

More on Technology

caroline sinders
3 years ago
Holographic concerts are the AI of the Future.

A few days ago, I was discussing dall-e with two art and tech pals. One artist acquaintance said she knew a frightened illustrator. Would the ability to create anything with a click derail her career? The artist feared this. My curator friend smiled and said this has always been a dread among artists. When the camera was invented, didn't painters say this? Even in the Instagram era, painting exists.
When art and technology collide, there's room for innovation, experimentation, and fear — especially if the technology replicates or replaces art making. What is art's future with dall-e? How does technology affect music, beyond visual art? Recently, I saw "ABBA Voyage," a holographic ABBA concert in London.
"Abba voyage?" my phone asked in early March. A Gen X friend I met through a fashion blogging ring texted me.
"What's abba Voyage?" I asked while opening my front door with keys and coffee.
We're going! Marti, visiting London, took me to a show.
"Absolutely no ABBA songs here." I responded.
My parents didn't play ABBA much, so I don't know much about them. Dad liked Jimi Hendrix, Cream, Deep Purple, and New Orleans jazz. Marti told me ABBA Voyage was a holographic ABBA show with a live band.
The show was fun, extraordinary fun. Nearly everyone on the dance floor wore wigs, ankle-breaking platforms, sequins, and bellbottoms. I saw some millennials and Zoomers among the boomers.
I was intoxicated by the experience.
Automatons date back to the 18th-century mechanical turk. The mechanical turk was a chess automaton operated by a person. The mechanical turk seemed to perform like a human without human intervention, but it required a human in the loop to work properly.
Humans have used non-humans in entertainment for centuries, such as puppets, shadow play, and smoke and mirrors. A show can have animatronic, technological, and non-technological elements, and a live show can blur real and illusion. From medieval puppet shows to mechanical turks to AI filters, bots, and holograms, entertainment has evolved over time.
I'm not a hologram skeptic, but I'm skeptical of technology, especially since I work with it. I love live performances, I love hearing singers breathe, forget lines, and make jokes. Live shows are my favorite because I love watching performers make mistakes or interact with the audience. ABBA Voyage was different.
Marti and I traveled to Manchester after ABBA Voyage to see Liam Gallagher. Similar but different vibe. Similar in that thousands dressed up for the show. ABBA's energy was dizzying. 90s chic replaced sequins in the crowd. Doc Martens, nylon jackets, bucket hats, shaggy hair. The Charlatans and Liam Gallagher opened and closed, respectively. Fireworks. Incredible. People went crazy. Yelling exhausted my voice.
This week in music featured AI-enabled holograms and a decades-old rocker. Both are warm and gooey in our memories.
After seeing both, I'm wondering if we need AI hologram shows. Why? Is it good?
Like everything tech-related, my answer is "maybe." Because context and performance matter. Liam Gallagher and ABBA both had great, different shows.
For a hologram to work, it must be impossible and big. It must be big, showy, and improbable to justify a hologram. It must feel...expensive, like a stadium pop show. According to a quick search, ABBA broke up on bad terms. Reuniting is unlikely. This is also why Prince or Tupac hologram shows work. We can only engage with their legacy through covers or...holograms.
I drove around listening to the radio a few weeks ago. "Dreaming of You" by Selena played. Selena's music defined my childhood. I sang along and turned up the volume (or as loud as my husband would allow me while driving on the highway).
I discovered Selena's music six months after her death, so I never saw her perform live. My babysitter Melissa played me her album after I moved to Houston. Melissa took me to see the Selena movie five times when it came out. I quickly wore out my VHS copy. I constantly sang "Bibi Bibi Bom Bom" and "Como la Flor." I love Selena. A Selena hologram? Yes, probably.
Instagram advertised a cellist's Arthur Russell tribute show. Russell is another deceased artist I love. I almost walked down the aisle to "This is How We Walk on the Moon," but our cellist couldn't find it. Instead, I walked to Magnetic Fields' "The Book of Love." I "discovered" Russell after a friend introduced me to his music a few years ago.
I use these as analogies for the Liam Gallagher and ABBA concerts.
You have no idea how much I'd pay to see a hologram of Selena's 1995 Houston Livestock Show and Rodeo concert. Arthur Russell's hologram is unnecessary. Russell's work was intimate and performance-based. We can't separate his life from his legacy; popular audiences overlooked his genius. He died of AIDS broke. Like Selena, he died prematurely. Given his music and history, another performer would be a better choice than a hologram. He's no Selena. Selena could have rivaled Beyonce.
Pop shows' size works for holograms. Along with ABBA holograms, there was an anime movie and a light show that would put Tron to shame. ABBA created a tourable stadium show. The event was lavish, expensive, and well-planned. Pop, unlike rock, isn't gritty. Liam Gallagher hologram? No longer impossible, it wouldn't work. He's touring. I'm not sure if a rockstar alone should be rendered as a hologram; it was the show that made ABBA a hologram.
Holograms, like AI, are part of the future of entertainment, but not all of it. Because only modern interpretations of Arthur Russell's work reveal his legacy. That's his legacy.

Large-scale arena performers may use holograms in the future, but the experience must be impossible. A teacher once said that the only way to convey emotion in opera is through song, and I feel the same way about holograms, AR, VR, and mixed reality. A story's impossibility must make sense, like in opera. Impossibility and bombastic performance must be present for an immersive element to "work." ABBA was an impossible and improbable experience, which made it magical. It helped the holographic show work.
Marti told me about ABBA Voyage. She said it was a great concert. Marti has worked in music since the 1990s. She's a music expert; she's seen many shows.
Ai isn't a god or sentient, and the ABBA holograms aren't real. The renderings were glassy-eyed, flat, and robotic, like the Polar Express or the Jaws shark. Even today, the uncanny valley is insurmountable. We know it's not real because it's not about reality. It was about a suspended moment and performance feelings.
I knew this was impossible, an 'unreal' experience, but the emotions I felt were real, like watching a movie or tv show. Perhaps this is one of the better uses of AI, like CGI and special effects, like the beauty of entertainment- we were enraptured and entertained for hours. I've been playing ABBA since then.

Nikhil Vemu
3 years ago
7 Mac Tips You Never Knew You Needed
Unleash the power of the Option key ⌥

#1 Open a link in the Private tab first.
Previously, if I needed to open a Safari link in a private window, I would:
copied the URL with the right click command,
choose File > New Private Window to open a private window, and
clicked return after pasting the URL.
I've found a more straightforward way.
Right-clicking a link shows this, right?
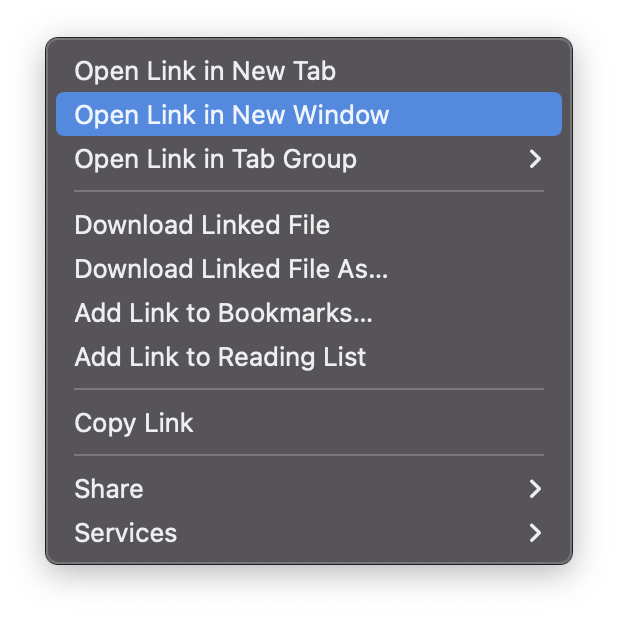
Hold option (⌥) for:
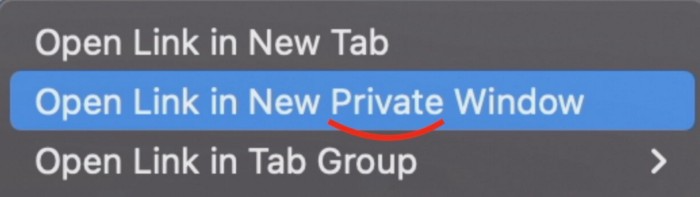
Click Open Link in New Private Window while holding.
Finished!
#2. Instead of searching for specific characters, try this
You may use unicode for business or school. Most people Google them when they need them.
That is lengthy!
You can type some special characters just by pressing ⌥ and a key.
For instance
• ⌥+2 -> ™ (Trademark)
• ⌥+0 -> ° (Degree)
• ⌥+G -> © (Copyright)
• ⌥+= -> ≠ (Not equal to)
• ⌥+< -> ≤ (Less than or equal to)
• ⌥+> -> ≥ (Greater then or equal to)
• ⌥+/ -> ÷ (Different symbol for division)#3 Activate Do Not Disturb silently.
Do Not Disturb when sharing my screen is awkward for me (because people may think Im trying to hide some secret notifications).
Here's another method.
Hold ⌥ and click on Time (at the extreme right on the menu-bar).

Now, DND is activated (secretly!). To turn it off, do it again.
Note: This works only for DND focus.#4. Resize a window starting from its center
Although this is rarely useful, it is still a hidden trick.
When you resize a window, the opposite edge or corner is used as the pivot, right?
However, if you want to resize it with its center as the pivot, hold while doing so.
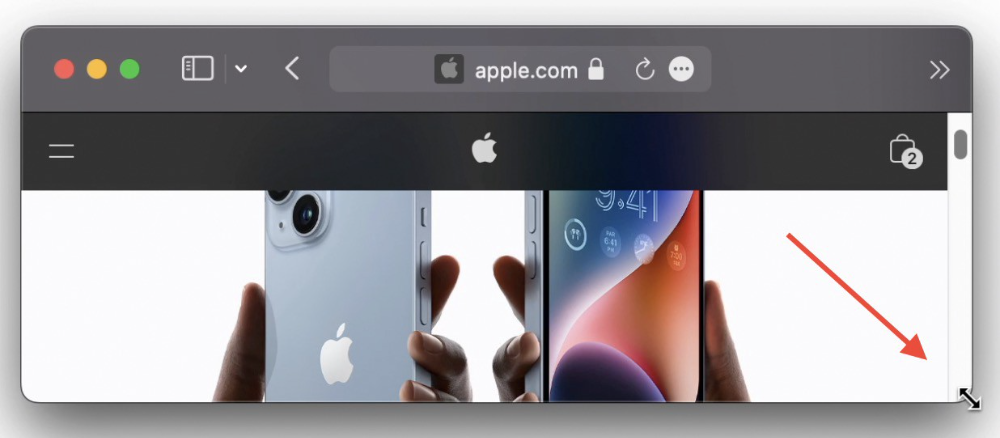
#5. Yes, Cut-Paste is available on Macs as well (though it is slightly different).
I call it copy-move rather than cut-paste. This is how it works.
Carry it out.
Choose a file (by clicking on it), then copy it (⌘+C).
Go to a new location on your Mac. Do you use ⌘+V to paste it? However, to move it, press ⌘+⌥+V.
This removes the file from its original location and copies it here. And it works exactly like cut-and-paste on Windows.
#6. Instantly expand all folders
Set your Mac's folders to List view.
Assume you have one folder with multiple subfolders, each of which contains multiple files. And you wanted to look at every single file that was over there.
How would you do?
You're used to clicking the ⌄ glyph near the folder and each subfolder to expand them all, right? Instead, hold down ⌥ while clicking ⌄ on the parent folder.
This is what happens next.
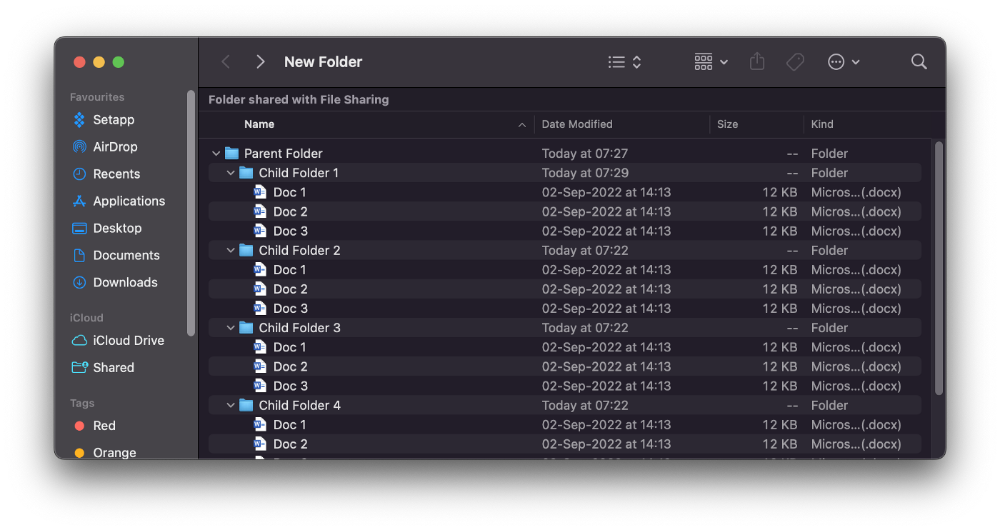
Everything expands.
View/Copy a file's path as an added bonus
If you want to see the path of a file in Finder, select it and hold ⌥, and you'll see it at the bottom for a moment.
To copy its path, right-click on the folder and hold down ⌥ to see this
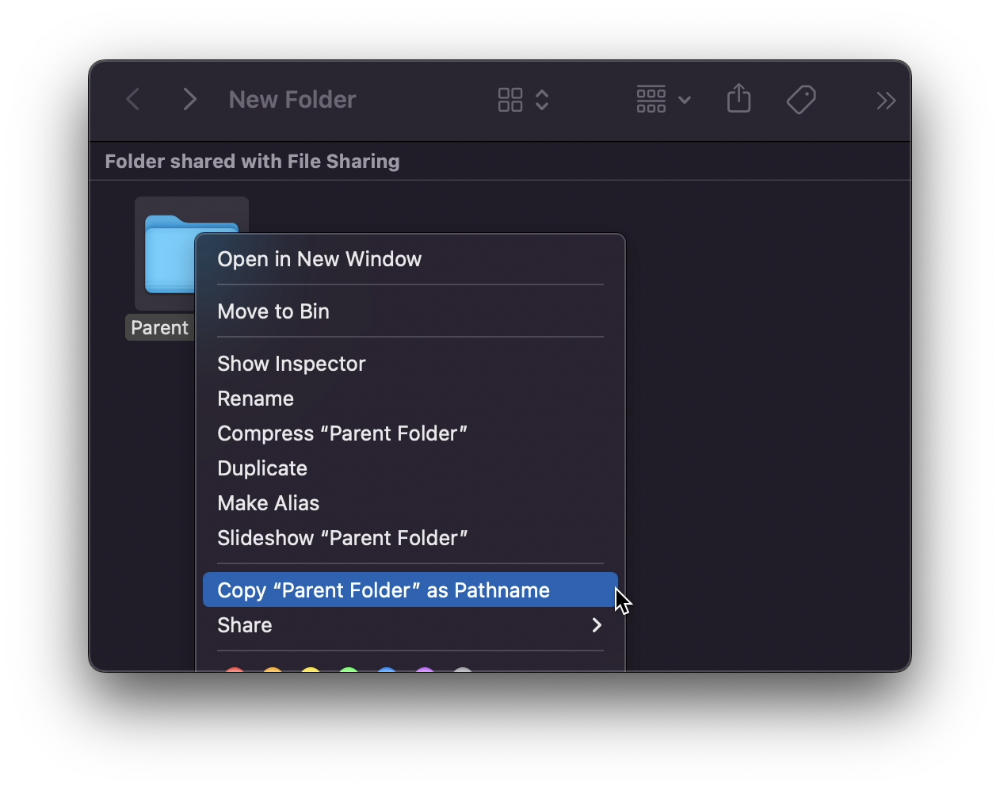
Click on Copy <"folder name"> as Pathname to do it.
#7 "Save As"
I was irritated by the lack of "Save As" in Pages when I first got a Mac (after 15 years of being a Windows guy).
It was necessary for me to save the file as a new file, in a different location, with a different name, or both.
Unfortunately, I couldn't do it on a Mac.
However, I recently discovered that it appears when you hold ⌥ when in the File menu.
Yay!

Ben "The Hosk" Hosking
3 years ago
The Yellow Cat Test Is Typically Failed by Software Developers.
Believe what you see, what people say

It’s sad that we never get trained to leave assumptions behind. - Sebastian Thrun
Many problems in software development are not because of code but because developers create the wrong software. This isn't rare because software is emergent and most individuals only realize what they want after it's built.
Inquisitive developers who pass the yellow cat test can improve the process.
Carpenters measure twice and cut the wood once. Developers are rarely so careful.
The Yellow Cat Test
Game of Thrones made dragons cool again, so I am reading The Game of Thrones book.
The yellow cat exam is from Syrio Forel, Arya Stark's fencing instructor.
Syrio tells Arya he'll strike left when fencing. He hits her after she dodges left. Arya says “you lied”. Syrio says his words lied, but his eyes and arm told the truth.
Arya learns how Syrio became Bravos' first sword.
“On the day I am speaking of, the first sword was newly dead, and the Sealord sent for me. Many bravos had come to him, and as many had been sent away, none could say why. When I came into his presence, he was seated, and in his lap was a fat yellow cat. He told me that one of his captains had brought the beast to him, from an island beyond the sunrise. ‘Have you ever seen her like?’ he asked of me.
“And to him I said, ‘Each night in the alleys of Braavos I see a thousand like him,’ and the Sealord laughed, and that day I was named the first sword.”
Arya screwed up her face. “I don’t understand.”
Syrio clicked his teeth together. “The cat was an ordinary cat, no more. The others expected a fabulous beast, so that is what they saw. How large it was, they said. It was no larger than any other cat, only fat from indolence, for the Sealord fed it from his own table. What curious small ears, they said. Its ears had been chewed away in kitten fights. And it was plainly a tomcat, yet the Sealord said ‘her,’ and that is what the others saw. Are you hearing?” Reddit discussion.
Development teams should not believe what they are told.
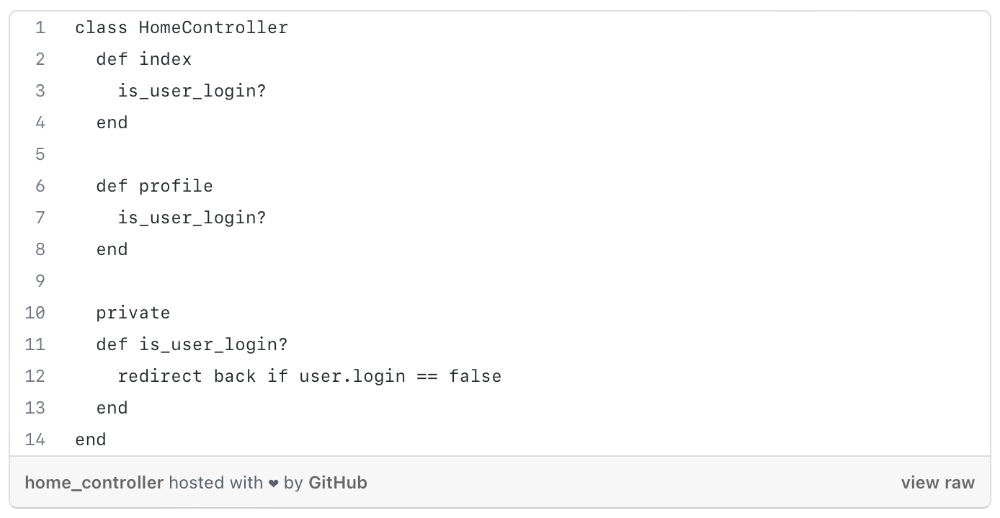
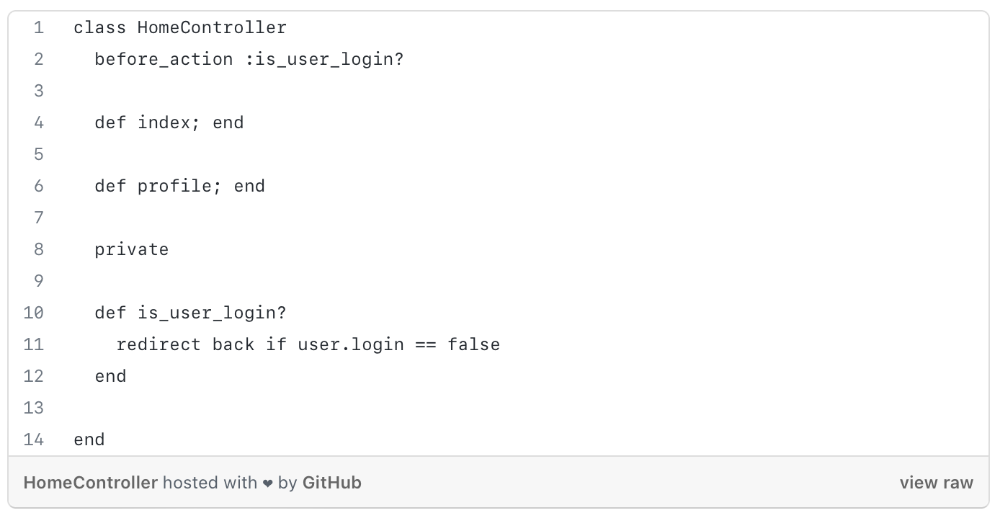
We created an appointment booking system. We thought it was an appointment-booking system. Later, we realized the software's purpose was to book the right people for appointments and discourage the unneeded ones.
The first 3 months of the project had half-correct requirements and software understanding.
Open your eyes
“Open your eyes is all that is needed. The heart lies and the head plays tricks with us, but the eyes see true. Look with your eyes, hear with your ears. Taste with your mouth. Smell with your nose. Feel with your skin. Then comes the thinking afterwards, and in that way, knowing the truth” Syrio Ferel
We must see what exists, not what individuals tell the development team or how developers think the software should work. Initial criteria cover 50/70% and change.
Developers build assumptions problems by assuming how software should work. Developers must quickly explain assumptions.
When a development team's assumptions are inaccurate, they must alter the code, DevOps, documentation, and tests.
It’s always faster and easier to fix requirements before code is written.
First-draft requirements can be based on old software. Development teams must grasp corporate goals and consider needs from many angles.
Testers help rethink requirements. They look at how software requirements shouldn't operate.
Technical features and benefits might misdirect software projects.
The initiatives that focused on technological possibilities developed hard-to-use software that needed extensive rewriting following user testing.
Software development
High-level criteria are different from detailed ones.
The interpretation of words determines their meaning.
Presentations are lofty, upbeat, and prejudiced.
People's perceptions may be unclear, incorrect, or just based on one perspective (half the story)
Developers can be misled by requirements, circumstances, people, plans, diagrams, designs, documentation, and many other things.
Developers receive misinformation, misunderstandings, and wrong assumptions. The development team must avoid building software with erroneous specifications.
Once code and software are written, the development team changes and fixes them.
Developers create software with incomplete information, they need to fill in the blanks to create the complete picture.
Conclusion
Yellow cats are often inaccurate when communicating requirements.
Before writing code, clarify requirements, assumptions, etc.
Everyone will pressure the development team to generate code rapidly, but this will slow down development.
Code changes are harder than requirements.
You might also like
Tom Connor
3 years ago
12 mental models that I use frequently
https://tomconnor.me/wp-content/uploads/2021/08/10x-Engineer-Mental-Models.pdf
I keep returning to the same mental models and tricks after writing and reading about a wide range of topics.
Top 12 mental models
12.
Survival bias - We perceive the surviving population as remarkable, yet they may have gotten there through sheer grit.
Survivorship bias affects us in many situations. Our retirement fund; the unicorn business; the winning team. We often study and imitate the last one standing. This can lead to genuine insights and performance improvements, but it can also lead us astray because the leader may just be lucky.
11.
The Helsinki Bus Theory - How to persevere Buss up!
Always display new work, and always be compared to others. Why? Easy. Keep riding. Stay on the fucking bus.
10.
Until it sticks… Turning up every day… — Artists teach engineers plenty. Quality work over a career comes from showing up every day and starting.
9.
WRAP decision making process (Heath Brothers)
Decision-making WRAP Model:
W — Widen your Options
R — Reality test your assumptions
A — Attain Distance
P — Prepare to be wrong or Right
8.
Systems for knowledge worker excellence - Todd Henry and Cal Newport write about techniques knowledge workers can employ to build a creative rhythm and do better work.
Todd Henry's FRESH framework:
Focus: Keep the start in mind as you wrap up.
Relationships: close a loop that's open.
Pruning is an energy.
Set aside time to be inspired by stimuli.
Hours: Spend time thinking.
7.
BBT is learning from mistakes. Science has transformed the world because it constantly updates its theories in light of failures. Complexity guarantees failure. Do we learn or self-justify?
6.
The OODA Loop - Competitive advantage
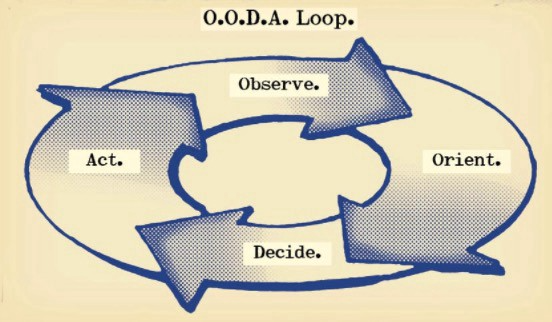
O: Observe: collect the data. Figure out exactly where you are, what’s happening.
O: Orient: analyze/synthesize the data to form an accurate picture.
D: Decide: select an action from possible options
A: Action: execute the action, and return to step (1)
Boyd's approach indicates that speed and agility are about information processing, not physical reactions. They form feedback loops. More OODA loops improve speed.
5.
Leaders who try to impose order in a complex situation fail; those who set the stage, step back, and allow patterns to develop win.
https://vimeo.com/640941172?embedded=true&source=vimeo_logo&owner=11999906
4.
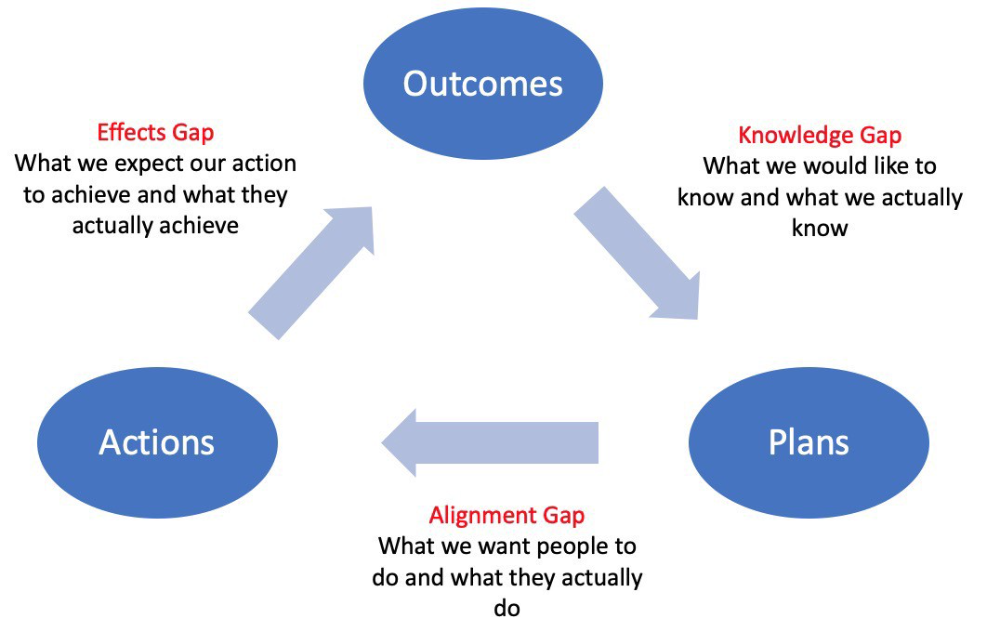
Information Gap - The discrepancy between what we know and what we would like to know
Gap in Alignment - What individuals actually do as opposed to what we wish them to do
Effects Gap - the discrepancy between our expectations and the results of our actions
3.
Theory of Constraints — The Goal - To maximize system production, maximize bottleneck throughput.
Goldratt creates a five-step procedure:
Determine the restriction
Improve the restriction.
Everything else should be based on the limitation.
Increase the restriction
Go back to step 1 Avoid letting inertia become a limitation.
Any non-constraint improvement is an illusion.
2.
Serendipity and the Adjacent Possible - Why do several amazing ideas emerge at once? How can you foster serendipity in your work?
You need specialized abilities to reach to the edge of possibilities, where you can pursue exciting tasks that will change the world. Few people do it since it takes a lot of hard work. You'll stand out if you do.
Most people simply lack the comfort with discomfort required to tackle really hard things. At some point, in other words, there’s no way getting around the necessity to clear your calendar, shut down your phone, and spend several hard days trying to make sense of the damn proof.
1.
Boundaries of failure - Rasmussen's accident model.

Rasmussen modeled this. It has economic, workload, and performance boundaries.
The economic boundary is a company's profit zone. If the lights are on, you're within the economic boundaries, but there's pressure to cut costs and do more.
Performance limit reflects system capacity. Taking shortcuts is a human desire to minimize work. This is often necessary to survive because there's always more labor.
Both push operating points toward acceptable performance. Personal or process safety, or equipment performance.
If you exceed acceptable performance, you'll push back, typically forcefully.

Maria Urkedal York
3 years ago
When at work, don't give up; instead, think like a designer.
How to reframe irritation and go forward

“… before you can figure out where you are going, you need to know where you are, and once you know and accept where you are, you can design your way to where you want to be.” — Bill Burnett and Dave Evans
“You’ve been here before. But there are some new ingredients this time. What can tell yourself that will make you understand that now isn’t just like last year? That there’s something new in this August.”
My coach paused. I sighed, inhaled deeply, and considered her question.
What could I say? I simply needed a plan from her so everything would fall into place and I could be the happy, successful person I want to be.
Time passed. My mind was exhausted from running all morning, all summer, or the last five years, searching for what to do next and how to get there.
Calmer, I remembered that my coach's inquiry had benefited me throughout the summer. The month before our call, I read Designing Your Work Life — How to Thrive and Change and Find Happiness at Work from Standford University’s Bill Burnett and Dave Evans.
A passage in their book felt like a lifeline: “We have something important to say to you: Wherever you are in your work life, whatever job you are doing, it’s good enough. For now. Not forever. For now.”
As I remembered this book on the coaching call, I wondered if I could embrace where I am in August and say my job life is good enough for now. Only temporarily.
I've done that since. I'm getting unstuck.
Here's how you can take the first step in any area where you feel stuck.
How to acquire the perspective of "Good enough for now" for yourself
We’ve all heard the advice to just make the best of a bad situation. That´s not bad advice, but if you only make the best of a bad situation, you are still in a bad situation. It doesn’t get to the root of the problem or offer an opportunity to change the situation. You’re more cheerfully navigating lousiness, which is an improvement, but not much of one and rather hard to sustain over time.” — Bill Burnett and Dave Evans
Reframing Burnett at Evans says good enough for now is the key to being happier at work. Because, as they write, a designer always has options.
Choosing to believe things are good enough for now is liberating. It helps us feel less victimized and less judged. Accepting our situation helps us become unstuck.
Let's break down the process, which designers call constructing your way ahead, into steps you can take today.
Writing helps get started. First, write down your challenge and why it's essential to you. If pen and paper help, try this strategy:
Make the decision to accept the circumstance as it is. Designers always begin by acknowledging the truth of the situation. You now refrain from passing judgment. Instead, you simply describe the situation as accurately as you can. This frees us from negative thought patterns that prevent us from seeing the big picture and instead keep us in a tunnel of negativity.
Look for a reframing right now. Begin with good enough for the moment. Take note of how your body feels as a result. Tell yourself repeatedly that whatever is occurring is sufficient for the time being. Not always, but just now. If you want to, you can even put it in writing and repeatedly breathe it in, almost like a mantra.
You can select a reframe that is more relevant to your situation once you've decided that you're good enough for now and have allowed yourself to believe it. Try to find another perspective that is possible, for instance, if you feel unappreciated at work and your perspective of I need to use and be recognized for all my new skills in my job is making you sad and making you want to resign. For instance, I can learn from others at work and occasionally put my new abilities to use.
After that, leave your mind and act in accordance with your new perspective. Utilize the designer's bias for action to test something out and create a prototype that you can learn from. Your beginning point for creating experiences that will support the new viewpoint derived from the aforementioned point is the new perspective itself. By doing this, you recognize a circumstance at work where you can provide value to yourself or your workplace and then take appropriate action. Send two or three coworkers from whom you wish to learn anything an email, for instance, asking them to get together for coffee or a talk.
Choose tiny, doable actions. You prioritize them at work.
Let's assume you're feeling disconnected at work, so you make a list of folks you may visit each morning or invite to lunch. If you're feeling unmotivated and tired, take a daily walk and treat yourself to a decent coffee.
This may be plenty for now. If you want to take this procedure further, use Burnett and Evans' internet tools and frameworks.
Developing the daily practice of reframing
“We’re not discontented kids in the backseat of the family minivan, but how many of us live our lives, especially our work lives, as if we are?” — Bill Burnett and Dave Evans
I choose the good enough for me perspective every day, often. No quick fix. Am a failing? Maybe a little bit, but I like to think of it more as building muscle.
This way, every time I tell myself it's ok, I hear you. For now, that muscle gets stronger.
Hopefully, reframing will become so natural for us that it will become a habit, and not a technique anymore.
If you feel like you’re stuck in your career or at work, the reframe of Good enough, for now, might be valuable, so just go ahead and try it out right now.
And while you’re playing with this, why not think of other areas of your life too, like your relationships, where you live — even your writing, and see if you can feel a shift?

Erik Engheim
4 years ago
You Misunderstand the Russian Nuclear Threat
Many believe Putin is simply sabre rattling and intimidating us. They see no threat of nuclear war. We can send NATO troops into Ukraine without risking a nuclear war.
I keep reading that Putin is just using nuclear blackmail and that a strong leader will call the bluff. That, in my opinion, misunderstands the danger of sending NATO into Ukraine.
It assumes that once NATO moves in, Putin can either push the red nuclear button or not.
Sure, Putin won't go nuclear if NATO invades Ukraine. So we're safe? Can't we just move NATO?
No, because history has taught us that wars often escalate far beyond our initial expectations. One domino falls, knocking down another. That's why having clear boundaries is vital. Crossing a seemingly harmless line can set off a chain of events that are unstoppable once started.
One example is WWI. The assassin of Archduke Franz Ferdinand could not have known that his actions would kill millions. They couldn't have known that invading Serbia to punish them for not handing over the accomplices would start a world war. Every action triggered a counter-action, plunging Europe into a brutal and bloody war. Each leader saw their actions as limited, not realizing how they kept the dominos falling.
Nobody can predict the future, but it's easy to imagine how NATO intervention could trigger a chain of events leading to a total war. Let me suggest some outcomes.
NATO creates a no-fly-zone. In retaliation, Russia bombs NATO airfields. Russia may see this as a limited counter-move that shouldn't cause further NATO escalation. They think it's a reasonable response to force NATO out of Ukraine. Nobody has yet thought to use the nuke.
Will NATO act? Polish airfields bombed, will they be stuck? Is this an article 5 event? If so, what should be done?
It could happen. Maybe NATO sends troops into Ukraine to punish Russia. Maybe NATO will bomb Russian airfields.
Putin's response Is bombing Russian airfields an invasion or an attack? Remember that Russia has always used nuclear weapons for defense, not offense. But let's not panic, let's assume Russia doesn't go nuclear.
Maybe Russia retaliates by attacking NATO military bases with planes. Maybe they use ships to attack military targets. How does NATO respond? Will they fight Russia in Ukraine or escalate? Will they invade Russia or attack more military installations there?
Seen the pattern? As each nation responds, smaller limited military operations can grow in scope.
So far, the Russian military has shown that they begin with less brutal methods. As losses and failures increase, brutal means are used. Syria had the same. Assad used chemical weapons and attacked hospitals, schools, residential areas, etc.
A NATO invasion of Ukraine would cost Russia dearly. “Oh, this isn't looking so good, better pull out and finish this war,” do you think? No way. Desperate, they will resort to more brutal tactics. If desperate, Russia has a huge arsenal of ugly weapons. They have nerve agents, chemical weapons, and other nasty stuff.
What happens if Russia uses chemical weapons? What if Russian nerve agents kill NATO soldiers horribly? West calls for retaliation will grow. Will we invade Russia? Will we bomb them?
We are angry and determined to punish war criminal Putin, so NATO tanks may be heading to Moscow. We want vengeance for his chemical attacks and bombing of our cities.
Do you think the distance between that red nuclear button and Putin's finger will be that far once NATO tanks are on their way to Moscow?
We might avoid a nuclear apocalypse. A NATO invasion force or even Western cities may be used by Putin. Not as destructive as ICBMs. Putin may think we won't respond to tactical nukes with a full nuclear counterattack. Why would we risk a nuclear Holocaust by launching ICBMs on Russia?
Maybe. My point is that at every stage of the escalation, one party may underestimate the other's response. This war is spiraling out of control and the chances of a nuclear exchange are increasing. Nobody really wants it.
Fear, anger, and resentment cause it. If Putin and his inner circle decide their time is up, they may no longer care about the rest of the world. We saw it with Hitler. Hitler, seeing the end of his empire, ordered the destruction of Germany. Nobody should win if he couldn't. He wanted to destroy everything, including Paris.
In other words, the danger isn't what happens after NATO intervenes The danger is the potential chain reaction. Gambling has a psychological equivalent. It's best to exit when you've lost less. We humans are willing to take small risks for big rewards. To avoid losses, we are willing to take high risks. Daniel Kahneman describes this behavior in his book Thinking, Fast and Slow.
And so bettors who have lost a lot begin taking bigger risks to make up for it. We get a snowball effect. NATO involvement in the Ukraine conflict is akin to entering a casino and placing a bet. We'll start taking bigger risks as we start losing to Russian retaliation. That's the game's psychology.
It's impossible to stop. So will politicians and citizens from both Russia and the West, until we risk the end of human civilization.
You can avoid spiraling into ever larger bets in the Casino by drawing a hard line and declaring “I will not enter that Casino.” We're doing it now. We supply Ukraine. We send money and intelligence but don't cross that crucial line.
It's difficult to watch what happened in Bucha without demanding NATO involvement. What should we do? Of course, I'm not in charge. I'm a writer. My hope is that people will think about the consequences of the actions we demand. My hope is that you think ahead not just one step but multiple dominos.
More and more, we are driven by our emotions. We cannot act solely on emotion in matters of life and death. If we make the wrong choice, more people will die.
Read the original post here.