








More on Web3 & Crypto

Ren & Heinrich
3 years ago
200 DeFi Projects were examined. Here is what I learned.
I analyze the top 200 DeFi crypto projects in this article.
This isn't a study. The findings benefit crypto investors.
Let’s go!
A set of data
I analyzed data from defillama.com. In my analysis, I used the top 200 DeFis by TVL in October 2022.
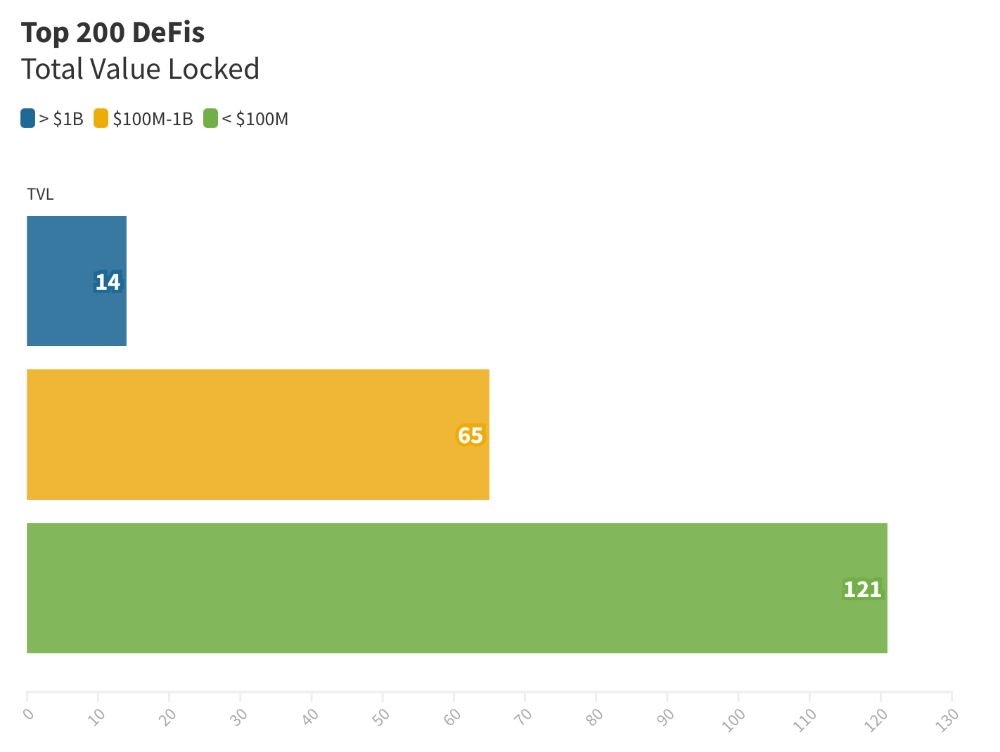
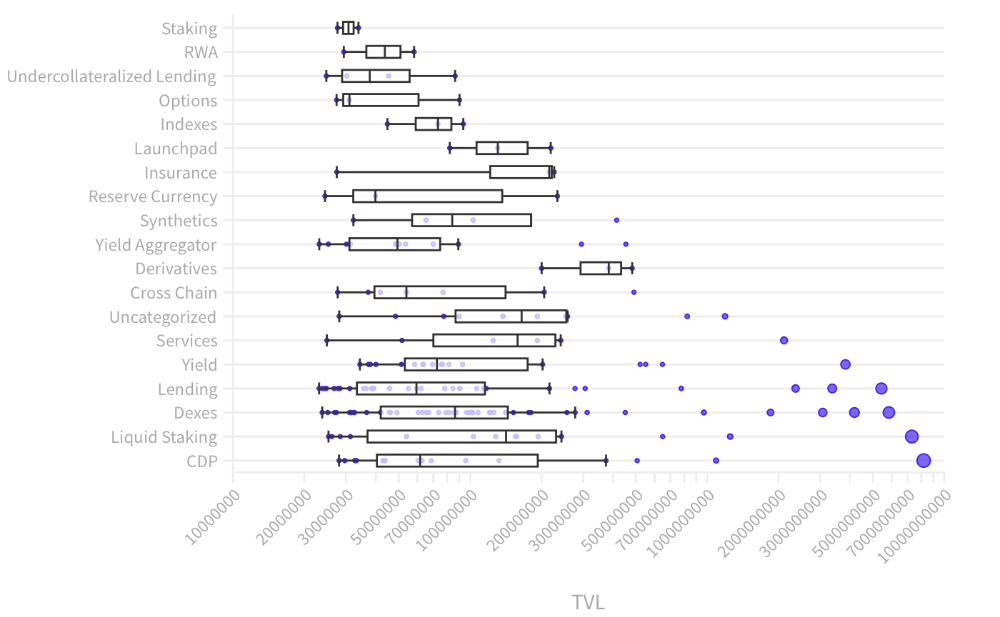
Total Locked Value
The chart below shows platform-specific locked value.
14 platforms had $1B+ TVL. 65 platforms have $100M-$1B TVL. The remaining 121 platforms had TVLs below $100 million, with the lowest being $23 million.
TVLs are distributed Pareto. Top 40% of DeFis account for 80% of TVLs.
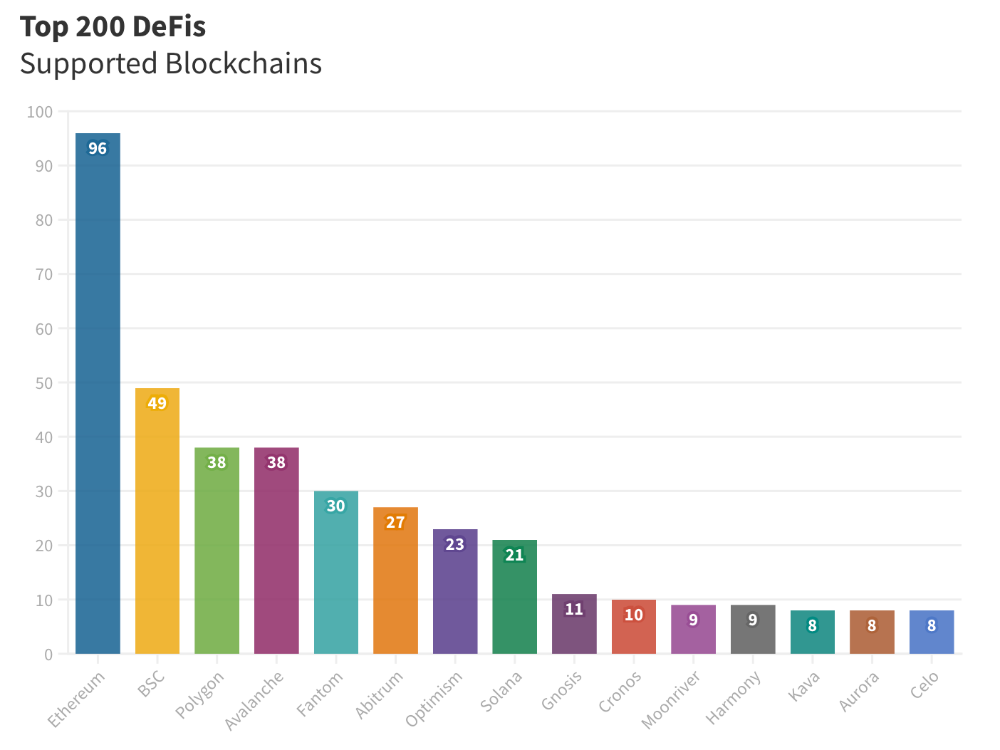
Compliant Blockchains
Ethereum's blockchain leads DeFi. 96 of the examined projects offer services on Ethereum. Behind BSC, Polygon, and Avalanche.
Five platforms used 10+ blockchains. 36 between 2-10 159 used 1 blockchain.
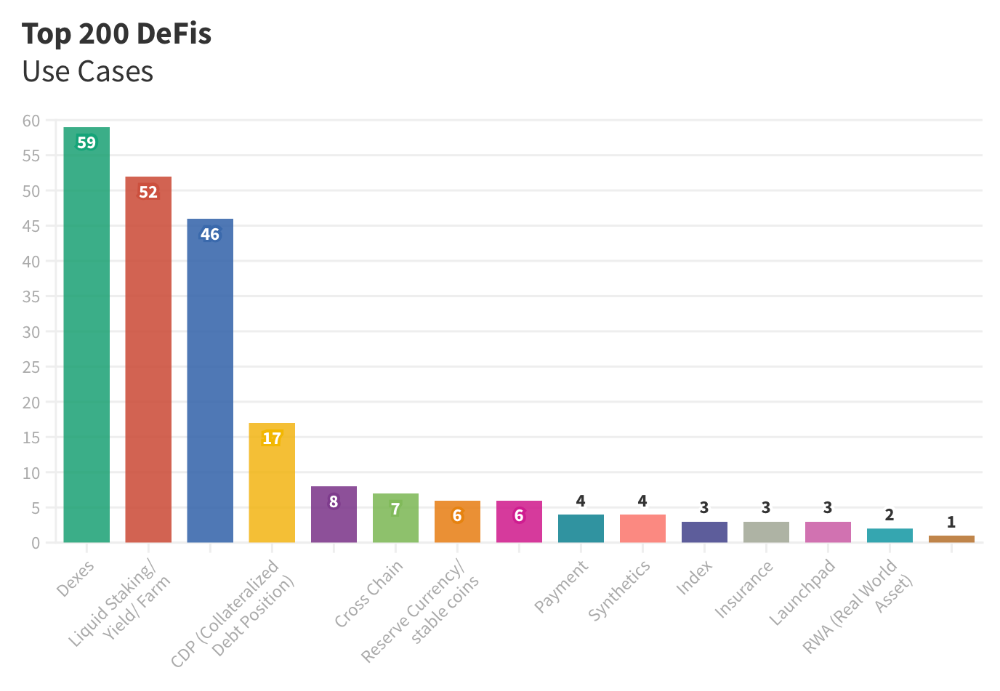
Use Cases for DeFi
The chart below shows platform use cases. Each platform has decentralized exchanges, liquid staking, yield farming, and lending.
These use cases are DefiLlama's main platform features.
Which use case costs the most? Chart explains. Collateralized debt, liquid staking, dexes, and lending have high TVLs.
The DeFi Industry
I compared three high-TVL platforms (Maker DAO, Balancer, AAVE). The columns show monthly TVL and token price changes. The graph shows monthly Bitcoin price changes.
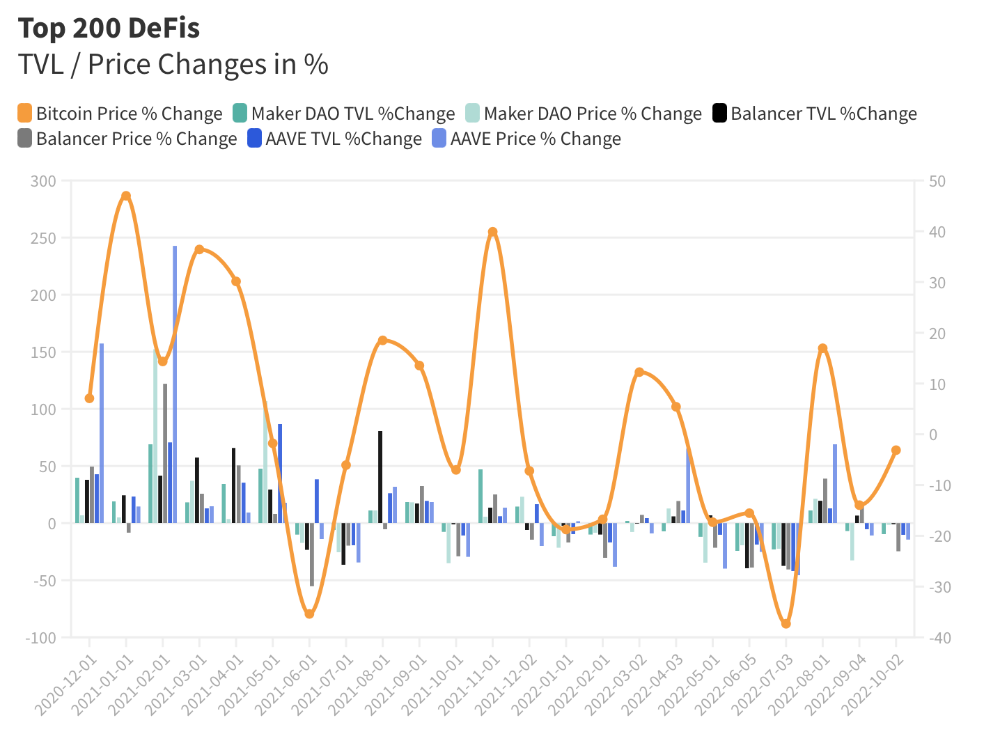
Each platform's market moves similarly.
Probably because most DeFi deposits are cryptocurrencies. Since individual currencies are highly correlated with Bitcoin, it's not surprising that they move in unison.
Takeaways
This analysis shows that the most common DeFi services (decentralized exchanges, liquid staking, yield farming, and lending) also have the highest average locked value.
Some projects run on one or two blockchains, while others use 15 or 20. Our analysis shows that a project's blockchain count has no correlation with its success.
It's hard to tell if certain use cases are rising. Bitcoin's price heavily affects the entire DeFi market.
TVL seems to be a good indicator of a DeFi platform's success and quality. Higher TVL platforms are cheaper. They're a better long-term investment because they gain or lose less value than DeFis with lower TVLs.

Koji Mochizuki
4 years ago
How to Launch an NFT Project by Yourself
Creating 10,000 auto-generated artworks, deploying a smart contract to the Ethereum / Polygon blockchain, setting up some tools, etc.
There is so much to do from launching to running an NFT project. Creating parts for artworks, generating 10,000 unique artworks and metadata, creating a smart contract and deploying it to a blockchain network, creating a website, creating a Twitter account, setting up a Discord server, setting up an OpenSea collection. In addition, you need to have MetaMask installed in your browser and have some ETH / MATIC. Did you get tired of doing all this? Don’t worry, once you know what you need to do, all you have to do is do it one by one.
To be honest, it’s best to run an NFT project in a team of three or more, including artists, developers, and marketers. However, depending on your motivation, you can do it by yourself. Some people might come later to offer help with your project. The most important thing is to take a step as soon as possible.
Creating Parts for Artworks
There are lots of free/paid software for drawing, but after all, I think Adobe Illustrator or Photoshop is the best. The images of Skulls In Love are a composite of 48x48 pixel parts created using Photoshop.
The most important thing in creating parts for generative art is to repeatedly test what your artworks will look like after each layer has been combined. The generated artworks should not be too unnatural.
How Many Parts Should You Create?
Are you wondering how many parts you should create to avoid duplication as much as possible when generating your artworks? My friend Stephane, a developer, has created a great tool to help with that.
Generating 10,000 Unique Artworks and Metadata
I highly recommend using the HashLips Art Engine to generate your artworks and metadata. Perhaps there is no better artworks generation tool at the moment.
GitHub: https://github.com/HashLips/hashlips_art_engine
YouTube:
Storing Artworks and Metadata
Ideally, the generated artworks and metadata should be stored on-chain, but if you want to store them off-chain, you should use IPFS. Do not store in centralized storage. This is because data will be lost if the server goes down or if the company goes down. On the other hand, IPFS is a more secure way to find data because it utilizes a distributed, decentralized system.
Storing to IPFS is easy with Pinata, NFT.Storage, and so on. The Skulls In Love uses Pinata. It’s very easy to use, just upload the folder containing your artworks.
Creating and Deploying a Smart Contract
You don’t have to create a smart contract from scratch. There are many great NFT projects, many of which publish their contract source code on Etherscan / PolygonScan. You can choose the contract you like and reuse it. Of course, that requires some knowledge of Solidity, but it depends on your efforts. If you don’t know which contract to choose, use the HashLips smart contract. It’s very simple, but it has almost all the functions you need.
GitHub: https://github.com/HashLips/hashlips_nft_contract
Note: Later on, you may want to change the cost value. You can change it on Remix or Etherscan / PolygonScan. But in this case, enter the Wei value instead of the Ether value. For example, if you want to sell for 1 MATIC, you have to enter “1000000000000000000”. If you set this value to “1”, you will have a nightmare. I recommend using Simple Unit Converter as a tool to calculate the Wei value.
Creating a Website
The website here is not just a static site to showcase your project, it’s a so-called dApp that allows you to access your smart contract and mint NFTs. In fact, this level of dApp is not too difficult for anyone who has ever created a website. Because the ethers.js / web3.js libraries make it easy to interact with your smart contract. There’s also no problem connecting wallets, as MetaMask has great documentation.
The Skulls In Love uses a simple, fast, and modern dApp that I built from scratch using Next.js. It is published on GitHub, so feel free to use it.
Why do people mint NFTs on a website?
Ethereum’s gas fees are high, so if you mint all your NFTs, there will be a huge initial cost. So it makes sense to get the buyers to help with the gas fees for minting.
What about Polygon? Polygon’s gas fees are super cheap, so even if you mint 10,000 NFTs, it’s not a big deal. But we don’t do that. Since NFT projects are a kind of game, it involves the fun of not knowing what will come out after minting.
Creating a Twitter Account
I highly recommend creating a Twitter account. Twitter is an indispensable tool for announcing giveaways and reaching more people. It’s better to announce your project and your artworks little by little, 1–2 weeks before launching your project.
Creating and Setting Up a Discord Server
I highly recommend creating a Discord server as well as a Twitter account. The Discord server is a community and its home. Fans of your NFT project will want to join your community and interact with many other members. So, carefully create each channel on your Discord server to make it a cozy place for your community members.
If you are unfamiliar with Discord, you may be particularly confused by the following:
What bots should I use?
How should I set roles and permissions?
But don’t worry. There are lots of great YouTube videos and blog posts about these.
It’s also a good idea to join the Discord servers of some NFT projects and see how they’re made. Our Discord server is so simple that even beginners will find it easy to understand. Please join us and see it!
Note: First, create a test account and a test server to make sure your bots and permissions work properly. It is better to verify the behavior on the test server before setting up your production server.
UPDATED: As your Discord server grows, you cannot manage it on your own. In this case, you will be hiring several moderators, but choose carefully before hiring. And don’t give them important role permissions right after hiring. Initially, the same permissions as other members are sufficient. After a while, you can add permissions as needed, such as kicking/banning, using the “@every” tag, and adding roles. Again, don’t immediately give significant permissions to your Mod role. Your server can be messed up by fake moderators.
Setting Up Your OpenSea Collection
Before you start selling your NFTs, you need to reserve some for airdrops, giveaways, staff, and more. It’s up to you whether it’s 100, 500, or how many.
After minting some of your NFTs, your account and collection should have been created in OpenSea. Go to OpenSea, connect to your wallet, and set up your collection. Just set your logo, banner image, description, links, royalties, and more. It’s not that difficult.
Promoting Your Project
After all, promotion is the most important thing. In fact, almost every successful NFT project spends a lot of time and effort on it.
In addition to Twitter and Discord, it’s even better to use Instagram, Reddit, and Medium. Also, register your project in NFTCalendar and DISBOARD
DISBOARD is the public Discord server listing community.
About Promoters
You’ll probably get lots of contacts from promoters on your Discord, Twitter, Instagram, and more. But most of them are scams, so don’t pay right away. If you have a promoter that looks attractive to you, be sure to check the promoter’s social media accounts or website to see who he/she is. They basically charge in dollars. The amount they charge isn’t cheap, but promoters with lots of followers may have some temporary effect on your project. Some promoters accept 50% prepaid and 50% postpaid. If you can afford it, it might be worth a try. I never ask them, though.
When Should the Promotion Activities Start?
You may be worried that if you promote your project before it starts, someone will copy your project (artworks). It is true that some projects have actually suffered such damage. I don’t have a clear answer to this question right now, but:
- Do not publish all the information about your project too early
- The information should be released little by little
- Creating artworks that no one can easily copy
I think these are important.
If anyone has a good idea, please share it!
About Giveaways
When hosting giveaways, you’ll probably use multiple social media platforms. You may want to grow your Discord server faster. But if joining the Discord server is included in the giveaway requirements, some people hate it. I recommend holding giveaways for each platform. On Twitter and Reddit, you should just add the words “Discord members-only giveaway is being held now! Please join us if you like!”.
If you want to easily pick a giveaway winner in your browser, I recommend Twitter Picker.
Precautions for Distributing Free NFTs
If you want to increase your Twitter followers and Discord members, you can actually get a lot of people by holding events such as giveaways and invite contests. However, distributing many free NFTs at once can be dangerous. Some people who want free NFTs, as soon as they get a free one, sell it at a very low price on marketplaces such as OpenSea. They don’t care about your project and are only thinking about replacing their own “free” NFTs with Ethereum. The lower the floor price of your NFTs, the lower the value of your NFTs (project). Try to think of ways to get people to “buy” your NFTs as much as possible.
Ethereum vs. Polygon
Even though Ethereum has high gas fees, NFT projects on the Ethereum network are still mainstream and popular. On the other hand, Polygon has very low gas fees and fast transaction processing, but NFT projects on the Polygon network are not very popular.
Why? There are several reasons, but the biggest one is that it’s a lot of work to get MATIC (on Polygon blockchain, use MATIC instead of ETH) ready to use. Simply put, you need to bridge your tokens to the Polygon chain. So people need to do this first before minting your NFTs on your website. It may not be a big deal for those who are familiar with crypto and blockchain, but it may be complicated for those who are not. I hope that the tedious work will be simplified in the near future.
If you are confident that your NFTs will be purchased even if they are expensive, or if the total supply of your NFTs is low, you may choose Ethereum. If you just want to save money, you should choose Polygon. Keep in mind that gas fees are incurred not only when minting, but also when performing some of your smart contract functions and when transferring your NFTs.
If I were to launch a new NFT project, I would probably choose Ethereum or Solana.
Conclusion
Some people may want to start an NFT project to make money, but don’t forget to enjoy your own project. Several months ago, I was playing with creating generative art by imitating the CryptoPunks. I found out that auto-generated artworks would be more interesting than I had imagined, and since then I’ve been completely absorbed in generative art.
This is one of the Skulls In Love artworks:
This character wears a cowboy hat, black slim sunglasses, and a kimono. If anyone looks like this, I can’t help laughing!
The Skulls In Love NFTs can be minted for a small amount of MATIC on the official website. Please give it a try to see what kind of unique characters will appear 💀💖
Thank you for reading to the end. I hope this article will be helpful to those who want to launch an NFT project in the future ✨

Farhan Ali Khan
2 years ago
Introduction to Zero-Knowledge Proofs: The Art of Proving Without Revealing
Zero-Knowledge Proofs for Beginners
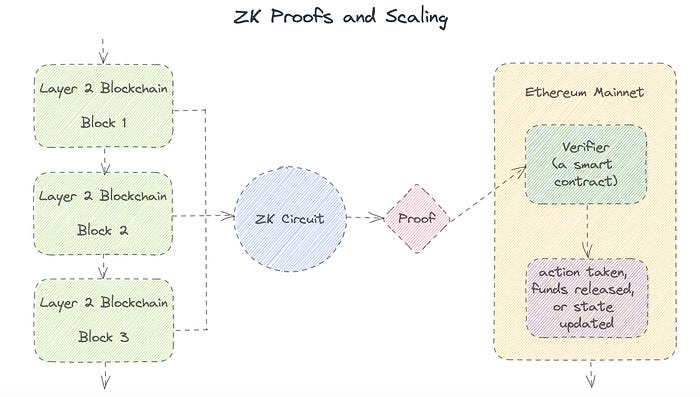
Published here originally.
Introduction
I Spy—did you play as a kid? One person chose a room object, and the other had to guess it by answering yes or no questions. I Spy was entertaining, but did you know it could teach you cryptography?
Zero Knowledge Proofs let you show your pal you know what they picked without exposing how. Math replaces electronics in this secret spy mission. Zero-knowledge proofs (ZKPs) are sophisticated cryptographic tools that allow one party to prove they have particular knowledge without revealing it. This proves identification and ownership, secures financial transactions, and more. This article explains zero-knowledge proofs and provides examples to help you comprehend this powerful technology.
What is a Proof of Zero Knowledge?
Zero-knowledge proofs prove a proposition is true without revealing any other information. This lets the prover show the verifier that they know a fact without revealing it. So, a zero-knowledge proof is like a magician's trick: the prover proves they know something without revealing how or what. Complex mathematical procedures create a proof the verifier can verify.
Want to find an easy way to test it out? Try out with tis awesome example! ZK Crush
Describe it as if I'm 5
Alex and Jack found a cave with a center entrance that only opens when someone knows the secret. Alex knows how to open the cave door and wants to show Jack without telling him.
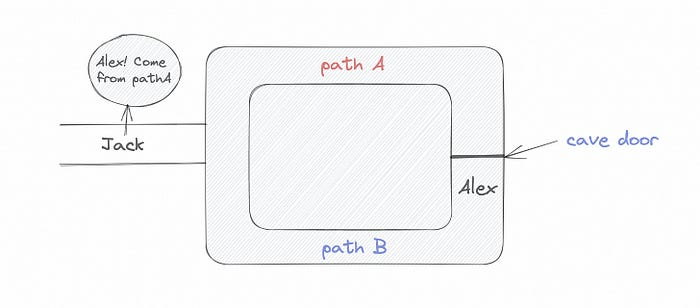
Alex and Jack name both pathways (let’s call them paths A and B).
In the first phase, Alex is already inside the cave and is free to select either path, in this case A or B.
As Alex made his decision, Jack entered the cave and asked him to exit from the B path.
Jack can confirm that Alex really does know the key to open the door because he came out for the B path and used it.
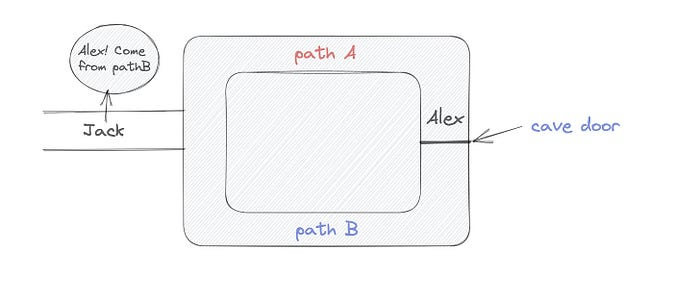
To conclude, Alex and Jack repeat:
Alex walks into the cave.
Alex follows a random route.
Jack walks into the cave.
Alex is asked to follow a random route by Jack.
Alex follows Jack's advice and heads back that way.
What is a Zero Knowledge Proof?
At a high level, the aim is to construct a secure and confidential conversation between the prover and the verifier, where the prover convinces the verifier that they have the requisite information without disclosing it. The prover and verifier exchange messages and calculate in each round of the dialogue.
The prover uses their knowledge to prove they have the information the verifier wants during these rounds. The verifier can verify the prover's truthfulness without learning more by checking the proof's mathematical statement or computation.
Zero knowledge proofs use advanced mathematical procedures and cryptography methods to secure communication. These methods ensure the evidence is authentic while preventing the prover from creating a phony proof or the verifier from extracting unnecessary information.
ZK proofs require examples to grasp. Before the examples, there are some preconditions.
Criteria for Proofs of Zero Knowledge
Completeness: If the proposition being proved is true, then an honest prover will persuade an honest verifier that it is true.
Soundness: If the proposition being proved is untrue, no dishonest prover can persuade a sincere verifier that it is true.
Zero-knowledge: The verifier only realizes that the proposition being proved is true. In other words, the proof only establishes the veracity of the proposition being supported and nothing more.
The zero-knowledge condition is crucial. Zero-knowledge proofs show only the secret's veracity. The verifier shouldn't know the secret's value or other details.
Example after example after example
To illustrate, take a zero-knowledge proof with several examples:
Initial Password Verification Example
You want to confirm you know a password or secret phrase without revealing it.
Use a zero-knowledge proof:
You and the verifier settle on a mathematical conundrum or issue, such as figuring out a big number's components.
The puzzle or problem is then solved using the hidden knowledge that you have learned. You may, for instance, utilize your understanding of the password to determine the components of a particular number.
You provide your answer to the verifier, who can assess its accuracy without knowing anything about your private data.
You go through this process several times with various riddles or issues to persuade the verifier that you actually are aware of the secret knowledge.
You solved the mathematical puzzles or problems, proving to the verifier that you know the hidden information. The proof is zero-knowledge since the verifier only sees puzzle solutions, not the secret information.
In this scenario, the mathematical challenge or problem represents the secret, and solving it proves you know it. The evidence does not expose the secret, and the verifier just learns that you know it.
My simple example meets the zero-knowledge proof conditions:
Completeness: If you actually know the hidden information, you will be able to solve the mathematical puzzles or problems, hence the proof is conclusive.
Soundness: The proof is sound because the verifier can use a publicly known algorithm to confirm that your answer to the mathematical conundrum or difficulty is accurate.
Zero-knowledge: The proof is zero-knowledge because all the verifier learns is that you are aware of the confidential information. Beyond the fact that you are aware of it, the verifier does not learn anything about the secret information itself, such as the password or the factors of the number. As a result, the proof does not provide any new insights into the secret.
Explanation #2: Toss a coin.
One coin is biased to come up heads more often than tails, while the other is fair (i.e., comes up heads and tails with equal probability). You know which coin is which, but you want to show a friend you can tell them apart without telling them.
Use a zero-knowledge proof:
One of the two coins is chosen at random, and you secretly flip it more than once.
You show your pal the following series of coin flips without revealing which coin you actually flipped.
Next, as one of the two coins is flipped in front of you, your friend asks you to tell which one it is.
Then, without revealing which coin is which, you can use your understanding of the secret order of coin flips to determine which coin your friend flipped.
To persuade your friend that you can actually differentiate between the coins, you repeat this process multiple times using various secret coin-flipping sequences.
In this example, the series of coin flips represents the knowledge of biased and fair coins. You can prove you know which coin is which without revealing which is biased or fair by employing a different secret sequence of coin flips for each round.
The evidence is zero-knowledge since your friend does not learn anything about which coin is biased and which is fair other than that you can tell them differently. The proof does not indicate which coin you flipped or how many times you flipped it.
The coin-flipping example meets zero-knowledge proof requirements:
Completeness: If you actually know which coin is biased and which is fair, you should be able to distinguish between them based on the order of coin flips, and your friend should be persuaded that you can.
Soundness: Your friend may confirm that you are correctly recognizing the coins by flipping one of them in front of you and validating your answer, thus the proof is sound in that regard. Because of this, your acquaintance can be sure that you are not just speculating or picking a coin at random.
Zero-knowledge: The argument is that your friend has no idea which coin is biased and which is fair beyond your ability to distinguish between them. Your friend is not made aware of the coin you used to make your decision or the order in which you flipped the coins. Consequently, except from letting you know which coin is biased and which is fair, the proof does not give any additional information about the coins themselves.
Figure out the prime number in Example #3.
You want to prove to a friend that you know their product n=pq without revealing p and q. Zero-knowledge proof?
Use a variant of the RSA algorithm. Method:
You determine a new number s = r2 mod n by computing a random number r.
You email your friend s and a declaration that you are aware of the values of p and q necessary for n to equal pq.
A random number (either 0 or 1) is selected by your friend and sent to you.
You send your friend r as evidence that you are aware of the values of p and q if e=0. You calculate and communicate your friend's s/r if e=1.
Without knowing the values of p and q, your friend can confirm that you know p and q (in the case where e=0) or that s/r is a legitimate square root of s mod n (in the situation where e=1).
This is a zero-knowledge proof since your friend learns nothing about p and q other than their product is n and your ability to verify it without exposing any other information. You can prove that you know p and q by sending r or by computing s/r and sending that instead (if e=1), and your friend can verify that you know p and q or that s/r is a valid square root of s mod n without learning anything else about their values. This meets the conditions of completeness, soundness, and zero-knowledge.
Zero-knowledge proofs satisfy the following:
Completeness: The prover can demonstrate this to the verifier by computing q = n/p and sending both p and q to the verifier. The prover also knows a prime number p and a factorization of n as p*q.
Soundness: Since it is impossible to identify any pair of numbers that correctly factorize n without being aware of its prime factors, the prover is unable to demonstrate knowledge of any p and q that do not do so.
Zero knowledge: The prover only admits that they are aware of a prime number p and its associated factor q, which is already known to the verifier. This is the extent of their knowledge of the prime factors of n. As a result, the prover does not provide any new details regarding n's prime factors.
Types of Proofs of Zero Knowledge
Each zero-knowledge proof has pros and cons. Most zero-knowledge proofs are:
Interactive Zero Knowledge Proofs: The prover and the verifier work together to establish the proof in this sort of zero-knowledge proof. The verifier disputes the prover's assertions after receiving a sequence of messages from the prover. When the evidence has been established, the prover will employ these new problems to generate additional responses.
Non-Interactive Zero Knowledge Proofs: For this kind of zero-knowledge proof, the prover and verifier just need to exchange a single message. Without further interaction between the two parties, the proof is established.
A statistical zero-knowledge proof is one in which the conclusion is reached with a high degree of probability but not with certainty. This indicates that there is a remote possibility that the proof is false, but that this possibility is so remote as to be unimportant.
Succinct Non-Interactive Argument of Knowledge (SNARKs): SNARKs are an extremely effective and scalable form of zero-knowledge proof. They are utilized in many different applications, such as machine learning, blockchain technology, and more. Similar to other zero-knowledge proof techniques, SNARKs enable one party—the prover—to demonstrate to another—the verifier—that they are aware of a specific piece of information without disclosing any more information about that information.
The main characteristic of SNARKs is their succinctness, which refers to the fact that the size of the proof is substantially smaller than the amount of the original data being proved. Because to its high efficiency and scalability, SNARKs can be used in a wide range of applications, such as machine learning, blockchain technology, and more.
Uses for Zero Knowledge Proofs
ZKP applications include:
Verifying Identity ZKPs can be used to verify your identity without disclosing any personal information. This has uses in access control, digital signatures, and online authentication.
Proof of Ownership ZKPs can be used to demonstrate ownership of a certain asset without divulging any details about the asset itself. This has uses for protecting intellectual property, managing supply chains, and owning digital assets.
Financial Exchanges Without disclosing any details about the transaction itself, ZKPs can be used to validate financial transactions. Cryptocurrency, internet payments, and other digital financial transactions can all use this.
By enabling parties to make calculations on the data without disclosing the data itself, Data Privacy ZKPs can be used to preserve the privacy of sensitive data. Applications for this can be found in the financial, healthcare, and other sectors that handle sensitive data.
By enabling voters to confirm that their vote was counted without disclosing how they voted, elections ZKPs can be used to ensure the integrity of elections. This is applicable to electronic voting, including internet voting.
Cryptography Modern cryptography's ZKPs are a potent instrument that enable secure communication and authentication. This can be used for encrypted messaging and other purposes in the business sector as well as for military and intelligence operations.
Proofs of Zero Knowledge and Compliance
Kubernetes and regulatory compliance use ZKPs in many ways. Examples:
Security for Kubernetes ZKPs offer a mechanism to authenticate nodes without disclosing any sensitive information, enhancing the security of Kubernetes clusters. ZKPs, for instance, can be used to verify, without disclosing the specifics of the program, that the nodes in a Kubernetes cluster are running permitted software.
Compliance Inspection Without disclosing any sensitive information, ZKPs can be used to demonstrate compliance with rules like the GDPR, HIPAA, and PCI DSS. ZKPs, for instance, can be used to demonstrate that data has been encrypted and stored securely without divulging the specifics of the mechanism employed for either encryption or storage.
Access Management Without disclosing any private data, ZKPs can be used to offer safe access control to Kubernetes resources. ZKPs can be used, for instance, to demonstrate that a user has the necessary permissions to access a particular Kubernetes resource without disclosing the details of those permissions.
Safe Data Exchange Without disclosing any sensitive information, ZKPs can be used to securely transmit data between Kubernetes clusters or between several businesses. ZKPs, for instance, can be used to demonstrate the sharing of a specific piece of data between two parties without disclosing the details of the data itself.
Kubernetes deployments audited Without disclosing the specifics of the deployment or the data being processed, ZKPs can be used to demonstrate that Kubernetes deployments are working as planned. This can be helpful for auditing purposes and for ensuring that Kubernetes deployments are operating as planned.
ZKPs preserve data and maintain regulatory compliance by letting parties prove things without revealing sensitive information. ZKPs will be used more in Kubernetes as it grows.
You might also like

Alana Rister, Ph.D.
3 years ago
Don't rely on lessons you learned with a small audience.
My growth-killing mistake

When you initially start developing your audience, you need guidance.
What does my audience like? What do they not like? How can I grow more?
When I started writing two years ago, I inquired daily. Taking cues from your audience to develop more valuable content is a good concept, but it's simple to let them destroy your growth.
A small audience doesn't represent the full picture.
When I had fewer than 100 YouTube subscribers, I tried several video styles and topics. I looked to my audience for what to preserve and what to change.
If my views, click-through rate, or average view % dropped, that topic or style was awful. Avoiding that style helped me grow.
Vlogs, talking head videos on writing, and long-form tutorials didn't fare well.
Since I was small, I've limited the types of films I make. I have decided to make my own videos.
Surprisingly, the videos I avoided making meet or exceed my views, CTR, and audience retention.
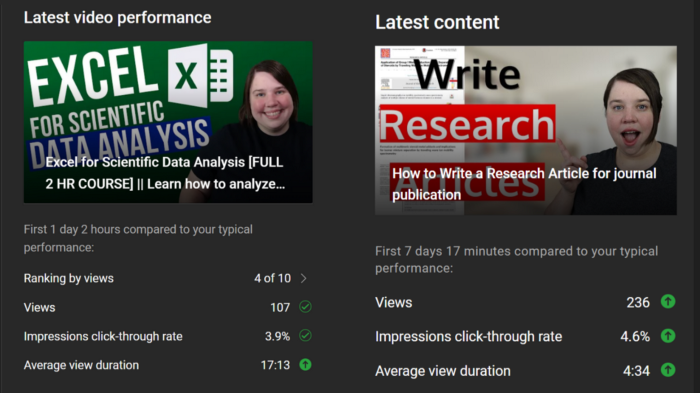
A limited audience can't tell you what your tribe wants. Therefore, limiting your innovation will prohibit you from reaching the right audience. Finding them may take longer.
Large Creators Experience The Same Issue
In the last two years, I've heard Vanessa Lau and Cathrin Manning say they felt pigeonholed into generating videos they didn't want to do.
Why does this happen over and over again?
Once you have a popular piece of content, your audience will grow. So when you publish inconsistent material, fewer of your new audience will view it. You interpret the drop in views as a sign that your audience doesn't want the content, so you stop making it.
Repeat this procedure a few times, and you'll create stuff you're not passionate about because you're frightened to publish it.
How to Manage Your Creativity and Audience Development
I'm not recommending you generate random content.
Instead of feeling trapped by your audience, you can cultivate a diverse audience.
Create quality material on a range of topics and styles as you improve. Be creative until you get 100 followers. Look for comments on how to improve your article.
If you observe trends in the types of content that expand your audience, focus 50-75% of your material on those trends. Allow yourself to develop 25% non-performing material.
This method can help you expand your audience faster with your primary trends and like all your stuff. Slowly, people will find 25% of your material, which will boost its performance.
How to Expand Your Audience Without Having More Limited Content
Follow these techniques to build your audience without feeling confined.
Don't think that you need restrict yourself to what your limited audience prefers.
Don't let the poor performance of your desired material demotivate you.
You shouldn't restrict the type of content you publish or the themes you cover when you have less than 100 followers.
When your audience expands, save 25% of your content for your personal interests, regardless of how well it does.

Katherine Kornei
3 years ago
The InSight lander from NASA has recorded the greatest tremor ever felt on Mars.
The magnitude 5 earthquake was responsible for the discharge of energy that was 10 times greater than the previous record holder.
Any Martians who happen to be reading this should quickly learn how to duck and cover.
NASA's Jet Propulsion Laboratory in Pasadena, California, reported that on May 4, the planet Mars was shaken by an earthquake of around magnitude 5, making it the greatest Marsquake ever detected to this point. The shaking persisted for more than six hours and unleashed more than ten times as much energy as the earthquake that had previously held the record for strongest.
The event was captured on record by the InSight lander, which is operated by the United States Space Agency and has been researching the innards of Mars ever since it touched down on the planet in 2018 (SN: 11/26/18). The epicenter of the earthquake was probably located in the vicinity of Cerberus Fossae, which is located more than 1,000 kilometers away from the lander.
The surface of Cerberus Fossae is notorious for being broken up and experiencing periodic rockfalls. According to geophysicist Philippe Lognonné, who is the lead investigator of the Seismic Experiment for Interior Structure, the seismometer that is onboard the InSight lander, it is reasonable to assume that the ground is moving in that area. "This is an old crater from a volcanic eruption."
Marsquakes, which are similar to earthquakes in that they give information about the interior structure of our planet, can be utilized to investigate what lies beneath the surface of Mars (SN: 7/22/21). And according to Lognonné, who works at the Institut de Physique du Globe in Paris, there is a great deal that can be gleaned from analyzing this massive earthquake. Because the quality of the signal is so high, we will be able to focus on the specifics.

Sofien Kaabar, CFA
3 years ago
How to Make a Trading Heatmap
Python Heatmap Technical Indicator

Heatmaps provide an instant overview. They can be used with correlations or to predict reactions or confirm the trend in trading. This article covers RSI heatmap creation.
The Market System
Market regime:
Bullish trend: The market tends to make higher highs, which indicates that the overall trend is upward.
Sideways: The market tends to fluctuate while staying within predetermined zones.
Bearish trend: The market has the propensity to make lower lows, indicating that the overall trend is downward.
Most tools detect the trend, but we cannot predict the next state. The best way to solve this problem is to assume the current state will continue and trade any reactions, preferably in the trend.
If the EURUSD is above its moving average and making higher highs, a trend-following strategy would be to wait for dips before buying and assuming the bullish trend will continue.
Indicator of Relative Strength
J. Welles Wilder Jr. introduced the RSI, a popular and versatile technical indicator. Used as a contrarian indicator to exploit extreme reactions. Calculating the default RSI usually involves these steps:
Determine the difference between the closing prices from the prior ones.
Distinguish between the positive and negative net changes.
Create a smoothed moving average for both the absolute values of the positive net changes and the negative net changes.
Take the difference between the smoothed positive and negative changes. The Relative Strength RS will be the name we use to describe this calculation.
To obtain the RSI, use the normalization formula shown below for each time step.
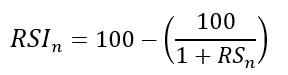
The 13-period RSI and black GBPUSD hourly values are shown above. RSI bounces near 25 and pauses around 75. Python requires a four-column OHLC array for RSI coding.
import numpy as np
def add_column(data, times):
for i in range(1, times + 1):
new = np.zeros((len(data), 1), dtype = float)
data = np.append(data, new, axis = 1)
return data
def delete_column(data, index, times):
for i in range(1, times + 1):
data = np.delete(data, index, axis = 1)
return data
def delete_row(data, number):
data = data[number:, ]
return data
def ma(data, lookback, close, position):
data = add_column(data, 1)
for i in range(len(data)):
try:
data[i, position] = (data[i - lookback + 1:i + 1, close].mean())
except IndexError:
pass
data = delete_row(data, lookback)
return data
def smoothed_ma(data, alpha, lookback, close, position):
lookback = (2 * lookback) - 1
alpha = alpha / (lookback + 1.0)
beta = 1 - alpha
data = ma(data, lookback, close, position)
data[lookback + 1, position] = (data[lookback + 1, close] * alpha) + (data[lookback, position] * beta)
for i in range(lookback + 2, len(data)):
try:
data[i, position] = (data[i, close] * alpha) + (data[i - 1, position] * beta)
except IndexError:
pass
return data
def rsi(data, lookback, close, position):
data = add_column(data, 5)
for i in range(len(data)):
data[i, position] = data[i, close] - data[i - 1, close]
for i in range(len(data)):
if data[i, position] > 0:
data[i, position + 1] = data[i, position]
elif data[i, position] < 0:
data[i, position + 2] = abs(data[i, position])
data = smoothed_ma(data, 2, lookback, position + 1, position + 3)
data = smoothed_ma(data, 2, lookback, position + 2, position + 4)
data[:, position + 5] = data[:, position + 3] / data[:, position + 4]
data[:, position + 6] = (100 - (100 / (1 + data[:, position + 5])))
data = delete_column(data, position, 6)
data = delete_row(data, lookback)
return dataMake sure to focus on the concepts and not the code. You can find the codes of most of my strategies in my books. The most important thing is to comprehend the techniques and strategies.
My weekly market sentiment report uses complex and simple models to understand the current positioning and predict the future direction of several major markets. Check out the report here:
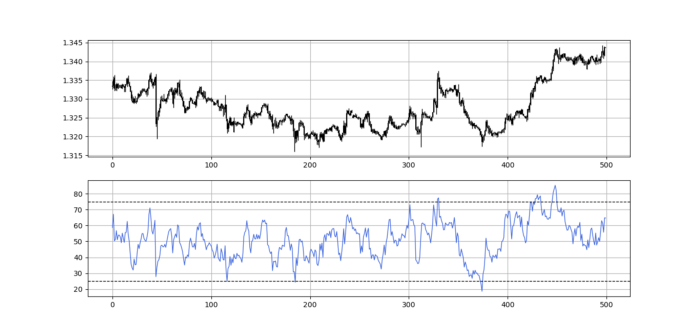
Using the Heatmap to Find the Trend
RSI trend detection is easy but useless. Bullish and bearish regimes are in effect when the RSI is above or below 50, respectively. Tracing a vertical colored line creates the conditions below. How:
When the RSI is higher than 50, a green vertical line is drawn.
When the RSI is lower than 50, a red vertical line is drawn.
Zooming out yields a basic heatmap, as shown below.
Plot code:
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
if sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)
Call RSI on your OHLC array's fifth column. 4. Adjusting lookback parameters reduces lag and false signals. Other indicators and conditions are possible.
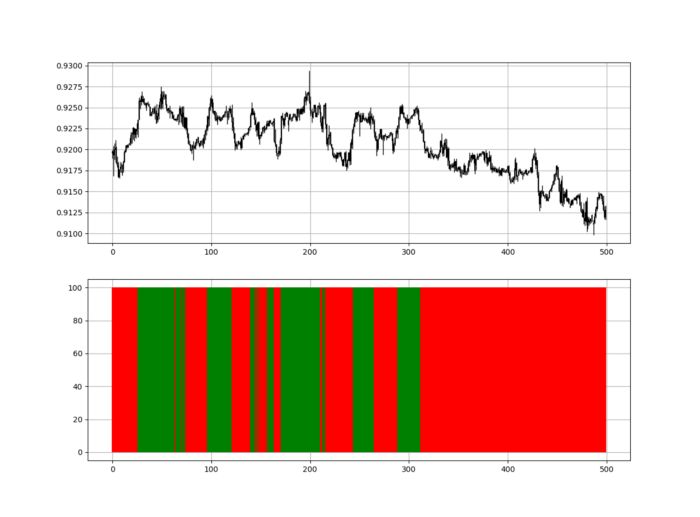
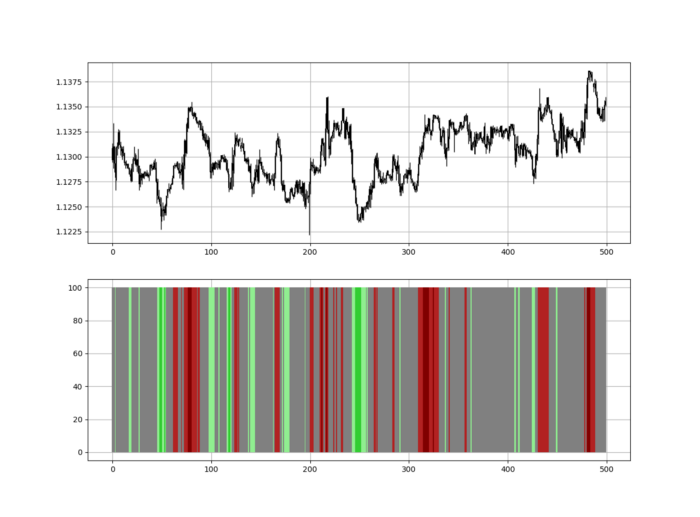
Another suggestion is to develop an RSI Heatmap for Extreme Conditions.
Contrarian indicator RSI. The following rules apply:
Whenever the RSI is approaching the upper values, the color approaches red.
The color tends toward green whenever the RSI is getting close to the lower values.
Zooming out yields a basic heatmap, as shown below.
Plot code:
import matplotlib.pyplot as plt
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
if sample[i, second_panel] > 80 and sample[i, second_panel] < 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'darkred', linewidth = 1.5)
if sample[i, second_panel] > 70 and sample[i, second_panel] < 80:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'maroon', linewidth = 1.5)
if sample[i, second_panel] > 60 and sample[i, second_panel] < 70:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'firebrick', linewidth = 1.5)
if sample[i, second_panel] > 50 and sample[i, second_panel] < 60:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 40 and sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 30 and sample[i, second_panel] < 40:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'lightgreen', linewidth = 1.5)
if sample[i, second_panel] > 20 and sample[i, second_panel] < 30:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'limegreen', linewidth = 1.5)
if sample[i, second_panel] > 10 and sample[i, second_panel] < 20:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'seagreen', linewidth = 1.5)
if sample[i, second_panel] > 0 and sample[i, second_panel] < 10:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)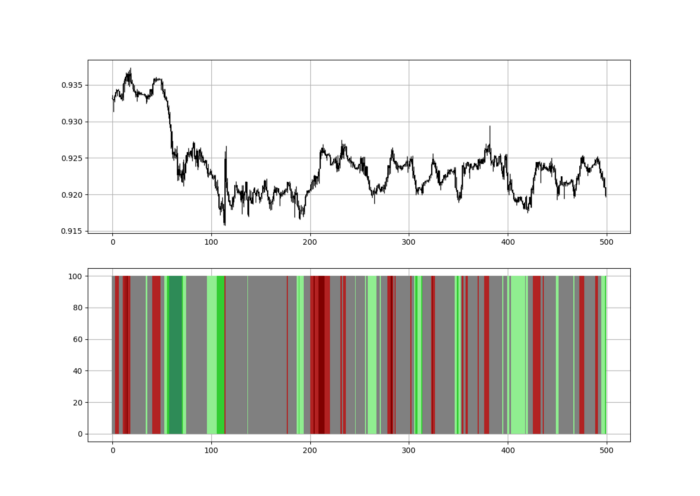
Dark green and red areas indicate imminent bullish and bearish reactions, respectively. RSI around 50 is grey.
Summary
To conclude, my goal is to contribute to objective technical analysis, which promotes more transparent methods and strategies that must be back-tested before implementation.
Technical analysis will lose its reputation as subjective and unscientific.
When you find a trading strategy or technique, follow these steps:
Put emotions aside and adopt a critical mindset.
Test it in the past under conditions and simulations taken from real life.
Try optimizing it and performing a forward test if you find any potential.
Transaction costs and any slippage simulation should always be included in your tests.
Risk management and position sizing should always be considered in your tests.
After checking the above, monitor the strategy because market dynamics may change and make it unprofitable.