



More on Personal Growth

Alexander Nguyen
3 years ago
How can you bargain for $300,000 at Google?
Don’t give a number

Google pays its software engineers generously. While many of their employees are competent, they disregard a critical skill to maximize their pay.
Negotiation.
If Google employees have never negotiated, they're as helpless as anyone else.
In this piece, I'll reveal a compensation negotiation tip that will set you apart.
The Fallacy of Negotiating
How do you negotiate your salary? “Just give them a number twice the amount you really want”. - Someplace on the internet
Above is typical negotiation advice. If you ask for more than you want, the recruiter may meet you halfway.
It seems logical and great, but here's why you shouldn't follow that advice.
Haitian hostage rescue
In 1977, an official's aunt was kidnapped in Haiti. The kidnappers demanded $150,000 for the aunt's life. It seems reasonable until you realize why kidnappers want $150,000.
FBI detective and negotiator Chris Voss researched why they demanded so much.
“So they could party through the weekend”
When he realized their ransom was for partying, he offered $4,751 and a CD stereo. Criminals freed the aunt.
These thieves gave 31.57x their estimated amount and got a fraction. You shouldn't trust these thieves to negotiate your compensation.
What happened?
Negotiating your offer and Haiti
This narrative teaches you how to negotiate with a large number.
You can and will be talked down.
If a recruiter asks your wage expectation and you offer double, be ready to explain why.
If you can't justify your request, you may be offered less. The recruiter will notice and talk you down.
Reasonably,
a tiny bit more than the present amount you earn
a small premium over an alternative offer
a little less than the role's allotted amount
Real-World Illustration

Recruiter: What’s your expected salary? Candidate: (I know the role is usually $100,000) $200,000 Recruiter: How much are you compensated in your current role? Candidate: $90,000 Recruiter: We’d be excited to offer you $95,000 for your experiences for the role.
So Why Do They Even Ask?
Recruiters ask for a number to negotiate a lower one. Asking yourself limits you.
You'll rarely get more than you asked for, and your request can be lowered.
The takeaway from all of this is to never give an expected compensation.
Tell them you haven't thought about it when you applied.

Khyati Jain
3 years ago
By Engaging in these 5 Duplicitous Daily Activities, You Rapidly Kill Your Brain Cells
No, it’s not smartphones, overeating, or sugar.

Everyday practices affect brain health. Good brain practices increase memory and cognition.
Bad behaviors increase stress, which destroys brain cells.
Bad behaviors can reverse evolution and diminish the brain. So, avoid these practices for brain health.
1. The silent assassin
Introverts appreciated quarantine.
Before the pandemic, they needed excuses to remain home; thereafter, they had enough.
I am an introvert, and I didn’t hate quarantine. There are billions of people like me who avoid people.
Social relationships are important for brain health. Social anxiety harms your brain.
Antisocial behavior changes brains. It lowers IQ and increases drug abuse risk.
What you can do is as follows:
Make a daily commitment to engage in conversation with a stranger. Who knows, you might turn out to be your lone mate.
Get outside for at least 30 minutes each day.
Shop for food locally rather than online.
Make a call to a friend you haven't spoken to in a while.
2. Try not to rush things.
People love hustle culture. This economy requires a side gig to save money.
Long hours reduce brain health. A side gig is great until you burn out.
Work ages your wallet and intellect. Overworked brains age faster and lose cognitive function.
Working longer hours can help you make extra money, but it can harm your brain.
Side hustle but don't overwork.
What you can do is as follows:
Decide what hour you are not permitted to work after.
Three hours prior to night, turn off your laptop.
Put down your phone and work.
Assign due dates to each task.
3. Location is everything!
The environment may cause brain fog. High pollution can cause brain damage.
Air pollution raises Alzheimer's risk. Air pollution causes cognitive and behavioral abnormalities.
Polluted air can trigger early development of incurable brain illnesses, not simply lung harm.
Your city's air quality is uncontrollable. You may take steps to improve air quality.
In Delhi, schools and colleges are closed to protect pupils from polluted air. So I've adapted.
What you can do is as follows:
To keep your mind healthy and young, make an investment in a high-quality air purifier.
Enclose your windows during the day.
Use a N95 mask every day.
4. Don't skip this meal.
Fasting intermittently is trendy. Delaying breakfast to finish fasting is frequent.
Some skip breakfast and have a hefty lunch instead.
Skipping breakfast might affect memory and focus. Skipping breakfast causes low cognition, delayed responsiveness, and irritation.
Breakfast affects mood and productivity.
Intermittent fasting doesn't prevent healthy breakfasts.
What you can do is as follows:
Try to fast for 14 hours, then break it with a nutritious breakfast.
So that you can have breakfast in the morning, eat dinner early.
Make sure your breakfast is heavy in fiber and protein.
5. The quickest way to damage the health of your brain
Brain health requires water. 1% dehydration can reduce cognitive ability by 5%.
Cerebral fog and mental clarity might result from 2% brain dehydration. Dehydration shrinks brain cells.
Dehydration causes midday slumps and unproductivity. Water improves work performance.
Dehydration can harm your brain, so drink water throughout the day.
What you can do is as follows:
Always keep a water bottle at your desk.
Enjoy some tasty herbal teas.
With a big glass of water, begin your day.
Bring your own water bottle when you travel.
Conclusion
Bad habits can harm brain health. Low cognition reduces focus and productivity.
Unproductive work leads to procrastination, failure, and low self-esteem.
Avoid these harmful habits to optimize brain health and function.

Ian Writes
3 years ago
Rich Dad, Poor Dad is a Giant Steaming Pile of Sh*t by Robert Kiyosaki.
Don't promote it.

I rarely read a post on how Rich Dad, Poor Dad motivated someone to grow rich or change their investing/finance attitude. Rich Dad, Poor Dad is a sham, though. This book isn't worth anyone's attention.
Robert Kiyosaki, the author of this garbage, doesn't deserve recognition or attention. This first finance guru wanted to build his own wealth at your expense. These charlatans only care about themselves.
The reason why Rich Dad, Poor Dad is a huge steaming piece of trash
The book's ideas are superficial, apparent, and unsurprising to entrepreneurs and investors. The book's themes may seem profound to first-time readers.
Apparently, starting a business will make you rich.
The book supports founding or buying a business, making it self-sufficient, and being rich through it. Starting a business is time-consuming, tough, and expensive. Entrepreneurship isn't for everyone. Rarely do enterprises succeed.
Robert says we should think like his mentor, a rich parent. Robert never said who or if this guy existed. He was apparently his own father. Robert proposes investing someone else's money in several enterprises and properties. The book proposes investing in:
“have returns of 100 percent to infinity. Investments that for $5,000 are soon turned into $1 million or more.”
In rare cases, a business may provide 200x returns, but 65% of US businesses fail within 10 years. Australia's first-year business failure rate is 60%. A business that lasts 10 years doesn't mean its owner is rich. These statistics only include businesses that survive and pay their owners.
Employees are depressed and broke.
The novel portrays employees as broke and sad. The author degrades workers.
I've owned and worked for a business. I was broke and miserable as a business owner, working 80 hours a week for absolutely little salary. I work 50 hours a week and make over $200,000 a year. My work is hard, intriguing, and I'm surrounded by educated individuals. Self-employed or employee?
Don't listen to a charlatan's tax advice.
From a bad advise perspective, Robert's tax methods were funny. Robert suggests forming a corporation to write off holidays as board meetings or health club costs as business expenses. These actions can land you in serious tax trouble.
Robert dismisses college and traditional schooling. Rich individuals learn by doing or living, while educated people are agitated and destitute, says Robert.
Rich dad says:
“All too often business schools train employees to become sophisticated bean-counters. Heaven forbid a bean counter takes over a business. All they do is look at the numbers, fire people, and kill the business.”
And then says:
“Accounting is possibly the most confusing, boring subject in the world, but if you want to be rich long-term, it could be the most important subject.”
Get rich by avoiding paying your debts to others.
While this book has plenty of bad advice, I'll end with this: Robert advocates paying yourself first. This man's work with Trump isn't surprising.
Rich Dad's book says:
“So you see, after paying myself, the pressure to pay my taxes and the other creditors is so great that it forces me to seek other forms of income. The pressure to pay becomes my motivation. I’ve worked extra jobs, started other companies, traded in the stock market, anything just to make sure those guys don’t start yelling at me […] If I had paid myself last, I would have felt no pressure, but I’d be broke.“
Paying yourself first shouldn't mean ignoring debt, damaging your credit score and reputation, or paying unneeded fees and interest. Good business owners pay employees, creditors, and other costs first. You can pay yourself after everyone else.
If you follow Robert Kiyosaki's financial and business advice, you might as well follow Donald Trump's, the most notoriously ineffective businessman and swindle artist.
This book's popularity is unfortunate. Robert utilized the book's fame to promote paid seminars. At these seminars, he sold more expensive seminars to the gullible. This strategy was utilized by several conmen and Trump University.
It's reasonable that many believed him. It sounded appealing because he was pushing to get rich by thinking like a rich person. Anyway. At a time when most persons addressing wealth development advised early sacrifices (such as eschewing luxury or buying expensive properties), Robert told people to act affluent now and utilize other people's money to construct their fantasy lifestyle. It's exciting and fast.
I often voice my skepticism and scorn for internet gurus now that social media and platforms like Medium make it easier to promote them. Robert Kiyosaki was a guru. Many people still preach his stuff because he was so good at pushing it.
You might also like

The Verge
4 years ago
Bored Ape Yacht Club creator raises $450 million at a $4 billion valuation.
Yuga Labs, owner of three of the biggest NFT brands on the market, announced today a $450 million funding round. The money will be used to create a media empire based on NFTs, starting with games and a metaverse project.
The team's Otherside metaverse project is an MMORPG meant to connect the larger NFT universe. They want to create “an interoperable world” that is “gamified” and “completely decentralized,” says Wylie Aronow, aka Gordon Goner, co-founder of Bored Ape Yacht Club. “We think the real Ready Player One experience will be player run.”
Just a few weeks ago, Yuga Labs announced the acquisition of CryptoPunks and Meebits from Larva Labs. The deal brought together three of the most valuable NFT collections, giving Yuga Labs more IP to work with when developing games and metaverses. Last week, ApeCoin was launched as a cryptocurrency that will be governed independently and used in Yuga Labs properties.
Otherside will be developed by “a few different game studios,” says Yuga Labs CEO Nicole Muniz. The company plans to create development tools that allow NFTs from other projects to work inside their world. “We're welcoming everyone into a walled garden.”
However, Yuga Labs believes that other companies are approaching metaverse projects incorrectly, allowing the startup to stand out. People won't bond spending time in a virtual space with nothing going on, says Yuga Labs co-founder Greg Solano, aka Gargamel. Instead, he says, people bond when forced to work together.
In order to avoid getting smacked, Solano advises making friends. “We don't think a Zoom chat and walking around saying ‘hi' creates a deep social experience.” Yuga Labs refused to provide a release date for Otherside. Later this year, a play-to-win game is planned.
The funding round was led by Andreessen Horowitz, a major investor in the Web3 space. It previously backed OpenSea and Coinbase. Animoca Brands, Coinbase, and MoonPay are among those who have invested. Andreessen Horowitz general partner Chris Lyons will join Yuga Labs' board. The Financial Times broke the story last month.
"META IS A DOMINANT DIGITAL EXPERIENCE PROVIDER IN A DYSTOPIAN FUTURE."
This emerging [Web3] ecosystem is important to me, as it is to companies like Meta,” Chris Dixon, head of Andreessen Horowitz's crypto arm, tells The Verge. “In a dystopian future, Meta is the dominant digital experience provider, and it controls all the money and power.” (Andreessen Horowitz co-founder Marc Andreessen sits on Meta's board and invested early in Facebook.)
Yuga Labs has been profitable so far. According to a leaked pitch deck, the company made $137 million last year, primarily from its NFT brands, with a 95% profit margin. (Yuga Labs declined to comment on deck figures.)
But the company has built little so far. According to OpenSea data, it has only released one game for a limited time. That means Yuga Labs gets hundreds of millions of dollars to build a gaming company from scratch, based on a hugely lucrative art project.
Investors fund Yuga Labs based on its success. That's what they did, says Dixon, “they created a culture phenomenon”. But ultimately, the company is betting on the same thing that so many others are: that a metaverse project will be the next big thing. Now they must construct it.

Miguel Saldana
3 years ago
Crypto Inheritance's Catch-22
Security, privacy, and a strategy!

How to manage digital assets in worst-case scenarios is a perennial crypto concern. Since blockchain and bitcoin technology is very new, this hasn't been a major issue. Many early developers are still around, and many groups created around this technology are young and feel they have a lot of life remaining. This is why inheritance and estate planning in crypto should be handled promptly. As cryptocurrency's intrinsic worth rises, many people in the ecosystem are holding on to assets that might represent generational riches. With that much value, it's crucial to have a plan. Creating a solid plan entails several challenges.
the initial hesitation in coming up with a plan
The technical obstacles to ensuring the assets' security and privacy
the passing of assets from a deceased or incompetent person
Legal experts' lack of comprehension and/or understanding of how to handle and treat cryptocurrency.
This article highlights several challenges, a possible web3-native solution, and how to learn more.

The Challenge of Inheritance:
One of the biggest hurdles to inheritance planning is starting the conversation. As humans, we don't like to think about dying. Early adopters will experience crazy gains as cryptocurrencies become more popular. Creating a plan is crucial if you wish to pass on your riches to loved ones. Without a plan, the technical and legal issues I barely mentioned above would erode value by requiring costly legal fees and/or taxes, and you could lose everything if wallets and assets are not distributed appropriately (associated with the private keys). Raising awareness of the consequences of not having a plan should motivate people to make one.

Controlling Change:
Having an inheritance plan for your digital assets is crucial, but managing the guts and bolts poses a new set of difficulties. Privacy and security provided by maintaining your own wallet provide different issues than traditional finances and assets. Traditional finance is centralized (say a stock brokerage firm). You can assign another person to handle the transfer of your assets. In crypto, asset transfer is reimagined. One may suppose future transaction management is doable, but the user must consent, creating an impossible loop.
I passed away and must send a transaction to the person I intended to deliver it to.
I have to confirm or authorize the transaction, but I'm dead.
In crypto, scheduling a future transaction wouldn't function. To transfer the wallet and its contents, we'd need the private keys and/or seed phrase. Minimizing private key exposure is crucial to protecting your crypto from hackers, social engineering, and phishing. People have lost private keys after utilizing Life Hack-type tactics to secure them. People that break and hide their keys, lose them, or make them unreadable won't help with managing and/or transferring. This will require a derived solution.

Legal Challenges and Implications
Unlike routine cryptocurrency transfers and transactions, local laws may require special considerations. Even in the traditional world, estate/inheritance taxes, how assets will be split, and who executes the will must be considered. Many lawyers aren't crypto-savvy, which complicates the matter. There will be many hoops to jump through to safeguard your crypto and traditional assets and give them to loved ones.
Knowing RUFADAA/UFADAA, depending on your state, is vital for Americans. UFADAA offers executors and trustees access to online accounts (which crypto wallets would fall into). RUFADAA was changed to limit access to the executor to protect assets. RUFADAA outlines how digital assets are administered following death and incapacity in the US.
A Succession Solution
Having a will and talking about who would get what is the first step to having a solution, but using a Dad Mans Switch is a perfect tool for such unforeseen circumstances. As long as the switch's controller has control, nothing happens. Losing control of the switch initiates a state transition.
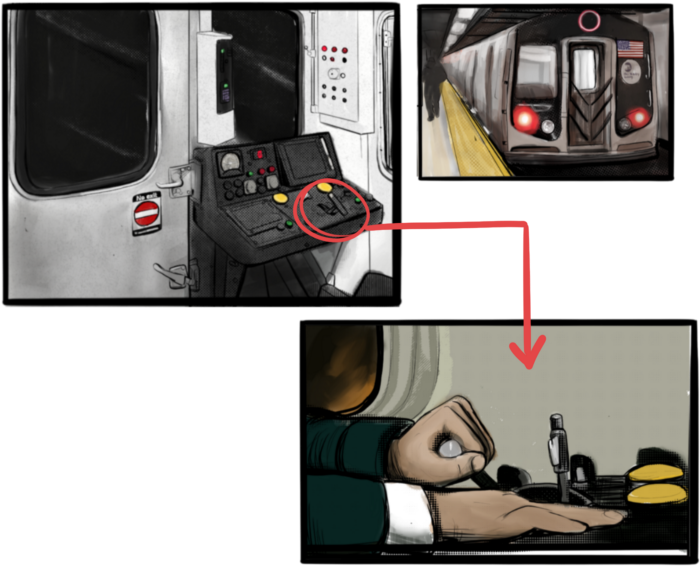
Subway or railway operations are examples. Modern control systems need the conductor to hold a switch to keep the train going. If they can't, the train stops.

Enter Sarcophagus
Sarcophagus is a decentralized dead man's switch built on Ethereum and Arweave. Sarcophagus allows actors to maintain control of their possessions even while physically unable to do so. Using a programmable dead man's switch and dual encryption, anything can be kept and passed on. This covers assets, secrets, seed phrases, and other use cases to provide authority and control back to the user and release trustworthy services from this work. Sarcophagus is built on a decentralized, transparent open source codebase. Sarcophagus is there if you're unprepared.


Jennifer Tieu
4 years ago
Why I Love Azuki
Azuki Banner (www.azuki.com)
Disclaimer: This is my personal viewpoint. I'm not on the Azuki team. Please keep in mind that I am merely a fan, community member, and holder. Please do your own research and pardon my grammar. Thanks!
Azuki has changed my view of NFTs.
When I first entered the NFT world, I had no idea what to expect. I liked the idea. So I invested in some projects, fought for whitelists, and discovered some cool NFTs projects (shout-out to CATC). I lost more money than I earned at one point, but I hadn't invested excessively (only put in what you can afford to lose). Despite my losses, I kept looking. I almost waited for the “ah-ha” moment. A NFT project that changed my perspective on NFTs. What makes an NFT project more than a work of art?
Answer: Azuki.
The Art
The Azuki art drew me in as an anime fan. It looked like something out of an anime, and I'd never seen it before in NFT.
The project was still new. The first two animated teasers were released with little fanfare, but I was impressed with their quality. You can find them on Instagram or in their earlier Tweets.
The teasers hinted that this project could be big and that the team could deliver. It was amazing to see Shao cut the Azuki posters with her katana. Especially at the end when she sheaths her sword and the music cues. Then the live action video of the young boy arranging the Azuki posters seemed movie-like. I felt like I was entering the Azuki story, brand, and dope theme.
The team did not disappoint with the Azuki NFTs. The level of detail in the art is stunning. There were Azukis of all genders, skin and hair types, and more. These 10,000 Azukis have so much representation that almost anyone can find something that resonates. Rather than me rambling on, I suggest you visit the Azuki gallery
The Team
If the art is meant to draw you in and be the project's face, the team makes it more. The NFT would be a JPEG without a good team leader. Not that community isn't important, but no community would rally around a bad team.
Because I've been rugged before, I'm very focused on the team when considering a project. While many project teams are anonymous, I try to find ones that are doxxed (public) or at least appear to be established. Unlike Azuki, where most of the Azuki team is anonymous, Steamboy is public. He is (or was) Overwatch's character art director and co-creator of Azuki. I felt reassured and could trust the project after seeing someone from a major game series on the team.
Then I tried to learn as much as I could about the team. Following everyone on Twitter, reading their tweets, and listening to recorded AMAs. I was impressed by the team's professionalism and dedication to their vision for Azuki, led by ZZZAGABOND.
I believe the phrase “actions speak louder than words” applies to Azuki. I can think of a few examples of what the Azuki team has done, but my favorite is ERC721A.
With ERC721A, Azuki has created a new algorithm that allows minting multiple NFTs for essentially the same cost as minting one NFT.
I was ecstatic when the dev team announced it. This fascinates me as a self-taught developer. Azuki released a product that saves people money, improves the NFT space, and is open source. It showed their love for Azuki and the NFT community.
The Community
Community, community, community. It's almost a chant in the NFT space now. A community, like a team, can make or break a project. We are the project's consumers, shareholders, core, and lifeblood. The team builds the house, and we fill it. We stay for the community.
When I first entered the Azuki Discord, I was surprised by the calm atmosphere. There was no news about the project. No release date, no whitelisting requirements. No grinding or spamming either. People just wanted to hangout, get to know each other, and talk. It was nice. So the team could pick genuine people for their mintlist (aka whitelist).
But nothing fundamental has changed since the release. It has remained an authentic, fun, and helpful community. I'm constantly logging into Discord to chat with others or follow conversations. I see the community's openness to newcomers. Everyone respects each other (barring a few bad apples) and the variety of people passing through is fascinating. This human connection and interaction is what I enjoy about this place. Being a part of a group that supports a cause.
Finally, I want to thank the amazing Azuki mod team and the kissaten channel for their contributions.
The Brand
So, what sets Azuki apart from other projects? They are shaping a brand or identity. The Azuki website, I believe, best captures their vision. (This is me gushing over the site.)
If you go to the website, turn on the dope playlist in the bottom left. The playlist features a mix of Asian and non-Asian hip-hop and rap artists, with some lo-fi thrown in. The songs on the playlist change, but I think you get the vibe Azuki embodies just by turning on the music.
The Garden is our next stop where we are introduced to Azuki.
A brand.
We're creating a new brand together.
A metaverse brand. By the people.
A collection of 10,000 avatars that grant Garden membership. It starts with exclusive streetwear collabs, NFT drops, live events, and more. Azuki allows for a new media genre that the world has yet to discover. Let's build together an Azuki, your metaverse identity.
The Garden is a magical internet corner where art, community, and culture collide. The boundaries between the physical and digital worlds are blurring.
Try a Red Bean.
The text begins with Azuki's intention in the space. It's a community-made metaverse brand. Then it goes into more detail about Azuki's plans. Initiation of a story or journey. "Would you like to take the red bean and jump down the rabbit hole with us?" I love the Matrix red pill or blue pill play they used. (Azuki in Japanese means red bean.)
Morpheus, the rebel leader, offers Neo the choice of a red or blue pill in The Matrix. “You take the blue pill... After the story, you go back to bed and believe whatever you want. Your red pill... Let me show you how deep the rabbit hole goes.” Aware that the red pill will free him from the enslaving control of the machine-generated dream world and allow him to escape into the real world, he takes it. However, living the “truth of reality” is harsher and more difficult.
It's intriguing and draws you in. Taking the red bean causes what? Where am I going? I think they did well in piqueing a newcomer's interest.
Not convinced by the Garden? Read the Manifesto. It reinforces Azuki's role.
Here comes a new wave…
And surfing here is different.
Breaking down barriers.
Building open communities.
Creating magic internet money with our friends.
To those who don’t get it, we tell them: gm.
They’ll come around eventually.
Here’s to the ones with the courage to jump down a peculiar rabbit hole.
One that pulls you away from a world that’s created by many and owned by few…
To a world that’s created by more and owned by all.
From The Garden come the human beans that sprout into your family.
We rise together.
We build together.
We grow together.
Ready to take the red bean?
Not to mention the Mindmap, it sets Azuki apart from other projects and overused Roadmaps. I like how the team recognizes that the NFT space is not linear. So many of us are still trying to figure it out. It is Azuki's vision to adapt to changing environments while maintaining their values. I admire their commitment to long-term growth.
Conclusion
To be honest, I have no idea what the future holds. Azuki is still new and could fail. But I'm a long-term Azuki fan. I don't care about quick gains. The future looks bright for Azuki. I believe in the team's output. I love being an Azuki.
Thank you! IKUZO!
Full post here