


More on Science

Will Lockett
3 years ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.

Sara_Mednick
3 years ago
Since I'm a scientist, I oppose biohacking
Understanding your own energy depletion and restoration is how to truly optimize

Hack has meant many bad things for centuries. In the 1800s, a hack was a meager horse used to transport goods.
Modern usage describes a butcher or ax murderer's cleaver chop. The 1980s programming boom distinguished elegant code from "hacks". Both got you to your goal, but the latter made any programmer cringe and mutter about changing the code. From this emerged the hacker trope, the friendless anti-villain living in a murky hovel lit by the computer monitor, eating junk food and breaking into databases to highlight security system failures or steal hotdog money.

Now, start-a-billion-dollar-business-from-your-garage types have shifted their sights from app development to DIY biology, coining the term "bio-hack". This is a required keyword and meta tag for every fitness-related podcast, book, conference, app, or device.
Bio-hacking involves bypassing your body and mind's security systems to achieve a goal. Many biohackers' initial goals were reasonable, like lowering blood pressure and weight. Encouraged by their own progress, self-determination, and seemingly exquisite control of their biology, they aimed to outsmart aging and death to live 180 to 1000 years (summarized well in this vox.com article).
With this grandiose north star, the hunt for novel supplements and genetic engineering began.
Companies selling do-it-yourself biological manipulations cite lab studies in mice as proof of their safety and success in reversing age-related diseases or promoting longevity in humans (the goal changes depending on whether a company is talking to the federal government or private donors).
The FDA is slower than science, they say. Why not alter your biochemistry by buying pills online, editing your DNA with a CRISPR kit, or using a sauna delivered to your home? How about a microchip or electrical stimulator?
What could go wrong?
I'm not the neo-police, making citizen's arrests every time someone introduces a new plumbing gadget or extrapolates from animal research on resveratrol or catechins that we should drink more red wine or eat more chocolate. As a scientist who's spent her career asking, "Can we get better?" I've come to view bio-hacking as misguided, profit-driven, and counterproductive to its followers' goals.
We're creatures of nature. Despite all the new gadgets and bio-hacks, we still use Roman plumbing technology, and the best way to stay fit, sharp, and happy is to follow a recipe passed down since the beginning of time. Bacteria, plants, and all natural beings are rhythmic, with alternating periods of high activity and dormancy, whether measured in seconds, hours, days, or seasons. Nature repeats successful patterns.
During the Upstate, every cell in your body is naturally primed and pumped full of glycogen and ATP (your cells' energy currencies), as well as cortisol, which supports your muscles, heart, metabolism, cognitive prowess, emotional regulation, and general "get 'er done" attitude. This big energy release depletes your batteries and requires the Downstate, when your subsystems recharge at the cellular level.
Downstates are when you give your heart a break from pumping nutrient-rich blood through your body; when you give your metabolism a break from inflammation, oxidative stress, and sympathetic arousal caused by eating fast food — or just eating too fast; or when you give your mind a chance to wander, think bigger thoughts, and come up with new creative solutions. When you're responding to notifications, emails, and fires, you can't relax.
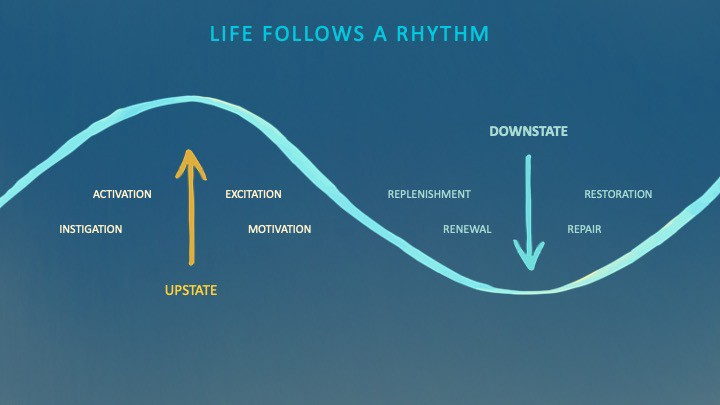
Downstates aren't just for consistently recharging your battery. By spending time in the Downstate, your body and brain get extra energy and nutrients, allowing you to grow smarter, faster, stronger, and more self-regulated. This state supports half-marathon training, exam prep, and mediation. As we age, spending more time in the Downstate is key to mental and physical health, well-being, and longevity.
When you prioritize energy-demanding activities during Upstate periods and energy-replenishing activities during Downstate periods, all your subsystems, including cardiovascular, metabolic, muscular, cognitive, and emotional, hum along at their optimal settings. When you synchronize the Upstates and Downstates of these individual rhythms, their functioning improves. A hard workout causes autonomic stress, which triggers Downstate recovery.
By choosing the right timing and type of exercise during the day, you can ensure a deeper recovery and greater readiness for the next workout by working with your natural rhythms and strengthening your autonomic and sleep Downstates.
Morning cardio workouts increase deep sleep compared to afternoon workouts. Timing and type of meals determine when your sleep hormone melatonin is released, ushering in sleep.
Rhythm isn't a hack. It's not a way to cheat the system or the boss. Nature has honed its optimization wisdom over trillions of days and nights. Stop looking for quick fixes. You're a whole system made of smaller subsystems that must work together to function well. No one pill or subsystem will make it all work. Understanding and coordinating your rhythms is free, easy, and only benefits you.
Dr. Sara C. Mednick is a cognitive neuroscientist at UC Irvine and author of The Power of the Downstate (HachetteGO)

Nojus Tumenas
3 years ago
NASA: Strange Betelgeuse Explosion Just Took Place

Orion's red supergiant Betelgeuse erupted. This is astronomers' most magnificent occurrence.
Betelgeuse, a supergiant star in Orion, garnered attention in 2019 for its peculiar appearance. It continued to dim in 2020.
The star was previously thought to explode as a supernova. Studying the event has revealed what happened to Betelgeuse since it happened.
Astronomers saw that the star released a large amount of material, causing it to lose a section of its surface.
They have never seen anything like this and are unsure what caused the star to release so much material.
According to Harvard-Smithsonian Center for Astrophysics astrophysicist Andrea Dupre, astronomers' data reveals an unexplained mystery.
They say it's a new technique to examine star evolution. The James Webb telescope revealed the star's surface features.
Corona flares are stellar mass ejections. These eruptions change the Sun's outer atmosphere.
This could affect power grids and satellite communications if it hits Earth.
Betelgeuse's flare ejected four times more material than the Sun's corona flare.
Astronomers have monitored star rhythms for 50 years. They've seen its dimming and brightening cycle start, stop, and repeat.
Monitoring Betelgeuse's pulse revealed the eruption's power.
Dupre believes the star's convection cells are still amplifying the blast's effects, comparing it to an imbalanced washing machine tub.
The star's outer layer has returned to normal, Hubble data shows. The photosphere slowly rebuilds its springy surface.
Dupre noted the star's unusual behavior. For instance, it’s causing its interior to bounce.
This suggests that the mass ejections that caused the star's surface to lose mass were two separate processes.
Researchers hope to better understand star mass ejection with the James Webb Space Telescope.
You might also like

Dr Mehmet Yildiz
3 years ago
How I train my brain daily for clarity and productivity.
I use a conceptual and practical system I developed decades ago as an example.

Since childhood, I've been interested in the brain-mind connection, so I developed a system using scientific breakthroughs, experiments, and the experiences of successful people in my circles.
This story provides a high-level overview of a custom system to inform and inspire readers. Creating a mind gym was one of my best personal and professional investments.
Such a complex system may not be possible for everyone or appear luxurious at first. However, the process and approach may help you find more accessible and viable solutions.
Visualizing the brain as a muscle, I learned to stimulate it with physical and mental exercises, applying a new mindset and behavioral changes.
My methods and practices may not work for others because we're all different. I focus on the approach's principles and highlights so you can create your own program.
Some create a conceptual and practical system intuitively, and others intellectually. Both worked. I see intellect and intuition as higher selves.
The mental tools I introduce are based on lifestyle changes and can be personalized by anyone, barring physical constraints or underlying health conditions.
Some people can't meditate despite wanting to due to mental constraints. This story lacks exceptions.
People's systems may vary. Many have used my tools successfully. All have scientific backing because their benefits attracted scientists. None are unethical or controversial.
My focus is cognition, which is the neocortex's ability. These practices and tools can affect the limbic and reptilian brain regions.
A previous article discussed brain health's biological aspects. This article focuses on psychology.
Thinking, learning, and remembering are cognitive abilities. Cognitive abilities determine our health and performance.
Cognitive health is the ability to think, concentrate, learn, and remember. Cognitive performance boosting involves various tools and processes. My system and protocols address cognitive health and performance.
As a biological organ, the brain's abilities decline with age, especially if not used regularly. Older people have more neurodegenerative disorders like dementia.
As aging is inevitable, I focus on creating cognitive reserves to remain mentally functional as we age and face mental decline or cognitive impairment.
My protocols focus on neurogenesis, or brain growth and maintenance. Neurons and connections can grow at any age.
Metacognition refers to knowing our cognitive abilities, like thinking about thinking and learning how to learn.
In the following sections, I provide an overview of my system, mental tools, and protocols.
This system summarizes my 50-year career. Some may find it too abstract, so I give examples.
First, explain the system. Section 2 introduces activities. Third, how to measure and maintain mental growth.
1 — Developed a practical mental gym.
The mental gym is a metaphor for the physical fitness gym to improve our mental muscles.
This concept covers brain and mind functionality. Integrated biological and psychological components.
I'll describe my mental gym so my other points make sense. My mental gym has physical and mental tools.
Mindfulness, meditation, visualization, self-conversations, breathing exercises, expressive writing, working in a flow state, reading, music, dance, isometric training, barefoot walking, cold/heat exposure, CBT, and social engagements are regular tools.
Dancing, walking, and thermogenesis are body-related tools. As the brain is part of the body and houses the mind, these tools can affect mental abilities such as attention, focus, memory, task switching, and problem-solving.
Different people may like different tools. I chose these tools based on my needs, goals, and lifestyle. They're just examples. You can choose tools that fit your goals and personality.
2 — Performed tasks regularly.
These tools gave me clarity. They became daily hobbies. Some I did alone, others with others.
Some examples: I meditate daily. Even though my overactive mind made daily meditation difficult at first, I now enjoy it. Meditation three times a day sharpens my mind.
Self-talk is used for self-therapy and creativity. Self-talk was initially difficult, but neurogenesis rewired my brain to make it a habit.
Cold showers, warm baths with Epsom salts, fasting, barefoot walks on the beach or grass, dancing, calisthenics, trampoline hopping, and breathing exercises increase my mental clarity, creativity, and productivity.
These exercises can increase BDNF, which promotes nervous system growth. They improve mental capacity and performance by increasing blood flow and brain oxygenation.
I use weekly and occasional activities like dry saunas, talking with others, and community activities.
These activities stimulate the brain and mind, improving performance and cognitive capacity.
3 — Measured progress, set growth goals.
Measuring progress helps us stay on track. Without data, it's hard to stay motivated. When we face inevitable setbacks, we may abandon our dreams.
I created a daily checklist for a spreadsheet with macros. I tracked how often and long I did each activity.
I measured my progress objectively and subjectively. In the progress spreadsheet, I noted my meditation hours and subjective feelings.
In another column, I used good, moderate, and excellent to get qualitative data. It took time and effort. Later, I started benefiting from this automated structure.
Creating a page for each activity, such as meditation, self-talk, cold showers, walking, expressive writing, personal interactions, etc., gave me empirical data I could analyze, modify, and graph to show progress.
Colored charts showed each area's strengths and weaknesses.
Strengths motivate me to continue them. Identifying weaknesses helped me improve them.
As the system matured, data recording became a habit and took less time. I saw the result immediately because I automated the charts when I entered daily data. Early time investment paid off later.
Mind Gym Benefits, Effective Use, and Progress Measuring
This concept helped me move from comfort to risk. I accept things as they are.
Turnarounds were made. I stopped feeling "Fight-Flight-Freeze" and maintained self-control.
I tamed my overactive amygdala by strengthening my brain. Stress and anxiety decreased. With these shifts, I accepted criticism and turned envy into admiration. Clarity improved.
When the cognitive part of the brain became stronger and the primitive part was tamed, managing thoughts and emotions became easier. My AQ increased. I learned to tolerate people, physical, mental, and emotional obstacles.
Accessing vast information sources in my subconscious mind through an improved RAS allowed me to easily tap into my higher self and recognize flaws in my lower self.
Summary
The brain loves patterns and routines, so habits help. Observing, developing, and monitoring habits mindfully can be beneficial. Mindfulness helps us achieve this goal systematically.
As body and mind are connected, we must consider both when building habits. Consistent and joyful practices can strengthen neurons and neural connections.
Habits help us accomplish more with less effort. Regularly using mental tools and processes can improve our cognitive health and performance as we age.
Creating daily habits to improve cognitive abilities can sharpen our minds and boost our well-being.
Some apps monitor our activities and behavior to help build habits. If you can't replicate my system, try these apps. Some smartwatches and fitness devices include them.
Set aside time each day for mental activities you enjoy. Regular scheduling and practice can strengthen brain regions and form habits. Once you form habits, tasks become easy.
Improving our minds is a lifelong journey. It's easier and more sustainable to increase our efforts daily, weekly, monthly, or annually.
Despite life's ups and downs, many want to remain calm and cheerful.
This valuable skill is unrelated to wealth or fame. It's about our mindset, fueled by our biological and psychological needs.
Here are some lessons I've learned about staying calm and composed despite challenges and setbacks.
1 — Tranquillity starts with observing thoughts and feelings.
2 — Clear the mental clutter and emotional entanglements with conscious breathing and gentle movements.
3 — Accept situations and events as they are with no resistance.
4 — Self-love can lead to loving others and increasing compassion.
5 — Count your blessings and cultivate gratitude.
Clear thinking can bring joy and satisfaction. It's a privilege to wake up with a healthy body and clear mind, ready to connect with others and serve them.
Thank you for reading my perspectives. I wish you a healthy and happy life.

Ivona Hirschi
3 years ago
7 LinkedIn Tips That Will Help in Audience Growth
In 8 months, I doubled my audience with them.

LinkedIn's buzz isn't over.
People dream of social proof every day. They want clients, interesting jobs, and field recognition.
LinkedIn coaches will benefit greatly. Sell learning? Probably. Can you use it?
Consistency has been key in my eight-month study of LinkedIn. However, I'll share seven of my tips. 700 to 4500 people followed me.
1. Communication, communication, communication
LinkedIn is a social network. I like to think of it as a cafe. Here, you can share your thoughts, meet friends, and discuss life and work.
Do not treat LinkedIn as if it were a board for your post-its.
More socializing improves relationships. It's about people, like any network.
Consider interactions. Three main areas:
Respond to criticism left on your posts.
Comment on other people's posts
Start and maintain conversations through direct messages.
Engage people. You spend too much time on Facebook if you only read your wall. Keeping in touch and having meaningful conversations helps build your network.
Every day, start a new conversation to make new friends.
2. Stick with those you admire
Interact thoughtfully.
Choose your contacts. Build your tribe is a term. Respectful networking.
I only had past colleagues, family, and friends in my network at the start of this year. Not business-friendly. Since then, I've sought out people I admire or can learn from.
Finding a few will help you. As they connect you to their networks. Friendships can lead to clients.
Don't underestimate network power. Cafe-style. Meet people at each table. But avoid people who sell SEO, web redesign, VAs, mysterious job opportunities, etc.
3. Share eye-catching infographics
Daily infographics flood LinkedIn. Visuals are popular. Use Canva's free templates if you can't draw them.
Last week's:

It's a fun way to visualize your topic.
You can repost and comment on infographics. Involve your network. I prefer making my own because I build my brand around certain designs.
My friend posted infographics consistently for four months and grew his network to 30,000.
If you start, credit the authors. As you steal someone's work.
4. Invite some friends over.
LinkedIn alone can be lonely. Having a few friends who support your work daily will boost your growth.
I was lucky to be invited to a group of networkers. We share knowledge and advice.
Having a few regulars who can discuss your posts is helpful. It's artificial, but it works and engages others.
Consider who you'd support if they were in your shoes.
You can pay for an engagement group, but you risk supporting unrelated people with rubbish posts.
Help each other out.
5. Don't let your feed or algorithm divert you.
LinkedIn's algorithm is magical.
Which time is best? How fast do you need to comment? Which days are best?
Overemphasize algorithms. Consider the user. No need to worry about the best time.
Remember to spend time on LinkedIn actively. Not passively. That is what Facebook is for.
Surely someone would find a LinkedIn recipe. Don't beat the algorithm yet. Consider your audience.
6. The more personal, the better
Personalization isn't limited to selfies. Share your successes and failures.
The more personality you show, the better.
People relate to others, not theories or quotes. Why should they follow you? Everyone posts the same content?
Consider your friends. What's their appeal?
Because they show their work and identity. It's simple. Medium and Linkedin are your platforms. Find out what works.
You can copy others' hooks and structures. You decide how simple to make it, though.
7. Have fun with those who have various post structures.
I like writing, infographics, videos, and carousels. Because you can:
Repurpose your content!
Out of one blog post I make:
Newsletter
Infographics (positive and negative points of view)
Carousel
Personal stories
Listicle
Create less but more variety. Since LinkedIn posts last 24 hours, you can rotate the same topics for weeks without anyone noticing.
Effective!
The final LI snippet to think about
LinkedIn is about consistency. Some say 15 minutes. If you're serious about networking, spend more time there.
The good news is that it is worth it. The bad news is that it takes time.

Ben Carlson
3 years ago
Bear market duration and how to invest during one

Bear markets don't last forever, but that's hard to remember. Jamie Cullen's illustration
A bear market is a 20% decline from peak to trough in stock prices.
The S&P 500 was down 24% from its January highs at its low point this year. Bear market.
The U.S. stock market has had 13 bear markets since WWII (including the current one). Previous 12 bear markets averaged –32.7% losses. From peak to trough, the stock market averaged 12 months. The average time from bottom to peak was 21 months.
In the past seven decades, a bear market roundtrip to breakeven has averaged less than three years.
Long-term averages can vary widely, as with all historical market data. Investors can learn from past market crashes.
Historical bear markets offer lessons.
Bear market duration
A bear market can cost investors money and time. Most of the pain comes from stock market declines, but bear markets can be long.
Here are the longest U.S. stock bear markets since World war 2:
Stock market crashes can make it difficult to break even. After the 2008 financial crisis, the stock market took 4.5 years to recover. After the dotcom bubble burst, it took seven years to break even.
The longer you're underwater in the market, the more suffering you'll experience, according to research. Suffering can lead to selling at the wrong time.
Bear markets require patience because stocks can take a long time to recover.
Stock crash recovery
Bear markets can end quickly. The Corona Crash in early 2020 is an example.
The S&P 500 fell 34% in 23 trading sessions, the fastest bear market from a high in 90 years. The entire crash lasted one month. Stocks broke even six months after bottoming. Stocks rose 100% from those lows in 15 months.
Seven bear markets have lasted two years or less since 1945.
The 2020 recovery was an outlier, but four other bear markets have made investors whole within 18 months.
During a bear market, you don't know if it will end quickly or feel like death by a thousand cuts.
Recessions vs. bear markets
Many people believe the U.S. economy is in or heading for a recession.
I agree. Four-decade high inflation. Since 1945, inflation has exceeded 5% nine times. Each inflationary spike caused a recession. Only slowing economic demand seems to stop price spikes.
This could happen again. Stocks seem to be pricing in a recession.
Recessions almost always cause a bear market, but a bear market doesn't always equal a recession. In 1946, the stock market fell 27% without a recession in sight. Without an economic slowdown, the stock market fell 22% in 1966. Black Monday in 1987 was the most famous stock market crash without a recession. Stocks fell 30% in less than a week. Many believed the stock market signaled a depression. The crash caused no slowdown.
Economic cycles are hard to predict. Even Wall Street makes mistakes.
Bears vs. bulls
Bear markets for U.S. stocks always end. Every stock market crash in U.S. history has been followed by new all-time highs.
How should investors view the recession? Investing risk is subjective.
You don't have as long to wait out a bear market if you're retired or nearing retirement. Diversification and liquidity help investors with limited time or income. Cash and short-term bonds drag down long-term returns but can ensure short-term spending.
Young people with years or decades ahead of them should view this bear market as an opportunity. Stock market crashes are good for net savers in the future. They let you buy cheap stocks with high dividend yields.
You need discipline, patience, and planning to buy stocks when it doesn't feel right.
Bear markets aren't fun because no one likes seeing their portfolio fall. But stock market downturns are a feature, not a bug. If stocks never crashed, they wouldn't offer such great long-term returns.