












More on Personal Growth

Akshad Singi
3 years ago
Four obnoxious one-minute habits that help me save more than 30 hours each week
These four, when combined, destroy procrastination.

You're not rushed. You waste it on busywork.
You'll accept this eventually.
In 2022, the daily average usage of a user on social media is 2.5 hours.
By 2020, 6 billion hours of video were watched each month by Netflix's customers, who used the service an average of 3.2 hours per day.
When we see these numbers, we think "Wow!" People squander so much time as though they don't contribute. True. These are yours. Likewise.
We don't lack time; we just waste it. Once you realize this, you can change your habits to save time. This article explains. If you adopt ALL 4 of these simple behaviors, you'll see amazing benefits.
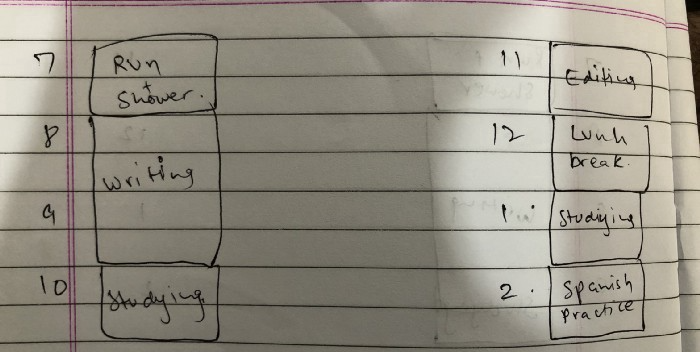
Time-blocking
Cal Newport's time-blocking trick takes a minute but improves your day's clarity.
Divide the next day into 30-minute (or 5-minute, if you're Elon Musk) segments and assign responsibilities. As seen.
Here's why:
The procrastination that results from attempting to determine when to begin working is eliminated. Procrastination is a given if you choose when to begin working in real-time. Even if you may assume you'll start working in five minutes, it won't take you long to realize that five minutes have turned into an hour. But if you've already determined to start working at 2:00 the next day, your odds of procrastinating are greatly decreased, if not eliminated altogether.
You'll also see that you have a lot of time in a day when you plan your day out on paper and assign chores to each hour. Doing this daily will permanently eliminate the lack of time mindset.
5-4-3-2-1: Have breakfast with the frog!
“If it’s your job to eat a frog, it’s best to do it first thing in the morning. And If it’s your job to eat two frogs, it’s best to eat the biggest one first.”
Eating the frog means accomplishing the day's most difficult chore. It's better to schedule it first thing in the morning when time-blocking the night before. Why?
The day's most difficult task is also the one that causes the most postponement. Because of the stress it causes, the later you schedule it, the more time you risk wasting by procrastinating.
However, if you do it right away in the morning, you'll feel good all day. This is the reason it was set for the morning.
Mel Robbins' 5-second rule can help. Start counting backward 54321 and force yourself to start at 1. If you acquire the urge to work on a goal, you must act within 5 seconds or your brain will destroy it. If you're scheduled to eat your frog at 9, eat it at 8:59. Start working.
Micro-visualisation
You've heard of visualizing to enhance the future. Visualizing a bright future won't do much if you're not prepared to focus on the now and develop the necessary habits. Alexander said:
People don’t decide their futures. They decide their habits and their habits decide their future.
I visualize the next day's schedule every morning. My day looks like this
“I’ll start writing an article at 7:30 AM. Then, I’ll get dressed up and reach the medicine outpatient department by 9:30 AM. After my duty is over, I’ll have lunch at 2 PM, followed by a nap at 3 PM. Then, I’ll go to the gym at 4…”
etc.
This reinforces the day you planned the night before. This makes following your plan easy.
Set the timer.
It's the best iPhone productivity app. A timer is incredible for increasing productivity.
Set a timer for an hour or 40 minutes before starting work. Your call. I don't believe in techniques like the Pomodoro because I can focus for varied amounts of time depending on the time of day, how fatigued I am, and how cognitively demanding the activity is.
I work with a timer. A timer keeps you focused and prevents distractions. Your mind stays concentrated because of the timer. Timers generate accountability.
To pee, I'll pause my timer. When I sit down, I'll continue. Same goes for bottle refills. To use Twitter, I must pause the timer. This creates accountability and focuses work.
Connecting everything
If you do all 4, you won't be disappointed. Here's how:
Plan out your day's schedule the night before.
Next, envision in your mind's eye the same timetable in the morning.
Speak aloud 54321 when it's time to work: Eat the frog! In the morning, devour the largest frog.
Then set a timer to ensure that you remain focused on the task at hand.
Tom Connor
3 years ago
12 mental models that I use frequently
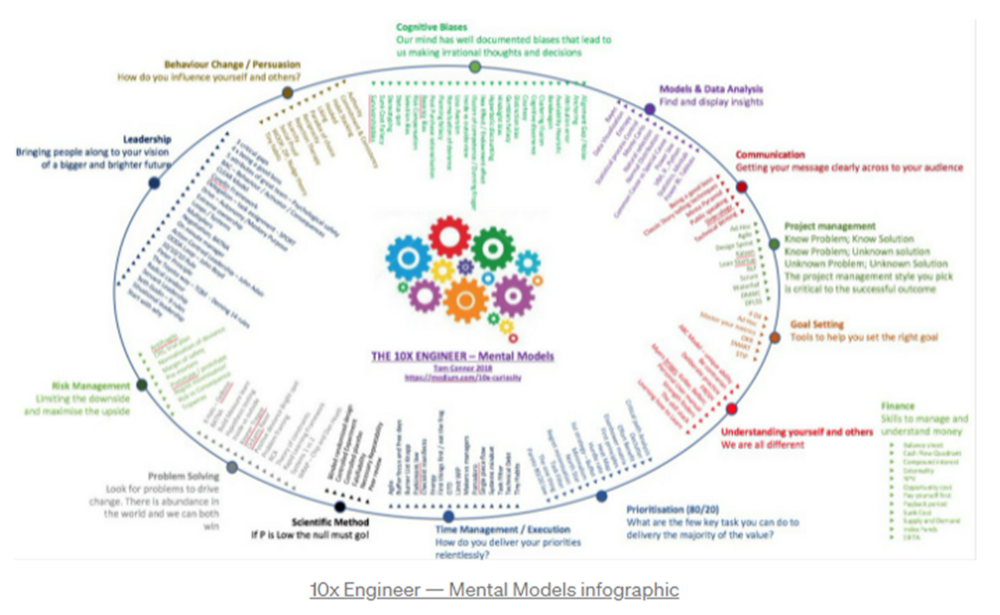
https://tomconnor.me/wp-content/uploads/2021/08/10x-Engineer-Mental-Models.pdf
I keep returning to the same mental models and tricks after writing and reading about a wide range of topics.
Top 12 mental models
12.
Survival bias - We perceive the surviving population as remarkable, yet they may have gotten there through sheer grit.
Survivorship bias affects us in many situations. Our retirement fund; the unicorn business; the winning team. We often study and imitate the last one standing. This can lead to genuine insights and performance improvements, but it can also lead us astray because the leader may just be lucky.
11.
The Helsinki Bus Theory - How to persevere Buss up!
Always display new work, and always be compared to others. Why? Easy. Keep riding. Stay on the fucking bus.
10.
Until it sticks… Turning up every day… — Artists teach engineers plenty. Quality work over a career comes from showing up every day and starting.
9.
WRAP decision making process (Heath Brothers)
Decision-making WRAP Model:
W — Widen your Options
R — Reality test your assumptions
A — Attain Distance
P — Prepare to be wrong or Right
8.
Systems for knowledge worker excellence - Todd Henry and Cal Newport write about techniques knowledge workers can employ to build a creative rhythm and do better work.
Todd Henry's FRESH framework:
Focus: Keep the start in mind as you wrap up.
Relationships: close a loop that's open.
Pruning is an energy.
Set aside time to be inspired by stimuli.
Hours: Spend time thinking.
7.
BBT is learning from mistakes. Science has transformed the world because it constantly updates its theories in light of failures. Complexity guarantees failure. Do we learn or self-justify?
6.
The OODA Loop - Competitive advantage
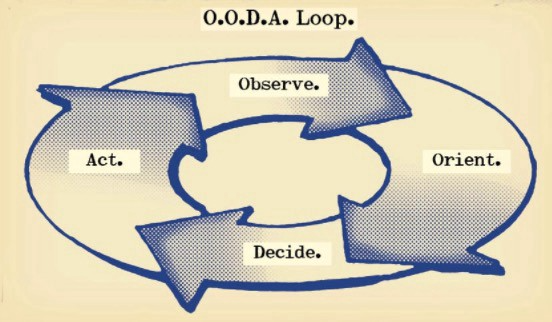
O: Observe: collect the data. Figure out exactly where you are, what’s happening.
O: Orient: analyze/synthesize the data to form an accurate picture.
D: Decide: select an action from possible options
A: Action: execute the action, and return to step (1)
Boyd's approach indicates that speed and agility are about information processing, not physical reactions. They form feedback loops. More OODA loops improve speed.
5.
Leaders who try to impose order in a complex situation fail; those who set the stage, step back, and allow patterns to develop win.
https://vimeo.com/640941172?embedded=true&source=vimeo_logo&owner=11999906
4.
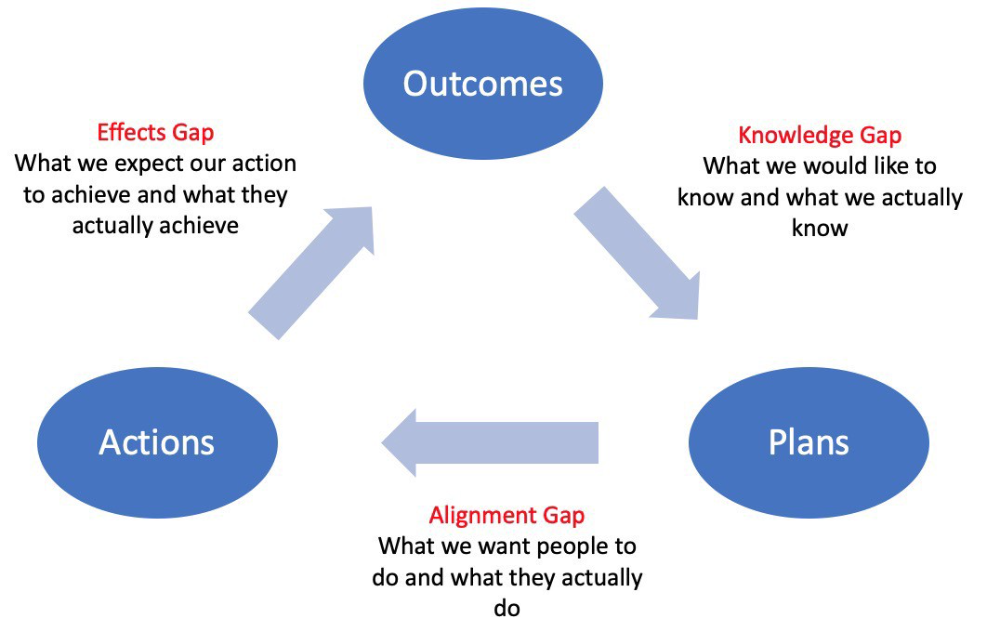
Information Gap - The discrepancy between what we know and what we would like to know
Gap in Alignment - What individuals actually do as opposed to what we wish them to do
Effects Gap - the discrepancy between our expectations and the results of our actions
3.
Theory of Constraints — The Goal - To maximize system production, maximize bottleneck throughput.
Goldratt creates a five-step procedure:
Determine the restriction
Improve the restriction.
Everything else should be based on the limitation.
Increase the restriction
Go back to step 1 Avoid letting inertia become a limitation.
Any non-constraint improvement is an illusion.
2.
Serendipity and the Adjacent Possible - Why do several amazing ideas emerge at once? How can you foster serendipity in your work?
You need specialized abilities to reach to the edge of possibilities, where you can pursue exciting tasks that will change the world. Few people do it since it takes a lot of hard work. You'll stand out if you do.
Most people simply lack the comfort with discomfort required to tackle really hard things. At some point, in other words, there’s no way getting around the necessity to clear your calendar, shut down your phone, and spend several hard days trying to make sense of the damn proof.
1.
Boundaries of failure - Rasmussen's accident model.

Rasmussen modeled this. It has economic, workload, and performance boundaries.
The economic boundary is a company's profit zone. If the lights are on, you're within the economic boundaries, but there's pressure to cut costs and do more.
Performance limit reflects system capacity. Taking shortcuts is a human desire to minimize work. This is often necessary to survive because there's always more labor.
Both push operating points toward acceptable performance. Personal or process safety, or equipment performance.
If you exceed acceptable performance, you'll push back, typically forcefully.

John Rampton
3 years ago
Ideas for Samples of Retirement Letters

Ready to quit full-time? No worries.
Baby Boomer retirement has accelerated since COVID-19 began. In 2020, 29 million boomers retire. Over 3 million more than in 2019. 75 million Baby Boomers will retire by 2030.
First, quit your work to enjoy retirement. Leave a professional legacy. Your retirement will start well. It all starts with a retirement letter.
Retirement Letter
Retirement letters are formal resignation letters. Different from other resignation letters, these don't tell your employer you're leaving. Instead, you're quitting.
Since you're not departing over grievances or for a better position or higher income, you may usually terminate the relationship amicably. Consulting opportunities are possible.
Thank your employer for their support and give them transition information.
Resignation letters aren't merely a formality. This method handles wages, insurance, and retirement benefits.
Retirement letters often accompany verbal notices to managers. Schedule a meeting before submitting your retirement letter to discuss your plans. The letter will be stored alongside your start date, salary, and benefits in your employee file.
Retirement is typically well-planned. Employers want 6-12 months' notice.
Summary
Guidelines for Giving Retirement Notice
Components of a Successful Retirement Letter
Template for Retirement Letter
Ideas for Samples of Retirement Letters
First Example of Retirement Letter
Second Example of Retirement Letter
Third Example of Retirement Letter
Fourth Example of Retirement Letter
Fifth Example of Retirement Letter
Sixth Example of Retirement Letter
Seventh Example of Retirement Letter
Eighth Example of Retirement Letter
Ninth Example of Retirement Letter
Tenth Example of Retirement Letter
Frequently Asked Questions
1. What is a letter of retirement?
2. Why should you include a letter of retirement?
3. What information ought to be in your retirement letter?
4. Must I provide notice?
5. What is the ideal retirement age?
Guidelines for Giving Retirement Notice
While starting a new phase, you're also leaving a job you were qualified for. You have years of experience. So, it may not be easy to fill a retirement-related vacancy.
Talk to your boss in person before sending a letter. Notice is always appreciated. Properly announcing your retirement helps you and your organization transition.
How to announce retirement:
Learn about the retirement perks and policies offered by the company. The first step in figuring out whether you're eligible for retirement benefits is to research your company's retirement policy.
Don't depart without providing adequate notice. You should give the business plenty of time to replace you if you want to retire in a few months.
Help the transition by offering aid. You could be a useful resource if your replacement needs training.
Contact the appropriate parties. The original copy should go to your boss. Give a copy to HR because they will manage your 401(k), pension, and health insurance.
Investigate the option of working as a consultant or part-time. If you desire, you can continue doing some limited work for the business.
Be nice to others. Describe your achievements and appreciation. Additionally, express your gratitude for giving you the chance to work with such excellent coworkers.
Make a plan for your future move. Simply updating your employer on your goals will help you maintain a good working relationship.
Use a formal letter or email to formalize your plans. The initial step is to speak with your supervisor and HR in person, but you must also give written notice.
Components of a Successful Retirement Letter
To write a good retirement letter, keep in mind the following:
A formal salutation. Here, the voice should be deliberate, succinct, and authoritative.
Be specific about your intentions. The key idea of your retirement letter is resignation. Your decision to depart at this time should be reflected in your letter. Remember that your intention must be clear-cut.
Your deadline. This information must be in resignation letters. Laws and corporate policies may both stipulate a minimum amount of notice.
A kind voice. Your retirement letter shouldn't contain any resentments, insults, or other unpleasantness. Your letter should be a model of professionalism and grace. A straightforward thank you is a terrific approach to accomplish that.
Your ultimate goal. Chaos may start to happen as soon as you turn in your resignation letter. Your position will need to be filled. Additionally, you will have to perform your obligations up until a successor is found. Your availability during the interim period should be stated in your resignation letter.
Give us a way to reach you. Even if you aren't consulting, your company will probably get in touch with you at some point. They might send you tax documents and details on perks. By giving your contact information, you can make this process easier.
Template for Retirement Letter
Identify
Title you held
Address
Supervisor's name
Supervisor’s position
Company name
HQ address
Date
[SUPERVISOR],
1.
Inform that you're retiring. Include your last day worked.
2.
Employer thanks. Mention what you're thankful for. Describe your accomplishments and successes.
3.
Helping moves things ahead. Plan your retirement. Mention your consultancy interest.
Sincerely,
[Signature]
First and last name
Phone number
Personal Email
Ideas for Samples of Retirement Letters
First Example of Retirement Letter
Martin D. Carey
123 Fleming St
Bloomfield, New Jersey 07003
(555) 555-1234
June 6th, 2022
Willie E. Coyote
President
Acme Co
321 Anvil Ave
Fairfield, New Jersey 07004
Dear Mr. Coyote,
This letter notifies Acme Co. of my retirement on August 31, 2022.
There has been no other organization that has given me that sense of belonging and purpose.
My fifteen years at the helm of the Structural Design Division have given me a strong sense of purpose. I’ve been fortunate to have your support, and I’ll be always grateful for the opportunity you offered me.
I had a difficult time making this decision. As a result of finding a small property in Arizona where we will be able to spend our remaining days together, my wife and I have decided to officially retire.
In spite of my regret at being unable to contribute to the firm we’ve built, I believe it is wise to move on.
My heart will always belong to Acme Co. Thank you for the opportunity and best of luck in the years to come.
Sincerely,
Martin D. Carey
Second Example of Retirement Letter
Gustavo Fring
Los Pollas Hermanos
12000–12100 Coors Rd SW,
Albuquerque, New Mexico 87045
Dear Mr. Fring,
I write this letter to announce my formal retirement from Los Pollas Hermanos as manager, effective October 15.
As an employee at Los Pollas Hermanos, I appreciate all the great opportunities you have given me. It has been a pleasure to work with and learn from my colleagues for the past 10 years, and I am looking forward to my next challenge.
If there is anything I can do to assist during this time, please let me know.
Sincerely,
Linda T. Crespo
Third Example of Retirement Letter
William M. Arviso
4387 Parkview Drive
Tustin, CA 92680
May 2, 2023
Tony Stark
Owner
Stark Industries
200 Industrial Avenue
Long Beach, CA 90803
Dear Tony:
I’m writing to inform you that my final day of work at Stark Industries will be May14, 2023. When that time comes, I intend to retire.
As I embark on this new chapter in my life, I would like to thank you and the entire Stark Industries team for providing me with so many opportunities. You have all been a pleasure to work with and I will miss you all when I retire.
I am glad to assist you with the transition in any way I can to ensure your new hire has a seamless experience. All ongoing projects will be completed until my retirement date, and all key information will be handed over to the team.
Once again, thank you for the opportunity to be part of the Stark Industries team. All the best to you and the team in the days to come.
Please do not hesitate to contact me if you require any additional information. In order to finalize my retirement plans, I’ll meet with HR and can provide any details that may be necessary.
Sincerely,
(Signature)
William M. Arviso
Fourth Example of Retirement Letter
Garcia, Barbara
First Street, 5432
New York City, NY 10001
(1234) (555) 123–1234
1 October 2022
Gunther
Owner
Central Perk
199 Lafayette St.
New York City, NY 10001
Mr. Gunther,
The day has finally arrived. As I never imagined, I will be formally retiring from Central Perk on November 1st, 2022.
Considering how satisfied I am with my current position, this may surprise you. It would be best if I retired now since my health has deteriorated, so I think this is a good time to do so.
There is no doubt that the past two decades have been wonderful. Over the years, I have seen a small coffee shop grow into one of the city’s top destinations.
It will be hard for me to leave this firm without wondering what more success we could have achieved. But I’m confident that you and the rest of the Central Perk team will achieve great things.
My family and I will never forget what you’ve done for us, and I am grateful for the chance you’ve given me. My house is always open to you.
Sincerely Yours
Garcia, Barbara
Fifth Example of Retirement Letter
Pat Williams
618 Spooky Place
Monstropolis, 23221
123–555–0031
pwilliams@email.com
Feb. 16, 2022
Mike Wazowski
Co-CEO
Monters, Inc.
324 Scare Road
Monstropolis
Dear Mr. Wazowski,
As a formal notice of my upcoming retirement, I am submitting this letter. I will be leaving Monters, Inc. on April 13.
These past 10 years as a marketing associate have provided me with many opportunities. Since we started our company a decade ago, we have seen the face of harnessing screams change dramatically into harnessing laughter. During my time working with this dynamic marketing team, I learned a lot about customer behavior and marketing strategies. Working closely with some of our long-standing clients, such as Boo, was a particular pleasure.
I would be happy to assist with the transition following my retirement. It would be my pleasure to assist in the hiring or training of my replacement. In order to spend more time with my family, I will also be able to offer part-time consulting services.
After I retire, I plan to cash out the eight unused vacation days I’ve accumulated and take my pension as a lump sum.
Thank you for the opportunity to work with Monters, Inc. In the years to come, I wish you all the best!
Sincerely,
Paul Williams
Sixth Example of Retirement Letter
Dear Micheal,
As In my tenure at Dunder Mifflin Paper Company, I have given everything I had. It has been an honor to work here. But I have decided to move on to new challenges and retire from my position — mainly bears, beets, and Battlestar Galactia.
I appreciate the opportunity to work here and learn so much. During my time at this company, I will always remember the good times and memories we shared. Wishing you all the best in the future.
Sincerely,
Dwight K. Shrute
Your signature
May 16
Seventh Example of Retirement Letter
Greetings, Bill
I am announcing my retirement from Initech, effective March 15, 2023.
Over the course of my career here, I’ve had the privilege of working with so many talented and inspiring people.
In 1999, when I began working as a customer service representative, we were a small organization located in a remote office park.
The fact that we now occupy a floor of the Main Street office building with over 150 employees continues to amaze me.
I am looking forward to spending more time with family and traveling the country in our RV. Although I will be sad to leave.
Please let me know if there are any extra steps I can take to facilitate this transfer.
Sincerely,
Frankin, RenitaEighth Example of Retirement Letter
Height Example of Retirement Letter
Bruce,
Please accept my resignation from Wayne Enterprises as Marketing Communications Director. My last day will be August 1, 2022.
The decision to retire has been made after much deliberation. Now that I have worked in the field for forty years, I believe it is a good time to begin completing my bucket list.
It was not easy for me to decide to leave the company. Having worked at Wayne Enterprises has been rewarding both professionally and personally. There are still a lot of memories associated with my first day as a college intern.
My intention was not to remain with such an innovative company, as you know. I was able to see the big picture with your help, however. Today, we are a force that is recognized both nationally and internationally.
In addition to your guidance, the bold, visionary leadership of our company contributed to the growth of our company.
My departure from the company coincides with a particularly hectic time. Despite my best efforts, I am unable to postpone my exit.
My position would be well served by an internal solution. I have a more than qualified marketing manager in Caroline Crown. It would be a pleasure to speak with you about this.
In case I can be of assistance during the switchover, please let me know. Contact us at (555)555–5555. As part of my responsibilities, I am responsible for making sure all work is completed to Wayne Enterprise’s stringent requirements. Having the opportunity to work with you has been a pleasure. I wish you continued success with your thriving business.
Sincerely,
Cash, Cole
Marketing/Communications
Ninth Example of Retirement Letter
Norman, Jamie
2366 Hanover Street
Whitestone, NY 11357
555–555–5555
15 October 2022
Mr. Lippman
Head of Pendant Publishing
600 Madison Ave.
New York, New York
Respected Mr. Lippman,
Please accept my resignation effective November 1, 2022.
Over the course of my ten years at Pendant Publishing, I’ve had a great deal of fun and I’m quite grateful for all the assistance I’ve received.
It was a pleasure to wake up and go to work every day because of our outstanding corporate culture and the opportunities for promotion and professional advancement available to me.
While I am excited about retiring, I am going to miss being part of our team. It’s my hope that I’ll be able to maintain the friendships I’ve formed here for a long time to come.
In case I can be of assistance prior to or following my departure, please let me know. If I can assist in any way to ensure a smooth transfer to my successor, I would be delighted to do so.
Sincerely,
Signed (hard copy letter)
Norman, Jamie
Tenth Example of Retirement Letter
17 January 2023
Greg S. Jackson
Cyberdyne Systems
18144 El Camino Real,
Sunnyvale, CA
Respected Mrs. Duncan,
I am writing to inform you that I will be resigning from Cyberdyne Systems as of March 1, 2023. I’m grateful to have had this opportunity, and it was a difficult decision to make.
My development as a programmer and as a more seasoned member of the organization has been greatly assisted by your coaching.
I have been proud of Cyberdyne Systems’ ethics and success throughout my 25 years at the company. Starting as a mailroom clerk and currently serving as head programmer.
The portfolios of our clients have always been handled with the greatest care by my colleagues. It is our employees and services that have made Cyberdyne Systems the success it is today.
During my tenure as head of my division, I’ve increased our overall productivity by 800 percent, and I expect that trend to continue after I retire.
In light of the fact that the process of replacing me may take some time, I would like to offer my assistance in any way I can.
The greatest contender for this job is Troy Ledford, my current assistant.
Also, before I leave, I would be willing to teach any partners how to use the programmer I developed to track and manage the development of Skynet.
Over the next few months, I’ll be enjoying vacations with my wife as well as my granddaughter moving to college.
If Cyberdyne Systems has any openings for consultants, please let me know. It has been a pleasure working with you over the last 25 years. I appreciate your concern and care.
Sincerely,
Greg S, Jackson
Questions and Answers
1. What is a letter of retirement?
Retirement letters tell your supervisor you're retiring. This informs your employer that you're departing, like a letter. A resignation letter also requests retirement benefits.
Supervisors frequently receive retirement letters and verbal resignations. Before submitting your retirement letter, meet to discuss your plans. This letter will be filed with your start date, salary, and benefits.
2. Why should you include a letter of retirement?
Your retirement letter should explain why you're leaving. When you quit, your manager and HR department usually know. Regardless, a retirement letter might help you leave on a positive tone. It ensures they have the necessary papers.
In your retirement letter, you tell the firm your plans so they can find your replacement. You may need to stay in touch with your company after sending your retirement letter until a successor is identified.
3. What information ought to be in your retirement letter?
Format it like an official letter. Include your retirement plans and retirement-specific statistics. Date may be most essential.
In some circumstances, benefits depend on when you resign and retire. A date on the letter helps HR or senior management verify when you gave notice and how long.
In addition to your usual salutation, address your letter to your manager or supervisor.
The letter's body should include your retirement date and transition arrangements. Tell them whether you plan to help with the transition or train a new employee. You may have a three-month time limit.
Tell your employer your job title, how long you've worked there, and your biggest successes. Personalize your letter by expressing gratitude for your career and outlining your retirement intentions. Finally, include your contact info.
4. Must I provide notice?
Two-week notice isn't required. Your company may require it. Some state laws contain exceptions.
Check your contract, company handbook, or HR to determine your retirement notice. Resigning may change the policy.
Regardless of your company's policy, notification is standard. Entry-level or junior jobs can be let go so the corporation can replace them.
Middle managers, high-level personnel, and specialists may take months to replace. Two weeks' notice is a courtesy. Start planning months ahead.
You can finish all jobs at that period. Prepare transition documents for coworkers and your replacement.
5. What is the ideal retirement age?
Depends on finances, state, and retirement plan. The average American retires at 62. The average retirement age is 66, according to Gallup's 2021 Economy and Personal Finance Survey.
Remember:
Before the age of 59 1/2, withdrawals from pre-tax retirement accounts, such as 401(k)s and IRAs, are subject to a penalty.
Benefits from Social Security can be accessed as early as age 62.
Medicare isn't available to you till you're 65,
Depending on the year of your birth, your Full Retirement Age (FRA) will be between 66 and 67 years old.
If you haven't taken them already, your Social Security benefits increase by 8% annually between ages 6 and 77.
You might also like

Bradley Vangelder
3 years ago
How we started and then quickly sold our startup
From a simple landing where we tested our MVP to a platform that distributes 20,000 codes per month, we learned a lot.

Starting point
Kwotet was my first startup. Everyone might post book quotes online.
I wanted a change.
Kwotet lacked attention, thus I felt stuck. After experiencing the trials of starting Kwotet, I thought of developing a waitlist service, but I required a strong co-founder.
I knew Dries from school, but we weren't close. He was an entrepreneurial programmer who worked a lot outside school. I needed this.
We brainstormed throughout school hours. We developed features to put us first. We worked until 3 am to launch this product.
Putting in the hours is KEY when building a startup

The instant that we lost our spark
In Belgium, college seniors do their internship in their last semester.
As we both made the decision to pick a quite challenging company, little time was left for Lancero.
Eventually, we lost interest. We lost the spark…
The only logical choice was to find someone with the same spark we started with to acquire Lancero.
And we did @ MicroAcquire.
Sell before your product dies. Make sure to profit from all the gains.
What did we do following the sale?
Not far from selling Lancero I lost my dad. I was about to start a new company. It was focused on positivity. I got none left at the time.
We still didn’t let go of the dream of becoming full-time entrepreneurs. As Dries launched the amazing company Plunk, and I’m still in the discovering stages of my next journey!

Dream!
You’re an entrepreneur if:
You're imaginative.
You enjoy disassembling and reassembling things.
You're adept at making new friends.
YOU HAVE DREAMS.
You don’t need to believe me if I tell you “everything is possible”… I wouldn't believe it myself if anyone told me this 2 years ago.
Until I started doing, living my dreams.

Dmitrii Eliuseev
3 years ago
Creating Images on Your Local PC Using Stable Diffusion AI
Deep learning-based generative art is being researched. As usual, self-learning is better. Some models, like OpenAI's DALL-E 2, require registration and can only be used online, but others can be used locally, which is usually more enjoyable for curious users. I'll demonstrate the Stable Diffusion model's operation on a standard PC.

Let’s get started.
What It Does
Stable Diffusion uses numerous components:
A generative model trained to produce images is called a diffusion model. The model is incrementally improving the starting data, which is only random noise. The model has an image, and while it is being trained, the reversed process is being used to add noise to the image. Being able to reverse this procedure and create images from noise is where the true magic is (more details and samples can be found in the paper).
An internal compressed representation of a latent diffusion model, which may be altered to produce the desired images, is used (more details can be found in the paper). The capacity to fine-tune the generation process is essential because producing pictures at random is not very attractive (as we can see, for instance, in Generative Adversarial Networks).
A neural network model called CLIP (Contrastive Language-Image Pre-training) is used to translate natural language prompts into vector representations. This model, which was trained on 400,000,000 image-text pairs, enables the transformation of a text prompt into a latent space for the diffusion model in the scenario of stable diffusion (more details in that paper).
This figure shows all data flow:
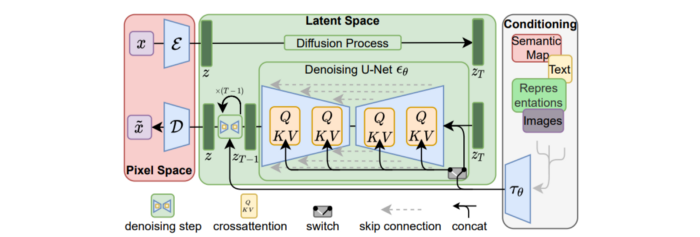
The weights file size for Stable Diffusion model v1 is 4 GB and v2 is 5 GB, making the model quite huge. The v1 model was trained on 256x256 and 512x512 LAION-5B pictures on a 4,000 GPU cluster using over 150.000 NVIDIA A100 GPU hours. The open-source pre-trained model is helpful for us. And we will.
Install
Before utilizing the Python sources for Stable Diffusion v1 on GitHub, we must install Miniconda (assuming Git and Python are already installed):
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
conda update -n base -c defaults condaInstall the source and prepare the environment:
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip3 install transformers --upgradeDownload the pre-trained model weights next. HiggingFace has the newest checkpoint sd-v14.ckpt (a download is free but registration is required). Put the file in the project folder and have fun:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Almost. The installation is complete for happy users of current GPUs with 12 GB or more VRAM. RuntimeError: CUDA out of memory will occur otherwise. Two solutions exist.
Running the optimized version
Try optimizing first. After cloning the repository and enabling the environment (as previously), we can run the command:
python3 optimizedSD/optimized_txt2img.py --prompt "hello world" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Stable Diffusion worked on my visual card with 8 GB RAM (alas, I did not behave well enough to get NVIDIA A100 for Christmas, so 8 GB GPU is the maximum I have;).
Running Stable Diffusion without GPU
If the GPU does not have enough RAM or is not CUDA-compatible, running the code on a CPU will be 20x slower but better than nothing. This unauthorized CPU-only branch from GitHub is easiest to obtain. We may easily edit the source code to use the latest version. It's strange that a pull request for that was made six months ago and still hasn't been approved, as the changes are simple. Readers can finish in 5 minutes:
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available at line 20 of ldm/models/diffusion/ddim.py ().
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available in line 20 of ldm/models/diffusion/plms.py ().
Replace device=cuda in lines 38, 55, 83, and 142 of ldm/modules/encoders/modules.py with device=cuda if torch.cuda.is available(), otherwise cpu.
Replace model.cuda() in scripts/txt2img.py line 28 and scripts/img2img.py line 43 with if torch.cuda.is available(): model.cuda ().
Run the script again.
Testing
Test the model. Text-to-image is the first choice. Test the command line example again:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1The slow generation takes 10 seconds on a GPU and 10 minutes on a CPU. Final image:

Hello world is dull and abstract. Try a brush-wielding hamster. Why? Because we can, and it's not as insane as Napoleon's cat. Another image:

Generating an image from a text prompt and another image is interesting. I made this picture in two minutes using the image editor (sorry, drawing wasn't my strong suit):
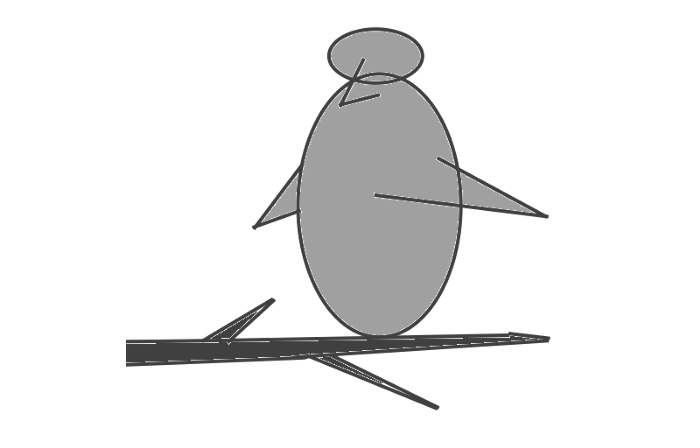
I can create an image from this drawing:
python3 scripts/img2img.py --prompt "A bird is sitting on a tree branch" --ckpt sd-v1-4.ckpt --init-img bird.png --strength 0.8It was far better than my initial drawing:

I hope readers understand and experiment.
Stable Diffusion UI
Developers love the command line, but regular users may struggle. Stable Diffusion UI projects simplify image generation and installation. Simple usage:
Unpack the ZIP after downloading it from https://github.com/cmdr2/stable-diffusion-ui/releases. Linux and Windows are compatible with Stable Diffusion UI (sorry for Mac users, but those machines are not well-suitable for heavy machine learning tasks anyway;).
Start the script.
Done. The web browser UI makes configuring various Stable Diffusion features (upscaling, filtering, etc.) easy:
V2.1 of Stable Diffusion
I noticed the notification about releasing version 2.1 while writing this essay, and it was intriguing to test it. First, compare version 2 to version 1:
alternative text encoding. The Contrastive LanguageImage Pre-training (CLIP) deep learning model, which was trained on a significant number of text-image pairs, is used in Stable Diffusion 1. The open-source CLIP implementation used in Stable Diffusion 2 is called OpenCLIP. It is difficult to determine whether there have been any technical advancements or if legal concerns were the main focus. However, because the training datasets for the two text encoders were different, the output results from V1 and V2 will differ for the identical text prompts.
a new depth model that may be used to the output of image-to-image generation.
a revolutionary upscaling technique that can quadruple the resolution of an image.
Generally higher resolution Stable Diffusion 2 has the ability to produce both 512x512 and 768x768 pictures.
The Hugging Face website offers a free online demo of Stable Diffusion 2.1 for code testing. The process is the same as for version 1.4. Download a fresh version and activate the environment:
conda deactivate
conda env remove -n ldm # Use this if version 1 was previously installed
git clone https://github.com/Stability-AI/stablediffusion
cd stablediffusion
conda env create -f environment.yaml
conda activate ldmHugging Face offers a new weights ckpt file.
The Out of memory error prevented me from running this version on my 8 GB GPU. Version 2.1 fails on CPUs with the slow conv2d cpu not implemented for Half error (according to this GitHub issue, the CPU support for this algorithm and data type will not be added). The model can be modified from half to full precision (float16 instead of float32), however it doesn't make sense since v1 runs up to 10 minutes on the CPU and v2.1 should be much slower. The online demo results are visible. The same hamster painting with a brush prompt yielded this result:

It looks different from v1, but it functions and has a higher resolution.
The superresolution.py script can run the 4x Stable Diffusion upscaler locally (the x4-upscaler-ema.ckpt weights file should be in the same folder):
python3 scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml x4-upscaler-ema.ckptThis code allows the web browser UI to select the image to upscale:
The copy-paste strategy may explain why the upscaler needs a text prompt (and the Hugging Face code snippet does not have any text input as well). I got a GPU out of memory error again, although CUDA can be disabled like v1. However, processing an image for more than two hours is unlikely:
Stable Diffusion Limitations
When we use the model, it's fun to see what it can and can't do. Generative models produce abstract visuals but not photorealistic ones. This fundamentally limits The generative neural network was trained on text and image pairs, but humans have a lot of background knowledge about the world. The neural network model knows nothing. If someone asks me to draw a Chinese text, I can draw something that looks like Chinese but is actually gibberish because I never learnt it. Generative AI does too! Humans can learn new languages, but the Stable Diffusion AI model includes only language and image decoder brain components. For instance, the Stable Diffusion model will pull NO WAR banner-bearers like this:
V1:

V2.1:

The shot shows text, although the model never learned to read or write. The model's string tokenizer automatically converts letters to lowercase before generating the image, so typing NO WAR banner or no war banner is the same.
I can also ask the model to draw a gorgeous woman:
V1:

V2.1:

The first image is gorgeous but physically incorrect. A second one is better, although it has an Uncanny valley feel. BTW, v2 has a lifehack to add a negative prompt and define what we don't want on the image. Readers might try adding horrible anatomy to the gorgeous woman request.
If we ask for a cartoon attractive woman, the results are nice, but accuracy doesn't matter:
V1:

V2.1:

Another example: I ordered a model to sketch a mouse, which looks beautiful but has too many legs, ears, and fingers:
V1:

V2.1: improved but not perfect.

V1 produces a fun cartoon flying mouse if I want something more abstract:

I tried multiple times with V2.1 but only received this:

The image is OK, but the first version is closer to the request.
Stable Diffusion struggles to draw letters, fingers, etc. However, abstract images yield interesting outcomes. A rural landscape with a modern metropolis in the background turned out well:
V1:

V2.1:

Generative models help make paintings too (at least, abstract ones). I searched Google Image Search for modern art painting to see works by real artists, and this was the first image:

I typed "abstract oil painting of people dancing" and got this:
V1:

V2.1:

It's a different style, but I don't think the AI-generated graphics are worse than the human-drawn ones.
The AI model cannot think like humans. It thinks nothing. A stable diffusion model is a billion-parameter matrix trained on millions of text-image pairs. I input "robot is creating a picture with a pen" to create an image for this post. Humans understand requests immediately. I tried Stable Diffusion multiple times and got this:

This great artwork has a pen, robot, and sketch, however it was not asked. Maybe it was because the tokenizer deleted is and a words from a statement, but I tried other requests such robot painting picture with pen without success. It's harder to prompt a model than a person.
I hope Stable Diffusion's general effects are evident. Despite its limitations, it can produce beautiful photographs in some settings. Readers who want to use Stable Diffusion results should be warned. Source code examination demonstrates that Stable Diffusion images feature a concealed watermark (text StableDiffusionV1 and SDV2) encoded using the invisible-watermark Python package. It's not a secret, because the official Stable Diffusion repository's test watermark.py file contains a decoding snippet. The put watermark line in the txt2img.py source code can be removed if desired. I didn't discover this watermark on photographs made by the online Hugging Face demo. Maybe I did something incorrectly (but maybe they are just not using the txt2img script on their backend at all).
Conclusion
The Stable Diffusion model was fascinating. As I mentioned before, trying something yourself is always better than taking someone else's word, so I encourage readers to do the same (including this article as well;).
Is Generative AI a game-changer? My humble experience tells me:
I think that place has a lot of potential. For designers and artists, generative AI can be a truly useful and innovative tool. Unfortunately, it can also pose a threat to some of them since if users can enter a text field to obtain a picture or a website logo in a matter of clicks, why would they pay more to a different party? Is it possible right now? unquestionably not yet. Images still have a very poor quality and are erroneous in minute details. And after viewing the image of the stunning woman above, models and fashion photographers may also unwind because it is highly unlikely that AI will replace them in the upcoming years.
Today, generative AI is still in its infancy. Even 768x768 images are considered to be of a high resolution when using neural networks, which are computationally highly expensive. There isn't an AI model that can generate high-resolution photographs natively without upscaling or other methods, at least not as of the time this article was written, but it will happen eventually.
It is still a challenge to accurately represent knowledge in neural networks (information like how many legs a cat has or the year Napoleon was born). Consequently, AI models struggle to create photorealistic photos, at least where little details are important (on the other side, when I searched Google for modern art paintings, the results are often even worse;).
When compared to the carefully chosen images from official web pages or YouTube reviews, the average output quality of a Stable Diffusion generation process is actually less attractive because to its high degree of randomness. When using the same technique on their own, consumers will theoretically only view those images as 1% of the results.
Anyway, it's exciting to witness this area's advancement, especially because the project is open source. Google's Imagen and DALL-E 2 can also produce remarkable findings. It will be interesting to see how they progress.

Sean Bloomfield
3 years ago
How Jeff Bezos wins meetings over

We've all been there: You propose a suggestion to your team at a meeting, and most people appear on board, but a handful or small minority aren't. How can we achieve collective buy-in when we need to go forward but don't know how to deal with some team members' perceived intransigence?
Steps:
Investigate the divergent opinions: Begin by sincerely attempting to comprehend the viewpoint of your disagreeing coworkers. Maybe it makes sense to switch horses in the middle of the race. Have you completely overlooked a blind spot, such as a political concern that could arise as an unexpected result of proceeding? This is crucial to ensure that the person or people feel heard as well as to advance the goals of the team. Sometimes all individuals need is a little affirmation before they fully accept your point of view.
It says a lot about you as a leader to be someone who always lets the perceived greatest idea win, regardless of the originating channel, if after studying and evaluating you see the necessity to align with the divergent position.
If, after investigation and assessment, you determine that you must adhere to the original strategy, we go to Step 2.
2. Disagree and Commit: Jeff Bezos, CEO of Amazon, has had this experience, and Julie Zhuo describes how he handles it in her book The Making of a Manager.
It's OK to disagree when the team is moving in the right direction, but it's not OK to accidentally or purposefully damage the team's efforts because you disagree. Let the team know your opinion, but then help them achieve company goals even if they disagree. Unknown. You could be wrong in today's ever-changing environment.
So next time you have a team member who seems to be dissenting and you've tried the previous tactics, you may ask the individual in the meeting I understand you but I don't want us to leave without you on board I need your permission to commit to this approach would you give us your commitment?