



More on Society & Culture

The Velocipede
2 years ago
Stolen wallet
How a misplaced item may change your outlook

Losing your wallet means life stops. Money vanishes. No credit. Your identity is unverifiable. As you check your pockets for the missing object, you can't drive. You can't borrow a library book.
Last seen? intuitively. Every kid asks this, including yours. However, you know where you lost it: On the Providence River cycling trail. While pedaling vigorously, the wallet dropped out of your back pocket and onto the pavement.
A woman you know—your son's art teacher—says it will be returned. Faith.
You want that faith. Losing a wallet is all-consuming. You must presume it has been stolen and is being used to buy every diamond and non-fungible token on the market. Your identity may have been used to open bank accounts and fake passports. Because he used your license address, a ski mask-wearing man may be driving slowly past your house.
As you delete yourself by canceling cards, these images run through your head. You wait in limbo for replacements. Digital text on the DMV website promises your new license will come within 60 days and be approved by local and state law enforcement. In the following two months, your only defense is a screenshot.
Your wallet was ordinary. A worn, overstuffed leather rectangle. You understand how tenuous your existence has always been since you've never lost a wallet. You barely breathe without your documents.
Ironically, you wore a wallet-belt chain. You adored being a 1993 slacker for 15 years. Your wife just convinced you last year that your office job wasn't professional. You nodded and hid the chain.
Never lost your wallet. Until now.
Angry. Feeling stupid. How could you drop something vital? Why? Is the world cruel? No more dumb luck. You're always one pedal-stroke from death.
Then you get a call: We have your wallet.
Local post office, not cops.
The clerk said someone returned it. Due to trying to identify you, it's a chaos. It has your cards but no cash.
Your automobile screeches down the highway. You yell at the windshield, amazed. Submitted. Art teacher was right. Have some trust.
You thank the postmaster. You ramble through the story. The clerk doesn't know the customer, simply a neighborhood Good Samaritan. You wish you could thank that person for lifting your spirits.
You get home, beaming with gratitude. You thumb through your wallet, amazed that it’s all intact. Then you dig out your chain and reattach it.
Because even faith could use a little help.

umair haque
2 years ago
The reasons why our civilization is deteriorating
The Industrial Revolution's Curse: Why One Age's Power Prevents the Next Ones
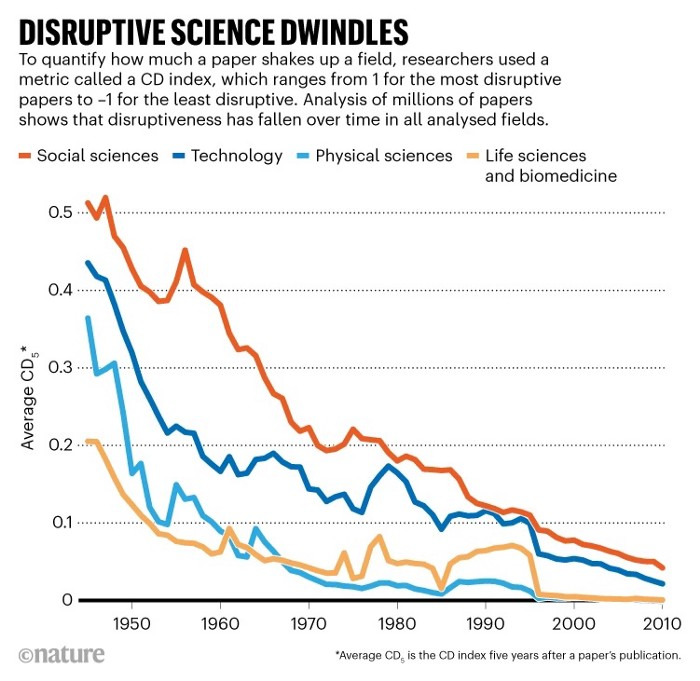
A surprising fact. Recently, Big Oil's 1970s climate change projections were disturbingly accurate. Of course, we now know that it worked tirelessly to deny climate change, polluting our societies to this day. That's a small example of the Industrial Revolution's curse.
Let me rephrase this nuanced and possibly weird thought. The chart above? Disruptive science is declining. The kind that produces major discoveries, new paradigms, and shattering prejudices.
Not alone. Our civilisation reached a turning point suddenly. Progress stopped and reversed for the first time in centuries.
The Industrial Revolution's Big Bang started it all. At least some humans had riches for the first time, if not all, and with that wealth came many things. Longer, healthier lives since now health may be publicly and privately invested in. For the first time in history, wealthy civilizations could invest their gains in pure research, a good that would have sounded frivolous to cultures struggling to squeeze out the next crop, which required every shoulder to the till.
So. Don't confuse me with the Industrial Revolution's curse. Industry progressed. Contrary. I'm claiming that the Big Bang of Progress is slowing, plateauing, and ultimately reversing. All social indicators show that. From progress itself to disruptive, breakthrough research, everything is slowing down.
It's troubling. Because progress slows and plateaus, pre-modern social problems like fascism, extremism, and fundamentalism return. People crave nostalgic utopias when they lose faith in modernity. That strongman may shield me from this hazardous life. If I accept my place in a blood-and-soil hierarchy, I have a stable, secure position and someone to punch and detest. It's no coincidence that as our civilization hits a plateau of progress, there is a tsunami pulling the world backwards, with people viscerally, openly longing for everything from theocracy to fascism to fundamentalism, an authoritarian strongman to soothe their fears and tell them what to do, whether in Britain, heartland America, India, China, and beyond.
However, one aspect remains unknown. Technology. Let me clarify.
How do most people picture tech? Say that without thinking. Most people think of social media or AI. Well, small correlation engines called artificial neurons are a far cry from biological intelligence, which functions in far more obscure and intricate ways, down to the subatomic level. But let's try it.
Today, tech means AI. But. Do you foresee it?
Consider why civilisation is plateauing and regressing. Because we can no longer provide the most basic necessities at the same rate. On our track, clean air, water, food, energy, medicine, and healthcare will become inaccessible to huge numbers within a decade or three. Not enough. There isn't, therefore prices for food, medicine, and energy keep rising, with occasional relief.
Why our civilizations are encountering what economists like me term a budget constraint—a hard wall of what we can supply—should be evident. Global warming and extinction. Megafires, megadroughts, megafloods, and failed crops. On a civilizational scale, good luck supplying the fundamentals that way. Industrial food production cannot feed a planet warming past two degrees. Crop failures, droughts, floods. Another example: glaciers melt, rivers dry up, and the planet's fresh water supply contracts like a heart attack.
Now. Let's talk tech again. Mostly AI, maybe phone apps. The unsettling reality is that current technology cannot save humanity. Not much.
AI can do things that have become cliches to titillate the masses. It may talk to you and act like a person. It can generate art, which means reproduce it, but nonetheless, AI art! Despite doubts, it promises to self-drive cars. Unimportant.
We need different technology now. AI won't grow crops in ash-covered fields, cleanse water, halt glaciers from melting, or stop the clear-cutting of the planet's few remaining forests. It's not useless, but on a civilizational scale, it's much less beneficial than its proponents claim. By the time it matures, AI can help deliver therapy, keep old people company, and even drive cars more efficiently. None of it can save our culture.
Expand that scenario. AI's most likely use? Replacing call-center workers. Support. It may help doctors diagnose, surgeons orient, or engineers create more fuel-efficient motors. This is civilizationally marginal.
Non-disruptive. Do you see the connection with the paper that indicated disruptive science is declining? AI exemplifies that. It's called disruptive, yet it's a textbook incremental technology. Oh, cool, I can communicate with a bot instead of a poor human in an underdeveloped country and have the same or more trouble being understood. This bot is making more people unemployed. I can now view a million AI artworks.
AI illustrates our civilization's trap. Its innovative technologies will change our lives. But as you can see, its incremental, delivering small benefits at most, and certainly not enough to balance, let alone solve, the broader problem of steadily dropping living standards as our society meets a wall of being able to feed itself with fundamentals.
Contrast AI with disruptive innovations we need. What do we need to avoid a post-Roman Dark Age and preserve our civilization in the coming decades? We must be able to post-industrially produce all our basic needs. We need post-industrial solutions for clean water, electricity, cement, glass, steel, manufacture for garments and shoes, starting with the fossil fuel-intensive plastic, cotton, and nylon they're made of, and even food.
Consider. We have no post-industrial food system. What happens when crop failures—already dangerously accelerating—reach a critical point? Our civilization is vulnerable. Think of ancient civilizations that couldn't survive the drying up of their water sources, the failure of their primary fields, which they assumed the gods would preserve forever, or an earthquake or sickness that killed most of their animals. Bang. Lost. They failed. They splintered, fragmented, and abandoned vast capitols and cities, and suddenly, in history's sight, poof, they were gone.
We're getting close. Decline equals civilizational peril.
We believe dumb notions about AI becoming disruptive when it's incremental. Most of us don't realize our civilization's risk because we believe these falsehoods. Everyone should know that we cannot create any thing at civilizational scale without fossil fuels. Most of us don't know it, thus we don't realize that the breakthrough technologies and systems we need don't manipulate information anymore. Instead, biotechnologies, largely but not genes, generate food without fossil fuels.
We need another Industrial Revolution. AI, apps, bots, and whatnot won't matter unless you think you can eat and drink them while the world dies and fascists, lunatics, and zealots take democracy's strongholds. That's dramatic, but only because it's already happening. Maybe AI can entertain you in that bunker while society collapses with smart jokes or a million Mondrian-like artworks. If civilization is to survive, it cannot create the new Industrial Revolution.
The revolution has begun, but only in small ways. Post-industrial fundamental systems leaders are developing worldwide. The Netherlands is leading post-industrial agriculture. That's amazing because it's a tiny country performing well. Correct? Discover how large-scale agriculture can function, not just you and me, aged hippies, cultivating lettuce in our backyards.
Iceland is leading bioplastics, which, if done well, will be a major advance. Of sure, microplastics are drowning the oceans. What should we do since we can't live without it? We need algae-based bioplastics for green plastic.
That's still young. Any of the above may not function on a civilizational scale. Bioplastics use algae, which can cause problems if overused. None of the aforementioned indicate the next Industrial Revolution is here. Contrary. Slowly.
We have three decades until everything fails. Before life ends. Curtain down. No more fields, rivers, or weather. Freshwater and life stocks have plummeted. Again, we've peaked and declined in our ability to live at today's relatively rich standards. Game over—no more. On a dying planet, producing the fundamentals for a civilisation that left it too late to construct post-industrial systems becomes next to impossible, with output dropping faster and quicker each year, quarter, and day.
Too slow. That's because it's not really happening. Most people think AI when I say tech. I get a politicized response if I say Green New Deal or Clean Industrial Revolution. Half the individuals I talk to have been politicized into believing that climate change isn't real and that any breakthrough technical progress isn't required, desirable, possible, or genuine. They'll suffer.
The Industrial Revolution curse. Every revolution creates new authorities, which ossify and refuse to relinquish their privileges. For fifty years, Big Oil has denied climate change, even though their scientists predicted it. We also have a software industry and its venture capital power centers that are happy for the average person to think tech means chatbots, not being able to produce basics for a civilization without destroying the planet, and billionaires who buy comms platforms for the same eye-watering amount of money it would take to save life on Earth.
The entire world's vested interests are against the next industrial revolution, which is understandable since they were established from fossil money. From finance to energy to corporate profits to entertainment, power in our world is the result of the last industrial revolution, which means it has no motivation or purpose to give up fossil money, as we are witnessing more brutally out in the open.
Thus, the Industrial Revolution's curse—fossil power—rules our globe. Big Agriculture, Big Pharma, Wall St., Silicon Valley, and many others—including politics, which they buy and sell—are basically fossil power, and they have no interest in generating or letting the next industrial revolution happen. That's why tiny enterprises like those creating bioplastics in Iceland or nations savvy enough to shun fossil power, like the Netherlands, which has a precarious relationship with nature, do it. However, fossil power dominates politics, economics, food, clothes, energy, and medicine, and it has no motivation to change.
Allow disruptive innovations again. As they occur, its position becomes increasingly vulnerable. If you were fossil power, would you allow another industrial revolution to destroy its privilege and wealth?
You might, since power and money haven't corrupted you. However, fossil power prevents us from building, creating, and growing what we need to survive as a society. I mean the entire economic, financial, and political power structure from the last industrial revolution, not simply Big Oil. My friends, fossil power's chokehold over our society is likely to continue suffocating the advances that could have spared our civilization from a decline that's now here and spiraling closer to oblivion.

The woman
3 years ago
The renowned and highest-paid Google software engineer
His story will inspire you.

“Google search went down for a few hours in 2002; Jeff Dean handled all the queries by hand and checked quality doubled.”- Jeff Dean Facts.
One of many Jeff Dean jokes, but you get the idea.
Google's top six engineers met in a war room in mid-2000. Google's crawling system, which indexed the Web, stopped working. Users could still enter queries, but results were five months old.
Google just signed a deal with Yahoo to power a ten-times-larger search engine. Tension rose. It was crucial. If they failed, the Yahoo agreement would likely fall through, risking bankruptcy for the firm. Their efforts could be lost.
A rangy, tall, energetic thirty-one-year-old man named Jeff dean was among those six brilliant engineers in the makeshift room. He had just left D. E. C. a couple of months ago and started his career in a relatively new firm Google, which was about to change the world. He rolled his chair over his colleague Sanjay and sat right next to him, cajoling his code like a movie director. The history started from there.
When you think of people who shaped the World Wide Web, you probably picture founders and CEOs like Larry Page and Sergey Brin, Marc Andreesen, Tim Berners-Lee, Bill Gates, and Mark Zuckerberg. They’re undoubtedly the brightest people on earth.
Under these giants, legions of anonymous coders work at keyboards to create the systems and products we use. These computer workers are irreplaceable.
Let's get to know him better.
It's possible you've never heard of Jeff Dean. He's American. Dean created many behind-the-scenes Google products. Jeff, co-founder and head of Google's deep learning research engineering team, is a popular technology, innovation, and AI keynote speaker.
While earning an MS and Ph.D. in computer science at the University of Washington, he was a teaching assistant, instructor, and research assistant. Dean joined the Compaq Computer Corporation Western Research Laboratory research team after graduating.
Jeff co-created ProfileMe and the Continuous Profiling Infrastructure for Digital at Compaq. He co-designed and implemented Swift, one of the fastest Java implementations. He was a senior technical staff member at mySimon Inc., retrieving and caching electronic commerce content.
Dean, a top young computer scientist, joined Google in mid-1999. He was always trying to maximize a computer's potential as a child.
An expert
His high school program for processing massive epidemiological data was 26 times faster than professionals'. Epi Info, in 13 languages, is used by the CDC. He worked on compilers as a computer science Ph.D. These apps make source code computer-readable.
Dean never wanted to work on compilers forever. He left Academia for Google, which had less than 20 employees. Dean helped found Google News and AdSense, which transformed the internet economy. He then addressed Google's biggest issue, scaling.
Growing Google faced a huge computing challenge. They developed PageRank in the late 1990s to return the most relevant search results. Google's popularity slowed machine deployment.
Dean solved problems, his specialty. He and fellow great programmer Sanjay Ghemawat created the Google File System, which distributed large data over thousands of cheap machines.
These two also created MapReduce, which let programmers handle massive data quantities on parallel machines. They could also add calculations to the search algorithm. A 2004 research article explained MapReduce, which became an industry sensation.
Several revolutionary inventions
Dean's other initiatives were also game-changers. BigTable, a petabyte-capable distributed data storage system, was based on Google File. The first global database, Spanner, stores data on millions of servers in dozens of data centers worldwide.
It underpins Gmail and AdWords. Google Translate co-founder Jeff Dean is surprising. He contributes heavily to Google News. Dean is Senior Fellow of Google Research and Health and leads Google AI.
Recognitions
The National Academy of Engineering elected Dean in 2009. He received the 2009 Association for Computing Machinery fellowship and the 2016 American Academy of Arts and Science fellowship. He received the 2007 ACM-SIGOPS Mark Weiser Award and the 2012 ACM-Infosys Foundation Award. Lists could continue.
A sneaky question may arrive in your mind: How much does this big brain earn? Well, most believe he is one of the highest-paid employees at Google. According to a survey, he is paid $3 million a year.
He makes espresso and chats with a small group of Googlers most mornings. Dean steams milk, another grinds, and another brews espresso. They discuss families and technology while making coffee. He thinks this little collaboration and idea-sharing keeps Google going.
“Some of us have been working together for more than 15 years,” Dean said. “We estimate that we’ve collectively made more than 20,000 cappuccinos together.”
We all know great developers and software engineers. It may inspire many.
You might also like

Jon Brosio
3 years ago
You can learn more about marketing from these 8 copywriting frameworks than from a college education.
Email, landing pages, and digital content

Today's most significant skill:
Copywriting.
Unfortunately, most people don't know how to write successful copy because they weren't taught in school.
I've been obsessed with copywriting for two years. I've read 15 books, completed 3 courses, and studied internet's best digital entrepreneurs.
Here are 8 copywriting frameworks that educate more than a four-year degree.
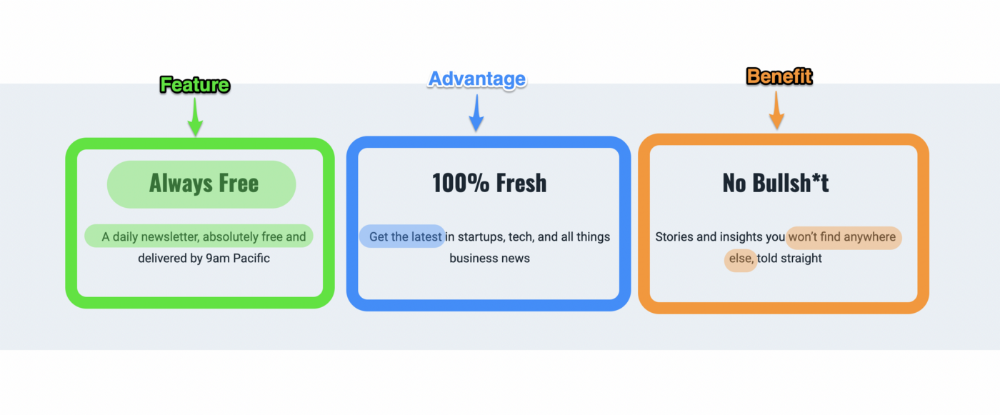
1. Feature — Advantage — Benefit (F.A.B)
This is the most basic copywriting foundation. Email marketing, landing page copy, and digital video ads can use it.
F.A.B says:
How it works (feature)
which is helpful (advantage)
What's at stake (benefit)
The Hustle uses this framework on their landing page to convince people to sign up:
2. P. A. S. T. O. R.
This framework is for longer-form copywriting. PASTOR uses stories to engage with prospects. It explains why people should buy this offer.
PASTOR means:
Problem
Amplify
Story
Testimonial
Offer
Response
Dan Koe's landing page is a great example. It shows PASTOR frame-by-frame.

3. Before — After — Bridge
Before-after-bridge is a copywriting framework that draws attention and shows value quickly.
This framework highlights:
where you are
where you want to be
how to get there
Works great for: Email threads/landing pages
Zain Kahn utilizes this framework to write viral threads.

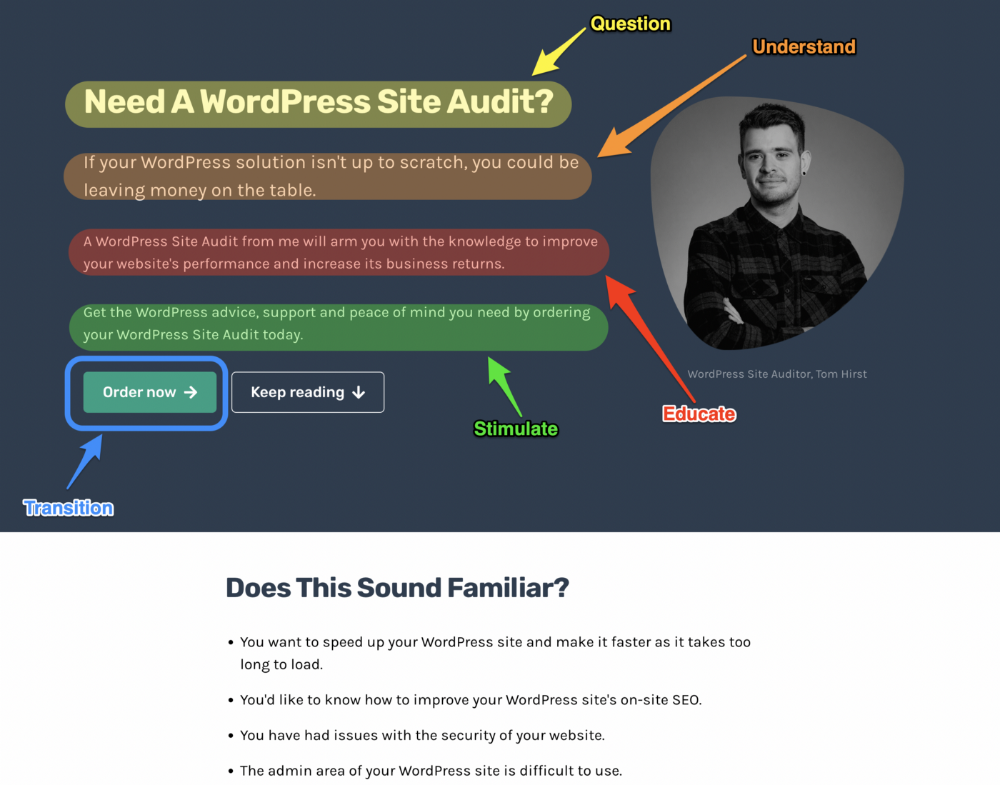
4. Q.U.E.S.T
QUEST is about empathetic writing. You know their issues, obstacles, and headaches. This allows coverups.
QUEST:
Qualifies
Understands
Educates
Stimulates
Transitions
Tom Hirst's landing page uses the QUEST framework.
5. The 4P’s model
The 4P’s approach pushes your prospect to action. It educates and persuades quickly.
4Ps:
The problem the visitor is dealing with
The promise that will help them
The proof the promise works
A push towards action
Mark Manson is a bestselling author, digital creator, and pop-philosopher. He's also a great copywriter, and his membership offer uses the 4P’s framework.

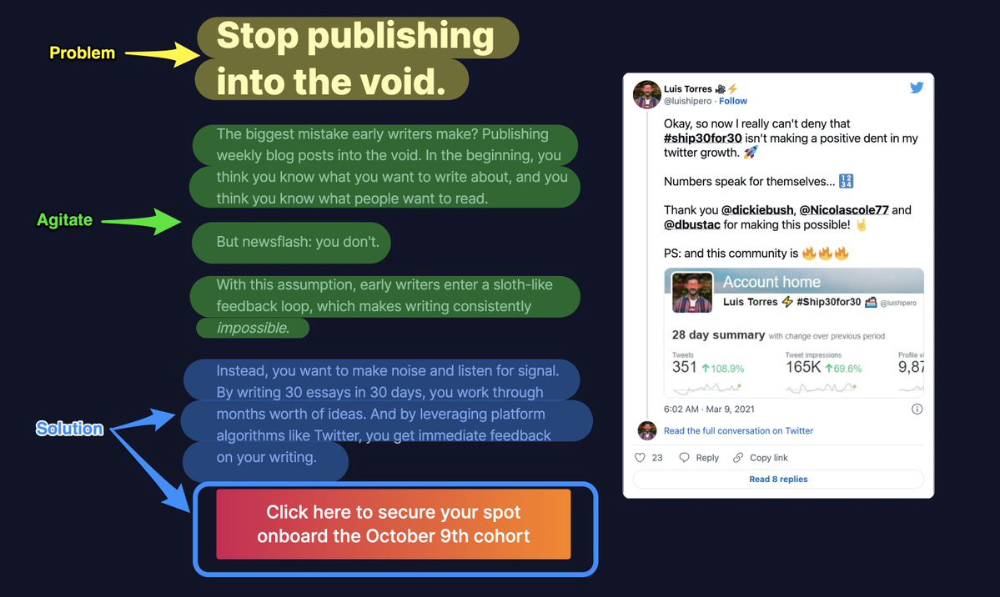
6. Problem — Agitate — Solution (P.A.S)
Up-and-coming marketers should understand problem-agitate-solution copywriting. Once you understand one structure, others are easier. It drives passion and presents a clear solution.
PAS outlines:
The issue the visitor is having
It then intensifies this issue through emotion.
finally offers an answer to that issue (the offer)
The customer's story loops. Nicolas Cole and Dickie Bush use PAS to promote Ship 30 for 30.
7. Star — Story — Solution (S.S.S)
PASTOR + PAS = star-solution-story. Like PAS, it employs stories to persuade.
S.S.S. is effective storytelling:
Star: (Person had a problem)
Story: (until they had a breakthrough)
Solution: (That created a transformation)
Ali Abdaal is a YouTuber with a great S.S.S copy.
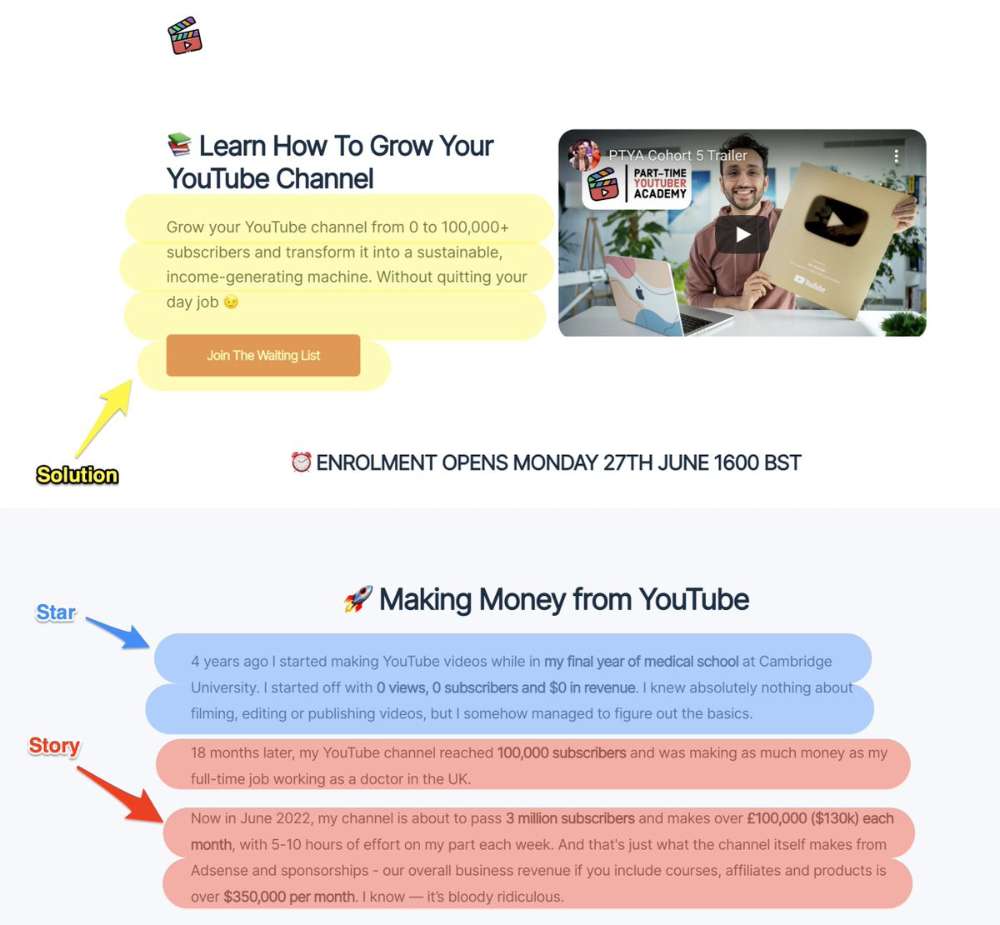
8. Attention — Interest — Desire — Action
AIDA is another classic. This copywriting framework is great for fast-paced environments (think all digital content on Linkedin, Twitter, Medium, etc.).
It works with:
Page landings
writing on thread
Email
It's a good structure since it's concise, attention-grabbing, and action-oriented.
Shane Martin, Twitter's creator, uses this approach to create viral content.
TL;DR
8 copywriting frameworks that teach marketing better than a four-year degree
Feature-advantage-benefit
Before-after-bridge
Star-story-solution
P.A.S.T.O.R
Q.U.E.S.T
A.I.D.A
P.A.S
4P’s

Desiree Peralta
3 years ago
How to Use the 2023 Recession to Grow Your Wealth Exponentially
This season's three best money moves.

“Millionaires are made in recessions.” — Time Capital
We're in a serious downturn, whether or not we're in a recession.
97% of business owners are decreasing costs by more than 10%, and all markets are down 30%.
If you know what you're doing and analyze the markets correctly, this is your chance to become a millionaire.
In any recession, there are always excellent possibilities to seize. Real estate, crypto, stocks, enterprises, etc.
What you do with your money could influence your future riches.
This article analyzes the three key markets, their circumstances for 2023, and how to profit from them.
Ways to make money on the stock market.
If you're conservative like me, you should invest in an index fund. Most of these funds are down 10-30% of ATH:
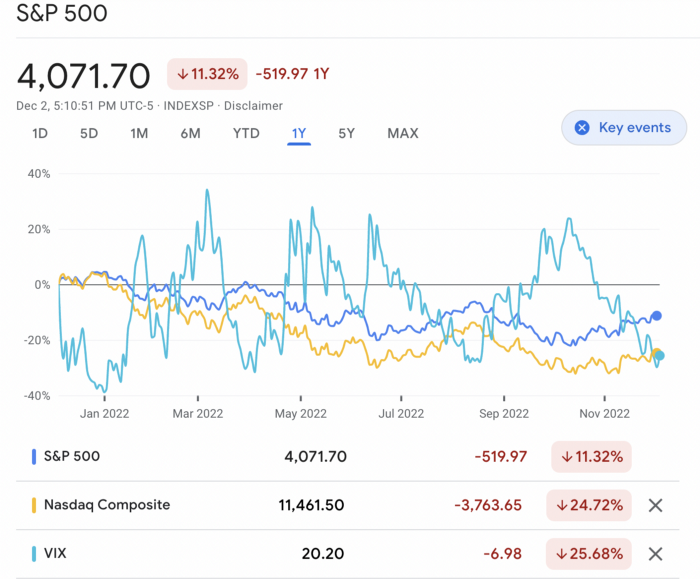
In earlier recessions, most money index funds lost 20%. After this downturn, they grew and passed the ATH in subsequent months.
Now is the greatest moment to invest in index funds to grow your money in a low-risk approach and make 20%.
If you want to be risky but wise, pick companies that will get better next year but are struggling now.
Even while we can't be 100% confident of a company's future performance, we know some are strong and will have a fantastic year.
Microsoft (down 22%), JPMorgan Chase (15.6%), Amazon (45%), and Disney (33.8%).
These firms give dividends, so you can earn passively while you wait.
So I consider that a good strategy to make wealth in the current stock market is to create two portfolios: one based on index funds to earn 10% to 20% profit when the corrections end, and the other based on individual stocks of popular and strong companies to earn 20%-30% return and dividends while you wait.
How to profit from the downturn in the real estate industry.
With rising mortgage rates, it's the worst moment to buy a home if you don't want to be eaten by banks. In the U.S., interest rates are double what they were three years ago, so buying now looks foolish.
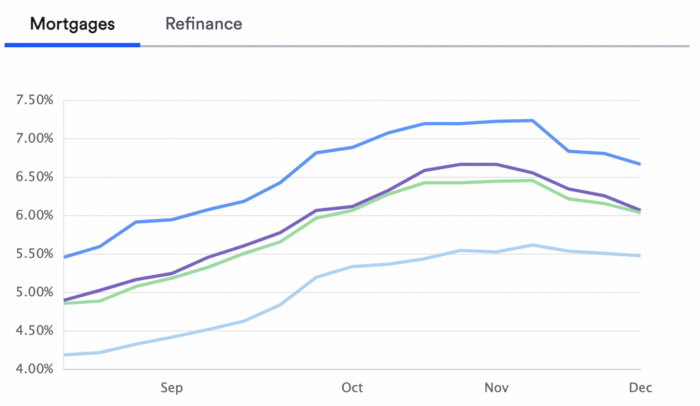
Due to these rates, property prices are falling, but that won't last long since individuals will take advantage.
According to historical data, now is the ideal moment to buy a house for the next five years and perhaps forever.
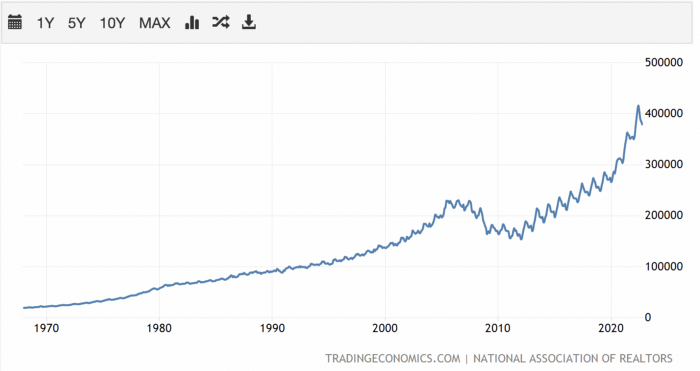
If you can buy a house, do it. You can refinance the interest at a lower rate with acceptable credit, but not the house price.
Take advantage of the housing market prices now because you won't find a decent deal when rates normalize.
How to profit from the cryptocurrency market.
This is the riskiest market to tackle right now, but it could offer the most opportunities if done appropriately.
The most powerful cryptocurrencies are down more than 60% from last year: $68,990 for BTC and $4,865 for ETH.
If you focus on those two coins, you can make 30%-60% without waiting for them to return to their ATH, and they're low enough to be a solid investment.
I don't encourage trying other altcoins because the crypto market is in crisis and you can lose everything if you're greedy.
Still, the main Cryptos are a good investment provided you store them in an external wallet and follow financial gurus' security advice.
Last thoughts
We can't anticipate a recession until it ends. We can't forecast a market or asset's lowest point, therefore waiting makes little sense.
If you want to develop your wealth, assess the money prospects on all the marketplaces and initiate long-term trades.
Many millionaires are made during recessions because they don't fear negative figures and use them to scale their money.

Vivek Singh
4 years ago
A Warm Welcome to Web3 and the Future of the Internet
Let's take a look back at the internet's history and see where we're going — and why.
Tim Berners Lee had a problem. He was at CERN, the world's largest particle physics factory, at the time. The institute's stated goal was to study the simplest particles with the most sophisticated scientific instruments. The institute completed the LEP Tunnel in 1988, a 27 kilometer ring. This was Europe's largest civil engineering project (to study smaller particles — electrons).
The problem Tim Berners Lee found was information loss, not particle physics. CERN employed a thousand people in 1989. Due to team size and complexity, people often struggled to recall past project information. While these obstacles could be overcome, high turnover was nearly impossible. Berners Lee addressed the issue in a proposal titled ‘Information Management'.
When a typical stay is two years, data is constantly lost. The introduction of new people takes a lot of time from them and others before they understand what is going on. An emergency situation may require a detective investigation to recover technical details of past projects. Often, the data is recorded but cannot be found. — Information Management: A Proposal
He had an idea. Create an information management system that allowed users to access data in a decentralized manner using a new technology called ‘hypertext'.
To quote Berners Lee, his proposal was “vague but exciting...”. The paper eventually evolved into the internet we know today. Here are three popular W3C standards used by billions of people today:
(credit: CERN)
HTML (Hypertext Markup)
A web formatting language.
URI (Unique Resource Identifier)
Each web resource has its own “address”. Known as ‘a URL'.
HTTP (Hypertext Transfer Protocol)
Retrieves linked resources from across the web.
These technologies underpin all computer work. They were the seeds of our quest to reorganize information, a task as fruitful as particle physics.
Tim Berners-Lee would probably think the three decades from 1989 to 2018 were eventful. He'd be amazed by the billions, the inspiring, the novel. Unlocking innovation at CERN through ‘Information Management'.
The fictional character would probably need a drink, walk, and a few deep breaths to fully grasp the internet's impact. He'd be surprised to see a few big names in the mix.
Then he'd say, "Something's wrong here."
We should review the web's history before going there. Was it a success after Berners Lee made it public? Web1 and Web2: What is it about what we are doing now that so many believe we need a new one, web3?
Per Outlier Ventures' Jamie Burke:
Web 1.0 was read-only.
Web 2.0 was the writable
Web 3.0 is a direct-write web.
Let's explore.
Web1: The Read-Only Web
Web1 was the digital age. We put our books, research, and lives ‘online'. The web made information retrieval easier than any filing cabinet ever. Massive amounts of data were stored online. Encyclopedias, medical records, and entire libraries were put away into floppy disks and hard drives.
In 2015, the web had around 305,500,000,000 pages of content (280 million copies of Atlas Shrugged).
Initially, one didn't expect to contribute much to this database. Web1 was an online version of the real world, but not yet a new way of using the invention.
One gets the impression that the web has been underutilized by historians if all we can say about it is that it has become a giant global fax machine. — Daniel Cohen, The Web's Second Decade (2004)
That doesn't mean developers weren't building. The web was being advanced by great minds. Web2 was born as technology advanced.
Web2: Read-Write Web
Remember when you clicked something on a website and the whole page refreshed? Is it too early to call the mid-2000s ‘the good old days'?
Browsers improved gradually, then suddenly. AJAX calls augmented CGI scripts, and applications began sending data back and forth without disrupting the entire web page. One button to ‘digg' a post (see below). Web experiences blossomed.
In 2006, Digg was the most active ‘Web 2.0' site. (Photo: Ethereum Foundation Taylor Gerring)
Interaction was the focus of new applications. Posting, upvoting, hearting, pinning, tweeting, liking, commenting, and clapping became a lexicon of their own. It exploded in 2004. Easy ways to ‘write' on the internet grew, and continue to grow.
Facebook became a Web2 icon, where users created trillions of rows of data. Google and Amazon moved from Web1 to Web2 by better understanding users and building products and services that met their needs.
Business models based on Software-as-a-Service and then managing consumer data within them for a fee have exploded.
Web2 Emerging Issues
Unbelievably, an intriguing dilemma arose. When creating this read-write web, a non-trivial question skirted underneath the covers. Who owns it all?
You have no control over [Web 2] online SaaS. People didn't realize this because SaaS was so new. People have realized this is the real issue in recent years.
Even if these organizations have good intentions, their incentive is not on the users' side.
“You are not their customer, therefore you are their product,” they say. With Laura Shin, Vitalik Buterin, Unchained
A good plot line emerges. Many amazing, world-changing software products quietly lost users' data control.
For example: Facebook owns much of your social graph data. Even if you hate Facebook, you can't leave without giving up that data. There is no ‘export' or ‘exit'. The platform owns ownership.
While many companies can pull data on you, you cannot do so.
On the surface, this isn't an issue. These companies use my data better than I do! A complex group of stakeholders, each with their own goals. One is maximizing shareholder value for public companies. Tim Berners-Lee (and others) dislike the incentives created.
“Show me the incentive and I will show you the outcome.” — Berkshire Hathaway's CEO
It's easy to see what the read-write web has allowed in retrospect. We've been given the keys to create content instead of just consume it. On Facebook and Twitter, anyone with a laptop and internet can participate. But the engagement isn't ours. Platforms own themselves.
Web3: The ‘Unmediated’ Read-Write Web
Tim Berners Lee proposed a decade ago that ‘linked data' could solve the internet's data problem.
However, until recently, the same principles that allowed the Web of documents to thrive were not applied to data...
The Web of Data also allows for new domain-specific applications. Unlike Web 2.0 mashups, Linked Data applications work with an unbound global data space. As new data sources appear on the Web, they can provide more complete answers.
At around the same time as linked data research began, Satoshi Nakamoto created Bitcoin. After ten years, it appears that Berners Lee's ideas ‘link' spiritually with cryptocurrencies.
What should Web 3 do?
Here are some quick predictions for the web's future.
Users' data:
Users own information and provide it to corporations, businesses, or services that will benefit them.
Defying censorship:
No government, company, or institution should control your access to information (1, 2, 3)
Connect users and platforms:
Create symbiotic rather than competitive relationships between users and platform creators.
Open networks:
“First, the cryptonetwork-participant contract is enforced in open source code. Their voices and exits are used to keep them in check.” Dixon, Chris (4)
Global interactivity:
Transacting value, information, or assets with anyone with internet access, anywhere, at low cost
Self-determination:
Giving you the ability to own, see, and understand your entire digital identity.
Not pull, push:
‘Push' your data to trusted sources instead of ‘pulling' it from others.
Where Does This Leave Us?
Change incentives, change the world. Nick Babalola
People believe web3 can help build a better, fairer system. This is not the same as equal pay or outcomes, but more equal opportunity.
It should be noted that some of these advantages have been discussed previously. Will the changes work? Will they make a difference? These unanswered questions are technical, economic, political, and philosophical. Unintended consequences are likely.
We hope Web3 is a more democratic web. And we think incentives help the user. If there’s one thing that’s on our side, it’s that open has always beaten closed, given a long enough timescale.
We are at the start.