



More on Entrepreneurship/Creators

The woman
3 years ago
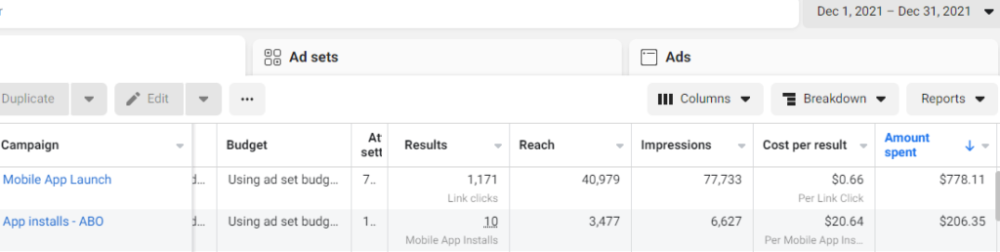
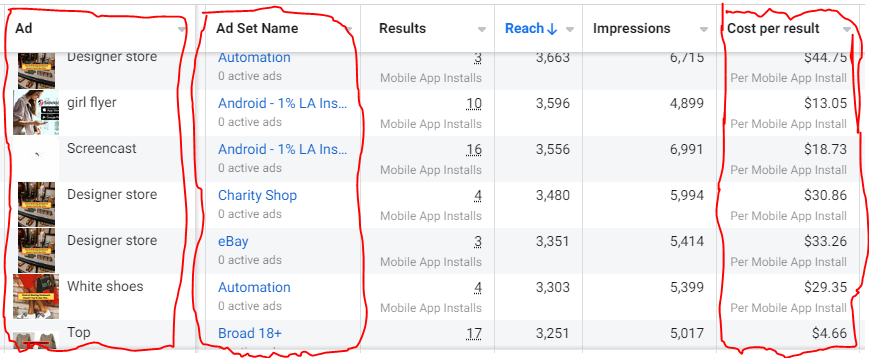
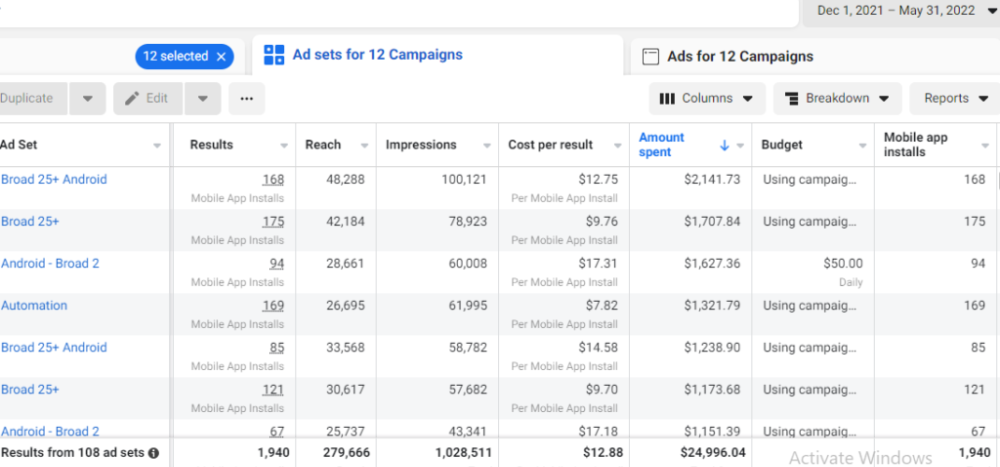
Because he worked on his side projects during working hours, my junior was fired and sued.
Many developers do it, but I don't approve.

Aren't many programmers part-time? Many work full-time but also freelance. If the job agreement allows it, I see no problem.
Tech businesses' policies vary. I have a friend in Google, Germany. According to his contract, he couldn't do an outside job. Google owns any code he writes while employed.
I was shocked. Later, I found that different Google regions have different policies.
A corporation can normally establish any agreement before hiring you. They're negotiable. When there's no agreement, state law may apply. In court, law isn't so simple.
I won't delve into legal details. Instead, let’s talk about the incident.
How he was discovered
In one month, he missed two deadlines. His boss was frustrated because the assignment wasn't difficult to miss twice. When a team can't finish work on time, they all earn bad grades.
He annoyed the whole team. One team member (anonymous) told the project manager he worked on side projects during office hours. He may have missed deadlines because of this.
The project manager was furious. He needed evidence. The manager caught him within a week. The manager told higher-ups immediately.
The company wanted to set an example
Management could terminate him and settle the problem. But the company wanted to set an example for those developers who breached the regulation.
Because dismissal isn't enough. Every organization invests heavily in developer hiring. If developers depart or are fired after a few months, the company suffers.
The developer spent 10 months there. The employer sacked him and demanded ten months' pay. Or they'd sue him.
It was illegal and unethical. The youngster paid the fine and left the company quietly to protect his career.
Right or wrong?
Is the developer's behavior acceptable? Let's discuss developer malpractice.
During office hours, may developers work on other projects? If they're bored during office hours, they might not. Check the employment contract or state law.
If there's no employment clause, check country/state law. Because you can't justify breaking the law. Always. Most employers own their employees' work hours unless it's a contractual position.
If the company agrees, it's fine.
I also oppose companies that force developers to work overtime without pay.
Most states and countries have laws that help companies and workers. Law supports employers in this case. If any of the following are true, the company/employer owns the IP under California law.
using the business's resources
any equipment, including a laptop used for business.
company's mobile device.
offices of the company.
business time as well. This is crucial. Because this occurred in the instance of my junior.
Company resources are dangerous. Because your company may own the product's IP. If you have seen the TV show Silicon Valley, you have seen a similar situation there, right?
Conclusion
Simple rule. I avoid big side projects. I work on my laptop on weekends for side projects. I'm safe. But I also know that my company might not be happy with that.
As an employee, I suppose I can. I can make side money. I won't promote it, but I'll respect their time, resources, and task. I also sometimes work extra time to finish my company’s deadlines.

Kaitlin Fritz
3 years ago
The Entrepreneurial Chicken and Egg
University entrepreneurship is like a Willy Wonka Factory of ideas. Classes, roommates, discussions, and the cafeteria all inspire new ideas. I've seen people establish a business without knowing its roots.
Chicken or egg? On my mind: I've asked university founders around the world whether the problem or solution came first.
The Problem
One African team I met started with the “instant noodles” problem in their academic ecosystem. Many of us have had money issues in college, which may have led to poor nutritional choices.
Many university students in a war-torn country ate quick noodles or pasta for dinner.

Noodles required heat, water, and preparation in the boarding house. Unreliable power from one hot plate per blue moon. What's healthier, easier, and tastier than sodium-filled instant pots?
BOOM. They were fixing that. East African kids need affordable, nutritious food.
This is a real difficulty the founders faced every day with hundreds of comrades.
This sparked their serendipitous entrepreneurial journey and became their business's cornerstone.
The Solution
I asked a UK team about their company idea. They said the solution fascinated them.
The crew was fiddling with social media algorithms. Why are some people more popular? They were studying platforms and social networks, which offered a way for them.

Solving a problem? Yes. Long nights of university research lead them to it. Is this like world hunger? Social media influencers confront this difficulty regularly.
It made me ponder something. Is there a correct response?
In my heart, yes, but in my head…maybe?
I believe you should lead with empathy and embrace the problem, not the solution. Big or small, businesses should solve problems. This should be your focus. This is especially true when building a social company with an audience in mind.
Philosophically, invention and innovation are occasionally accidental. Also not penalized. Think about bugs and the creation of Velcro, or the inception of Teflon. They tackle difficulties we overlook. The route to the problem may look different, but there is a path there.
There's no golden ticket to the Chicken-Egg debate, but I'll keep looking this summer.

Sammy Abdullah
3 years ago
R&D, S&M, and G&A expense ratios for SaaS
SaaS spending is 40/40/20. 40% of operating expenses should be R&D, 40% sales and marketing, and 20% G&A. We wanted to see the statistics behind the rules of thumb. Since October 2017, 73 SaaS startups have gone public. Perhaps the rule of thumb should be 30/50/20. The data is below.
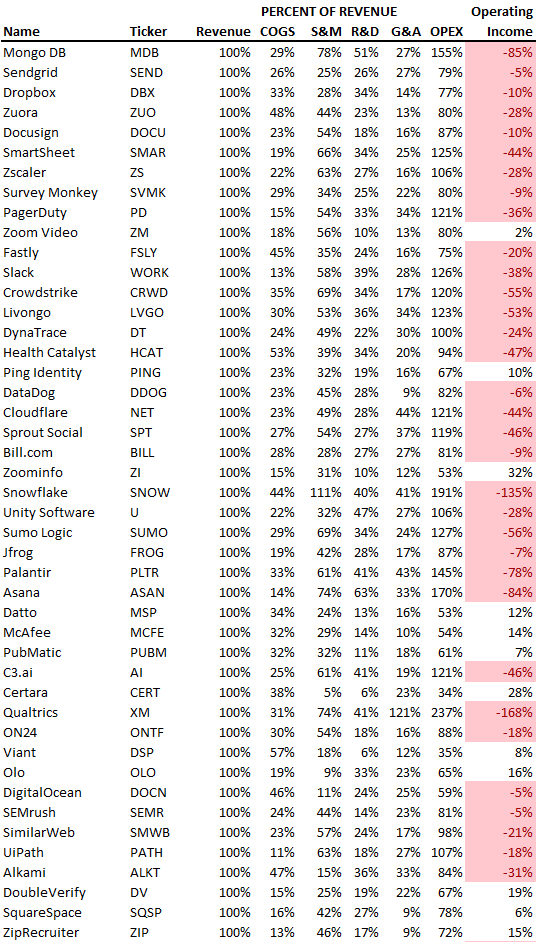
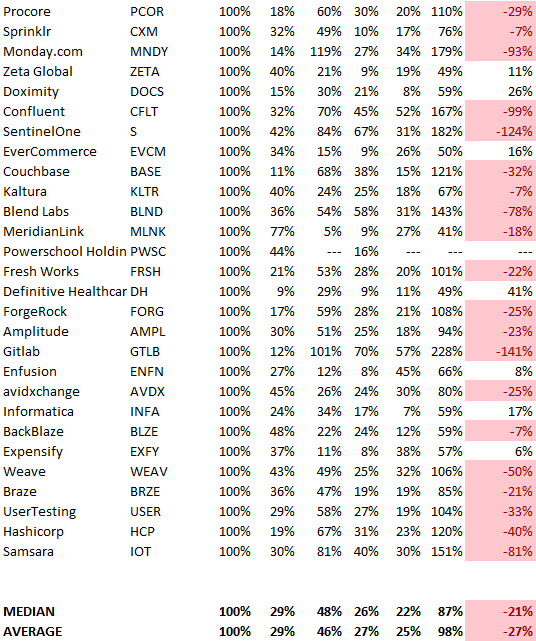
30/50/20. R&D accounts for 26% of opex, sales and marketing 48%, and G&A 22%. We think R&D/S&M/G&A should be 30/50/20.
There are outliers. There are exceptions to rules of thumb. Dropbox spent 45% on R&D whereas Zoom spent 13%. Zoom spent 73% on S&M, Dropbox 37%, and Bill.com 28%. Snowflake spent 130% of revenue on S&M, while their EBITDA margin is -192%.
G&A shouldn't stand out. Minimize G&A spending. Priorities should be product development and sales. Cloudflare, Sendgrid, Snowflake, and Palantir spend 36%, 34%, 37%, and 43% on G&A.
Another myth is that COGS is 20% of revenue. Median and averages are 29%.
Where is the profitability? Data-driven operating income calculations were simplified (Revenue COGS R&D S&M G&A). 20 of 73 IPO businesses reported operational income. Median and average operating income margins are -21% and -27%.
As long as you're growing fast, have outstanding retention, and marquee clients, you can burn cash since recurring income that doesn't churn is a valuable annuity.
The data was compelling overall. 30/50/20 is the new 40/40/20 for more established SaaS enterprises, unprofitability is alright as long as your business is expanding, and COGS can be somewhat more than 20% of revenue.
You might also like
Isobel Asher Hamilton
3 years ago
$181 million in bitcoin buried in a dump. $11 million to get them back

James Howells lost 8,000 bitcoins. He has $11 million to get them back.
His life altered when he threw out an iPhone-sized hard drive.
Howells, from the city of Newport in southern Wales, had two identical laptop hard drives squirreled away in a drawer in 2013. One was blank; the other had 8,000 bitcoins, currently worth around $181 million.
He wanted to toss out the blank one, but the drive containing the Bitcoin went to the dump.
He's determined to reclaim his 2009 stash.
Howells, 36, wants to arrange a high-tech treasure hunt for bitcoins. He can't enter the landfill.

Newport's city council has rebuffed Howells' requests to dig for his hard drive for almost a decade, stating it would be expensive and environmentally destructive.
I got an early look at his $11 million idea to search 110,000 tons of trash. He expects submitting it to the council would convince it to let him recover the hard disk.
110,000 tons of trash, 1 hard drive
Finding a hard disk among heaps of trash may seem Herculean.
Former IT worker Howells claims it's possible with human sorters, robot dogs, and an AI-powered computer taught to find hard drives on a conveyor belt.
His idea has two versions, depending on how much of the landfill he can search.
His most elaborate solution would take three years and cost $11 million to sort 100,000 metric tons of waste. Scaled-down version costs $6 million and takes 18 months.
He's created a team of eight professionals in AI-powered sorting, landfill excavation, garbage management, and data extraction, including one who recovered Columbia's black box data.
The specialists and their companies would be paid a bonus if they successfully recovered the bitcoin stash.
Howells: "We're trying to commercialize this project."
Howells claimed rubbish would be dug up by machines and sorted near the landfill.
Human pickers and a Max-AI machine would sort it. The machine resembles a scanner on a conveyor belt.
Remi Le Grand of Max-AI told us it will train AI to recognize Howells-like hard drives. A robot arm would select candidates.
Howells has added security charges to his scheme because he fears people would steal the hard drive.
He's budgeted for 24-hour CCTV cameras and two robotic "Spot" canines from Boston Dynamics that would patrol at night and look for his hard drive by day.
Howells said his crew met in May at the Celtic Manor Resort outside Newport for a pitch rehearsal.
Richard Hammond's narrative swings from banal to epic.
Richard Hammond filmed the meeting and created a YouTube documentary on Howells.
Hammond said of Howells' squad, "They're committed and believe in him and the idea."
Hammond: "It goes from banal to gigantic." "If I were in his position, I wouldn't have the strength to answer the door."
Howells said trash would be cleaned and repurposed after excavation. Reburying the rest.
"We won't pollute," he declared. "We aim to make everything better."

After the project is finished, he hopes to develop a solar or wind farm on the dump site. The council is unlikely to accept his vision soon.
A council representative told us, "Mr. Howells can't convince us of anything." "His suggestions constitute a significant ecological danger, which we can't tolerate and are forbidden by our permit."
Will the recovered hard drive work?
The "platter" is a glass or metal disc that holds the hard drive's data. Howells estimates 80% to 90% of the data will be recoverable if the platter isn't damaged.
Phil Bridge, a data-recovery expert who consulted Howells, confirmed these numbers.

If the platter is broken, Bridge adds, data recovery is unlikely.
Bridge says he was intrigued by the proposal. "It's an intriguing case," he added. Helping him get it back and proving everyone incorrect would be a great success story.
Who'd pay?
Swiss and German venture investors Hanspeter Jaberg and Karl Wendeborn told us they would fund the project if Howells received council permission.
Jaberg: "It's a needle in a haystack and a high-risk investment."
Howells said he had no contract with potential backers but had discussed the proposal in Zoom meetings. "Until Newport City Council gives me something in writing, I can't commit," he added.
Suppose he finds the bitcoins.
Howells said he would keep 30% of the data, worth $54 million, if he could retrieve it.
A third would go to the recovery team, 30% to investors, and the remainder to local purposes, including gifting £50 ($61) in bitcoin to each of Newport's 150,000 citizens.
Howells said he opted to spend extra money on "professional firms" to help convince the council.
What if the council doesn't approve?
If Howells can't win the council's support, he'll sue, claiming its actions constitute a "illegal embargo" on the hard drive. "I've avoided that path because I didn't want to cause complications," he stated. I wanted to cooperate with Newport's council.
Howells never met with the council face-to-face. He mentioned he had a 20-minute Zoom meeting in May 2021 but thought his new business strategy would help.
He met with Jessica Morden on June 24. Morden's office confirmed meeting.
After telling the council about his proposal, he can only wait. "I've never been happier," he said. This is our most professional operation, with the best employees.
The "crypto proponent" buys bitcoin every month and sells it for cash.
Howells tries not to think about what he'd do with his part of the money if the hard disk is found functional. "Otherwise, you'll go mad," he added.
This post is a summary. Read the full article here.

Nitin Sharma
3 years ago
Quietly Create a side business that will revolutionize everything in a year.
Quitting your job for a side gig isn't smart.

A few years ago, I would have laughed at the idea of starting a side business.
I never thought a side gig could earn more than my 9-to-5. My side gig pays more than my main job now.
You may then tell me to leave your job. But I don't want to gamble, and my side gig is important. Programming and web development help me write better because of my job.
Yes, I share work-related knowledge. Web development, web3, programming, money, investment, and side hustles are key.
Let me now show you how to make one.
Create a side business based on your profession or your interests.
I'd be direct.
Most people don't know where to start or which side business to pursue.
You can make money by taking online surveys, starting a YouTube channel, or playing web3 games, according to several blogs.
You won't make enough money and will waste time.
Nitin directs our efforts. My friend, you've worked and have talent. Profit from your talent.
Example:
College taught me web development. I soon created websites, freelanced, and made money. First year was hardest for me financially and personally.
As I worked, I became more skilled. Soon after, I got more work, wrote about web development on Medium, and started selling products.
I've built multiple income streams from web development. It wasn't easy. Web development skills got me a 9-to-5 job.
Focus on a specific skill and earn money in many ways. Most people start with something they hate or are bad at; the rest is predictable.
Result? They give up, frustrated.
Quietly focus for a year.
I started my side business in college and never told anyone. My parents didn't know what I did for fun.
The only motivation is time constraints. So I focused.
As I've said, I focused on my strengths (learned skills) and made money. Yes, I was among Medium's top 500 authors in a year and got a bonus.
How did I succeed? Since I know success takes time, I never imagined making enough money in a month. I spent a year concentrating.
I became wealthy. Now that I have multiple income sources, some businesses pay me based on my skill.
I recommend learning skills and working quietly for a year. You can do anything with this.
The hardest part will always be the beginning.
When someone says you can make more money working four hours a week. Leave that, it's bad advice.
If someone recommends a paid course to help you succeed, think twice.
The beginning is always the hardest.
I made many mistakes learning web development. When I started my technical content side gig, it was tough. I made mistakes and changed how I create content, which helped.
And it’s applicable everywhere.
Don't worry if you face problems at first. Time and effort heal all wounds.
Quitting your job to work a side job is not a good idea.
Some honest opinions.
Most online gurus encourage side businesses. It takes time to start and grow a side business.
Suppose you quit and started a side business.
After six months, what happens? Your side business won't provide enough money to survive.
Indeed. Later, you'll become demotivated and tense and look for work.
Instead, work 9-5, and start a side business. You decide. Stop watching Netflix and focus on your side business.
I know you're busy, but do it.
Next? It'll succeed or fail in six months. You can continue your side gig for another six months because you have a job and have tried it.
You'll probably make money, but you may need to change your side gig.
That’s it.
You've created a new revenue stream.
Remember.
Starting a side business, a company, or finding work is difficult. There's no free money in a competitive world. You'll only succeed with skill.
Read it again.
Focusing silently for a year can help you succeed.
I studied web development and wrote about it. First year was tough. I went viral, hit the top 500, and other firms asked me to write for them. So, my life changed.
Yours can too. One year of silence is required.
Enjoy!

Deon Ashleigh
3 years ago
You can dominate your daily productivity with these 9 little-known Google Calendar tips.
Calendars are great unpaid employees.
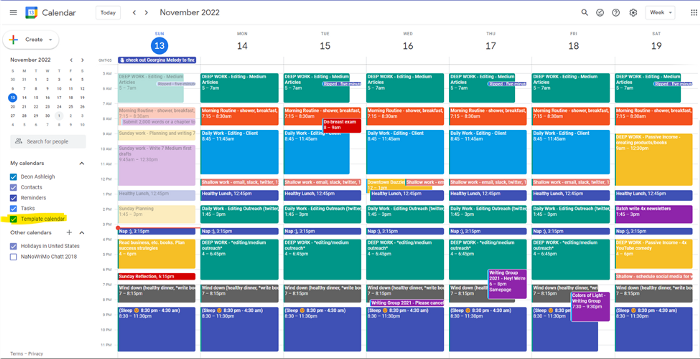
After using Notion to organize my next three months' goals, my days were a mess.
I grew very chaotic afterward. I was overwhelmed, unsure of what to do, and wasting time attempting to plan the day after it had started.
Imagine if our skeletons were on the outside. Doesn’t work.
The goals were too big; I needed to break them into smaller chunks. But how?
Enters Google Calendar
RescueTime’s recommendations took me seven hours to make a daily planner. This epic narrative begins with a sheet of paper and concludes with a daily calendar that helps me focus and achieve more goals. Ain’t nobody got time for “what’s next?” all day.
Onward!
Return to the Paleolithic Era
Plan in writing.
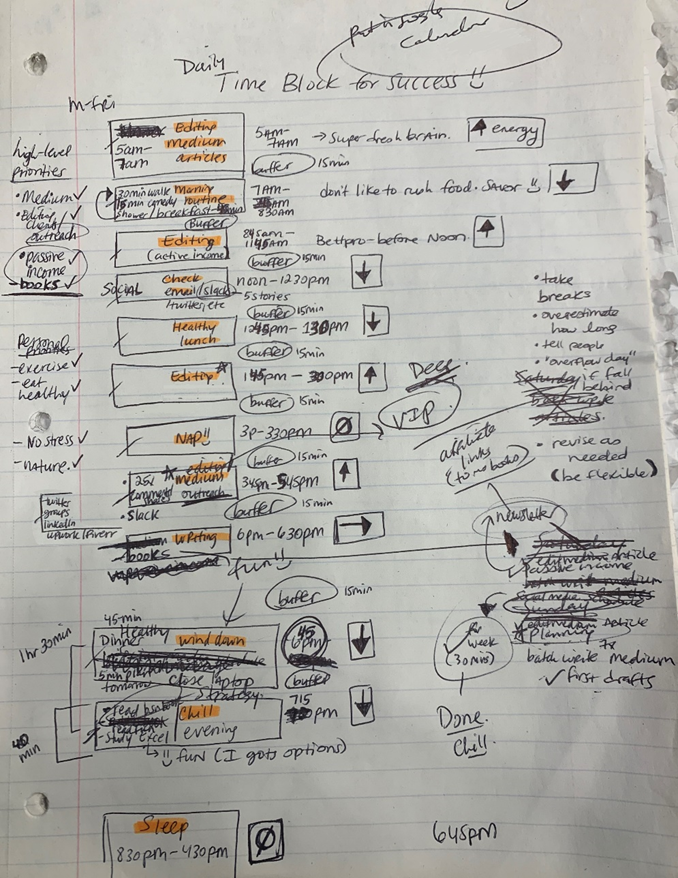
Not on the list, but it helped me plan my day. Physical writing boosts creativity and recall.
Find My Heart
i.e. prioritize
RescueTime suggested I prioritize before planning. Personal and business goals were proposed.
My top priorities are to exercise, eat healthily, spend time in nature, and avoid stress.
Priorities include writing and publishing Medium articles, conducting more freelance editing and Medium outreach, and writing/editing sci-fi books.
These eight things will help me feel accomplished every day.
Make a baby calendar.
Create daily calendar templates.
Make family, pleasure, etc. calendars.
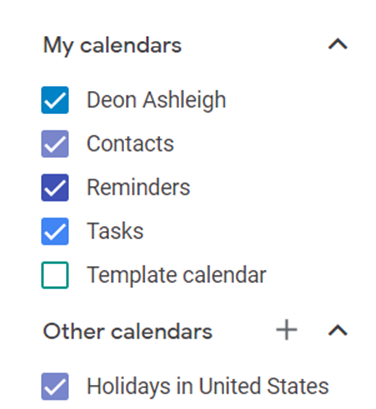
Google Calendar instructions:
Other calendars
Press the “+” button
Create a new calendar
Create recurring events for each day
My calendar, without the template:
Empty, so I can fill it with vital tasks.
With the template:
My daily skeleton corresponds with my priorities. I've been overwhelmed for years because I lack daily, weekly, monthly, and yearly structure.
Google Calendars helps me reach my goals and focus my energy.
Get your colored pencils ready
Time-block color-coding.
Color labeling lets me quickly see what's happening. Maybe you are too.
Google Calendar instructions:
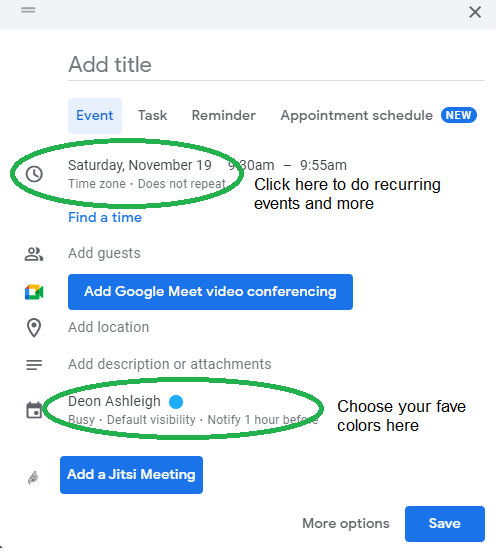
Determine which colors correspond to each time block.
When establishing new events, select a color.
Save
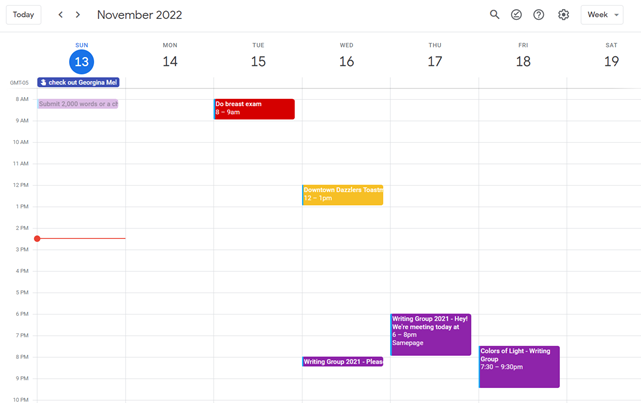
My calendar is color-coded as follows:
Yellow — passive income or other future-related activities
Red — important activities, like my monthly breast exam
Flamingo — shallow work, like emails, Twitter, etc.
Blue — all my favorite activities, like walking, watching comedy, napping, and sleeping. Oh, and eating.
Green — money-related events required for this adulting thing
Purple — writing-related stuff
Associating a time block with a color helps me stay focused. Less distractions mean faster work.
Open My Email
aka receive a daily email from Google Calendar.
Google Calendar sends a daily email feed of your calendars. I sent myself the template calendar in this email.
Google Calendar instructions:
Access settings
Select the calendar that you want to send (left side)
Go down the page to see more alerts
Under the daily agenda area, click Email.

Get in Touch With Your Red Bull Wings — Naturally
aka audit your energy levels.
My daily planner has arrows. These indicate how much energy each activity requires or how much I have.
Rightward arrow denotes medium energy.
I do my Medium and professional editing in the morning because it's energy-intensive.
Niharikaa Sodhi recommends morning Medium editing.
I’m a morning person. As long as I go to bed at a reasonable time, 5 a.m. is super wild GO-TIME. It’s like the world was just born, and I marvel at its wonderfulness.
Freelance editing lets me do what I want. An afternoon snooze will help me finish on time.
Ditch Schedule View
aka focus on the weekly view.
RescueTime advocated utilizing the weekly view of Google Calendar, so I switched.
When you launch the phone app or desktop calendar, a red line shows where you are in the day.
I'll follow the red line's instructions. My digital supervisor is easy to follow.
In the image above, it's almost 3 p.m., therefore the red line implies it's time to snooze.
I won't forget this block ;).
Reduce the Lighting
aka dim previous days.
This is another Google Calendar feature I didn't know about. Once the allotted time passes, the time block dims. This keeps me present.
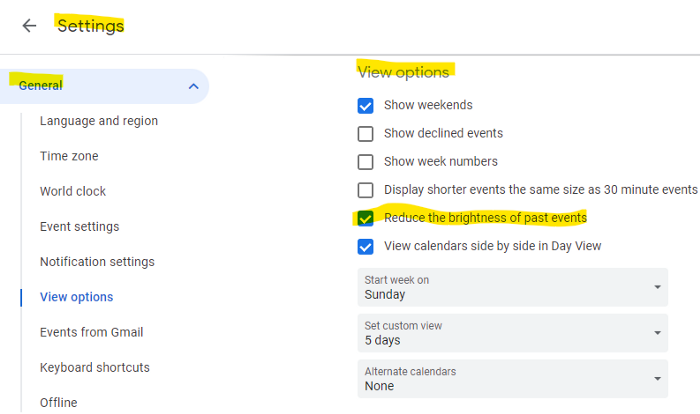
Google Calendar instructions:
Access settings
remaining general
To view choices, click.
Check Diminish the glare of the past.
Bonus
Two additional RescueTimes hacks:
Maintain a space between tasks
I left 15 minutes between each time block to transition smoothly. This relates to my goal of less stress. If I set strict start and end times, I'll be stressed.
With a buffer, I can breathe, stroll around, and start the following time block fresh.
Find a time is related to the buffer.
This option allows you conclude small meetings five minutes early and longer ones ten. Before the next meeting, relax or go wild.
Decide on a backup day.
This productivity technique is amazing.
Spend this excess day catching up on work. It helps reduce tension and clutter.
That's all I can say about Google Calendar's functionality.