


More on Leadership

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.

Caspar Mahoney
3 years ago
Changing Your Mindset From a Project to a Product
Product game mindsets? How do these vary from Project mindset?
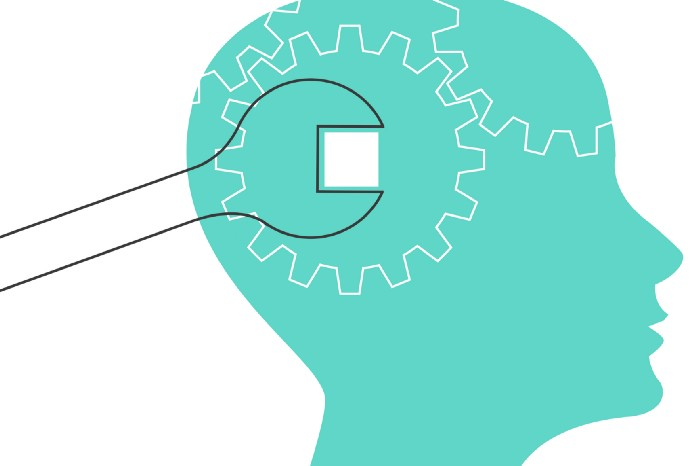
1950s spawned the Iron Triangle. Project people everywhere know and live by it. In stakeholder meetings, it is used to stretch the timeframe, request additional money, or reduce scope.
Quality was added to this triangle as things matured.
Quality was intended to be transformative, but none of these principles addressed why we conduct projects.
Value and benefits are key.
Product value is quantified by ROI, revenue, profit, savings, or other metrics. For me, every project or product delivery is about value.
Most project managers, especially those schooled 5-10 years or more ago (thousands working in huge corporations worldwide), understand the world in terms of the iron triangle. What does that imply? They worry about:
a) enough time to get the thing done.
b) have enough resources (budget) to get the thing done.
c) have enough scope to fit within (a) and (b) >> note, they never have too little scope, not that I have ever seen! although, theoretically, this could happen.
Boom—iron triangle.
To make the triangle function, project managers will utilize formal governance (Steering) to move those things. Increase money, scope, or both if time is short. Lacking funds? Increase time, scope, or both.
In current product development, shifting each item considerably may not yield value/benefit.
Even terrible. This approach will fail because it deprioritizes Value/Benefit by focusing the major stakeholders (Steering participants) and delivery team(s) on Time, Scope, and Budget restrictions.
Pre-agile, this problem was terrible. IT projects failed wildly. History is here.
Value, or benefit, is central to the product method. Product managers spend most of their time planning value-delivery paths.
Product people consider risk, schedules, scope, and budget, but value comes first. Let me illustrate.
Imagine managing internal products in an enterprise. Your core customer team needs a rapid text record of a chat to fix a problem. The consumer wants a feature/features added to a product you're producing because they think it's the greatest spot.
Project-minded, I may say;
Ok, I have budget as this is an existing project, due to run for a year. This is a new requirement to add to the features we’re already building. I think I can keep the deadline, and include this scope, as it sounds related to the feature set we’re building to give the desired result”.
This attitude repeats Scope, Time, and Budget.
Since it meets those standards, a project manager will likely approve it. If they have a backlog, they may add it and start specking it out assuming it will be built.
Instead, think like a product;
What problem does this feature idea solve? Is that problem relevant to the product I am building? Can that problem be solved quicker/better via another route ? Is it the most valuable problem to solve now? Is the problem space aligned to our current or future strategy? or do I need to alter/update the strategy?
A product mindset allows you to focus on timing, resource/cost, feasibility, feature detail, and so on after answering the aforementioned questions.
The above oversimplifies because
Leadership in discovery

Project managers are facilitators of ideas. This is as far as they normally go in the ‘idea’ space.
Business Requirements collection in classic project delivery requires extensive upfront documentation.
Agile project delivery analyzes requirements iteratively.
However, the project manager is a facilitator/planner first and foremost, therefore topic knowledge is not expected.
I mean business domain, not technical domain (to confuse matters, it is true that in some instances, it can be both technical and business domains that are important for a single individual to master).
Product managers are domain experts. They will become one if they are training/new.
They lead discovery.
Product Manager-led discovery is much more than requirements gathering.
Requirements gathering involves a Business Analyst interviewing people and documenting their requests.
The project manager calculates what fits and what doesn't using their Iron Triangle (presumably in their head) and reports back to Steering.
If this requirements-gathering exercise failed to identify requirements, what would a project manager do? or bewildered by project requirements and scope?
They would tell Steering they need a Business SME or Business Lead assigning or more of their time.
Product discovery requires the Product Manager's subject knowledge and a new mindset.
How should a Product Manager handle confusing requirements?
Product Managers handle these challenges with their talents and tools. They use their own knowledge to fill in ambiguity, but they have the discipline to validate those assumptions.
To define the problem, they may perform qualitative or quantitative primary research.
They might discuss with UX and Engineering on a whiteboard and test assumptions or hypotheses.
Do Product Managers escalate confusing requirements to Steering/Senior leaders? They would fix that themselves.
Product managers raise unclear strategy and outcomes to senior stakeholders. Open talks, soft skills, and data help them do this. They rarely raise requirements since they have their own means of handling them without top stakeholder participation.
Discovery is greenfield, exploratory, research-based, and needs higher-order stakeholder management, user research, and UX expertise.
Product Managers also aid discovery. They lead discovery. They will not leave customer/user engagement to a Business Analyst. Administratively, a business analyst could aid. In fact, many product organizations discourage business analysts (rely on PM, UX, and engineer involvement with end-users instead).
The Product Manager must drive user interaction, research, ideation, and problem analysis, therefore a Product professional must be skilled and confident.
Creating vs. receiving and having an entrepreneurial attitude

Product novices and project managers focus on details rather than the big picture. Project managers prefer spreadsheets to strategy whiteboards and vision statements.
These folks ask their manager or senior stakeholders, "What should we do?"
They then elaborate (in Jira, in XLS, in Confluence or whatever).
They want that plan populated fast because it reduces uncertainty about what's going on and who's supposed to do what.
Skilled Product Managers don't only ask folks Should we?
They're suggesting this, or worse, Senior stakeholders, here are some options. After asking and researching, they determine what value this product adds, what problems it solves, and what behavior it changes.
Therefore, to move into Product, you need to broaden your view and have courage in your ability to discover ideas, find insightful pieces of information, and collate them to form a valuable plan of action. You are constantly defining RoI and building Business Cases, so much so that you no longer create documents called Business Cases, it is simply ingrained in your work through metrics, intelligence, and insights.
Product Management is not a free lunch.
Plateless.
Plates and food must be prepared.
In conclusion, Product Managers must make at least three mentality shifts:
You put value first in all things. Time, money, and scope are not as important as knowing what is valuable.
You have faith in the field and have the ability to direct the search. YYou facilitate, but you don’t just facilitate. You wouldn't want to limit your domain expertise in that manner.
You develop concepts, strategies, and vision. You are not a waiter or an inbox where other people can post suggestions; you don't merely ask folks for opinion and record it. However, you excel at giving things that aren't clearly spoken or written down physical form.

Sean Bloomfield
3 years ago
How Jeff Bezos wins meetings over

We've all been there: You propose a suggestion to your team at a meeting, and most people appear on board, but a handful or small minority aren't. How can we achieve collective buy-in when we need to go forward but don't know how to deal with some team members' perceived intransigence?
Steps:
Investigate the divergent opinions: Begin by sincerely attempting to comprehend the viewpoint of your disagreeing coworkers. Maybe it makes sense to switch horses in the middle of the race. Have you completely overlooked a blind spot, such as a political concern that could arise as an unexpected result of proceeding? This is crucial to ensure that the person or people feel heard as well as to advance the goals of the team. Sometimes all individuals need is a little affirmation before they fully accept your point of view.
It says a lot about you as a leader to be someone who always lets the perceived greatest idea win, regardless of the originating channel, if after studying and evaluating you see the necessity to align with the divergent position.
If, after investigation and assessment, you determine that you must adhere to the original strategy, we go to Step 2.
2. Disagree and Commit: Jeff Bezos, CEO of Amazon, has had this experience, and Julie Zhuo describes how he handles it in her book The Making of a Manager.
It's OK to disagree when the team is moving in the right direction, but it's not OK to accidentally or purposefully damage the team's efforts because you disagree. Let the team know your opinion, but then help them achieve company goals even if they disagree. Unknown. You could be wrong in today's ever-changing environment.
So next time you have a team member who seems to be dissenting and you've tried the previous tactics, you may ask the individual in the meeting I understand you but I don't want us to leave without you on board I need your permission to commit to this approach would you give us your commitment?
You might also like

Katrine Tjoelsen
3 years ago
8 Communication Hacks I Use as a Young Employee
Learn these subtle cues to gain influence.

Hate being ignored?
As a 24-year-old, I struggled at work. Attention-getting tips How to avoid being judged by my size, gender, and lack of wrinkles or gray hair?
I've learned seniority hacks. Influence. Within two years as a product manager, I led a team. I'm a Stanford MBA student.
These communication hacks can make you look senior and influential.
1. Slowly speak
We speak quickly because we're afraid of being interrupted.
When I doubt my ideas, I speak quickly. How can we slow down? Jamie Chapman says speaking slowly saps our energy.
Chapman suggests emphasizing certain words and pausing.
2. Interrupted? Stop the stopper
Someone interrupt your speech?
Don't wait. "May I finish?" No pause needed. Stop interrupting. I first tried this in Leadership Laboratory at Stanford. How quickly I gained influence amazed me.
Next time, try “May I finish?” If that’s not enough, try these other tips from Wendy R.S. O’Connor.
3. Context
Others don't always see what's obvious to you.
Through explanation, you help others see the big picture. If a senior knows it, you help them see where your work fits.
4. Don't ask questions in statements
“Your statement lost its effect when you ended it on a high pitch,” a group member told me. Upspeak, it’s called. I do it when I feel uncertain.
Upspeak loses influence and credibility. Unneeded. When unsure, we can say "I think." We can even ask a proper question.
Someone else's boasting is no reason to be dismissive. As leaders and colleagues, we should listen to our colleagues even if they use this speech pattern.
Give your words impact.
5. Signpost structure
Signposts improve clarity by providing structure and transitions.
Communication coach Alexander Lyon explains how to use "first," "second," and "third" He explains classic and summary transitions to help the listener switch topics.
Signs clarify. Clarity matters.

6. Eliminate email fluff
“Fine. When will the report be ready? — Jeff.”
Notice how senior leaders write short, direct emails? I often use formalities like "dear," "hope you're well," and "kind regards"
Formality is (usually) unnecessary.
7. Replace exclamation marks with periods
See how junior an exclamation-filled email looks:
Hi, all!
Hope you’re as excited as I am for tomorrow! We’re celebrating our accomplishments with cake! Join us tomorrow at 2 pm!
See you soon!
Why the exclamation points? Why not just one?
Hi, all.
Hope you’re as excited as I am for tomorrow. We’re celebrating our accomplishments with cake. Join us tomorrow at 2 pm!
See you soon.
8. Take space
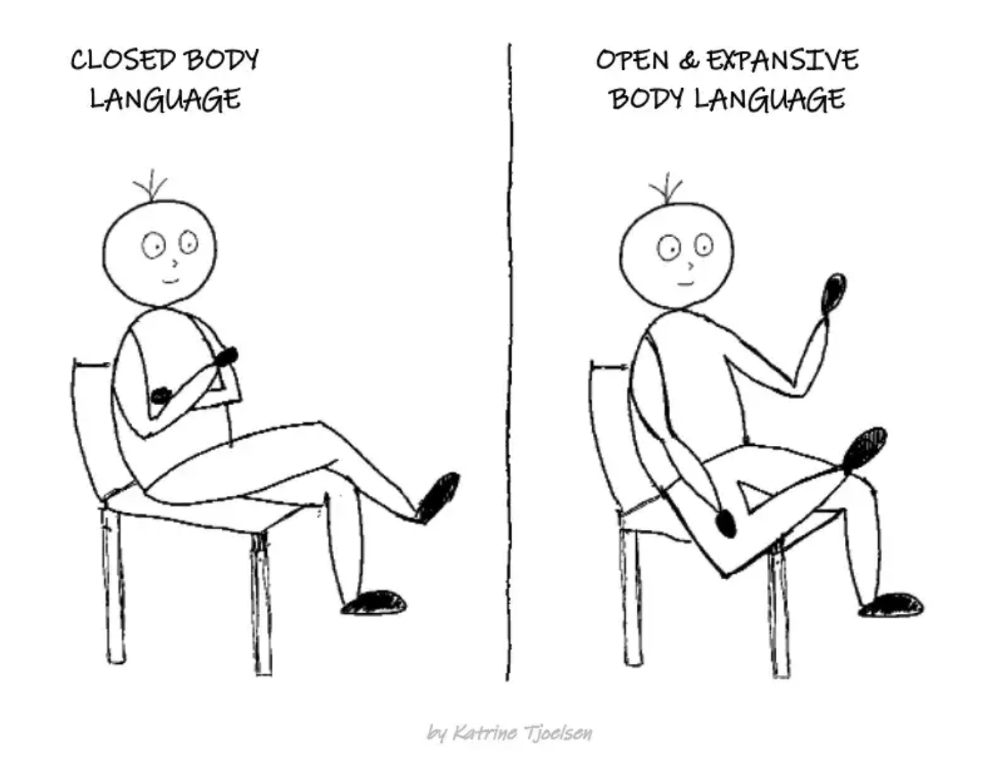
"Playing high" means having an open, relaxed body, says Stanford professor and author Deborah Gruenfield.
Crossed legs or looking small? Relax. Get bigger.
Thomas Smith
3 years ago
ChatGPT Is Experiencing a Lightbulb Moment
Why breakthrough technologies must be accessible

ChatGPT has exploded. Over 1 million people have used the app, and coding sites like Stack Overflow have banned its answers. It's huge.
I wouldn't have called that as an AI researcher. ChatGPT uses the same GPT-3 technology that's been around for over two years.
More than impressive technology, ChatGPT 3 shows how access makes breakthroughs usable. OpenAI has finally made people realize the power of AI by packaging GPT-3 for normal users.
We think of Thomas Edison as the inventor of the lightbulb, not because he invented it, but because he popularized it.
Going forward, AI companies that make using AI easy will thrive.
Use-case importance
Most modern AI systems use massive language models. These language models are trained on 6,000+ years of human text.
GPT-3 ate 8 billion pages, almost every book, and Wikipedia. It created an AI that can write sea shanties and solve coding problems.
Nothing new. I began beta testing GPT-3 in 2020, but the system's basics date back further.
Tools like GPT-3 are hidden in many apps. Many of the AI writing assistants on this platform are just wrappers around GPT-3.
Lots of online utilitarian text, like restaurant menu summaries or city guides, is written by AI systems like GPT-3. You've probably read GPT-3 without knowing it.
Accessibility
Why is ChatGPT so popular if the technology is old?
ChatGPT makes the technology accessible. Free to use, people can sign up and text with the chatbot daily. ChatGPT isn't revolutionary. It does it in a way normal people can access and be amazed by.
Accessibility isn't easy. OpenAI's Sam Altman tweeted that opening ChatGPT to the public increased computing costs.
Each chat costs "low-digit cents" to process. OpenAI probably spends several hundred thousand dollars a day to keep ChatGPT running, with no immediate business case.
Academic researchers and others who developed GPT-3 couldn't afford it. Without resources to make technology accessible, it can't be used.
Retrospective
This dynamic is old. In the history of science, a researcher with a breakthrough idea was often overshadowed by an entrepreneur or visionary who made it accessible to the public.
We think of Thomas Edison as the inventor of the lightbulb. But really, Vasilij Petrov, Thomas Wright, and Joseph Swan invented the lightbulb. Edison made technology visible and accessible by electrifying public buildings, building power plants, and wiring.
Edison probably lost a ton of money on stunts like building a power plant to light JP Morgan's home, the NYSE, and several newspaper headquarters.
People wanted electric lights once they saw their benefits. By making the technology accessible and visible, Edison unlocked a hugely profitable market.
Similar things are happening in AI. ChatGPT shows that developing breakthrough technology in the lab or on B2B servers won't change the culture.
AI must engage people's imaginations to become mainstream. Before the tech impacts the world, people must play with it and see its revolutionary power.
As the field evolves, companies that make the technology widely available, even at great cost, will succeed.
OpenAI's compute fees are eye-watering. Revolutions are costly.

Nick Nolan
3 years ago
In five years, starting a business won't be hip.

People are slowly recognizing entrepreneurship's downside.
Growing up, entrepreneurship wasn't common. High school class of 2012 had no entrepreneurs.
Businesses were different.
They had staff and a lengthy history of achievement.
I never wanted a business. It felt unattainable. My friends didn't care.
Weird.
People desired degrees to attain good jobs at big companies.
When graduated high school:
9 out of 10 people attend college
Earn minimum wage (7%) working in a restaurant or retail establishment
Or join the military (3%)
Later, entrepreneurship became a thing.
2014-ish
I was in the military and most of my high school friends were in college, so I didn't hear anything.
Entrepreneurship soared in 2015, according to Google Trends.
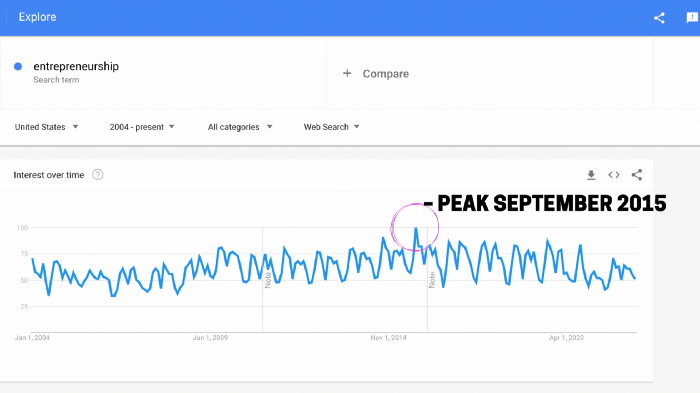
Then more individuals were interested. Entrepreneurship went from unusual to cool.
In 2015, it was easier than ever to build a website, run Facebook advertisements, and achieve organic social media reach.
There were several online business tools.
You didn't need to spend years or money figuring it out. Most entry barriers were gone.
Everyone wanted a side gig to escape the 95.
Small company applications have increased during the previous 10 years.
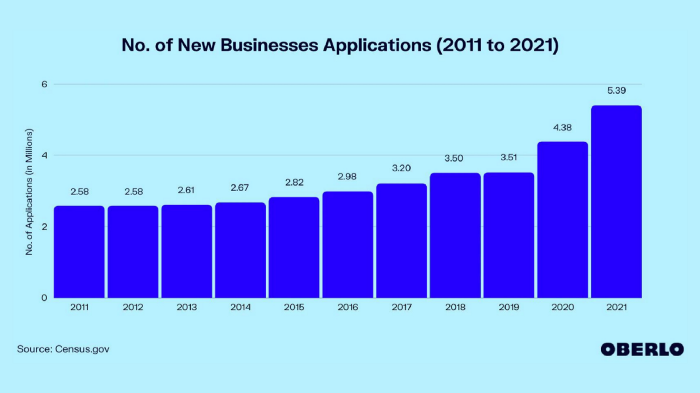
2011-2014 trend continues.
2015 adds 150,000 applications. 2016 adds 200,000. Plus 300,000 in 2017.
The graph makes it look little, but that's a considerable annual spike with no indications of stopping.
By 2021, new business apps had doubled.
Entrepreneurship will return to its early 2010s level.
I think we'll go backward in 5 years.
Entrepreneurship is half as popular as it was in 2015.
In the late 2020s and 30s, entrepreneurship will again be obscure.
Entrepreneurship's decade-long splendor is fading. People will cease escaping 9-5 and launch fewer companies.
That’s not a bad thing.
I think people have a rose-colored vision of entrepreneurship. It's fashionable. People feel that they're missing out if they're not entrepreneurial.
Reality is showing up.
People say on social media, "I knew starting a business would be hard, but not this hard."
More negative posts on entrepreneurship:

Luke adds:
Is being an entrepreneur ‘healthy’? I don’t really think so. Many like Gary V, are not role models for a well-balanced life. Despite what feel-good LinkedIn tells you the odds are against you as an entrepreneur. You have to work your face off. It’s a tough but rewarding lifestyle. So maybe let’s stop glorifying it because it takes a lot of (bleepin) work to survive a pandemic, mental health battles, and a competitive market.
Entrepreneurship is no longer a pipe dream.
It’s hard.
I went full-time in March 2020. I was done by April 2021. I had a good-paying job with perks.
When that fell through (on my start date), I had to continue my entrepreneurial path. I needed money by May 1 to pay rent.
Entrepreneurship isn't as great as many think.
Entrepreneurship is a serious business.
If you have a 9-5, the grass isn't greener here. Most people aren't telling the whole story when they post on social media or quote successful entrepreneurs.
People prefer to communicate their victories than their defeats.
Is this a bad thing?
I don’t think so.
Over the previous decade, entrepreneurship went from impossible to the finest thing ever.
It peaked in 2020-21 and is returning to reality.
Startups aren't for everyone.
If you like your job, don't quit.
Entrepreneurship won't amaze people if you quit your job.
It's irrelevant.
You're doomed.
And you'll probably make less money.
If you hate your job, quit. Change jobs and bosses. Changing jobs could net you a greater pay or better perks.
When you go solo, your paycheck and perks vanish. Did I mention you'll fail, sleep less, and stress more?
Nobody will stop you from pursuing entrepreneurship. You'll face several challenges.
Possibly.
Entrepreneurship may be romanticized for years.
Based on what I see from entrepreneurs on social media and trends, entrepreneurship is challenging and few will succeed.