



More on Entrepreneurship

Sanjay Priyadarshi
3 months ago
A 19-year-old dropped out of college to build a $2,300,000,000 company in 2 years.
His success was unforeseeable.

2014 saw Facebook's $2.3 billion purchase of Oculus VR.
19-year-old Palmer Luckey founded Oculus. He quit journalism school. His parents worried about his college dropout.
Facebook bought Oculus VR in less than 2 years.
Palmer Luckey started Anduril Industries. Palmer has raised $385 million with Anduril.
The Oculus journey began in a trailer
Palmer Luckey, 19, owned the trailer.
Luckey had his trailer customized. The trailer had all six of Luckey's screens. In the trailer's remaining area, Luckey conducted hardware tests.
At 16, he became obsessed with virtual reality. Virtual reality was rare at the time.
Luckey didn't know about VR when he started.
Previously, he liked "portabilizing" mods. Hacking ancient game consoles into handhelds.
In his city, fewer portabilizers actively traded.
Luckey started "ModRetro" for other portabilizers. Luckey was exposed to VR headsets online.
Luckey:
“Man, ModRetro days were the best.”
Palmer Luckey used VR headsets for three years. His design had 50 prototypes.
Luckey used to work at the Long Beach Sailing Center for minimum salary, servicing diesel engines and cleaning boats.
Luckey worked in a USC Institute for Creative Technologies mixed reality lab in July 2011. (ICT).
Luckey cleaned the lab, did reports, and helped other students with VR projects.
Luckey's lab job was dull.
Luckey chose to work in the lab because he wanted to engage with like-minded folks.
By 2012, Luckey had a prototype he hoped to share globally. He made cheaper headsets than others.
Luckey wanted to sell an easy-to-assemble virtual reality kit on Kickstarter.
He realized he needed a corporation to do these sales legally. He started looking for names. "Virtuality," "virtual," and "VR" are all taken.
Hence, Oculus.
If Luckey sold a hundred prototypes, he would be thrilled since it would boost his future possibilities.
John Carmack, legendary game designer
Carmack has liked sci-fi and fantasy since infancy.
Carmack loved imagining intricate gaming worlds.
His interest in programming and computer science grew with age.
He liked graphics. He liked how mismatching 0 and 1 might create new colors and visuals.
Carmack played computer games as a teen. He created Shadowforge in high school.
He founded Id software in 1991. When Carmack created id software, console games were the best-sellers.
Old computer games have weak graphics. John Carmack and id software developed "adaptive tile refresh."
This technique smoothed PC game scrolling. id software launched 3-D, Quake, and Doom using "adaptive tile refresh."
These games made John Carmack a gaming star. Later, he sold Id software to ZeniMax Media.
How Palmer Luckey met Carmack
In 2011, Carmack was thinking a lot about 3-D space and virtual reality.
He was underwhelmed by the greatest HMD on the market. Because of their flimsiness and latency.
His disappointment was partly due to the view (FOV). Best HMD had 40-degree field of view.
Poor. The best VR headset is useless with a 40-degree FOV.
Carmack intended to show the press Doom 3 in VR. He explored VR headsets and internet groups for this reason.
Carmack identified a VR enthusiast in the comments section of "LEEP on the Cheap." "PalmerTech" was the name.
Carmack approached PalmerTech about his prototype. He told Luckey about his VR demos, so he wanted to see his prototype.
Carmack got a Rift prototype. Here's his May 17 tweet.
John Carmack tweeted an evaluation of the Luckey prototype.
Dan Newell, a Valve engineer, and Mick Hocking, a Sony senior director, pre-ordered Oculus Rift prototypes with Carmack's help.
Everyone praised Luckey after Carmack demoed Rift.
Palmer Luckey received a job offer from Sony.
It was a full-time position at Sony Computer Europe.
He would run Sony’s R&D lab.
The salary would be $70k.
Who is Brendan Iribe?
Brendan Iribe started early with Startups. In 2004, he and Mike Antonov founded Scaleform.
Scaleform created high-performance middleware. This package allows 3D Flash games.
In 2011, Iribe sold Scaleform to Autodesk for $36 million.
How Brendan Iribe discovered Palmer Luckey.
Brendan Iribe's friend Laurent Scallie.
Laurent told Iribe about a potential opportunity.
Laurent promised Iribe VR will work this time. Laurent introduced Iribe to Luckey.
Iribe was doubtful after hearing Laurent's statements. He doubted Laurent's VR claims.
But since Laurent took the name John Carmack, Iribe thought he should look at Luckey Innovation. Iribe was hooked on virtual reality after reading Palmer Luckey stories.
He asked Scallie about Palmer Luckey.
Iribe convinced Luckey to start Oculus with him
First meeting between Palmer Luckey and Iribe.
The Iribe team wanted Luckey to feel comfortable.
Iribe sought to convince Luckey that launching a company was easy. Iribe told Luckey anyone could start a business.
Luckey told Iribe's staff he was homeschooled from childhood. Luckey took self-study courses.
Luckey had planned to launch a Kickstarter campaign and sell kits for his prototype. Many companies offered him jobs, nevertheless.
He's considering Sony's offer.
Iribe advised Luckey to stay independent and not join a firm. Iribe asked Luckey how he could raise his child better. No one sees your baby like you do?
Iribe's team pushed Luckey to stay independent and establish a software ecosystem around his device.
After conversing with Iribe, Luckey rejected every job offer and merger option.
Iribe convinced Luckey to provide an SDK for Oculus developers.
After a few months. Brendan Iribe co-founded Oculus with Palmer Luckey. Luckey trusted Iribe and his crew, so he started a corporation with him.
Crowdfunding
Brendan Iribe and Palmer Luckey launched a Kickstarter.
Gabe Newell endorsed Palmer's Kickstarter video.
Gabe Newell wants folks to trust Palmer Luckey since he's doing something fascinating and answering tough questions.
Mark Bolas and David Helgason backed Palmer Luckey's VR Kickstarter video.
Luckey introduced Oculus Rift during the Kickstarter campaign. He introduced virtual reality during press conferences.
Oculus' Kickstarter effort was a success. Palmer Luckey felt he could raise $250,000.
Oculus raised $2.4 million through Kickstarter. Palmer Luckey's virtual reality vision was well-received.
Mark Zuckerberg's Oculus discovery
Brendan Iribe and Palmer Luckey hired the right personnel after a successful Kickstarter campaign.
Oculus needs a lot of money for engineers and hardware. They needed investors' money.
Series A raised $16M.
Next, Andreessen Horowitz partner Brain Cho approached Iribe.
Cho told Iribe that Andreessen Horowitz could invest in Oculus Series B if the company solved motion sickness.
Mark Andreessen was Iribe's dream client.
Marc Andreessen and his partners gave Oculus $75 million.
Andreessen introduced Iribe to Zukerberg. Iribe and Zukerberg discussed the future of games and virtual reality by phone.
Facebook's Oculus demo
Iribe showed Zuckerberg Oculus.
Mark was hooked after using Oculus. The headset impressed him.
The whole Facebook crew who saw the demo said only one thing.
“Holy Crap!”
This surprised them all.
Mark Zuckerberg was impressed by the team's response. Mark Zuckerberg met the Oculus team five days after the demo.
First meeting Palmer Luckey.
Palmer Luckey is one of Mark's biggest supporters and loves Facebook.
Oculus Acquisition
Zuckerberg wanted Oculus.
Brendan Iribe had requested for $4 billion, but Mark wasn't interested.
Facebook bought Oculus for $2.3 billion after months of drama.
After selling his company, how does Palmer view money?
Palmer loves the freedom money gives him. Money frees him from small worries.
Money has allowed him to pursue things he wouldn't have otherwise.
“If I didn’t have money I wouldn’t have a collection of vintage military vehicles…You can have nice hobbies that keep you relaxed when you have money.”
He didn't start Oculus to generate money. His virtual reality passion spanned years.
He didn't have to lie about how virtual reality will transform everything until he needed funding.
The company's success was an unexpected bonus. He was merely passionate about a good cause.
After Oculus' $2.3 billion exit, what changed?
Palmer didn't mind being rich. He did similar things.
After Facebook bought Oculus, he moved to Silicon Valley and lived in a 12-person shared house due to high rents.
Palmer might have afforded a big mansion, but he prefers stability and doing things because he wants to, not because he has to.
“Taco Bell is never tasted so good as when you know you could afford to never eat taco bell again.”
Palmer's leadership shifted.
Palmer changed his leadership after selling Oculus.
When he launched his second company, he couldn't work on his passions.
“When you start a tech company you do it because you want to work on a technology, that is why you are interested in that space in the first place. As the company has grown, he has realized that if he is still doing optical design in the company it’s because he is being negligent about the hiring process.”
Once his startup grows, the founder's responsibilities shift. He must recruit better firm managers.
Recruiting talented people becomes the top priority. The founder must convince others of their influence.
A book that helped me write this:
The History of the Future: Oculus, Facebook, and the Revolution That Swept Virtual Reality — Blake Harris
*This post is a summary. Read the full article here.

Aaron Dinin, PhD
1 month ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.

Antonio Neto
3 months ago
What's up with tech?
Massive Layoffs, record low VC investment, debate over crash... why is it happening and what’s the endgame?

This article generalizes a diverse industry. For objectivity, specific tech company challenges like growing competition within named segments won't be considered. Please comment on the posts.
According to Layoffs.fyi, nearly 120.000 people have been fired from startups since March 2020. More than 700 startups have fired 1% to 100% of their workforce. "The tech market is crashing"
Venture capital investment dropped 19% QoQ in the first four months of 2022, a 2018 low. Since January 2022, Nasdaq has dropped 27%. Some believe the tech market is collapsing.
It's bad, but nothing has crashed yet. We're about to get super technical, so buckle up!
I've written a follow-up article about what's next. For a more optimistic view of the crisis' aftermath, see: Tech Diaspora and Silicon Valley crisis
What happened?
Insanity reigned. Last decade, everyone became a unicorn. Seed investments can be made without a product or team. While the "real world" economy suffered from the pandemic for three years, tech companies enjoyed the "new normal."
COVID sped up technology adoption on several fronts, but this "new normal" wasn't so new after many restrictions were lifted. Worse, it lived with disrupted logistics chains, high oil prices, and WW3. The consumer market has felt the industry's boom for almost 3 years. Inflation, unemployment, mental distress...what looked like a fast economic recovery now looks like unfulfilled promises.
People rethink everything they eat. Paying a Netflix subscription instead of buying beef is moronic if you can watch it for free on your cousin’s account. No matter how great your real estate app's UI is, buying a house can wait until mortgage rates drop. PLGProduct Led Growth (PLG) isn't the go-to strategy when consumers have more basic expense priorities.
Exponential growth and investment
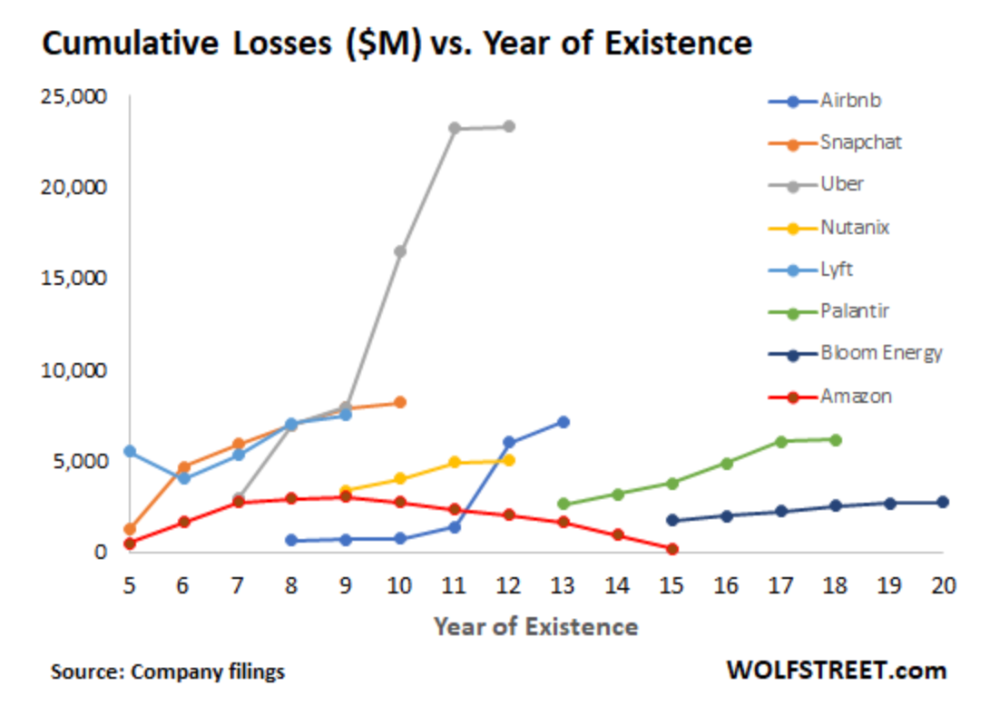
Until recently, tech companies believed that non-exponential revenue growth was fatal. Exponential growth entails doing more with less. From Salim Ismail words:
An Exponential Organization (ExO) has 10x the impact of its peers.
Many tech companies' theories are far from reality.
Investors have funded (sometimes non-exponential) growth. Scale-driven companies throw people at problems until they're solved. Need an entire closing team because you’ve just bought a TV prime time add? Sure. Want gold-weight engineers to colorize buttons? Why not?
Tech companies don't need cash flow to do it; they can just show revenue growth and get funding. Even though it's hard to get funding, this was the market's momentum until recently.
The graph at the beginning of this section shows how industry heavyweights burned money until 2020, despite being far from their market-share seed stage. Being big and being sturdy are different things, and a lot of the tech startups out there are paper tigers. Without investor money, they have no foundation.
A little bit about interest rates
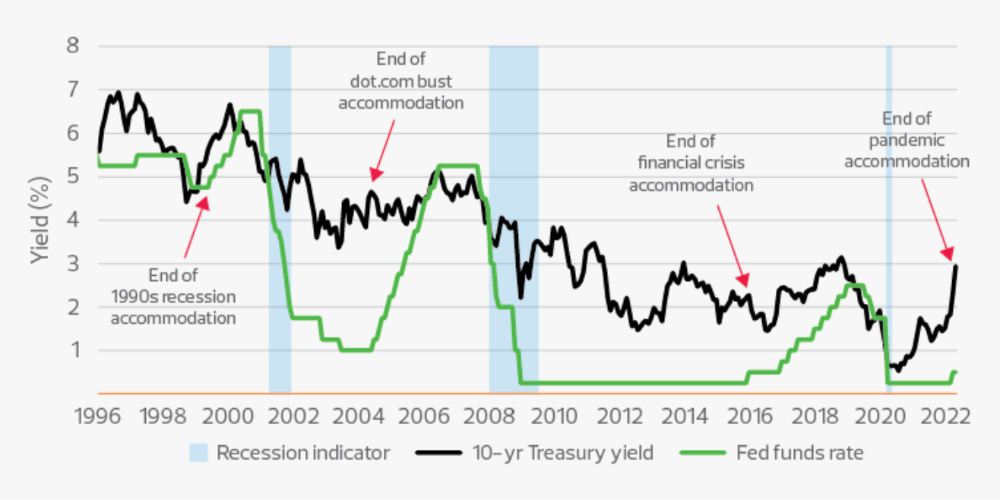
Inflation-driven high interest rates are said to be causing tough times. Investors would rather leave money in the bank than spend it (I myself said it some days ago). It’s not wrong, but it’s also not that simple.
The USA central bank (FED) is a good proxy of global economics. Dollar treasury bonds are the safest investment in the world. Buying U.S. debt, the only country that can print dollars, guarantees payment.
The graph above shows that FED interest rates are low and 10+ year bond yields are near 2018 levels. Nobody was firing at 2018. What’s with that then?
Full explanation is too technical for this article, so I'll just summarize: Bond yields rise due to lack of demand or market expectations of longer-lasting inflation. Safe assets aren't a "easy money" tactic for investors. If that were true, we'd have seen the current scenario before.
Long-term investors are protecting their capital from inflation.
Not a crash, a landing
I bombarded you with info... Let's review:
Consumption is down, hurting revenue.
Tech companies of all ages have been hiring to grow revenue at the expense of profit.
Investors expect inflation to last longer, reducing future investment gains.
Inflation puts pressure on a wheel that was rolling full speed not long ago. Investment spurs hiring, growth, and more investment. Worried investors and consumers reduce the cycle, and hiring follows.
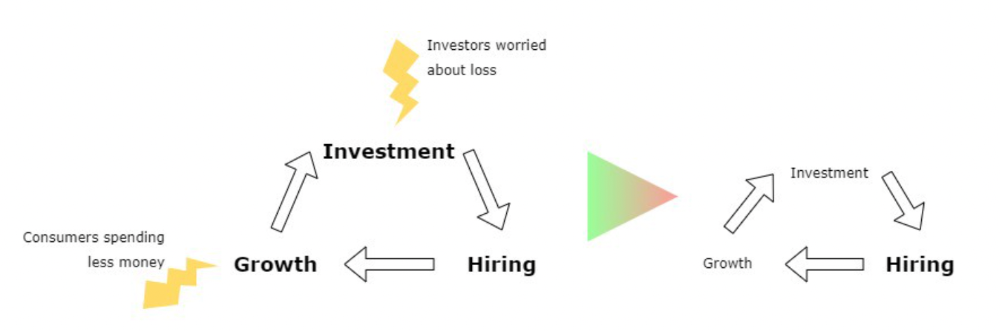
Long-term investors back startups. When the invested company goes public or is sold, it's ok to burn money. What happens when the payoff gets further away? What if all that money sinks? Investors want immediate returns.
Why isn't the market crashing? Technology is not losing capital. It’s expecting change. The market realizes it threw moderation out the window and is reversing course. Profitability is back on the menu.
People solve problems and make money, but they also cost money. Huge cost for the tech industry. Engineers, Product Managers, and Designers earn up to 100% more than similar roles. Businesses must be careful about who they keep and in what positions to avoid wasting money.
What the future holds
From here on, it's all speculation. I found many great articles while researching this piece. Some are cited, others aren't (like this and this). We're in an adjustment period that may or may not last long.
Big companies aren't laying off many workers. Netflix firing 100 people makes headlines, but it's only 1% of their workforce. The biggest seem to prefer not hiring over firing.
Smaller startups beyond the seeding stage may be hardest hit. Without structure or product maturity, many will die.
I expect layoffs to continue for some time, even at Meta or Amazon. I don't see any industry names falling like they did during the .com crisis, but the market will shrink.
If you are currently employed, think twice before moving out and where to.
If you've been fired, hurry, there are still many opportunities.
If you're considering a tech career, wait.
If you're starting a business, I respect you. Good luck.
You might also like

Michael Le
6 months ago
Union LA x Air Jordan 2 “Future Is Now” PREVIEW
With the help of Virgil Abloh and Union LA‘s Chris Gibbs, it's now clear that Jordan Brand intended to bring the Air Jordan 2 back in 2022.
The “Future Is Now” collection includes two colorways of MJ's second signature as well as an extensive range of apparel and accessories.
“We wanted to juxtapose what some futuristic gear might look like after being worn and patina'd,”
Union stated on the collaboration's landing page.
“You often see people's future visions that are crisp and sterile. We thought it would be cool to wear it in and make it organic...”
The classic co-branding appears on short-sleeve tees, hoodies, and sweat shorts/sweat pants, all lightly distressed at the hems and seams.
Also, a filtered black-and-white photo of MJ graces the adjacent long sleeves, labels stitch into the socks, and the Jumpman logo adorns the four caps.
Liner jackets and flight pants will also be available, adding reimagined militaria to a civilian ensemble.
The Union LA x Air Jordan 2 (Grey Fog and Rattan) shares many of the same beats. Vintage suedes show age, while perforations and detailing reimagine Bruce Kilgore's design for the future.
The “UN/LA” tag across the modified eye stays, the leather patch across the tongue, and the label that wraps over the lateral side of the collar complete the look.
The footwear will also include a Crater Slide in the “Grey Fog” color scheme.
BUYING
On 4/9 and 4/10 from 9am-3pm, Union LA will be giving away a pair of Air Jordan 2s at their La Brea storefront (110 S. LA BREA AVE. LA, CA 90036). The raffle is only open to LA County residents with a valid CA ID. You must enter by 11:59pm on 4/10 to win. Winners will be notified via email.

Joseph Mavericks
5 days ago
Apples Top 100 Meeting: Steve Jobs's Secret Agenda's Lessons
Jobs' secret emails became public due to a litigation with Samsung.

Steve Jobs sent Phil Schiller an email at the end of 2010. Top 100 A was the codename for Apple's annual Top 100 executive meetings. The 2011 one was scheduled.
Everything about this gathering is secret, even attendance. The location is hidden, and attendees can't even drive themselves. Instead, buses transport them to a 2-3 day retreat.
Due to a litigation with Samsung, this Top 100 meeting's agenda was made public in 2014. This was a critical milestone in Apple's history, not a Top 100 meeting. Apple had many obstacles in the 2010s to remain a technological leader. Apple made more money with non-PC goods than with its best-selling Macintosh series. This was the last Top 100 gathering Steve Jobs would attend before passing, and he wanted to make sure his messages carried on before handing over his firm to Tim Cook.
In this post, we'll discuss lessons from Jobs' meeting agenda. Two sorts of entrepreneurs can use these tips:
Those who manage a team in a business and must ensure that everyone is working toward the same goals, upholding the same principles, and being inspired by the same future.
Those who are sole proprietors or independent contractors and who must maintain strict self-discipline in order to stay innovative in their industry and adhere to their own growth strategy.
Here's Steve Jobs's email outlining the annual meeting agenda. It's an 11-part summary of the company's shape and strategy.



Steve Jobs outlines Apple's 2011 strategy, 10/24/10
1. Correct your data
Business leaders must comprehend their company's metrics. Jobs either mentions critical information he already knows or demands slides showing the numbers he wants. These numbers fall under 2 categories:
Metrics for growth and strategy
As we will see, this was a crucial statistic for Apple since it signaled the beginning of the Post PC era and required them to make significant strategic changes in order to stay ahead of the curve. Post PC products now account for 66% of our revenues.
Within six months, iPad outsold Mac, another sign of the Post-PC age. As we will see, Jobs thought the iPad would be the next big thing, and item number four on the agenda is one of the most thorough references to the iPad.
Geographical analysis: Here, Jobs emphasizes China, where the corporation has a slower start than anticipated. China was dominating Apple's sales growth with 16% of revenue one year after this meeting.
Metrics for people & culture
The individuals that make up a firm are more significant to its success than its headcount or average age. That holds true regardless of size, from a 5-person startup to a Fortune 500 firm. Jobs was aware of this, which is why his suggested agenda begins by emphasizing demographic data.
Along with the senior advancements in the previous year's requested statistic, it's crucial to demonstrate that if the business is growing, the employees who make it successful must also grow.
2. Recognize the vulnerabilities and strengths of your rivals
Steve Jobs was known for attacking his competition in interviews and in his strategies and roadmaps. This agenda mentions 18 competitors, including:
Google 7 times
Android 3 times
Samsung 2 times
Jobs' agenda email was issued 6 days after Apple's Q4 results call (2010). On the call, Jobs trashed Google and Android. His 5-minute intervention included:
Google has acknowledged that the present iteration of Android is not tablet-optimized.
Future Android tablets will not work (Dead On Arrival)
While Google Play only has 90,000 apps, the Apple App Store has 300,000.
Android is extremely fragmented and is continuing to do so.
The App Store for iPad contains over 35,000 applications. The market share of the latest generation of tablets (which debuted in 2011) will be close to nil.
Jobs' aim in blasting the competition on that call was to reassure investors about the upcoming flood of new tablets. Jobs often criticized Google, Samsung, and Microsoft, but he also acknowledged when they did a better job. He was great at detecting his competitors' advantages and devising ways to catch up.
Jobs doesn't hold back when he says in bullet 1 of his agenda: "We further lock customers into our ecosystem while Google and Microsoft are further along on the technology, but haven't quite figured it out yet tie all of our goods together."
The plan outlined in bullet point 5 is immediately clear: catch up to Android where we are falling behind (notifications, tethering, and speech), and surpass them (Siri,). It's important to note that Siri frequently let users down and never quite lived up to expectations.
Regarding MobileMe, see Bullet 6 Jobs admits that when it comes to cloud services like contacts, calendars, and mail, Google is far ahead of Apple.
3. Adapt or perish
Steve Jobs was a visionary businessman. He knew personal computers were the future when he worked on the first Macintosh in the 1980s.
Jobs acknowledged the Post-PC age in his 2010 D8 interview.
Will the tablet replace the laptop, Walt Mossberg questioned Jobs? Jobs' response:
“You know, when we were an agrarian nation, all cars were trucks, because that’s what you needed on the farm. As vehicles started to be used in the urban centers and America started to move into those urban and suburban centers, cars got more popular and innovations like automatic transmission and things that you didn’t care about in a truck as much started to become paramount in cars. And now, maybe 1 out of every 25 vehicles is a truck, where it used to be 100%. PCs are going to be like trucks. They’re still going to be around, still going to have a lot of value, but they’re going to be used by one out of X people.”
Imagine how forward-thinking that was in 2010, especially for the Macintosh creator. You have to be willing to recognize that things were changing and that it was time to start over and focus on the next big thing.
Post-PC is priority number 8 in his 2010 agenda's 2011 Strategy section. Jobs says Apple is the first firm to get here and that Post PC items account about 66% of our income. The iPad outsold the Mac in 6 months, and the Post-PC age means increased mobility (smaller, thinner, lighter). Samsung had just introduced its first tablet, while Apple was working on the iPad 3. (as mentioned in bullet 4).
4. Plan ahead (and different)
Jobs' agenda warns that Apple risks clinging to outmoded paradigms. Clayton Christensen explains in The Innovators Dilemma that huge firms neglect disruptive technologies until they become profitable. Samsung's Galaxy tab, released too late, never caught up to Apple.
Apple faces a similar dilemma with the iPhone, its cash cow for over a decade. It doesn't sell as much because consumers aren't as excited about new iPhone launches and because technology is developing and cell phones may need to be upgraded.
Large companies' established consumer base typically hinders innovation. Clayton Christensen emphasizes that loyal customers from established brands anticipate better versions of current products rather than something altogether fresh and new technologies.
Apple's marketing is smart. Apple's ecosystem is trusted by customers, and its products integrate smoothly. So much so that Apple can afford to be a disruptor by doing something no one has ever done before, something the world's largest corporation shouldn't be the first to try. Apple can test the waters and produce a tremendous innovation tsunami, something few corporations can do.
In March 2011, Jobs appeared at an Apple event. During his address, Steve reminded us about Apple's brand:
“It’s in Apple’s DNA, that technology alone is not enough. That it’s technology married with liberal arts, married with the humanities that yields us the results that make our hearts sink. And nowhere is that more true that in these Post-PC devices.“
More than a decade later, Apple remains one of the most innovative and trailblazing companies in the Post-PC world (industry-disrupting products like Airpods or the Apple Watch came out after that 2011 strategy meeting), and it has reinvented how we use laptops with its M1-powered line of laptops offering unprecedented performance.
A decade after Jobs' death, Apple remains the world's largest firm, and its former CEO had a crucial part in its expansion. If you can do 1% of what Jobs did, you may be 1% as successful.
Not bad.

Francesca Furchtgott
2 months ago
Giving customers what they want or betraying the values of the brand?
A J.Crew collaboration for fashion label Eveliina Vintage is not a paradox; it is a solution.

Eveliina Vintage's capsule collection debuted yesterday at J.Crew. This J.Crew partnership stopped me in my tracks.
Eveliina Vintage sells vintage goods. Eeva Musacchia founded the shop in Finland in the 1970s. It's recognized for its one-of-a-kind slip dresses from the 1930s and 1940s.
I wondered why a vintage brand would partner with a mass shop. Fast fashion against vintage shopping? Will Eveliina Vintages customers be turned off?
But Eveliina Vintages customers don't care about sustainability. They want Eveliina's Instagram look. Eveliina Vintage collaborated with J.Crew to give customers what they wanted: more Eveliina at a lower price.
Vintage: A Fashion Option That Is Eco-Conscious
Secondhand shopping is a trendy response to quick fashion. J.Crew releases hundreds of styles annually. Waste and environmental damage have been criticized. A pair of jeans requires 1,800 gallons of water. J.Crew's limited-time deals promote more purchases. J.Crew items are likely among those Americans wear 7 times before discarding.
Consumers and designers have emphasized sustainability in recent years. Stella McCartney and Eileen Fisher are popular eco-friendly brands. They've also flocked to ThredUp and similar sites.
Gap, Levis, and Allbirds have listened to consumer requests. They promote recycling, ethical sourcing, and secondhand shopping.
Secondhand shoppers feel good about reusing and recycling clothing that might have ended up in a landfill.
Eco-conscious fashionistas shop vintage. These shoppers enjoy the thrill of the hunt (that limited-edition Chanel bag!) and showing off a unique piece (nobody will have my look!). They also reduce their environmental impact.
Is Eveliina Vintage capitalizing on an aesthetic or is it a sustainable brand?
Eveliina Vintage emphasizes environmental responsibility. Vogue's Amanda Musacchia emphasized sustainability. Amanda, founder Eeva's daughter, is a company leader.
But Eveliina's press message doesn't address sustainability, unlike Instagram. Scarcity and fame rule.
Eveliina Vintages Instagram has see-through dresses and lace-trimmed slip dresses. Celebrities and influencers are often photographed in Eveliina's apparel, which has 53,000+ followers. Vogue appreciates Eveliina's style. Multiple publications discuss Alexa Chung's Eveliina dress.
Eveliina Vintage markets its one-of-a-kind goods. It teases future content, encouraging visitors to return. Scarcity drives demand and raises clothing prices. One dress is $1,600+, but most are $500-$1,000.
The catch: Eveliina can't monetize its expanding popularity due to exorbitant prices and limited quantity. Why?
Most people struggle to pay for their clothing. But Eveliina Vintage lacks those more affordable entry-level products, in contrast to other luxury labels that sell accessories or perfume.
Many people have trouble fitting into their clothing. The bodies of most women in the past were different from those for which vintage clothing was designed. Each Eveliina dress's specific measurements are mentioned alongside it. Be careful, you can fall in love with an ill-fitting dress.
No matter how many people can afford it and fit into it, there is only one item to sell. To get the item before someone else does, those people must be on the Eveliina Vintage website as soon as it becomes available.
A Way for Eveliina Vintage to Make Money (and Expand) with J.Crew Its following
Eveliina Vintages' cooperation with J.Crew makes commercial sense.
This partnership spreads Eveliina's style. Slightly better pricing The $390 outfits have multicolored slips and gauzy cotton gowns. Sizes range from 00 to 24, which is wider than vintage racks.
Eveliina Vintage customers like the combination. Excited comments flood the brand's Instagram launch post. Nobody is mocking the 50-year-old vintage brand's fast-fashion partnership.
Vintage may be a sustainable fashion trend, but that's not why Eveliina's clients love the brand. They only care about the old look.
And that is a tale as old as fashion.