




More on Science

Michael Hunter, MD
3 years ago
5 Drugs That May Increase Your Risk of Dementia

While our genes can't be changed easily, you can avoid some dementia risk factors. Today we discuss dementia and five drugs that may increase risk.
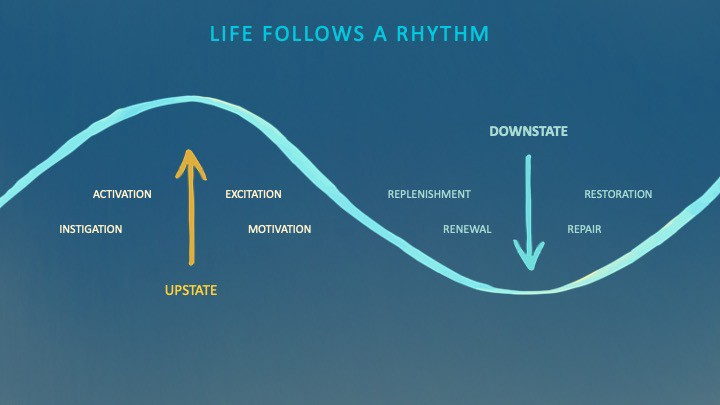
Memory loss appears to come with age, but we're not talking about forgetfulness. Sometimes losing your car keys isn't an indication of dementia. Dementia impairs the capacity to think, remember, or make judgments. Dementia hinders daily tasks.
Alzheimers is the most common dementia. Dementia is not normal aging, unlike forgetfulness. Aging increases the risk of Alzheimer's and other dementias. A family history of the illness increases your risk, according to the Mayo Clinic (USA).
Given that our genes are difficult to change (I won't get into epigenetics), what are some avoidable dementia risk factors? Certain drugs may cause cognitive deterioration.
Today we look at four drugs that may cause cognitive decline.
Dementia and benzodiazepines
Benzodiazepine sedatives increase brain GABA levels. Example benzodiazepines:
Diazepam (Valium) (Valium)
Alprazolam (Xanax) (Xanax)
Clonazepam (Klonopin) (Klonopin)
Addiction and overdose are benzodiazepine risks. Yes! These medications don't raise dementia risk.
USC study: Benzodiazepines don't increase dementia risk in older adults.
Benzodiazepines can produce short- and long-term amnesia. This memory loss hinders memory formation. Extreme cases can permanently impair learning and memory. Anterograde amnesia is uncommon.
2. Statins and dementia
Statins reduce cholesterol. They prevent a cholesterol-making chemical. Examples:
Atorvastatin (Lipitor) (Lipitor)
Fluvastatin (Lescol XL) (Lescol XL)
Lovastatin (Altoprev) (Altoprev)
Pitavastatin (Livalo, Zypitamag) (Livalo, Zypitamag)
Pravastatin (Pravachol) (Pravachol)
Rosuvastatin (Crestor, Ezallor) (Crestor, Ezallor)
Simvastatin (Zocor) (Zocor)
This finding is contentious. Harvard's Brigham and Womens Hospital's Dr. Joann Manson says:
“I think that the relationship between statins and cognitive function remains controversial. There’s still not a clear conclusion whether they help to prevent dementia or Alzheimer’s disease, have neutral effects, or increase risk.”
This one's off the dementia list.
3. Dementia and anticholinergic drugs
Anticholinergic drugs treat many conditions, including urine incontinence. Drugs inhibit acetylcholine (a brain chemical that helps send messages between cells). Acetylcholine blockers cause drowsiness, disorientation, and memory loss.
First-generation antihistamines, tricyclic antidepressants, and overactive bladder antimuscarinics are common anticholinergics among the elderly.
Anticholinergic drugs may cause dementia. One study found that taking anticholinergics for three years or more increased the risk of dementia by 1.54 times compared to three months or less. After stopping the medicine, the danger may continue.
4. Drugs for Parkinson's disease and dementia
Cleveland Clinic (USA) on Parkinson's:
Parkinson's disease causes age-related brain degeneration. It causes delayed movements, tremors, and balance issues. Some are inherited, but most are unknown. There are various treatment options, but no cure.
Parkinson's medications can cause memory loss, confusion, delusions, and obsessive behaviors. The drug's effects on dopamine cause these issues.
A 2019 JAMA Internal Medicine study found powerful anticholinergic medications enhance dementia risk.
Those who took anticholinergics had a 1.5 times higher chance of dementia. Individuals taking antidepressants, antipsychotic drugs, anti-Parkinson’s drugs, overactive bladder drugs, and anti-epileptic drugs had the greatest risk of dementia.
Anticholinergic medicines can lessen Parkinson's-related tremors, but they slow cognitive ability. Anticholinergics can cause disorientation and hallucinations in those over 70.
5. Antiepileptic drugs and dementia
The risk of dementia from anti-seizure drugs varies with drugs. Levetiracetam (Keppra) improves Alzheimer's cognition.
One study linked different anti-seizure medications to dementia. Anti-epileptic medicines increased the risk of Alzheimer's disease by 1.15 times in the Finnish sample and 1.3 times in the German population. Depakote, Topamax are drugs.

Tomas Pueyo
2 years ago
Soon, a Starship Will Transform Humanity
SpaceX's Starship.

Launched last week.
Four minutes in:
SpaceX will succeed. When it does, its massiveness will matter.
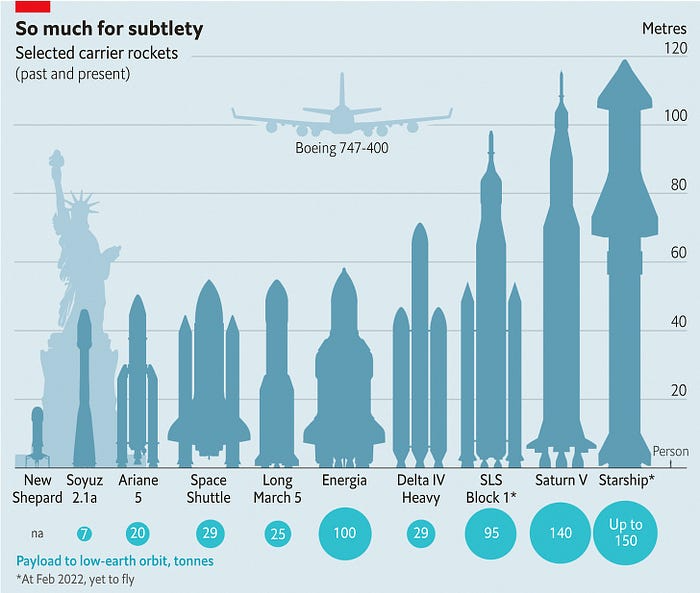
Its payload will revolutionize space economics.
Civilization will shift.
We don't yet understand how this will affect space and Earth culture. Grab it.
The Cost of Space Transportation Has Decreased Exponentially
Space launches have increased dramatically in recent years.
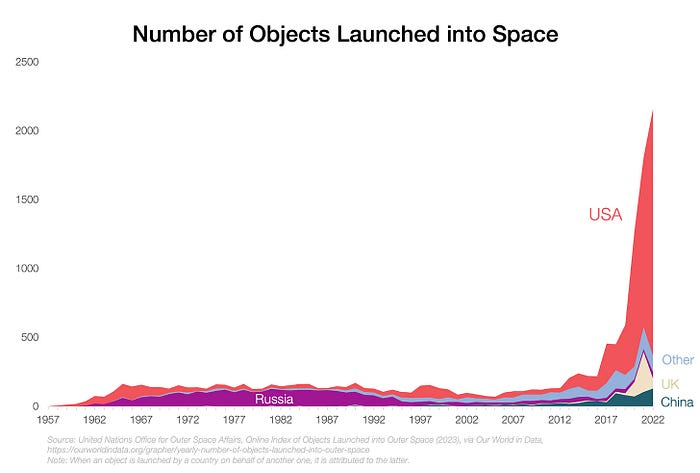
We mostly send items to LEO, the green area below:
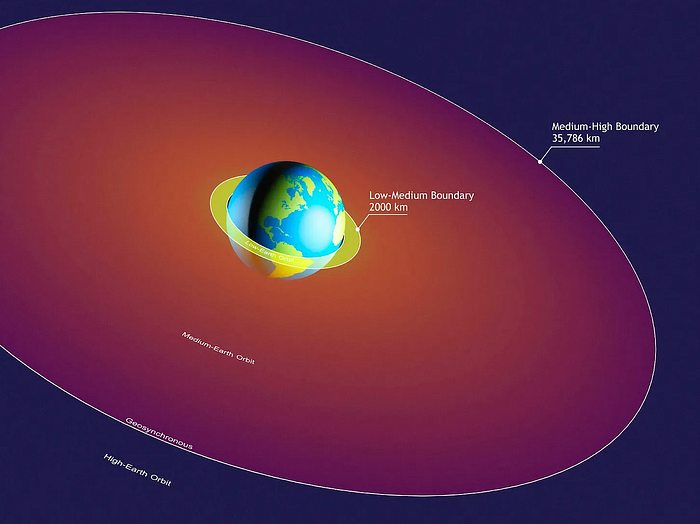
SpaceX's reusable rockets can send these things to LEO. Each may launch dozens of payloads into space.
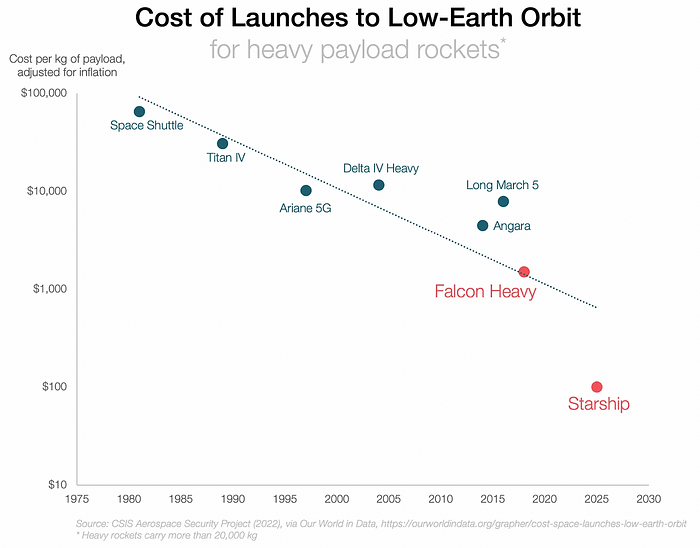
With all these launches, we're sending more than simply things to space. Volume and mass. Since the 1980s, launching a kilogram of payload to LEO has become cheaper:
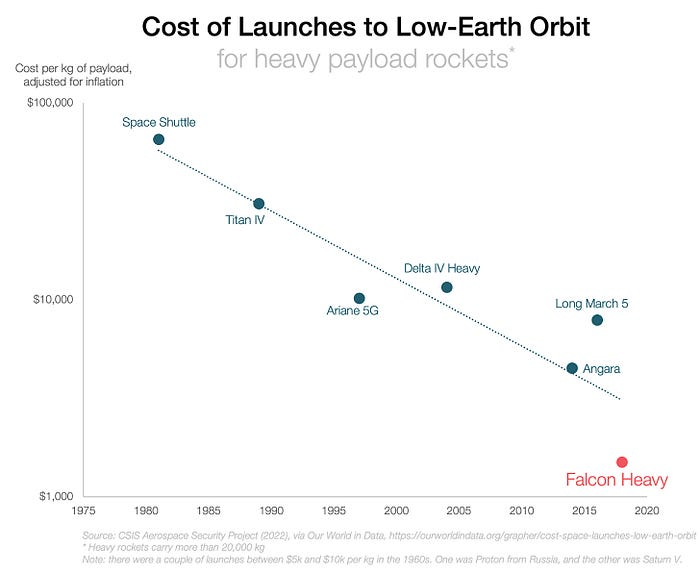
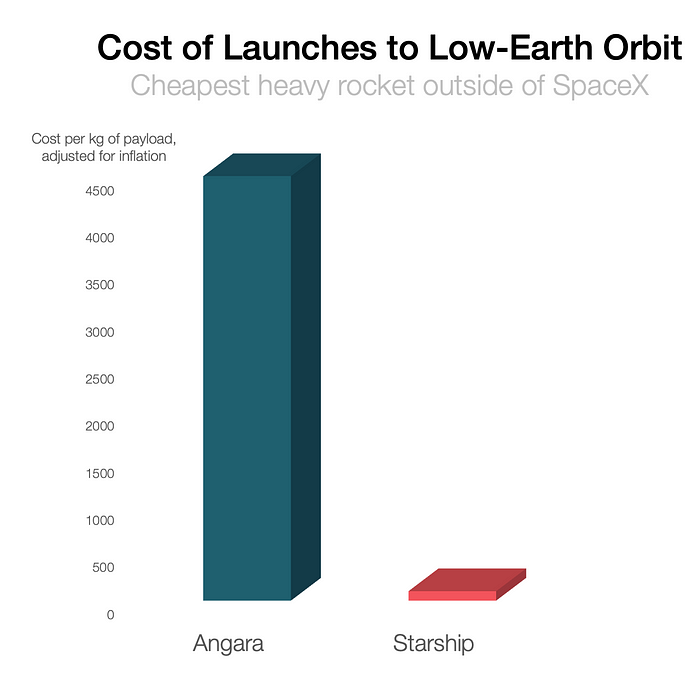
One kilogram in a large rocket cost over $75,000 in the 1980s. Carrying one astronaut cost nearly $5M! Falcon Heavy's $1,500/kg price is 50 times lower. SpaceX's larger, reusable rockets are amazing.
SpaceX's Starship rocket will continue. It can carry over 100 tons to LEO, 50% more than the current Falcon heavy. Thousands of launches per year. Elon Musk predicts Falcon Heavy's $1,500/kg cost will plummet to $100 in 23 years.
In context:
People underestimate this.
2. The Benefits of Affordable Transportation
Compare Earth's transportation costs:
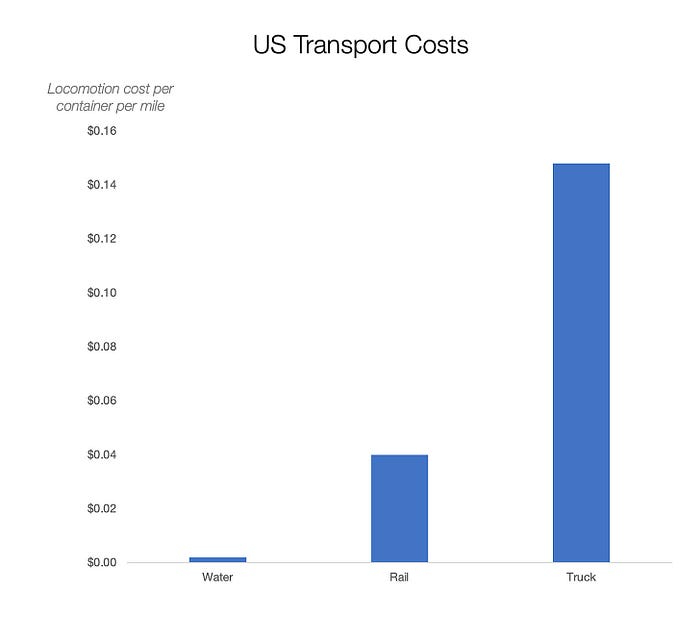
It's no surprise that the US and Northern Europe are the wealthiest and have the most navigable interior waterways.
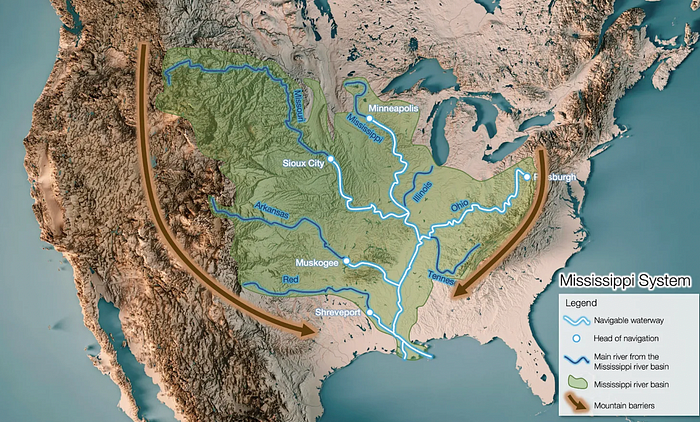
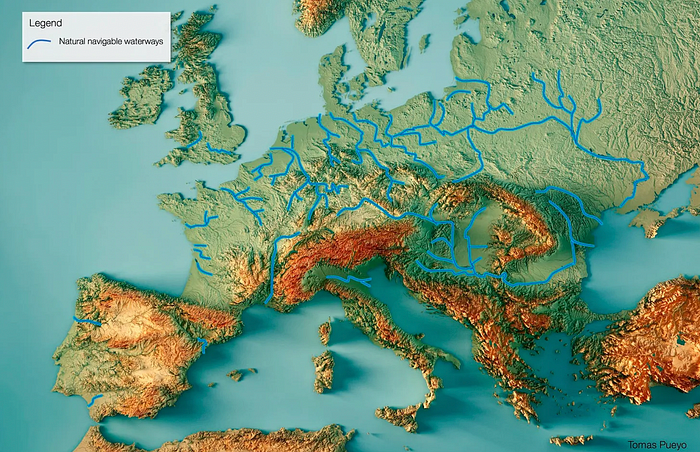
So what? since sea transportation is cheaper than land. Inland waterways are even better than sea transportation since weather is less of an issue, currents can be controlled, and rivers serve two banks instead of one for coastal transportation.
In France, because population density follows river systems, rivers are valuable. Cheap transportation brought people and money to rivers, especially their confluences.
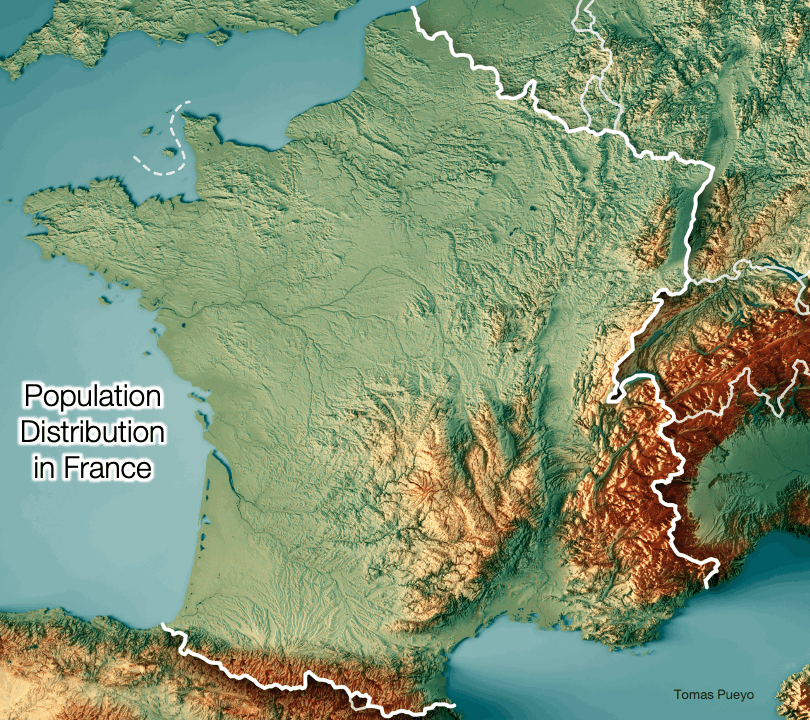
How come? Why were humans surrounding rivers?
Imagine selling meat for $10 per kilogram. Transporting one kg one kilometer costs $1. Your margin decreases $1 each kilometer. You can only ship 10 kilometers. For example, you can only trade with four cities:
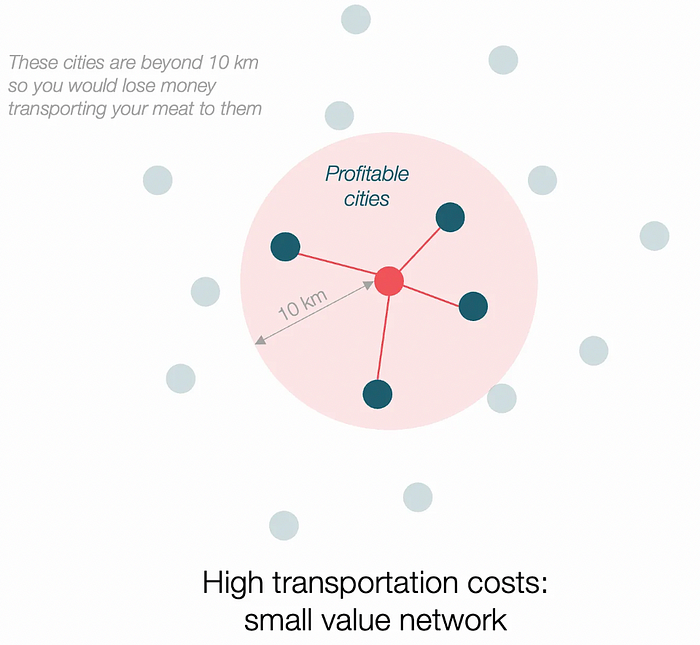
If instead, your cost of transportation is half, what happens? It costs you $0.5 per km. You now have higher margins with each city you traded with. More importantly, you can reach 20-km markets.
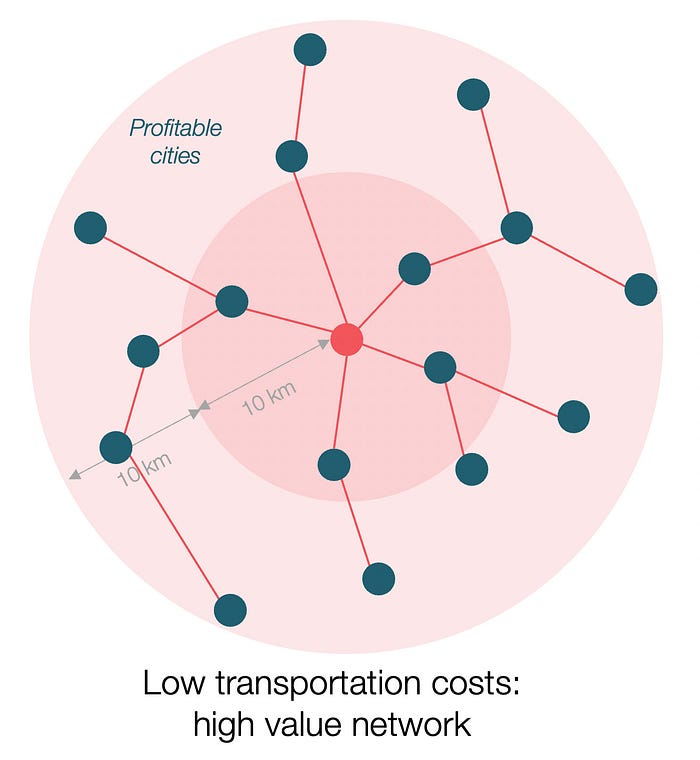
However, 2x distance 4x surface! You can now trade with sixteen cities instead of four! Metcalfe's law states that a network's value increases with its nodes squared. Since now sixteen cities can connect to yours. Each city now has sixteen connections! They get affluent and can afford more meat.
Rivers lower travel costs, connecting many cities, which can trade more, get wealthy, and buy more.
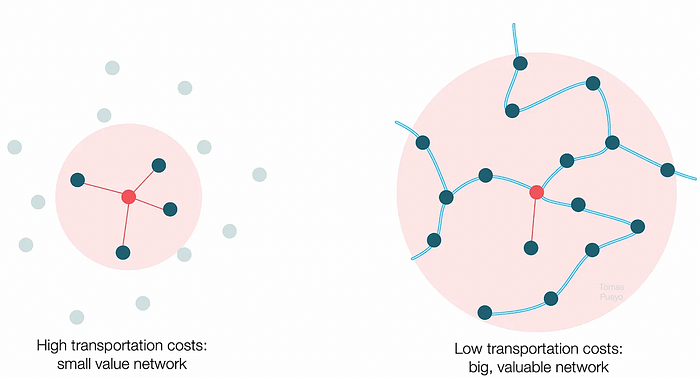
The right network is worth at least an order of magnitude more than the left! The cheaper the transport, the more trade at a lower cost, the more income generated, the more that wealth can be reinvested in better canals, bridges, and roads, and the wealth grows even more.
Throughout history. Rome was established around cheap Mediterranean transit and preoccupied with cutting overland transportation costs with their famous roadways. Communications restricted their empire.
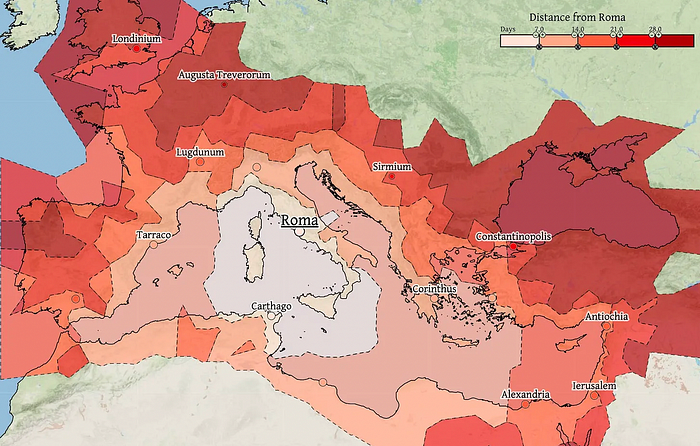
The Egyptians lived around the Nile, the Vikings around the North Sea, early Japan around the Seto Inland Sea, and China started canals in the 5th century BC.
Transportation costs shaped empires.Starship is lowering new-world transit expenses. What's possible?
3. Change Organizations, Change Companies, Change the World
Starship is a conveyor belt to LEO. A new world of opportunity opens up as transportation prices drop 100x in a decade.
Satellite engineers have spent decades shedding milligrams. Weight influenced every decision: pricing structure, volumes to be sent, material selections, power sources, thermal protection, guiding, navigation, and control software. Weight was everything in the mission. To pack as much science into every millimeter, NASA missions had to be miniaturized. Engineers were indoctrinated against mass.
No way.
Starship is not constrained by any space mission, robotic or crewed.
Starship obliterates the mass constraint and every last vestige of cultural baggage it has gouged into the minds of spacecraft designers. A dollar spent on mass optimization no longer buys a dollar saved on launch cost. It buys nothing. It is time to raise the scope of our ambition and think much bigger. — Casey Handmer, Starship is still not understood
A Tesla Roadster in space makes more sense.

It went beyond bad PR. It told the industry: Did you care about every microgram? No more. My rockets are big enough to send a Tesla without noticing. Industry watchers should have noticed.
Most didn’t. Artemis is a global mission to send astronauts to the Moon and build a base. Artemis uses disposable Space Launch System rockets. Instead of sending two or three dinky 10-ton crew habitats over the next decade, Starship might deliver 100x as much cargo and create a base for 1,000 astronauts in a year or two. Why not? Because Artemis remains in a pre-Starship paradigm where each kilogram costs a million dollars and we must aggressively descope our objective.

Space agencies can deliver 100x more payload to space for the same budget with 100x lower costs and 100x higher transportation volumes. How can space economy saturate this new supply?
Before Starship, NASA supplied heavy equipment for Moon base construction. After Starship, Caterpillar and Deere may space-qualify their products with little alterations. Instead than waiting decades for NASA engineers to catch up, we could send people to build a space outpost with John Deere equipment in a few years.
History is littered with the wreckage of former industrial titans that underestimated the impact of new technology and overestimated their ability to adapt: Blockbuster, Motorola, Kodak, Nokia, RIM, Xerox, Yahoo, IBM, Atari, Sears, Hitachi, Polaroid, Toshiba, HP, Palm, Sony, PanAm, Sega, Netscape, Compaq, GM… — Casey Handmer, Starship is still not understood
Everyone saw it coming, but senior management failed to realize that adaption would involve moving beyond their established business practice. Others will if they don't.
4. The Starship Possibilities
It's Starlink.

SpaceX invented affordable cargo space and grasped its implications first. How can we use all this inexpensive cargo nobody knows how to use?
Satellite communications seemed like the best way to capitalize on it. They tried. Starlink, designed by SpaceX, provides fast, dependable Internet worldwide. Beaming information down is often cheaper than cable. Already profitable.
Starlink is one use for all this cheap cargo space. Many more. The longer firms ignore the opportunity, the more SpaceX will acquire.
What are these chances?
Satellite imagery is outdated and lacks detail. We can improve greatly. Synthetic aperture radar can take beautiful shots like this:

Have you ever used Google Maps and thought, "I want to see this in more detail"? What if I could view Earth live? What if we could livestream an infrared image of Earth?

We could launch hundreds of satellites with such mind-blowing visual precision of the Earth that we would dramatically improve the accuracy of our meteorological models; our agriculture; where crime is happening; where poachers are operating in the savannah; climate change; and who is moving military personnel where. Is that useful?
What if we could see Earth in real time? That affects businesses? That changes society?

Katherine Kornei
3 years ago
The InSight lander from NASA has recorded the greatest tremor ever felt on Mars.
The magnitude 5 earthquake was responsible for the discharge of energy that was 10 times greater than the previous record holder.
Any Martians who happen to be reading this should quickly learn how to duck and cover.
NASA's Jet Propulsion Laboratory in Pasadena, California, reported that on May 4, the planet Mars was shaken by an earthquake of around magnitude 5, making it the greatest Marsquake ever detected to this point. The shaking persisted for more than six hours and unleashed more than ten times as much energy as the earthquake that had previously held the record for strongest.
The event was captured on record by the InSight lander, which is operated by the United States Space Agency and has been researching the innards of Mars ever since it touched down on the planet in 2018 (SN: 11/26/18). The epicenter of the earthquake was probably located in the vicinity of Cerberus Fossae, which is located more than 1,000 kilometers away from the lander.
The surface of Cerberus Fossae is notorious for being broken up and experiencing periodic rockfalls. According to geophysicist Philippe Lognonné, who is the lead investigator of the Seismic Experiment for Interior Structure, the seismometer that is onboard the InSight lander, it is reasonable to assume that the ground is moving in that area. "This is an old crater from a volcanic eruption."
Marsquakes, which are similar to earthquakes in that they give information about the interior structure of our planet, can be utilized to investigate what lies beneath the surface of Mars (SN: 7/22/21). And according to Lognonné, who works at the Institut de Physique du Globe in Paris, there is a great deal that can be gleaned from analyzing this massive earthquake. Because the quality of the signal is so high, we will be able to focus on the specifics.
You might also like

Michelle Teheux
3 years ago
Get Real, All You Grateful Laid-Off LinkedIn Users
WTF is wrong with you people?

When I was laid off as editor of my town's daily newspaper, I went silent on social media. I knew it was coming and had been quietly removing personal items each day, but the pain was intense.
I posted a day later. I didn't bad-mouth GateHouse Media but expressed my sadness at leaving the newspaper industry, pride in my accomplishments, and hope for success in another industry.
Normal job-loss response.
What do you recognize as abnormal?
The bullshit I’ve been reading from laid-off folks on LinkedIn.
If you're there, you know. Many Twitter or Facebook/Meta employees recently lost their jobs.
Well, many of them did not “lose their job,” actually. They were “impacted by the layoffs” at their former employer. I keep seeing that phrase.
Why don’t they want to actually say it? Why the euphemism?
Many are excited about the opportunities ahead. The jobless deny being sad.
They're ecstatic! They have big plans.
Hope so. Sincerely! Being laid off stinks, especially if, like me, your skills are obsolete. It's worse if, like me, you're too old to start a new career. Ageism exists despite denials.
Nowadays, professionalism seems to demand psychotic levels of fake optimism.
Why? Life is unpredictable. That's indisputable. You shouldn't constantly complain or cry in public, but you also shouldn't pretend everything's great.
It makes you look psychotic, not positive. It's like saying at work:
“I was impacted by the death of my spouse of 20 years this week, and many of you have reached out to me, expressing your sympathy. However, I’m choosing to remember the amazing things we shared. I feel confident that there is another marriage out there for me, and after taking a quiet weekend trip to reset myself, I’ll be out there looking for the next great marital adventure! #staypositive #available #opentolove
Also:
“Now looking for our next #dreamhome after our entire neighborhood was demolished by a wildfire last night. We feel so lucky to have lived near so many amazing and inspirational neighbors, all of whom we will miss as we go on our next housing adventure. The best house for us is yet to come! If you have a great neighborhood you’d recommend, please feel free to reach out and touch base with us! #newhouse #newneighborhood #newlife
Admit it. That’s creepy.
The constant optimism makes me feel sick to my stomach.
Viscerally.
I hate fakes.
Imagine a fake wood grain desk. Wouldn't it be better if the designer accepted that it's plastic and went with that?
Real is better but not always nice. When something isn't nice, you don't have to go into detail, but you also shouldn't pretend it's great.
How to announce your job loss to the world.
Do not pretend to be happy, but don't cry and drink vodka all afternoon.
Say you loved your job, and that you're looking for new opportunities.
Yes, if you'll miss your coworkers. Otherwise, don't badmouth. No bridge-burning!
Please specify the job you want. You may want to pivot.
Alternatively, try this.
You could always flame out.
If you've pushed yourself too far into toxic positivity, you may be ready to burn it all down. If so, make it worthwhile by writing something like this:
Well, I was shitcanned by the losers at #Acme today. That bitch Linda in HR threw me under the bus just because she saw that one of my “friends” tagged me in some beach pics on social media after I called in sick with Covid. The good thing is I will no longer have to watch my ass around that #asspincher Ron in accounting, but I’m sad that I will no longer have a cushy job with high pay or access to the primo office supplies I’ve been sneaking home for the last five years. (Those gel pens were the best!) I am going to be taking some time off to enjoy my unemployment and hammer down shots of Jägermeister but in about five months I’ll be looking for anything easy with high pay and great benefits. Reach out if you can help! #officesupplies #unemploymentrocks #drinkinglikeagirlboss #acmesucks
It beats the fake positivity.

Max Parasol
4 years ago
What the hell is Web3 anyway?
"Web 3.0" is a trendy buzzword with a vague definition. Everyone agrees it has to do with a blockchain-based internet evolution, but what is it?
Yet, the meaning and prospects for Web3 have become hot topics in crypto communities. Big corporations use the term to gain a foothold in the space while avoiding the negative connotations of “crypto.”
But it can't be evaluated without a definition.
Among those criticizing Web3's vagueness is Cobie:
“Despite the dominie's deluge of undistinguished think pieces, nobody really agrees on what Web3 is. Web3 is a scam, the future, tokenizing the world, VC exit liquidity, or just another name for crypto, depending on your tribe.
“Even the crypto community is split on whether Bitcoin is Web3,” he adds.
The phrase was coined by an early crypto thinker, and the community has had years to figure out what it means. Many ideologies and commercial realities have driven reverse engineering.
Web3 is becoming clearer as a concept. It contains ideas. It was probably coined by Ethereum co-founder Gavin Wood in 2014. His definition of Web3 included “trustless transactions” as part of its tech stack. Wood founded the Web3 Foundation and the Polkadot network, a Web3 alternative future.
The 2013 Ethereum white paper had previously allowed devotees to imagine a DAO, for example.
Web3 now has concepts like decentralized autonomous organizations, sovereign digital identity, censorship-free data storage, and data divided by multiple servers. They intertwine discussions about the “Web3” movement and its viability.
These ideas are linked by Cobie's initial Web3 definition. A key component of Web3 should be “ownership of value” for one's own content and data.
Noting that “late-stage capitalism greedcorps that make you buy a fractionalized micropayment NFT on Cardano to operate your electric toothbrush” may build the new web, he notes that “crypto founders are too rich to care anymore.”
Very Important
Many critics of Web3 claim it isn't practical or achievable. Web3 critics like Moxie Marlinspike (creator of sslstrip and Signal/TextSecure) can never see people running their own servers. Early in January, he argued that protocols are more difficult to create than platforms.
While this is true, some projects, like the file storage protocol IPFS, allow users to choose which jurisdictions their data is shared between.
But full decentralization is a difficult problem. Suhaza, replying to Moxie, said:
”People don't want to run servers... Companies are now offering API access to an Ethereum node as a service... Almost all DApps interact with the blockchain using Infura or Alchemy. In fact, when a DApp uses a wallet like MetaMask to interact with the blockchain, MetaMask is just calling Infura!
So, here are the questions: Web3: Is it a go? Is it truly decentralized?
Web3 history is shaped by Web2 failure.
This is the story of how the Internet was turned upside down...
Then came the vision. Everyone can create content for free. Decentralized open-source believers like Tim Berners-Lee popularized it.
Real-world data trade-offs for content creation and pricing.
A giant Wikipedia page married to a giant Craig's List. No ads, no logins, and a private web carve-up. For free usage, you give up your privacy and data to the algorithmic targeted advertising of Web 2.
Our data is centralized and savaged by giant corporations. Data localization rules and geopolitical walls like China's Great Firewall further fragment the internet.
The decentralized Web3 reflects Berners-original Lee's vision: "No permission is required from a central authority to post anything... there is no central controlling node and thus no single point of failure." Now he runs Solid, a Web3 data storage startup.
So Web3 starts with decentralized servers and data privacy.
Web3 begins with decentralized storage.
Data decentralization is a key feature of the Web3 tech stack. Web2 has closed databases. Large corporations like Facebook, Google, and others go to great lengths to collect, control, and monetize data. We want to change it.
Amazon, Google, Microsoft, Alibaba, and Huawei, according to Gartner, currently control 80% of the global cloud infrastructure market. Web3 wants to change that.
Decentralization enlarges power structures by giving participants a stake in the network. Users own data on open encrypted networks in Web3. This area has many projects.
Apps like Filecoin and IPFS have led the way. Data is replicated across multiple nodes in Web3 storage providers like Filecoin.
But the new tech stack and ideology raise many questions.
Giving users control over their data
According to Ryan Kris, COO of Verida, his “Web3 vision” is “empowering people to control their own data.”
Verida targets SDKs that address issues in the Web3 stack: identity, messaging, personal storage, and data interoperability.
A big app suite? “Yes, but it's a frontier technology,” he says. They are currently building a credentialing system for decentralized health in Bermuda.
By empowering individuals, how will Web3 create a fairer internet? Kris, who has worked in telecoms, finance, cyber security, and blockchain consulting for decades, admits it is difficult:
“The viability of Web3 raises some good business questions,” he adds. “How can users regain control over centralized personal data? How are startups motivated to build products and tools that support this transition? How are existing Web2 companies encouraged to pivot to a Web3 business model to compete with market leaders?
Kris adds that new technologies have regulatory and practical issues:
"On storage, IPFS is great for redundantly sharing public data, but not designed for securing private personal data. It is not controlled by the users. When data storage in a specific country is not guaranteed, regulatory issues arise."
Each project has varying degrees of decentralization. The diehards say DApps that use centralized storage are no longer “Web3” companies. But fully decentralized technology is hard to build.
Web2.5?
Some argue that we're actually building Web2.5 businesses, which are crypto-native but not fully decentralized. This is vital. For example, the NFT may be on a blockchain, but it is linked to centralized data repositories like OpenSea. A server failure could result in data loss.
However, according to Apollo Capital crypto analyst David Angliss, OpenSea is “not exactly community-led”. Also in 2021, much to the chagrin of crypto enthusiasts, OpenSea tried and failed to list on the Nasdaq.
This is where Web2.5 is defined.
“Web3 isn't a crypto segment. “Anything that uses a blockchain for censorship resistance is Web3,” Angliss tells us.
“Web3 gives users control over their data and identity. This is not possible in Web2.”
“Web2 is like feudalism, with walled-off ecosystems ruled by a few. For example, an honest user owned the Instagram account “Meta,” which Facebook rebranded and then had to make up a reason to suspend. Not anymore with Web3. If I buy ‘Ethereum.ens,' Ethereum cannot take it away from me.”
Angliss uses OpenSea as a Web2.5 business example. Too decentralized, i.e. censorship resistant, can be unprofitable for a large company like OpenSea. For example, OpenSea “enables NFT trading”. But it also stopped the sale of stolen Bored Apes.”
Web3 (or Web2.5, depending on the context) has been described as a new way to privatize internet.
“Being in the crypto ecosystem doesn't make it Web3,” Angliss says. The biggest risk is centralized closed ecosystems rather than a growing Web3.
LooksRare and OpenDAO are two community-led platforms that are more decentralized than OpenSea. LooksRare has even been “vampire attacking” OpenSea, indicating a Web3 competitor to the Web2.5 NFT king could find favor.
The addition of a token gives these new NFT platforms more options for building customer loyalty. For example, OpenSea charges a fee that goes nowhere. Stakeholders of LOOKS tokens earn 100% of the trading fees charged by LooksRare on every basic sale.
Maybe Web3's time has come.
So whose data is it?
Continuing criticisms of Web3 platforms' decentralization may indicate we're too early. Users want to own and store their in-game assets and NFTs on decentralized platforms like the Metaverse and play-to-earn games. Start-ups like Arweave, Sia, and Aleph.im propose an alternative.
To be truly decentralized, Web3 requires new off-chain models that sidestep cloud computing and Web2.5.
“Arweave and Sia emerged as formidable competitors this year,” says the Messari Report. They seek to reduce the risk of an NFT being lost due to a data breach on a centralized server.
Aleph.im, another Web3 cloud competitor, seeks to replace cloud computing with a service network. It is a decentralized computing network that supports multiple blockchains by retrieving and encrypting data.
“The Aleph.im network provides a truly decentralized alternative where it is most needed: storage and computing,” says Johnathan Schemoul, founder of Aleph.im. For reasons of consensus and security, blockchains are not designed for large storage or high-performance computing.
As a result, large data sets are frequently stored off-chain, increasing the risk for centralized databases like OpenSea
Aleph.im enables users to own digital assets using both blockchains and off-chain decentralized cloud technologies.
"We need to go beyond layer 0 and 1 to build a robust decentralized web. The Aleph.im ecosystem is proving that Web3 can be decentralized, and we intend to keep going.”
Aleph.im raised $10 million in mid-January 2022, and Ubisoft uses its network for NFT storage. This is the first time a big-budget gaming studio has given users this much control.
It also suggests Web3 could work as a B2B model, even if consumers aren't concerned about “decentralization.” Starting with gaming is common.
Can Tokenomics help Web3 adoption?
Web3 consumer adoption is another story. The average user may not be interested in all this decentralization talk. Still, how much do people value privacy over convenience? Can tokenomics solve the privacy vs. convenience dilemma?
Holon Global Investments' Jonathan Hooker tells us that human internet behavior will change. “Do you own Bitcoin?” he asks in his Web3 explanation. How does it feel to own and control your own sovereign wealth? Then:
“What if you could own and control your data like Bitcoin?”
“The business model must find what that person values,” he says. Putting their own health records on centralized systems they don't control?
“How vital are those medical records to that person at a critical time anywhere in the world? Filecoin and IPFS can help.”
Web3 adoption depends on NFT storage competition. A free off-chain storage of NFT metadata and assets was launched by Filecoin in April 2021.
Denationalization and blockchain technology have significant implications for data ownership and compensation for lending, staking, and using data.
Tokenomics can change human behavior, but many people simply sign into Web2 apps using a Facebook API without hesitation. Our data is already owned by Google, Baidu, Tencent, and Facebook (and its parent company Meta). Is it too late to recover?
Maybe. “Data is like fruit, it starts out fresh but ages,” he says. "Big Tech's data on us will expire."
Web3 founder Kris agrees with Hooker that “value for data is the issue, not privacy.” People accept losing their data privacy, so tokenize it. People readily give up data, so why not pay for it?
"Personalized data offering is valuable in personalization. “I will sell my social media data but not my health data.”
Purists and mass consumer adoption struggle with key management.
Others question data tokenomics' optimism. While acknowledging its potential, Box founder Aaron Levie questioned the viability of Web3 models in a Tweet thread:
“Why? Because data almost always works in an app. A product and APIs that moved quickly to build value and trust over time.”
Levie contends that tokenomics may complicate matters. In addition to community governance and tokenomics, Web3 ideals likely add a new negotiation vector.
“These are hard problems about human coordination, not software or blockchains,”. Using a Facebook API is simple. The business model and user interface are crucial.
For example, the crypto faithful have a common misconception about logging into Web3. It goes like this: Web 1 had usernames and passwords. Web 2 uses Google, Facebook, or Twitter APIs, while Web 3 uses your wallet. Pay with Ethereum on MetaMask, for example.
But Levie is correct. Blockchain key management is stressed in this meme. Even seasoned crypto enthusiasts have heart attacks, let alone newbies.
Web3 requires a better user experience, according to Kris, the company's founder. “How does a user recover keys?”
And at this point, no solution is likely to be completely decentralized. So Web3 key management can be improved. ”The moment someone loses control of their keys, Web3 ceases to exist.”
That leaves a major issue for Web3 purists. Put this one in the too-hard basket.
Is 2022 the Year of Web3?
Web3 must first solve a number of issues before it can be mainstreamed. It must be better and cheaper than Web2.5, or have other significant advantages.
Web3 aims for scalability without sacrificing decentralization protocols. But decentralization is difficult and centralized services are more convenient.
Ethereum co-founder Vitalik Buterin himself stated recently"
This is why (centralized) Binance to Binance transactions trump Ethereum payments in some places because they don't have to be verified 12 times."
“I do think a lot of people care about decentralization, but they're not going to take decentralization if decentralization costs $8 per transaction,” he continued.
“Blockchains need to be affordable for people to use them in mainstream applications... Not for 2014 whales, but for today's users."
For now, scalability, tokenomics, mainstream adoption, and decentralization believers seem to be holding Web3 hostage.
Much like crypto's past.
But stay tuned.

ANDREW SINGER
3 years ago
Crypto seen as the ‘future of money’ in inflation-mired countries
Crypto as the ‘future of money' in inflation-stricken nations
Citizens of devalued currencies “need” crypto. “Nice to have” in the developed world.
According to Gemini's 2022 Global State of Crypto report, cryptocurrencies “evolved from what many considered a niche investment into an established asset class” last year.
More than half of crypto owners in Brazil (51%), Hong Kong (51%), and India (54%), according to the report, bought cryptocurrency for the first time in 2021.
The study found that inflation and currency devaluation are powerful drivers of crypto adoption, especially in emerging market (EM) countries:
“Respondents in countries that have seen a 50% or greater devaluation of their currency against the USD over the last decade were more than 5 times as likely to plan to purchase crypto in the coming year.”
Between 2011 and 2021, the real lost 218 percent of its value against the dollar, and 45 percent of Brazilians surveyed by Gemini said they planned to buy crypto in 2019.
The rand (South Africa's currency) has fallen 103 percent in value over the last decade, second only to the Brazilian real, and 32 percent of South Africans expect to own crypto in the coming year. Mexico and India, the third and fourth highest devaluation countries, followed suit.
Compared to the US dollar, Hong Kong and the UK currencies have not devalued in the last decade. Meanwhile, only 5% and 8% of those surveyed in those countries expressed interest in buying crypto.
What can be concluded? Noah Perlman, COO of Gemini, sees various crypto use cases depending on one's location.
‘Need to have' investment in countries where the local currency has devalued against the dollar, whereas in the developed world it is still seen as a ‘nice to have'.
Crypto as money substitute
As an adjunct professor at New York University School of Law, Winston Ma distinguishes between an asset used as an inflation hedge and one used as a currency replacement.
Unlike gold, he believes Bitcoin (BTC) is not a “inflation hedge”. They acted more like growth stocks in 2022. “Bitcoin correlated more closely with the S&P 500 index — and Ether with the NASDAQ — than gold,” he told Cointelegraph. But in the developing world, things are different:
“Inflation may be a primary driver of cryptocurrency adoption in emerging markets like Brazil, India, and Mexico.”
According to Justin d'Anethan, institutional sales director at the Amber Group, a Singapore-based digital asset firm, early adoption was driven by countries where currency stability and/or access to proper banking services were issues. Simply put, he said, developing countries want alternatives to easily debased fiat currencies.
“The larger flows may still come from institutions and developed countries, but the actual users may come from places like Lebanon, Turkey, Venezuela, and Indonesia.”
“Inflation is one of the factors that has and continues to drive adoption of Bitcoin and other crypto assets globally,” said Sean Stein Smith, assistant professor of economics and business at Lehman College.
But it's only one factor, and different regions have different factors, says Stein Smith. As a “instantaneously accessible, traceable, and cost-effective transaction option,” investors and entrepreneurs increasingly recognize the benefits of crypto assets. Other places promote crypto adoption due to “potential capital gains and returns”.
According to the report, “legal uncertainty around cryptocurrency,” tax questions, and a general education deficit could hinder adoption in Asia Pacific and Latin America. In Africa, 56% of respondents said more educational resources were needed to explain cryptocurrencies.
Not only inflation, but empowering our youth to live better than their parents without fear of failure or allegiance to legacy financial markets or products, said Monica Singer, ConsenSys South Africa lead. Also, “the issue of cash and remittances is huge in Africa, as is the issue of social grants.”
Money's future?
The survey found that Brazil and Indonesia had the most cryptocurrency ownership. In each country, 41% of those polled said they owned crypto. Only 20% of Americans surveyed said they owned cryptocurrency.
These markets are more likely to see cryptocurrencies as the future of money. The survey found:
“The majority of respondents in Latin America (59%) and Africa (58%) say crypto is the future of money.”
Brazil (66%), Nigeria (63%), Indonesia (61%), and South Africa (57%). Europe and Australia had the fewest believers, with Denmark at 12%, Norway at 15%, and Australia at 17%.
Will the Ukraine conflict impact adoption?
The poll was taken before the war. Will the devastating conflict slow global crypto adoption growth?
With over $100 million in crypto donations directly requested by the Ukrainian government since the war began, Stein Smith says the war has certainly brought crypto into the mainstream conversation.
“This real-world demonstration of decentralized money's power could spur wider adoption, policy debate, and increased use of crypto as a medium of exchange.”
But the war may not affect all developing nations. “The Ukraine war has no impact on African demand for crypto,” Others loom larger. “Yes, inflation, but also a lack of trust in government in many African countries, and a young demographic very familiar with mobile phones and the internet.”
A major success story like Mpesa in Kenya has influenced the continent and may help accelerate crypto adoption. Creating a plan when everyone you trust fails you is directly related to the African spirit, she said.
On the other hand, Ma views the Ukraine conflict as a sort of crisis check for cryptocurrencies. For those in emerging markets, the Ukraine-Russia war has served as a “stress test” for the cryptocurrency payment rail, he told Cointelegraph.
“These emerging markets may see the greatest future gains in crypto adoption.”
Inflation and currency devaluation are persistent global concerns. In such places, Bitcoin and other cryptocurrencies are now seen as the “future of money.” Not in the developed world, but that could change with better regulation and education. Inflation and its impact on cash holdings are waking up even Western nations.
Read original post here.