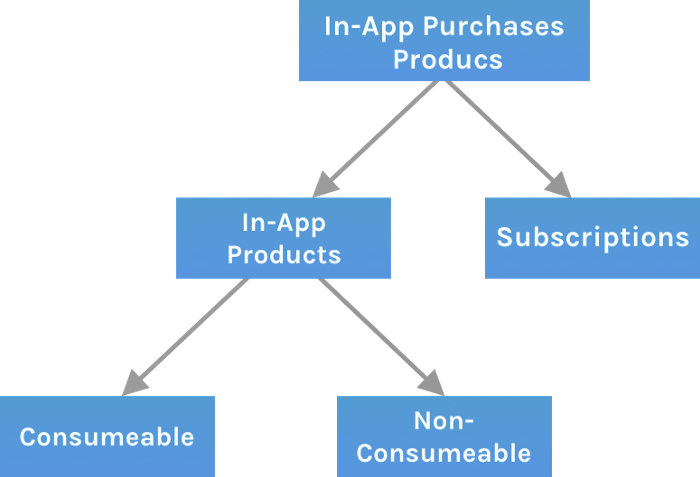
Consumables are like gaming cash that runs out. Non-consumable products provide a permanent advantage without repeated purchases.
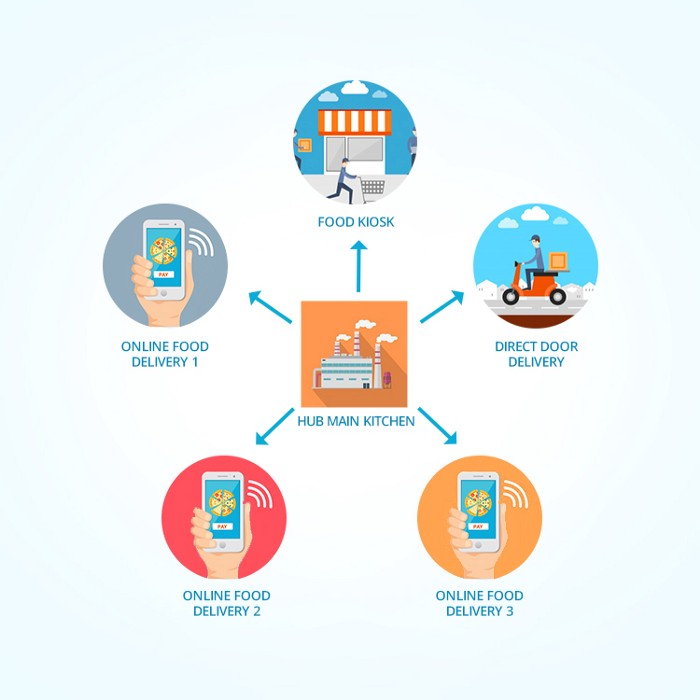
30. Business Models for Cloud Kitchens
Ghost, Dark, Black Box, etc.
Delivery-only restaurant.
These restaurants don't provide dine-in, only delivery.
For instance, NextBite and Faasos
31. Crowdsourcing as a Business Model
Crowdsourcing = Using the crowd as a platform's source.
In crowdsourcing, you get support from people around the world without hiring them.
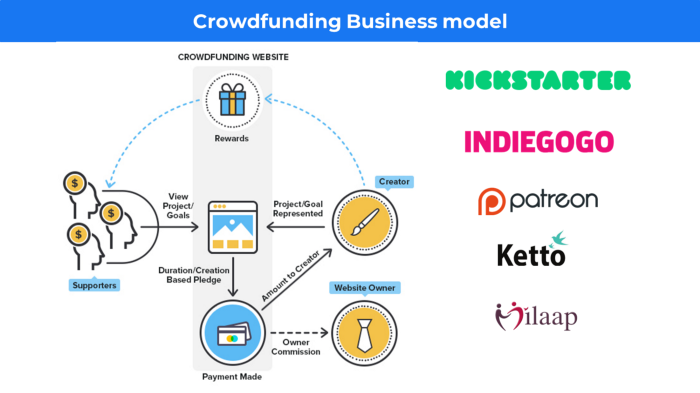
Crowdsourcing sites
Open-Source Software gives access to the software's source code so that developers can edit or enhance it. Examples include Firefox browsers and Linux operating systems.
Crowdfunding The oculus headgear would be an example of crowdfunding in essence, with no expectations.
Benjamin Lin
3 years ago
I sold my side project for $20,000: 6 lessons I learned
How I monetized and sold an abandoned side project for $20,000

The Origin Story
I've always wanted to be an entrepreneur but never succeeded. I often had business ideas, made a landing page, and told my buddies. Never got customers.
In April 2021, I decided to try again with a new strategy. I noticed that I had trouble acquiring an initial set of customers, so I wanted to start by acquiring a product that had a small user base that I could grow.
I found a SaaS marketplace called MicroAcquire.com where you could buy and sell SaaS products. I liked Shareit.video, an online Loom-like screen recorder.
Shareit.video didn't generate revenue, but 50 people visited daily to record screencasts.
Purchasing a Failed Side Project
I eventually bought Shareit.video for $12,000 from its owner.
$12,000 was probably too much for a website without revenue or registered users.
I thought time was most important. I could have recreated the website, but it would take months. $12,000 would give me an organized code base and a working product with a few users to monetize.

I considered buying a screen recording website and trying to grow it versus buying a new car or investing in crypto with the $12K.
Buying the website would make me a real entrepreneur, which I wanted more than anything.
Putting down so much money would force me to commit to the project and prevent me from quitting too soon.
A Year of Development
I rebranded the website to be called RecordJoy and worked on it with my cousin for about a year. Within a year, we made $5000 and had 3000 users.
We spent $3500 on ads, hosting, and software to run the business.
AppSumo promoted our $120 Life Time Deal in exchange for 30% of the revenue.
We put RecordJoy on maintenance mode after 6 months because we couldn't find a scalable user acquisition channel.
We improved SEO and redesigned our landing page, but nothing worked.

Despite not being able to grow RecordJoy any further, I had already learned so much from working on the project so I was fine with putting it on maintenance mode. RecordJoy still made $500 a month, which was great lunch money.
Getting Taken Over
One of our customers emailed me asking for some feature requests and I replied that we weren’t going to add any more features in the near future. They asked if we'd sell.
We got on a call with the customer and I asked if he would be interested in buying RecordJoy for 15k. The customer wanted around $8k but would consider it.
Since we were negotiating with one buyer, we put RecordJoy on MicroAcquire to see if there were other offers.

We quickly received 10+ offers. We got 18.5k. There was also about $1000 in AppSumo that we could not withdraw, so we agreed to transfer that over for $600 since about 40% of our sales on AppSumo usually end up being refunded.
Lessons Learned
First, create an acquisition channel
We couldn't discover a scalable acquisition route for RecordJoy. If I had to start another project, I'd develop a robust acquisition channel first. It might be LinkedIn, Medium, or YouTube.
Purchase Power of the Buyer Affects Acquisition Price
Some of the buyers we spoke to were individuals looking to buy side projects, as well as companies looking to launch a new product category. Individual buyers had less budgets than organizations.
Customers of AppSumo vary.
AppSumo customers value lifetime deals and low prices, which may not be a good way to build a business with recurring revenue. Designed for AppSumo users, your product may not connect with other users.
Try to increase acquisition trust
Acquisition often fails. The buyer can go cold feet, cease communicating, or run away with your stuff. Trusting the buyer ensures a smooth asset exchange. First acquisition meeting was unpleasant and price negotiation was tight. In later meetings, we spent the first few minutes trying to get to know the buyer’s motivations and background before jumping into the negotiation, which helped build trust.
Operating expenses can reduce your earnings.
Monitor operating costs. We were really happy when we withdrew the $5000 we made from AppSumo and Stripe until we realized that we had spent $3500 in operating fees. Spend money on software and consultants to help you understand what to build.
Don't overspend on advertising
We invested $1500 on Google Ads but made little money. For a side project, it’s better to focus on organic traffic from SEO rather than paid ads unless you know your ads are going to have a positive ROI.

Aaron Dinin, PhD
3 years ago
I'll Never Forget the Day a Venture Capitalist Made Me Feel Like a Dunce
Are you an idiot at fundraising?

Humans undervalue what they don't grasp. Consider NASCAR. How is that a sport? ask uneducated observers. Circular traffic. Driving near a car's physical limits is different from daily driving. When driving at 200 mph, seemingly simple things like changing gas weight or asphalt temperature might be life-or-death.
Venture investors do something similar in entrepreneurship. Most entrepreneurs don't realize how complex venture finance is.
In my early startup days, I didn't comprehend venture capital's intricacy. I thought VCs were rich folks looking for the next Mark Zuckerberg. I was meant to be a sleek, enthusiastic young entrepreneur who could razzle-dazzle investors.
Finally, one of the VCs I was trying to woo set me straight. He insulted me.
How I learned that I was approaching the wrong investor
I was constructing a consumer-facing, pre-revenue marketplace firm. I looked for investors in my old university's alumni database. My city had one. After some research, I learned he was a partner at a growth-stage, energy-focused VC company with billions under management.
Billions? I thought. Surely he can write a million-dollar cheque. He'd hardly notice.
I emailed the VC about our shared alumni status, explaining that I was building a startup in the area and wanted advice. When he agreed to meet the next week, I prepared my pitch deck.
First error.
The meeting seemed like a funding request. Imagine the awkwardness.
His assistant walked me to the firm's conference room and told me her boss was running late. While waiting, I prepared my pitch. I connected my computer to the projector, queued up my PowerPoint slides, and waited for the VC.
He didn't say hello or apologize when he entered a few minutes later. What are you doing?
Hi! I said, Confused but confident. Dinin Aaron. My startup's pitch.
Who? Suspicious, he replied. Your email says otherwise. You wanted help.
I said, "Isn't that a euphemism for contacting investors?" Fundraising I figured I should pitch you.
As he sat down, he smiled and said, "Put away your computer." You need to study venture capital.
Recognizing the business aspects of venture capital
The VC taught me venture capital in an hour. Young entrepreneur me needed this lesson. I assume you need it, so I'm sharing it.
Most people view venture money from an entrepreneur's perspective, he said. They envision a world where venture capital serves entrepreneurs and startups.
As my VC indicated, VCs perceive their work differently. Venture investors don't serve entrepreneurs. Instead, they run businesses. Their product doesn't look like most products. Instead, the VCs you're proposing have recognized an undervalued market segment. By investing in undervalued companies, they hope to profit. It's their investment thesis.
Your company doesn't fit my investment thesis, the venture capitalist told me. Your pitch won't beat my investing theory. I invest in multimillion-dollar clean energy companies. Asking me to invest in you is like ordering a breakfast burrito at a fancy steakhouse. They could, but why? They don't do that.
Yeah, I’m not a fine steak yet, I laughed, feeling like a fool for pitching a growth-stage VC used to looking at energy businesses with millions in revenues on my pre-revenue, consumer startup.
He stressed that it's not necessary. There are investors targeting your company. Not me. Find investors and pitch them.
Remember this when fundraising. Your investors aren't philanthropists who want to help entrepreneurs realize their company goals. Venture capital is a sophisticated investment strategy, and VC firm managers are industry experts. They're looking for companies that meet their investment criteria. As a young entrepreneur, I didn't grasp this, which is why I struggled to raise money. In retrospect, I probably seemed like an idiot. Hopefully, you won't after reading this.
You might also like

Max Chafkin
3 years ago
Elon Musk Bets $44 Billion on Free Speech's Future
Musk’s purchase of Twitter has sealed his bond with the American right—whether the platform’s left-leaning employees and users like it or not.
Elon Musk's pursuit of Twitter Inc. began earlier this month as a joke. It started slowly, then spiraled out of control, culminating on April 25 with the world's richest man agreeing to spend $44 billion on one of the most politically significant technology companies ever. There have been bigger financial acquisitions, but Twitter's significance has always outpaced its balance sheet. This is a unique Silicon Valley deal.
To recap: Musk announced in early April that he had bought a stake in Twitter, citing the company's alleged suppression of free speech. His complaints were vague, relying heavily on the dog whistles of the ultra-right. A week later, he announced he'd buy the company for $54.20 per share, four days after initially pledging to join Twitter's board. Twitter's directors noticed the 420 reference as well, and responded with a “shareholder rights” plan (i.e., a poison pill) that included a 420 joke.
Musk - Patrick Pleul/Getty Images
No one knew if the bid was genuine. Musk's Twitter plans seemed implausible or insincere. In a tweet, he referred to automated accounts that use his name to promote cryptocurrency. He enraged his prospective employees by suggesting that Twitter's San Francisco headquarters be turned into a homeless shelter, renaming the company Titter, and expressing solidarity with his growing conservative fan base. “The woke mind virus is making Netflix unwatchable,” he tweeted on April 19.
But Musk got funding, and after a frantic weekend of negotiations, Twitter said yes. Unlike most buyouts, Musk will personally fund the deal, putting up up to $21 billion in cash and borrowing another $12.5 billion against his Tesla stock.
Free Speech and Partisanship
Percentage of respondents who agree with the following
The deal is expected to replatform accounts that were banned by Twitter for harassing others, spreading misinformation, or inciting violence, such as former President Donald Trump's account. As a result, Musk is at odds with his own left-leaning employees, users, and advertisers, who would prefer more content moderation rather than less.
Dorsey - Photographer: Joe Raedle/Getty Images
Previously, the company's leadership had similar issues. Founder Jack Dorsey stepped down last year amid concerns about slowing growth and product development, as well as his dual role as CEO of payments processor Block Inc. Compared to Musk, a father of seven who already runs four companies (besides Tesla and SpaceX), Dorsey is laser-focused.
Musk's motivation to buy Twitter may be political. Affirming the American far right with $44 billion spent on “free speech” Right-wing activists have promoted a series of competing upstart Twitter competitors—Parler, Gettr, and Trump's own effort, Truth Social—since Trump was banned from major social media platforms for encouraging rioters at the US Capitol on Jan. 6, 2021. But Musk can give them a social network with lax content moderation and a real user base. Trump said he wouldn't return to Twitter after the deal was announced, but he wouldn't be the first to do so.
Trump - Eli Hiller/Bloomberg
Conservative activists and lawmakers are already ecstatic. “A great day for free speech in America,” said Missouri Republican Josh Hawley. The day the deal was announced, Tucker Carlson opened his nightly Fox show with a 10-minute laudatory monologue. “The single biggest political development since Donald Trump's election in 2016,” he gushed over Musk.
But Musk's supporters and detractors misunderstand how much his business interests influence his political ideology. He marketed Tesla's cars as carbon-saving machines that were faster and cooler than gas-powered luxury cars during George W. Bush's presidency. Musk gained a huge following among wealthy environmentalists who reserved hundreds of thousands of Tesla sedans years before they were made during Barack Obama's presidency. Musk in the Trump era advocated for a carbon tax, but he also fought local officials (and his own workers) over Covid rules that slowed the reopening of his Bay Area factory.
Teslas at the Las Vegas Convention Center Loop Central Station in April 2021. The Las Vegas Convention Center Loop was Musk's first commercial project. Ethan Miller/Getty Images
Musk's rightward shift matched the rise of the nationalist-populist right and the desire to serve a growing EV market. In 2019, he unveiled the Cybertruck, a Tesla pickup, and in 2018, he announced plans to manufacture it at a new plant outside Austin. In 2021, he decided to move Tesla's headquarters there, citing California's "land of over-regulation." After Ford and General Motors beat him to the electric truck market, Musk reframed Tesla as a company for pickup-driving dudes.
Similarly, his purchase of Twitter will be entwined with his other business interests. Tesla has a factory in China and is friendly with Beijing. This could be seen as a conflict of interest when Musk's Twitter decides how to treat Chinese-backed disinformation, as Amazon.com Inc. founder Jeff Bezos noted.
Musk has focused on Twitter's product and social impact, but the company's biggest challenges are financial: Either increase cash flow or cut costs to comfortably service his new debt. Even if Musk can't do that, he can still benefit from the deal. He has recently used the increased attention to promote other business interests: Boring has hyperloops and Neuralink brain implants on the way, Musk tweeted. Remember Tesla's long-promised robotaxis!
Musk may be comfortable saying he has no expectation of profit because it benefits his other businesses. At the TED conference on April 14, Musk insisted that his interest in Twitter was solely charitable. “I don't care about money.”
The rockets and weed jokes make it easy to see Musk as unique—and his crazy buyout will undoubtedly add to that narrative. However, he is a megabillionaire who is risking a small amount of money (approximately 13% of his net worth) to gain potentially enormous influence. Musk makes everything seem new, but this is a rehash of an old media story.

Stephen Moore
3 years ago
Web 2 + Web 3 = Web 5.
Monkey jpegs and shitcoins have tarnished Web3's reputation. Let’s move on.

Web3 was called "the internet's future."
Well, 'crypto bros' shouted about it loudly.
As quickly as it arrived to be the next internet, it appears to be dead. It's had scandals, turbulence, and crashes galore:
Web 3.0's cryptocurrencies have crashed. Bitcoin's all-time high was $66,935. This month, Ethereum fell from $2130 to $1117. Six months ago, the cryptocurrency market peaked at $3 trillion. Worst is likely ahead.
Gas fees make even the simplest Web3 blockchain transactions unsustainable.
Terra, Luna, and other dollar pegs collapsed, hurting crypto markets. Celsius, a crypto lender backed by VCs and Canada's second-largest pension fund, and Binance, a crypto marketplace, have withheld money and coins. They're near collapse.
NFT sales are falling rapidly and losing public interest.
Web3 has few real-world uses, like most crypto/blockchain technologies. Web3's image has been tarnished by monkey profile pictures and shitcoins while failing to become decentralized (the whole concept is controlled by VCs).
The damage seems irreparable, leaving Web3 in the gutter.
Step forward our new saviour — Web5
Fear not though, as hero awaits to drag us out of the Web3 hellscape. Jack Dorsey revealed his plan to save the internet quickly.
Dorsey has long criticized Web3, believing that VC capital and silicon valley insiders have created a centralized platform. In a tweet that upset believers and VCs (he was promptly blocked by Marc Andreessen), Dorsey argued, "You don't own "Web3." VCs and LPs do. Their incentives prevent it. It's a centralized organization with a new name.
Dorsey announced Web5 on June 10 in a very Elon-like manner. Block's TBD unit will work on the project (formerly Square).
Web5's pitch is that users will control their own data and identity. Bitcoin-based. Sound familiar? The presentation pack's official definition emphasizes decentralization. Web5 is a decentralized web platform that enables developers to write decentralized web apps using decentralized identifiers, verifiable credentials, and decentralized web nodes, returning ownership and control over identity and data to individuals.
Web5 would be permission-less, open, and token-less. What that means for Earth is anyone's guess. Identity. Ownership. Blockchains. Bitcoin. Different.
Web4 appears to have been skipped, forever destined to wish it could have shown the world what it could have been. (It was probably crap.) As this iteration combines Web2 and Web3, simple math and common sense add up to 5. Or something.
Dorsey and his team have had this idea simmering for a while. Daniel Buchner, a member of Block's Decentralized Identity team, said, "We're finishing up Web5's technical components."
Web5 could be the project that decentralizes the internet. It must be useful to users and convince everyone to drop the countless Web3 projects, products, services, coins, blockchains, and websites being developed as I write this.
Web5 may be too late for Dorsey and the incoming flood of creators.
Web6 is planned!
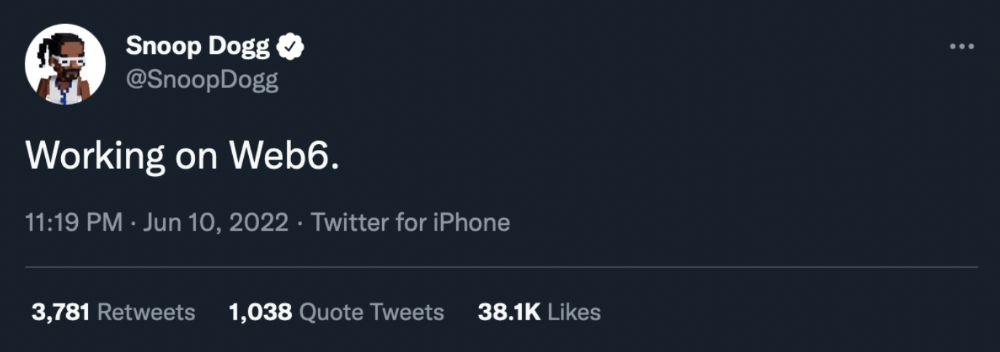
The next months and years will be hectic and less stable than the transition from Web 1.0 to Web 2.0.
Web1 was around 1991-2004.
Web2 ran from 2004 to 2021. (though the Web3 term was first used in 2014, it only really gained traction years later.)
Web3 lasted a year.
Web4 is dead.
Silicon Valley billionaires are turning it into a startup-style race, each disrupting the next iteration until they crack it. Or destroy it completely.
Web5 won't last either.
JEFF JOHN ROBERTS
3 years ago
What just happened in cryptocurrency? A plain-English Q&A about Binance's FTX takedown.

Crypto people have witnessed things. They've seen big hacks, mind-boggling swindles, and amazing successes. They've never seen a day like Tuesday, when the world's largest crypto exchange murdered its closest competition.
Here's a primer on Binance and FTX's lunacy and why it matters if you're new to crypto.
What happened?
CZ, a shrewd Chinese-Canadian billionaire, runs Binance. FTX, a newcomer, has challenged Binance in recent years. SBF (Sam Bankman-Fried)—a young American with wild hair—founded FTX (initials are a thing in crypto).
Last weekend, CZ complained about SBF's lobbying and then exploited Binance's market power to attack his competition.
How did CZ do that?
CZ invested in SBF's new cryptocurrency exchange when they were friends. CZ sold his investment in FTX for FTT when he no longer wanted it. FTX clients utilize those tokens to get trade discounts, although they are less liquid than Bitcoin.
SBF made a mistake by providing CZ just too many FTT tokens, giving him control over FTX. It's like Pepsi handing Coca-Cola a lot of stock it could sell at any time. CZ got upset with SBF and flooded the market with FTT tokens.
SBF owns a trading fund with many FTT tokens, therefore this was catastrophic. SBF sought to defend FTT's worth by selling other assets to buy up the FTT tokens flooding the market, but it didn't succeed, and as FTT's value plummeted, his liabilities exceeded his assets. By Tuesday, his companies were insolvent, so he sold them to his competition.
Crazy. How could CZ do that?
CZ likely did this to crush a rising competition. It was also personal. In recent months, regulators have been tough toward the crypto business, and Binance and FTX have been trying to stay on their good side. CZ believed SBF was poisoning U.S. authorities by saying CZ was linked to China, so CZ took retribution.
“We supported previously, but we won't pretend to make love after divorce. We're neutral. But we won't assist people that push against other industry players behind their backs," CZ stated in a tragic tweet on Sunday. He crushed his rival's company two days later.
So does Binance now own FTX?
No. Not yet. CZ has only stated that Binance signed a "letter of intent" to acquire FTX. CZ and SBF say Binance will protect FTX consumers' funds.
Who’s to blame?
You could blame CZ for using his control over FTX to destroy it. SBF is also being criticized for not disclosing the full overlap between FTX and his trading company, which controlled plenty of FTT. If he had been upfront, someone might have warned FTX about this vulnerability earlier, preventing this mess.
Others have alleged that SBF utilized customer monies to patch flaws in his enterprises' balance accounts. That happened to multiple crypto startups that collapsed this spring, which is unfortunate. These are allegations, not proof.
Why does this matter? Isn't this common in crypto?
Crypto is notorious for shady executives and pranks. FTX is the second-largest crypto business, and SBF was largely considered as the industry's golden boy who would help it get on authorities' good side. Thus far.
Does this affect cryptocurrency prices?
Short-term, it's bad. Prices fell on suspicions that FTX was in peril, then rallied when Binance rescued it, only to fall again later on Tuesday.
These occurrences have hurt FTT and SBF's Solana token. It appears like a huge token selloff is affecting the rest of the market. Bitcoin fell 10% and Ethereum 15%, which is bad but not catastrophic for the two largest coins by market cap.