

# DeaMau5’s PIXELYNX and Beatport Launch Festival NFTs
Pixelynx, a music metaverse gaming platform, has teamed up with Beatport, an online music retailer focusing in electronic music, to establish a Synth Heads non-fungible token (NFT) Collection.
Richie Hawtin, aka Deadmau5, and Joel Zimmerman, nicknamed Pixelynx, have invented a new music metaverse game platform called Pixelynx. In January 2022, they released their first Beatport NFT drop, which saw 3,030 generative NFTs sell out in seconds.
The limited edition Synth Heads NFTs will be released in collaboration with Junction 2, the largest UK techno festival, and having one will grant fans special access tickets and experiences at the London-based festival.
Membership in the Synth Head community, day passes to the Junction 2 Festival 2022, Junction 2 and Beatport apparel, special vinyl releases, and continued access to future ticket drops are just a few of the experiences available.
Five lucky NFT holders will also receive a Golden Ticket, which includes access to a backstage artist bar and tickets to Junction 2's next large-scale London event this summer, in addition to full festival entrance for both days.
The Junction 2 festival will take place at Trent Park in London on June 18th and 19th, and will feature performances from Four Tet, Dixon, Amelie Lens, Robert Hood, and a slew of other artists. Holders of the original Synth Head NFT will be granted admission to the festival's guestlist as well as line-jumping privileges.
The new Synth Heads NFTs collection contain 300 NFTs.
NFTs that provide IRL utility are in high demand.
The benefits of NFT drops related to In Real Life (IRL) utility aren't limited to Beatport and Pixelynx.
Coachella, a well-known music event, recently partnered with cryptocurrency exchange FTX to offer free NFTs to 2022 pass holders. Access to a dedicated entry lane, a meal and beverage pass, and limited-edition merchandise were all included with the NFTs.
Coachella also has its own NFT store on the Solana blockchain, where fans can buy Coachella NFTs and digital treasures that unlock exclusive on-site experiences, physical objects, lifetime festival passes, and "future adventures."
Individual artists and performers have begun taking advantage of NFT technology outside of large music festivals like Coachella.
DJ Tisto has revealed that he would release a VIP NFT for his upcoming "Eagle" collection during the EDC festival in Las Vegas in 2022. This NFT, dubbed "All Access Eagle," gives collectors the best chance to get NFTs from his first drop, as well as unique access to the music "Repeat It."
NFTs are one-of-a-kind digital assets that can be verified, purchased, sold, and traded on blockchains, opening up new possibilities for artists and businesses alike. Time will tell whether Beatport and Pixelynx's Synth Head NFT collection will be successful, but if it's anything like the first release, it's a safe bet.
More on NFTs & Art

Ezra Reguerra
3 years ago
Yuga Labs’ Otherdeeds NFT mint triggers backlash from community
Unhappy community members accuse Yuga Labs of fraud, manipulation, and favoritism over Otherdeeds NFT mint.
Following the Otherdeeds NFT mint, disgruntled community members took to Twitter to criticize Yuga Labs' handling of the event.
Otherdeeds NFTs were a huge hit with the community, selling out almost instantly. Due to high demand, the launch increased Ethereum gas fees from 2.6 ETH to 5 ETH.
But the event displeased many people. Several users speculated that the mint was “planned to fail” so the group could advertise launching its own blockchain, as the team mentioned a chain migration in one tweet.
Others like Mark Beylin tweeted that he had "sold out" on all Ape-related NFT investments after Yuga Labs "revealed their true colors." Beylin also advised others to assume Yuga Labs' owners are “bad actors.”
Some users who failed to complete transactions claim they lost ETH. However, Yuga Labs promised to refund lost gas fees.
CryptoFinally, a Twitter user, claimed Yuga Labs gave BAYC members better land than non-members. Others who wanted to participate paid for shittier land, while BAYCS got the only worthwhile land.
The Otherdeed NFT drop also increased Ethereum's burn rate. Glassnode and Data Always reported nearly 70,000 ETH burned on mint day.

Protos
3 years ago
Plagiarism on OpenSea: humans and computers
OpenSea, a non-fungible token (NFT) marketplace, is fighting plagiarism. A new “two-pronged” approach will aim to root out and remove copies of authentic NFTs and changes to its blue tick verified badge system will seek to enhance customer confidence.
According to a blog post, the anti-plagiarism system will use algorithmic detection of “copymints” with human reviewers to keep it in check.
Last year, NFT collectors were duped into buying flipped images of the popular BAYC collection, according to The Verge. The largest NFT marketplace had to remove its delay pay minting service due to an influx of copymints.
80% of NFTs removed by the platform were minted using its lazy minting service, which kept the digital asset off-chain until the first purchase.
NFTs copied from popular collections are opportunistic money-grabs. Right-click, save, and mint the jacked JPEGs that are then flogged as an authentic NFT.
The anti-plagiarism system will scour OpenSea's collections for flipped and rotated images, as well as other undescribed permutations. The lack of detail here may be a deterrent to scammers, or it may reflect the new system's current rudimentary nature.
Thus, human detectors will be needed to verify images flagged by the detection system and help train it to work independently.
“Our long-term goal with this system is two-fold: first, to eliminate all existing copymints on OpenSea, and second, to help prevent new copymints from appearing,” it said.
“We've already started delisting identified copymint collections, and we'll continue to do so over the coming weeks.”
It works for Twitter, why not OpenSea
OpenSea is also changing account verification. Early adopters will be invited to apply for verification if their NFT stack is worth $100 or more. OpenSea plans to give the blue checkmark to people who are active on Twitter and Discord.
This is just the beginning. We are committed to a future where authentic creators can be verified, keeping scammers out.
Also, collections with a lot of hype and sales will get a blue checkmark. For example, a new NFT collection sold by the verified BAYC account will have a blue badge to verify its legitimacy.
New requests will be responded to within seven days, according to OpenSea.
These programs and products help protect creators and collectors while ensuring our community can confidently navigate the world of NFTs.
By elevating authentic content and removing plagiarism, these changes improve trust in the NFT ecosystem, according to OpenSea.
OpenSea is indeed catching up with the digital art economy. Last August, DevianArt upgraded its AI image recognition system to find stolen tokenized art on marketplaces like OpenSea.
It scans all uploaded art and compares it to “public blockchain events” like Ethereum NFTs to detect stolen art.

Jake Prins
3 years ago
What are NFTs 2.0 and what issues are they meant to address?
New standards help NFTs reach their full potential.

NFTs lack interoperability and functionality. They have great potential but are mostly speculative. To maximize NFTs, we need flexible smart contracts.
Current requirements are too restrictive.
Most NFTs are based on ERC-721, which makes exchanging them easy. CryptoKitties, a popular online game, used the 2017 standard to demonstrate NFTs' potential.
This simple standard includes a base URI and incremental IDs for tokens. Add the tokenID to the base URI to get the token's metadata.
This let creators collect NFTs. Many NFT projects store metadata on IPFS, a distributed storage network, but others use Google Drive. NFT buyers often don't realize that if the creators delete or move the files, their NFT is just a pointer.
This isn't the standard's biggest issue. There's no way to validate NFT projects.
Creators are one of the most important aspects of art, but nothing is stored on-chain.
ERC-721 contracts only have a name and symbol.
Most of the data on OpenSea's collection pages isn't from the NFT's smart contract. It was added through a platform input field, so it's in the marketplace's database. Other websites may have different NFT information.
In five years, your NFT will be just a name, symbol, and ID.
Your NFT doesn't mention its creators. Although the smart contract has a public key, it doesn't reveal who created it.
The NFT's creators and their reputation are crucial to its value. Think digital fashion and big brands working with well-known designers when more professionals use NFTs. Don't you want them in your NFT?
Would paintings be as valuable if their artists were unknown? Would you believe it's real?
Buying directly from an on-chain artist would reduce scams. Current standards don't allow this data.
Most creator profiles live on centralized marketplaces and could disappear. Current platforms have outpaced underlying standards. The industry's standards are lagging.
For NFTs to grow beyond pointers to a monkey picture file, we may need to use new Web3-based standards.
Introducing NFTs 2.0
Fabian Vogelsteller, creator of ERC-20, developed new web3 standards. He proposed LSP7 Digital Asset and LSP8 Identifiable Digital Asset, also called NFT 2.0.
NFT and token metadata inputs are extendable. Changes to on-chain metadata inputs allow NFTs to evolve. Instead of public keys, the contract can have Universal Profile addresses attached. These profiles show creators' faces and reputations. NFTs can notify asset receivers, automating smart contracts.
LSP7 and LSP8 use ERC725Y. Using a generic data key-value store gives contracts much-needed features:
The asset can be customized and made to stand out more by allowing for unlimited data attachment.
Recognizing changes to the metadata
using a hash reference for metadata rather than a URL reference
This base will allow more metadata customization and upgradeability. These guidelines are:
Genuine and Verifiable Now, the creation of an NFT by a specific Universal Profile can be confirmed by smart contracts.
Dynamic NFTs can update Flexible & Updatable Metadata, allowing certain things to evolve over time.
Protected metadata Now, secure metadata that is readable by smart contracts can be added indefinitely.
Better NFTS prevent the locking of NFTs by only being sent to Universal Profiles or a smart contract that can interact with them.
Summary
NFTS standards lack standardization and powering features, limiting the industry.
ERC-721 is the most popular NFT standard, but it only represents incremental tokenIDs without metadata or asset representation. No standard sender-receiver interaction or security measures ensure safe asset transfers.
NFT 2.0 refers to the new LSP7-DigitalAsset and LSP8-IdentifiableDigitalAsset standards.
They have new standards for flexible metadata, secure transfers, asset representation, and interactive transfer.
With NFTs 2.0 and Universal Profiles, creators could build on-chain reputations.
NFTs 2.0 could bring the industry's needed innovation if it wants to move beyond trading profile pictures for speculation.
You might also like

Jon Brosio
3 years ago
You can learn more about marketing from these 8 copywriting frameworks than from a college education.
Email, landing pages, and digital content

Today's most significant skill:
Copywriting.
Unfortunately, most people don't know how to write successful copy because they weren't taught in school.
I've been obsessed with copywriting for two years. I've read 15 books, completed 3 courses, and studied internet's best digital entrepreneurs.
Here are 8 copywriting frameworks that educate more than a four-year degree.
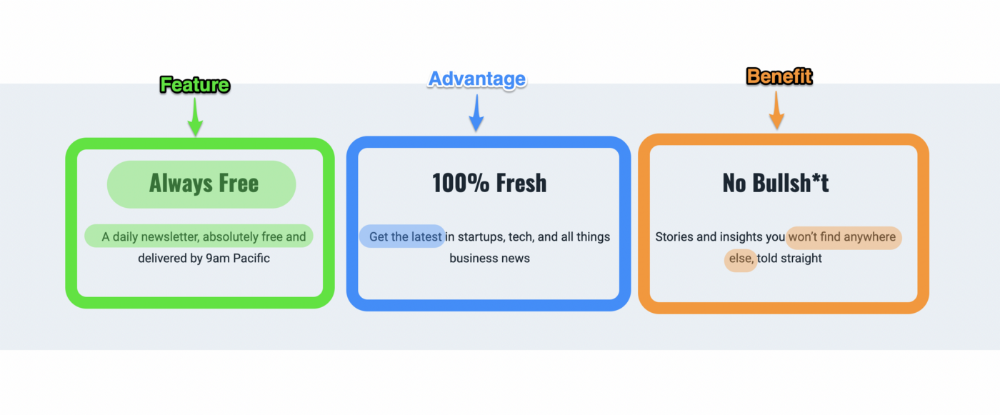
1. Feature — Advantage — Benefit (F.A.B)
This is the most basic copywriting foundation. Email marketing, landing page copy, and digital video ads can use it.
F.A.B says:
How it works (feature)
which is helpful (advantage)
What's at stake (benefit)
The Hustle uses this framework on their landing page to convince people to sign up:
2. P. A. S. T. O. R.
This framework is for longer-form copywriting. PASTOR uses stories to engage with prospects. It explains why people should buy this offer.
PASTOR means:
Problem
Amplify
Story
Testimonial
Offer
Response
Dan Koe's landing page is a great example. It shows PASTOR frame-by-frame.

3. Before — After — Bridge
Before-after-bridge is a copywriting framework that draws attention and shows value quickly.
This framework highlights:
where you are
where you want to be
how to get there
Works great for: Email threads/landing pages
Zain Kahn utilizes this framework to write viral threads.

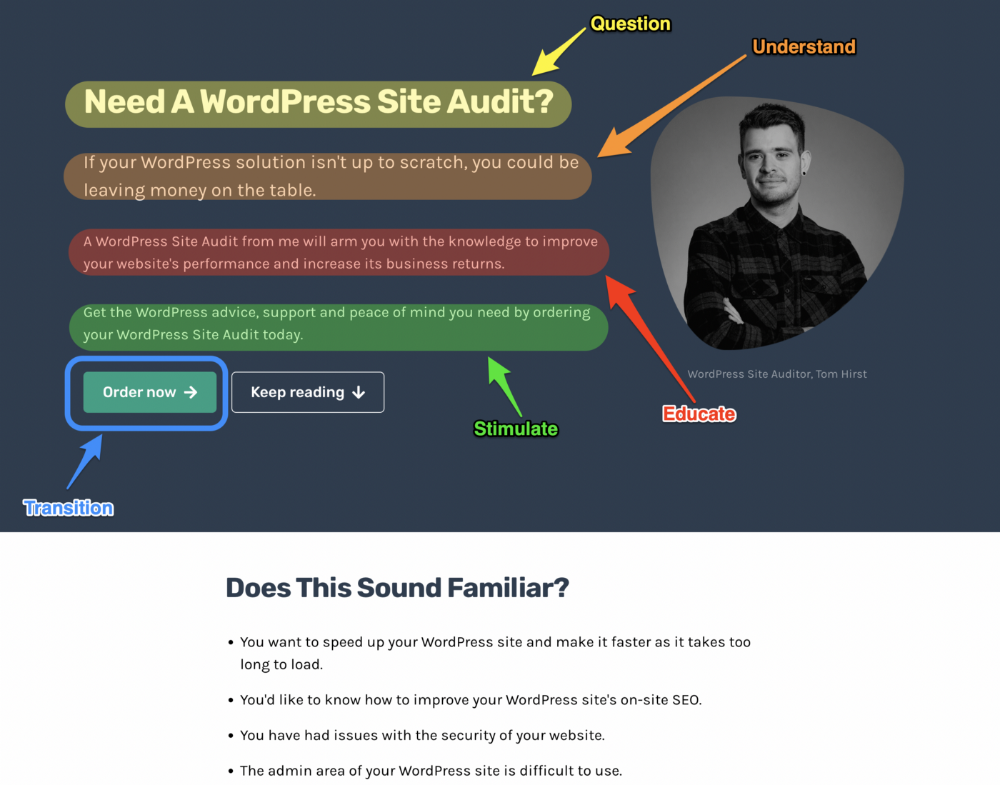
4. Q.U.E.S.T
QUEST is about empathetic writing. You know their issues, obstacles, and headaches. This allows coverups.
QUEST:
Qualifies
Understands
Educates
Stimulates
Transitions
Tom Hirst's landing page uses the QUEST framework.
5. The 4P’s model
The 4P’s approach pushes your prospect to action. It educates and persuades quickly.
4Ps:
The problem the visitor is dealing with
The promise that will help them
The proof the promise works
A push towards action
Mark Manson is a bestselling author, digital creator, and pop-philosopher. He's also a great copywriter, and his membership offer uses the 4P’s framework.

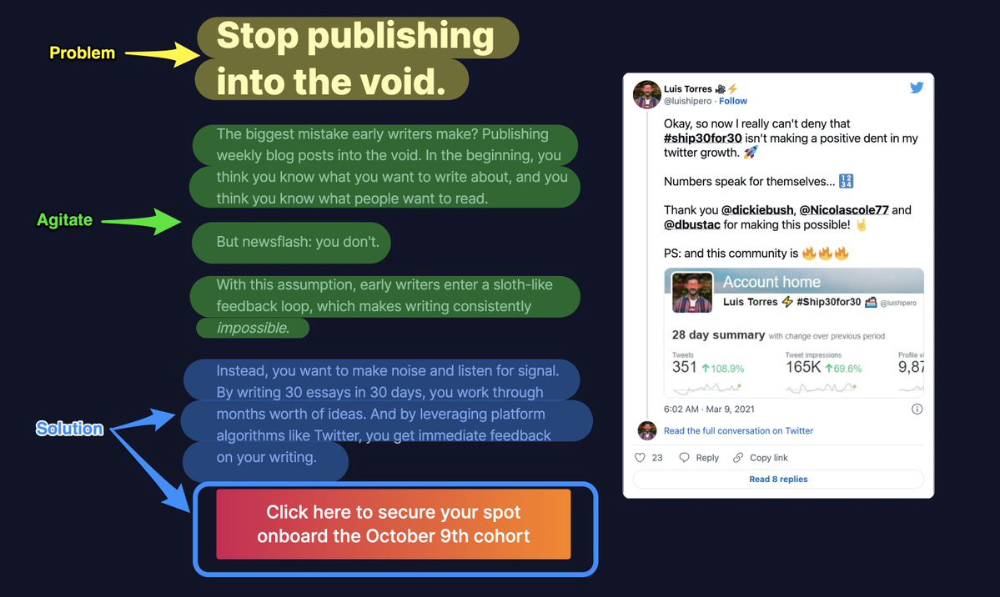
6. Problem — Agitate — Solution (P.A.S)
Up-and-coming marketers should understand problem-agitate-solution copywriting. Once you understand one structure, others are easier. It drives passion and presents a clear solution.
PAS outlines:
The issue the visitor is having
It then intensifies this issue through emotion.
finally offers an answer to that issue (the offer)
The customer's story loops. Nicolas Cole and Dickie Bush use PAS to promote Ship 30 for 30.
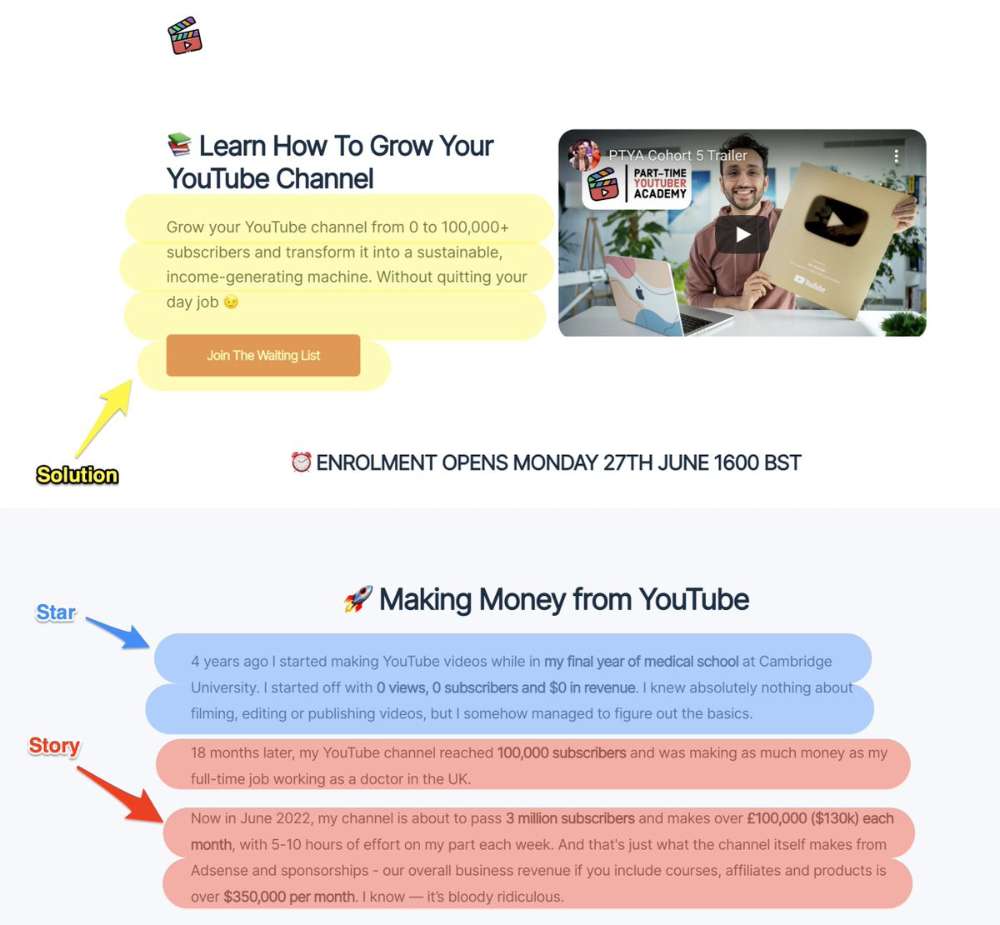
7. Star — Story — Solution (S.S.S)
PASTOR + PAS = star-solution-story. Like PAS, it employs stories to persuade.
S.S.S. is effective storytelling:
Star: (Person had a problem)
Story: (until they had a breakthrough)
Solution: (That created a transformation)
Ali Abdaal is a YouTuber with a great S.S.S copy.
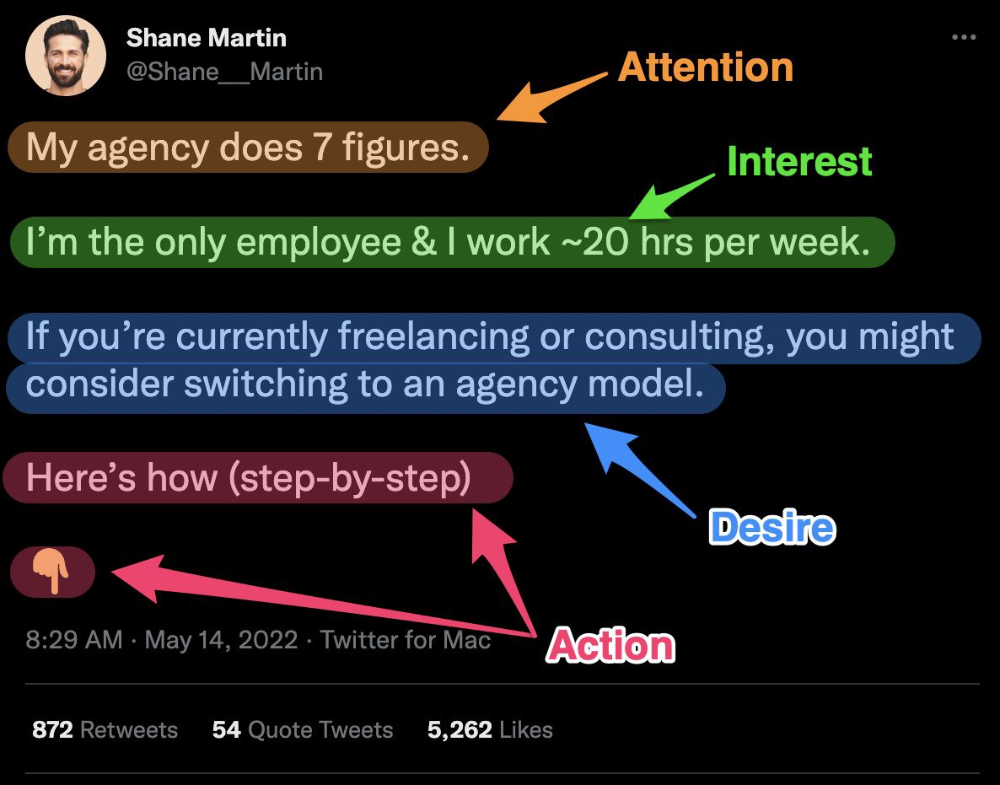
8. Attention — Interest — Desire — Action
AIDA is another classic. This copywriting framework is great for fast-paced environments (think all digital content on Linkedin, Twitter, Medium, etc.).
It works with:
Page landings
writing on thread
Email
It's a good structure since it's concise, attention-grabbing, and action-oriented.
Shane Martin, Twitter's creator, uses this approach to create viral content.
TL;DR
8 copywriting frameworks that teach marketing better than a four-year degree
Feature-advantage-benefit
Before-after-bridge
Star-story-solution
P.A.S.T.O.R
Q.U.E.S.T
A.I.D.A
P.A.S
4P’s

mbvissers.eth
3 years ago
Why does every smart contract seem to implement ERC165?

ERC165 (or EIP-165) is a standard utilized by various open-source smart contracts like Open Zeppelin or Aavegotchi.
What's it? You must implement? Why do we need it? I'll describe the standard and answer any queries.
What is ERC165
ERC165 detects and publishes smart contract interfaces. Meaning? It standardizes how interfaces are recognized, how to detect if they implement ERC165, and how a contract publishes the interfaces it implements. How does it work?
Why use ERC165? Sometimes it's useful to know which interfaces a contract implements, and which version.
Identifying interfaces
An interface function's selector. This verifies an ABI function. XORing all function selectors defines an interface in this standard. The following code demonstrates.
// SPDX-License-Identifier: UNLICENCED
pragma solidity >=0.8.0 <0.9.0;
interface Solidity101 {
function hello() external pure;
function world(int) external pure;
}
contract Selector {
function calculateSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector ^ i.world.selector;
// Returns 0xc6be8b58
}
function getHelloSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector;
// Returns 0x19ff1d21
}
function getWorldSelector() public pure returns (bytes4) {
Solidity101 i;
return i.world.selector;
// Returns 0xdf419679
}
}This code isn't necessary to understand function selectors and how an interface's selector can be determined from the functions it implements.
Run that sample in Remix to see how interface function modifications affect contract function output.
Contracts publish their implemented interfaces.
We can identify interfaces. Now we must disclose the interfaces we're implementing. First, import IERC165 like so.
pragma solidity ^0.4.20;
interface ERC165 {
/// @notice Query if a contract implements an interface
/// @param interfaceID The interface identifier, as specified in ERC-165
/// @dev Interface identification is specified in ERC-165.
/// @return `true` if the contract implements `interfaceID` and
/// `interfaceID` is not 0xffffffff, `false` otherwise
function supportsInterface(bytes4 interfaceID) external view returns (bool);
}We still need to build this interface in our smart contract. ERC721 from OpenZeppelin is a good example.
// SPDX-License-Identifier: MIT
// OpenZeppelin Contracts (last updated v4.5.0) (token/ERC721/ERC721.sol)
pragma solidity ^0.8.0;
import "./IERC721.sol";
import "./extensions/IERC721Metadata.sol";
import "../../utils/introspection/ERC165.sol";
// ...
contract ERC721 is Context, ERC165, IERC721, IERC721Metadata {
// ...
function supportsInterface(bytes4 interfaceId) public view virtual override(ERC165, IERC165) returns (bool) {
return
interfaceId == type(IERC721).interfaceId ||
interfaceId == type(IERC721Metadata).interfaceId ||
super.supportsInterface(interfaceId);
}
// ...
}I deleted unnecessary code. The smart contract imports ERC165, IERC721 and IERC721Metadata. The is keyword at smart contract declaration implements all three.
Kind (interface).
Note that type(interface).interfaceId returns the same as the interface selector.
We override supportsInterface in the smart contract to return a boolean that checks if interfaceId is the same as one of the implemented contracts.
Super.supportsInterface() calls ERC165 code. Checks if interfaceId is IERC165.
function supportsInterface(bytes4 interfaceId) public view virtual override returns (bool) {
return interfaceId == type(IERC165).interfaceId;
}So, if we run supportsInterface with an interfaceId, our contract function returns true if it's implemented and false otherwise. True for IERC721, IERC721Metadata, andIERC165.
Conclusion
I hope this post has helped you understand and use ERC165 and why it's employed.
Have a great day, thanks for reading!

Tim Denning
3 years ago
Elon Musk’s Rich Life Is a Nightmare
I'm sure you haven't read about Elon's other side.
Elon divorced badly.
Nobody's surprised.
Imagine you're a parent. Someone isn't home year-round. What's next?
That’s what happened to YOLO Elon.
He can do anything. He can intervene in wars, shoot his mouth off, bang anyone he wants, avoid tax, make cool tech, buy anything his ego desires, and live anywhere exotic.
Few know his billionaire backstory. I'll tell you so you don't worship his lifestyle. It’s a cult.
Only his career succeeds. His life is a nightmare otherwise.
Psychopaths' schedule
Elon has said he works 120-hour weeks.
As he told the reporter about his job, he choked up, which was unusual for him.
His crazy workload and lack of sleep forced him to scold innocent Wall Street analysts. Later, he apologized.
In the same interview, he admits he hadn't taken more than a week off since 2001, when he was bedridden with malaria. Elon stays home after a near-death experience.
He's rarely outside.
Elon says he sometimes works 3 or 4 days straight.
He admits his crazy work schedule has cost him time with his kids and friends.
Elon's a slave
Elon's birthday description made him emotional.
Elon worked his entire birthday.
"No friends, nothing," he said, stuttering.
His brother's wedding in Catalonia was 48 hours after his birthday. That meant flying there from Tesla's factory prison.
He arrived two hours before the big moment, barely enough time to eat and change, let alone see his brother.
Elon had to leave after the bouquet was tossed to a crowd of billionaire lovers. He missed his brother's first dance with his wife.
Shocking.
He went straight to Tesla's prison.
The looming health crisis
Elon was asked if overworking affected his health.
Not great. Friends are worried.
Now you know why Elon tweets dumb things. Working so hard has probably caused him mental health issues.
Mental illness removed my reality filter. You do stupid things because you're tired.
Astronauts pelted Elon
Elon's overwork isn't the first time his life has made him emotional.
When asked about Neil Armstrong and Gene Cernan criticizing his SpaceX missions, he got emotional. Elon's heroes.
They're why he started the company, and they mocked his work. In another interview, we see how Elon’s business obsession has knifed him in the heart.
Once you have a company, you must feed, nurse, and care for it, even if it destroys you.
"Yep," Elon says, tearing up.
In the same interview, he's asked how Tesla survived the 2008 recession. Elon stopped the interview because he was crying. When Tesla and SpaceX filed for bankruptcy in 2008, he nearly had a nervous breakdown. He called them his "children."
All the time, he's risking everything.
Jack Raines explains best:
Too much money makes you a slave to your net worth.
Elon's emotions are admirable. It's one of the few times he seems human, not like an alien Cyborg.
Stop idealizing Elon's lifestyle
Building a side business that becomes a billion-dollar unicorn startup is a nightmare.
"Billionaire" means financially wealthy but otherwise broke. A rich life includes more than business and money.
This post is a summary. Read full article here