



More on Technology

Nikhil Vemu
3 years ago
7 Mac Apps That Are Exorbitantly Priced But Totally Worth It

Wish you more bang for your buck
By ‘Cost a Bomb’ I didn’t mean to exaggerate. It’s an idiom that means ‘To be very expensive’. In fact, no app on the planet costs a bomb lol.
So, to the point.
Chronicle
(Freemium. For Pro, $24.99 | Available on Setapp)
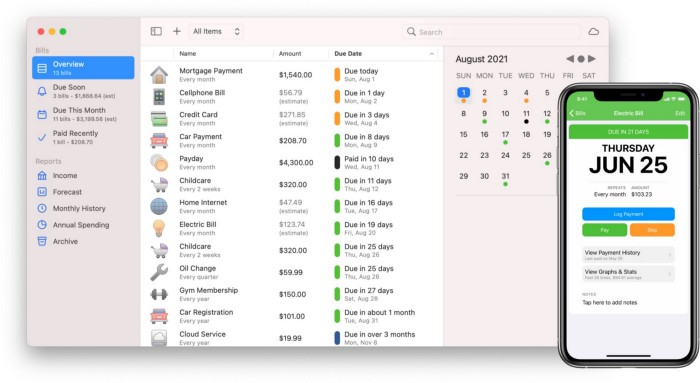
You probably have trouble keeping track of dozens of bills and subscriptions each month.
Try Chronicle.
Easy-to-use app
Add payment due dates and receive reminders,
Save payment documentation,
Analyze your spending by season, year, and month.
Observe expenditure trends and create new budgets.
Best of all, Chronicle features an integrated browser for fast payment and logging.
iOS and macOS sync.
SoundSource
($39 for lifetime)
Background Music, a free macOS program, was featured in #6 of this post last month.
It controls per-app volume, stereo balance, and audio over its max level.
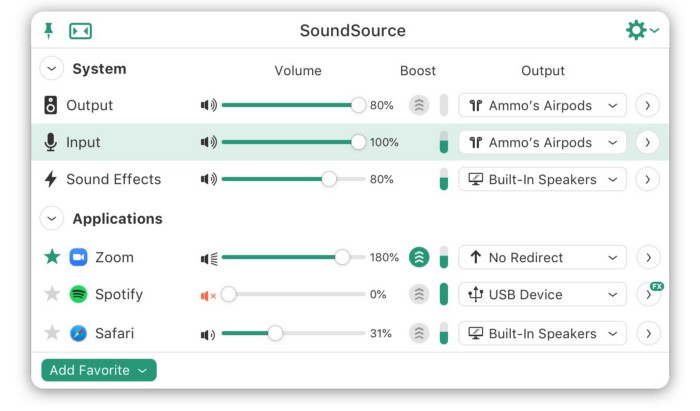
Background Music is fully supported. Additionally,
Connect various speakers to various apps (Wow! ),
change the audio sample rate for each app,
To facilitate access, add a floating SoundSource window.
Use its blocks in Shortcuts app,
On the menu bar, include meters for output/input devices and running programs.
PixelSnap
($39 for lifetime | Available on Setapp)
This software is heaven for UI designers.
It aids you.
quickly calculate screen distances (in pixels) ,
Drag an area around an object to determine its borders,

Measure the distances between the additional guides,

screenshots should be pixel-perfect.
What’s more.
You can
Adapt your tolerance for items with poor contrast and shadows.
Use your Touch Bar to perform important tasks, if you have one.
Mate Translation
($3.99 a month / $29.99 a year | Available on Setapp)
Mate Translate resembles a roided-up version of BarTranslate, which I wrote about in #1 of this piece last month.
If you translate often, utilize Mate Translate on macOS and Safari.
I'm really vocal about it.
It stays on the menu bar, and is accessible with a click or ⌥+shift+T hotkey.
It lets you
Translate in 103 different languages,
To translate text, double-click or right-click on it.
Totally translate websites. Additionally, Netflix subtitles,
Listen to their pronunciation to see how close it is to human.
iPhone and Mac sync Mate-ing history.
Swish
($16 for lifetime | Available on Setapp)
Swish is awesome!
Swipe, squeeze, tap, and hold movements organize chaotic desktop windows. Swish operates with mouse and trackpad.
Some gestures:
• Pinch Once: Close an app
• Pinch Twice: Quit an app
• Swipe down once: Minimise an app
• Pinch Out: Enter fullscreen mode
• Tap, Hold, & Swipe: Arrange apps in grids
and many more...

After getting acquainted to the movements, your multitasking will improve.
Unite
($24.99 for lifetime | Available on Setapp)
It turns webapps into macOS apps. The end.
Unite's functionality is a million times better.

Provide extensive customization (incl. its icon, light and dark modes)
make menu bar applications,
Get badges for web notifications and automatically refresh websites,
Replace any dock icon in the window with it (Wow!) by selecting that portion of the window.

Use PiP (Picture-in-Picture) on video sites that support it.
Delete advertising,
Throughout macOS, use floating windows
and many more…
I feel $24.99 one-off for this tool is a great deal, considering all these features. What do you think?
CleanShot X
(Basic: $29 one-off. Pro: $8/month | Available on Setapp)

CleanShot X can achieve things the macOS screenshot tool cannot. Complete screenshot toolkit.
CleanShot X, like Pixel Snap 2 (#3), is fantastic.
Allows
Scroll to capture a long page,
screen recording,
With webcam on,
• With mic and system audio,
• Highlighting mouse clicks and hotkeys.
Maintain floating screenshots for reference
While capturing, conceal desktop icons and notifications.
Recognize text in screenshots (OCR),
You may upload and share screenshots using the built-in cloud.
These are just 6 in 50+ features, and you’re already saying Wow!

Enrique Dans
3 years ago
You may not know about The Merge, yet it could change society

Ethereum is the second-largest cryptocurrency. The Merge, a mid-September event that will convert Ethereum's consensus process from proof-of-work to proof-of-stake if all goes according to plan, will be a game changer.
Why is Ethereum ditching proof-of-work? Because it can. We're talking about a fully functioning, open-source ecosystem with a capacity for evolution that other cryptocurrencies lack, a change that would allow it to scale up its performance from 15 transactions per second to 100,000 as its blockchain is used for more and more things. It would reduce its energy consumption by 99.95%. Vitalik Buterin, the system's founder, would play a less active role due to decentralization, and miners, who validated transactions through proof of work, would be far less important.
Why has this conversion taken so long and been so cautious? Because it involves modifying a core process while it's running to boost its performance. It requires running the new mechanism in test chains on an ever-increasing scale, assessing participant reactions, and checking for issues or restrictions. The last big test was in early June and was successful. All that's left is to converge the mechanism with the Ethereum blockchain to conclude the switch.
What's stopping Bitcoin, the leader in market capitalization and the cryptocurrency that began blockchain's appeal, from doing the same? Satoshi Nakamoto, whoever he or she is, departed from public life long ago, therefore there's no community leadership. Changing it takes a level of consensus that is impossible to achieve without strong leadership, which is why Bitcoin's evolution has been sluggish and conservative, with few modifications.
Secondly, The Merge will balance the consensus mechanism (proof-of-work or proof-of-stake) and the system decentralization or centralization. Proof-of-work prevents double-spending, thus validators must buy hardware. The system works, but it requires a lot of electricity and, as it scales up, tends to re-centralize as validators acquire more hardware and the entire network activity gets focused in a few nodes. Larger operations save more money, which increases profitability and market share. This evolution runs opposed to the concept of decentralization, and some anticipate that any system that uses proof of work as a consensus mechanism will evolve towards centralization, with fewer large firms able to invest in efficient network nodes.
Yet radical bitcoin enthusiasts share an opposite argument. In proof-of-stake, transaction validators put their funds at stake to attest that transactions are valid. The algorithm chooses who validates each transaction, giving more possibilities to nodes that put more coins at stake, which could open the door to centralization and government control.
In both cases, we're talking about long-term changes, but Bitcoin's proof-of-work has been evolving longer and seems to confirm those fears, while proof-of-stake is only employed in coins with a minuscule volume compared to Ethereum and has no predictive value.
As of mid-September, we will have two significant cryptocurrencies, each with a different consensus mechanisms and equally different characteristics: one is intrinsically conservative and used only for economic transactions, while the other has been evolving in open source mode, and can be used for other types of assets, smart contracts, or decentralized finance systems. Some even see it as the foundation of Web3.
Many things could change before September 15, but The Merge is likely to be a turning point. We'll have to follow this closely.

M.G. Siegler
3 years ago
G3nerative
Generative AI hype: some thoughts

The sudden surge in "generative AI" startups and projects feels like the inverse of the recent "web3" boom. Both came from hyped-up pots. But while web3 hyped idealistic tech and an easy way to make money, generative AI hypes unsettling tech and questions whether it can be used to make money.
Web3 is technology looking for problems to solve, while generative AI is technology creating almost too many solutions. Web3 has been evangelists trying to solve old problems with new technology. As Generative AI evolves, users are resolving old problems in stunning new ways.
It's a jab at web3, but it's true. Web3's hype, including crypto, was unhealthy. Always expected a tech crash and shakeout. Tech that won't look like "web3" but will enhance "web2"
But that doesn't mean AI hype is healthy. There'll be plenty of bullshit here, too. As moths to a flame, hype attracts charlatans. Again, the difference is the different starting point. People want to use it. Try it.
With the beta launch of Dall-E 2 earlier this year, a new class of consumer product took off. Midjourney followed suit (despite having to jump through the Discord server hoops). Twelve more generative art projects. Lensa, Prisma Labs' generative AI self-portrait project, may have topped the hype (a startup which has actually been going after this general space for quite a while). This week, ChatGPT went off-topic.
This has a "fake-it-till-you-make-it" vibe. We give these projects too much credit because they create easy illusions. This also unlocks new forms of creativity. And faith in new possibilities.
As a user, it's thrilling. We're just getting started. These projects are not only fun to play with, but each week brings a new breakthrough. As an investor, it's all happening so fast, with so much hype (and ethical and societal questions), that no one knows how it will turn out. Web3's demand won't be the issue. Too much demand may cause servers to melt down, sending costs soaring. Companies will try to mix rapidly evolving tech to meet user demand and create businesses. Frustratingly difficult.
Anyway, I wanted an excuse to post some Lensa selfies.

These are really weird. I recognize them as me or a version of me, but I have no memory of them being taken. It's surreal, out-of-body. Uncanny Valley.
You might also like

The woman
3 years ago
Why Google's Hiring Process is Brilliant for Top Tech Talent
Without a degree and experience, you can get a high-paying tech job.

Most organizations follow this hiring rule: you chat with HR, interview with your future boss and other senior managers, and they make the final hiring choice.
If you've ever applied for a job, you know how arduous it can be. A newly snapped photo and a glossy resume template can wear you out. Applying to Google can change this experience.
According to an Universum report, Google is one of the world's most coveted employers. It's not simply the search giant's name and reputation that attract candidates, but its role requirements or lack thereof.
Candidates no longer need a beautiful resume, cover letter, Ivy League laurels, or years of direct experience. The company requires no degree or experience.
Elon Musk started it. He employed the two-hands test to uncover talented non-graduates. The billionaire eliminated the requirement for experience.
Google is deconstructing traditional employment with programs like the Google Project Management Degree, a free online and self-paced professional credential course.
Google's hiring is interesting. After its certification course, applicants can work in project management. Instead of academic degrees and experience, the company analyzes coursework.
Google finds the best project managers and technical staff in exchange. Google uses three strategies to find top talent.
Chase down the innovators
Google eliminates restrictions like education, experience, and others to find the polar bear amid the snowfall. Google's free project management education makes project manager responsibilities accessible to everyone.
Many jobs don't require a degree. Overlooking individuals without a degree can make it difficult to locate a candidate who can provide value to a firm.
Firsthand knowledge follows the same rule. A lack of past information might be an employer's benefit. This is true for creative teams or businesses that prefer to innovate.
Or when corporations conduct differently from the competition. No-experience candidates can offer fresh perspectives. Fast Company reports that people with no sales experience beat those with 10 to 15 years of experience.
Give the aptitude test first priority.
Google wants the best candidates. Google wouldn't be able to receive more applications if it couldn't screen them for fit. Its well-organized online training program can be utilized as a portfolio.
Google learns a lot about an applicant through completed assignments. It reveals their ability, leadership style, communication capability, etc. The course mimics the job to assess candidates' suitability.
Basic screening questions might provide information to compare candidates. Any size small business can use screening questions and test projects to evaluate prospective employees.
Effective training for employees
Businesses must train employees regardless of their hiring purpose. Formal education and prior experience don't guarantee success. Maintaining your employees' professional knowledge gaps is key to their productivity and happiness. Top-notch training can do that. Learning and development are key to employee engagement, says Bob Nelson, author of 1,001 Ways to Engage Employees.
Google's online certification program isn't available everywhere. Improving the recruiting process means emphasizing aptitude over experience and a degree. Instead of employing new personnel and having them work the way their former firm trained them, train them how you want them to function.
If you want to know more about Google’s recruiting process, we recommend you watch the movie “Internship.”

cdixon
3 years ago
2000s Toys, Secrets, and Cycles
During the dot-com bust, I started my internet career. People used the internet intermittently to check email, plan travel, and do research. The average internet user spent 30 minutes online a day, compared to 7 today. To use the internet, you had to "log on" (most people still used dial-up), unlike today's always-on, high-speed mobile internet. In 2001, Amazon's market cap was $2.2B, 1/500th of what it is today. A study asked Americans if they'd adopt broadband, and most said no. They didn't see a need to speed up email, the most popular internet use. The National Academy of Sciences ranked the internet 13th among the 100 greatest inventions, below radio and phones. The internet was a cool invention, but it had limited uses and wasn't a good place to build a business.
A small but growing movement of developers and founders believed the internet could be more than a read-only medium, allowing anyone to create and publish. This is web 2. The runner up name was read-write web. (These terms were used in prominent publications and conferences.)
Web 2 concepts included letting users publish whatever they want ("user generated content" was a buzzword), social graphs, APIs and mashups (what we call composability today), and tagging over hierarchical navigation. Technical innovations occurred. A seemingly simple but important one was dynamically updating web pages without reloading. This is now how people expect web apps to work. Mobile devices that could access the web were niche (I was an avid Sidekick user).
The contrast between what smart founders and engineers discussed over dinner and on weekends and what the mainstream tech world took seriously during the week was striking. Enterprise security appliances, essentially preloaded servers with security software, were a popular trend. Many of the same people would talk about "serious" products at work, then talk about consumer internet products and web 2. It was tech's biggest news. Web 2 products were seen as toys, not real businesses. They were hobbies, not work-related.
There's a strong correlation between rich product design spaces and what smart people find interesting, which took me some time to learn and led to blog posts like "The next big thing will start out looking like a toy" Web 2's novel product design possibilities sparked dinner and weekend conversations. Imagine combining these features. What if you used this pattern elsewhere? What new product ideas are next? This excited people. "Serious stuff" like security appliances seemed more limited.
The small and passionate web 2 community also stood out. I attended the first New York Tech meetup in 2004. Everyone fit in Meetup's small conference room. Late at night, people demoed their software and chatted. I have old friends. Sometimes I get asked how I first met old friends like Fred Wilson and Alexis Ohanian. These topics didn't interest many people, especially on the east coast. We were friends. Real community. Alex Rampell, who now works with me at a16z, is someone I met in 2003 when a friend said, "Hey, I met someone else interested in consumer internet." Rare. People were focused and enthusiastic. Revolution seemed imminent. We knew a secret nobody else did.
My web 2 startup was called SiteAdvisor. When my co-founders and I started developing the idea in 2003, web security was out of control. Phishing and spyware were common on Internet Explorer PCs. SiteAdvisor was designed to warn users about security threats like phishing and spyware, and then, using web 2 concepts like user-generated reviews, add more subjective judgments (similar to what TrustPilot seems to do today). This staged approach was common at the time; I called it "Come for the tool, stay for the network." We built APIs, encouraged mashups, and did SEO marketing.
Yahoo's 2005 acquisitions of Flickr and Delicious boosted web 2 in 2005. By today's standards, the amounts were small, around $30M each, but it was a signal. Web 2 was assumed to be a fun hobby, a way to build cool stuff, but not a business. Yahoo was a savvy company that said it would make web 2 a priority.
As I recall, that's when web 2 started becoming mainstream tech. Early web 2 founders transitioned successfully. Other entrepreneurs built on the early enthusiasts' work. Competition shifted from ideation to execution. You had to decide if you wanted to be an idealistic indie bar band or a pragmatic stadium band.
Web 2 was booming in 2007 Facebook passed 10M users, Twitter grew and got VC funding, and Google bought YouTube. The 2008 financial crisis tested entrepreneurs' resolve. Smart people predicted another great depression as tech funding dried up.
Many people struggled during the recession. 2008-2011 was a golden age for startups. By 2009, talented founders were flooding Apple's iPhone app store. Mobile apps were booming. Uber, Venmo, Snap, and Instagram were all founded between 2009 and 2011. Social media (which had replaced web 2), cloud computing (which enabled apps to scale server side), and smartphones converged. Even if social, cloud, and mobile improve linearly, the combination could improve exponentially.
This chart shows how I view product and financial cycles. Product and financial cycles evolve separately. The Nasdaq index is a proxy for the financial sentiment. Financial sentiment wildly fluctuates.
Next row shows iconic startup or product years. Bottom-row product cycles dictate timing. Product cycles are more predictable than financial cycles because they follow internal logic. In the incubation phase, enthusiasts build products for other enthusiasts on nights and weekends. When the right mix of technology, talent, and community knowledge arrives, products go mainstream. (I show the biggest tech cycles in the chart, but smaller ones happen, like web 2 in the 2000s and fintech and SaaS in the 2010s.)
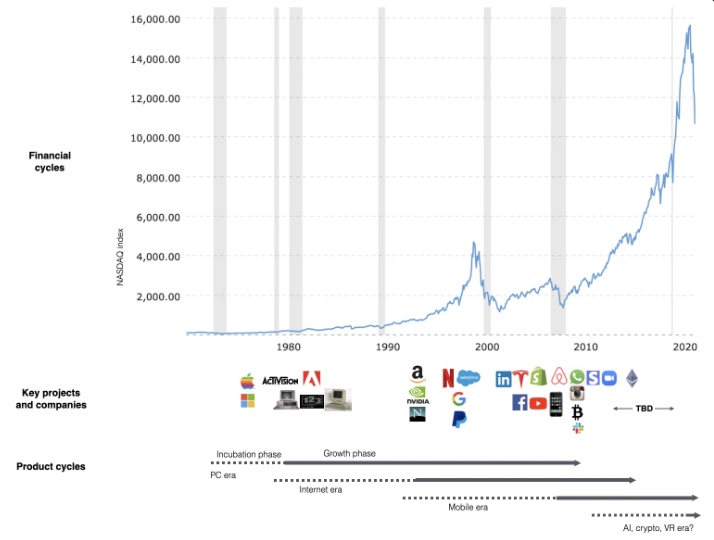
Tech has changed since the 2000s. Few tech giants dominate the internet, exerting economic and cultural influence. In the 2000s, web 2 was ignored or dismissed as trivial. Entrenched interests respond aggressively to new movements that could threaten them. Creative patterns from the 2000s continue today, driven by enthusiasts who see possibilities where others don't. Know where to look. Crypto and web 3 are where I'd start.
Today's negative financial sentiment reminds me of 2008. If we face a prolonged downturn, we can learn from 2008 by preserving capital and focusing on the long term. Keep an eye on the product cycle. Smart people are interested in things with product potential. This becomes true. Toys become necessities. Hobbies become mainstream. Optimists build the future, not cynics.
Full article is available here

Sam Hickmann
4 years ago
Improving collaboration with the Six Thinking Hats
Six Thinking Hats was written by Dr. Edward de Bono. "Six Thinking Hats" and parallel thinking allow groups to plan thinking processes in a detailed and cohesive way, improving collaboration.
Fundamental ideas
In order to develop strategies for thinking about specific issues, the method assumes that the human brain thinks in a variety of ways that can be intentionally challenged. De Bono identifies six brain-challenging directions. In each direction, the brain brings certain issues into conscious thought (e.g. gut instinct, pessimistic judgement, neutral facts). Some may find wearing hats unnatural, uncomfortable, or counterproductive.
The example of "mismatch" sensitivity is compelling. In the natural world, something out of the ordinary may be dangerous. This mode causes negative judgment and critical thinking.
Colored hats represent each direction. Putting on a colored hat symbolizes changing direction, either literally or metaphorically. De Bono first used this metaphor in his 1971 book "Lateral Thinking for Management" to describe a brainstorming framework. These metaphors allow more complete and elaborate thought separation. Six thinking hats indicate ideas' problems and solutions.
Similarly, his CoRT Thinking Programme introduced "The Five Stages of Thinking" method in 1973.
| HAT | OVERVIEW | TECHNIQUE |
|---|---|---|
| BLUE | "The Big Picture" & Managing | CAF (Consider All Factors); FIP (First Important Priorities) |
| WHITE | "Facts & Information" | Information |
| RED | "Feelings & Emotions" | Emotions and Ego |
| BLACK | "Negative" | PMI (Plus, Minus, Interesting); Evaluation |
| YELLOW | "Positive" | PMI |
| GREEN | "New Ideas" | Concept Challenge; Yes, No, Po |
Strategies and programs
After identifying the six thinking modes, programs can be created. These are groups of hats that encompass and structure the thinking process. Several of these are included in the materials for franchised six hats training, but they must often be adapted. Programs are often "emergent," meaning the group plans the first few hats and the facilitator decides what to do next.
The group agrees on how to think, then thinks, then evaluates the results and decides what to do next. Individuals or groups can use sequences (and indeed hats). Each hat is typically used for 2 minutes at a time, although an extended white hat session is common at the start of a process to get everyone on the same page. The red hat is recommended to be used for a very short period to get a visceral gut reaction – about 30 seconds, and in practice often takes the form of dot-voting.
| ACTIVITY | HAT SEQUENCE |
|---|---|
| Initial Ideas | Blue, White, Green, Blue |
| Choosing between alternatives | Blue, White, (Green), Yellow, Black, Red, Blue |
| Identifying Solutions | Blue, White, Black, Green, Blue |
| Quick Feedback | Blue, Black, Green, Blue |
| Strategic Planning | Blue, Yellow, Black, White, Blue, Green, Blue |
| Process Improvement | Blue, White, White (Other People's Views), Yellow, Black, Green, Red, Blue |
| Solving Problems | Blue, White, Green, Red, Yellow, Black, Green, Blue |
| Performance Review | Blue, Red, White, Yellow, Black, Green, Blue |
Use
Speedo's swimsuit designers reportedly used the six thinking hats. "They used the "Six Thinking Hats" method to brainstorm, with a green hat for creative ideas and a black one for feasibility.
Typically, a project begins with extensive white hat research. Each hat is used for a few minutes at a time, except the red hat, which is limited to 30 seconds to ensure an instinctive gut reaction, not judgement. According to Malcolm Gladwell's "blink" theory, this pace improves thinking.
De Bono believed that the key to a successful Six Thinking Hats session was focusing the discussion on a particular approach. A meeting may be called to review and solve a problem. The Six Thinking Hats method can be used in sequence to explore the problem, develop a set of solutions, and choose a solution through critical examination.
Everyone may don the Blue hat to discuss the meeting's goals and objectives. The discussion may then shift to Red hat thinking to gather opinions and reactions. This phase may also be used to determine who will be affected by the problem and/or solutions. The discussion may then shift to the (Yellow then) Green hat to generate solutions and ideas. The discussion may move from White hat thinking to Black hat thinking to develop solution set criticisms.
Because everyone is focused on one approach at a time, the group is more collaborative than if one person is reacting emotionally (Red hat), another is trying to be objective (White hat), and another is critical of the points which emerge from the discussion (Black hat). The hats help people approach problems from different angles and highlight problem-solving flaws.