



More on Entrepreneurship/Creators

Eve Arnold
3 years ago
Your Ideal Position As a Part-Time Creator
Inspired by someone I never met

Inspiration is good and bad.
Paul Jarvis inspires me. He's a web person and writer who created his own category by being himself.
Paul said no thank you when everyone else was developing, building, and assuming greater responsibilities. This isn't success. He rewrote the rules. Working for himself, expanding at his own speed, and doing what he loves were his definitions of success.
Play with a problem that you have
The biggest problem can be not recognizing a problem.
Acceptance without question is deception. When you don't push limits, you forget how. You start thinking everything must be as it is.
For example: working. Paul worked a 9-5 agency work with little autonomy. He questioned whether the 9-5 was a way to live, not the way.
Another option existed. So he chipped away at how to live in this new environment.
Don't simply jump
Internet writers tell people considering quitting 9-5 to just quit. To throw in the towel. To do what you like.
The advice is harmful, despite the good intentions. People think quitting is hard. Like courage is the issue. Like handing your boss a resignation letter.
Nope. The tough part comes after. It’s easy to jump. Landing is difficult.
The landing
Paul didn't quit. Intelligent individuals don't. Smart folks focus on landing. They imagine life after 9-5.
Paul had been a web developer for a long time, had solid clients, and was respected. Hence if he pushed the limits and discovered another route, he had the potential to execute.
Working on the side
Society loves polarization. It’s left or right. Either way. Or chaos. It's 9-5 or entrepreneurship.
But like Paul, you can stretch polarization's limits. In-between exists.
You can work a 9-5 and side jobs (as I do). A mix of your favorites. The 9-5's stability and creativity. Fire and routine.
Remember you can't have everything but anything. You can create and work part-time.
My hybrid lifestyle
Not selling books doesn't destroy my world. My globe keeps spinning if my new business fails or if people don't like my Tweets. Unhappy algorithm? Cool. I'm not bothered (okay maybe a little).
The mix gives me the best of both worlds. To create, hone my skill, and grasp big-business basics. I like routine, but I also appreciate spending 4 hours on Saturdays writing.
Some days I adore leaving work at 5 pm and disconnecting. Other days, I adore having a place to write if inspiration strikes during a run or a discussion.
I’m a part-time creator
I’m a part-time creator. No, I'm not trying to quit. I don't work 5 pm - 2 am on the side. No, I'm not at $10,000 MRR.
I work part-time but enjoy my 9-5. My 9-5 has goodies. My side job as well.
It combines both to meet my lifestyle. I'm satisfied.
Join the Part-time Creators Club for free here. I’ll send you tips to enhance your creative game.

Tim Denning
3 years ago
Bills are paid by your 9 to 5. 6 through 12 help you build money.
40 years pass. After 14 years of retirement, you die. Am I the only one who sees the problem?

I’m the Jedi master of escaping the rat race.
Not to impress. I know this works since I've tried it. Quitting a job to make money online is worse than Kim Kardashian's internet-burning advice.
Let me help you rethink the move from a career to online income to f*ck you money.
To understand why a job is a joke, do some life math.
Without a solid why, nothing makes sense.
The retirement age is 65. Our processed food consumption could shorten our 79-year average lifespan.
You spend 40 years working.
After 14 years of retirement, you die.
Am I alone in seeing the problem?
Life is too short to work a job forever, especially since most people hate theirs. After-hours skills are vital.
Money equals unrestricted power, f*ck you.
F*ck you money is the answer.
Jack Raines said it first. He says we can do anything with the money. Jack, a young rebel straight out of college, can travel and try new foods.
F*ck you money signifies not checking your bank account before buying.
F*ck you” money is pure, unadulterated freedom with no strings attached.
Jack claims you're rich when you rarely think about money.
Avoid confusion.
This doesn't imply you can buy a Lamborghini. It indicates your costs, income, lifestyle, and bank account are balanced.
Jack established an online portfolio while working for UPS in Atlanta, Georgia. So he gained boundless power.
The portion that many erroneously believe
Yes, you need internet abilities to make money, but they're not different from 9-5 talents.
Sahil Lavingia, Gumroad's creator, explains.
A job is a way to get paid to learn.
Mistreat your boss 9-5. Drain his skills. Defuse him. Love and leave him (eventually).
Find another employment if yours is hazardous. Pick an easy job. Make sure nothing sneaks into your 6-12 time slot.
The dumb game that makes you a sheep
A 9-5 job requires many job interviews throughout life.
You email your résumé to employers and apply for jobs through advertisements. This game makes you a sheep.
You're competing globally. Work-from-home makes the competition tougher. If you're not the cheapest, employers won't hire you.
After-hours online talents (say, 6 pm-12 pm) change the game. This graphic explains it better:
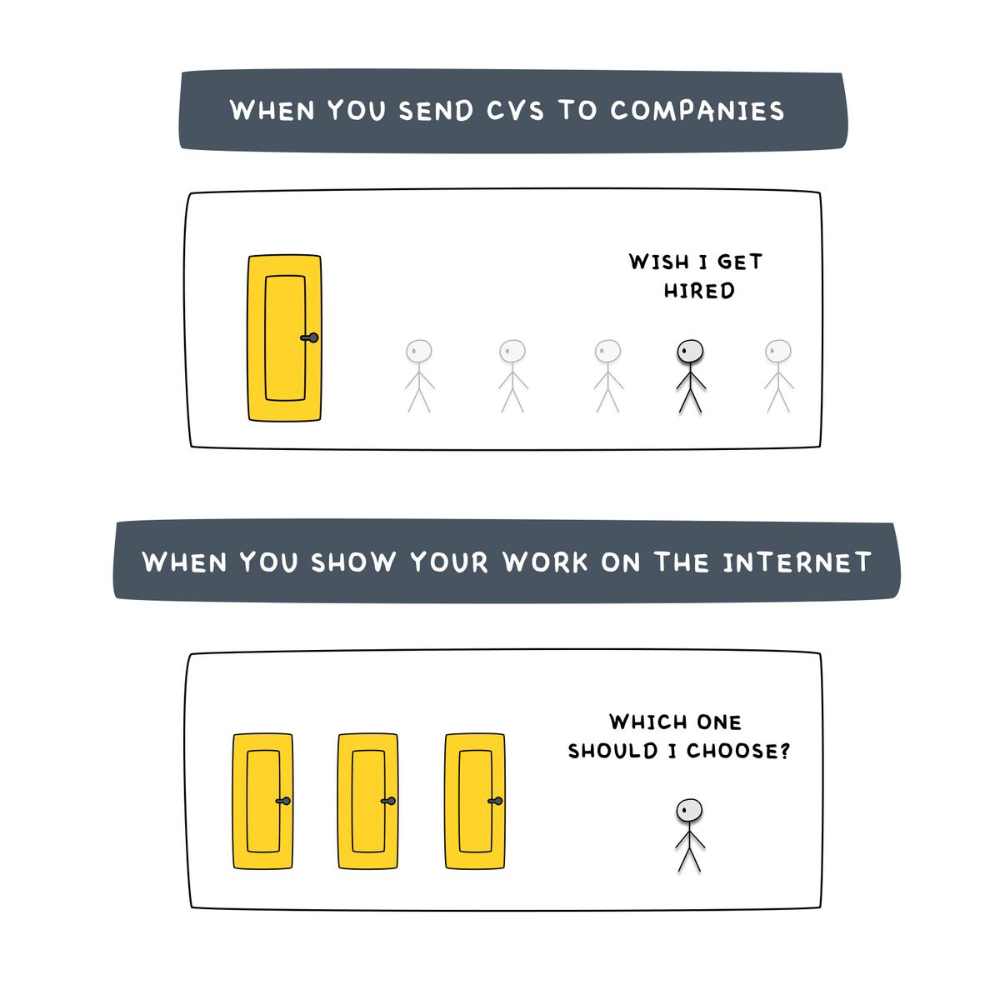
Online talents boost after-hours opportunities.
You go from wanting to be picked to picking yourself. More chances equal more money. Your f*ck you fund gets the extra cash.
A novel method of learning is essential.
College costs six figures and takes a lifetime to repay.
Informal learning is distinct. 6-12pm:
Observe the carefully controlled Twitter newsfeed.
Make use of Teachable and Gumroad's online courses.
Watch instructional YouTube videos
Look through the top Substack newsletters.
Informal learning is more effective because it's not obvious. It's fun to follow your curiosity and hobbies.

The majority of people lack one attitude. It's simple to learn.
One big impediment stands in the way of f*ck you money and time independence. So often.
Too many people plan after 6-12 hours. Dreaming. Big-thinkers. Strategically. They fill their calendar with meetings.
This is after-hours masturb*tion.
Sahil Bloom reminded me that a bias towards action will determine if this approach works for you.
The key isn't knowing what to do from 6-12 a.m. Trust yourself and develop abilities as you go. It's for building the parachute after you jump.
Sounds risky. We've eliminated the risk by finishing this process after hours while you work 9-5.
With no risk, you can have an I-don't-care attitude and still be successful.
When you choose to move forward, this occurs.
Once you try 9-5/6-12, you'll tell someone.
It's bad.
Few of us hang out with problem-solvers.
It's how much of society operates. So they make reasons so they can feel better about not giving you money.
Matthew Kobach told me chasing f*ck you money is easier with like-minded folks.
Without f*ck you money friends, loneliness will take over and you'll think you've messed up when you just need to keep going.
Steal this easy guideline
Let's act. No more fluffing and caressing.
1. Learn
If you detest your 9-5 talents or don't think they'll work online, get new ones. If you're skilled enough, continue.
Easlo recommends these skills:
Designer for Figma
Designer Canva
bubble creators
editor in Photoshop
Automation consultant for Zapier
Designer of Webflow
video editor Adobe
Ghostwriter for Twitter
Idea consultant
Artist in Blender Studio
2. Develop the ability
Every night from 6-12, apply the skill.
Practicing ghostwriting? Write someone's tweets for free. Do someone's website copy to learn copywriting. Get a website to the top of Google for a keyword to understand SEO.
Free practice is crucial. Your 9-5 pays the money, so work for free.
3. Take off stealthily like a badass
Another mistake. Sell to few. Don't be the best. Don't claim expertise.
Sell your new expertise to others behind you.
Two ways:
Using a digital good
By providing a service,
Point 1 also includes digital service examples. Digital products include eBooks, communities, courses, ad-supported podcasts, and templates. It's easy. Your 9-5 job involves one of these.
Take ideas from work.
Why? They'll steal your time for profit.
4. Iterate while feeling awful
First-time launches always fail. You'll feel terrible. Okay. Remember your 9-5?
Find improvements. Ask free and paying consumers what worked.
Multiple relaunches, each 1% better.
5. Discover more
Never stop learning. Improve your skill. Add a relevant skill. Learn copywriting if you write online.
After-hours students earn the most.
6. Continue
Repetition is key.
7. Make this one small change.
Consistently. The 6-12 momentum won't make you rich in 30 days; that's success p*rn.
Consistency helps wage slaves become f*ck you money. Most people can't switch between the two.
Putting everything together
It's easy. You're probably already doing some.
This formula explains why, how, and what to do. It's a 5th-grade-friendly blueprint. Good.
Reduce financial risk with your 9-to-5. Replace Netflix with 6-12 money-making talents.
Life is short; do whatever you want. Today.

Nick Nolan
3 years ago
In five years, starting a business won't be hip.

People are slowly recognizing entrepreneurship's downside.
Growing up, entrepreneurship wasn't common. High school class of 2012 had no entrepreneurs.
Businesses were different.
They had staff and a lengthy history of achievement.
I never wanted a business. It felt unattainable. My friends didn't care.
Weird.
People desired degrees to attain good jobs at big companies.
When graduated high school:
9 out of 10 people attend college
Earn minimum wage (7%) working in a restaurant or retail establishment
Or join the military (3%)
Later, entrepreneurship became a thing.
2014-ish
I was in the military and most of my high school friends were in college, so I didn't hear anything.
Entrepreneurship soared in 2015, according to Google Trends.
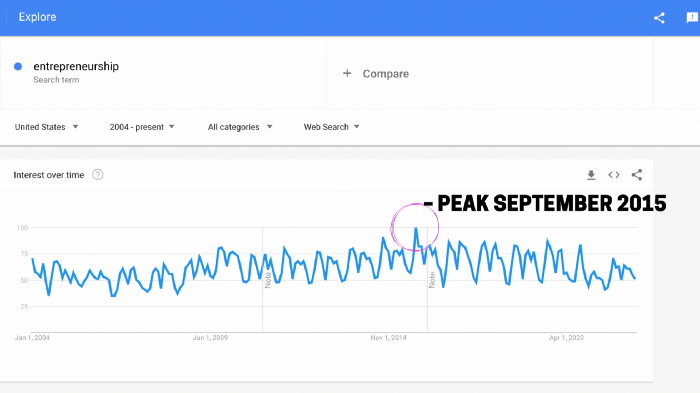
Then more individuals were interested. Entrepreneurship went from unusual to cool.
In 2015, it was easier than ever to build a website, run Facebook advertisements, and achieve organic social media reach.
There were several online business tools.
You didn't need to spend years or money figuring it out. Most entry barriers were gone.
Everyone wanted a side gig to escape the 95.
Small company applications have increased during the previous 10 years.
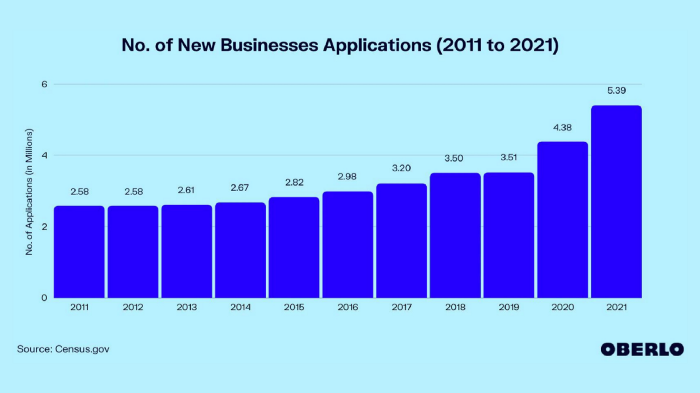
2011-2014 trend continues.
2015 adds 150,000 applications. 2016 adds 200,000. Plus 300,000 in 2017.
The graph makes it look little, but that's a considerable annual spike with no indications of stopping.
By 2021, new business apps had doubled.
Entrepreneurship will return to its early 2010s level.
I think we'll go backward in 5 years.
Entrepreneurship is half as popular as it was in 2015.
In the late 2020s and 30s, entrepreneurship will again be obscure.
Entrepreneurship's decade-long splendor is fading. People will cease escaping 9-5 and launch fewer companies.
That’s not a bad thing.
I think people have a rose-colored vision of entrepreneurship. It's fashionable. People feel that they're missing out if they're not entrepreneurial.
Reality is showing up.
People say on social media, "I knew starting a business would be hard, but not this hard."
More negative posts on entrepreneurship:

Luke adds:
Is being an entrepreneur ‘healthy’? I don’t really think so. Many like Gary V, are not role models for a well-balanced life. Despite what feel-good LinkedIn tells you the odds are against you as an entrepreneur. You have to work your face off. It’s a tough but rewarding lifestyle. So maybe let’s stop glorifying it because it takes a lot of (bleepin) work to survive a pandemic, mental health battles, and a competitive market.
Entrepreneurship is no longer a pipe dream.
It’s hard.
I went full-time in March 2020. I was done by April 2021. I had a good-paying job with perks.
When that fell through (on my start date), I had to continue my entrepreneurial path. I needed money by May 1 to pay rent.
Entrepreneurship isn't as great as many think.
Entrepreneurship is a serious business.
If you have a 9-5, the grass isn't greener here. Most people aren't telling the whole story when they post on social media or quote successful entrepreneurs.
People prefer to communicate their victories than their defeats.
Is this a bad thing?
I don’t think so.
Over the previous decade, entrepreneurship went from impossible to the finest thing ever.
It peaked in 2020-21 and is returning to reality.
Startups aren't for everyone.
If you like your job, don't quit.
Entrepreneurship won't amaze people if you quit your job.
It's irrelevant.
You're doomed.
And you'll probably make less money.
If you hate your job, quit. Change jobs and bosses. Changing jobs could net you a greater pay or better perks.
When you go solo, your paycheck and perks vanish. Did I mention you'll fail, sleep less, and stress more?
Nobody will stop you from pursuing entrepreneurship. You'll face several challenges.
Possibly.
Entrepreneurship may be romanticized for years.
Based on what I see from entrepreneurs on social media and trends, entrepreneurship is challenging and few will succeed.
You might also like
Colin Faife
3 years ago
The brand-new USB Rubber Ducky is much riskier than before.
The brand-new USB Rubber Ducky is much riskier than before.

With its own programming language, the well-liked hacking tool may now pwn you.
With a vengeance, the USB Rubber Ducky is back.
This year's Def Con hacking conference saw the release of a new version of the well-liked hacking tool, and its author, Darren Kitchen, was on hand to explain it. We put a few of the new features to the test and discovered that the most recent version is riskier than ever.
WHAT IS IT?
The USB Rubber Ducky seems to the untrained eye to be an ordinary USB flash drive. However, when you connect it to a computer, the computer recognizes it as a USB keyboard and will accept keystroke commands from the device exactly like a person would type them in.
Kitchen explained to me, "It takes use of the trust model built in, where computers have been taught to trust a human, in that anything it types is trusted to the same degree as the user is trusted. And a computer is aware that clicks and keystrokes are how people generally connect with it.

Over ten years ago, the first Rubber Ducky was published, quickly becoming a hacker favorite (it was even featured in a Mr. Robot scene). Since then, there have been a number of small upgrades, but the most recent Rubber Ducky takes a giant step ahead with a number of new features that significantly increase its flexibility and capability.
WHERE IS ITS USE?
The options are nearly unlimited with the proper strategy.
The Rubber Ducky has already been used to launch attacks including making a phony Windows pop-up window to collect a user's login information or tricking Chrome into sending all saved passwords to an attacker's web server. However, these attacks lacked the adaptability to operate across platforms and had to be specifically designed for particular operating systems and software versions.

The nuances of DuckyScript 3.0 are described in a new manual.
The most recent Rubber Ducky seeks to get around these restrictions. The DuckyScript programming language, which is used to construct the commands that the Rubber Ducky will enter into a target machine, receives a significant improvement with it. DuckyScript 3.0 is a feature-rich language that allows users to write functions, store variables, and apply logic flow controls, in contrast to earlier versions that were primarily limited to scripting keystroke sequences (i.e., if this... then that).
This implies that, for instance, the new Ducky can check to see if it is hooked into a Windows or Mac computer and then conditionally run code specific to each one, or it can disable itself if it has been attached to the incorrect target. In order to provide a more human effect, it can also generate pseudorandom numbers and utilize them to add a configurable delay between keystrokes.
The ability to steal data from a target computer by encoding it in binary code and transferring it through the signals intended to instruct a keyboard when the CapsLock or NumLock LEDs should light up is perhaps its most astounding feature. By using this technique, a hacker may plug it in for a brief period of time, excuse themselves by saying, "Sorry, I think that USB drive is faulty," and then take it away with all the credentials stored on it.
HOW SERIOUS IS THE RISK?
In other words, it may be a significant one, but because physical device access is required, the majority of people aren't at risk of being a target.
The 500 or so new Rubber Duckies that Hak5 brought to Def Con, according to Kitchen, were his company's most popular item at the convention, and they were all gone on the first day. It's safe to suppose that hundreds of hackers already possess one, and demand is likely to persist for some time.
Additionally, it has an online development toolkit that can be used to create attack payloads, compile them, and then load them onto the target device. A "payload hub" part of the website makes it simple for hackers to share what they've generated, and the Hak5 Discord is also busy with conversation and helpful advice. This makes it simple for users of the product to connect with a larger community.
It's too expensive for most individuals to distribute in volume, so unless your favorite cafe is renowned for being a hangout among vulnerable targets, it's doubtful that someone will leave a few of them there. To that end, if you intend to plug in a USB device that you discovered outside in a public area, pause to consider your decision.
WOULD IT WORK FOR ME?
Although the device is quite straightforward to use, there are a few things that could cause you trouble if you have no prior expertise writing or debugging code. For a while, during testing on a Mac, I was unable to get the Ducky to press the F4 key to activate the launchpad, but after forcing it to identify itself using an alternative Apple keyboard device ID, the problem was resolved.
From there, I was able to create a script that, when the Ducky was plugged in, would instantly run Chrome, open a new browser tab, and then immediately close it once more without requiring any action from the laptop user. Not bad for only a few hours of testing, and something that could be readily changed to perform duties other than reading technology news.

The Verge
3 years ago
Bored Ape Yacht Club creator raises $450 million at a $4 billion valuation.
Yuga Labs, owner of three of the biggest NFT brands on the market, announced today a $450 million funding round. The money will be used to create a media empire based on NFTs, starting with games and a metaverse project.
The team's Otherside metaverse project is an MMORPG meant to connect the larger NFT universe. They want to create “an interoperable world” that is “gamified” and “completely decentralized,” says Wylie Aronow, aka Gordon Goner, co-founder of Bored Ape Yacht Club. “We think the real Ready Player One experience will be player run.”
Just a few weeks ago, Yuga Labs announced the acquisition of CryptoPunks and Meebits from Larva Labs. The deal brought together three of the most valuable NFT collections, giving Yuga Labs more IP to work with when developing games and metaverses. Last week, ApeCoin was launched as a cryptocurrency that will be governed independently and used in Yuga Labs properties.
Otherside will be developed by “a few different game studios,” says Yuga Labs CEO Nicole Muniz. The company plans to create development tools that allow NFTs from other projects to work inside their world. “We're welcoming everyone into a walled garden.”
However, Yuga Labs believes that other companies are approaching metaverse projects incorrectly, allowing the startup to stand out. People won't bond spending time in a virtual space with nothing going on, says Yuga Labs co-founder Greg Solano, aka Gargamel. Instead, he says, people bond when forced to work together.
In order to avoid getting smacked, Solano advises making friends. “We don't think a Zoom chat and walking around saying ‘hi' creates a deep social experience.” Yuga Labs refused to provide a release date for Otherside. Later this year, a play-to-win game is planned.
The funding round was led by Andreessen Horowitz, a major investor in the Web3 space. It previously backed OpenSea and Coinbase. Animoca Brands, Coinbase, and MoonPay are among those who have invested. Andreessen Horowitz general partner Chris Lyons will join Yuga Labs' board. The Financial Times broke the story last month.
"META IS A DOMINANT DIGITAL EXPERIENCE PROVIDER IN A DYSTOPIAN FUTURE."
This emerging [Web3] ecosystem is important to me, as it is to companies like Meta,” Chris Dixon, head of Andreessen Horowitz's crypto arm, tells The Verge. “In a dystopian future, Meta is the dominant digital experience provider, and it controls all the money and power.” (Andreessen Horowitz co-founder Marc Andreessen sits on Meta's board and invested early in Facebook.)
Yuga Labs has been profitable so far. According to a leaked pitch deck, the company made $137 million last year, primarily from its NFT brands, with a 95% profit margin. (Yuga Labs declined to comment on deck figures.)
But the company has built little so far. According to OpenSea data, it has only released one game for a limited time. That means Yuga Labs gets hundreds of millions of dollars to build a gaming company from scratch, based on a hugely lucrative art project.
Investors fund Yuga Labs based on its success. That's what they did, says Dixon, “they created a culture phenomenon”. But ultimately, the company is betting on the same thing that so many others are: that a metaverse project will be the next big thing. Now they must construct it.

Sam Hickmann
3 years ago
Nomad.xyz got exploited for $190M
Key Takeaways:
Another hack. This time was different. This is a doozy.
Why? Nomad got exploited for $190m. It was crypto's 5th-biggest hack. Ouch.
It wasn't hackers, but random folks. What happened:
A Nomad smart contract flaw was discovered. They couldn't drain the funds at once, so they tried numerous transactions. Rookie!
People noticed and copied the attack.
They just needed to discover a working transaction, substitute the other person's address with theirs, and run it.

In a two-and-a-half-hour attack, $190M was siphoned from Nomad Bridge.
Nomad is a novel approach to blockchain interoperability that leverages an optimistic mechanism to increase the security of cross-chain communication. — nomad.xyz
This hack was permissionless, therefore anyone could participate.
After the fatal blow, people fought over the scraps.
Cross-chain bridges remain a DeFi weakness and exploit target. When they collapse, it's typically total.
$190M...gobbled.
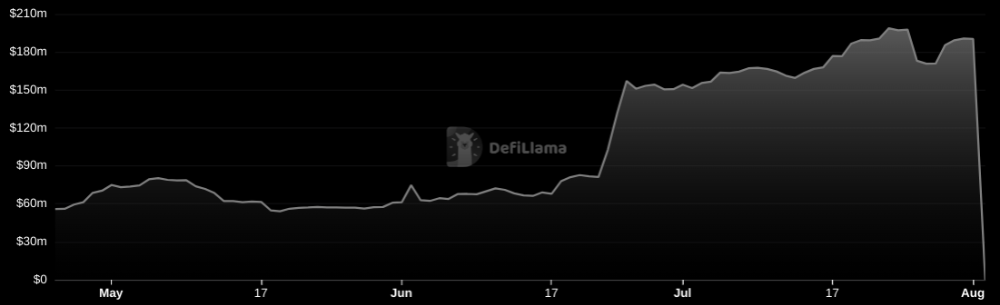
Unbacked assets are hurting Nomad-dependent chains. Moonbeam, EVMOS, and Milkomeda's TVLs dropped.
This incident is every-man-for-himself, although numerous whitehats exploited the issue...
But what triggered the feeding frenzy?
How did so many pick the bones?
After a normal upgrade in June, the bridge's Replica contract was initialized with a severe security issue. The 0x00 address was a trusted root, therefore all messages were valid by default.
After a botched first attempt (costing $350k in gas), the original attacker's exploit tx called process() without first 'proving' its validity.
The process() function executes all cross-chain messages and checks the merkle root of all messages (line 185).
The upgrade caused transactions with a'messages' value of 0 (invalid, according to old logic) to be read by default as 0x00, a trusted root, passing validation as 'proven'
Any process() calls were valid. In reality, a more sophisticated exploiter may have designed a contract to drain the whole bridge.
Copycat attackers simply copied/pasted the same process() function call using Etherscan, substituting their address.
The incident was a wild combination of crowdhacking, whitehat activities, and MEV-bot (Maximal Extractable Value) mayhem.
For example, 🍉🍉🍉. eth stole $4M from the bridge, but claims to be whitehat.

Others stood out for the wrong reasons. Repeat criminal Rari Capital (Artibrum) exploited over $3M in stablecoins, which moved to Tornado Cash.
The top three exploiters (with 95M between them) are:
$47M: 0x56D8B635A7C88Fd1104D23d632AF40c1C3Aac4e3
$40M: 0xBF293D5138a2a1BA407B43672643434C43827179
$8M: 0xB5C55f76f90Cc528B2609109Ca14d8d84593590E
Here's a list of all the exploiters:
The project conducted a Quantstamp audit in June; QSP-19 foreshadowed a similar problem.
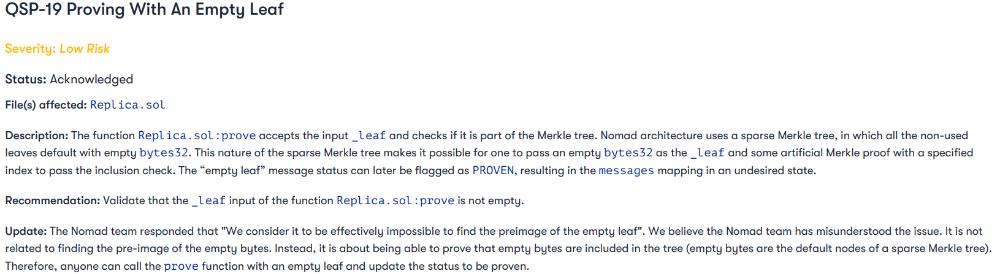
The auditor's comments that "We feel the Nomad team misinterpreted the issue" speak to a troubling attitude towards security that the project's "Long-Term Security" plan appears to confirm:
Concerns were raised about the team's response time to a live, public exploit; the team's official acknowledgement came three hours later.
"Removing the Replica contract as owner" stopped the exploit, but it was too late to preserve the cash.
Closed blockchain systems are only as strong as their weakest link.
The Harmony network is in turmoil after its bridge was attacked and lost $100M in late June.
What's next for Nomad's ecosystems?
Moonbeam's TVL is now $135M, EVMOS's is $3M, and Milkomeda's is $20M.
Loss of confidence may do more damage than $190M.
Cross-chain infrastructure is difficult to secure in a new, experimental sector. Bridge attacks can pollute an entire ecosystem or more.
Nomadic liquidity has no permanent home, so consumers will always migrate in pursuit of the "next big thing" and get stung when attentiveness wanes.
DeFi still has easy prey...
Sources: rekt.news & The Milk Road.