


More on Personal Growth

NonConformist
3 years ago
Before 6 AM, read these 6 quotations.
These quotes will change your perspective.

I try to reflect on these quotes daily. Reading it in the morning can affect your day, decisions, and priorities. Let's start.
1. Friedrich Nietzsche once said, "He who has a why to live for can bear almost any how."
What's your life goal?
80% of people don't know why they live or what they want to accomplish in life if you ask them randomly.
Even those with answers may not pursue their why. Without a purpose, life can be dull.
Your why can guide you through difficult times.
Create a life goal. Growing may change your goal. Having a purpose in life prevents feeling lost.

2. Seneca said, "He who fears death will never do anything fit for a man in life."
FAILURE STINKS Yes.
This quote is great if you're afraid to try because of failure. What if I'm not made for it? What will they think if I fail?
This wastes most of our lives. Many people prefer not failing over trying something with a better chance of success, according to studies.
Failure stinks in the short term, but it can transform our lives over time.

3. Two men peered through the bars of their cell windows; one saw mud, the other saw stars. — Dale Carnegie
It’s not what you look at that matters; it’s what you see.
The glass-full-or-empty meme is everywhere. It's hard to be positive when facing adversity.
This is a skill. Positive thinking can change our future.
We should stop complaining about our life and how easy success is for others.
Seductive pessimism. Realize this and start from first principles.

4. “Smart people learn from everything and everyone, average people from their experiences, and stupid people already have all the answers.” — Socrates.
Knowing we're ignorant can be helpful.
Every person and situation teaches you something. You can learn from others' experiences so you don't have to. Analyzing your and others' actions and applying what you learn can be beneficial.
Reading (especially non-fiction or biographies) is a good use of time. Walter Issacson wrote Benjamin Franklin's biography. Ben Franklin's early mistakes and successes helped me in some ways.
Knowing everything leads to disaster. Every incident offers lessons.

5. “We must all suffer one of two things: the pain of discipline or the pain of regret or disappointment.“ — James Rohn
My favorite Jim Rohn quote.
Exercise hurts. Healthy eating can be painful. But they're needed to get in shape. Avoiding pain can ruin our lives.
Always choose progress over hopelessness. Myth: overnight success Everyone who has mastered a craft knows that mastery comes from overcoming laziness.
Turn off your inner critic and start working. Try Can't Hurt Me by David Goggins.

6. “A champion is defined not by their wins, but by how they can recover when they fail.“ — Serena Williams
Have you heard of Traf-o-Data?
Gates and Allen founded Traf-O-Data. After some success, it failed. Traf-o-Data's failure led to Microsoft.
Allen said Traf-O-Data's setback was important for Microsoft's first product a few years later. Traf-O-Data was a business failure, but it helped them understand microprocessors, he wrote in 2017.
“The obstacle in the path becomes the path. Never forget, within every obstacle is an opportunity to improve our condition.” — Ryan Holiday.
Bonus Quotes
More helpful quotes:
“Those who cannot change their minds cannot change anything.” — George Bernard Shaw.
“Do something every day that you don’t want to do; this is the golden rule for acquiring the habit of doing your duty without pain.” — Mark Twain.
“Never give up on a dream just because of the time it will take to accomplish it. The time will pass anyway.” — Earl Nightingale.
“A life spent making mistakes is not only more honorable, but more useful than a life spent doing nothing.” — George Bernard Shaw.
“We don’t stop playing because we grow old; we grow old because we stop playing.” — George Bernard Shaw.
Conclusion
Words are powerful. Utilize it. Reading these inspirational quotes will help you.

Darius Foroux
2 years ago
My financial life was changed by a single, straightforward mental model.
Prioritize big-ticket purchases
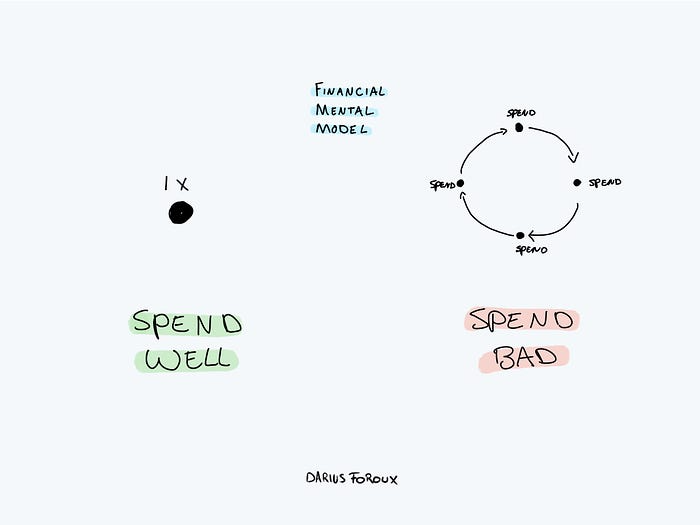
I've made several spending blunders. I get sick thinking about how much money I spent.
My financial mental model was poor back then.
Stoicism and mindfulness keep me from attaching to those feelings. It still hurts.
Until four or five years ago, I bought a new winter jacket every year.
Ten years ago, I spent twice as much. Now that I have a fantastic, warm winter parka, I don't even consider acquiring another one. No more spending. I'm not looking for jackets either.
Saving time and money by spending well is my thinking paradigm.
The philosophy is expressed in most languages. Cheap is expensive in the Netherlands. This applies beyond shopping.
In this essay, I will offer three examples of how this mental paradigm transformed my financial life.
Publishing books
In 2015, I presented and positioned my first book poorly.
I called the book Huge Life Success and made a funny Canva cover in 30 minutes. This:

That looks nothing like my present books. No logo or style. The book felt amateurish.
The book started bothering me a few weeks after publication. The advice was good, but it didn't appear professional. I studied the book business extensively.
I created a style for all my designs. Branding. Win Your Inner Wars was reissued a year later.
Title, cover, and description changed. Rearranging the chapters improved readability.
Seven years later, the book sells hundreds of copies a month. That taught me a lot.
Rushing to finish a project is enticing. Send it and move forward.
Avoid rushing everything. Relax. Develop your projects. Perform well. Perform the job well.
My first novel was underfunded and underworked. A bad book arrived. I then invested time and money in writing the greatest book I could.
That book still sells.
Traveling
I hate travel. Airports, flights, trains, and lines irritate me.
But, I enjoy traveling to beautiful areas.
I do it strangely. I make up travel rules. I never go to airports in summer. I hate being near airports on holidays. Unworthy.
No vacation packages for me. Those airline packages with a flight, shuttle, and hotel. I've had enough.
I try to avoid crowds and popular spots. July Paris? Nuts and bolts, please. Christmas in NYC? No, please keep me sane.
I fly business class behind. I accept upgrades upon check-in. I prefer driving. I drove from the Netherlands to southern Spain.
Thankfully, no lines. What if travel costs more? Thus? I enjoy it from the start. I start traveling then.
I rarely travel since I'm so difficult. One great excursion beats several average ones.
Personal effectiveness
New apps, tools, and strategies intrigue most productivity professionals.
No.
I researched years ago. I spent years investigating productivity in university.
I bought books, courses, applications, and tools. It was expensive and time-consuming.
Im finished. Productivity no longer costs me time or money. OK. I worked on it once and now follow my strategy.
I avoid new programs and systems. My stuff works. Why change winners?
Spending wisely saves time and money.
Spending wisely means spending once. Many people ignore productivity. It's understudied. No classes.
Some assume reading a few articles or a book is enough. Productivity is personal. You need a personal system.
Time invested is one-time. You can trust your system for life once you find it.
Concentrate on the expensive choices.
Life's short. Saving money quickly is enticing.
Spend less on groceries today. True. That won't fix your finances.
Adopt a lifestyle that makes you affluent over time. Consider major choices.
Are they causing long-term poverty? Are you richer?
Leasing cars comes to mind. The automobile costs a fortune today. The premium could accomplish a million nice things.
Focusing on important decisions makes life easier. Consider your future. You want to improve next year.

Datt Panchal
3 years ago
The Learning Habit

The Habit of Learning implies constantly learning something new. One daily habit will make you successful. Learning will help you succeed.
Most successful people continually learn. Success requires this behavior. Daily learning.
Success loves books. Books offer expert advice. Everything is online today. Most books are online, so you can skip the library. You must download it and study for 15-30 minutes daily. This habit changes your thinking.

Typical Successful People
Warren Buffett reads 500 pages of corporate reports and five newspapers for five to six hours each day.
Each year, Bill Gates reads 50 books.
Every two weeks, Mark Zuckerberg reads at least one book.
According to his brother, Elon Musk studied two books a day as a child and taught himself engineering and rocket design.
Learning & Making Money Online
No worries if you can't afford books. Everything is online. YouTube, free online courses, etc.

How can you create this behavior in yourself?
1) Consider what you want to know
Before learning, know what's most important. So, move together.
Set a goal and schedule learning.
After deciding what you want to study, create a goal and plan learning time.
3) GATHER RESOURCES
Get the most out of your learning resources. Online or offline.
You might also like

The woman
3 years ago
I received a $2k bribe to replace another developer in an interview
I can't believe they’d even think it works!

Developers are usually interviewed before being hired, right? Every organization wants candidates who meet their needs. But they also want to avoid fraud.
There are cheaters in every field. Only two come to mind for the hiring process:
Lying on a resume.
Cheating on an online test.
Recently, I observed another one. One of my coworkers invited me to replace another developer during an online interview! I was astonished, but it’s not new.
The specifics
My ex-colleague recently texted me. No one from your former office will ever approach you after a year unless they need something.
Which was the case. My coworker said his wife needed help as a programmer. I was glad someone asked for my help, but I'm still a junior programmer.
Then he informed me his wife was selected for a fantastic job interview. He said he could help her with the online test, but he needed someone to help with the online interview.
Okay, I guess. Preparing for an online interview is beneficial. But then he said she didn't need to be ready. She needed someone to take her place.
I told him it wouldn't work. Every remote online interview I've ever seen required an open camera.
What followed surprised me. She'd ask to turn off the camera, he said.
I asked why.
He told me if an applicant is unwell, the interviewer may consider an off-camera interview. His wife will say she's sick and prefers no camera.
The plan left me speechless. I declined politely. He insisted and promised $2k if she got the job.
I felt insulted and told him if he persisted, I'd inform his office. I was furious. Later, I apologized and told him to stop.
I'm not sure what they did after that
I'm not sure if they found someone or listened to me. They probably didn't. How would she do the job if she even got it?
It's an internship, he said. With great pay, though. What should an intern do?
I suggested she do the interview alone. Even if she failed, she'd gain confidence and valuable experience.
Conclusion
Many interviewees cheat. My profession is vital to me, thus I'd rather improve my abilities and apply honestly. It's part of my identity.
Am I truthful? Most professionals are not. They fabricate their CVs. Often.
When you support interview cheating, you encourage more cheating! When someone cheats, another qualified candidate may not obtain the job.
One day, that could be you or me.
Matthew Royse
3 years ago
5 Tips for Concise Writing
Here's how to be clear.
“I have only made this letter longer because I have not had the time to make it shorter.” — French mathematician, physicist, inventor, philosopher, and writer Blaise Pascal
Concise.
People want this. We tend to repeat ourselves and use unnecessary words.
Being vague frustrates readers. It focuses their limited attention span on figuring out what you're saying rather than your message.
Edit carefully.
“Examine every word you put on paper. You’ll find a surprising number that don’t serve any purpose.” — American writer, editor, literary critic, and teacher William Zinsser
How do you write succinctly?
Here are three ways to polish your writing.
1. Delete
Your readers will appreciate it if you delete unnecessary words. If a word or phrase is essential, keep it. Don't force it.
Many readers dislike bloated sentences. Ask yourself if cutting a word or phrase will change the meaning or dilute your message.
For example, you could say, “It’s absolutely essential that I attend this meeting today, so I know the final outcome.” It’s better to say, “It’s critical I attend the meeting today, so I know the results.”
Key takeaway
Delete actually, completely, just, full, kind of, really, and totally. Keep the necessary words, cut the rest.
2. Just Do It
Don't tell readers your plans. Your readers don't need to know your plans. Who are you?
Don't say, "I want to highlight our marketing's problems." Our marketing issues are A, B, and C. This cuts 5–7 words per sentence.
Keep your reader's attention on the essentials, not the fluff. What are you doing? You won't lose readers because you get to the point quickly and don't build up.
Key takeaway
Delete words that don't add to your message. Do something, don't tell readers you will.
3. Cut Overlap
You probably repeat yourself unintentionally. You may add redundant sentences when brainstorming. Read aloud to detect overlap.
Remove repetition from your writing. It's important to edit our writing and thinking to avoid repetition.
Key Takeaway
If you're repeating yourself, combine sentences to avoid overlap.
4. Simplify
Write as you would to family or friends. Communicate clearly. Don't use jargon. These words confuse readers.
Readers want specifics, not jargon. Write simply. Done.
Most adults read at 8th-grade level. Jargon and buzzwords make speech fluffy. This confuses readers who want simple language.
Key takeaway
Ensure all audiences can understand you. USA Today's 5th-grade reading level is intentional. They want everyone to understand.
5. Active voice
Subjects perform actions in active voice. When you write in passive voice, the subject receives the action.
For example, “the board of directors decided to vote on the topic” is an active voice, while “a decision to vote on the topic was made by the board of directors” is a passive voice.
Key takeaway
Active voice clarifies sentences. Active voice is simple and concise.
Bringing It All Together
Five tips help you write clearly. Delete, just do it, cut overlap, use simple language, and write in an active voice.
Clear writing is effective. It's okay to occasionally use unnecessary words or phrases. Realizing it is key. Check your writing.
Adding words costs.
Write more concisely. People will appreciate it and read your future articles, emails, and messages. Spending extra time will increase trust and influence.
“Not that the story need be long, but it will take a long while to make it short.” — Naturalist, essayist, poet, and philosopher Henry David Thoreau

Hector de Isidro
3 years ago
Why can't you speak English fluently even though you understand it?
Many of us have struggled for years to master a second language (in my case, English). Because (at least in my situation) we've always used an input-based system or method.
I'll explain in detail, but briefly: We can understand some conversations or sentences (since we've trained), but we can't give sophisticated answers or speak fluently (because we have NOT trained at all).
What exactly is input-based learning?
Reading, listening, writing, and speaking are key language abilities (if you look closely at that list, it seems that people tend to order them in this way: inadvertently giving more priority to the first ones than to the last ones).
These talents fall under two learning styles:
Reading and listening are input-based activities (sometimes referred to as receptive skills or passive learning).
Writing and speaking are output-based tasks (also known as the productive skills and/or active learning).
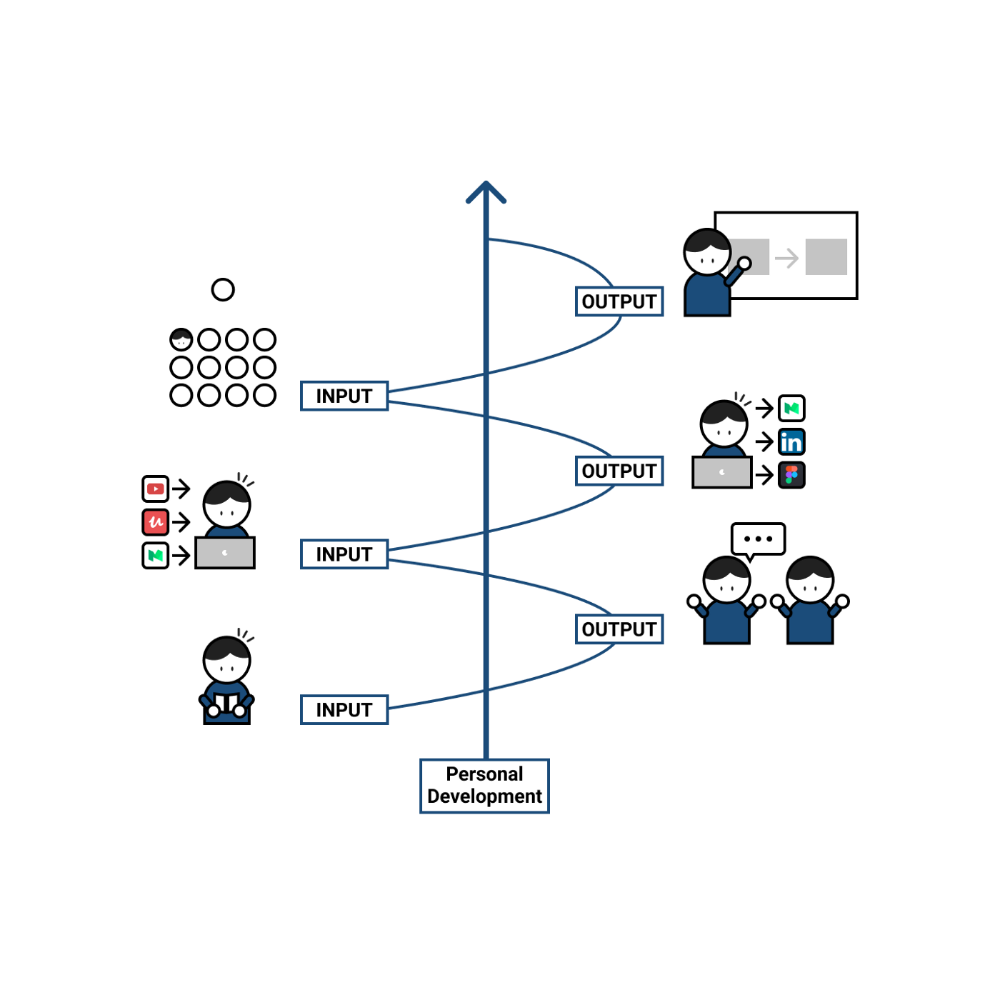
What's the best learning style? To learn a language, we must master four interconnected skills. The difficulty is how much time and effort we give each.
According to Shion Kabasawa's books The Power of Input: How to Maximize Learning and The Power of Output: How to Change Learning to Outcome (available only in Japanese), we spend 7:3 more time on Input Based skills than Output Based skills when we should be doing the opposite, leaning more towards Output (Input: Output->3:7).
I can't tell you how he got those numbers, but I think he's not far off because, for example, think of how many people say they're learning a second language and are satisfied bragging about it by only watching TV, series, or movies in VO (and/or reading a book or whatever) their Input is: 7:0 output!
You can't be good at a sport by watching TikTok videos about it; you must play.
“being pushed to produce language puts learners in a better position to notice the ‘gaps’ in their language knowledge”, encouraging them to ‘upgrade’ their existing interlanguage system. And, as they are pushed to produce language in real time and thereby forced to automate low-level operations by incorporating them into higher-level routines, it may also contribute to the development of fluency. — Scott Thornbury (P is for Push)
How may I practice output-based learning more?
I know that listening or reading is easy and convenient because we can do it on our own in a wide range of situations, even during another activity (although, as you know, it's not ideal), writing can be tedious/boring (it's funny that we almost always excuse ourselves in the lack of ideas), and speaking requires an interlocutor. But we must leave our comfort zone and modify our thinking to go from 3:7 to 7:3. (or at least balance it better to something closer). Gradually.
“You don’t have to do a lot every day, but you have to do something. Something. Every day.” — Callie Oettinger (Do this every day)
We can practice speaking like boxers shadow box.
Speaking out loud strengthens the mind-mouth link (otherwise, you will still speak fluently in your mind but you will choke when speaking out loud). This doesn't mean we should talk to ourselves on the way to work, while strolling, or on public transportation. We should try to do it without disturbing others, such as explaining what we've heard, read, or seen (the list is endless: you can TALK about what happened yesterday, your bedtime book, stories you heard at the office, that new kitten video you saw on Instagram, an experience you had, some new fact, that new boring episode you watched on Netflix, what you ate, what you're going to do next, your upcoming vacation, what’s trending, the news of the day)
Who will correct my grammar, vocabulary, or pronunciation with an imagined friend? We can't have everything, but tools and services can help [1].
Lack of bravery
Fear of speaking a language different than one's mother tongue in front of native speakers is global. It's easier said than done, because strangers, not your friends, will always make fun of your accent or faults. Accept it and try again. Karma will prevail.
Perfectionism is a trap. Stop self-sabotaging. Communication is key (and for that you have to practice the Output too ).
“Don’t forget to have fun and enjoy the process.” — Ruri Ohama
[1] Grammarly, Deepl, Google Translate, etc.