


10 Predictions for Web3 and the Cryptoeconomy for 2022
By Surojit Chatterjee, Chief Product Officer
2021 proved to be a breakout year for crypto with BTC price gaining almost 70% yoy, Defi hitting $150B in value locked, and NFTs emerging as a new category. Here’s my view through the crystal ball into 2022 and what it holds for our industry:
1. Eth scalability will improve, but newer L1 chains will see substantial growth — As we welcome the next hundred million users to crypto and Web3, scalability challenges for Eth are likely to grow. I am optimistic about improvements in Eth scalability with the emergence of Eth2 and many L2 rollups. Traction of Solana, Avalanche and other L1 chains shows that we’ll live in a multi-chain world in the future. We’re also going to see newer L1 chains emerge that focus on specific use cases such as gaming or social media.
2. There will be significant usability improvements in L1-L2 bridges — As more L1 networks gain traction and L2s become bigger, our industry will desperately seek improvements in speed and usability of cross-L1 and L1-L2 bridges. We’re likely to see interesting developments in usability of bridges in the coming year.
3. Zero knowledge proof technology will get increased traction — 2021 saw protocols like ZkSync and Starknet beginning to get traction. As L1 chains get clogged with increased usage, ZK-rollup technology will attract both investor and user attention. We’ll see new privacy-centric use cases emerge, including privacy-safe applications, and gaming models that have privacy built into the core. This may also bring in more regulator attention to crypto as KYC/AML could be a real challenge in privacy centric networks.
4. Regulated Defi and emergence of on-chain KYC attestation — Many Defi protocols will embrace regulation and will create separate KYC user pools. Decentralized identity and on-chain KYC attestation services will play key roles in connecting users’ real identity with Defi wallet endpoints. We’ll see more acceptance of ENS type addresses, and new systems from cross chain name resolution will emerge.
5. Institutions will play a much bigger role in Defi participation — Institutions are increasingly interested in participating in Defi. For starters, institutions are attracted to higher than average interest-based returns compared to traditional financial products. Also, cost reduction in providing financial services using Defi opens up interesting opportunities for institutions. However, they are still hesitant to participate in Defi. Institutions want to confirm that they are only transacting with known counterparties that have completed a KYC process. Growth of regulated Defi and on-chain KYC attestation will help institutions gain confidence in Defi.
6. Defi insurance will emerge — As Defi proliferates, it also becomes the target of security hacks. According to London-based firm Elliptic, total value lost by Defi exploits in 2021 totaled over $10B. To protect users from hacks, viable insurance protocols guaranteeing users’ funds against security breaches will emerge in 2022.
7. NFT Based Communities will give material competition to Web 2.0 social networks — NFTs will continue to expand in how they are perceived. We’ll see creator tokens or fan tokens take more of a first class seat. NFTs will become the next evolution of users’ digital identity and passport to the metaverse. Users will come together in small and diverse communities based on types of NFTs they own. User created metaverses will be the future of social networks and will start threatening the advertising driven centralized versions of social networks of today.
8. Brands will start actively participating in the metaverse and NFTs — Many brands are realizing that NFTs are great vehicles for brand marketing and establishing brand loyalty. Coca-Cola, Campbell’s, Dolce & Gabbana and Charmin released NFT collectibles in 2021. Adidas recently launched a new metaverse project with Bored Ape Yacht Club. We’re likely to see more interesting brand marketing initiatives using NFTs. NFTs and the metaverse will become the new Instagram for brands. And just like on Instagram, many brands may start as NFT native. We’ll also see many more celebrities jumping in the bandwagon and using NFTs to enhance their personal brand.
9. Web2 companies will wake up and will try to get into Web3 — We’re already seeing this with Facebook trying to recast itself as a Web3 company. We’re likely to see other big Web2 companies dipping their toes into Web3 and metaverse in 2022. However, many of them are likely to create centralized and closed network versions of the metaverse.
10. Time for DAO 2.0 — We’ll see DAOs become more mature and mainstream. More people will join DAOs, prompting a change in definition of employment — never receiving a formal offer letter, accepting tokens instead of or along with fixed salaries, and working in multiple DAO projects at the same time. DAOs will also confront new challenges in terms of figuring out how to do M&A, run payroll and benefits, and coordinate activities in larger and larger organizations. We’ll see a plethora of tools emerge to help DAOs execute with efficiency. Many DAOs will also figure out how to interact with traditional Web2 companies. We’re likely to see regulators taking more interest in DAOs and make an attempt to educate themselves on how DAOs work.
Thanks to our customers and the ecosystem for an incredible 2021. Looking forward to another year of building the foundations for Web3. Wagmi.
More on Web3 & Crypto

rekt
4 years ago
LCX is the latest CEX to have suffered a private key exploit.
The attack began around 10:30 PM +UTC on January 8th.
Peckshield spotted it first, then an official announcement came shortly after.
We’ve said it before; if established companies holding millions of dollars of users’ funds can’t manage their own hot wallet security, what purpose do they serve?
The Unique Selling Proposition (USP) of centralised finance grows smaller by the day.
The official incident report states that 7.94M USD were stolen in total, and that deposits and withdrawals to the platform have been paused.
LCX hot wallet: 0x4631018f63d5e31680fb53c11c9e1b11f1503e6f
Hacker’s wallet: 0x165402279f2c081c54b00f0e08812f3fd4560a05
Stolen funds:
- 162.68 ETH (502,671 USD)
- 3,437,783.23 USDC (3,437,783 USD)
- 761,236.94 EURe (864,840 USD)
- 101,249.71 SAND Token (485,995 USD)
- 1,847.65 LINK (48,557 USD)
- 17,251,192.30 LCX Token (2,466,558 USD)
- 669.00 QNT (115,609 USD)
- 4,819.74 ENJ (10,890 USD)
- 4.76 MKR (9,885 USD)
**~$1M worth of $LCX remains in the address, along with 611k EURe which has been frozen by Monerium.
The rest, a total of 1891 ETH (~$6M) was sent to Tornado Cash.**
Why can’t they keep private keys private?
Is it really that difficult for a traditional corporate structure to maintain good practice?
CeFi hacks leave us with little to say - we can only go on what the team chooses to tell us.
Next time, they can write this article themselves.
See below for a template.

Trent Lapinski
4 years ago
What The Hell Is A Crypto Punk?
We are Crypto Punks, and we are changing your world.
A “Crypto Punk” is a new generation of entrepreneurs who value individual liberty and collective value creation and co-creation through decentralization. While many Crypto Punks were born and raised in a digital world, some of the early pioneers in the crypto space are from the Oregon Trail generation. They were born to an analog world, but grew up simultaneously alongside the birth of home computing, the Internet, and mobile computing.
A Crypto Punk’s world view is not the same as previous generations. By the time most Crypto Punks were born everything from fiat currency, the stock market, pharmaceuticals, the Internet, to advanced operating systems and microprocessing were already present or emerging. Crypto Punks were born into pre-existing conditions and systems of control, not governed by logic or reason but by greed, corporatism, subversion, bureaucracy, censorship, and inefficiency.
All Systems Are Human Made
Crypto Punks understand that all systems were created by people and that previous generations did not have access to information technologies that we have today. This is why Crypto Punks have different values than their parents, and value liberty, decentralization, equality, social justice, and freedom over wealth, money, and power. They understand that the only path forward is to work together to build new and better systems that make the old world order obsolete.
Unlike the original cypher punks and cyber punks, Crypto Punks are a new iteration or evolution of these previous cultures influenced by cryptography, blockchain technology, crypto economics, libertarianism, holographics, democratic socialism, and artificial intelligence. They are tasked with not only undoing the mistakes of previous generations, but also innovating and creating new ways of solving complex problems with advanced technology and solutions.
Where Crypto Punks truly differ is in their understanding that computer systems can exist for more than just engagement and entertainment, but actually improve the human condition by automating bureaucracy and inefficiency by creating more efficient economic incentives and systems.
Crypto Punks Value Transparency and Do Not Trust Flawed, Unequal, and Corrupt Systems
Crypto Punks have a strong distrust for inherently flawed and corrupt systems. This why Crypto Punks value transparency, free speech, privacy, and decentralization. As well as arguably computer systems over human powered systems.
Crypto Punks are the children of the Great Recession, and will never forget the economic corruption that still enslaves younger generations.
Crypto Punks were born to think different, and raised by computers to view reality through an LED looking glass. They will not surrender to the flawed systems of economic wage slavery, inequality, censorship, and subjection. They will literally engineer their own unstoppable financial systems and trade in cryptography over fiat currency merely to prove that belief systems are more powerful than corruption.
Crypto Punks are here to help achieve freedom from world governments, corporations and bankers who monetizine our data to control our lives.
Crypto Punks Decentralize
Despite all the evils of the world today, Crypto Punks know they have the power to create change. This is why Crypto Punks are optimistic about the future despite all the indicators that humanity is destined for failure.
Crypto Punks believe in systems that prioritize people and the planet above profit. Even so, Crypto Punks still believe in capitalistic systems, but only capitalistic systems that incentivize good behaviors that do not violate the common good for the sake of profit.
Cyber Punks Are Co-Creators
We are Crypto Punks, and we will build a better world for all of us. For the true price of creation is not in US dollars, but through working together as equals to replace the unequal and corrupt greedy systems of previous generations.
Where they have failed, Crypto Punks will succeed. Not because we want to, but because we have to. The world we were born into is so corrupt and its systems so flawed and unequal we were never given a choice.
We have to be the change we seek.
We are Crypto Punks.
Either help us, or get out of our way.
Are you a Crypto Punk?

CNET
4 years ago
How a $300K Bored Ape Yacht Club NFT was accidentally sold for $3K
The Bored Ape Yacht Club is one of the most prestigious NFT collections in the world. A collection of 10,000 NFTs, each depicting an ape with different traits and visual attributes, Jimmy Fallon, Steph Curry and Post Malone are among their star-studded owners. Right now the price of entry is 52 ether, or $210,000.
Which is why it's so painful to see that someone accidentally sold their Bored Ape NFT for $3,066.
Unusual trades are often a sign of funny business, as in the case of the person who spent $530 million to buy an NFT from themselves. In Saturday's case, the cause was a simple, devastating "fat-finger error." That's when people make a trade online for the wrong thing, or for the wrong amount. Here the owner, real name Max or username maxnaut, meant to list his Bored Ape for 75 ether, or around $300,000. Instead he accidentally listed it for 0.75. One hundredth the intended price.
It was bought instantaneously. The buyer paid an extra $34,000 to speed up the transaction, ensuring no one could snap it up before them. The Bored Ape was then promptly listed for $248,000. The transaction appears to have been done by a bot, which can be coded to immediately buy NFTs listed below a certain price on behalf of their owners in order to take advantage of these exact situations.
"How'd it happen? A lapse of concentration I guess," Max told me. "I list a lot of items every day and just wasn't paying attention properly. I instantly saw the error as my finger clicked the mouse but a bot sent a transaction with over 8 eth [$34,000] of gas fees so it was instantly sniped before I could click cancel, and just like that, $250k was gone."
"And here within the beauty of the Blockchain you can see that it is both honest and unforgiving," he added.
Fat finger trades happen sporadically in traditional finance -- like the Japanese trader who almost bought 57% of Toyota's stock in 2014 -- but most financial institutions will stop those transactions if alerted quickly enough. Since cryptocurrency and NFTs are designed to be decentralized, you essentially have to rely on the goodwill of the buyer to reverse the transaction.
Fat finger errors in cryptocurrency trades have made many a headline over the past few years. Back in 2019, the company behind Tether, a cryptocurrency pegged to the US dollar, nearly doubled its own coin supply when it accidentally created $5 billion-worth of new coins. In March, BlockFi meant to send 700 Gemini Dollars to a set of customers, worth roughly $1 each, but mistakenly sent out millions of dollars worth of bitcoin instead. Last month a company erroneously paid a $24 million fee on a $100,000 transaction.
Similar incidents are increasingly being seen in NFTs, now that many collections have accumulated in market value over the past year. Last month someone tried selling a CryptoPunk NFT for $19 million, but accidentally listed it for $19,000 instead. Back in August, someone fat finger listed their Bored Ape for $26,000, an error that someone else immediately capitalized on. The original owner offered $50,000 to the buyer to return the Bored Ape -- but instead the opportunistic buyer sold it for the then-market price of $150,000.
"The industry is so new, bad things are going to happen whether it's your fault or the tech," Max said. "Once you no longer have control of the outcome, forget and move on."
The Bored Ape Yacht Club launched back in April 2021, with 10,000 NFTs being sold for 0.08 ether each -- about $190 at the time. While NFTs are often associated with individual digital art pieces, collections like the Bored Ape Yacht Club, which allow owners to flaunt their NFTs by using them as profile pictures on social media, are becoming increasingly prevalent. The Bored Ape Yacht Club has since become the second biggest NFT collection in the world, second only to CryptoPunks, which launched in 2017 and is considered the "original" NFT collection.
You might also like

Jack Burns
3 years ago
Here's what to expect from NASA Artemis 1 and why it's significant.
NASA's Artemis 1 mission will help return people to the Moon after a half-century break. The mission is a shakedown cruise for NASA's Space Launch System and Orion Crew Capsule.
The spaceship will visit the Moon, deploy satellites, and enter orbit. NASA wants to practice operating the spacecraft, test the conditions people will face on the Moon, and ensure a safe return to Earth.
We asked Jack Burns, a space scientist at the University of Colorado Boulder and former member of NASA's Presidential Transition Team, to describe the mission, explain what the Artemis program promises for space exploration, and reflect on how the space program has changed in the half-century since humans last set foot on the moon.
What distinguishes Artemis 1 from other rockets?
Artemis 1 is the Space Launch System's first launch. NASA calls this a "heavy-lift" vehicle. It will be more powerful than Apollo's Saturn V, which transported people to the Moon in the 1960s and 1970s.
It's a new sort of rocket system with two strap-on solid rocket boosters from the space shuttle. It's a mix of the shuttle and Saturn V.
The Orion Crew Capsule will be tested extensively. It'll spend a month in the high-radiation Moon environment. It will also test the heat shield, which protects the capsule and its occupants at 25,000 mph. The heat shield must work well because this is the fastest capsule descent since Apollo.
This mission will also carry miniature Moon-orbiting satellites. These will undertake vital precursor science, including as examining further into permanently shadowed craters where scientists suspect there is water and measuring the radiation environment to see long-term human consequences.
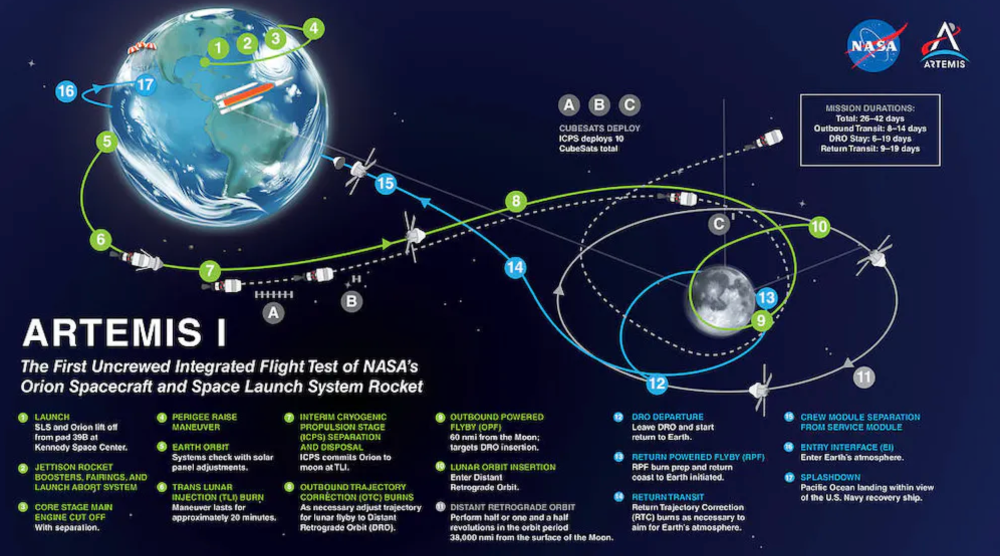
Artemis 1 will launch, fly to the Moon, place satellites, orbit it, return to Earth, and splash down in the ocean. NASA.
What's Artemis's goal? What launches are next?
The mission is a first step toward Artemis 3, which will lead to the first human Moon missions since 1972. Artemis 1 is unmanned.
Artemis 2 will have astronauts a few years later. Like Apollo 8, it will be an orbital mission that circles the Moon and returns. The astronauts will orbit the Moon longer and test everything with a crew.
Eventually, Artemis 3 will meet with the SpaceX Starship on the Moon's surface and transfer people. Orion will stay in orbit while the lunar Starship lands astronauts. They'll go to the Moon's south pole to investigate the water ice there.
Artemis is reminiscent of Apollo. What's changed in 50 years?
Kennedy wanted to beat the Soviets to the Moon with Apollo. The administration didn't care much about space flight or the Moon, but the goal would place America first in space and technology.
You live and die by the sword if you do that. When the U.S. reached the Moon, it was over. Russia lost. We planted flags and did science experiments. Richard Nixon canceled the program after Apollo 11 because the political goals were attained.
Large rocket with two boosters between two gates

NASA's new Space Launch System is brought to a launchpad. NASA
50 years later... It's quite different. We're not trying to beat the Russians, Chinese, or anyone else, but to begin sustainable space exploration.
Artemis has many goals. It includes harnessing in-situ resources like water ice and lunar soil to make food, fuel, and building materials.
SpaceX is part of this first journey to the Moon's surface, therefore the initiative is also helping to develop a lunar and space economy. NASA doesn't own the Starship but is buying seats for astronauts. SpaceX will employ Starship to transport cargo, private astronauts, and foreign astronauts.
Fifty years of technology advancement has made getting to the Moon cheaper and more practical, and computer technology allows for more advanced tests. 50 years of technological progress have changed everything. Anyone with enough money can send a spacecraft to the Moon, but not humans.
Commercial Lunar Payload Services engages commercial companies to develop uncrewed Moon landers. We're sending a radio telescope to the Moon in January. Even 10 years ago, that was impossible.
Since humans last visited the Moon 50 years ago, technology has improved greatly.
What other changes does Artemis have in store?
The government says Artemis 3 will have at least one woman and likely a person of color.
I'm looking forward to seeing more diversity so young kids can say, "Hey, there's an astronaut that looks like me. I can do this. I can be part of the space program.”

Alex Mathers
3 years ago
8 guidelines to help you achieve your objectives 5x fast

If you waste time every day, even though you're ambitious, you're not alone.
Many of us could use some new time-management strategies, like these:
Focus on the following three.
You're thinking about everything at once.
You're overpowered.
It's mental. We just have what's in front of us. So savor the moment's beauty.
Prioritize 1-3 things.
To be one of the most productive people you and I know, follow these steps.
Get along with boredom.
Many of us grow bored, sweat, and turn on Netflix.
We shout, "I'm rarely bored!" Look at me! I'm happy.
Shut it, Sally.
You're not making wonderful things for the world. Boredom matters.
If you can sit with it for a second, you'll get insight. Boredom? Breathe.
Go blank.
Then watch your creativity grow.
Check your MacroVision once more.
We don't know what to do with our time, which contributes to time-wasting.
Nobody does, either. Jeff Bezos won't hand-deliver that crap to you.
Daily vision checks are required.
Also:
What are 5 things you'd love to create in the next 5 years?
You're soul-searching. It's food.
Return here regularly, and you'll adore the high you get from doing valuable work.
Improve your thinking.
What's Alex's latest nonsense?
I'm talking about overcoming our own thoughts. Worrying wastes so much time.
Too many of us are assaulted by lies, myths, and insecurity.
Stop letting your worries massage you into a worried coma like a Thai woman.
Optimizing your thoughts requires accepting what you can't control.
It means letting go of unhelpful thoughts and returning to the moment.
Keep your blood sugar level.
I gave up gluten, donuts, and sweets.
This has really boosted my energy.
Blood-sugar-spiking carbs make us irritable and tired.
These day-to-day ups and downs aren't productive. It's crucial.
Know how your diet affects insulin levels. Now I have more energy and can do more without clenching my teeth.
Reduce harmful carbs to boost energy.
Create a focused setting for yourself.
When we optimize the mind, we have more energy and use our time better because we're not tense.
Changing our environment can also help us focus. Disabling alerts is one example.
Too hot makes me procrastinate and irritable.
List five items that hinder your productivity.
You may be amazed at how much you may improve by removing distractions.
Be responsible.
Accountability is a time-saver.
Creating an emotional pull to finish things.
Writing down our goals makes us accountable.
We can engage a coach or work with an accountability partner to feel horrible if we don't show up and finish on time.
‘Hey Jake, I’m going to write 1000 words every day for 30 days — you need to make sure I do.’ ‘Sure thing, Nathan, I’ll be making sure you check in daily with me.’
Tick.
You might also blog about your ambitions to show your dedication.
Now you can't hide when you promised to appear.
Acquire a liking for bravery.
Boldness changes everything.
I sometimes feel lazy and wonder why. If my food and sleep are in order, I should assess my footing.
Most of us live backward. Doubtful. Uncertain. Feelings govern us.
Backfooting isn't living. It's lame, and you'll soon melt. Live boldly now.
Be assertive.
Get disgustingly into everything. Expand.
Even if it's hard, stop being a b*tch.
Those that make Mr. Bold Bear their spirit animal benefit. Save time to maximize your effect.

Jerry Keszka
3 years ago
10 Crazy Useful Free Websites No One Told You About But You Needed
The internet is a massive information resource. With so much stuff, it's easy to forget about useful websites. Here are five essential websites you may not have known about.

1. Companies.tools
Companies.tools are what successful startups employ. This website offers a curated selection of design, research, coding, support, and feedback resources. Ct has the latest app development platform and greatest client feedback method.
2. Excel Formula Bot
Excel Formula Bot can help if you forget a formula. Formula Bot uses AI to convert text instructions into Excel formulas, so you don't have to remember them.
Just tell the Bot what to do, and it will do it. Excel Formula Bot can calculate sales tax and vacation days. When you're stuck, let the Bot help.
3.TypeLit
TypeLit helps you improve your typing abilities while reading great literature.
TypeLit.io lets you type any book or dozens of preset classics. TypeLit provides real-time feedback on accuracy and speed.
Goals and progress can be tracked. Why not improve your typing and learn great literature with TypeLit?
4. Calm Schedule
Finding a meeting time that works for everyone is difficult. Personal and business calendars might be difficult to coordinate.
Synchronize your two calendars to save time and avoid problems. You may avoid searching through many calendars for conflicts and keep your personal information secret. Having one source of truth for personal and work occasions will help you never miss another appointment.
https://calmcalendar.com/
5. myNoise
myNoise makes the outside world quieter. myNoise is the right noise for a noisy office or busy street.
If you can't locate the right noise, make it. MyNoise unlocks the world. Shut out distractions. Thank your ears.
6. Synthesia
Professional videos require directors, filmmakers, editors, and animators. Now, thanks to AI, you can generate high-quality videos without video editing experience.
AI avatars are crucial. You can design a personalized avatar using a web-based software like synthesia.io. Our avatars can lip-sync in over 60 languages, so you can make worldwide videos. There's an AI avatar for every video goal.
Not free. Amazing service, though.
7. Cleaning-up-images
Have you shot a wonderful photo just to notice something in the background? You may have a beautiful headshot but wish to erase an imperfection.
Cleanup.pictures removes undesirable objects from photos. Our algorithms will eliminate the selected object.
Cleanup.pictures can help you obtain the ideal shot every time. Next time you take images, let Cleanup.pictures fix any flaws.
8. PDF24 Tools
Editing a PDF can be a pain. Most of us don't know Adobe Acrobat's functionalities. Why buy something you'll rarely use? Better options exist.
PDF24 is an online PDF editor that's free and subscription-free. Rotate, merge, split, compress, and convert PDFs in your browser. PDF24 makes document signing easy.
Upload your document, sign it (or generate a digital signature), and download it. It's easy and free. PDF24 is a free alternative to pricey PDF editing software.
9. Class Central
Finding online classes is much easier. Class Central has classes from Harvard, Stanford, Coursera, Udemy, and Google, Amazon, etc. in one spot.
Whether you want to acquire a new skill or increase your knowledge, you'll find something. New courses bring variety.
10. Rome2rio
Foreign travel offers countless transport alternatives. How do you get from A to B? It’s easy!
Rome2rio will show you the best method to get there, including which mode of transport is ideal.
Plane
Car
Train
Bus
Ferry
Driving
Shared bikes
Walking
Do you know any free, useful websites?